nlp|微调大语言模型初探索(2),训练自己的聊天机器人
前言
上篇文章记录了具体的微调语言大模型步骤,以及在微调过程中可能遇见的各种报错,美中不足的是只是基于开源数据集的微调,今天来记录一下怎么基于自己的数据集去微调大语言模型,训练自己的智能机器人!!!!
1.微调数据集介绍
了解数据集的种类及其标注格式对于模型的微调至关重要。不同的数据集有不同的训练目标和标注方式,这些差异决定了模型学习的重点和微调策略的选择。通过深入理解数据集的结构和目标,能够帮助我们更精准地制定微调计划,优化模型的表现,并提升其在实际应用中的效果。
1.1 Alpaca 格式
[{"instruction": "输入三支篮球队的名称并生成一个适当的口号。","input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。","output": "输出: \"雷霆,公牛和网队:各显神通,角逐群雄!\""},...
]
这种格式很好理解,一共就三部分instruction、input和output。
instruction: 任务的指令,告诉模型需要完成什么操作。
input: 任务所需的输入。如果任务是开放式的或者不需要明确的输入,这一字段可以为空字符串。
output: 任务的期望输出,也就是模型在给定指令和输入情况下需要生成的内容。
侧重提升模型各种自然语言处理任务,适合来微调大模型做文本生成、翻译、总结等任务
1.2 DPO 格式
[{"conversations": [{"from": "human","value": "为印度国家投资促进与便利机构的银行、金融服务、保险(BFSI)和金融科技团队的面试候选人创建一个案例研究任务。该团队的使命是支持外国投资进入印度的BFSI领域,并就该领域的产业参与者的政策建议和问题进行工作。"}],"chosen": {"from": "gpt","value": "标题:支持外国投资在BFSI领域:印度国家投资促进和便利机构的案例研究\n\n目标:\n要求候选人创建一个全面的案例研究..."},"rejected": {"from": "gpt","value": "让我们了解为BFSI团队面试候选人创建案例研究作业的要求。"}},...
]
from: 字段指示消息的来源,可以是 “human” 或 “gpt”,表示输入是由人类或模型提供。
value: 字段包含消息的具体内容,可能是输入文本、模型选择的输出或被拒绝的输出。
chosen: 中的内容是模型最终认为最合适的回应。
rejected: 中的内容是模型认为不合适的候选回应。
DPO可以通过调整回答的偏好来生成更符合用户需求的回复,适合微调大模型来做用户偏好回答。
1.3 ShareGPT 格式
[{"conversations": [{"role": "user","content": "What is the capital of France?"},{"role": "assistant","content": "The capital of France is Paris."},{"role": "user","content": "Can you tell me more about Paris?"},{"role": "assistant","content": "Paris is the largest city and the capital of France. It is known for its art, culture, and history..."}]}...
]
role: 表示对话的角色,通常为“user”表示用户,“assistant”表示AI助手。
content: 具体的对话内容
ShareGPT 适合对话场景,更贴近人类与 AI 交互的方式,适用于构建和微调对话模型。
Q1.为什么这么多格式的数据集,统一数据集岂不是更方便?
我的理解是,不同类型格式的数据集对模型性能的提升不同,比如说DPO 侧重于根据用户偏好调整模型的输出,使其更符合个性化需求,而Alpaca 侧重于通过少量高质量的训练数据提升模型的指令跟随能力和高效训练。
2.制作微调数据集
我这里基于gpt,根据Alpaca 格式去生成json数据集:
from docx import Document
from chat_test import get_response
import json
from tqdm import tqdmdef extract_json_from_string(input_str):# 使用正则表达式提取[]里的内容,包括大括号head_pos = input_str.find("[")tail_pos = input_str.find("]")if head_pos != -1 and tail_pos != -1:return json.loads(input_str[head_pos:tail_pos + 1]) # 包括']',所以尾部索引需要+1else:return None # 如果没有找到[],返回Nonepath = 'F:/Desktop/docs/xxx.docx'
doc = Document(path)
text = ""
data_json = []
file = open("alpaca_zh_mydata1.json", "w", encoding="utf-8")
for para in tqdm(doc.paragraphs):if para.text == "":# print("=============None")continue# print(para.text)text = text + para.text + "\n"# print(len(text))if len(text) >= 2000:text = text + " 根据上述信息,将其制作成alpaca数据集。包括instruction、input和output"res = get_response(text)# print(res)json_str = Nonetry:json_str = extract_json_from_string(res)except:print("extract_json_from_string run error")if json_str is None:text = ""continuedata_json = data_json + json_strjson.dump(data_json, file, ensure_ascii=False, indent=2)
file.close()其中get_response函数为chatgpt的api接口,可以根据自己的需求去封装。
如图所示,生成的数据集是这样的:

3.开始微调数据集
3.1 将生成json文件放到LLaMA-Factory/data/

3.2 修改LLaMA-Factory/data/dataset_info.json文件

3.3 修改LLaMA-Factory/data/dataset_info.json文件
开始微调大模型:
conda activate lora-llama
cd LLaMA-Factory
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml

参考文章
大模型微调——训练数据集的格式Alpaca 和 ShareGPT
相关文章:
nlp|微调大语言模型初探索(2),训练自己的聊天机器人
前言 上篇文章记录了具体的微调语言大模型步骤,以及在微调过程中可能遇见的各种报错,美中不足的是只是基于开源数据集的微调,今天来记录一下怎么基于自己的数据集去微调大语言模型,训练自己的智能机器人!!&…...

win11安装wsl报错:无法解析服务器的名称或地址(启用wsl2)
1. 启用wsl报错如下 # 查看可安装的 wsl --install wsl --list --online此原因是因为没有开启DNS的原因,所以需要我们手动开启DNS。 2. 按照如下配置即可 Google的DNS(8.8.8.8和8.8.4.4) 全国通用DNS地址 (114.114.114.114) 3. 运行以下命令来重启 WSL…...

Gentleman:优雅的Go语言HTTP客户端工具包
gentlemen介绍,特点等 插件驱动架构:Gentleman的核心特点是其插件系统,允许用户注册和重用各种自定义插件,如重试策略或动态服务器发现,以增强HTTP客户端的功能。 中间件层:项目内置了一个上下文感知的层次…...

解锁豆瓣高清海报(三)从深度爬虫到URL构造,实现极速下载
脚本地址: 项目地址: Gazer PosterBandit_v2.py 前瞻 之前的 PosterBandit.py 是按照深度爬虫的思路一步步进入海报界面来爬取, 是个值得学习的思路, 但缺点是它爬取慢, 仍然容易碰到豆瓣的 418 错误, 本文也会指出彻底解决旧版 418 错误的方法并提高爬取速度. 现在我将介绍…...

IDEA单元测试插件 SquareTest 延长试用期权限
SquareTest是一款强大的IDEA单元测试生成插件工具,具体使用方法就不过多介绍了,这里主要介绍变更试用期,方便大家使用 配置信息 我的电脑安装前提配置条件 IntelliJ IDEA 2023.2windows 系统 软件安装 IntelliJ IDEA 直接安装插件Squar…...

PLC的五个学习步骤
五个学习步骤详解: 1. 夯实电气基础 (第一步) 核心思想: PLC控制技术是建立在传统电气控制技术之上的,因此扎实的电气基础至关重要。学习内容: 电气元件原理: 深入理解继电器、接触器、按钮、三相异步电机等常用电气元件的工作原理。这是理解电气控制回…...

深度学习05 ResNet残差网络
目录 传统卷积神经网络存在的问题 如何解决 批量归一化BatchNormalization, BN 残差连接方式 残差结构 ResNet网络 ResNet 网络是在 2015年 由微软实验室中的何凯明等几位大神提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得CO…...
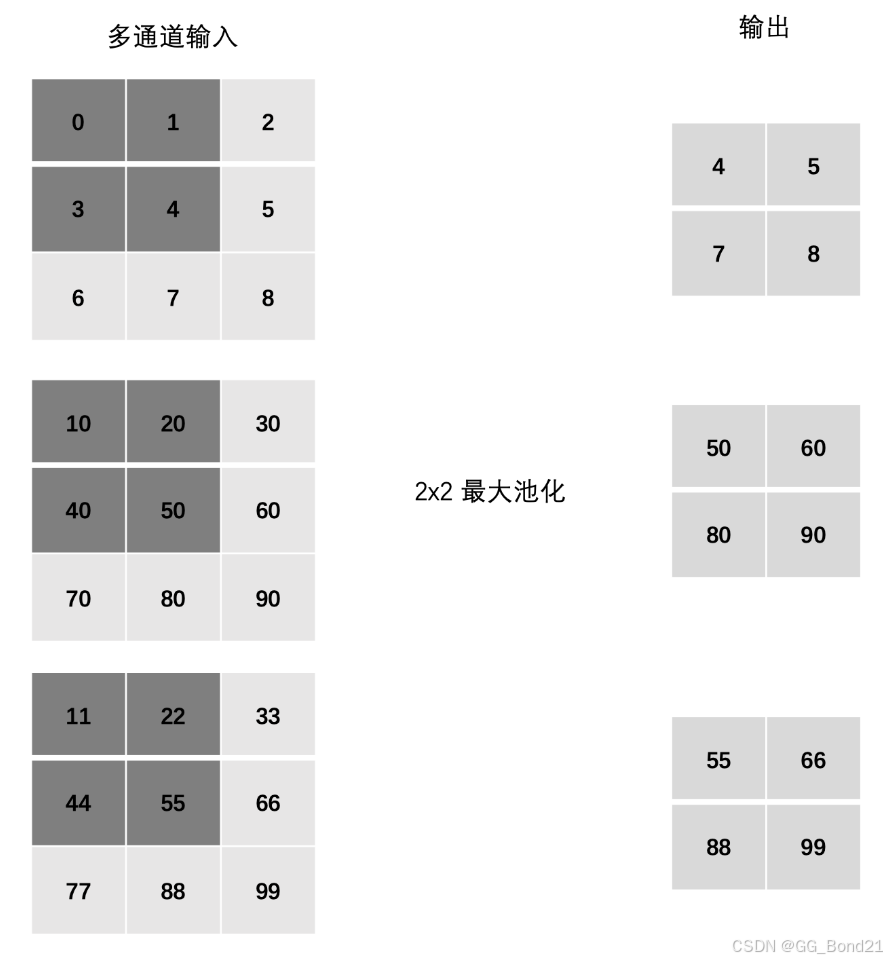
卷积神经网络CNN
目录 一、CNN概述 二、图像基础知识 三、卷积层 3.1 卷积的计算 3.2 Padding 3.3 Stride 3.4 多通道卷积计算 3.5 多卷积核卷积计算 3.6 特征图大小计算 3.7 Pytorch 卷积层API 四、池化层 4.1 池化计算 4.2 Stride 4.3 Padding 4.4 多通道池化计算 4.5 Pytorc…...

Android:播放Rtsp视频流的两种方式
一.SurfaceView Mediaplayer XML中添加SurfaceView: <SurfaceViewandroid:id"id/surface_view"android:layout_width"match_parent"android:layout_height"match_parent"/> Activity代码: package com.android.rtsp;impor…...

web信息泄露 ctfshow-web入门web1-web10
01做题思路 判断做题的思路是读取,写入,还是执行判断大概的类型,有登录逻辑就尝试sql注入,有下载逻辑就尝试文件读取,有源码就做源码审计 02信息泄露及利用 robots.txt 以ctfshow的web1为例,访问robots…...

Log4j在Spring项目中的应用与实践
在现代Java开发中,日志记录是不可或缺的一部分。它不仅帮助开发者调试和监控应用程序的运行状态,还能在出现问题时快速定位原因。今天,我们就来探讨如何在Spring项目中使用Log4j进行日志管理,并通过具体的实例来展示其强大的功能。…...

docker安装mysql:8.0
1.docker源 目前docker国内的源基本上用不了了,建议去淘宝找一找,我整了一个大概是10R一个月。 2.拉取镜像 docker pull mysql:8.0 3.启动容器 命令如下: docker run \-p 3306:3306 \-e MYSQL_ROOT_PASSWORD123456 \-v /home/data/mysq…...

搭建一个 Spring Boot 项目,解决jdk与springboot版本不匹配
搭建一个 Spring Boot 项目 方式一:使用 Spring Initializr Spring Initializr 是一个基于 Web 的工具,用于快速生成 Spring Boot 项目的基础结构。 访问 Spring Initializr 网站:https://start.spring.io/配置项目信息: …...

心心相系:十颗心
心心相系:十颗心 【1】心脏;人心,热心 heart //注:h-通c-或k- warmhearted a.热心的,热心肠的;亲切的a warm-hearted person 为人古道热肠 词根cardi(o)-(heart),例词:cardiology(…...

ChatGPT行业热门应用提示词案例-AI绘画类
AI 绘画指令是一段用于指导 AI 绘画工具(如 DALLE、Midjourney 等)生成特定图像的文本描述。它通常包含场景、主体、风格、色彩、氛围等关键信息,帮助 AI 理解创作者的意图,从而生成符合要求的绘画作品。 ChatGPT 拥有海量的知识…...

前端面试手写--虚拟列表
目录 一.问题背景 二.代码讲解 三.代码改装 四.代码发布 今天我们来学习如何手写一个虚拟列表,本文将把虚拟列表进行拆分并讲解,然后发布到npm网站上. 一.问题背景 为什么需要虚拟列表呢?这是因为在面对大量数据的时候,我们的浏览器会将所有数据都渲染到表格上面,但是渲…...

达梦数据库针对慢SQL,收集统计信息清除执行计划缓存
前言:若遇到以下场景,大概率是SQL走错了执行计划: 1、一条SQL在页面上查询特别慢,但拿到数据库终端执行特别快 2、一条SQL在某种检索条件下查询特别慢,但拿到数据库终端执行特别快 此时,可以尝试按照下述步…...
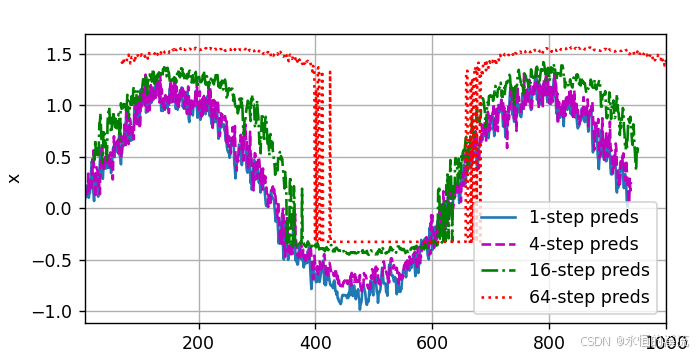
李沐--动手学深度学习 序列模型
1.使用正弦函数和可加性噪声生成序列数据 import torch from torch import nn from d2l import torch as d2l#使用正弦函数和可加性噪声生成序列数据 T 1000 #总共产生1000个点 time torch.arange(1,T1,dtypetorch.float32) x torch.sin(0.01*time) torch.normal(0,0.2,(…...
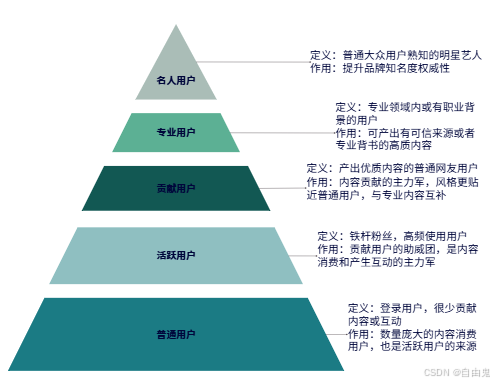
数据分析、商业智能、业务分析三者之间的关系
商业智能 (Business Intelligence, BI)、业务分析 (Business Analytics, BA) 和数据分析 (Data Analytics, DA) 三者都与数据密切相关,但在目标、方法和应用上存在差异。为了能够清晰地解释,下面将从定义入手,然后阐述它们之间的联系和区别。…...

【Spring+MyBatis】留言墙的实现
目录 1. 添加依赖 2. 配置数据库 2.1 创建数据库与数据表 2.2 创建与数据库对应的实体类 3. 后端代码 3.1 目录结构 3.2 MessageController类 3.3 MessageService类 3.4 MessageMapper接口 4. 前端代码 5. 单元测试 5.1 后端接口测试 5.2 使用前端页面测试 在Spri…...

通过Taotoken CLI工具一键配置开发环境中的多模型访问密钥
通过Taotoken CLI工具一键配置开发环境中的多模型访问密钥 1. Taotoken CLI工具概述 Taotoken CLI工具(taotoken/taotoken)是为开发者提供的命令行工具,用于快速配置开发环境中的多模型访问密钥。该工具支持通过交互式菜单或子命令方式&…...

快马平台助力fireworks-tech-graph:三步生成可交互技术架构原型
最近在做一个技术架构可视化的项目,发现从设计到落地验证的过程特别耗时。传统的做法需要先画草图,再用专业工具建模,最后还要写代码实现交互,整个过程至少要花上几天时间。直到尝试了InsCode(快马)平台,发现可以用更简…...

如果文件是客服回话记录,需要采用文件中用户原话,但是一次又不能投入太多文本,怎么解决 ?基于LangChain创建Excel大文件分析技能
如果文件是客服回话记录,需要采用文件中用户原话,但是一次又不能投入太多文本,怎么解决 目录 如果文件是客服回话记录,需要采用文件中用户原话,但是一次又不能投入太多文本,怎么解决 核心原则(不可突破) 第一步:零成本前置降token(不碰原话,直接砍掉冗余) 第二步:…...
)
“ConnectionResetError”凌晨三点炸群?Python数据库适配稳定性军规(含12项生产环境Checklist)
更多请点击: https://intelliparadigm.com 第一章:ConnectionResetError凌晨三点炸群?Python数据库适配稳定性军规(含12项生产环境Checklist) 凌晨三点,告警群突然刷屏:ConnectionResetError: …...

游戏开发中的状态机与程序化生成技术解析
1. 游戏世界状态转换的核心机制游戏世界状态转换是游戏引擎中最基础也最关键的子系统之一。它决定了游戏对象如何响应事件、环境如何随时间演变、玩家行为如何影响虚拟世界。现代游戏开发中,状态转换系统已经从简单的if-else判断进化到基于事件驱动的复杂状态机。1.…...

实战指南:将你的Tesseract OCR服务Docker化并发布到阿里云镜像仓库
实战指南:将Tesseract OCR服务Docker化并发布到阿里云镜像仓库 在当今快速迭代的开发环境中,容器化技术已成为团队协作和项目部署的标配。对于需要处理图像识别的开发者而言,将Tesseract OCR服务封装成Docker镜像不仅能保证环境一致性&#x…...

树莓派4B安装Ubuntu20.04桌面版和ros 1 noetic
2025年4月4日更新: 通过网盘分享的文件:Ubuntu20 链接: https://pan.baidu.com/s/1ApISdPpRMacfEmizDncirQ?pwdqwer 提取码: qwer --来自百度网盘超级会员v2的分享 我直接把镜像烧录出来了,大小为15G,经测试可以在所有版本的树莓…...

Python第三方库Emoji库的使用教程
0. 背景Emoji库是一个Python第三方库,用于在程序中处理和使用表情符号。表情符号(Emoji)起源于日本,最初由栗田穣崇(Shigetaka Kurita)在1999年创建,用于在移动通信中传达情感和信息。随着智能手机的普及,表情符号已成为全球通用的…...

Windows平台APK安装解决方案:无缝运行Android应用的核心技术与实践指南
Windows平台APK安装解决方案:无缝运行Android应用的核心技术与实践指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows系统上直接运行Android应用…...

Windows系统INF文件安装自定义光标主题:从原理到实践
1. 项目概述:为Windows桌面注入macOS的灵魂作为一个长期在Windows和macOS双系统间切换的用户,我始终对macOS那套简洁、优雅的鼠标指针念念不忘。Windows的默认指针虽然功能齐全,但在视觉精致度和动画流畅度上,总觉得差了那么点意思…...