动手学Agent——Day2
文章目录
- 一、用 Llama-index 创建 Agent
- 1. 测试模型
- 2. 自定义一个接口类
- 3. 使用 ReActAgent & FunctionTool 构建 Agent
- 二、数据库对话 Agent
- 1. SQLite 数据库
- 1.1 创建数据库 & 连接
- 1.2 创建、插入、查询、更新、删除数据
- 1.3 关闭连接
- 建立数据库
- 2. ollama
- 3. 配置对话 & Embedding 模型
- 三、RAG 接入Agent
一、用 Llama-index 创建 Agent
LlamaIndex 实现 Agent,需要导入:
- Function Tool:将工具函数放在 Function Tool 对象中
- 工具函数 -> 完成 Agent 任务。⚠️大模型会根据函数注释来判断使用哪个函数来完成任务,所以,注释一定要写清楚函数功能和返回值
- ReActAgent:通过结合推理(Reasoning)和行动(Acting)来创建动态的 LLM Agent 的框架
- 初始推理:agent首先进行推理步骤,以理解任务、收集相关信息并决定下一步行为
- 行动:agent基于其推理采取行动——例如查询API、检索数据或执行命令
- 观察:agent观察行动的结果并收集任何新的信息
- 优化推理:利用新消息,代理再次进行推理,更新其理解、计划或假设
- 重复:代理重复该循环,在推理和行动之间交替,直到达到满意的结论或完成任务
1. 测试模型
- 使用一个数学能力较差的模型
# https://bailian.console.aliyun.com/#/model-market/detail/chatglm3-6b?tabKey=sdk
from dashscope import Generation messages = [{'role': "system", 'content': 'You are a helpful assistant.'},{'role': "user", 'content': '9.11 和 9.8 哪个大?'},
]gen = Generation()
response = gen.call(api_key=os.getenv("API_KEY"),model='chatglm3-6b',messages=messages,result_format='message',
)print(response.output.choices[0].message.content)
9.11 比 9.8 更大。
2. 自定义一个接口类
# https://www.datawhale.cn/learn/content/86/3058
from llama_index.core.llms import CustomLLM, LLMMetadata, CompletionResponse
from llama_index.core.llms.callbacks import llm_completion_callback
import os
from typing import Any, Generatorclass MyLLM(CustomLLM):api_key: str = Field(default=os.getenv("API_KEY"))base_url: str = Field(default=os.getenv("BASE_URL"))client: Generation = Field(default=Generation(), exclude=True)model_name: str@propertydef metadata(self) -> LLMMetadata:return LLMMetadata(model_name=self.model_name,context_window=32768, # 根据模型实际情况设置num_output=512)@llm_completion_callback()def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:messages = [{'role': "user", 'content': prompt}, # 根据API需求调整]response = self.client.call(api_key=self.api_key,model=self.model_name,messages=messages,result_format='message',)return CompletionResponse(text=response.output.choices[0].message.content)@llm_completion_callback()def stream_complete(self, prompt: str, **kwargs: Any) -> Generator[CompletionResponse, None, None]:response = self.client.call(api_key=self.api_key,model=self.model_name,messages=[{'role': "user", 'content': prompt}],stream=True,)current_text = ""for chunk in response:content = chunk.output.choices[0].delta.get('content', '')current_text += contentyield CompletionResponse(text=current_text, delta=content)# 实例化时使用大写环境变量名
llm = MyLLM(api_key=os.getenv("API_KEY"), base_url=os.getenv("BASE_URL"), model_name='chatglm3-6b'
)
3. 使用 ReActAgent & FunctionTool 构建 Agent
from llama_index.core.tools import FunctionTool
from llama_index.core.agent import ReActAgentdef compare_number(a: float, b: float) -> str:"""比较两个数的大小"""if a > b:return f"{a} 大于 {b}"elif a < b:return f"{a} 小于 {b}"else:return f"{a} 等于 {b}"tool = FunctionTool.from_defaults(fn=compare_number)
agent = ReActAgent.from_tools([tool], llm=llm, verbose=True)
response = agent.chat("9.11 和 9.8 哪个大?使用工具计算")
print(response)
> Running step 8c56594a-4edd-4d63-a196-99198df94e12. Step input: 9.11 和 9.8 哪个大?使用工具计算
Observation: Error: Could not parse output. Please follow the thought-action-input format. Try again.
Running step 22bbb997-4b52-4230-8a4d-d8eda252b7d1. Step input: None
Thought: The user is asking to compare the numbers 9.11 and 9.8, and they would like to know which one is greater. I can use the compare_number function to achieve this.
Action: compare_number
Action Input: {'a': 9.11, 'b': 9.8}
Observation: 9.11 小于 9.8
> Running step c6ce4186-3ea7-48c8-8f76-7d219118afc4. Step input: None
Thought: 根据比较结果,9.11小于9.8。
Answer: 9.11 < 9.8
9.11 < 9.8
二、数据库对话 Agent
1. SQLite 数据库
1.1 创建数据库 & 连接
import sqlite3# 连接数据库
conn = sqlite3.connect('mydatabase.db')# 创建游标对象
cursor = conn.cursor()
1.2 创建、插入、查询、更新、删除数据
- 创建
# create
create_tabel_sql = """CREATE TABLE IF NOT EXISTS employees ( id INTEGER PRIMARY KEY, name TEXT NOT NULL, department TEXT,salary REAL ); """cursor.execute(create_table_sql)# 提交事务
conn.commit()
- 插入
insert_sql = "INSERT INTO employees (name, department, salary) VALUES (?, ?, ?)"# insert single
data = ("Alice", "Engineering", 75000.0)
cursor.execute(insert_sql, data)
cursor.commit()# insert many
employees = [("Bob", "Marketing", 68000.0),("Charlie", "Sales", 72000.0)
]
cursor.executemany(insert_sql, employees)
cursor.commit()
- 查询
# 查询
# 条件查询(按部门筛选)
cursor.execute("SELECT name, salary FROM employees WHERE department=?", ("Engineering",))
engineering_employees = cursor.fetchall()
print("\nEngineering department:")
for emp in engineering_employees: print(f"{emp[0]} - ${emp[1]:.2f}")
- 更新
update_sql = "UPDATE employees SET salary = ? WHERE name = ?"
cursor.execute(update_sql, (8000.0, 'Alice'))
cursor.commit()
- 删除
delect_sql = "DELECT FROM employees WHERE name = ?"
cursor.execute(delect_sql, ("Bob",))
conn.commit()
1.3 关闭连接
# 关闭游标和连接(释放资源)
cursor.close()
conn.close()
建立数据库
python建立数据库的方法
import sqlite3
# create sql
sqlite_path = "llmdb.db"
# 1. 创建数据库、创建游标对象
conn = sqlite3.connect(sqlite_path)
curosr = conn.cursor()create_sql = """CREATE TABLE `section_stats` (`部门` varchar(100) DEFAULT NULL,`人数` int(11) DEFAULT NULL);"""insert_sql = """INSERT INTO section_stats (部门, 人数)values(?, ?)"""data = [['专利部', 22], ['商务部', 25]]# 2. 创建数据库
cursor.execute(create_sql)
cursor.commit()
# 3. 插入数据
cursor.executemany(insert_sql, data)
cursor.commit()
# 4. 关闭连接
cursor.close()
conn.close()2. ollama
安装 ollama
- 官网下载安装: [https://ollama.com](https://ollama.com/)
- 模型安装, 如运行 ollama run qwen2.5:7b(出现了success安装成功)- 然后出现 >>> 符号,即对话窗口, 输入 /bye 推出交互页面- 浏览器输入 127.0.0.1:11434, 如果出现 ollama is running,说明端口运行正常
- 环境配置- `OLLAMA_MODELS` & `OLLAMA_HOST` 环境配置1. 创建存储路径,如`mkdir -p ~/programs/ollama/models`2. 编辑环境变量配置路径 `vim ~/.bash_profile # ~/.zshrc``export OLLAMA_MODELS=~/programs/ollama/models``export OLLAMA_HOST=0.0.0.0:11434`- 确定mac地址和防火墙允许:系统偏好设置 -> 网络 (安全性和隐私-> 防火墙)- 使配置生效`source ~/.bash_profile # ~/.zshrc`3. 配置对话 & Embedding 模型
!pip install llama-index-llms-dashscope
三、RAG 接入Agent
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/README.md


https://github.com/deepseek-ai/DeepSeek-R1/blob/main/README.md
相关文章:
动手学Agent——Day2
文章目录 一、用 Llama-index 创建 Agent1. 测试模型2. 自定义一个接口类3. 使用 ReActAgent & FunctionTool 构建 Agent 二、数据库对话 Agent1. SQLite 数据库1.1 创建数据库 & 连接1.2 创建、插入、查询、更新、删除数据1.3 关闭连接建立数据库 2. ollama3. 配置对话…...

JSONObject,TreeUtil,EagelMap,BeanUtil使用
目录 JSONObject的使用 TreeUtil的使用 EagleMap使用 安装 application.yml配置 springboot导入依赖 配置信息 简单使用 如果想获取这个json字符串里面的distance的值 BeanUtil拷贝注意 JSONObject的使用 假如我现在要处理这样的json数据 可以直接使用JSONUtil.parseObj…...

Unity嵌入到Winform
Unity嵌入到Winform Winform工程🌈...

TCP/UDP协议与OSI七层模型的关系解析| HTTPS与HTTP安全性深度思考》
目录 OSI 7层模型每一层包含的协议: TCP和UDP协议: TCP (Transmission Control Protocol): UDP (User Datagram Protocol): 数据包流程图 TCP与UDP的区别: 传输层与应用层的关联 传输层和应用层的关联…...

《Zookeeper 分布式过程协同技术详解》读书笔记-2
目录 zk的一些内部原理和应用请求,事务和标识读写操作事务标识(zxid) 群首选举Zab协议(ZooKeeper Atomic Broadcast protocol)文件系统和监听通知机制分布式配置中心, 简单Demojava code 集群管理code 分布式锁 zk的一…...

缺陷检测之图片标注工具--labme
一、labelme简介 Labelme是开源的图像标注工具,常用做检测,分割和分类任务的图像标注。 它的功能很多,包括: 对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注&a…...

机器学习_13 决策树知识总结
决策树是一种直观且强大的机器学习算法,广泛应用于分类和回归任务。它通过树状结构的决策规则来建模数据,易于理解和解释。今天,我们就来深入探讨决策树的原理、实现和应用。 一、决策树的基本概念 1.1 决策树的工作原理 决策树是一种基于…...

请解释一下Standford Alpaca格式、sharegpt数据格式-------deepseek问答记录
1 Standford Alpaca格式 json格式数据。Stanford Alpaca 格式是一种用于训练和评估自然语言处理(NLP)模型的数据格式,特别是在指令跟随任务中。它由斯坦福大学的研究团队开发,旨在帮助模型理解和执行自然语言指令。以下是该格式的…...

ubuntu 安装管理多版本python3 相关问题解决
背景:使用ubuntu 22.04 默认python 未3.10.编译一些模块的时候发现需要降级到python3.9.于是下载安装 下载: wget https://www.python.org/ftp/python/3.9.16/Python-3.9.16.tgz解压与编译 tar -xf Python-3.9.16.tgz cd Python-3.9.16 ./configure -…...

滑动窗口算法篇:连续子区间与子串问题
1.滑动窗口原理 那么一谈到子区间的问题,我们可能会想到我们可以用我们的前缀和来应用子区间问题,但是这里对于子区间乃至子串问题,我们也可以尝试往滑动窗口的思路方向去进行一个尝试,那么说那么半天,滑动窗口是什么…...

Python爬虫实战:股票分时数据抓取与存储 (1)
在金融数据分析中,股票分时数据是投资者和分析师的重要资源。它能够帮助我们了解股票在交易日内的价格波动情况,从而为交易决策提供依据。然而,获取这些数据往往需要借助专业的金融数据平台,其成本较高。幸运的是,通过…...

【设计模式】【行为型模式】访问者模式(Visitor)
👋hi,我不是一名外包公司的员工,也不会偷吃茶水间的零食,我的梦想是能写高端CRUD 🔥 2025本人正在沉淀中… 博客更新速度 👍 欢迎点赞、收藏、关注,跟上我的更新节奏 🎵 当你的天空突…...

基于实例详解pytest钩子pytest_generate_tests动态生成测试的全过程
关注开源优测不迷路 大数据测试过程、策略及挑战 测试框架原理,构建成功的基石 在自动化测试工作之前,你应该知道的10条建议 在自动化测试中,重要的不是工具 作为一名软件开发人员,你一定深知有效测试策略的重要性,尤其…...

Copilot基于企业PPT模板生成演示文稿
关于copilot创建PPT,咱们写过较多文章了: Copilot for PowerPoint通过文件创建PPT Copilot如何将word文稿一键转为PPT Copilot一键将PDF转为PPT,治好了我的精神内耗 测评Copilot和ChatGPT-4o从PDF创建PPT功能 Copilot for PPT全新功能&a…...

2025百度快排技术分析:模拟点击与发包算法的背后原理
一晃做SEO已经15年了,2025年还有人问我如何做百度快速排名,我能给出的答案就是:做好内容的前提下,多刷刷吧!百度的SEO排名算法一直是众多SEO从业者研究的重点,模拟算法、点击算法和发包算法是百度快速排名的…...

七星棋牌全开源修复版源码解析:6端兼容,200种玩法全面支持
本篇文章将详细讲解 七星棋牌修复版源码 的 技术架构、功能实现、二次开发思路、搭建教程 等内容,助您快速掌握该棋牌系统的开发技巧。 1. 七星棋牌源码概述 七星棋牌修复版源码是一款高度自由的 开源棋牌项目,该版本修复了原版中的多个 系统漏洞&#…...

解锁原型模式:Java 中的高效对象创建之道
系列文章目录 后续补充~~~ 文章目录 一、引言1.1 软件开发中的对象创建困境1.2 原型模式的登场 二、原型模式的核心概念2.1 定义与概念2.2 工作原理剖析2.3 与其他创建型模式的差异 三、原型模式的结构与角色3.1 抽象原型角色3.2 具体原型角色3.3 客户端角色3.4 原型管理器角色…...
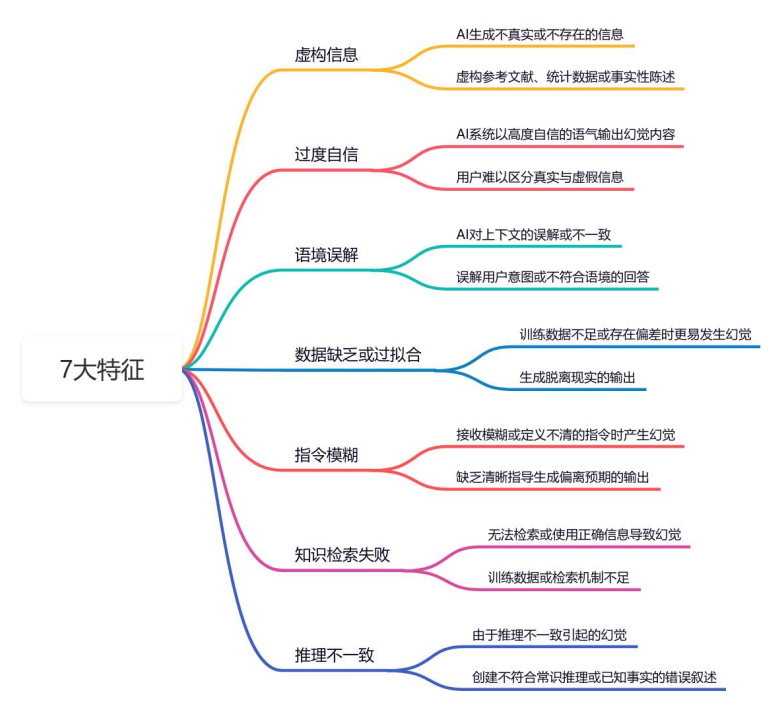
DeepSeek从入门到精通:揭秘 AI 提示语设计误区与 AI 幻觉(新手避坑指南)
文章目录 引言常见陷阱与应对策略:新手必知的提示词设计误区缺乏迭代陷阱:期待一次性完美结果过度指令与模糊指令陷阱:当细节缺乏重点或意图不明确假设偏见陷阱:当前 AI 只听你想听的幻觉生成陷阱:当AI自信地胡说八道忽…...

Jenkins同一个项目不同分支指定不同JAVA环境
背景 一些系统应用,会为了适配不同的平台,导致不同的分支下用的是不同的gradle,导致需要不同的JAVA环境来编译,比如a分支需要使用JAVA11, b分支使用JAVA17。 但是jenkins上,一般都是Global Tool Configuration 全局所有环境公用一个JAVA_HOME。 尝试过用 Build 的Execut…...
从入门到精通:Postman 实用指南
Postman 是一款超棒的 API 开发工具,能用来测试、调试和管理 API,大大提升开发效率。下面就给大家详细讲讲它的安装、使用方法,再分享些实用技巧。 一、安装 Postman 你能在 Postman 官网(https://www.postman.com )下…...

别再只把MinIO当S3平替了!聊聊它在K8s里做数据卷的3个实战场景
MinIO在Kubernetes中的高阶实践:超越S3兼容的三大数据卷场景 当大多数技术文档还在讨论MinIO如何作为Amazon S3的替代品时,真正的云原生实践者已经在Kubernetes集群中解锁了它更强大的存储能力。作为专为云原生环境设计的对象存储系统,MinIO…...

Agent 一接无限滚动页就开始漏内容:从 Viewport Checkpoint 到 Stable Item Key 的工程实战
很多团队把浏览器 Agent 接到商品流或监控列表后,第一批线上事故并不是“不会滚动”,而是它滚得很勤,却依旧漏内容。⚠️ 页面每次只暴露一个视口,模型若把“当前看到的列表”直接当成“完整世界”,结果就会一边下滚一…...

如何快速获取八大网盘直链下载链接:新手友好的完整教程
如何快速获取八大网盘直链下载链接:新手友好的完整教程 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

终极小说下载神器:一键保存200+网站小说的完整离线阅读方案
终极小说下载神器:一键保存200网站小说的完整离线阅读方案 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,小说爱好者常常面临一个令人沮丧的…...

基于LLM的智能写作助手:办公场景下的提示词工程与模板引擎实践
1. 项目概述:一个为办公场景量身定制的智能写作助手最近在GitHub上看到一个挺有意思的项目,叫laoguo2025/office-copywriter。光看这个名字,很多朋友可能就心领神会了——“老郭”的“办公室文案写手”。这名字起得挺接地气,一下子…...

教育科技公司利用Taotoken构建多模型对比演示平台的设计思路
教育科技公司利用Taotoken构建多模型对比演示平台的设计思路 1. 需求背景与架构设计 教育科技公司在开发AI教学工具时,常需要向学生展示不同大模型的能力差异。传统方案需要对接多个厂商API,面临密钥管理复杂、计费分散、响应格式不统一等问题。通过Ta…...

终极指南:如何在Linux系统上安装CH341SER驱动解决USB转串口设备识别问题
终极指南:如何在Linux系统上安装CH341SER驱动解决USB转串口设备识别问题 【免费下载链接】CH341SER CH341SER driver with fixed bug 项目地址: https://gitcode.com/gh_mirrors/ch/CH341SER 你是否在Linux系统上连接CH340/CH341 USB转串口设备时遇到识别问题…...

微信聊天记录备份工具:数字记忆的安全守护者
微信聊天记录备份工具:数字记忆的安全守护者 【免费下载链接】WechatBakTool 基于C#的微信PC版聊天记录备份工具,提供图形界面,解密微信数据库并导出聊天记录。 项目地址: https://gitcode.com/gh_mirrors/we/WechatBakTool 你是否曾经…...
)
保姆级教程:手把手教你给YOLOv5s模型集成CBAM注意力模块(附完整代码)
YOLOv5模型集成CBAM注意力模块实战指南 在目标检测领域,YOLOv5以其出色的速度和精度平衡成为工业界的热门选择。而注意力机制的引入,能够进一步提升模型对关键特征的捕捉能力。本文将手把手教你如何为YOLOv5s模型集成CBAM(Convolutional Bloc…...

利用 taotoken 实现多模型 a b 测试以优化应用程序 ai 功能
利用 Taotoken 实现多模型 A/B 测试以优化应用程序 AI 功能 1. 多模型 A/B 测试的核心价值 在应用程序集成 AI 能力的过程中,模型选型往往需要综合考虑响应质量、推理速度和调用成本等多个维度。Taotoken 提供的统一 API 接入层使得开发者能够在不修改业务代码的前…...