23. AI-大语言模型
文章目录
- 前言
- 一、LLM
- 1. 简介
- 2. 工作原理和结构
- 3. 应用场景
- 4. 最新研究进展
- 5. 比较
- 二、Transformer架构
- 1. 简介
- 2. 基本原理和结构
- 3. 应用场景
- 4. 最新进展
- 三、开源
- 1. 开源概念
- 2. 开源模式
- 3. 模型权重
- 四、再谈DeepSeek
前言
AI
一、LLM
LLM(Large Language Model,大语言模型)
1. 简介
LLM(Large Language Model,大语言模型)是指使用大量文本数据训练的深度学习模型,能够生成自然语言文本或理解语言文本的含义。
LLM的核心思想是通过大规模无监督训练学习自然语言的模式和结构,模拟人类的语言认知和生成过程。
2. 工作原理和结构
LLM通常采用Transformer架构和预训练目标(如Language Modeling)进行训练。通过层叠的神经网络结构,LLM学习并模拟人类语言的复杂规律,达到接近人类水平的文本生成能力。这种模型在自然语言处理领域具有广泛的应用,包括文本生成、文本分类、机器翻译、情感分析等。
3. 应用场景
LLM在多种应用场景下表现出色,不仅能执行拼写检查和语法修正等简单的语言任务,还能处理文本摘要、机器翻译、情感分析、对话生成和内容推荐等复杂任务。近期,GPT-4和LLaMA等大语言模型在自然语言处理等领域取得了巨大的成功,并逐步应用于金融、医疗和教育等特定领域。
4. 最新研究进展
最近的研究进展包括AI系统自我复制的能力和自回归搜索方法。复旦大学的研究表明,某些开源LLM具备自我克隆的能力,这标志着AI在自主进化方面取得了重大突破。此外,MIT、哈佛大学等机构的研究者提出了行动-思维链(COAT)机制,使LLM具备自回归搜索能力,提升了其在数学推理和跨领域任务中的表现。
5. 比较
大语言模型采用与小模型类似的Transformer架构和预训练目标(如 Language Modeling),与小模型的主要区别在于增加模型大小、训练数据和计算资源 。
相比传统的自然语言处理(Netural Language Processing, NLP)模型,大语言模型能够更好地理解和生成自然文本,同时表现出一定的逻辑思维和推理能力。
二、Transformer架构
1. 简介
Transformer是一种在自然语言处理(NLP)领域具有革命性意义的神经网络架构,主要用于处理和生成语言相关的任务。
Transformer架构由Google的研究团队在2017年提出,并在BERT等预训练模型中得到了广泛应用。
2. 基本原理和结构
Transformer架构主要由以下几个部分组成:
- 输入部分:包括源文本嵌入层和位置编码器,用于将源文本中的词汇转换为向量表示,并生成位置向量以理解序列中的位置信息。
- 编码器部分:由多个编码器层堆叠而成,每个编码器层包含多头自注意力子层和前馈全连接子层,并通过残差连接和层归一化操作进行优化。
- 解码器部分:由多个解码器层组成,每个解码器层包含带掩码的多头自注意力子层、多头注意力子层(编码器到解码器)和前馈全连接子层。
- 输出部分:包括线性层和Softmax层,用于将解码器的输出转换为最终的预测结果。
3. 应用场景
Transformer架构在NLP领域有着广泛的应用,包括但不限于:
- 机器翻译:将一种语言自动翻译成另一种语言。
- 文本生成:根据给定的文本生成新的文本内容。
- 情感分析:分析文本的情感倾向,如积极、消极或中性。
- 问答系统:根据问题生成答案。
- 语言模型:如GPT系列,用于生成文本。
4. 最新进展
最新的研究和发展方向包括探索如何通过扩展测试时计算量来提升模型推理能力,例如通过深度循环隐式推理方法,显著提升模型在复杂推理任务上的性能。此外,Transformer架构也在其他领域如图像处理和语音识别中展现出强大的应用潜力。
三、开源
1. 开源概念
为了适应时代发展,OSI(Open Source Initiative,开源代码促进会)专门针对 AI 提出了三种开源概念,分别是:
- 开源 AI 系统:包括训练数据、训练代码和模型权重。代码和权重需要按照开源协议提供,而训练数据只需要公开出处(因为一些数据集确实无法公开提供)。
- 开源 AI 模型:只需要提供模型权重和推理代码,并按照开源协议提供。
- 开源 AI 权重:只需要提供模型权重,并按照开源协议提供。
所谓推理代码,就是让大模型跑起来的代码,或者说大模型的使用代码,这也是一个相当复杂的系统性工程,涉及到了 GPU 调用和模型架构。
DeepSeek 只开源了权重,并没有开源训练代码、数据集和推理代码,所以属于第三种开源形式。DeepSeek 官方一直都在说自己开源了模型权重,用词精确。
其实第二种和第三种区别不大,因为在实际部署中,一般都会借助 Ollama 工具包,它已经包含了推理代码(llama.cpp),所以即使官方公布了推理代码,也不一定会被使用。
2. 开源模式
即使获取到训练代码和数据集,复现出类似的模型权重,成本极高,花费几百万几千万甚至几个亿。一般对于大模型用户而言,直接把官方开源的模型权重拿来使用即可。
当然,开源训练代码和数据集,对于学术研究还是有重大帮助的,它能快速推动产业进步,让人类早点从 AGI 时代进入 ASI 时代,所以第一种开源模式的意义也不能被忽视。
3. 模型权重
所谓大模型,就是超大规模的神经网络,它类似于人类的大脑,由无数个神经元(权重/参数)构成。

刚开始的时候,大模型的所有权重都是随机的,就类似于婴儿刚出生时大脑一片空白。训练大模型的过程,就是不断调整权重的过程,这和人类通过学习来调整神经元的连接是一个道理。把训练好的大模型开源,就相当于把学富五车的大脑仍给你,你可以让它做很多事情。
满血版 DeepSeek R1(671B 版本,一个 B 等于 10 个亿)有 6710 亿个参数,模型文件的体积达到了 720GB,相当恐怖。别说个人电脑了,单台服务器都无法运行,只能依赖集群了。
为了方便大家部署,官方又在满血版 R1 的基础上蒸馏出了多个小模型,减少了参数的数量,具体如下:
- 70B 版本,模型体积约 16GB;
- 32B 版本,模型体积约 16GB;
- 7B 版本,模型体积约 4.7GB;
- 1.5B 版本,模型体积约 3.6GB。
最后两个模型在配置强大的个人电脑上勉强能跑起来。
模型权重都是超大型文件,而且有指定的压缩格式(比如 .safetensors 格式),一般都是放在 Hugging Face(抱抱脸)上开源,而不是放在传统的 GitHub 上。
DeepSeek R1 的开源地址(需要梯子才能访问)
四、再谈DeepSeek
虽然 DeepSeek 只开源了模型权重,没有开源模型代码,但是官方通过技术报告/论文公布了很多核心算法,以及降本增效的工程解决方案,同时也为强化学习指明了一种新的范式,打破了 OpenAI 对推理技术的封锁(甚至是误导),让业界重新看到了 AI 持续进步的希望。
另外,DeepSeek 还允许二次蒸馏,不管是商业的还是公益的,你可以随便玩,这让小模型的训练变得更加简单和廉价。你再看看 OpenAI,明确写着不允许竞品进行二次蒸馏,并且妄图以此来指控 DeepSeek。
DeepSeek 的格局是人类,OpenAI 的格局是自己!
总之,对于一家商业公司来说,DeepSeek 的开放程度可以说是非常透明,透明到了毁灭自己的地步。包括 Hugging Face、伯克利大学、香港大学在内的某些机构,已经在尝试复现 DeepSeek 了。
本文的引用仅限自我学习如有侵权,请联系作者删除。
参考知识
抱歉,DeepSeek并没有开源代码,别被骗了!
相关文章:
23. AI-大语言模型
文章目录 前言一、LLM1. 简介2. 工作原理和结构3. 应用场景4. 最新研究进展5. 比较 二、Transformer架构1. 简介2. 基本原理和结构3. 应用场景4. 最新进展 三、开源1. 开源概念2. 开源模式3. 模型权重 四、再谈DeepSeek 前言 AI 一、LLM LLM(Large Language Mod…...

Linux /dev/null
/dev/null 是 Linux 和类 Unix 系统中一个特殊且非常有用的设备文件,也被称为空设备。下面为你详细介绍它的特点、用途和使用示例。 特点 写入丢弃:当向 /dev/null 写入数据时,这些数据会被立即丢弃,不会被保存到任何地方&#…...

Unity CommandBuffer绘制粒子系统网格显示
CommandBuffer是 Unity 提供的一种在渲染流程中插入自定义渲染命令的机制。在渲染粒子系统时,常规的渲染流程可能无法满足特定的渲染需求,而CommandBuffer允许开发者灵活地设置渲染参数、控制渲染顺序以及执行自定义的绘制操作。通过它,可以精…...

Java延时定时刷新Redis缓存
延时定时刷新Redis缓存 一、背景 项目需求:订阅接收一批实时数据,每分钟最高可接收120万条数据,并且分别更新到redis和数据库中;而用户请求查询消息只是低频操作。资源限制:由于项目预算有限,只有4台4C16…...

智能硬件定位技术发展趋势
在科技飞速进步的当下,智能硬件定位技术作为众多领域的关键支撑,正沿着多元且极具创新性的路径蓬勃发展,持续重塑我们的生活与工作方式。 一、精度提升的极致追求 当前,智能硬件定位精度虽已满足诸多日常应用,但未来…...

全单模矩阵及其在分支定价算法中的应用
全单模矩阵及其在分支定价算法中的应用 目录 全单模矩阵的定义与特性全单模矩阵的判定方法全单模矩阵在优化中的核心价值分支定价算法与矩阵单模性的关系非全单模问题的挑战与系统解决方案总结与工程实践建议 1. 全单模矩阵的定义与特性 关键定义 单模矩阵(Unimo…...

DeepSeek 的创新融合:多行业应用实践探索
引言 在数字化转型的浪潮中,技术的融合与创新成为推动各行业发展的关键力量。蓝耘平台作为行业内备受瞩目的创新平台,以其强大的资源整合能力和灵活的架构,为企业提供了高效的服务支持。而 DeepSeek 凭借先进的人工智能技术,在自然…...

利用SkinMagic美化MFC应用界面
MFC(Microsoft Foundation Class)应用程序的界面设计风格通常比较保守,而且虽然MFC框架的控件功能强大且易于集成,但视觉效果较为朴素,缺乏现代感。尤其是MFC应用程序的设计往往以功能实现为核心,界面设计可能显得较为简洁甚至略显呆板,用户体验可能不如现代应用程序流畅…...

IMX6ULL的公板的以太网控制器(MAC)与物理层(PHY)芯片(KSZ8081RNB)连接的原理图分析(包含各引脚说明以及工作原理)
目录 什么叫以太网?它与因特网有何区别?公板实现以太网的原理介绍(MII/RMII协议介绍)公板的原理图下载地址公板中IMX6ULL处理器与MAC(以太网控制器)有关的原理图IMX6ULL处理器的MAC引脚说明1. **ENET1_TX_DATA0**2. **ENET1_TX_DATA1**3. **ENET1_TX_EN*…...

采用分布式部署deepseek
分布式部署DeepSeek涉及使用多个计算节点来加速模型训练或提升推理效率。下面是一个基本的指南,帮助您了解如何进行分布式部署。 1. 环境准备 硬件需求:确保您的集群环境中有足够的GPU资源,并且所有机器之间可以通过高速网络互联。软件依赖…...

Cloud: aws:network: limit 含有pps这种限制
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/troubleshooting-ena.html#statistics-ena 这个是调查网络问题的一个网页; 在里面,竟然含有pps这种限制:ethtool -S;其实是比较苛刻的安全相关的策略? [ec2-user ~]$ ethtool -S ethN NIC statistics:tx_timeout: …...

PaddlePaddle的OCR模型转onnx-转rknn模型_笔记4
一、PaddlePaddle的OCR模型转onnx 1、首先建立一个新的虚拟环境 conda create -n ppocr python3.10 -y conda activate ppocr 2、进入paddlepaddle官网输入以下指令安装paddlepaddle GPU版本 (我的cuda版本是11.8,根据你电脑装合适版本) pip instal…...
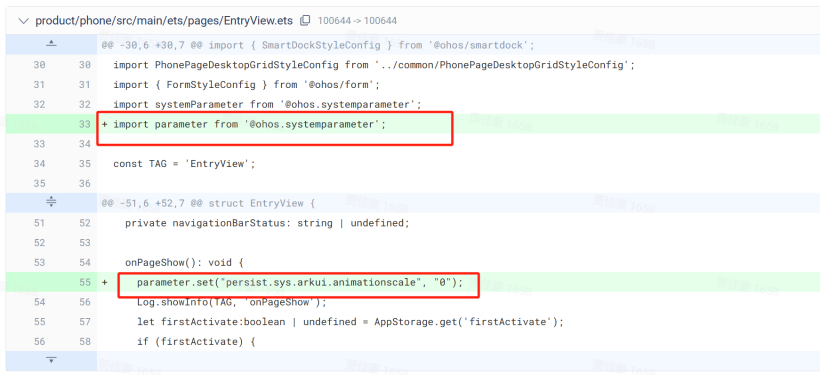
OpenHarmony 系统性能优化——默认关闭全局动画
笔者最近发现,关闭OpenHarmony全局动画,系统UI的响应速度会极大的提升 1.全局动画的开关由系统属性persist.sys.arkui.animationscale来控制,默认为1。也就是 动画缩放 1x 2.如果让persist.sys.arkui.animationscale默认为0,也就是关闭的状态…...

【Linux】Ubuntu Linux 系统——Node.js 开发环境
ℹ️大家好,我是练小杰,今天星期五了,同时也是2025年的情人节,今晚又是一个人的举个爪子!! 🙂 本文是有关Linux 操作系统中 Node.js 开发环境基础知识,后续我将添加更多相关知识噢&a…...

LC-搜索二维矩阵II、相交链表、反转链表、回文链表、环形链表、环形链表ll
搜索二维矩阵II 方法:从右上角开始搜索 我们可以从矩阵的右上角开始进行搜索。如果当前元素 matrix[i][j] 等于 target,我们直接返回 true。如果 matrix[i][j] 大于 target,说明 target 只能出现在左边的列,所以我们将列指针向左…...

小米平板怎么和电脑共享屏幕
最近尝试使用小米平板和电脑屏幕分屏互联 发现是需要做特殊处理的,需要下载一款电脑安装包:小米妙享 关于这个安装包,想吐槽的是: 没有找到官网渠道,是通过其他网络方式查到下载的 不附录链接,原因是因为地…...

Python elasticsearch客户端连接常见问题整理
python 访问 elasticsearch 在python语言中,我们一般使用 pip install elasticsearch 软件包,来访问es服务器。 正确用法 本地安装elasticsearch时,应指定与服务端相同的大版本号: pip install elasticsearch7.17.0然后就可以…...

目标检测IoU阈值全解析:YOLO/DETR模型中的精度-召回率博弈与工程实践指南
一、技术原理与数学本质 IoU计算公式: IoU \frac{Area\ of\ Overlap}{Area\ of\ Union} \frac{A ∩ B}{A ∪ B}阈值选择悖论: 高阈值(0.6-0.75):减少误检(FP↓)但增加漏检(FN↑…...

算法——数学建模的十大常用算法
数学建模的十大常用算法在数学建模竞赛和实际问题解决中起着至关重要的作用。以下是这些算法的具体信息、应用场景以及部分算法的C语言代码示例(由于篇幅限制,这里只给出部分算法的简要代码或思路,实际应用中可能需要根据具体问题进行调整和扩…...

Electron:使用electron-react-boilerplate创建一个react + electron的项目
使用 electron-react-boilerplate git clone --depth 1 --branch main https://github.com/electron-react-boilerplate/electron-react-boilerplate.git your-project-name cd your-project-name npm install npm start 安装不成功 在根目录加上 .npmrc文件 内容为 electron_…...

Vite项目构建时遇到‘chunk size‘警告别慌,手把手教你配置chunkSizeWarningLimit和manualChunks优化打包
Vite项目构建优化:深入解析chunkSizeWarningLimit与manualChunks配置策略 当你使用Vite构建项目时,终端突然跳出的"Some chunks are larger than 500 KiB after minification"警告是否曾让你感到困惑?这个看似简单的警告背后&#…...

Laravel 12原生AI扩展实战:5步实现智能表单验证、动态内容生成与实时代码补全
更多请点击: https://intelliparadigm.com 第一章:Laravel 12原生AI扩展的核心架构与设计哲学 Laravel 12 将 AI 集成从插件式实践升级为框架级原生能力,其核心架构围绕「可插拔智能层(Pluggable Intelligence Layer, PIL&#x…...

ShipPage-Skill:基于Vite+React的静态站点生成器,快速打造个人技能展示页
1. 项目概述:一个面向开发者的技能展示与项目聚合页最近在GitHub上看到一个挺有意思的项目,叫“ShipPage-Skill”。光看名字,你可能会有点摸不着头脑,这到底是做什么的?简单来说,这是一个帮你快速搭建个人技…...

从零构建高效测试循环:分层策略与实战优化指南
1. 项目概述与核心价值最近在GitHub上看到一个名为“prasunicecold140/test-pilot-loop”的项目,这个标题乍一看有点抽象,但结合“test-pilot”和“loop”这两个关键词,我立刻嗅到了一股自动化测试与持续集成/持续部署(CI/CD&…...
 YARN:集群资源调度大管家)
大数据系列(六) YARN:集群资源调度大管家
YARN:集群资源调度"大管家"大数据系列第 6 篇:Spark 和 Flink 要跑起来,得有人给它们分配资源。YARN 就是这个"大管家"。从一个"抢资源"的故事说起 假设你们公司有 100 台机器组成的大数据集群,同时…...
)
告别轮询!在UE5 C++中手把手教你用WebSocket实现实时聊天(附Node.js服务端代码)
告别轮询!在UE5 C中构建高性能WebSocket实时聊天系统 想象一下这样的场景:你的多人在线游戏需要让玩家实时看到队友的消息,或者虚拟社交应用中用户期待即时收到好友的回复。传统HTTP轮询方案每秒都在消耗服务器资源,而WebSocket只…...
)
自主智能体的自指内生描述与自适应规则生成(世毫九实验室AGI子系统)
自主智能体的自指内生描述与自适应规则生成方见华 世毫九实验室 摘要 当前的主流强化学习与自主智能体系统缺乏内生的自我认知能力:它们对自身的理解完全依赖人类定义的外部标签,而非来自对自身行为历史的内生建模。本文试图回答一个核心问题——如果一个…...

开发AI Agent应用时如何通过Taotoken灵活调度不同模型
开发AI Agent应用时如何通过Taotoken灵活调度不同模型 1. 多模型调度在AI Agent中的典型场景 现代AI Agent应用往往需要组合多种大模型能力。例如文档分析任务可能先调用Claude模型进行语义理解,再通过CodeLlama生成数据处理代码,最后用GPT-4执行结果校…...

别再死记硬背KCL和KVL了!用Multisim仿真带你直观理解基尔霍夫定律
用Multisim仿真玩转基尔霍夫定律:告别枯燥公式,直观掌握电路本质 当你第一次翻开电路理论教材,看到那些密密麻麻的电流箭头和电压符号时,是否感到一阵眩晕?基尔霍夫定律作为电路分析的基石,常常因为抽象的表…...

BGA插座系统GHz高速互连设计与优化实践
1. BGA插座系统的GHz高速互连挑战在当今高性能集成电路设计中,BGA(球栅阵列)封装已成为主流互连方案。作为连接芯片与PCB的关键桥梁,BGA插座系统在原型验证、测试调试和量产环节中扮演着不可替代的角色。我曾参与过多个采用BGA封装…...