SQLMesh 系列教程5- 详解SQL模型
本文将详细介绍 SQLMesh 的 SQL 模型组成要素及其在实际项目中的应用。SQLMesh 是一个强大的数据工程工具,其 SQL 模型由 MODEL DDL、预处理语句、主查询、后处理语句以及可选的
ON VIRTUAL UPDATE语句组成。我们将通过一个电商平台每日销售报告的实例,展示如何利用这些要素构建高效的数据管道。文章将逐步解析每个部分的作用,并说明如何通过 SQLMesh 实现增量更新和虚拟更新测试,帮助读者掌握 SQLMesh 的核心功能及其在实际场景中的最佳实践。
SQL模型概述
SQL模型是SQLMesh使用的主要模型类型。这些模型可以使用SQL或生成SQL的Python来定义。

基于sql的定义,基于SQL的SQL模型定义是最常见的定义,它由以下部分组成:
-
MODEL DDL:
使用
MODEL关键字定义模型的基本信息,包括模型名称、目标表、分区策略等。这是 SQL 模型的入口点,用于声明模型的元数据。 -
可选的预处理语句(Pre-statements):
在模型的主查询之前执行的 SQL 语句。通常用于创建临时表、设置变量或执行其他准备工作。
-
单个查询(Main Query):
模型的核心部分,定义数据转换逻辑。必须是一个单独的
SELECT查询,用于生成目标表的数据。 -
可选的后处理语句(Post-statements):
在主查询之后执行的 SQL 语句。通常用于清理临时表、更新元数据或执行其他收尾工作。
-
可选的
ON VIRTUAL UPDATE语句:用于定义在虚拟更新(Virtual Update)时的行为。虚拟更新是 SQLMesh 的一种机制,允许在不实际修改数据的情况下测试模型的更改。
这些模型的设计目的是让你看起来像是在简单地使用SQL,但它们可以针对高级用例进行定制。
要创建基于sql的模型,请在SQLMesh项目中的models/目录(或models/的子目录)中添加一个后缀为.sql的新文件。虽然文件名并不重要,但是习惯上使用模型名(不带模式名)作为文件名。例如,包含sqlmesh_example.seed_model的模型文件,将被命名为seed_model.sql。
举例:
-- This is the MODEL DDL, where you specify model metadata and configuration information.
MODEL (name db.customers,kind FULL,
);/*Optional pre-statements that will run before the model's query.You should NOT do things that cause side effects that could error out whenexecuted concurrently with other statements, such as creating physical tables.
*/
CACHE TABLE countries AS SELECT * FROM raw.countries;/*This is the single query that defines the model's logic.Although it is not required, it is considered best practice to explicitlyspecify the type for each one of the model's columns through casting.
*/
SELECTr.id::INT,r.name::TEXT,c.country::TEXT
FROM raw.restaurants AS r
JOIN countries AS cON r.id = c.restaurant_id;/*Optional post-statements that will run after the model's query.You should NOT do things that cause side effects that could error out whenexecuted concurrently with other statements, such as creating physical tables.
*/
UNCACHE TABLE countries;- 模型DDL
MODEL DDL用于指定关于模型的元数据,例如模型的名称、类型、所有者、cron等。这应该是基于sql的模型文件中的首个语句。有关允许的属性的完整列表,请参阅MODEL属性。
- 可pre/post-statements
可选的pre/post语句允许你分别在模型运行之前和之后执行SQL命令。
例如,pre/post语句可能会修改设置或创建表索引。但是,如果并发运行,请注意不要运行任何可能与另一个模型的执行冲突的语句,例如创建物理表。
pre/post 语句只是位于模型查询之前/之后的标准SQL命令。它们必须以分号结束,如果存在后置语句,则模型查询必须以分号结束。上面的例子包含了前置语句和后置语句。
Pre/post语句被求值两次:当创建模型的表时,以及当计算其查询逻辑时。多次执行语句可能会产生意想不到的副作用,因此可以根据SQLMesh的运行时阶段有条件地执行语句。
上面示例中的pre/post语句将运行两次,因为它们不受运行时阶段的限制。
我们可以使用@IF宏操作符和@runtime_stage宏变量对后置语句进行条件调整,使其仅在模型查询被评估后运行,如下所示:
MODEL (name db.customers,kind FULL,
);[...same as example above...]@IF(@runtime_stage = 'evaluating',UNCACHE TABLE countries
);注意,@IF()宏中的SQL命令UNCACHE TABLE countries不以分号结束。相反,分号出现在@IF()宏的右括号之后。
- 可选的on-virtual-update语句
可选的on-virtual-update语句允许你在虚拟更新完成后执行SQL命令。
例如,可以使用这些权限来授予虚拟层视图的权限。这些SQL语句必须包含在ON_VIRTUAL_UPDATE_BEGIN;…;ON_VIRTUAL_UPDATE_END;
MODEL (name db.customers,kind FULL
);SELECTr.id::INT
FROM raw.restaurants AS r;ON_VIRTUAL_UPDATE_BEGIN;
GRANT SELECT ON VIEW @this_model TO ROLE role_name;
JINJA_STATEMENT_BEGIN;
GRANT SELECT ON VIEW {{ this_model }} TO ROLE admin;
JINJA_END;
ON_VIRTUAL_UPDATE_END;也可以在其中使用Jinja表达式,如上面的示例所示。这些表达式必须正确地嵌套在JINJA_STATEMENT_BEGIN;和JINJA_END;块。
这些语句的表解析发生在虚拟层。这意味着表名,包括@this_model宏,被解析为它们的限定视图名。例如,当在名为dev的环境中运行计划时,db.customers
和@this_model将解析为db__dev.customers而不是物理表名。
- 模型查询
模型必须包含一个独立的查询,它可以是单个SELECT表达式,也可以是多个SELECT表达式与UNION、INTERSECT或EXCEPT操作符的组合。该查询的结果将用于填充模型的表或视图。
完整实例
实际应用场景
在一个电商平台的数据分析项目中,该 SQL 模型可以用于:
- 每日销售报告:每天自动生成销售数据,供业务团队分析。
- 增量更新:只处理当天的订单数据,避免全量计算,提高效率。
- 虚拟更新测试:在部署前测试模型的更改,确保不会破坏现有数据管道。
以下是一个完整的 SQLMesh SQL 模型示例,结合上述实际应用场景:假设我们需要从原始订单数据中生成每日销售报告。
- 原始数据表:
raw_orders,包含订单的详细信息。 - 目标数据表:
daily_sales_report,按天汇总销售数据。
SQL 模型脚本
-- MODEL DDL
MODEL (name db.daily_sales_report, -- 模型名称和目标表kind INCREMENTAL_BY_TIME_RANGE ( -- 增量模型,按时间范围更新time_column order_date),cron '@daily', -- 每天执行一次grain [order_date] -- 数据粒度
);-- 可选的预处理语句
-- 例如:创建一个临时表来存储当天的订单数据
CREATE TEMPORARY TABLE temp_daily_orders AS
SELECT *
FROM raw_orders
WHERE order_date = @start_ds;-- 单个查询(主查询)
SELECTorder_date,SUM(quantity * price) AS total_sales, -- 计算总销售额COUNT(DISTINCT order_id) AS total_orders, -- 计算总订单数SUM(quantity * price) / COUNT(DISTINCT order_id) AS avg_order_value -- 计算平均订单价值
FROM temp_daily_orders
GROUP BY order_date;-- 可选的后处理语句
-- 例如:删除临时表
DROP TABLE IF EXISTS temp_daily_orders;-- 可选的 ON VIRTUAL UPDATE 语句
ON VIRTUAL UPDATE {-- 在虚拟更新时,返回一个示例结果集SELECT'2023-10-01' AS order_date,1000.00 AS total_sales,10 AS total_orders,100.00 AS avg_order_value;
};
详细说明
- MODEL DDL:
name:定义模型的名称和目标表(db.daily_sales_report)。kind:指定模型的类型。这里使用INCREMENTAL_BY_TIME_RANGE,表示这是按时间范围更新的增量模型。time_column:指定时间列(order_date),用于增量更新。cron:定义模型的调度频率(每天执行一次)。grain:定义数据的粒度(按order_date聚合)。
- 预处理语句:
- 创建了一个临时表
temp_daily_orders,用于存储当天的订单数据。 @start_ds是 SQLMesh 提供的宏,表示当前处理的时间范围起点。
- 创建了一个临时表
- 主查询:
- 从临时表
temp_daily_orders中查询数据,按order_date聚合计算总销售额、总订单数和平均订单价值。
- 从临时表
- 后处理语句:
- 清理临时表
temp_daily_orders,避免占用资源。
- 清理临时表
- ON VIRTUAL UPDATE:
- 在虚拟更新时,返回一个示例结果集,用于测试模型的输出结构。
通过这种方式,SQLMesh 的 SQL 模型能够清晰地定义数据转换逻辑,同时支持增量更新和虚拟更新,非常适合复杂的数据工程场景。

最后总结
本文深入探讨了 SQLMesh 的 SQL 模型组成要素,包括 MODEL DDL、预处理语句、主查询、后处理语句以及 ON VIRTUAL UPDATE 语句。通过一个电商平台每日销售报告的实例,我们展示了如何利用 SQLMesh 构建高效、可维护的数据管道。SQLMesh 的增量更新机制和虚拟更新测试功能,极大地提升了数据工程的灵活性和可靠性。无论是处理大规模数据还是优化数据工作流,SQLMesh 都提供了强大的工具和方法,帮助团队实现数据驱动决策。希望本文能为读者在实际项目中应用 SQLMesh 提供有价值的参考。
相关文章:
SQLMesh 系列教程5- 详解SQL模型
本文将详细介绍 SQLMesh 的 SQL 模型组成要素及其在实际项目中的应用。SQLMesh 是一个强大的数据工程工具,其 SQL 模型由 MODEL DDL、预处理语句、主查询、后处理语句以及可选的 ON VIRTUAL UPDATE 语句组成。我们将通过一个电商平台每日销售报告的实例,…...

本地DeepSeek模型GGUF文件转换为PyTorch格式
接前文,我们在本地Windows系统上,基于GGUF文件部署了DeepSeek模型(DeepSeek-R1-Distill-Qwen-1.5B.gguf版本),但是GGUF是已经量化的版本,我们除了对其进行微调之外,无法对其训练,那么还有没有其他办法对本地的GGUF部署的DeepSeek模型进行训练呢?今天我们就反其道而行之…...
)
Flutter:动态表单(在不确定字段的情况下,生成动态表单)
关于数据模型:模型就是一种规范约束,便于维护管理,在不确定表单内会出现什么数据时,就没有模型一说。 这时就要用到动态表单(根据接口返回的字段,生成动态表单) 1、观察数据格式,定义…...

【Python项目】文本相似度计算系统
【Python项目】文本相似度计算系统 技术简介:采用Python技术、Django技术、MYSQL数据库等实现。 系统简介:本系统基于Django进行开发,包含前端和后端两个部分。前端基于Bootstrap框架进行开发,主要包括系统首页,文本分…...

C# ref 和 out 的使用详解
总目录 前言 在 C# 编程中,ref 和 out 是两个非常重要的关键字,它们都用于方法参数的传递,但用途和行为却有所不同。今天,我们就来深入探讨一下这两个关键字的用法和区别,让你在编程中能够得心应手地使用它们。 一、什…...

Ubuntu 24.04.1 LTS 本地部署 DeepSeek 私有化知识库
文章目录 前言工具介绍与作用工具的关联与协同工作必要性分析 1、DeepSeek 简介1.1、DeepSeek-R1 硬件要求 2、Linux 环境说明2.1、最小部署(Ollama DeepSeek)2.1.1、扩展(非必须) - Ollama 后台运行、开机自启: 2.2、…...

用 WOW.js 和 animate.css 实现动画效果
用 wow.js 就可以实现动画效果,但由于里面的动画样式太少,一般还会引入 animated.css 第一步:下载 选择合适的包管理器下载对应的内容 pnpm i wow.js animated.css --save 第二步:引入 在main.js中加入: import …...

1-知识图谱-概述和介绍
知识图谱:浙江大学教授 陈华军 知识图谱 1课时 http://openkg.cn/datasets-type/ 知识图谱的价值 知识图谱是有什么用? 语义搜索 问答系统 QA问答对知识图谱:结构化图 辅助推荐系统 大数据分析系统 自然语言理解 辅助视觉理解 例…...

flink jobgraph详细介绍
一、Flink JobGraph 的核心概念 JobGraph 是 Flink 作业的核心执行计划,它描述了作业的任务拓扑结构和数据流关系。JobGraph 由以下几部分组成: 顶点(Vertex) 每个顶点代表一个任务(Task),例如…...

使用nginx+rtmp+ffmpeg实现桌面直播
使用nginxrtmpffmpeg实现桌面直播 流媒体服务器搭建 docker run docker镜像基于添加了rtmp模块的nginx,和ffmpeg docker pull alfg/nginx-rtmp docker run -d -p 1935:1935 -p 8080:80 --namenginx-rtmp alfg/nginx-rtmprtmp模块说明 进入容器内部查看 docker…...

每日一题——将数字字符串转化为IP地址
将数字字符串转化为IP地址 题目描述解题思路回溯法步骤分解 代码实现全局变量有效性验证函数回溯函数主函数完整代码 复杂度分析关键点说明总结 这题难度还挺大的,整体上实现并不容易。建议参考视频 和https://programmercarl.com/0093.%E5%A4%8D%E5%8E%9FIP%E5%9C%…...

机器学习数学基础:25.随机变量分布详解
一、随机变量与分布函数的基本概念 (一)什么是随机变量? 在概率论领域,随机变量是将随机试验的结果进行数值化的关键概念。它就像一座桥梁,把抽象的随机事件和具体的数学分析连接起来。 举例来说,在一个…...

香港电讯与Zenlayer达成战略合作,拓展全球互联生态圈
作为主要国际金融与贸易中心,香港一直是连系中国内地及全球市场的重要门户。香港电讯作为本地领先的综合电讯服务提供商,拥有广泛的网络资源和深厚的技术专长,一直支持国内企业“走出去”和外资企业“走进来”。而旗下由PCCW Global营运的Con…...

MySQL-事务隔离级别
事务有四大特性(ACID):原子性,一致性,隔离性和持久性。隔离性一般在事务并发的时候需要保证事务的隔离性,事务并发会出现很多问题,包括脏写,脏读,不可重复读,…...
)
【Python学习 / 6】面向对象编程(OOP)
文章目录 ⭐前言⭐一、类和对象:面向对象编程基础1. 类(Class)类的组成:例子:定义一个简单的 Dog 类代码解析: 2. 对象(Object)对象的创建: 3. 三大特性:封装…...

Ollama DeepSeek + AnythingLLM 实现本地私有AI知识库
Ollama DeepSeek AnythingLLM 实现本地私有AI知识库 本地部署DeepSeek-r1下载安装AnythingLLMAnythingLLM 配置LLM首选项Embedder首选项向量数据库工作区其他配置 AnythingLLM Workspace使用上传知识词嵌入知识检索 本文主要介绍了如何使用AnythingLLM结合Ollama部署的DeepSee…...

个人博客测试报告
一、项目背景 个人博客系统采用前后端分离的方法来实现,同时使用了数据库来存储相关的数据,同时将其部署到云服务器上。前端主要有四个页面构成:登录页、列表页、详情页以及编辑页,以上模拟实现了最简单的个人博客系统。其结合后…...

嵌入式八股文(四)计算机网络篇
第一章 基础概念 1. 服务 指网络中各层为紧邻的上层提供的功能调用,是垂直的。包括面向连接服务、无连接服务、可靠服务、不可靠服务。 2. 协议 是计算机⽹络相互通信的对等层实体之间交换信息时必须遵守的规则或约定的集合。⽹络协议的三个基本要素:语法、…...

基于Electron+Vue3创建桌面应用
Electron 是一个开源框架,基于 Chromium 和 Node.js,用于开发跨平台桌面应用程序。它允许开发者使用 HTML、CSS 和 JavaScript 等 Web 技术构建原生桌面应用,支持 Windows、macOS 和 Linux。Electron 以其开发便捷性、强大的功能和丰富的生态系统而广泛应用于工具类应用、媒…...
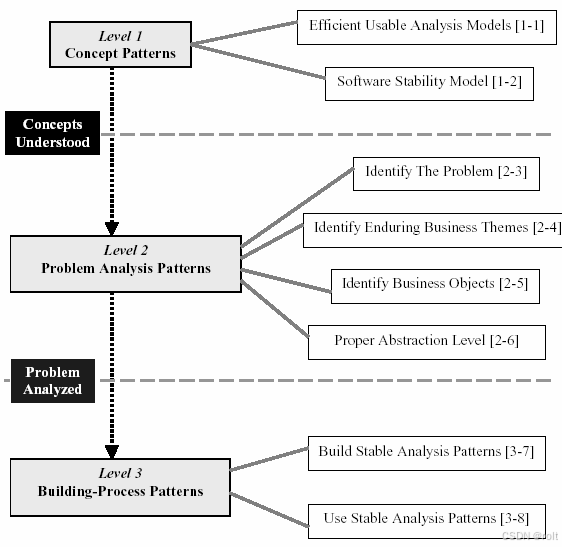
建立稳定分析模式的模式语言01
Haitham Hamza 等 著,wnb 译 摘要 一般认为,软件分析模式在减少开销和缩短软件产品生命周期等方面会起到重要的作用。然而,分析模式的巨大潜能还未被充分发掘。缺乏稳定性是当前分析模式存在的主要问题。多数情况下,为特定问题建…...
)
Docker 27 AI调度白皮书核心节选(含调度延迟P99<87ms的基准测试数据与拓扑约束配置清单)
更多请点击: https://intelliparadigm.com 第一章:Docker 27 AI容器智能调度架构演进与核心定位 Docker 27(代号“Orion”)标志着容器运行时从轻量编排向AI感知型智能调度范式的重大跃迁。其核心不再仅关注进程隔离与镜像分发&am…...

3分钟掌握云存储开发:GitHub Copilot助你轻松集成S3与Azure Blob
3分钟掌握云存储开发:GitHub Copilot助你轻松集成S3与Azure Blob 【免费下载链接】awesome-copilot Community-contributed instructions, agents, skills, and configurations to help you make the most of GitHub Copilot. 项目地址: https://gitcode.com/GitH…...

【WebRTC深度解析】从零构建一个稳定的WebRTC视频聊天应用
文章目录 📁 项目概述 项目结构 依赖说明 🏗️ 一、核心架构解析 1.1 系统整体架构 1.2 WebRTC通信完整流程 1.3 关键技术组件 💻 二、客户端核心代码深度解析 (`chatclient.js`) 2.1 全局状态管理 2.2 日志工具函数 2.3 WebSocket连接与消息分发 (`connect` 函数) 2.4 R…...

Intel Mobileye EyeQ Ultra:RISC-V架构的L4自动驾驶芯片解析
1. Intel Mobileye EyeQ Ultra:面向L4自动驾驶的RISC-V处理器解析在2022年CES展会上,Intel旗下Mobileye发布的EyeQ Ultra处理器引发了行业震动。这款专为L4级自动驾驶设计的SoC彻底摒弃了传统x86架构,转而采用12核RISC-V CPU集群,…...

NsEmuTools:让NS模拟器管理变得简单高效的跨平台自动化方案
NsEmuTools:让NS模拟器管理变得简单高效的跨平台自动化方案 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 您是否曾经为了安装和配置NS模拟器而花费数小时?是否在…...
)
电商订单系统设计(简单版)
下单 支付 主动取消订单 超时自动关单配套:完整建表、实体、Mapper、XML、Service、Controller、事务、定时任务、异步、防超卖、状态流转,基于 SpringBoot2.5 MyBatis原生XML MySQL8.0。一、完整数据库表结构sqlCREATE DATABASE IF NOT EXISTS sho…...

手把手教你用HanLP的CRF和NLP分词器:处理‘文心大模型’这类新词再也不怕了
深度解析HanLP分词器:如何精准处理"文心大模型"等科技新词 当"文心大模型"、"AI原生战略"这样的专业术语频繁出现在科技报道中,传统分词工具往往束手无策。本文将带您深入HanLP的CRF和NLP分词器核心,通过对比实…...

轻松掌握vue3-element-admin字体设置:从基础调整到深度定制全攻略
轻松掌握vue3-element-admin字体设置:从基础调整到深度定制全攻略 【免费下载链接】vue3-element-admin 🔥基于 Vue 3 Vite 7 TypeScript element-plus 构建的后台管理前端模板(配套后端源码),vue-element-admin 的 …...

小说下载器:200+小说网站一键下载,打造你的专属离线图书馆
小说下载器:200小说网站一键下载,打造你的专属离线图书馆 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 你是否曾因网络不稳定而无法畅快阅读?是…...

别再被LabVIEW事件结构坑了!程序修改控件值不触发事件?试试这个属性节点
LabVIEW事件结构深度解析:如何精准触发程序修改的控件值改变事件 在LabVIEW开发过程中,事件结构是构建响应式用户界面的核心工具之一。但许多初中级开发者都会遇到一个令人困惑的现象:当通过程序代码修改控件值时,预期中的"值…...