VisionTransformer(ViT)与CNN卷积神经网络的对比
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】 | 38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】 | 40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】 | 42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】 |
| 43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】 | 44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】 |
| 45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】 | 46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】 | 48.【基于深度学习的车辆检测追踪与流量计数系统】 |
| 49.【基于深度学习的行人检测追踪与双向流量计数系统】 | 50.【基于深度学习的反光衣检测与预警系统】 |
| 51.【基于深度学习的危险区域人员闯入检测与报警系统】 | 52.【基于深度学习的高密度人脸智能检测与统计系统】 |
| 53.【基于深度学习的CT扫描图像肾结石智能检测系统】 | 54.【基于深度学习的水果智能检测系统】 |
| 55.【基于深度学习的水果质量好坏智能检测系统】 | 56.【基于深度学习的蔬菜目标检测与识别系统】 |
| 57.【基于深度学习的非机动车驾驶员头盔检测系统】 | 58.【太基于深度学习的阳能电池板检测与分析系统】 |
| 59.【基于深度学习的工业螺栓螺母检测】 | 60.【基于深度学习的金属焊缝缺陷检测系统】 |
| 61.【基于深度学习的链条缺陷检测与识别系统】 | 62.【基于深度学习的交通信号灯检测识别】 |
| 63.【基于深度学习的草莓成熟度检测与识别系统】 | 64.【基于深度学习的水下海生物检测识别系统】 |
| 65.【基于深度学习的道路交通事故检测识别系统】 | 66.【基于深度学习的安检X光危险品检测与识别系统】 |
| 67.【基于深度学习的农作物类别检测与识别系统】 | 68.【基于深度学习的危险驾驶行为检测识别系统】 |
| 69.【基于深度学习的维修工具检测识别系统】 | 70.【基于深度学习的维修工具检测识别系统】 |
| 71.【基于深度学习的建筑墙面损伤检测系统】 | 72.【基于深度学习的煤矿传送带异物检测系统】 |
| 73.【基于深度学习的老鼠智能检测系统】 | 74.【基于深度学习的水面垃圾智能检测识别系统】 |
| 75.【基于深度学习的遥感视角船只智能检测系统】 | 76.【基于深度学习的胃肠道息肉智能检测分割与诊断系统】 |
| 77.【基于深度学习的心脏超声图像间隔壁检测分割与分析系统】 | 78.【基于深度学习的心脏超声图像间隔壁检测分割与分析系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 视觉变换器与卷积神经网络
- 引言
- 示例:CNN与Vision Transformer
- **CNN方法**
- **VisionTransformer方法**
- **结论**
视觉变换器与卷积神经网络
引言
Vision Transformer (ViT) 是一种将Transformer架构应用于计算机视觉任务的模型,最初由Google在2020年提出。不同于传统的卷积神经网络(CNNs),ViT完全依赖于自注意力机制来处理图像数据。具体来说,图像首先被分割成固定大小的块,每个块被视为一个“词”,然后通过线性嵌入映射到一个高维空间中,类似于自然语言处理中的词嵌入过程。这些嵌入向量随后被送入标准的Transformer编码器进行处理,以学习图像的表示。ViT展示了在大规模数据集上训练时,它能够取得与先进CNN模型相媲美的性能,同时减少了对归纳偏置(如局部性和翻译等变性)的依赖。这一方法为计算机视觉领域引入了新的研究方向,并促进了后续一系列基于Transformer的视觉模型的发展。
代码:https://github.com/RustamyF/vision-transformer
由于其计算效率和可扩展性,Transformer已成为NLP中的首选模型。在计算机视觉中,卷积神经网络(CNN)架构仍然占主导地位,但一些研究人员试图将CNN与自我注意力结合起来。作者尝试将标准的Transformer直接应用于图像,发现当在中等规模的数据集上训练时,与ResNet类架构相比,模型的准确性适中。然而,当在更大的数据集上训练时,Vision Transformer(ViT)取得了优异的成绩,在多个图像识别基准上接近或超过了最先进的水平。

图1(摘自原始论文)描述了一个模型,该模型通过将2D图像转换为扁平的2D补丁序列来处理2D图像。然后,补丁被映射到一个恒定的潜在向量大小与可训练的线性投影。一个可学习的嵌入被预先添加到补丁的序列中,并且其在Transformer编码器的输出处的状态用作图像表示。然后将图像表示通过分类头进行预训练或微调。添加位置嵌入以保留位置信息,并且嵌入向量的序列用作Transformer编码器的输入,该编码器由多头自注意和MLP块的交替层组成。
在过去,CNN长期以来一直是图像处理任务的首选。它们擅长通过卷积层捕获局部空间模式,从而实现分层特征提取。CNN擅长从大量图像数据中学习,并在图像分类、对象检测和分割等任务中取得了显着的成功。
虽然CNN在各种计算机视觉任务中有着良好的记录,并有效地处理大规模数据集,但Vision Transformers在全局依赖性和上下文理解至关重要的场景中具有优势。然而,Vision Transformers通常需要更大量的训练数据才能实现与CNN相当的性能。此外,由于其可并行化的性质,CNN在计算上是高效的,这使得它们对于实时和资源受限的应用更实用。
示例:CNN与Vision Transformer
在本节中,我们将使用CNN和vision Transformer方法,在Kaggle中提供的猫和狗数据集上训练视觉分类器。首先,我们将从Kaggle下载包含25000个RGB图像的猫和狗数据集。
from kaggle.api.kaggle_api_extended import KaggleApiapi = KaggleApi()
api.authenticate()# we write to the current directory with './'
api.dataset_download_files('karakaggle/kaggle-cat-vs-dog-dataset', path='./')
下载文件后,可以使用以下命令解压缩文件。
!unzip -qq kaggle-cat-vs-dog-dataset.zip
!rm -r kaggle-cat-vs-dog-dataset.zip
使用以下命令克隆vision-transformer GitHub存储库。这个存储库在vision_tr目录下包含了VisionTransformer所需的所有代码。
!git clone https://github.com/RustamyF/vision-transformer.git
!mv vision-transformer/vision_tr .
下载的数据需要清理和准备用于训练我们的图像分类器。创建以下实用程序函数以清理和加载Pytorch的DataLoader格式的数据。
import torch.nn as nn
import torch
import torch.optim as optimfrom torchvision import datasets, models, transforms
from torch.utils.data import DataLoader, Dataset
from PIL import Image
from sklearn.model_selection import train_test_splitimport osclass LoadData:def __init__(self):self.cat_path = 'kagglecatsanddogs_3367a/PetImages/Cat'self.dog_path = 'kagglecatsanddogs_3367a/PetImages/Dog'def delete_non_jpeg_files(self, directory):for filename in os.listdir(directory):if not filename.endswith('.jpg') and not filename.endswith('.jpeg'):file_path = os.path.join(directory, filename)try:if os.path.isfile(file_path) or os.path.islink(file_path):os.unlink(file_path)elif os.path.isdir(file_path):shutil.rmtree(file_path)print('deleted', file_path)except Exception as e:print('Failed to delete %s. Reason: %s' % (file_path, e))def data(self):self.delete_non_jpeg_files(self.dog_path)self.delete_non_jpeg_files(self.cat_path)dog_list = os.listdir(self.dog_path)dog_list = [(os.path.join(self.dog_path, i), 1) for i in dog_list]cat_list = os.listdir(self.cat_path)cat_list = [(os.path.join(self.cat_path, i), 0) for i in cat_list]total_list = cat_list + dog_listtrain_list, test_list = train_test_split(total_list, test_size=0.2)train_list, val_list = train_test_split(train_list, test_size=0.2)print('train list', len(train_list))print('test list', len(test_list))print('val list', len(val_list))return train_list, test_list, val_list# data Augumentation
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),
])class dataset(torch.utils.data.Dataset):def __init__(self, file_list, transform=None):self.file_list = file_listself.transform = transform# dataset lengthdef __len__(self):self.filelength = len(self.file_list)return self.filelength# load an one of imagesdef __getitem__(self, idx):img_path, label = self.file_list[idx]img = Image.open(img_path).convert('RGB')img_transformed = self.transform(img)return img_transformed, label
CNN方法
该图像分类器的CNN模型由三层2D卷积组成,内核大小为3,步幅为2,最大池化层为2。在卷积层之后,有两个完全连接的层,每个层由10个节点组成。下面是一个代码片段,说明了这个结构:
class Cnn(nn.Module):def __init__(self):super(Cnn, self).__init__()self.layer1 = nn.Sequential(nn.Conv2d(3, 16, kernel_size=3, padding=0, stride=2),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(2))self.layer2 = nn.Sequential(nn.Conv2d(16, 32, kernel_size=3, padding=0, stride=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(2))self.layer3 = nn.Sequential(nn.Conv2d(32, 64, kernel_size=3, padding=0, stride=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2))self.fc1 = nn.Linear(3 * 3 * 64, 10)self.dropout = nn.Dropout(0.5)self.fc2 = nn.Linear(10, 2)self.relu = nn.ReLU()def forward(self, x):out = self.layer1(x)out = self.layer2(out)out = self.layer3(out)out = out.view(out.size(0), -1)out = self.relu(self.fc1(out))out = self.fc2(out)return out
训练进行了10个训练时期。以下是每个epoch的训练循环的结果。

VisionTransformer方法
Vision Transformer架构设计为可根据特定要求进行调整的自定义尺寸。对于这种大小的图像数据集,这种架构仍然很大。
from vision_tr.simple_vit import ViT
model = ViT(image_size=224,patch_size=32,num_classes=2,dim=128,depth=12,heads=8,mlp_dim=1024,dropout=0.1,emb_dropout=0.1,
).to(device)
VisionTransformer中的每个参数都起着关键作用,如下所述:
image_size=224:此参数指定模型输入图像的所需大小(宽度和高度)。在这种情况下,图像的大小预期为224x224像素。patch_size=32:图像被分成更小的块,该参数定义每个块的大小(宽度和高度)。在这种情况下,每个补丁是32x32像素。num_classes=2:该参数表示分类任务中的类的数量。在这个例子中,模型被设计为将输入分为两类(猫和狗)。dim=128:指定模型中嵌入向量的维数。嵌入捕获每个图像块的表示。depth=12:此参数定义Vision Transformer模型(编码器模型)中的深度或层数。更高的深度允许更复杂的特征提取。heads=8:该参数表示模型的自注意机制中的注意头数。mlp_dim=1024:指定模型中多层感知器(MLP)隐藏层的维度。MLP负责在自我注意之后转换令牌表示。dropout=0.1:此参数控制dropout率,这是一种用于防止过拟合的正则化技术。它在训练过程中随机将一部分输入单位设置为0。emb_dropout = 0.1:它定义了专门应用于令牌嵌入的丢弃率。这种dropout有助于防止在训练过程中过度依赖特定的token。
用于分类任务的VisionTransformer的训练进行了20个epoch(而不是CNN使用的10个epoch),因为训练损失的收敛速度很慢。以下是每个时期的训练循环结果。

CNN方法在10个时期内达到了75%的准确率,而视觉Transformer模型达到了69%的准确率,并且需要更长的时间来训练。
结论
总之,当比较CNN和Vision Transformer模型时,在模型大小、内存要求、准确性和性能方面存在显著差异。CNN模型传统上以其紧凑的尺寸和高效的内存利用率而闻名,使其适用于资源受限的环境。它们已被证明在图像处理任务中非常有效,并在各种计算机视觉应用中表现出出色的精度。另一方面,Vision Transformers提供了一种强大的方法来捕获图像中的全局依赖关系和上下文理解,从而提高了某些任务的性能。然而,与CNN相比,Vision Transformers往往具有更大的模型大小和更高的内存要求。虽然它们可以实现令人印象深刻的准确性,特别是在处理较大的数据集时,但计算需求可能会限制它们在资源有限的情况下的实用性。
最终,CNN和Vision Transformer模型之间的选择取决于手头任务的具体要求,考虑可用资源,数据集大小以及模型复杂性,准确性和性能之间的权衡等因素。随着计算机视觉领域的不断发展,预计这两种架构都会有进一步的进步,使研究人员和从业人员能够根据他们的特定需求和限制做出更明智的选择。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
相关文章:
VisionTransformer(ViT)与CNN卷积神经网络的对比
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...

计算机视觉+Numpy和OpenCV入门
Day 1:Python基础Numpy和OpenCV入门 Python基础 变量与数据类型、函数与类的定义、列表与字典操作文件读写操作(读写图像和数据文件) 练习任务:写一个Python脚本,读取一个图像并保存灰度图像。 import cv2 img cv2.im…...
)
Vue 3 工程化打包工具:从理论到实践 (下篇)
引言 在前端开发中,打包工具是工程化的重要组成部分。Vue 3 作为当前流行的前端框架,其工程化离不开高效的打包工具。打包工具不仅能够将代码、样式、图片等资源进行优化和压缩,还能通过模块化、代码分割等功能提升应用的性能。本文将深入探…...
java经验快速学习python!
title: java经验快速学习python! date: 2025-02-19 01:52:05 tags: python学习路线 java经验快速学习python! 本篇文档会一直更新!!!变量、分支结构、循环结构、数据结构【列表、元组、集合字典】python常用内置函数元…...

爬虫破解网页禁止F12
右击页面显示如下 先点击f12再输入网址,回车后没有加载任何数据 目前的一种解决方法: 先 AltD ,再 CtrlShifti...

从零开始构建一个语言模型中vocab_size(词汇表大小)的设定规则
从零开始构建一个语言模型就要设计一个模型框架,其中要配置很多参数。在自然语言处理任务中,vocab_size(词汇表大小) 的设定是模型设计的关键参数之一,它直接影响模型的输入输出结构、计算效率和内存消耗。 本文是在我前文的基础上讲解的:从零开始构建一个小型字符级语言…...

Jenkins插件管理切换国内源地址
安装Jenkins 插件时,由于访问不了国外的插件地址,会导致基本插件都安装失败。 不用着急,等全部安装失败后,进入系统,修改插件源地址,重启后在安装所需插件。 替换国内插件更新地址 选择:系统…...

Q - learning 算法是什么
Q - learning 算法是什么 Q - learning 算法是一种经典的无模型强化学习算法,由克里斯沃特金斯(Chris Watkins)在 1989 年提出。它被广泛应用于解决各种决策问题,尤其适用于智能体在环境中通过与环境交互来学习最优策略的场景。下面从基本概念、核心公式、算法流程和特点几…...

nasm - console 32bits
文章目录 nasm - console 32bits概述笔记my_build.batnasm_main.asm用VS2019写个程序,按照win32方式编译,比较一下。备注END nasm - console 32bits 概述 看到一个nasm的例子(用nasm实现一个32bits控制台的程序架子) 学习一下 笔记 my_build.bat ec…...

11.编写前端内容|vscode链接Linux|html|css|js(C++)
vscode链接服务器 安装VScode插件 Chinese (Simplified) (简体中⽂) Language Pack for Visual Studio CodeOpen in BrowserRemote SSH 在命令行输入 remote-ssh接着输入 打开配置文件,已经配置好主机 点击远程资源管理器可以找到 右键链接 输入密码 …...

【deepseek-r1模型】linux部署deepseek
1、快速安装 Ollama 下载:Download Ollama on macOS Ollama 官方主页:https://ollama.com Ollama 官方 GitHub 源代码仓库:https://github.com/ollama/ollama/ 官网提供了一条命令行快速安装的方法。 (1)下载Olla…...

【Github每日推荐】-- 2024 年项目汇总
1、AI 技术 项目简述OmniParser一款基于纯视觉的 GUI 智能体,能够准确识别界面上可交互图标以及理解截图中各元素语义,实现自动化界面交互场景,如自动化测试、自动化操作等。ChatTTS一款专门为对话场景设计的语音生成模型,主要用…...

C++中的.*运算符
看运算符重载的时候,看到这一句 .* :: sizeof ?: . 注意以上5个运算符不能重载。 :: sizeof ?: . 这四个好理解,毕竟都学过,但.*是什么? 于是自己整理了一下 .* 是一种 C 中的运算符,称为指针到成…...
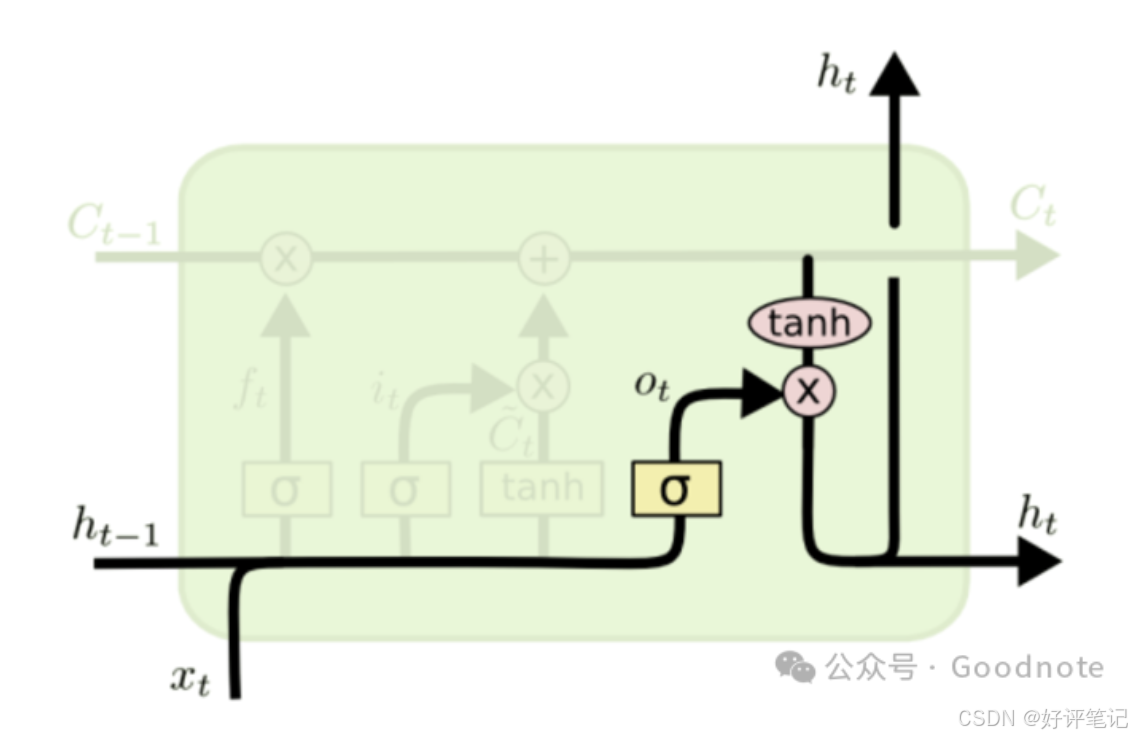
深度学习笔记——LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的LSTM知识点。 文章目录 LSTM(Long Short-Term Memory)LSTM 的核心部件LSTM 的公式和工作原理(1) 遗忘门&a…...

spring boot知识点2
1.spring boot 要开启一些特性,可通过什么方式开启 a.通过Enable注解,可启动定时服务 b.通过application.properties可设置端口号等地址信息 2.什么是热部署,以及spring boot通过什么方式进行热部署 热部署这个概念,我知道。就…...
【机器学习】CNN与Transformer的表面区别与本质区别
仅供参考 表面区别 1. 结构和原理: CNN:主要通过卷积层来提取特征,这些层通过滑动窗口(卷积核)捕捉局部特征,并通过池化层(如最大池化)来降低特征的空间维度。CNN非常适合处理具有网格状拓扑结构的数据,如图像。Transformer:基于自注意力(Self-Attention)机制,能…...
框架篇 - Hearth ArcGIS 框架扩展(DryIoC、Options、Nlog...)
框架篇 - Hearth ArcGISPro Addin 框架扩展(DryIoC、Options、Nlog…) 文章目录 框架篇 - Hearth ArcGISPro Addin 框架扩展(DryIoC、Options、Nlog...)1 使用IoC、DI1.1 服务注册1.1.1 `ServiceAttribute`服务特性1.2 依赖注入1.2.1 SDK底层创建实例类型依赖注入1.2.2 `In…...

JUC并发—7.AQS源码分析三
大纲 1.等待多线程完成的CountDownLatch介绍 2.CountDownLatch.await()方法源码 3.CountDownLatch.coutDown()方法源码 4.CountDownLatch总结 5.控制并发线程数的Semaphore介绍 6.Semaphore的令牌获取过程 7.Semaphore的令牌释放过程 8.同步屏障CyclicBarrier介绍 9.C…...
windows系统本地部署DeepSeek-R1全流程指南:Ollama+Docker+OpenWebUI
本文将手把手教您使用OllamaDockerOpenWebUI三件套在本地部署DeepSeek-R1大语言模型,实现私有化AI服务搭建。 一、环境准备 1.1 硬件要求 CPU:推荐Intel i7及以上(需支持AVX2指令集) 内存:最低16GB,推荐…...

当C#邂逅Deepseek, 或.net界面集成deepseek
最近,我开发了一个C#界面,并集成了Deepseek的接口功能,实现了本地化部署和流模式读取。 过程充满了挑战和乐趣,也让我深刻体会到Deepseek的强大之处。今天,我想和大家分享这段经历,希望能激发你对Deepseek的…...

我把 iOS 存钱 App 移植到鸿蒙:number 精度丢失坑了我两天
做了个什么东西 我有一个独立开发的存钱 App 叫「聚沙攒钱」,iOS 版上线快两年了。核心功能就是设一个储蓄目标,比如攒钱买耳机或者攒旅行基金,每次存钱会有硬币掉落动画,配合成就徽章和连续打卡,让存钱这件事不那么无…...

LFM2-2.6B-GGUF在运维自动化中的应用:智能解析日志并执行故障修复脚本
LFM2-2.6B-GGUF在运维自动化中的应用:智能解析日志并执行故障修复脚本 1. 运维自动化的新机遇 凌晨三点,服务器突然告警。运维工程师小王从睡梦中惊醒,手忙脚乱地登录系统查看日志,发现是数据库连接池耗尽导致的服务不可用。这种…...

敏捷教练的必备工具箱:让团队真正“敏捷”起来
在敏捷转型的浪潮中,软件测试从业者扮演着至关重要的角色。我们既是质量关隘的守卫者,也是流程效率的体验者与反馈者。然而,许多团队的“敏捷”实践常常流于形式,站会、看板、迭代回顾一应俱全,却未能触及敏捷的核心—…...

19.AI开发感悟
现在的AI大模型的能力一直在提升,但是算力跟不上,体现为上下文越长,AI越是乱来,这时遇到bug都不知道怎么修。如果你是这个领域的小白,不懂这个方向的技术,你根本不知道怎么办,如果你是这个领域的…...

Agent经典论文——ReAct框架
目录 1、论文概述 1.1 研究背景 1.2 现有方法局限 1.3 核心贡献 1.4 摘要 2、ReAct方法 2.1 智能体与环境交互的一般设置 2.2 动作空间扩展与生成流程 2.3 独特特征 3、实验 3.1 知识密集型推理任务 3.2 决策任务 4、结论 1、论文概述 在开始分享这篇论文之前&…...

微信语音导出mp3全攻略:手机免电脑、在线工具、格式工厂三种方法实测对比
微信语音导出MP3全攻略:三种方法实测与避坑指南 每次听到微信里珍贵的语音消息时,你是否想过把它们永久保存下来?无论是孩子第一次叫"爸爸妈妈"的稚嫩声音,还是商务谈判中的关键承诺,这些语音都值得用更通用…...

Phi-4-mini-reasoning企业落地:保险条款自动推理与理赔逻辑校验系统
Phi-4-mini-reasoning企业落地:保险条款自动推理与理赔逻辑校验系统 1. 项目背景与价值 保险行业长期面临两大核心痛点:复杂的条款解读和繁琐的理赔审核。传统人工处理方式存在效率低、成本高、标准不统一等问题。Phi-4-mini-reasoning模型凭借其强大的…...

从产品经理视角看:为什么内容运营增长平台一定要用 Redis?
很多人谈 Redis,习惯从技术角度切入:内存数据库快支持高并发支持多种数据结构但如果你是产品经理,真正需要思考的问题不是 Redis 快不快,而是:Redis 能解决什么业务问题?能带来什么产品价值?我曾…...
)
深入S32K3芯片内部:图解FCCU状态机与安全机制(从CONFIG到FAULT的完整流程)
深入解析S32K3芯片FCCU模块:状态机设计与安全机制实战指南 在汽车电子和工业控制领域,功能安全已成为系统设计的核心考量。NXP的S32K3系列微控制器凭借其强大的安全特性,在ADAS、BMS等关键应用中广受青睐。作为芯片安全架构的中枢神经&#x…...

Win11Debloat:终极Windows 11优化指南,三步打造纯净高效系统
Win11Debloat:终极Windows 11优化指南,三步打造纯净高效系统 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to…...