强化学习-价值学习算法
Sarsa
理论解释
Sarsa是基于时序差分算法的,它的公式非常简单且易理解,不像策略梯度算法那样需要复杂的推导过程。
Sarsa的核心函数是 Q ( s , a ) Q(s, a) Q(s,a),它的含义是在状态 s s s下执行 a a a,在后续轨迹中获取的期望总奖励。时序差分算法的核心思想,就是用当前获得的奖励加上下一个状态的价值估计来作为当前状态的价值估计,因此有以下公式,其中 V ( s t + 1 ) V(s_{t+1}) V(st+1)的含义是以状态 s t + 1 s_{t+1} st+1为起点,在后续的轨迹中获取的期望总奖励。
Q ( s t , a t ) ← r t + γ ⋅ V ( s t + 1 ) Q(s_t, a_t) \leftarrow r_t + \gamma \cdot V(s_{t+1}) Q(st,at)←rt+γ⋅V(st+1)
在这里我们做一步近似,在相同策略下智能体实际采取的动作为 a t + 1 a_{t + 1} at+1,那么我们认为 V ( s t + 1 ) V(s_{t+1}) V(st+1)和 Q ( s t + 1 , a t + 1 ) Q(s_{t+1}, a_{t+1}) Q(st+1,at+1)是近似相等的,因此我们可以得到Sarsa算法的核心公式:
Q ( s t , a t ) ← r t + γ ⋅ Q ( s t + 1 , a t + 1 ) Q(s_t, a_t) \leftarrow r_t + \gamma \cdot Q(s_{t+1}, a_{t+1}) Q(st,at)←rt+γ⋅Q(st+1,at+1)
在这里,我们使用神经网络来拟合 Q ( s , a ) Q(s, a) Q(s,a),在选取动作时采用 ϵ \epsilon ϵ-greedy策略,即有 ϵ \epsilon ϵ的概率随机选取一个动作, 1 − ϵ 1 - \epsilon 1−ϵ的概率选取 Q ( s , a ) Q(s, a) Q(s,a)最大的动作。
按照此策略我们在状态 s t s_t st时选取动作 a t a_t at,此时环境会返回状态 s t + 1 s_{t+1} st+1,则再按照此策略选取动作 a t + 1 a_{t+1} at+1,然后按照上述的公式来更新 Q ( s , a ) Q(s, a) Q(s,a)参数。由于这里我们使用神经网络来拟合参数,所以我们更新的方式是计算loss值,然后进行梯度下降。如下面所示,其中 l o s s f n loss_{fn} lossfn是指根据现有值和目标值来计算loss值的函数,在代码中采取的MSE均方误差函数。
q v a l u e = Q ( s , a ) q_{value} = Q(s, a) qvalue=Q(s,a)
q t a r g e t = r t + γ ⋅ Q ( s t + 1 , a t + 1 ) q_{target} = r_t + \gamma \cdot Q(s_{t+1}, a_{t+1}) qtarget=rt+γ⋅Q(st+1,at+1)
l o s s = l o s s f n ( q v a l u e , q t a r g e t ) loss = loss_{fn}(q_{value}, q_{target}) loss=lossfn(qvalue,qtarget)
代码
环境为python3.12,各依赖包均为最新版。
import random
import gymnasium as gym
import torch
import torch.nn as nn
from torch import tensorclass QNet(torch.nn.Module):def __init__(self, action_state_dim, hidden_dim):"""网络的输入由action和state连接而成,网络的输出是长度为1的向量,代表 q value。action用one-hot向量表示,例如动作空间为A = {0, 1, 2}时,向量(1, 0, 0)和(0, 1, 0)分别代表动作a = 0和动作a = 1。"""super(QNet, self).__init__()# 一个线性层 + 激活函数 + 一个线性层self.network = nn.Sequential(nn.Linear(action_state_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, 1),)def forward(self, x):x = self.network(x)return xclass Agent:def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma, device, epsilon):# 策略网络self.action_value_net = QNet(state_dim + action_dim, hidden_dim).to(device)# 创建优化器,优化器的作用是根据每个参数的梯度来更新参数self.optimizer = torch.optim.Adam(self.action_value_net.parameters(), lr=learning_rate)# 折扣因子self.gamma = gamma# 进行神经网络计算的设备self.device = device# 探索策略,有epsilon的概率随机选取动作self.epsilon = epsilon# 状态维度self.state_dim = state_dim# 动作维度self.action_dim = action_dim# 损失函数,根据当前值和目标值来计算得出损失值self.loss_fn = nn.MSELoss()def take_action(self, state):# 随机探索if random.random() < self.epsilon:return random.choice(range(self.action_dim))# 生成一个对角线矩阵,矩阵的每一行元素代表一个动作actions = torch.eye(self.action_dim).to(self.device)# 对state进行复制,actions中有多少个动作,就state复制为多少行state = tensor(state, dtype=torch.float).to(self.device)states = state.unsqueeze(0).repeat(actions.shape[0], 1)# 连接actions和states矩阵,得到的action_states可以看做是一个batch的动作状态向量action_states = torch.cat((actions, states), dim=1)# 将一个batch的动作状态向量输入到Q网络中,得到一组Q值# 注意q_values的形状是(batch_size, 1),我们将它转换成一维向量q_values = self.action_value_net(action_states).view(-1)# 获取最大Q值对应的下标,下标的值就是采取的最优动作max_value, max_index = torch.max(q_values, dim=0)return max_index.item()def update(self, transition):# 取出相关数据reward = torch.tensor(transition['reward']).to(self.device)state = torch.tensor(transition['state']).to(self.device)next_state = torch.tensor(transition['next_state']).to(self.device)terminated = transition['terminated']# 将数字action转换成one-hot action向量action = torch.zeros(self.action_dim, dtype=torch.float).to(self.device)action[transition['action']] = 1.# 将数字next_action转换成one-hot next_action向量next_action = torch.zeros(self.action_dim, dtype=torch.float).to(self.device)next_action[transition['next_action']] = 1.# 连接action和state向量action_state = torch.cat((action, state), dim=0)next_action_state = torch.cat((next_action, next_state), dim=0)# 获取Q值q_value = self.action_value_net(action_state)[0]# 计算目标Q值。一定要注意如果terminated为true,说明执行action后游戏就终止了# 那么next_state和next_action是无意义的,它们的Q值应该为0# 通过将Q值乘以(1. - float(terminated))的方式,来使其在终止时为0q_target = reward + self.action_value_net(next_action_state)[0] * self.gamma \* (1. - float(terminated))# 计算损失值,第一个参数为当前Q值,第二个参数为目标Q值loss = self.loss_fn(q_value, q_target)# 更新参数self.optimizer.zero_grad()loss.backward()self.optimizer.step()if __name__ == '__main__':# 更新网络参数的学习率learning_rate = 1e-3# 训练轮次num_episodes = 1000# 隐藏层神经元数量hidden_dim = 128# 计算累计奖励时的折扣率gamma = 0.98epsilon = 0.2# 如果存在cuda就用cuda,否则用cpudevice = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")env = gym.make('CartPole-v1')# 获取状态维度,为4state_dim = env.observation_space.shape[0]# 获取离散动作数量,为2action_dim = env.action_space.n# 强化学习智能体agent = Agent(state_dim, hidden_dim, action_dim, learning_rate, gamma, device, epsilon)for episode in range(num_episodes):# transition含义是,在state执行action后,环境返回reward、next_state、terminated# 根据next_state,继续采取next_action作为下一动作transition = {'state': None,'action': None,'next_state': None,'next_action': None,'reward': None,'terminated': None}# 统计信息,游戏结束时获得的总奖励sum_reward = 0# reset返回的是一个元组,第一个元素是初始state值,第二个元素是一个字典state = env.reset()[0]# 游戏终止信号terminated = Falseaction = agent.take_action(state)while not terminated:next_state, reward, terminated, _, _ = env.step(action)next_action = agent.take_action(next_state)# 为transition中添加当前的状态、动作等信息transition['state'] = statetransition['action'] = actiontransition['next_state'] = next_statetransition['reward'] = rewardtransition['next_action'] = next_actiontransition['terminated'] = terminated# 一定确保这里会学习到terminated为true的那一步agent.update(transition)sum_reward += reward# 进入下一状态state = next_stateaction = next_action# 每10轮打印一次统计信息if episode % 10 == 0:print(f"Episode: {episode}, Reward: {sum_reward}")
DQN
理论解释
DQN全程Deep Q Learning,与Sarsa算法十分类似,依然是使用时序差分算法来优化 Q ( s , a ) Q(s, a) Q(s,a)函数。不过DQN的 Q ( s , a ) Q(s, a) Q(s,a)函数含义和优化方式与Sarsa略有不同。
DQN中 Q ( s , a ) Q(s, a) Q(s,a)的含义是在状态 s s s执行动作 a a a后,在后续的轨迹中所能获得的最大累积奖励,为了作区分也有人把DQN的 Q ( s , a ) Q(s, a) Q(s,a)表示为 Q ⋆ ( s , a ) Q^\star(s, a) Q⋆(s,a),本文就不在作区分表示了。
DQN中 Q ( s , a ) Q(s, a) Q(s,a)的时序差分优化过程如下,其中 A A A是动作空间:
Q ( s t , a t ) ← r t + γ ⋅ max a ′ ∈ A Q ( s t + 1 , a ′ ) Q(s_t, a_t) \leftarrow r_t + \gamma \cdot \max\limits_{a' \in A} Q(s_{t+1}, a') Q(st,at)←rt+γ⋅a′∈AmaxQ(st+1,a′)
使用神经网络来拟合 Q ( s , a ) Q(s, a) Q(s,a),在选取动作时依然采用 ϵ \epsilon ϵ-greedy策略。按照此策略我们在状态 s t s_t st时选取动作 a t a_t at,此时环境会返回状态 s t + 1 s_{t+1} st+1,然后遍历所有的动作,选取 Q ( s t + 1 , a ′ ) Q(s_{t+1}, a') Q(st+1,a′)最大的动作 a ′ a' a′,然后计算loss值。
q v a l u e = Q ( s , a ) q_{value} = Q(s, a) qvalue=Q(s,a)
q t a r g e t = r t + γ ⋅ max a ′ ∈ A Q ( s t + 1 , a ′ ) q_{target} = r_t + \gamma \cdot \max\limits_{a' \in A} Q(s_{t+1}, a') qtarget=rt+γ⋅a′∈AmaxQ(st+1,a′)
l o s s = l o s s f n ( q v a l u e , q t a r g e t ) loss = loss_{fn}(q_{value}, q_{target}) loss=lossfn(qvalue,qtarget)
与Sarsa相同,损失函数的计算方式依然选择MSE均方误差。
代码
环境为python3.12,各依赖包均为最新版。
实现代码与Sarsa基本相同,仅有两处做了修改,修改位置已在代码中注释。
import random
import gymnasium as gym
import torch
import torch.nn as nn
from torch import tensorclass QNet(torch.nn.Module):def __init__(self, action_state_dim, hidden_dim):"""网络的输入由action和state连接而成,网络的输出是长度为1的向量,代表 q value。action用one-hot向量表示,例如动作空间为A = {0, 1, 2}时,向量(1, 0, 0)和(0, 1, 0)分别代表动作a = 0和动作a = 1。"""super(QNet, self).__init__()# 一个线性层 + 激活函数 + 一个线性层self.network = nn.Sequential(nn.Linear(action_state_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, 1),)def forward(self, x):x = self.network(x)return xclass Agent:def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma, device, epsilon):# 策略网络self.action_value_net = QNet(state_dim + action_dim, hidden_dim).to(device)# 创建优化器,优化器的作用是根据每个参数的梯度来更新参数self.optimizer = torch.optim.Adam(self.action_value_net.parameters(), lr=learning_rate)# 折扣因子self.gamma = gamma# 进行神经网络计算的设备self.device = device# 探索策略,有epsilon的概率随机选取动作self.epsilon = epsilon# 状态维度self.state_dim = state_dim# 动作维度self.action_dim = action_dim# 损失函数,根据当前值和目标值来计算得出损失值self.loss_fn = nn.MSELoss()def take_action(self, state):# 随机探索if random.random() < self.epsilon:return random.choice(range(self.action_dim))# 生成一个对角线矩阵,矩阵的每一行元素代表一个动作actions = torch.eye(self.action_dim).to(self.device)# 对state进行复制,actions中有多少个动作,就state复制为多少行state = tensor(state, dtype=torch.float).to(self.device)states = state.unsqueeze(0).repeat(actions.shape[0], 1)# 连接actions和states矩阵,得到的action_states可以看做是一个batch的动作状态向量action_states = torch.cat((actions, states), dim=1)# 将一个batch的动作状态向量输入到Q网络中,得到一组Q值# 注意q_values的形状是(batch_size, 1),我们将它转换成一维向量q_values = self.action_value_net(action_states).view(-1)# 获取最大Q值对应的下标,下标的值就是采取的最优动作max_value, max_index = torch.max(q_values, dim=0)return max_index.item()def update(self, transition):# 取出相关数据reward = torch.tensor(transition['reward']).to(self.device)state = torch.tensor(transition['state']).to(self.device)next_state = torch.tensor(transition['next_state']).to(self.device)terminated = transition['terminated']# 将数字action转换成one-hot action向量action = torch.zeros(self.action_dim, dtype=torch.float).to(self.device)action[transition['action']] = 1.# 连接action和state向量action_state = torch.cat((action, state), dim=0)# 获取Q值q_value = self.action_value_net(action_state)[0]"""与Sarsa算法主要不同的地方,在于q_target的计算方式:类似于take_action函数中的内容,这里需要把所有动作都进行one-hot操作,与状态连接并输入到网络中,获取所有动作的q_value中最大的值,作为计算q_target的一部分。"""next_actions = torch.eye(self.action_dim).to(self.device)next_states = next_state.unsqueeze(0).repeat(next_actions.shape[0], 1)next_action_states = torch.cat((next_actions, next_states), dim=1)q_target = reward + torch.max(self.action_value_net(next_action_states)) \* self.gamma * (1. - float(terminated))# 计算损失值,第一个参数为当前Q值,第二个参数为目标Q值loss = self.loss_fn(q_value, q_target)# 更新参数self.optimizer.zero_grad()loss.backward()self.optimizer.step()if __name__ == '__main__':# 更新网络参数的学习率learning_rate = 1e-3# 训练轮次num_episodes = 1000# 隐藏层神经元数量hidden_dim = 128# 计算累计奖励时的折扣率gamma = 0.98epsilon = 0.2# 如果存在cuda就用cuda,否则用cpudevice = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")env = gym.make('CartPole-v1')# 获取状态维度,为4state_dim = env.observation_space.shape[0]# 获取离散动作数量,为2action_dim = env.action_space.n# 强化学习智能体agent = Agent(state_dim, hidden_dim, action_dim, learning_rate, gamma, device, epsilon)for episode in range(num_episodes):# transition含义是,在state执行action后,环境返回reward、next_state、terminated# 根据next_state,继续采取next_action作为下一动作transition = {'state': None,'action': None,'next_state': None,'next_action': None,'reward': None,'terminated': None}# 统计信息,游戏结束时获得的总奖励sum_reward = 0# reset返回的是一个元组,第一个元素是初始state值,第二个元素是一个字典state = env.reset()[0]# 游戏终止信号terminated = Falsewhile not terminated:"""与Sarsa算法略有不同的地方,这里不需要再获取next_action"""action = agent.take_action(state)next_state, reward, terminated, _, _ = env.step(action)# 为transition中添加当前的状态、动作等信息transition['state'] = statetransition['action'] = actiontransition['next_state'] = next_statetransition['reward'] = rewardtransition['terminated'] = terminated# 一定确保这里会学习到terminated为true的那一步agent.update(transition)sum_reward += reward# 进入下一状态state = next_state# 每10轮打印一次统计信息if episode % 10 == 0:print(f"Episode: {episode}, Reward: {sum_reward}")
相关文章:

强化学习-价值学习算法
Sarsa 理论解释 Sarsa是基于时序差分算法的,它的公式非常简单且易理解,不像策略梯度算法那样需要复杂的推导过程。 Sarsa的核心函数是 Q ( s , a ) Q(s, a) Q(s,a),它的含义是在状态 s s s下执行 a a a,在后续轨迹中获取的期望…...

Golang深度学习
前言 在2009年,Google公司发布了一种新的编程语言,名为Go(或称为Golang),旨在提高编程效率、简化并发编程,并提供强大的标准库支持。Go语言的设计者们希望通过Go语言能够解决软件开发中的一些长期存在的问…...
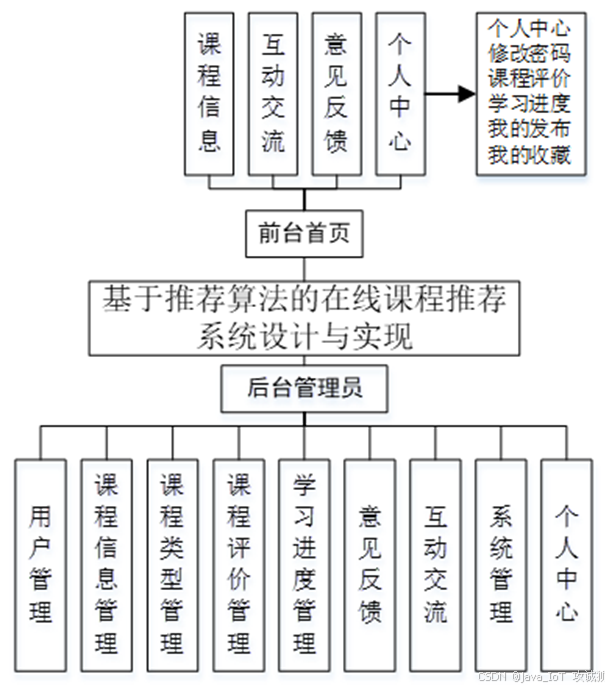
基于推荐算法的在线课程推荐系统设计与实现
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...

es和kibana安装
es安装 安装 wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.17.1-linux-x86_64.tar.gz 参考: https://www.cnblogs.com/shamo89/p/18504053 https://blog.csdn.net/u012899618/article/details/130383429 解压 tar -zxvf elastic…...
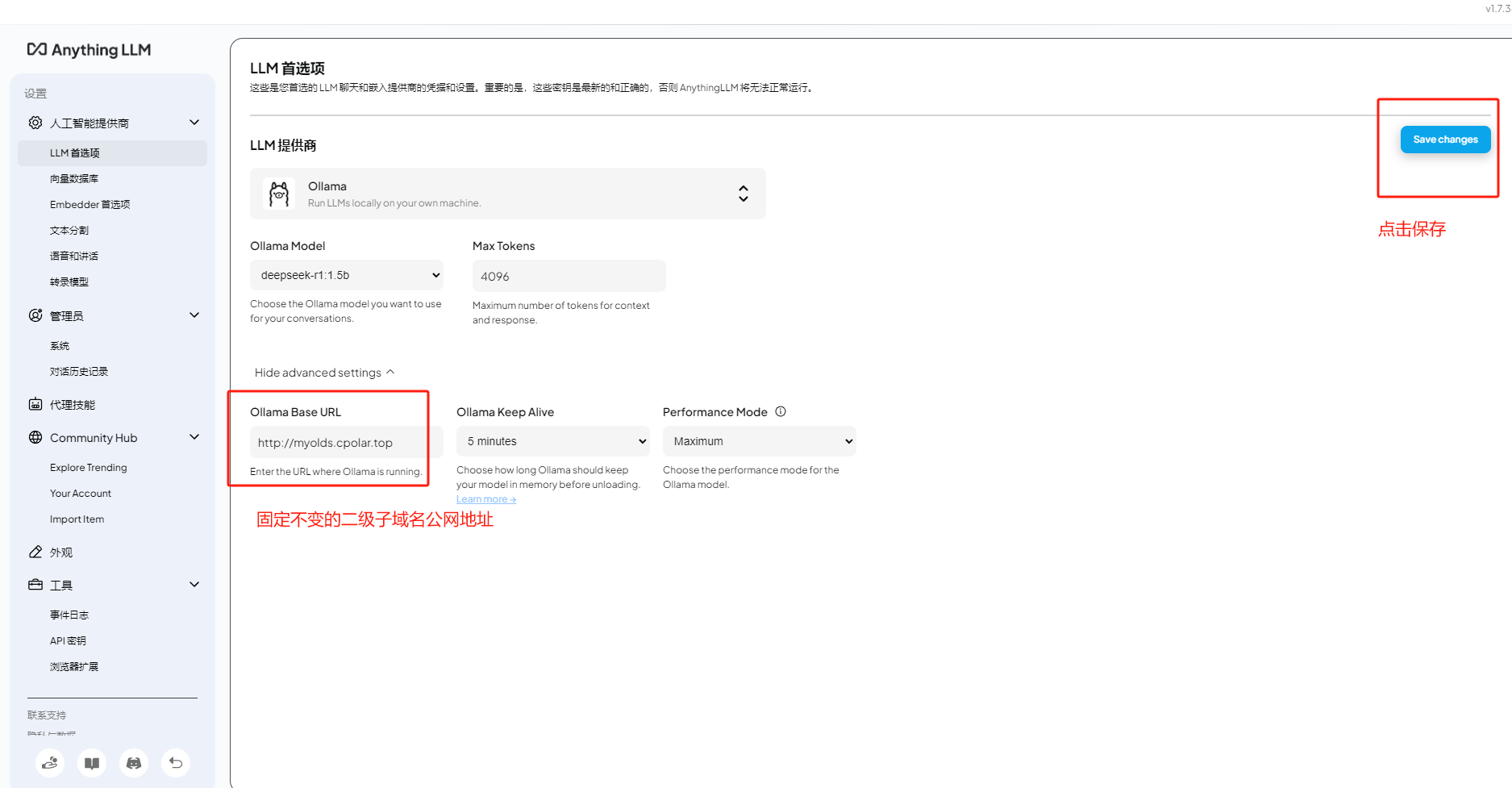
本地部署Anything LLM+Ollama+DeepSeek R1打造AI智能知识库教程
文章目录 前言1. 本地部署OllamaDeepSeek2. 本地安装Anything LLM3. 配置与使用演示4. 远程调用大模型5. 安装内网穿透6. 配置固定公网地址 前言 本文主要介绍如何在Windows电脑上本地部署Ollama并接入DeepSeek R1大模型,然后使用强大的开源AI工具Anything LLM结合…...

zyNo.25
SSRF漏洞 在了解ssrf漏洞前先了解curl命令的使用 1.curl命令的使用 基本格式:curl<参数值>请求地址 get请求:curl http://127.0.0.1 post请求:curl -X POST -d "a1&b2" http://127.0.0.1/(其中,使用-X参…...

Spring框架基本使用(Maven详解)
前言: 当我们创建项目的时候,第一步少不了搭建环境的相关准备工作。 那么如果想让我们的项目做起来方便快捷,应该引入更多的管理工具,帮我们管理。 Maven的出现帮我们大大解决了管理的难题!! Maven…...

关于前后端分离跨域问题——使用DeepSeek分析查错
我前端使用ant design vue pro框架,后端使用kratos框架开发。因为之前也解决过跨域问题,正常是在后端的http请求中加入中间件,设置跨域需要通过的字段即可,代码如下所示: func NewHTTPServer(c *conf.Server, s *conf…...
三层渗透测试-DMZ区域 二三层设备区域
DMZ区域渗透 信息收集 首先先进行信息收集,这里我们可以选择多种的信息收集方式,例如nmap如此之类的,我的建议是,可以通过自己现有的手里小工具,例如无影,密探这种工具,进行一个信息收集。以免…...

领航Linux UDP:构建高效网络新纪元
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 文章目录 引言Udp和Tcp的异同相同点不同点总结 1.1、socket1.2、bind1.3、recvfrom1.4、sendto2.1、代码2.1、说明3.1、代码3.2、说明 引言 在前几篇博客中,我们学习了Linux网络编程中的一些概念。…...

基于MATLAB的均匀面阵MUSIC算法DOA估计仿真
基于MATLAB的均匀面阵MUSIC算法DOA估计仿真 文章目录 前言一、二维MUSIC算法原理二、二维MUSIC算法MATLAB仿真三、MATLAB源代码总结 前言 \;\;\;\;\; 在波达角估计算法中,MUSIC 算法与ESPRIT算法属于特征结构子空间算法,是波达角估计算法中的基石。在前面…...

HTML/CSS中后代选择器
1.作用:选中指定元素中,符合要求的后代元素. 2.语法:选择器1 选择器2 选择器3 ...... 选择器n(使用空格隔开) 3.举例: /* 选中ul中的所有li */ul li{color: red;}/* 选中类名为subject元素中的所有li */.subject li{color: blue;}/* 选中类名为subject元素中的所有类名为f…...

深入解析「卡顿帧堆栈」 | UWA GPM 2.0 技术细节与常见问题
在游戏开发过程中,卡顿问题一直是影响玩家体验的关键因素。UWA GPM 2.0全新推出的「卡顿帧堆栈」功能,专为研发团队提供精准、高效的卡顿分析方案,能够直观呈现游戏运行时的堆栈信息,助力团队迅速找到性能瓶颈。该功能一经上线&am…...

推荐几款较好的开源成熟框架
一. 若依: 1. 官方网站:https://doc.ruoyi.vip/ruoyi/ 2. 若依SpringBootVueElement 的后台管理系统:https://gitee.com/y_project/RuoYi-Vue 3. 若依SpringBootVueElement 的后台管理系统:https://gitee.com/y_project/RuoYi-Cl…...

Mysql全文索引
引言 在MySQL 5.7.6之前,全文索引只支持英文全文索引,不支持中文全文索引,需要利用分词器把中文段落预处理拆分成单词,然后存入数据库。 从MySQL 5.7.6开始,MySQL内置了ngram全文解析器,用来支持中文、日文…...

配置终端代理
普通的魔法开启之后终端下git clone等命令仍然会无法使用,额外需要手动配置终端代理。 sudo vim /etc/apt/apt.conf.d/99proxyAcquire::http::Proxy "http://127.0.0.1:12334"; Acquire::https::Proxy "http://127.0.0.1:12334";在debian安装时…...

51单片机学习之旅——在LCD1602上显示时钟
新建工程 打开软件 LCD1602模块代码添加 因为我们在LCD1602上显示时钟,因此我们需要添加LCD1602的模块代码 跳转到这条博客51单片机学习之旅——模块化编程集_51单片机ruminant-CSDN博客,复制相关代码跳转到这条博客51单片机学习之旅——模块化编程集…...

Jest单元测试
由于格式和图片解析问题,可前往 阅读原文 前端自动化测试在提高代码质量、减少错误、提高团队协作和加速交付流程方面发挥着重要作用。它是现代软件开发中不可或缺的一部分,可以帮助开发团队构建可靠、高质量的应用程序 单元测试(Unit Testi…...

C++字符串处理指南:从基础操作到性能优化——基于std::string的全面解析
博主将从C标准库中的 std::string 出发,详细探讨字符串的处理方法,涵盖常见操作、性能优化和实际应用场景。以下内容将围绕std::string 的使用展开,结合代码示例进行说明。 一、std::string 的基本操作 1.1 创建与初始化 std::string 提供了…...

JVM类加载过程详解:从字节码到内存的蜕变之旅
一、类加载的意义与整体流程 在Java中,每一个.java文件经过编译都会生成.class字节码文件。但字节码本身并不能直接运行,必须通过 类加载(Class Loading)将其转化为JVM内存中的数据结构,才能被程序调用。 类加载过程就…...

揭秘3140亿参数Grok-1:马斯克AI巨兽的多语言能力技术突破
揭秘3140亿参数Grok-1:马斯克AI巨兽的多语言能力技术突破 【免费下载链接】grok-1 Grok open release 项目地址: https://gitcode.com/GitHub_Trending/gr/grok-1 Grok-1作为一款备受关注的开源AI模型,凭借其3140亿的惊人参数规模,在自…...

EmbedIQ:统一AI编码助手配置,实现企业级安全与合规自动化
1. 项目概述:一个为AI编码助手生成“灵魂”的配置工厂如果你和我一样,在团队里同时用着Claude Code、Cursor、GitHub Copilot,甚至还在尝试Gemini和Windsurf,那你一定体会过那种“精神分裂”般的痛苦。每个工具都有自己的配置格式…...

3步搞定Zotero重复文献:智能合并插件的完整使用指南
3步搞定Zotero重复文献:智能合并插件的完整使用指南 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 还在为文献库中大量重复的论文…...

Vite打包压缩插件vite-plugin-pack-orchestrator,自动搞定压缩、校验、自动哈希命名
📦 Vite 构建压缩插件:vite-plugin-pack-orchestrator 🤔 为什么又造一个轮子? 市面上已经有一些 Vite 打包插件,比如 vite-plugin-zip-pack、vite-plugin-compress 等,能用,但总差那么点意思…...

拼接最大数:你以为是贪心?其实是在“做选择的人生模拟”
🔥 拼接最大数:你以为是贪心?其实是在“做选择的人生模拟” 一、引子:很多人写对了代码,却没搞懂本质 这道题(Create Maximum Number),不少人第一次写的时候都会觉得: “这不就是贪心吗?每次选最大的数字就完了。” 然后一提交—— 要么WA(错误答案),要么超时…...
查询属性方法)
mapbox popup(动态定位)查询属性方法
标题popup 动态描点位置,防止内容遮盖 function queryFeatures (e) {const features window.map.queryRenderedFeatures? window.map.queryRenderedFeatures(e.point, {if (!features || !features.length) {ElMessage({message: "未查询到相关要素",ty…...

互联网大厂Java求职面试:从Spring Boot到微服务的技术探讨
互联网大厂Java求职面试:从Spring Boot到微服务的技术探讨 在某个阳光明媚的下午,互联网大厂的面试室里,面试官严肃地坐在桌子后面,准备对候选人燕双非进行一轮面试。第一轮提问 面试官:燕双非,你能给我讲讲…...

2026年云南旅行社供应商实力对比,选哪家更靠谱?
云南,一直是国内旅游的热门目的地。但美景背后,高原反应、隐形消费、行程踩坑……也劝退了不少游客。面对市场上五花八门的旅行社,如何选出一家真正靠谱、有实力、能让人放心的供应商?今天,我们不谈虚的,就…...

PyTorch 极简神经网络搭建|参数计算 + 代码全流程
🧠 PyTorch 极简神经网络搭建|参数计算 代码全流程✨ Bilibili 视频一、深度学习 vs 机器学习:流程极简对比📊二、神经网络结构可视化🎨三、参数计算:手把手算清 26 个参数🔢四、环境配置&…...

【每日一题】最小面积矩形——从平行坐标轴到任意角度的完整攻略
一、题目对比 题目LeetCode 939LeetCode 963题目名称最小面积矩形最小面积矩形 II边的限制必须平行于 x 轴和 y 轴任意角度,不一定平行于坐标轴数据范围1 ≤ points.length ≤ 5001 ≤ points.length ≤ 50返回值整数面积浮点数面积(误差 1e-5 内&#…...