高级推理的多样化推理与验证
25年2月来自波士顿大学、NotBadMath.AI、谷歌、哥伦比亚大学、MIT、Intuit公司和斯坦福大学的论文“Diverse Inference and Verification for Advanced Reasoning”。
OpenAI o1、o3 和 DeepSeek R1 等推理 LLM 在数学和编码方面取得重大进展,但仍发现 IMO 组合问题、ARC 谜题和 HLE 问题等高级任务具有挑战性。本文用多样化的推理方法,在测试时结合多种模型和方法。数学和代码问题以及对其他问题拒绝抽样的验证,简单而有效。其通过 Lean 自动验证 IMO 问题解决方案的正确性,采取代码自动验证 ARC 谜题,并发现 best-of-N 可以有效地回答 HLE 问题。本方法将 IMO 组合问题的答案准确率从 33.3% 提高到 77.8%,将 HLE 问题的准确率从 8% 提高到 37%,并解决 948 名人类无法解决的 80% ARC 难题还有 o3 高度计算无法解决的 26.5% ARC 难题。测试-时间模拟、强化学习和带推理反馈的元学习,通过调整智体的图表征和不同的提示、代码和数据集,可提高泛化能力。
OpenAI o1(OpenAI,2024)和 o3(OpenAI,2025b)以及 DeepSeek R1(Guo,2025)等推理 LLM 在数学、编码和问题解决方面取得令人瞩目的成绩。尽管取得这些进步,但单一的大型模型或方法可能难以完成具有挑战性的任务。为了解决这个问题,推理模型和方法的多样性,已成为一种利用互补优势来提高性能的机制。
数学里程碑中人工智能。数学人工智能 (Miao, 2024) 领域值得关注的里程碑包括 DeepMind 使用 AlphaProof 解决 2024 年 IMO 银牌级问题 (Google DeepMind, 2024a) 和使用 AlphaGeometry2 解决金牌级几何问题 (Chervonyi, 2025; Trinh, 2024; Google DeepMind, 2024b)。LLM 使用遗传算法和程序搜索近似极端组合问题 (Romera-Paredes, 2024)。通过深度强化学习,已经发现执行计算机科学核心操作更快的方法,包括排序 (Mankowitz, 2023) 和矩阵乘法 (Fawzi, 2022)。最近,OpenAI 发布 o1 (OpenAI, 2024) 和 o3 模型,这些模型的推理能力和数学能力与普通研究生相当 (Tao, 2024)。
定理证明。三种最流行的形式化证明语言是 Lean 4 (Moura & Ullrich, 2021)、Coq (The Coq Development Team, 2024) 和 Isabelle (Nipkow et al., 2002)。现有方法可分为非正式和正式定理证明。自动形式化、前提选择、证明步骤生成和证明搜索等任务各有其评估指标 (Li et al., 2024b)。证明策略可以使用基础模型,然后基于最佳优先搜索或 MCTS (Lamont et al., 2024) 来确定下一步要处理的目标,以序列或图表示。以前,机器学习引导数学家的直觉并提出猜想(Davies,2021)。一个迭代和交互的过程在一个闭环中执行,其中数学家从假设开始,人工智能生成数据,训练监督模型并找到模式。数学家提出一个猜想候选并最终证明一个定理。人工智能已广泛用于定理证明(Li,2024b),交互式和自动证明器(Polu & Sutskever,2020;Polu,2022;Yang,2024;Song,2024;Lin,2024;Wang,2024a)。证明搜索的示例包括 GPT-f(Polu & Sutskever,2020)搜索证明树、通过蒙特卡洛树搜索 (MCTS) 进行证明搜索(Wu et al.,2020)、学习哪些路径可以通向正确证明的超树(Lample et al.,2022)、使用基于 LLM MCTS 的 AlphaMath(Chen et al.,2024a)以及在测试时使用 MCTS 优化训练的 DeepSeek Prover(Xin et al.,2024)(Xin et al.,2024)。课程学习已应用于 LeanAgent(Kumarappan et al.,2024)以从易到难学习证明。已经开发一个代数不等式证明系统 (Wei et al., 2024) 来生成许多定理,使用由价值网络引导的符号代数不等式证明器,解决 10/20 IMO 代数不等式问题。三个开放定理证明器是 DeepSeek Prover 1.5 (Xin et al., 2024)、InternLM (Wu et al., 2024)、TheoremLlama (Wang et al., 2024c),一个封闭定理证明器是 AlphaProof (Google DeepMind, 2024a)。
最近的基准。现有的基准包括 miniF2F (Zheng et al., 2021),它由来自数学奥林匹克 AMC、AIME 和 IMO 的 244 个问题组成。由于数学人工智能的快速发展,基准测试已饱和,并引入更困难的基准测试,例如 FrontierMath(Glazer,2024)。针对 William Lowell Putnam 数学竞赛(美国首屈一指的大学数学竞赛)的 640 个形式化问题上定理证明器(Tsoukalas,2024)的基准测试,涵盖 IMO 以外的分析和抽象代数等主题。
证明数据集。最初,证明数据集相对较小。例如,Lean 的 mathlib(van Doorn,2020)包含 140K 个证明,而 Isabelle 有 250k 个证明。Isarstep 是一个基准数据集(Li,2020),其中包括使用分层 transformer 在证明中填写缺失中间命题的任务。 CoqGym (Yang & Deng, 2019) 是一个大型数据集和定理证明训练环境,包含 71k 个人工记录的证明。CoqGym 环境用于训练和评估自动化和交互式定理证明器。该系统通过编写抽象语法树将策略生成为程序。Mustard 数据集 (Huang et al., 2024) 有超过 5k 个示例,这些示例是通过提示 LLM 生成基于数学概念的问题,然后生成自然语言、形式证明和定理而生成的。一个 Lean 证明器验证形式证明以确保正确性。Fevler 数据集 (Lin et al., 2024) 包含 758 个定理、29k 个引理和 200k 个证明步骤,用于增强形式证明验证,其中证明步骤迭代应用以形成形式证明。
自动形式化。自动形式化涉及将自然语言问题和解决方案转化为形式证明。早期,机器翻译用于使用编码器-解码器架构将 LaTeX 中的数学语句转换为形式语句(Wang,2020)。LLM 已用于将数学竞赛问题自动形式化为 Isabelle,而无需对对齐数据进行训练(Wu,2022)。Lean 4 中的过程驱动自动形式化 (PDA)(Lu,2024)利用编译器反馈来提高性能,提供用于评估的数据集 FORML4。使用符号等价性和语义一致性对多个生成的候选进行评分和选择的方法(Li,2024c)进一步提高准确性。结合最相似的检索增强生成 (MS-RAG)、去噪步骤和带语法错误反馈的自动更正 (AutoSEF)(Zhang,2024b),可以在模型之间产生一致且可靠的形式化。
可解释的强化学习。可解释的强化学习旨在解释深度强化学习智体的视觉输出,例如,通过学习智体游戏玩法的结构化状态表示并提取可解释的符号策略 (Luo,2024)。基础模型为这些学习的策略和决策生成文本解释。
测试时间方法。不同的问题具有不同的难度和复杂性。对原始 LLM 的单次调用使用相同数量的计算。因此,解决不同难度的问题,可能需要在推理时进行不同数量的计算。LLM 推理计算成本和准确性之间存在权衡。编码问题的解决率,随着为问题生成的 LLM 样本数量增加而增加 (DeepMind,2023)。聚合样本的简单方法包括共识,例如通过自洽 (Wang,2022)。数学问题的准确性会随着推理时的计算量而增加,例如通过集成 (Jiang et al., 2023)、智体混合 (Wang et al., 2024b)、重复采样和聚合 (Brown et al., 2024; Chen et al., 2024b) 、以及使用强化学习和思维链训练的模型,在推理时得到应用 (OpenAI, 2024)。具有不同角色 LLM 之间的对话和辩论,也被证明可以提高数学推理能力 (Du et al., 2023),这实际上增加了用于推理的计算量。在测试时给出的推理问题,有可能是分布之外的情况。因此,测试示例之后的计算是众所周知的,尤其是在处理分布外的示例时。测试时训练早期已用于改进图像分类 (Sun et al., 2020)。 OptiLLM (Sharma, 2024) 等框架实现多种测试时间方法,以方便进行比较。
抽象和推理语料库 (ARC) 基准。2023 年,有人声称人工智能,特别是 LLM,无法以 8% 的准确率完成这项任务 (Biever, 2023);然而,这种批评很快被证明是错误的,使用 LLM 在 MiniARC (Qiu et al., 2024) 上的准确率为 33.1%,在 ARC 上的准确率为 53% (Li et al., 2024a) 和 61.9% (Akyürek et al., 2024),直到使用最新的高计算模型达到 91.25%,比人类平均水平高 15%。这些方法使用 LLM,通过 Leave-One-Out 对示例对进行训练,通过转换合成数据,微调 LLM,使用语言模型合成程序,执行这些程序,生成假设并验证其正确性。程序合成中大型推理模型的改进(El-Kishky,2025)也提高了 ARC 的性能。ARC 评估数据集上 948 人的共同努力在 400 个评估难题上取得 98.8% 的准确率(LeGris,2024),这激发高计算能力和模型与方法的多样性。
开放和封闭推理 LLM 和算子。OpenAI 发布具有封闭权重的 o1 推理 LLM 和封闭源 Operator 浏览器智体(阻止金融工具)。DeepSeek 发布 R1 推理 LLM,其性能与具有开放权重的 o1 相当。开源浏览器使用工具可在线使用,无限制。
推理LLM
具有预训练参数 θ 的基础模型 π 定义一个条件分布:p_θ(y | x),其中 x 是提示,y 是响应。推理模型经过训练可生成一个(隐藏的)基本原理,也称为思维链 (CoT) z,因此联合生成由以下公式给出:p_θ(z, y | x) = p_θ(z | x)p_θ(y | z, x)。
模型训练包括两个阶段:(i) 监督微调 (SFT):从 π 到 π_SFT;(ii) 强化学习 (RL):从 π_SFT 到 π_RL。
使用 π_θ 生成样本,并将其存储在数据集 D = {(x_i, y_i)}_i = 1, …, n 中。通过对数据集取负对数似然值,可得出监督微调损失:

类似地,对于推理模型,使用 π_θ 生成样本,并将其存储在数据集 D = {(x_i, z_i, y_i)}_i = 1, …, n 中。通过对数据集取负对数似然值,可得出监督微调损失:

对于解决数学问题或生成代码等任务,定义一个奖励函数 R(x, y),通过验证答案或证明或运行单元测试来自动检查该函数。然后进行优化:

这是一个经典的 RL 目标,无需学习偏好模型。
更一般地,给定一个基础模型,定义一个奖励:r(x, yˆ) = f_ π_RM(x, yˆ) ,其中 yˆ 是结果输出,f 是衡量该输出结果质量的函数。例如,使用策略梯度,通过以下方式更新 θ:

对于推理模型,让 zˆ 成为采样原理并定义奖励(Zelikman,2024):r(x, zˆ, yˆ) = f_π_RM (x, zˆ,yˆ), 其中 f 是量化推理质量的函数,例如作为奖励的未来 token 对数似然改进,或问答任务的正确性。对于推理模型,代入 CoT 的对数公式中:log p_θ (zˆ, yˆ | x) = log p_θ (zˆ | x) + log p_θ (yˆ | x, zˆ),得出梯度如下:

聚合各种模型和方法
聚合各种模型和方法的结果,这些模型和方法的解决方案可以通过最大值完美验证为正确。设 T = {t_1, t_2, …, t_N} 为 N 个 IMO 问题或 ARC 难题的集合,设 K 为模型数量 M = {M_1, M_2, …, M_K},其中每个 M_k 尝试解决每个 t_i ∈ T 。
由于可以验证每个解决方案的正确性,因此对于每个问题 t_i,存在一个真值验证机制,表明 M_k 提出的解决方案是否正确。通过对所有模型的正确性指标取逻辑最大值(即逻辑或),组合所有模型的输出。
当且仅当 M 中至少一种方法可以解决该问题时,问题 t_i 才被认为已得到解决。由于只要 K 个模型中的任何一个解决问题,问题就会被视为已解决,因此这种聚合是最佳情况。如果所有模型都犯不同的系统错误,这种方法相对于单个模型而言,可以大大提高可解决问题的覆盖率。如果任何模型的解决方案对于特定问题是正确的,则该问题在聚合结果中被标记为已解决,从而实现不同模型之间的最大性能。
测试时间仿真和强化学习
IMO。如图是解决 IMO 组合问题的方法的高级架构。流程由三个组件组成:编码、模拟和深度强化学习以及解码。在编码阶段,通过将问题公式化为状态空间、动作空间和奖励 (S、A、R) 来找到答案。然后,提示 LLM 将问题转换为游戏环境。在 Gymnasium 中将问题表示为具有智体和策略的 Python 代码。使用模拟和深度强化学习来寻找最佳策略。重复此过程,为每个问题生成具有不同维度的多个游戏,为每个游戏生成多个 episodes 的数据和视频。在解码阶段,提取数据和帧并通过转换对其进行扩充。用 LLM 以描述的形式编写每个序列的图像和策略解释的文本表示。最后,将这些信息与问题陈述、答案、书籍和指南一起使用,通过上下文学习自动形式化证明。整理 2006 年至 2023 年期间所有以前的 IMO ShortList 组合问题的数据集,并使用子集进行自动形式化的上下文学习。结果在 Lean 环境中自动验证,并经过改进以生成完整且正确的证明。本文方法处理可以表述为具有状态空间、动作空间和奖励的游戏组合问题。

Lean 中的自动形式化。除了用英语回答和解决问题外,还使用上下文学习进行循环自动形式化。给定一个问题,通过前几年 IMO 问题及其相应的 Lean 定理中的上下文示例对将其转化为正式的 Lean。自动验证 Lean 代码、删除注释、将 Lean 代码翻译回英语,并让 LLM 比较原始问题和反向翻译的问题,验证它们在数学上是否等价。强大而可靠的反向翻译和 Lean 的意义在于它允许自动验证问题陈述和证明。还要验证专家数学家的证明。正式地,用小样本学习将 X_EN 转换为 Lean 形式证明。具体而言,让 Φ_E→L : {英文文本} → {Lean 代码} 成为 M 的翻译函数(带有英语-Lean 对的上下文示例)。生成 X_Lean = Φ_E→L(X_EN) 函数,其之后用 Lean 编译。Compile(X_Lean)是一个布尔函数,指示证明是否在 Lean 环境中成功编译。为了验证最终的 Lean 定理是否与原始解决方案相匹配,删除 X_Lean 的注释或评论,避免使用可能作为文档出现的特定英文文本,并得到 X′_Lean。然后,应用逆翻译函数 Φ_L→E : { Lean 代码} → {英语文本} 来获得一个反向翻译定理 X_EN⋆= Φ_L→E (X’_Lean)。最后,用 LLM 将 X_EN⋆ 与 X_EN 进行比较以确认它们在数学上是等价的。正式地,要求:Equivalent(X_EN, X_EN⋆) = true,其中 Equivalent(·, ·) 是一个函数,它验证两个文本中的定理、定义和逻辑推论是否一致。如果等价成立,让数学家用 Lean 和英语评估该定理,以检查流水线是否成功生成并验证答案或证明。本文方法能够证明 2024 年 IMO 组合问题,而以前的模型或方法无法单独或使用现有的智体框架解决这些问题。为什么本文方法有效?原因之一是它添加了具有一个完美验证器的真实合成数据。
元学习
尝试使用 LLM 进行元学习,以修改智体图的超参、提示和代码以及智体图拓扑,添加或删除节点和边。输入是智体图,输出是图变型上运行的轨迹。实现基于 Gentrace(Gentrace,2025)和 LLM。以结构化格式表示流水线(智体图)。执行它们并记录中间步骤的详细跟踪。用 LLM 根据流水线表示、跟踪和结果提出流水线修订,并使用 LLM 更正修订后的流水线。
HLE
虽然数学和编码具有自动 0/1 验证器,但其他问题(例如许多 HLE 问题)却没有。因此,无法按最大值汇总非数学和非编码问题的答案。在实践中,在 N 较大的情况下,最佳 N 拒绝抽样对 HLE 问题效果很好。将不同模型或方法答案之间的一致性,计算为它们之间的平均一致性 c,多样性则为 1-c。
避免数据污染
在评估封闭和开放权重基础模型时,使用最佳实践来避免数据污染。模型的知识截止日期早于所评估问题的可用性,模型无法访问互联网,并使用新的 API 调用,以便不会无意中重复使用聊天内存中的解决方案,并且评估不会泄露有关解决方案的信息。用 OptiLLM(Sharma,2024)测试 OpenAI 模型,它包含多种可在线获取的方法、提示和默认参数。
测试封闭和开放权重模型。IMO 2020-2023 是在 OpenAI 模型训练之前进行的,因此无法评估它们或基于这些 IMO 构建映射而不会受到污染。 IMO 入围问题和解决方案将在下一届 IMO 之后发布,因此 2023 年 IMO 入围问题和解决方案将在 2024 年 7 月之后发布,即 LLM 截止日期之后,可以安全地用于测试,但问题 6 除外,该问题被选为 IMO 2024,因此被排除在外。通过生成新问题并解决它们,并验证答案和证明是否正确和完整,超越解决问题的范畴。
生成新的 IMO 问题和解决方案
OpenAI Deep Research (OpenAI, 2025a) 具有先进的推理能力。但是,它可以访问互联网,包括访问现有的 IMO 解决方案,因此它不用于解决现有问题或合成用于解决现有问题的数据。但是,用 Deep Research 来生成新问题以供将来使用,除了以前的 IMO 问题之外,这些生成的问题将作为针对 2025 年 IMO 的训练数据的一部分。
IMO 人工评估
IMO 答案、它们的 Lean 形式定理和证明由具有数学奥林匹克评估经验的专家数学家评估。
总结一下本文的三个贡献:
- 多样化推理。在测试时聚合多个模型、方法和智体,而不是依赖单个模型或方法。任何单个正确解决方案都会自动验证 IMO 组合和 ARC 拼图的可验证任务。具体来说:
IMO:使用八种不同的方法(LEAP、Z3、RTO、BoN、SC、MoA、MCTS、PV)可显著提高准确性。将英语自动形式化为 Lean,从而实现完美验证。
ARC:合成代码解决方案在训练示例上作为单元测试进行验证。
HLE:使用 best-of-N 作为不完美验证器,随着样本的增加而提高解决率。 - 测试时模拟和强化学习。在推理时生成额外的问题特定信息:
IMO:将组合问题转化为交互式游戏环境,并应用组合搜索或深度强化学习来得出部分结果或界限。
ARC:通过合成代码探索谜题转换可以修剪不正确的解决方案并优化候选解决方案。
在给定相同数据集的情况下,使用经过训练的验证器进行搜索通常比监督微调效果更好(Cobbe,2021),这激发强化学习微调。在测试时运行模拟和强化学习以生成额外数据,这些数据能够正确证明 2024 年 IMO 组合问题并解决困难的 ARC 谜题。 - 智体图的元学习。用 LLM 和工具来跟踪流水线运行,生成超参、提示、代码变型和数据的 A/B 测试,并自适应地修改智体图。
相关文章:
高级推理的多样化推理与验证
25年2月来自波士顿大学、NotBadMath.AI、谷歌、哥伦比亚大学、MIT、Intuit公司和斯坦福大学的论文“Diverse Inference and Verification for Advanced Reasoning”。 OpenAI o1、o3 和 DeepSeek R1 等推理 LLM 在数学和编码方面取得重大进展,但仍发现 IMO 组合问题…...
), 2) 的函数执行过程)
深入理解 MySQL 8 C++ 源码:SELECT MOD(MONTH(NOW()), 2) 的函数执行过程
MySQL 作为最流行的关系型数据库之一,其内部实现机制一直是开发者探索的热点。本文将以一条简单的 SQL 查询 SELECT MOD(MONTH(NOW()), 2) 为例,深入分析 MySQL 8 源码中内置函数 MOD、MONTH 和 NOW 的执行过程,揭示其底层实现逻辑。 一、SQL…...

【算法系列】leetcode1419 数青蛙 --模拟
一、题目 二、思路 模拟⻘蛙的叫声。 当遇到 r o a k 这四个字符的时候,我们要去看看每⼀个字符对应的前驱字符,有没有⻘蛙叫出来。如果有⻘蛙叫出来,那就让这个⻘蛙接下来喊出来这个字符;如果没有则为异常字符串,直接…...
)
蓝桥杯 Java B 组之背包问题、最长递增子序列(LIS)
Day 4:背包问题、最长递增子序列(LIS) 📖 一、动态规划(Dynamic Programming)简介 动态规划是一种通过将复杂问题分解成更小的子问题来解决问题的算法设计思想。它主要用于解决具有最优子结构和重叠子问题…...

Git如何将一个分支的内容同步到另一个分支
在 Git 中,可以通过多种方法将一个分支的内容同步到另一个分支。以下是几种常用的方法: 1. 使用 merge 命令 这是最常见的方法,将一个分支的更改合并到另一个分支。 # 切换到目标分支 git checkout target-branch# 合并源分支的内容 git m…...

[C#]C# winform部署yolov12目标检测的onnx模型
yolov12官方框架:github.com/sunsmarterjie/yolov12 【测试环境】 vs2019 netframework4.7.2 opencvsharp4.8.0 onnxruntime1.16.3 【效果展示】 【调用代码】 using System; using System.Collections.Generic; using System.ComponentModel; using System.…...

51c大模型~合集69
我自己的原文哦~ https://blog.51cto.com/whaosoft/12221979 #7项基于SAM万物分割模型研究工作 1、CC-SAM: SAM with Cross-feature Attention and Context for Ultrasound Image Segmentation #ECCV2024 #SAM #图像分割 #医学图像 Segment Anything Model (SAM) 在自…...

2025寒假周报4
2025寒假天梯训练7-CSDN博客 眨眼间寒假训练就告一段落了,准备回校继续战斗了。这周练了3场OI赛制的篮球杯,感觉非常糟糕,不像天梯赛,天梯赛打起来非常舒适顺畅,一直都不喜欢OI赛制,打着非常不稳定..还需要…...

自学Java-AI结合GUI开发一个石头迷阵的游戏
自学Java-AI结合GUI开发一个石头迷阵的游戏 准备环节1、创建石头迷阵的界面2、打乱顺序3、控制上下左右移动4、判断是否通关5、统计移动步骤,重启游戏6、拓展问题 准备环节 技术: 1、GUI界面编程 2、二维数组 3、程序流程控制 4、面向对象编程 ∙ \bulle…...

buuctf-[极客大挑战 2019]Knife题解
一个很简单的web题,进入界面 网页名还加白给的shell,并且给的提示也很明显,给了一个一句话木马再加上菜刀,很怀疑是一个webshell题,那么直接打开蚁剑测试连接拿shell 用提示的一句话木马的密码,测试链接发现…...

Spring MVC 对象转换器:初级开发者入门指南
Spring MVC 对象转换器:初级开发者入门指南 为什么需要对象转换器? 在 Web 应用中,我们经常需要处理不同类型的对象。例如:前端数据到后端对象 :用户通过表单提交的数据通常是HttpServletRequest 对象,我们…...

语音直播交友app出海:语音直播交友系统软件源码搭建国际化发展技术层面分析
随着移动互联网的普及和全球社交需求的增长以及国内如火如荼的Ai大模型引起的全球发展热潮,语音直播软件出海成为了具有巨大发展潜力的业务领域。以下是一些关键的技术方向,将为语音直播软件在国际市场的成功推广及搭建合作奠定基础。 通信技术 实时语音…...
Web Scraper,强大的浏览器爬虫插件!
Web Scraper是一款功能丰富的浏览器扩展爬虫工具,有着直观的图形界面,无需编写代码即可自定义数据抓取规则,高效地从网页中提取结构化数据,而且它支持灵活的数据导出选项,广泛应用于电商监控、内容聚合、市场调研等多元…...

EasyRTC:基于WebRTC与P2P技术,开启智能硬件音视频交互的全新时代
在数字化浪潮的席卷下,智能硬件已成为我们日常生活的重要组成部分,从智能家居到智能穿戴,从工业物联网到远程协作,设备间的互联互通已成为不可或缺的趋势。然而,高效、低延迟且稳定的音视频交互一直是智能硬件领域亟待…...

go 定时任务 gocron timer
选型推荐(DeepSeek) 简单任务调度: 推荐使用 cron 或 gocron,它们轻量且易用。 复杂任务调度: 推荐使用 go-quartz,支持任务依赖和持久化。 分布式任务调度: 推荐使用 asynq,基于 Redis 实现,适合分布式…...

uniapp引入uview组件库(可以引用多个组件)
第一步安装 npm install uview-ui2.0.31 第二步更新uview npm update uview-ui 第三步在main.js中引入uview组件库 第四步在uni.scss中引入import "uview-ui/theme.scss"样式 第五步在文件中使用组件...

MySQL主从架构
MySQL主从架构 MySQL REPLICATION 在实际生产环境中,如果对数据库的读和写都在一个数据库服务器中操作。无论是在安全性、高可用性,还是高并发等各个方面都是完全不能满足实际需求的,因此,一般来说都是通过主从复制(…...

科普mfc100.dll丢失怎么办?有没有简单的方法修复mfc100.dll文件
当电脑频繁弹窗提示“mfc100.dll丢失”或应用程序突然闪退时,这个看似普通的系统文件已成为影响用户体验的核心痛点。作为微软基础类库(MFC)的核心组件,mfc100.dll直接关联着Visual Studio 2010开发的大量软件运行命脉。从工业设计…...
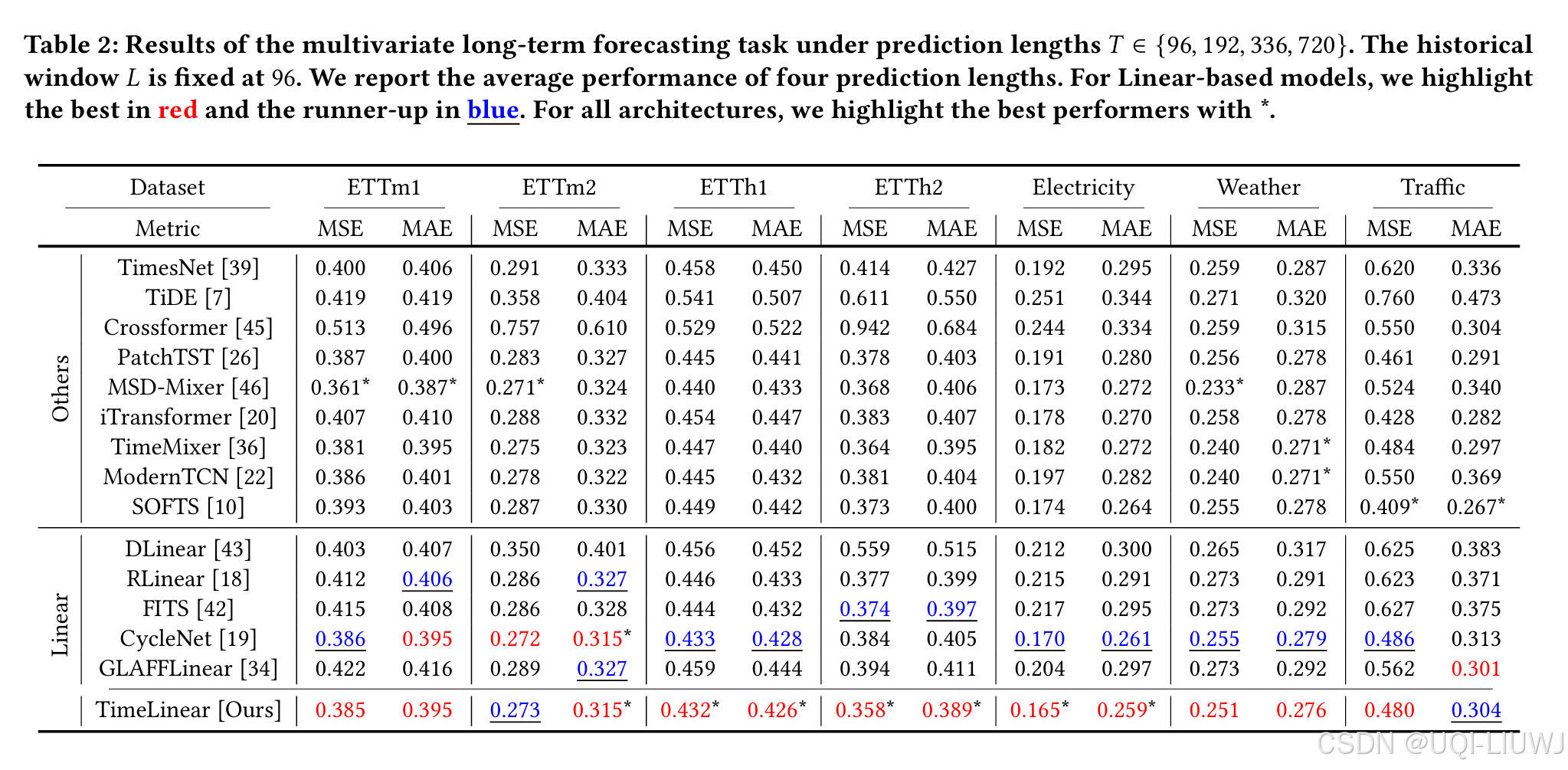
论文笔记:How Much Can Time-related Features Enhance Time Series Forecasting?
202412arxiv 许多时间序列预测方法靠变量建模,却忽略了时间戳相关特征(如季节、月份、星期几、小时、分钟等) ——>论文尝试仅基于时间戳进行预测(这个仅我觉得其实不是很严谨,还是用了时间序列变量的数据【不可能…...

Qt学习(六) 软件启动界面 ,注册表使用 ,QT绘图, 视图和窗口绘图,Graphics View绘图框架:简易CAD
一 软件启动界面 注册表使用 知识点1:这样创建的界面是不可以拖动的,需要手动创建函数来进行拖动,以下的3个函数是从父类继承过来的函数 virtual void mousePressEvent(QMouseEvent *event);virtual void mouseReleaseEvent(QMouseEvent *eve…...

win-vind开发者指南:参与开源项目的完整流程
win-vind开发者指南:参与开源项目的完整流程 【免费下载链接】win-vind You can operate Windows with key bindings like Vim. 项目地址: https://gitcode.com/gh_mirrors/wi/win-vind win-vind是一款让你能够像使用Vim一样通过按键绑定操作Windows的开源工…...

3大智能突破:重新定义百度网盘下载体验
3大智能突破:重新定义百度网盘下载体验 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾在深夜急需下载一份重要文件,却因百度网盘的限速而焦虑…...

我在项目里是怎么设计工作流表的:不是只看引擎表就够了
Activiti/Flowable 工作流实战:工作流表怎么设计?结合项目讲清主表、业务表、表单表和节点表 最近我在重新梳理这个项目里的工作流模块时,一个感觉特别强烈:真正决定系统能不能长期维护的,往往不是 Activiti/Flowable …...

【VSCode性能调优黄金法则】:基于V8引擎剖析+Electron 24内存模型的深度优化路径
更多请点击: https://intelliparadigm.com 第一章:VSCode性能调优黄金法则总览 Visual Studio Code 作为现代开发者最广泛使用的轻量级编辑器,其性能表现直接受工作区规模、插件生态与配置策略影响。当打开大型项目(如含数万行 T…...

机器学习算法迷你课程:从原理到实战
1. 机器学习算法迷你课程设计初衷三年前我在团队内部做过一次机器学习算法培训,当时用两周时间讲解了10个核心算法。后来不断有同事建议我把这个课程公开,经过多次迭代优化,最终形成了这个浓缩版的机器学习算法迷你课程。这个版本保留了最精华…...

算法训练营第十二天 | 多数元素
今日训练题:169. 多数元素 哈希表方法 代码如下: 思路: 准备一个 “计数器”:unordered_map<int, int> counts;左边记数字,右边记出现几次。 遍历数组,并实时记录出现次数,counts[num]&am…...

从‘猜错’到‘猜对’:CPU流水线是如何‘预测’你的if-else语句的?
从‘猜错’到‘猜对’:CPU流水线是如何‘预测’你的if-else语句的? 当你在键盘上敲下一行if (x > 0)时,可能不会想到这个简单的逻辑判断会让CPU陷入一场微型"决策危机"。现代处理器就像一位必须在瞬间做出选择的侦探——它必须在…...

Weka回归分析实战:从数据预处理到模型部署
1. 项目概述:Weka中的回归机器学习实战指南在数据科学领域,回归分析是预测连续型变量的经典方法。Weka作为一款开源的机器学习工作台,以其友好的图形界面和丰富的算法库,成为许多从业者快速验证模型的首选工具。不同于Python/R需要…...

别再死记硬背了!用‘移动语义’和‘完美转发’实战优化你的C++ STL vector性能
现代C性能优化实战:移动语义与完美转发在STL vector中的应用 1. 从拷贝到移动:理解C性能优化的关键转折 在传统C编程中,对象拷贝是性能损耗的主要来源之一。当我们在处理STL容器特别是vector时,这个问题尤为突出。考虑以下场景&am…...
在复杂功能实现上如何领先通义灵码)
AI编程助手实战评测:Claude3(Opus)在复杂功能实现上如何领先通义灵码
1. 复杂编程任务下的AI助手对决 最近在开发者圈子里有个热门话题:当遇到稍微复杂的编程需求时,到底该选择哪款AI编程助手?我恰好有个实际需求——用Python整合Azure语音服务开发带图形界面的应用,于是拿通义灵码和Claude3(Opus)做…...