Spring Cloud — Hystrix 服务隔离、请求缓存及合并
Hystrix 的核心是提供服务容错保护,防止任何单一依赖耗尽整个容器的全部用户线程。使用舱壁隔离模式,对资源或失败单元进行隔离,避免一个服务的失效导致整个系统垮掉(雪崩效应)。
1 Hystrix监控
Hystrix 提供了对服务请求的仪表盘监控。在客户端加入以下依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-hystrix-dashboard</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId>
</dependency>并在客户端的Application类加上@EnableHystrixDashboard注解。
访问地址:http://localhost:8080/hystrix
在输入框中输入监控地址:http://localhost:8080/hystrix.stream,然后点击“Monitor Stream”按钮。
图 Hystrix 监控初始界面

图 Hystrix 仪表盘主要参数及含义
2 服务隔离
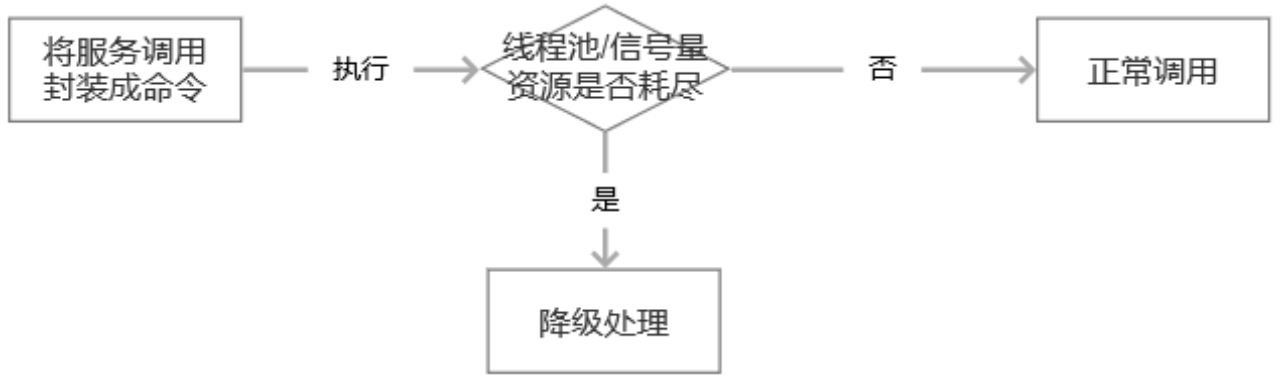
图 Hystrix 实现服务隔离的思路
2.1 隔离策略
Hystrix 提供了线程池隔离和信号量隔离两种隔离策略。
execution.isolation.strategy 属性配置隔离策略,默认为THREAD(线程池隔离),SEMAPHORE为信号量隔离。execution.isolation.thread.timeoutInMilliseconds属性配置请求超时时间,默认为1000ms。
2.1.1 线程池隔离
不同服务的执行使用不同的线程池,同时将用户请求的线程(如Tomcat)与具体业务执行的线程分开,业务执行的线程池可以控制在指定的大小范围内,从而使业务之间不受影响,达到隔离的效果。
| 优点 |
|
| 缺点 | 线程及线程池的创建及管理增加了计算开销。 |
表 线程池隔离的优缺点
关于线程池隔离的相关配置有如下参数:
coreSize:线程池核心线程数。即线程池中保持存活的最小线程数。默认为10。
maximumSize:线程池允许的最大线程数。当核心线程数已满且任务队列已满时,线程池会尝试创建新的线程,直到达到最大线程数。默认为10。
maxQueueSize:线程池任务队列的大小。默认为-1,表示任务将被直接交给工作线程处理,而不是放入队列中等待。
queueSizeRejectionThreshold:即便没达到maxQueueSize阈值,但达到该阈值时,请求也会被拒绝,默认值为5。
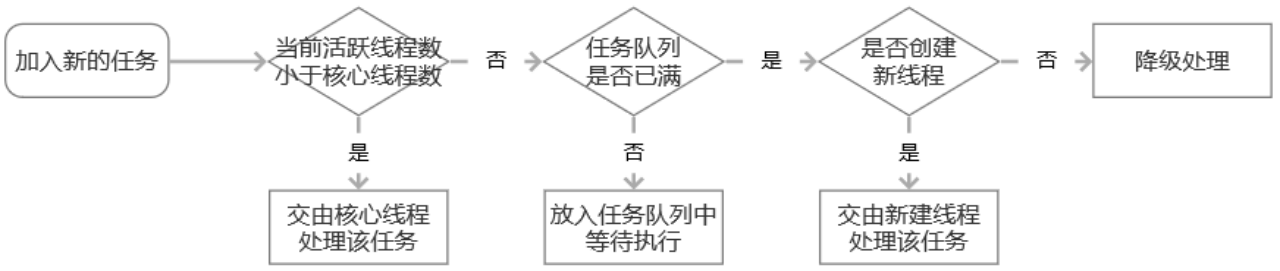
图 新的请求在线程池的处理过程
是否创建新线程,是指当前活跃线程已达到coreSize,但线程数小于maximumSize,Hystrix 会创建新的线程来处理该任务。(这一步还受到queueSizeRejectionThreshold及maxQueueSize参数的影响)。
2.1.2 信号量隔离
用户请求线程和业务执行线程是同一线程,通过设置信号量的大小限制用户请求对业务的并发访问量,从而达到限流的保护效果。
| 优点 | 1 开销小,避免了线程创建、销毁及上下文切换等开销。 2 配置简单,只需要设置信号量大小即可。 3 适合轻量级操作,如内存或缓存服务访问,这些操作不太可能导致长时间延迟,因此信号隔离可以保持系统的高效性。 |
| 缺点 | 限流能力有限,存在阻塞风险,如果依赖服务阻塞,因为其没有使用线程池来隔离请求,那么可能会影响整个请求链路,导致系统性能下降。 |
表 Hystrix 信号隔离的优缺点
execution.isolation.semaphore.maxConcurrentRequests 最大并发请求数(信号量大小)。默认为10。
2.2 服务隔离的颗粒度
@HystrixCommand 注解还有三个属性:commandKey(标识该命令全局唯一的名称,默认情况下,同一个服务名称共享一个线程池)、groupKey(组名,Hystrix 会让相同组名的命令使用同一个线程池)、threadPoolKey(线程池名称,多个服务可以设置同一个threadPoolKey,来共享同一个线程池,在信号量隔离策略中不起作用)。
3 请求缓存
在用户的同一个请求中,消费者可能会多次重复调用一个服务。Hystrix 提供的请求缓存可以在CommandKey/CommandGroup相同的情况下,直接共享第一次命令执行的结果,降低依赖调用次数。
@Service
public class UserService {private final RestTemplate restTemplate;public UserService(RestTemplate restTemplate) {this.restTemplate = restTemplate;}@CacheResult(cacheKeyMethod = "generateCacheKey")@HystrixCommand(commandKey = "info3",groupKey = "info3Group",commandProperties = {@HystrixProperty(name = "requestCache.enabled", value = "true")})public RequestResult<String> info3(String name) {System.out.println("发送请求:" + name);return RequestResult.success(restTemplate.getForObject("http://provider/user/info?name=" + name, String.class));}public String generateCacheKey(String name) {return name;}
}@RequestMapping("/home")
@RestController
public class HomeController {private final RestTemplate restTemplate;private final UserService userService;public HomeController(RestTemplate restTemplate, UserService userService) {this.restTemplate = restTemplate;this.userService = userService;}@GetMapping("/info3")public RequestResult<String> info3(String name) {HystrixRequestContext context = HystrixRequestContext.initializeContext();RequestResult<String> result = userService.info3(name);userService.info3(name);context.close();return result;}
}
4 请求合并
Hystrix针对高并发场景,支持将多个请求自动合并为一个请求,通过合并可以减少对依赖的请求,极大节省开销,提高系统效率。
请求合并主要是通过两部分实现:1)@HystrixCollapser 指定高并发请求的对应请求,其返回值为Futuer。2)@HystrixCommand 指定合并后的单个请求。其参数为第1部分请求参数的集合。
@Service
public class UserService {private final RestTemplate restTemplate;public UserService(RestTemplate restTemplate) {this.restTemplate = restTemplate;}@HystrixCollapser(collapserKey = "info",scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL,batchMethod = "batchInfo",collapserProperties = {@HystrixProperty(name = "timerDelayInMilliseconds", value = "1000"),@HystrixProperty(name = "maxRequestsInBatch", value = "3")})public Future<RequestResult<String>> batchInfo(String name) {// 不会被执行System.out.println("HystrixCollapser info");return null;}@HystrixCommandpublic List<RequestResult<String>> batchInfo(List<String> names) {System.out.println("批量发送:" + names);// 依赖也需要有一个支持批量的接口String res = restTemplate.getForObject("http://provider/user/info?name=" + names, String.class);List<RequestResult<String>> list = new ArrayList<>();int count = 0;for (String str : names) {list.add(RequestResult.success(res + "kk" + str + count++));}return list;}
}@RequestMapping("/home")
@RestController
public class HomeController {private final RestTemplate restTemplate;private final UserService userService;public HomeController(RestTemplate restTemplate, UserService userService) {this.restTemplate = restTemplate;this.userService = userService;}@GetMapping("/info2")public RequestResult<String> info2(String name) throws ExecutionException, InterruptedException {HystrixRequestContext context = HystrixRequestContext.initializeContext();Future<RequestResult<String>> future = userService.batchInfo(name);RequestResult<String> result = future.get();context.close();return result;}
}相关文章:
Spring Cloud — Hystrix 服务隔离、请求缓存及合并
Hystrix 的核心是提供服务容错保护,防止任何单一依赖耗尽整个容器的全部用户线程。使用舱壁隔离模式,对资源或失败单元进行隔离,避免一个服务的失效导致整个系统垮掉(雪崩效应)。 1 Hystrix监控 Hystrix 提供了对服务…...

Vmware虚拟机Ubantu安装Docker、k8s、kuboard
准备工作: 切换用户:su root关闭防火墙: sudo ufw diasble关闭swap: systemctl stop swap.target systemctl status swap.target systemctl disable swap.target #开机禁用 systemctl stop swap.img.swap systemctl status swap.img.swap关闭虚拟交换分区 vim /…...

PHP建立MySQL持久化连接(长连接)及mysql与mysqli扩展的区别
如果在 PHP 5.3 的版本以前想要创建MySQL的持久化连接(长连接),需要显式调用 pconnect 创建: $con mysql_pconnect($server[host], $server[username], $server[password]); if (!($con false)) { if (mysql_select_db($server[database], $con) fals…...

python爬虫系列课程2:如何下载Xpath Helper
python爬虫系列课程2:如何下载Xpath Helper 一、访问极简插件官网二、点击搜索按钮三、输入xpath并点击搜索四、点击推荐下载五、将下载下来的文件解压缩六、打开扩展程序界面七、将xpath.crx文件拖入扩展程序界面一、访问极简插件官网 极简插件官网地址:https://chrome.zzz…...

【Python项目】基于Python的Web漏洞挖掘系统
【Python项目】基于Python的Web漏洞挖掘系统 技术简介: 采用Python技术、MySQL数据库、Django框架、Scrapy爬虫等技术实现。 系统简介: Web漏洞挖掘系统是一个基于B/S架构的漏洞扫描平台,旨在通过自动化的方式对网站进行漏洞检测。系统主要功…...

多环境日志管理:使用Logback与Logstash集成实现高效日志处理
多环境日志管理:使用Logback与Logstash集成实现高效日志处理 在现代软件开发中,有效的日志管理是至关重要的。无论是调试问题、监控应用性能还是审计用户活动,良好的日志策略都能大大提高工作效率。本文将详细介绍如何配置Spring Boot项目以…...

idea连接gitee(使用idea远程兼容gitee)
文章目录 先登录你的gitee拿到你的邮箱找到idea的设置选择密码方式登录填写你的邮箱和密码登录成功 先登录你的gitee拿到你的邮箱 具体位置在gitee–>设置–>邮箱管理 找到idea的设置 选择密码方式登录 填写你的邮箱和密码 登录成功...

STM32 看门狗
目录 背景 独立看门狗(IWDG) 寄存器访问保护 窗口看门狗(WWDG) 程序 独立看门狗 设置独立看门狗程序 第一步、使能对独立看门狗寄存器的写操作 第二步、设置预分频和重装载值 第三步、喂狗 第四步、使能独立看门狗 喂狗…...

飞书API
extend目录下,API <?php // ---------------------------------------------------------------------- // | 飞书API // ---------------------------------------------------------------------- // | COPYRIGHT (C) 2021 http://www.jeoshi.com All rights reserved. …...

深入解析 Hydra 库:灵活强大的 Python 配置管理框架
深入解析 Hydra 库:灵活强大的 Python 配置管理框架 在机器学习、深度学习和复杂软件开发项目中,管理和维护大量的配置参数是一项具有挑战性的任务。传统的 argparse、json 或 yaml 方式虽然能管理部分配置,但随着项目规模的增长,…...

【开源免费】基于Vue和SpringBoot的失物招领平台(附论文)
本文项目编号 T 243 ,文末自助获取源码 \color{red}{T243,文末自助获取源码} T243,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...

科普:你的笔记本电脑中有三个IP:127.0.0.1、无线网 IP 和局域网 IP;两个域名:localhost和host.docker.internal
三个IP 你的笔记本电脑中有三个IP:127.0.0.1、无线网 IP 和局域网 IP。 在不同的场景下,需要选用不同的 IP 地址,如下为各自的特点及适用场景: 127.0.0.1(回环地址) 特点 127.0.0.1 是一个特殊的 IP 地…...

测试WSS服务器
必须有域名,证书也是强制关联这个域名,阿里云、腾讯云、百度云都可以申请免费的证书,外网对应的主机要备案到域名 备案:是针域名下的主机备案,不备案的话,会强制断网 这个网站可以测试本地WSS连接 …...

unity学习49:寻路网格链接 offMeshLinks, 以及传送门效果
目录 1 网格链接 offMeshLinks 功能入口 1.1 unity 2022之前 1.2 unity 2022之后 2 网格链接 offMeshLinks 功能设置 3 点击 offMeshLinks 功能里的bake 3.1 unity 2022之前 3.2 unity 2022之后 3.3 实测link 3.4 跳跃距离增大,可以实现轻功类的效果 4 …...

Web 开发中的 5 大跨域标签解析:如何安全地进行跨域请求与加载外部资源
在 Web 开发中,跨域(Cross-Origin)是指从一个源(协议、域名、端口)访问另一个源的资源。以下是5个常见的用于跨域操作的 HTML 标签,它们主要用于跨域请求或加载外部资源:1. <script> 标签 用途:最常用于进行跨域请求的标签,特别是在 JSONP 技术中。浏览器允许通…...

UMLS数据下载及访问
UMLS数据申请 这个直接在官网上申请即可,记得把地址填全,基本都会拿到lisence。 UMLS数据访问 UMLS的数据访问分为网页访问,API访问以及数据下载后的本地访问,网页访问,API访问按照官网的指示即可,这里主…...

23种设计模式 - 空对象模式
模式定义 空对象模式(Null Object Pattern)是一种行为型设计模式,通过用无操作的空对象替代null值,消除客户端对空值的检查,避免空指针异常。其核心是让空对象与真实对象实现相同接口,但空对象不执行实际逻…...

Redis三剑客解决方案
文章目录 缓存穿透缓存穿透的概念两种解决方案: 缓存雪崩缓存击穿 缓存穿透 缓存穿透的概念 每一次查询的 key 都不在 redis 中,数据库中也没有。 一般都是属于非法的请求,比如 id<0,比如可以在 API 入口做一些参数校验。 大量访问不存…...

大学本科教务系统设计方案,涵盖需求分析、架构设计、核心模块和技术实现要点
以下是大学本科教务系统的设计方案,涵盖需求分析、架构设计、核心模块和技术实现要点: 大学本科教务系统设计方案 一、需求分析 1. 核心用户角色 角色功能需求学生选课/退课、成绩查询、课表查看、学分统计、考试报名、学业预警教师成绩录入、课程大纲上传、教学进度管理、…...
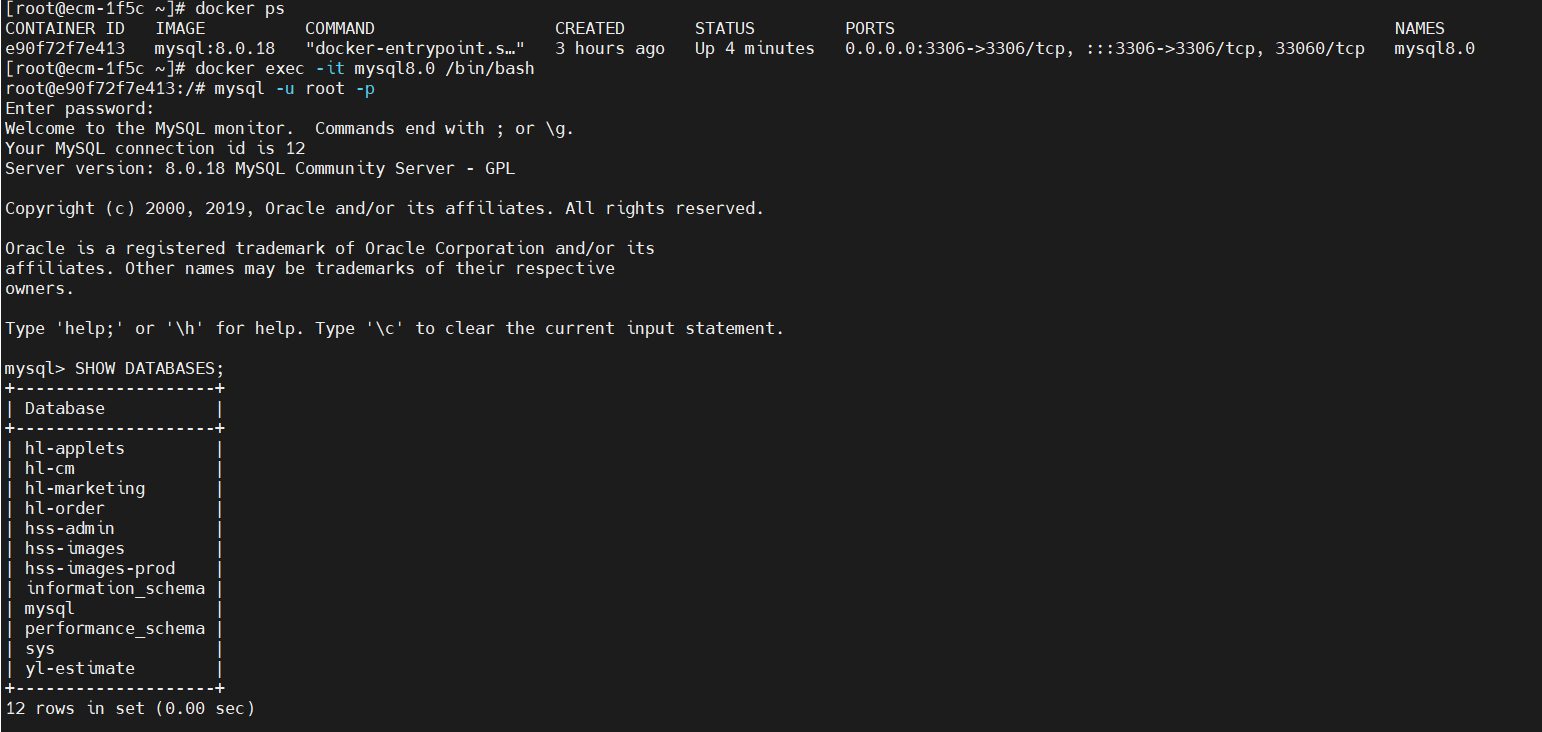
Docker Mysql 数据迁移
查看启动命令目录映射 查看容器名称 docker ps查看容器的启动命令 docker inspect mysql8.0 |grep CreateCommand -A 20如下图所示:我这边是把/var/lib/mysql 目录映射到我宿主机的/mnt/mysql/data目录下,而且我的数量比较大使用方法1的话时间比较久,所以我采用方法2 如果没…...

Windows 11任务栏拖放功能修复:如何恢复被微软移除的高效操作
Windows 11任务栏拖放功能修复:如何恢复被微软移除的高效操作 【免费下载链接】Windows11DragAndDropToTaskbarFix "Windows 11 Drag & Drop to the Taskbar (Fix)" fixes the missing "Drag & Drop to the Taskbar" support in Window…...

GEM 事件/报警系统的完整实现
——写给正在做国产半导体设备通信接口的研发工程师 系列文章目录 《SECS/GEM 协议介绍》 《HSMS(E37)通信层的正确实现方式》 《SECS-II 报文结构:工程师最容易犯的 10 个错误》 《GEM 事件/报警系统的完整实现》 《GEM300(…...

避坑指南:GD32F470的SPI FIFO与DMA刷屏时,为何屏幕会闪烁或花屏?
GD32F470 SPI DMA刷屏异常全解析:从FIFO机制到数据对齐的深度避坑指南 当你在GD32F470上实现SPI DMA刷屏时,是否遇到过屏幕闪烁、花屏或数据错位的诡异现象?这背后往往隐藏着SPI FIFO机制、DMA传输边界、数据宽度匹配等关键技术细节。本文将带…...
)
别再手动配环境了!用CMake+VS2022一键搞定PCL点云库(附完整项目模板)
现代C点云开发实战:基于CMake与VS2022的PCL高效配置指南 点云处理已成为计算机视觉、自动驾驶和三维重建领域的核心技术之一。对于C开发者而言,Point Cloud Library (PCL)提供了强大的工具集,但传统的配置方式往往令人望而生畏——手动设置包…...

广州海珠智能体案例中的“咨询+干预+随访”多智能体协作:医疗AI从“单点工具”到“执行系统”的范式转移
引言:从“工具”到“系统”的范式转移在过去的几年中,人工智能在医疗领域的应用取得了显著进展。从辅助医生识别肺结节的影像系统,到自动生成电子病历的自然语言处理工具,AI技术正逐步渗透到诊疗的各个环节。然而,这些…...

别再手动模拟时序了!深入理解STM32 FSMC如何“硬件级”简化外部SRAM访问
深入解析STM32 FSMC:硬件级SRAM访问优化实践 在嵌入式系统开发中,内存资源常常成为限制项目复杂度的瓶颈。当STM32内部SRAM不足以支撑大型应用时,外部SRAM扩展成为必选项。传统GPIO模拟时序的方法不仅代码臃肿,还存在性能瓶颈。本…...

BRDF Explorer核心功能深度解析:从Lambert到Disney BRDF的完整探索
BRDF Explorer核心功能深度解析:从Lambert到Disney BRDF的完整探索 【免费下载链接】brdf BRDF Explorer 项目地址: https://gitcode.com/gh_mirrors/br/brdf BRDF Explorer是一款功能强大的开源工具,专为探索和分析双向反射分布函数(…...

Zigbee2MQTT终极指南:轻松配置Viessmann 7963223气候传感器
Zigbee2MQTT终极指南:轻松配置Viessmann 7963223气候传感器 【免费下载链接】zigbee2mqtt Zigbee 🐝 to MQTT bridge 🌉, get rid of your proprietary Zigbee bridges 🔨 项目地址: https://gitcode.com/GitHub_Trending/zi/zi…...

量子噪声如何优化量子神经网络性能
1. 量子噪声与量子神经网络的正则化效应量子神经网络(QNN)作为量子机器学习的前沿模型,其训练过程与传统神经网络有着本质区别。在NISQ(含噪声中等规模量子)时代,量子噪声被视为阻碍QNN性能的主要因素。然而最新研究发现,特定类型的量子噪声反…...

LeCun和文心同发现:原生多模态是个偏科生
创新点 本文核心创新在于彻底摒弃基于预训练语言模型微调的范式,采用从 0 开始的统一多模态预训练方案,基于 Transfusion 框架将文本自回归预测与视觉流匹配扩散目标融合。揭示视觉与语言的缩放不对称性并给出架构解法,通过 IsoFLOP 分析发现…...