《深度学习实战》第1集:深度学习基础回顾与框架选择
本专栏系列博文旨在帮助读者从深度学习的基础知识逐步进阶到前沿技术,涵盖理论、实战和行业应用。每集聚焦一个核心知识点,并结合实际项目进行实践,避免空谈理论,简洁明快,快速切入代码,所有代码都经过验证,确保内容既深入又实用。同时,我们将探讨与当下最流行的大模型(如 GPT、BERT、Diffusion Models 等)相关的技术和知识点。
《深度学习实战》第1集:深度学习基础回顾与框架选择
引言
深度学习作为人工智能的核心技术之一,已经在计算机视觉、自然语言处理、语音识别等领域取得了突破性进展。然而,随着模型规模的不断增长,深度学习也逐渐从简单的神经网络发展到复杂的大规模模型(如 GPT、BERT 等)。在本集中,我们将回顾深度学习的基础知识,并探讨 TensorFlow 和 PyTorch 这两大主流框架的特点与适用场景。最后,通过一个实战项目——使用 TensorFlow 和 PyTorch 构建全连接神经网络解决 MNIST 手写数字分类问题,帮助你巩固理论并动手实践。

一、深度学习的基本概念
1.1 神经网络,机器学习 和 深度学习
神经网络是深度学习的核心结构,由多个层(Layer)组成,每层包含若干神经元(Neuron)。每个神经元接收输入信号,经过加权求和并通过激活函数生成输出。
神经网络结构图:
图 1: 全连接神经网络的典型结构

机器学习 和 深度学习 的简单对比:
图 2: 机器学习 Vs 深度学习

机器学习和深度学习都是人工智能领域的子领域,但它们在方法、复杂性和应用方面有所不同。以下是一个简单的对比:
机器学习 (Machine Learning, ML):
- 定义:
- 机器学习是使计算机能够从数据中学习并做出预测或决策的技术。
- 历史:
- 机器学习的发展可以追溯到20世纪50年代和60年代,但直到最近几十年才因计算能力的提升而得到广泛应用。
- 方法:
- 包括各种算法,如线性回归、逻辑回归、决策树、随机森林、支持向量机等。
- 通常需要手动提取特征(特征工程)。
- 数据需求:
- 通常需要较少的数据来训练模型。
- 计算资源:
- 相对较少的计算资源。
- 应用:
- 广泛应用于数据分析、预测建模、推荐系统等。
深度学习 (Deep Learning, DL):
- 定义:
- 深度学习是一种特殊的机器学习方法,它使用多层神经网络来模拟人脑处理信息的方式。
- 历史:
- 深度学习在21世纪初开始获得关注,特别是随着大数据和计算能力的显著提升。
- 方法:
- 主要包括深度神经网络,如卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等。
- 能够自动从数据中学习特征(端到端学习)。
- 数据需求:
- 需要大量的数据来训练模型。
- 计算资源:
- 需要高性能的计算资源,如GPU或TPU。
- 应用:
- 主要应用于图像识别、语音识别、自然语言处理、自动驾驶等领域。
对比总结:
- 复杂性:深度学习模型通常比传统机器学习模型更复杂,拥有更多的参数和层。
- 数据需求:深度学习需要更多的数据来训练,而传统机器学习算法在小数据集上可能表现更好。
- 计算资源:深度学习模型训练通常需要更强大的计算资源。
- 特征工程:深度学习减少了手动特征工程的需求,而机器学习通常需要更多的特征工程。
- 应用领域:深度学习在处理图像、视频和语音数据方面表现优异,而机器学习在处理结构化数据和一些特定任务上可能更高效。
两者都是人工智能领域中非常重要的技术,选择哪种方法取决于具体的应用场景、数据可用性和计算资源。
1.2 激活函数
激活函数为神经网络引入非线性特性,使其能够拟合复杂的函数关系。常见的激活函数包括:
- ReLU(Rectified Linear Unit):
f(x) = max(0, x),计算简单且梯度不会消失。 - Sigmoid:
f(x) = 1 / (1 + exp(-x)),适用于概率输出。 - Softmax:常用于多分类任务,将输出转化为概率分布。
1.3 损失函数
损失函数衡量模型预测值与真实值之间的差距,是优化的目标。常见损失函数包括:
- 交叉熵损失(Cross-Entropy Loss):适用于分类任务。
- 均方误差(Mean Squared Error, MSE):适用于回归任务。
1.4 优化器
优化器通过调整权重参数来最小化损失函数。常用优化器包括:
- SGD(随机梯度下降):简单但收敛速度慢。
- Adam:结合动量和自适应学习率,适合大多数场景。
二、常见深度学习框架对比:TensorFlow vs PyTorch

2.1 TensorFlow
- 优点:
- 成熟稳定,支持大规模分布式训练。
- 提供强大的可视化工具 TensorBoard。
- 部署友好,支持多种硬件加速(如 TPU)。
- 缺点:
- API 设计较为复杂,初学者上手难度较高。
2.2 PyTorch
- 优点:
- 动态计算图设计,灵活性高,适合研究和快速原型开发。
- 社区活跃,文档丰富。
- 缺点:
- 在生产环境中的部署支持相对较弱(可通过 TorchServe 改善)。
对比总结:
| 特性 | TensorFlow | PyTorch |
|---|---|---|
| 易用性 | 中等 | 高 |
| 灵活性 | 静态图 | 动态图 |
| 分布式训练 | 强 | 中等 |
| 生产部署 | 强 | 中等 |
三、GPU 加速与分布式训练简介
3.1 GPU 加速
GPU(图形处理器)因其并行计算能力,成为深度学习训练的核心硬件。相比于 CPU,GPU 可以显著加速矩阵运算,从而缩短训练时间。
GPU 加速示意图:
图 2: GPU 并行计算加速深度学习训练
3.2 分布式训练
对于超大规模模型(如 GPT-3),单个 GPU 的显存可能不足。分布式训练通过将模型或数据分布在多个设备上,解决了这一问题。常见方法包括:
- 数据并行(Data Parallelism):将数据分片到不同设备。
- 模型并行(Model Parallelism):将模型分片到不同设备。
四、实战项目:MNIST 手写数字分类
我们将分别使用 TensorFlow 和 PyTorch 构建全连接神经网络,解决 MNIST 数据集的手写数字分类问题。
4.1 数据集介绍
MNIST 数据集包含 60,000 张训练图像和 10,000 张测试图像,每张图像为 28x28 像素的灰度图片,标签为 0-9 的数字。
MNIST 数据集样例:
图 3: MNIST 数据集中的手写数字样例
4.2 使用 TensorFlow 实现
import tensorflow as tf
from tensorflow.keras import layers, models# 加载数据
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 # 归一化# 构建模型
model = models.Sequential([layers.Flatten(input_shape=(28, 28)),layers.Dense(128, activation='relu'),layers.Dropout(0.2),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"Test Accuracy: {test_acc:.4f}")
程序运行后输出:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11490434/11490434 ━━━━━━━━━━━━━━━━━━━━ 26s 2us/step
Epoch 1/5
D:\python_projects\jupyter_demo\lib\site-packages\keras\src\layers\reshaping\flatten.py:37: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.super().__init__(**kwargs)
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 3s 1ms/step - accuracy: 0.8592 - loss: 0.4790
Epoch 2/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 3s 1ms/step - accuracy: 0.9560 - loss: 0.1525
Epoch 3/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 3s 1ms/step - accuracy: 0.9662 - loss: 0.1094
Epoch 4/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 3s 1ms/step - accuracy: 0.9739 - loss: 0.0841
Epoch 5/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 3s 1ms/step - accuracy: 0.9778 - loss: 0.0728
313/313 ━━━━━━━━━━━━━━━━━━━━ 0s 958us/step - accuracy: 0.9760 - loss: 0.0788
Test Accuracy: 0.9797
可以看到一共五个批次的模型训练,模型精确度为97.97%
4.3 使用 PyTorch 实现
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms# 数据预处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)# 定义模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(28 * 28, 128)self.relu = nn.ReLU()self.dropout = nn.Dropout(0.2)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = x.view(-1, 28 * 28)x = self.relu(self.fc1(x))x = self.dropout(x)x = self.fc2(x)return xmodel = Net()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())# 训练模型
for epoch in range(5):for images, labels in train_loader:optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 测试模型
correct = 0
total = 0
with torch.no_grad():for images, labels in test_loader:outputs = model(images)_, predicted = torch.max(outputs, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f"Test Accuracy: {correct / total:.4f}")
程序运行后输出:
100.0%
100.0%
100.0%
100.0%
Test Accuracy: 0.9500
可以看到模型精确度为95%,相对TensorFlow低一些。
4.4 基于项目实践的 TensorFlow vs PyTorch 进一步对比分析
本项目对比分析
- 代码结构:
- TensorFlow:使用Keras API,代码结构清晰,层次分明,适合快速搭建模型。
- PyTorch:需要手动定义模型类和前向传播函数,代码更灵活,但稍微复杂一些。
- 在本项目中,可以看到 TensorFlow 的代码非常精简,模型训练速度也很快,PyTorch 代码是 TensorFlow 的两倍,训练速度也相对较慢。
-
训练过程:
- TensorFlow:
model.fit()方法封装了训练循环,使用起来非常方便。 - PyTorch:需要手动编写训练循环,灵活性更高,但需要更多的代码。
- TensorFlow:
-
调试:
- TensorFlow:由于静态图的存在,调试相对困难,但Eager Execution模式改善了这一点。
- PyTorch:动态图使得调试更加直观,可以直接打印张量的值。
-
部署:
- TensorFlow:更适合生产环境,支持多种部署方式。
- PyTorch:虽然也有部署工具,但相对来说不如TensorFlow成熟。
相同点
- 深度学习支持:两者都支持构建和训练深度神经网络,包括卷积神经网络(CNN)、循环神经网络(RNN)等。
- 自动微分:两者都提供了自动微分功能,可以自动计算梯度,简化了模型的训练过程。
- GPU加速:两者都支持使用GPU进行加速,提高模型训练和推理的速度。
- 社区和资源:两者都有庞大的社区支持和丰富的文档、教程资源。
不同点
-
编程风格:
- TensorFlow:早期版本采用静态计算图,需要先定义计算图再执行。虽然从2.0版本开始引入了Eager Execution模式,但默认仍然是基于计算图的。
- PyTorch:采用动态计算图(也称为“define-by-run”),代码更加直观,调试更容易。
-
易用性:
- TensorFlow:API较为复杂,初学者可能需要更多时间来熟悉。不过,Keras作为其高级API,大大简化了模型构建过程。
- PyTorch:API设计更接近Python原生,代码简洁易读,适合快速原型开发。
-
部署:
- TensorFlow:在生产环境中的部署更为成熟,尤其是通过TensorFlow Serving和TensorFlow Lite,可以方便地将模型部署到服务器或移动设备上。
- PyTorch:虽然也有TorchServe等工具,但在生产部署方面相对不如TensorFlow成熟。
-
生态系统:
- TensorFlow:拥有更广泛的生态系统,包括TensorBoard(可视化工具)、TFX(端到端机器学习平台)等。
- PyTorch:生态系统也在快速发展,特别是在研究领域,许多最新的研究成果都是基于PyTorch实现的。
优势和专长
-
TensorFlow:
- 优势:强大的生产部署能力、丰富的生态系统、大规模分布式训练支持。
- 专长:适用于企业级应用、大规模生产环境、跨平台部署。
-
PyTorch:
- 优势:灵活的动态计算图、易于调试、简洁的API。
- 专长:适合研究和实验、快速原型开发、学术界广泛使用。

为了更直观地对比 TensorFlow 和 PyTorch 在 MNIST 手写数字分类任务中的表现,我们整理了以下表格:
| 对比维度 | TensorFlow | PyTorch | 优劣分析 |
|---|---|---|---|
| 代码简洁性 | TensorFlow 的 Keras API 提供了高层次封装,代码简洁易读。 | PyTorch 的动态计算图设计使得代码更加灵活,但需要手动定义训练循环。 | TensorFlow 更适合快速构建模型,而 PyTorch 更适合研究和调试复杂的模型。 |
| 灵活性 | 静态图设计,灵活性较低,适合生产环境。 | 动态图设计,灵活性高,适合研究和实验。 | PyTorch 的灵活性更高,但在生产环境中可能需要额外的工作来优化性能。 |
| 性能 | TensorFlow 在大规模分布式训练中表现优异,尤其是在 TPU 上。 | PyTorch 的性能与 TensorFlow 相当,但在某些场景下可能稍逊于 TensorFlow。 | TensorFlow 在生产环境中的性能优势明显,尤其是需要分布式训练时。 |
| 社区与生态 | TensorFlow 社区庞大,生态系统完善,支持多种硬件加速和部署工具。 | PyTorch 社区活跃,文档丰富,适合学术研究。 | TensorFlow 的生态更适合工业应用,而 PyTorch 更受研究人员欢迎。 |
| 可视化工具 | 提供强大的 TensorBoard 工具,方便监控训练过程和模型性能。 | 可视化工具较少,通常需要第三方库(如 TensorBoardX)。 | TensorFlow 在可视化方面具有明显优势。 |
| 部署支持 | 支持多种部署方式(如 TensorFlow Serving、TensorRT),适合生产环境。 | 部署支持较弱,但可以通过 TorchServe 或 ONNX 改善。 | TensorFlow 在生产环境中的部署支持更为成熟。 |
五、前沿关联:为什么需要更深、更复杂的网络?
随着任务复杂度的增加,浅层网络往往无法捕捉数据中的高层次特征。例如:
- 计算机视觉:ResNet 通过残差连接解决了深层网络的梯度消失问题。
- 自然语言处理:Transformer 通过自注意力机制实现了对长距离依赖的建模。
- 大模型:GPT-3 等超大规模模型通过海量参数和数据,展现出惊人的泛化能力。
大模型的优势:
- 更强的表达能力:能够学习更复杂的模式。
- 迁移学习:通过预训练,在小样本任务中表现出色。
大模型的挑战:
- 计算资源需求高:需要大量 GPU/TPU 和存储空间。
- 训练成本高昂:一次完整训练可能耗费数百万美元。
总结
本集回顾了深度学习的基础知识,包括神经网络、激活函数、损失函数和优化器,并对比了 TensorFlow 和 PyTorch 的特点。通过 MNIST 手写数字分类的实战项目,我们展示了如何使用这两种框架构建简单的全连接神经网络,并通过表格对比了它们的优劣。最后,我们探讨了大模型的背景及其在深度学习领域的重要性。
希望这篇文章能为你提供清晰的学习路径!如果你有任何问题或想法,欢迎在评论区留言讨论。
下集预告:第2集将聚焦于卷积神经网络(CNN)与图像分类任务,带你深入了解 CNN 的核心原理及其在计算机视觉中的应用。
相关文章:
《深度学习实战》第1集:深度学习基础回顾与框架选择
本专栏系列博文旨在帮助读者从深度学习的基础知识逐步进阶到前沿技术,涵盖理论、实战和行业应用。每集聚焦一个核心知识点,并结合实际项目进行实践,避免空谈理论,简洁明快,快速切入代码,所有代码都经过验证…...

Docker 部署AnythingLLM
两个指令搞定 1.下载镜像 docker pull mintplexlabs/anythingllm 2.运行容器 export STORAGE_LOCATION$HOME/anythingllm mkdir -p $STORAGE_LOCATION chmod -R 777 $STORAGE_LOCATION touch "$STORAGE_LOCATION/.env" docker run -d -p 3001:3001 \ --cap-add SY…...

泰山派RK3566移植QT,动鼠标时出现屏幕闪烁
总结: 交叉编译到 泰山派rk3566跑调海康摄像头的qt应用程序失败了。 X11无效窗口。 移植QT注意 屏幕分辨率不要改。改了执行QT的时候,framebuffer识别不出设备。 命令行安装QT-Creator sudo install 类似的指令安装Qt-Creator时,可能找不到编…...

关于Java 反射的简单易懂的介绍
目录 #0.总览 #1. 类的反射 ①介绍 ②获取 ③作用 获取构造函数: 创建实例: 字段操作: 方法操作: 获取修饰符: #2.总结 #0.总览 反射,官方是这样介绍它的: Reflection is a …...

市场趋势中突破确认的多维度判断方法
波动率突破策略是众多交易者广泛采用的重要交易策略之一。而在这一策略中,准确判断突破是否有效,是决定交易成败的关键环节。仅仅依据单一因素来确认突破,往往会使交易者陷入误判的困境,导致不必要的损失。因此,采用多…...

网络空间安全(2)应用程序安全
前言 应用程序安全(Application Security,简称AppSec)是一个综合性的概念,它涵盖了应用程序从开发到部署,再到后续维护的整个过程中的安全措施。 一、定义与重要性 定义:应用程序安全是指识别和修复应用程序…...
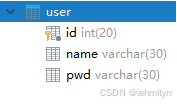
【MyBatis】CRUD、配置解析、ResultMap、分页实现
目录标题 1、Mybatis简介1.1、什么是MyBatis1.2、持久化1.3、持久层1.4、为什么需要MybatisMyBatis的优点 2.1、代码演示搭建实验数据库导入MyBatis相关 jar 包 03、CRUD操作3.1、namespace3.2、select3.3、insert3.4、update3.5、delete 04、MyBatis配置解析4、配置解析4.3、m…...

Linux系统编程之高级信号处理
概述 在前一篇文章中,我们介绍了signal函数、sigaction函数等基本的信号处理方法。在本篇中,我们将介绍信号处理的一些高级用法,包括:阻塞与解除阻塞、定时器等。 阻塞与解除阻塞 有时候,我们不希望某个信号立即被处理…...

深度学习驱动的车牌识别:技术演进与未来挑战
一、引言 1.1 研究背景 在当今社会,智能交通系统的发展日益重要,而车牌识别作为其关键组成部分,发挥着至关重要的作用。车牌识别技术广泛应用于交通管理、停车场管理、安防监控等领域。在交通管理中,它可以用于车辆识别、交通违…...

钉钉快捷免登录 通过浏览器打开第三方系统,
一、钉钉内跳转至浏览器的实现 使用钉钉JSAPI的跳转接口 在钉钉内通过dd.biz.navigation.openLink方法强制在系统浏览器中打开链接。此方法需在钉钉开发者后台配置应用权限,确保应用具备调用该API的资格37。 示例代码: dd.ready(() > {dd.biz.navigat…...

力扣——杨辉三角
题目链接: 链接 题目描述: 思路: 直接找规律,按照数学的思路来 每一行的列最大索引 < 行索引 实现代码: class Solution {public List<List<Integer>> generate(int numRows) {List<List<In…...

stm32108键C-B全调性_动态可视化乐谱钢琴
108键全调性钢琴 一 基本介绍1 项目简介2 实现方式3 项目构成 二 实现过程0 前置基本外设驱动1 声音控制2 乐谱录入&基础乐理3 点阵屏谱点动态刷新4 项目交互控制5 录入新曲子过程 三 展示,与链接视频地址1 主要功能函数一览2 下载链接3 视频效果 一 基本介绍 …...

mysql之规则优化器RBO
文章目录 MySQL 基于规则的优化 (RBO):RBO 的核心思想:模式匹配与规则应用RBO 的主要优化规则查询重写 (Query Rewrite) / 查询转换 (Query Transformation)子查询优化 (Subquery Optimization) - RBO 的重中之重非相关子查询 (Non-Correlated Subquery)…...

MySQL数据库——表的约束
1.空属性(null/not null) 两个值:null(默认的)和not null(不为空) 数据库默认字段基本都是字段为空,但是实际开发时,尽可能保证字段不为空,因为数据为空没办法…...

vue2.x 中子组件向父组件传递数据主要通过 $emit 方法触发自定义事件方式实现
在 Vue 2.x 中,子组件向父组件传递数据主要通过 自定义事件 的方式实现。具体步骤如下: 1. 子组件通过 $emit 触发事件 子组件可以使用 $emit 方法触发一个自定义事件,并将数据作为参数传递给父组件。 语法: this.$emit(事件名…...

洛谷 P1102 A-B 数对(详解)c++
题目链接:P1102 A-B 数对 - 洛谷 1.题目分析 2.算法原理 解法一:暴力 - 两层for循环 因为这道题需要你在数组中找出来两个数,让这两个数的差等于定值C就可以了,一层for循环枚举A第二层for循环枚举B,求一下看是否等于…...

python用 PythonNet 从 Python 调用 WPF 类库 UI 用XAML
pythonnet 是pythonhe.net通用的神器不多介绍了. 这次这基本上跟python没有关系了. 和winform一样先导包 import clr clr.AddReference("PresentationFramework.Classic, Version3.0.0.0, Cultureneutral, PublicKeyToken31bf3856ad364e35") clr.AddReference(&…...

C++——list模拟实现
目录 前言 一、list的结构 二、默认成员函数 构造函数 析构函数 clear 拷贝构造 赋值重载 swap 三、容量相关 empty size 四、数据访问 front/back 五、普通迭代器 begin/end 六、const迭代器 begin/end 七、插入数据 insert push_back push_front 八、…...

YOLOv11-ultralytics-8.3.67部分代码阅读笔记-utils.py
utils.py ultralytics\data\utils.py 目录 utils.py 1.所需的库和模块 2.def img2label_paths(img_paths): 3.def get_hash(paths): 4.def exif_size(img: Image.Image): 5.def verify_image(args): 6.def verify_image_label(args): 7.def visualize_image_ann…...

Linux 内核 RDMA CM 模块分析:drivers/infiniband/core/cma.c
一、引言 随着高性能计算和大数据处理需求的不断增长,远程直接内存访问(RDMA)技术在数据中心和高性能计算领域得到了广泛应用。RDMA 允许数据直接在不同系统的内存之间传输,而无需经过 CPU 和操作系统的干预,从而显著提高了数据传输效率和系统性能。Linux 内核中的 RDMA …...

萤石2026新品发布会:AI驱动创新,以安全科技共创美好生活
萤石举办2026品牌新品发布会,展现AI创新成果4月21日,全球领先的安全智能生活品牌萤石在杭州正式举办2026品牌新品发布会。这场以“驭智向前”(Ahead with Intelligence)为主题的盛会,全景式展现了AI驱动下的创新成果&a…...
)
用逻辑分析仪抓波形,手把手教你调试AT24C08的I2C读写时序(附代码避坑点)
用逻辑分析仪精准调试AT24C08的I2C通信:从波形捕获到代码优化的完整指南 当你在深夜调试一块无法正常读写的AT24C08 EEPROM芯片时,是否曾盯着示波器上那些跳动的波形感到无从下手?I2C通信作为嵌入式开发中最常见的协议之一,其看似…...

Mermaid Live Editor:让图表创作像聊天一样简单
Mermaid Live Editor:让图表创作像聊天一样简单 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-editor …...

三月七小助手:5步配置《崩坏:星穹铁道》自动化工具的完整指南
三月七小助手:5步配置《崩坏:星穹铁道》自动化工具的完整指南 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 厌倦了《崩坏:星穹铁…...

Geth实战:从零到一部署并交互一个HelloWorld智能合约
1. 环境准备与Geth安装 在开始部署智能合约之前,我们需要先搭建好开发环境。Geth是以太坊官方提供的Go语言实现客户端,它允许我们运行私有链进行开发和测试。我推荐使用Ubuntu 20.04作为开发环境,因为这个系统对开发者非常友好,而…...

CoolProp开源热力学计算库:工程师必备的120+流体物性数据解决方案
CoolProp开源热力学计算库:工程师必备的120流体物性数据解决方案 【免费下载链接】CoolProp Thermophysical properties for the masses 项目地址: https://gitcode.com/gh_mirrors/co/CoolProp 在现代工程设计和科学研究中,热力学物性数据的准确…...

LOL云顶之弈自动化脚本:3步搭建你的智能刷经验助手
LOL云顶之弈自动化脚本:3步搭建你的智能刷经验助手 【免费下载链接】LOL-Yun-Ding-Zhi-Yi 英雄联盟 云顶之弈 全自动挂机刷经验程序 外挂 脚本 ,下载慢可以到https://gitee.com/stringify/LOL-Yun-Ding-Zhi-Yi 项目地址: https://gitcode.com/gh_mirrors/lo/LOL-Y…...
告别ViT的‘算力焦虑’:手把手带你用Swin Transformer搞定图像分类(附PyTorch实战代码)
突破视觉Transformer算力瓶颈:Swin Transformer实战图像分类指南 在计算机视觉领域,Transformer架构正掀起一场革命。但当我们兴奋地将Vision Transformer(ViT)应用到实际项目中时,往往会遇到一个残酷的现实——显存爆…...
)
CLion高效编码:一键生成带参数说明的函数注释(实时模板+Doxygen实战)
CLion高效编码:一键生成带参数说明的函数注释(实时模板Doxygen实战) 在C/C开发中,规范的函数注释不仅是团队协作的基石,更是代码可维护性的关键。但手动编写包含参数说明、返回值描述的注释块,往往让开发者…...

VMware Unlocker:逆向工程视角下的macOS虚拟化突破
VMware Unlocker:逆向工程视角下的macOS虚拟化突破 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 通过二进制补丁技术绕过VMware对macOS的系统级限制,为开发者和安全研究人员提…...