论文笔记(七十二)Reward Centering(四)
Reward Centering(四)
- 文章概括
- 摘要
- 附录
- A 伪代码
文章概括
引用:
@article{naik2024reward,title={Reward Centering},author={Naik, Abhishek and Wan, Yi and Tomar, Manan and Sutton, Richard S},journal={arXiv preprint arXiv:2405.09999},year={2024}
}
Naik, A., Wan, Y., Tomar, M. and Sutton, R.S., 2024. Reward Centering. arXiv preprint arXiv:2405.09999.
原文: https://arxiv.org/abs/2405.09999
代码、数据和视频:
系列文章:
请在 《 《 《文章 》 》 》 专栏中查找
论文笔记(七十二)Reward Centering(一)
论文笔记(七十二)Reward Centering(二)
论文笔记(七十二)Reward Centering(三)
论文笔记(七十二)Reward Centering(四)
论文笔记(七十二)Reward Centering(五)
摘要
我们证明,在解决持续强化学习问题时,折扣方法如果通过减去奖励的经验均值来对奖励进行中心化处理,其性能会显著提升。在常用的折扣因子下,这种改进是显著的,并且随着折扣因子趋近于1,改进幅度进一步增加。此外,我们证明,如果一个问题的奖励被加上一个常数偏移量,则标准方法的表现会变得更差,而采用奖励中心化的方法则不受影响。在on-policy设置下,估计平均奖励是直接的;对于off-policy设置,我们提出了一种稍微更复杂的方法。奖励中心化是一个通用的概念,因此我们预计几乎所有的强化学习算法都能从奖励中心化的加入中受益。
附录
A 伪代码
在本节中,我们将介绍在 Q-learning 的表格、线性和非线性变体中添加基于值的奖励中心的伪代码。

这段伪代码实现了一个“表格型(Tabular)Q-learning”算法,区别在于它使用了基于值的奖励中心化(value-based reward centering)。也就是说:
- 它仍然是Q-learning:用一个Q表来存储每个状态-动作对 ( s , a ) (s,a) (s,a) 的价值估计 Q ( s , a ) Q(s,a) Q(s,a)。
- 奖励中心化:在计算时序差分(TD)误差时,使用 ( R − R ˉ ) (R - \bar{R}) (R−Rˉ) 代替原始奖励 R R R,并且同时更新一个平均奖励估计 R ˉ \bar{R} Rˉ。
这么做的原因在于:如果奖励有一个大常数偏移,或者折扣因子 γ \gamma γ 很接近 1,那么原始 Q-learning 会出现数值范围很大的问题;通过减去一个平均奖励 R ˉ \bar{R} Rˉ,可以让学习更稳定、更快速。
行0:输入与算法参数
Input: The behavior policy b (e.g. ε-greedy)
Algorithm parameters: discount factor γ, step-size parameters α, η
- 行为策略 b b b:这是智能体在训练中实际用来选动作的策略。例如,最常见的是 ϵ \epsilon ϵ-greedy——以概率 1 − ϵ 1-\epsilon 1−ϵ 选当前Q值最高的动作,以概率 ϵ \epsilon ϵ 随机选动作。
- 折扣因子 γ \gamma γ:决定未来奖励的重要性, γ ∈ [ 0 , 1 ) \gamma \in [0,1) γ∈[0,1)。数值越接近1,越重视长期回报;越小则越关注近期。
- 步长参数 α , η \alpha, \eta α,η: α \alpha α 多用于网络参数更新(学习率), η \eta η 用于调节平均奖励 R ˉ \bar{R} Rˉ 的更新幅度。
行1:初始化
Initialize Q(s, a) ∀s, R̄ arbitrarily (e.g., to zero)
- 我们为所有状态-动作对 ( s , a ) (s,a) (s,a) 初始化一个Q表,记为 Q ( s , a ) Q(s,a) Q(s,a)。在表格型设置下,这通常是一个二维数组,也可以用字典等结构实现。
- 初始化平均奖励 R ˉ \bar{R} Rˉ 为0或任意值。
行2:获得初始状态
Obtain initial S
- 与环境交互时,智能体先观察到一个起始状态 S S S。在仿真或某些任务中,这可能是随机选的或由环境指定。
行3, 4:主循环
for all time steps doTake action A according to b, observe R, S'
- 在每个时间步 t t t:
- 根据行为策略 b b b 从状态 S S S 选动作 A A A。
- 环境返回即时奖励 R R R 并转移到新状态 S ′ S' S′。
- 这是标准 Q-learning 过程:智能体在环境中执行动作并收集数据。
行5:计算时序差分误差 δ δ δ
δ = R - R̄ + γ max_a Q(S', a) - Q(S, A)
这是本算法的核心:
- R − R ˉ R - \bar{R} R−Rˉ:把原始奖励 R R R 减去当前的平均奖励估计 R ˉ \bar{R} Rˉ,得到“中心化奖励”。
- γ max a Q ( S ′ , a ) \gamma \max_{a} Q(S', a) γmaxaQ(S′,a):与标准Q-learning一样,估计下一状态 S ′ S' S′ 的最大Q值作为未来回报。
- − Q ( S , A ) - Q(S,A) −Q(S,A):我们要看“(中心化奖励 + 折扣后的最大下一步价值)与当前Q值估计”的差距,这就是TD误差 δ \delta δ。
在标准Q-learning里, δ = R + γ max a Q ( S ′ , a ) − Q ( S , A ) \delta = R + \gamma \max_{a} Q(S',a) - Q(S,A) δ=R+γmaxaQ(S′,a)−Q(S,A)。这里则变成 R − R ˉ R - \bar{R} R−Rˉ,多了个 − R ˉ -\bar{R} −Rˉ 的中心化操作。
行6:更新Q表
Q(S, A) = Q(S, A) + α δ
- 这是最基本的Q-learning更新:用TD误差 δ \delta δ 调整当前Q值,步长由 α \alpha α 决定。
- 由于 δ \delta δ 包含了 ( R − R ˉ ) (R - \bar{R}) (R−Rˉ),我们实际上是学习一个“相对于平均奖励”的Q值。
行7:更新平均奖励
R̄ = R̄ + η α δ
- 这是与标准Q-learning不同之处:我们同时更新平均奖励 R ˉ \bar{R} Rˉ,使其也跟随TD误差进行调整。
- 其中 η \eta η 是一个系数(伪代码里写的可能是“ η η η”,也可能用其他符号),用来控制更新速度;有时可与 α \alpha α 合并成一个“effective step-size”。
- 直观理解:如果 δ \delta δ 是正的,说明“实际的中心化奖励 + 未来回报”比我们预期的要好,于是我们适度提高 R ˉ \bar{R} Rˉ;若 δ \delta δ 为负,则降低 R ˉ \bar{R} Rˉ。
- 这样, R ˉ \bar{R} Rˉ 会逐渐收敛到一个与目标策略相关的平均奖励(若行为策略足够探索、步长合适等条件满足)。
行8:转移到新状态
S = S'
- 这一行将当前状态更新为下一个状态,为下个时间步的循环做准备。
行9:循环结束
end
- 该算法持续进行,直到满足某个停止条件(如到达最大步数或收敛)。
简单数值例子
假设我们有一个小小的任务:
- 状态空间只有2个状态: S 1 S_1 S1, S 2 S_2 S2;动作空间只有2个动作: A 1 A_1 A1, A 2 A_2 A2。
- 假设某个回合中:
- 当前状态 S = S 1 S = S_1 S=S1,动作 A = A 1 A = A_1 A=A1,获得即时奖励 R = 10 R = 10 R=10,下一状态 S ′ = S 2 S' = S_2 S′=S2。
- 当前估计的平均奖励 R ˉ = 8 \bar{R} = 8 Rˉ=8。
- γ = 0.9 \gamma = 0.9 γ=0.9,且我们查表发现 max a Q ( S 2 , a ) = 20 \max_a Q(S_2, a) = 20 maxaQ(S2,a)=20,而当前 Q ( S 1 , A 1 ) = 15 Q(S_1, A_1) = 15 Q(S1,A1)=15。
- 学习率 α = 0.1 \alpha = 0.1 α=0.1, η = 0.5 \eta = 0.5 η=0.5(示例取值)。
第5行:计算TD误差
δ = ( R − R ˉ ) + γ max a Q ( S 2 , a ) − Q ( S 1 , A 1 ) = ( 10 − 8 ) + 0.9 × 20 − 15 = 2 + 18 − 15 = 5. \delta = (R - \bar{R}) + \gamma \max_a Q(S_2,a) - Q(S_1,A_1) = (10 - 8) + 0.9 \times 20 - 15 = 2 + 18 - 15 = 5. δ=(R−Rˉ)+γamaxQ(S2,a)−Q(S1,A1)=(10−8)+0.9×20−15=2+18−15=5.
第6行:更新Q表
Q ( S 1 , A 1 ) ← 15 + 0.1 × 5 = 15.5. Q(S_1, A_1) \leftarrow 15 + 0.1 \times 5 = 15.5. Q(S1,A1)←15+0.1×5=15.5.
第7行:更新平均奖励
R ˉ ← 8 + 0.5 × 0.1 × 5 = 8 + 0.25 = 8.25. \bar{R} \leftarrow 8 + 0.5 \times 0.1 \times 5 = 8 + 0.25 = 8.25. Rˉ←8+0.5×0.1×5=8+0.25=8.25.
解释:
- 因为 δ = 5 \delta = 5 δ=5 为正数,表示实际获得的“中心化奖励 + 折扣未来回报”比我们先前估计的还要好,于是我们适度提高 Q ( S 1 , A 1 ) Q(S_1, A_1) Q(S1,A1) 并且也提高了平均奖励估计 R ˉ \bar{R} Rˉ(从8增加到8.25)。
- 这样,如果下次再拿到类似奖励,中心化奖励 R − R ˉ R - \bar{R} R−Rˉ 就会变小(10 - 8.25 = 1.75),防止Q值无限增大。

本算法是一个“线性Q-learning”的版本,与传统Q-learning相比,主要有两个特点:
-
线性函数逼近:
- 采用线性模型来近似 Q 值函数,即对每个动作 a a a 都维护一个参数向量 w a ∈ R d \mathbf{w}_a \in \mathbb{R}^d wa∈Rd,并将状态(或观测)转换为一个特征向量 x ∈ R d \mathbf{x} \in \mathbb{R}^d x∈Rd。
- 动作值估计为 q ^ ( x , a ) = w a ⊤ x \hat{q}(\mathbf{x}, a) = \mathbf{w}_a^\top \mathbf{x} q^(x,a)=wa⊤x。
-
基于值的奖励中心化(value-based reward centering):
- 在计算时序差分(TD)误差时,使用 ( R − R ˉ ) \bigl(R - \bar{R}\bigr) (R−Rˉ) 代替原始奖励 R R R,其中 R ˉ \bar{R} Rˉ 是一个在线估计的平均奖励。
- 同时,利用同一个 TD 误差更新平均奖励 R ˉ \bar{R} Rˉ 本身。
通过这种“奖励中心化”,我们可以去除奖励中可能存在的常数偏移,在高折扣因子或大常数奖励的情况下让学习更稳定、更有效。
行0:输入与算法参数
Input: The behavior policy b (e.g., ε-greedy)
Algorithm parameters: discount factor γ, step-size parameters α, η
- 行为策略 b b b:在训练过程中用于实际选动作的策略,例如 ϵ \epsilon ϵ-greedy。
- 折扣因子 γ \gamma γ:权衡当前奖励和未来奖励的重要程度, γ ∈ [ 0 , 1 ) \gamma \in [0,1) γ∈[0,1)。
- 步长参数 α \alpha α 和 η \eta η: α \alpha α 多用于网络参数更新(学习率), η \eta η 用于调节平均奖励 R ˉ \bar{R} Rˉ 的更新幅度。
行1:初始化
Initialize wₐ ∈ ℝ^d ∀a, R̄ arbitrarily (e.g., to zero)
- 对每个动作 a a a,都初始化一个权重向量 w a ∈ R d \mathbf{w}_a \in \mathbb{R}^d wa∈Rd。通常初始化为0向量或小随机值。
- 初始化平均奖励 R ˉ \bar{R} Rˉ 为0或任意值。
行2:获得初始观测
Obtain initial observation x
- 在与环境交互前,我们先得到一个初始状态或观测,并将其转换为一个特征向量 x \mathbf{x} x。
- 例如,在某个连续空间里,你可能会用 tile-coding 或其他方式把原始状态映射成 x \mathbf{x} x。
行3, 4:主循环
for all time steps doTake action A according to b, observe R, x'
- 每个时间步 t t t:
- 根据行为策略 b b b(如 ϵ \epsilon ϵ-greedy)从特征 x \mathbf{x} x 选择一个动作 A A A。
- 环境返回即时奖励 R R R 并转移到新观测 x ′ \mathbf{x}' x′。
行5:计算TD误差 δ δ δ
δ = R - R̄ + γ maxₐ (wₐ)ᵀ x' - (wA)ᵀ x
这是本算法最关键的一步:
- R − R ˉ R - \bar{R} R−Rˉ:将原始奖励减去平均奖励,得到“中心化奖励”。
- γ max a w a ⊤ x ′ \gamma \max_{a} \mathbf{w}_a^\top \mathbf{x}' γmaxawa⊤x′:估计下一状态的最大Q值(线性模型下为各动作权重向量与 x ′ \mathbf{x}' x′ 的内积)。
- − w A ⊤ x - \mathbf{w}_A^\top \mathbf{x} −wA⊤x:从当前Q值中减去上一步对所选动作 A A A 的Q值估计。
- 整体上, δ \delta δ 表示 “中心化即时奖励 + 折扣未来回报” 与 “当前Q值估计” 之间的差距 (即TD误差)。
行6:更新动作权重向量
wA = wA + α δ x
- 对于所选动作 A A A,我们用 TD 误差 δ \delta δ 调整其权重向量:
w A ← w A + α δ x . \mathbf{w}_A \leftarrow \mathbf{w}_A + \alpha \,\delta \,\mathbf{x}. wA←wA+αδx. - 线性模型下, ∇ w A ( w A ⊤ x ) = x \nabla_{\mathbf{w}_A} \bigl(\mathbf{w}_A^\top \mathbf{x}\bigr) = \mathbf{x} ∇wA(wA⊤x)=x,所以这是标准的梯度升/降更新形式。
行7:更新平均奖励
R̄ = R̄ + η α δ
- 同样地,我们也用同一个 TD 误差 δ \delta δ 来更新平均奖励 R ˉ \bar{R} Rˉ。
- η α \eta\alpha ηα 可以视作平均奖励更新的有效步长;若 η = 1 \eta=1 η=1,则直接用 α δ \alpha\delta αδ;若 η \eta η 不同于1,就能灵活调节更新幅度。
行8:更新当前特征
x = x'
- 将下一状态特征 x ′ \mathbf{x}' x′ 变为当前特征 x \mathbf{x} x,进入下一步循环。
行9:循环结束
end
- 算法在有限时间或直到收敛为止进行多次迭代。
知识点回顾
-
线性Q-learning:
- 不再用一个表格存储 Q ( s , a ) Q(s,a) Q(s,a),而是对每个动作维护一个权重向量 w a \mathbf{w}_a wa,用线性函数 w a ⊤ x \mathbf{w}_a^\top \mathbf{x} wa⊤x 逼近动作值。
- 在高维或连续状态下,这是常用的方法。
-
奖励中心化:
- 在TD误差中使用 ( R − R ˉ ) (R - \bar{R}) (R−Rˉ) 代替 R R R,减少由于奖励有常数偏移或 γ \gamma γ 较大导致的数值膨胀问题。
- 通过更新 R ˉ \bar{R} Rˉ,使其自适应地追踪策略的平均奖励水平。
-
TD误差 δ \delta δ:
- 反映了当前估计与目标之间的差距。
- 这里的“目标”是中心化即时奖励 + 折扣未来最优价值;
- δ \delta δ 越大(正),说明“实际情况比估计好”;越大(负),说明“比估计差”。
-
步长参数:
- α \alpha α 控制Q值(权重向量)更新速度;
- η α \eta\alpha ηα 控制平均奖励更新速度。
- 这些步长通常要满足一定条件(如 Robbins–Monro)才能保证收敛。
简单数值例子
下面我们给出一个简单的数值例子,展示如何在单步中计算并更新各量。
- 假设特征向量维度 d = 3 d=3 d=3。
- 当前状态特征 x = [ 1 , 0 , 2 ] ⊤ \mathbf{x} = [1, 0, 2]^\top x=[1,0,2]⊤。
- 下一状态特征 x ′ = [ 0 , 1 , 1 ] ⊤ \mathbf{x}' = [0, 1, 1]^\top x′=[0,1,1]⊤。
- 行为策略 ϵ \epsilon ϵ-greedy 从 x \mathbf{x} x 中选取动作 A A A,此处动作空间有2个动作: a 1 a_1 a1 和 a 2 a_2 a2。
权重向量与平均奖励初始化
- w a 1 = [ 0.5 , 0.2 , − 0.1 ] ⊤ \mathbf{w}_{a_1} = [0.5, 0.2, -0.1]^\top wa1=[0.5,0.2,−0.1]⊤, w a 2 = [ 0.3 , 0.4 , 0.1 ] ⊤ \mathbf{w}_{a_2} = [0.3, 0.4, 0.1]^\top wa2=[0.3,0.4,0.1]⊤。
- R ˉ = 2.0 \bar{R} = 2.0 Rˉ=2.0(任意初始化)。
- 折扣因子 γ = 0.9 \gamma = 0.9 γ=0.9。
- 学习率 α = 0.1 \alpha = 0.1 α=0.1,平均奖励更新因子 η = 0.5 \eta=0.5 η=0.5(示例值)。
执行动作并获得奖励
- 设定当前动作为 A = a 1 A = a_1 A=a1。
- 环境返回即时奖励 R = 5 R = 5 R=5,下一状态特征 x ′ = [ 0 , 1 , 1 ] ⊤ \mathbf{x}' = [0, 1, 1]^\top x′=[0,1,1]⊤。
计算TD误差 δ
- 计算中心化奖励: R − R ˉ = 5 − 2.0 = 3 R - \bar{R} = 5 - 2.0 = 3 R−Rˉ=5−2.0=3。
- 计算下一状态每个动作的Q值:
w a 1 ⊤ x ′ = [ 0.5 , 0.2 , − 0.1 ] ⋅ [ 0 , 1 , 1 ] = 0.2 + ( − 0.1 ) = 0.1 , \mathbf{w}_{a_1}^\top \mathbf{x}' = [0.5, 0.2, -0.1] \cdot [0, 1, 1] = 0.2 + (-0.1) = 0.1, wa1⊤x′=[0.5,0.2,−0.1]⋅[0,1,1]=0.2+(−0.1)=0.1, w a 2 ⊤ x ′ = [ 0.3 , 0.4 , 0.1 ] ⋅ [ 0 , 1 , 1 ] = 0.4 + 0.1 = 0.5. \mathbf{w}_{a_2}^\top \mathbf{x}' = [0.3, 0.4, 0.1] \cdot [0, 1, 1] = 0.4 + 0.1 = 0.5. wa2⊤x′=[0.3,0.4,0.1]⋅[0,1,1]=0.4+0.1=0.5.
因此, max a w a ⊤ x ′ = 0.5 \max_{a} \mathbf{w}_a^\top \mathbf{x}' = 0.5 maxawa⊤x′=0.5。 - 计算当前Q值:
w A ⊤ x = w a 1 ⊤ x = [ 0.5 , 0.2 , − 0.1 ] ⋅ [ 1 , 0 , 2 ] = 0.5 + ( − 0.2 ) = 0.3. \mathbf{w}_{A}^\top \mathbf{x} = \mathbf{w}_{a_1}^\top \mathbf{x} = [0.5, 0.2, -0.1] \cdot [1, 0, 2] = 0.5 + (-0.2) = 0.3. wA⊤x=wa1⊤x=[0.5,0.2,−0.1]⋅[1,0,2]=0.5+(−0.2)=0.3. - 整理得到:
δ = ( 5 − 2.0 ) + 0.9 × 0.5 − 0.3 = 3 + 0.45 − 0.3 = 3.15. \delta = (5 - 2.0) + 0.9 \times 0.5 - 0.3 = 3 + 0.45 - 0.3 = 3.15. δ=(5−2.0)+0.9×0.5−0.3=3+0.45−0.3=3.15.
更新动作权重向量
w a 1 ← w a 1 + α δ x = [ 0.5 , 0.2 , − 0.1 ] ⊤ + 0.1 × 3.15 × [ 1 , 0 , 2 ] ⊤ . \mathbf{w}_{a_1} \leftarrow \mathbf{w}_{a_1} + \alpha\,\delta\,\mathbf{x} = [0.5, 0.2, -0.1]^\top + 0.1 \times 3.15 \times [1, 0, 2]^\top. wa1←wa1+αδx=[0.5,0.2,−0.1]⊤+0.1×3.15×[1,0,2]⊤.
- 先计算增量: 0.1 × 3.15 = 0.315 0.1 \times 3.15 = 0.315 0.1×3.15=0.315。
- 对 x = [ 1 , 0 , 2 ] \mathbf{x}=[1,0,2] x=[1,0,2] 的增量为 [ 0.315 , 0 , 0.63 ] [0.315, 0, 0.63] [0.315,0,0.63]。
- 更新后:
w a 1 = [ 0.5 + 0.315 , 0.2 + 0 , − 0.1 + 0.63 ] = [ 0.815 , 0.2 , 0.53 ] . \mathbf{w}_{a_1} = [0.5 + 0.315, \; 0.2 + 0, \; -0.1 + 0.63] = [0.815, \; 0.2, \; 0.53]. wa1=[0.5+0.315,0.2+0,−0.1+0.63]=[0.815,0.2,0.53].
更新平均奖励
R ˉ ← R ˉ + η α δ = 2.0 + 0.5 × 0.1 × 3.15 = 2.0 + 0.1575 = 2.1575. \bar{R} \leftarrow \bar{R} + \eta \alpha \delta = 2.0 + 0.5 \times 0.1 \times 3.15 = 2.0 + 0.1575 = 2.1575. Rˉ←Rˉ+ηαδ=2.0+0.5×0.1×3.15=2.0+0.1575=2.1575.
更新当前特征
x ← x ′ = [ 0 , 1 , 1 ] ⊤ . \mathbf{x} \leftarrow \mathbf{x}' = [0,1,1]^\top. x←x′=[0,1,1]⊤.
解释:
- 通过上面这一步更新,我们提高了动作 a 1 a_1 a1 的权重,因为 δ \delta δ 为正数,表示“实际比我们估计的好”。
- 同时,也提高了平均奖励 R ˉ \bar{R} Rˉ(从2.0到2.1575),让之后的中心化奖励 R − R ˉ R - \bar{R} R−Rˉ 会相应变小(即不至于无限累加)。

本算法是一个“深度Q网络(DQN)”版本,但与传统DQN相比,它使用了基于值的奖励中心化(value-based reward centering)。也就是说:
-
非线性函数逼近(DQN)
- 我们用一个神经网络来逼近 Q 值函数:给定状态(或观测) x \mathbf{x} x,以及动作 a a a,输出 q ^ ( x , a ) \hat{q}(\mathbf{x}, a) q^(x,a)。
- 训练时,我们会用“经验回放(replay buffer)”批量采样过往数据,并通过梯度下降更新网络参数。
-
奖励中心化
- 在计算TD误差时,将即时奖励 R R R 替换为 ( R − R ˉ ) (R - \bar{R}) (R−Rˉ),其中 R ˉ \bar{R} Rˉ 是一个在线估计的平均奖励。
- 同时,用同一个TD误差来更新 R ˉ \bar{R} Rˉ。
- 这样可减轻高折扣因子或大常数奖励带来的数值膨胀,令学习更稳定。
行0:输入与算法参数
Input: The behavior policy b (e.g., ε-greedy)
Algorithm parameters: discount factor γ, step-size parameters α, η
- 行为策略 b b b:训练过程中智能体实际用来选动作的策略,如 ϵ \epsilon ϵ-greedy。
- 折扣因子 γ \gamma γ:衡量未来奖励的重要性, γ ∈ [ 0 , 1 ) \gamma \in [0,1) γ∈[0,1)。
- 步长参数 α , η \alpha, \eta α,η: α \alpha α 多用于网络参数更新(学习率), η \eta η 用于调节平均奖励 R ˉ \bar{R} Rˉ 的更新幅度。
行1:初始化
Initialize value network, target network; initialize R̄ arbitrarily (e.g., to zero)
- 初始化价值网络参数:例如,一个神经网络 θ \theta θ 用来逼近 Q 值 q ^ ( x , a ; θ ) \hat{q}(\mathbf{x}, a; \theta) q^(x,a;θ)。
- 初始化平均奖励 R ˉ \bar{R} Rˉ 为 0 或其他任意值。
行2:获得初始观测 x \mathbf{x} x
Obtain initial observation x
- 在与环境交互前,我们先得到初始状态(或观测)并将其表示为向量 x \mathbf{x} x。
行3–5:与环境交互 & 存储体验
for all time steps doTake action A according to b, observe R, x'Store tuple (x, A, R, x') in the experience buffer
- 与环境交互:在时间步 t t t,根据行为策略 b b b(如 ϵ \epsilon ϵ-greedy)选择动作 A A A,环境返回即时奖励 R R R 并转移到新观测 x ′ \mathbf{x}' x′。
- 存储体验:将四元组 ( x , A , R , x ′ ) (\mathbf{x}, A, R, \mathbf{x}') (x,A,R,x′) 存入“experience buffer”(经验回放池),以便后续批量采样训练。
行6–11:用采样的迷你批更新估计
if time to update estimates thenSample a minibatch of transitions (x, A, R, x')^bFor every i-th transition: δᵢ = Rᵢ - R̄ + γ maxₐ q̂(xᵢ', a) - q̂(xᵢ, Aᵢ)Perform a semi-gradient update of the value-network parameters with the δ² lossR̄ = R̄ + η α mean(δ)Update the target network occasionally
这是DQN训练的核心部分,与传统DQN相比多了“减去 R ˉ \bar{R} Rˉ”以及更新 R ˉ \bar{R} Rˉ:
-
采样迷你批:
- 从 replay buffer 中随机采样一批(batch)过往转移 { ( x i , A i , R i , x i ′ ) } \{(\mathbf{x}_i, A_i, R_i, \mathbf{x}_i')\} {(xi,Ai,Ri,xi′)}。
- 这使得训练更稳定且可重复利用经验。
-
计算 TD 误差
- 对每条转移计算
δ i = ( R i − R ˉ ) + γ max a q ^ ( x i ′ , a ) − q ^ ( x i , A i ) . \delta_i = \bigl(R_i - \bar{R}\bigr) + \gamma \max_a \hat{q}(\mathbf{x}_i', a) - \hat{q}(\mathbf{x}_i, A_i). δi=(Ri−Rˉ)+γamaxq^(xi′,a)−q^(xi,Ai). - 与标准DQN不同之处在于,奖励部分变成了 ( R i − R ˉ ) (R_i - \bar{R}) (Ri−Rˉ) 而非 R i R_i Ri;这样就是奖励中心化。
- 对每条转移计算
-
半梯度(semi-gradient)更新
- 在DQN中,我们通常用均方误差(MSE)来训练网络参数 θ \theta θ。
- 当TD目标是 ( R i − R ˉ ) + γ max a q ^ ( x i ′ , a ) \bigl(R_i - \bar{R}\bigr) + \gamma \max_a \hat{q}(\mathbf{x}_i', a) (Ri−Rˉ)+γmaxaq^(xi′,a),网络输出为 q ^ ( x i , A i ; θ ) \hat{q}(\mathbf{x}_i, A_i; \theta) q^(xi,Ai;θ),
其损失可以写作
L ( θ ) = 1 2 ∑ i [ δ i ( θ ) ] 2 , L(\theta) = \frac{1}{2}\sum_i \bigl[\delta_i(\theta)\bigr]^2, L(θ)=21i∑[δi(θ)]2,
其中 δ i ( θ ) \delta_i(\theta) δi(θ) 会随 θ \theta θ 改变。我们通过反向传播对 θ \theta θ 做梯度下降。
-
更新平均奖励
R ˉ ← R ˉ + η α mean ( δ ) , \bar{R} \leftarrow \bar{R} + \eta \,\alpha \,\text{mean}(\delta), Rˉ←Rˉ+ηαmean(δ),- 这里 mean ( δ ) \text{mean}(\delta) mean(δ) 表示对 minibatch 中所有 δ i \delta_i δi 取平均。
- 如果 δ \delta δ 平均值为正,说明当前整体回报超出估计;若为负,则说明不足。
-
更新目标网络
- 在 DQN 中,通常还会使用一个“目标网络(target network)”来稳定训练:定期或软更新其参数为 θ \theta θ,然后在 max a q ( x ′ , a ) \max_a q(\mathbf{x}', a) maxaq(x′,a) 时用该目标网络的值来计算。
行12–14:收尾与下一步
endx = x'
end
- 这里表明:在完成更新后,将当前观测 x \mathbf{x} x 设置为下一状态 x ′ \mathbf{x}' x′,然后进入下一个时间步。
关键知识点
-
DQN:
- 用神经网络逼近 Q 值,采用体验回放和目标网络来减少数据相关性和训练不稳定。
-
奖励中心化:
- 在 TD 误差中使用 ( R − R ˉ ) (R - \bar{R}) (R−Rˉ) 代替原始 R R R。
- 同时更新 R ˉ \bar{R} Rˉ,让它逐渐逼近策略的平均奖励。
- 这样可以缓解高折扣因子下 Q 值变得很大的问题,并提高训练稳定性。
-
半梯度更新:
- 我们把 δ i 2 \delta_i^2 δi2 作为损失,对网络参数 θ \theta θ 求梯度并更新。
- 称为“半梯度”或“近似梯度”,因为 δ i \delta_i δi 中包含了 max a q ^ ( x ′ , a ) \max_a \hat{q}(\mathbf{x}', a) maxaq^(x′,a),本身对 θ \theta θ 也有依赖,但在实际 DQN 中我们常用一个固定目标网络来近似,或者只对 q ^ ( x , A ) \hat{q}(\mathbf{x},A) q^(x,A) 的部分做梯度。
-
m e a n ( δ ) mean(\delta) mean(δ):
- 在一个 batch 中,每条样本都会产生一个 δ i \delta_i δi。我们对它们求平均,用于更新 R ˉ \bar{R} Rˉ。
- 如果整体 δ \delta δ 为正,表示当前估计偏保守;如果整体 δ \delta δ 为负,则表示估计偏乐观。
数值示例
1. 背景与思路
在非线性 DQN中,我们用一个神经网络来近似 Q 值函数:
Q θ ( x , a ) = NN ( x ; θ ) [ a ] , Q_\theta(\mathbf{x}, a) = \text{NN}(\mathbf{x}; \theta)[a], Qθ(x,a)=NN(x;θ)[a],
其中:
- x \mathbf{x} x 是状态(或观测)的输入;
- θ \theta θ 表示网络所有的可训练参数(如权重矩阵、偏置等);
- NN ( x ; θ ) \text{NN}(\mathbf{x}; \theta) NN(x;θ) 输出一个向量,每个分量对应一个动作的 Q 值。
在“value-based reward centering”里,我们在计算 TD 目标时使用 ( R − R ˉ ) (R - \bar{R}) (R−Rˉ) 代替原始奖励 R R R,并且利用同一个时序差分(TD)误差更新平均奖励 R ˉ \bar{R} Rˉ。下文会展示更完整的过程。
2. 一个小型神经网络示例
为了具体化,我们假设一个非常小的神经网络:
- 输入层:维度 = 2(状态/观测是 x ∈ R 2 \mathbf{x}\in \mathbb{R}^2 x∈R2)。
- 隐藏层:维度 = 2,带 ReLU 激活。
- 输出层:维度 = 2(表示有 2 个动作,输出对应 q ^ ( x , a 1 ) \hat{q}(\mathbf{x}, a_1) q^(x,a1) 和 q ^ ( x , a 2 ) \hat{q}(\mathbf{x}, a_2) q^(x,a2))。
用符号表示:
- 隐藏层:
h = max { 0 , W 1 x + b 1 } , \mathbf{h} = \max\{0,\; W_1 \mathbf{x} + \mathbf{b}_1\}, h=max{0,W1x+b1},
其中 W 1 W_1 W1 是 2 × 2 2\times 2 2×2 矩阵, b 1 \mathbf{b}_1 b1 是 2 维偏置, max { 0 , ⋅ } \max\{0,\cdot\} max{0,⋅} 表示 ReLU 逐元素操作。 - 输出层:
q θ ( x ) = W 2 h + b 2 , \mathbf{q}_\theta(\mathbf{x}) = W_2 \mathbf{h} + \mathbf{b}_2, qθ(x)=W2h+b2,
这是一个 2 维向量,分别对应动作 a 1 a_1 a1 和 a 2 a_2 a2 的 Q 值。
这样, θ \theta θ 包含 { W 1 , b 1 , W 2 , b 2 } \{W_1, \mathbf{b}_1, W_2, \mathbf{b}_2\} {W1,b1,W2,b2}。在实际DQN里可能更大更多层,但这里只演示一个非常小的网络方便手算。
3. 初始化与数据设定
我们随便给定一些初始参数(数字都很小、只作示例):
W 1 = ( 0.5 − 0.2 0.1 0.3 ) , b 1 = ( 0.0 0.1 ) , W_1 = \begin{pmatrix} 0.5 & -0.2 \\ 0.1 & 0.3 \end{pmatrix}, \quad \mathbf{b}_1 = \begin{pmatrix} 0.0 \\ 0.1 \end{pmatrix}, W1=(0.50.1−0.20.3),b1=(0.00.1),
W 2 = ( 0.4 0.2 − 0.1 0.3 ) , b 2 = ( 0.0 0.0 ) . W_2 = \begin{pmatrix} 0.4 & 0.2 \\ -0.1 & 0.3 \end{pmatrix}, \quad \mathbf{b}_2 = \begin{pmatrix} 0.0 \\ 0.0 \end{pmatrix}. W2=(0.4−0.10.20.3),b2=(0.00.0).
另外,设:
- 当前平均奖励 R ˉ = 5 \bar{R} = 5 Rˉ=5(示例);
- 折扣因子 γ = 0.9 \gamma=0.9 γ=0.9;
- 学习率 α = 0.01 \alpha=0.01 α=0.01(针对网络参数);
- 平均奖励更新因子 η = 1 \eta=1 η=1(只为简化,实际可不一样)。
一条训练样本
假设我们只看一条样本(batch size=1):
- 当前状态 x = [ 0.5 , − 1.2 ] ⊤ \mathbf{x}=[0.5, -1.2]^\top x=[0.5,−1.2]⊤;
- 动作 A = a 1 A=a_1 A=a1;
- 即时奖励 R = 7 R=7 R=7;
- 下一状态 x ′ = [ 1.0 , 0.3 ] ⊤ \mathbf{x}'=[1.0, 0.3]^\top x′=[1.0,0.3]⊤;
- 环境中还有另一个动作 a 2 a_2 a2,我们需要它来做 max a Q ( x ′ , a ) \max_a Q(\mathbf{x}',a) maxaQ(x′,a)。
我们先做一次前向传播,计算出:
- 当前状态 x \mathbf{x} x下,对动作 a 1 a_1 a1 和 a 2 a_2 a2 的 Q 值;
- 下一状态 x ′ \mathbf{x}' x′下,对动作 a 1 a_1 a1 和 a 2 a_2 a2 的 Q 值。
4. 前向传播(Forward Pass)
4.1 计算 q ^ θ ( x ) \hat{q}_\theta(\mathbf{x}) q^θ(x)
(1) 隐藏层激活 h \mathbf{h} h
z 1 = W 1 x + b 1 = ( 0.5 − 0.2 0.1 0.3 ) ( 0.5 − 1.2 ) + ( 0.0 0.1 ) . \mathbf{z}_1 = W_1 \mathbf{x} + \mathbf{b}_1 = \begin{pmatrix} 0.5 & -0.2 \\ 0.1 & 0.3 \end{pmatrix} \begin{pmatrix} 0.5 \\ -1.2 \end{pmatrix} + \begin{pmatrix} 0.0 \\ 0.1 \end{pmatrix}. z1=W1x+b1=(0.50.1−0.20.3)(0.5−1.2)+(0.00.1).
先做矩阵乘法:
- 第一行: 0.5 ∗ 0.5 + ( − 0.2 ) ∗ ( − 1.2 ) = 0.25 + 0.24 = 0.49 0.5*0.5 + (-0.2)*(-1.2) = 0.25 + 0.24 = 0.49 0.5∗0.5+(−0.2)∗(−1.2)=0.25+0.24=0.49;
- 第二行: 0.1 ∗ 0.5 + 0.3 ∗ ( − 1.2 ) = 0.05 − 0.36 = − 0.31 0.1*0.5 + 0.3*(-1.2) = 0.05 - 0.36 = -0.31 0.1∗0.5+0.3∗(−1.2)=0.05−0.36=−0.31;
然后加偏置 b 1 \mathbf{b}_1 b1:
- 第一维: 0.49 + 0.0 = 0.49 0.49 + 0.0 = 0.49 0.49+0.0=0.49;
- 第二维: − 0.31 + 0.1 = − 0.21 -0.31 + 0.1 = -0.21 −0.31+0.1=−0.21。
因此
z 1 = ( 0.49 − 0.21 ) . \mathbf{z}_1 = \begin{pmatrix} 0.49 \\ -0.21 \end{pmatrix}. z1=(0.49−0.21).
再做 ReLU: h = max { 0 , z 1 } \mathbf{h} = \max\{0, \mathbf{z}_1\} h=max{0,z1}:
- 第一维: max { 0 , 0.49 } = 0.49 \max\{0,0.49\} = 0.49 max{0,0.49}=0.49;
- 第二维: max { 0 , − 0.21 } = 0 \max\{0,-0.21\} = 0 max{0,−0.21}=0(因为 -0.21 < 0)。
所以
h = ( 0.49 0 ) . \mathbf{h} = \begin{pmatrix} 0.49 \\ 0 \end{pmatrix}. h=(0.490).
(2) 输出层 q θ ( x ) \mathbf{q}_\theta(\mathbf{x}) qθ(x)
q θ ( x ) = W 2 h + b 2 = ( 0.4 0.2 − 0.1 0.3 ) ( 0.49 0 ) + ( 0.0 0.0 ) . \mathbf{q}_\theta(\mathbf{x}) = W_2 \mathbf{h} + \mathbf{b}_2 = \begin{pmatrix} 0.4 & 0.2 \\ -0.1 & 0.3 \end{pmatrix} \begin{pmatrix} 0.49 \\ 0 \end{pmatrix} + \begin{pmatrix} 0.0 \\ 0.0 \end{pmatrix}. qθ(x)=W2h+b2=(0.4−0.10.20.3)(0.490)+(0.00.0).
矩阵乘法:
- 对输出第1维(动作 a 1 a_1 a1): 0.4 ∗ 0.49 + 0.2 ∗ 0 = 0.196 0.4*0.49 + 0.2*0 = 0.196 0.4∗0.49+0.2∗0=0.196;
- 对输出第2维(动作 a 2 a_2 a2): − 0.1 ∗ 0.49 + 0.3 ∗ 0 = − 0.049 -0.1*0.49 + 0.3*0 = -0.049 −0.1∗0.49+0.3∗0=−0.049。
所以
q θ ( x ) = ( 0.196 − 0.049 ) . \mathbf{q}_\theta(\mathbf{x}) = \begin{pmatrix} 0.196 \\ -0.049 \end{pmatrix}. qθ(x)=(0.196−0.049).
表示:
- q ^ θ ( x , a 1 ) = 0.196 \hat{q}_\theta(\mathbf{x}, a_1)=0.196 q^θ(x,a1)=0.196;
- q ^ θ ( x , a 2 ) = − 0.049 \hat{q}_\theta(\mathbf{x}, a_2)=-0.049 q^θ(x,a2)=−0.049。
4.2 计算 q ^ θ ( x ′ ) \hat{q}_\theta(\mathbf{x}') q^θ(x′)
同理,对下一状态 x ′ = [ 1.0 , 0.3 ] \mathbf{x}'=[1.0, 0.3] x′=[1.0,0.3]:
-
隐藏层:
z 1 ′ = W 1 x ′ + b 1 = ( 0.5 − 0.2 0.1 0.3 ) ( 1.0 0.3 ) + ( 0.0 0.1 ) . \mathbf{z}_1' = W_1 \mathbf{x}' + \mathbf{b}_1 = \begin{pmatrix} 0.5 & -0.2 \\ 0.1 & 0.3 \end{pmatrix} \begin{pmatrix} 1.0 \\ 0.3 \end{pmatrix} + \begin{pmatrix} 0.0 \\ 0.1 \end{pmatrix}. z1′=W1x′+b1=(0.50.1−0.20.3)(1.00.3)+(0.00.1).- 第一行: 0.5 ∗ 1.0 + ( − 0.2 ) ∗ 0.3 = 0.5 − 0.06 = 0.44 0.5*1.0 + (-0.2)*0.3 = 0.5 - 0.06 = 0.44 0.5∗1.0+(−0.2)∗0.3=0.5−0.06=0.44;
- 第二行: 0.1 ∗ 1.0 + 0.3 ∗ 0.3 = 0.1 + 0.09 = 0.19 0.1*1.0 + 0.3*0.3 = 0.1 + 0.09=0.19 0.1∗1.0+0.3∗0.3=0.1+0.09=0.19;
加偏置 b 1 \mathbf{b}_1 b1: - 第一维: 0.44 + 0 = 0.44 0.44 + 0=0.44 0.44+0=0.44;
- 第二维: 0.19 + 0.1 = 0.29 0.19 + 0.1=0.29 0.19+0.1=0.29。
z 1 ′ = ( 0.44 0.29 ) . \mathbf{z}_1' = \begin{pmatrix} 0.44 \\ 0.29 \end{pmatrix}. z1′=(0.440.29).
ReLU:
h ′ = ( max { 0 , 0.44 } max { 0 , 0.29 } ) = ( 0.44 0.29 ) . \mathbf{h}' = \begin{pmatrix} \max\{0,0.44\} \\ \max\{0,0.29\} \end{pmatrix} = \begin{pmatrix} 0.44 \\ 0.29 \end{pmatrix}. h′=(max{0,0.44}max{0,0.29})=(0.440.29).
-
输出层:
q θ ( x ′ ) = W 2 h ′ + b 2 = ( 0.4 0.2 − 0.1 0.3 ) ( 0.44 0.29 ) + ( 0 0 ) . \mathbf{q}_\theta(\mathbf{x}') = W_2 \mathbf{h}' + \mathbf{b}_2 = \begin{pmatrix} 0.4 & 0.2 \\ -0.1 & 0.3 \end{pmatrix} \begin{pmatrix} 0.44 \\ 0.29 \end{pmatrix} + \begin{pmatrix} 0 \\ 0 \end{pmatrix}. qθ(x′)=W2h′+b2=(0.4−0.10.20.3)(0.440.29)+(00).- 对动作 a 1 a_1 a1: 0.4 ∗ 0.44 + 0.2 ∗ 0.29 = 0.176 + 0.058 = 0.234 0.4*0.44 + 0.2*0.29=0.176 + 0.058=0.234 0.4∗0.44+0.2∗0.29=0.176+0.058=0.234;
- 对动作 a 2 a_2 a2: − 0.1 ∗ 0.44 + 0.3 ∗ 0.29 = − 0.044 + 0.087 = 0.043 -0.1*0.44 + 0.3*0.29=-0.044 + 0.087=0.043 −0.1∗0.44+0.3∗0.29=−0.044+0.087=0.043。
q θ ( x ′ ) = ( 0.234 0.043 ) . \mathbf{q}_\theta(\mathbf{x}') = \begin{pmatrix} 0.234 \\ 0.043 \end{pmatrix}. qθ(x′)=(0.2340.043).
即 - q ^ θ ( x ′ , a 1 ) = 0.234 \hat{q}_\theta(\mathbf{x}', a_1)=0.234 q^θ(x′,a1)=0.234;
- q ^ θ ( x ′ , a 2 ) = 0.043 \hat{q}_\theta(\mathbf{x}', a_2)=0.043 q^θ(x′,a2)=0.043。
5. 计算 TD 误差 δ \delta δ
在“value-based reward centering”中,TD 目标 = ( R − R ˉ ) + γ max a q ^ θ ( x ′ , a ) (R - \bar{R}) + \gamma \max_{a} \hat{q}_\theta(\mathbf{x}', a) (R−Rˉ)+γmaxaq^θ(x′,a)。
- 中心化奖励: R − R ˉ = 7 − 5 = 2 R - \bar{R} = 7 - 5=2 R−Rˉ=7−5=2。
- 下一状态最大 Q: max { 0.234 , 0.043 } = 0.234 \max\{0.234, 0.043\}=0.234 max{0.234,0.043}=0.234。
- 当前 Q: q ^ θ ( x , A = a 1 ) = 0.196 \hat{q}_\theta(\mathbf{x}, A=a_1)=0.196 q^θ(x,A=a1)=0.196。
- 折扣因子: γ = 0.9 \gamma=0.9 γ=0.9。
于是
δ = 7 − 5 + 0.9 × 0.234 − 0.196 = 2 + 0.2106 − 0.196 = 2.0146. \delta = 7 - 5 + 0.9 \times 0.234 - 0.196 = 2 + 0.2106 - 0.196 = 2.0146. δ=7−5+0.9×0.234−0.196=2+0.2106−0.196=2.0146.
这是我们这条样本的时序差分误差。
6. 损失函数与梯度下降
我们用均方误差(MSE)来训练网络参数 θ \theta θ。对这条样本来说,损失可以写作:
L ( θ ) = 1 2 [ δ ( θ ) ] 2 , L(\theta) = \frac12 \bigl[\delta(\theta)\bigr]^2, L(θ)=21[δ(θ)]2,
其中 δ ( θ ) \delta(\theta) δ(θ) 是上面算出来的 TD 误差,会随 θ \theta θ 改变。为了简化,我们此处把 δ \delta δ 视为“只依赖当前 θ \theta θ”的值(实际 DQN 常用“目标网络”或“停止梯度”技巧来使 δ \delta δ 的一部分不随 θ \theta θ 变)。在示例中,我们就把 δ = 2.0146 \delta=2.0146 δ=2.0146当作固定,便于演示梯度下降主流程。
6.1 反向传播(Backprop)
要更新 θ \theta θ,我们要对 L ( θ ) = 1 2 δ 2 L(\theta)=\tfrac12 \delta^2 L(θ)=21δ2 做梯度下降:
∇ θ L ( θ ) = δ ∇ θ δ . \nabla_\theta L(\theta) = \delta \,\nabla_\theta \delta. ∇θL(θ)=δ∇θδ.
但 δ ≈ q ^ θ ( x ′ , ⋅ ) \delta\approx \hat{q}_\theta(\mathbf{x}',\cdot) δ≈q^θ(x′,⋅) 等项都和 θ \theta θ 有关。如果在纯DQN实现里,我们通常冻结下一状态的 max q ^ θ ( x ′ , a ) \max \hat{q}_\theta(\mathbf{x}',a) maxq^θ(x′,a)(用目标网络 θ − \theta^- θ−)或做停止梯度,所以 δ \delta δ 中只有“ q ^ θ ( x , A ) \hat{q}_\theta(\mathbf{x},A) q^θ(x,A)”那一部分对 θ \theta θ 求导。这样:
∇ θ δ ≈ − ∇ θ q ^ θ ( x , A ) , \nabla_\theta \delta \approx -\,\nabla_\theta \hat{q}_\theta(\mathbf{x}, A), ∇θδ≈−∇θq^θ(x,A),
因为 δ = (常数) − q ^ θ ( x , A ) \delta = \text{(常数)} - \hat{q}_\theta(\mathbf{x}, A) δ=(常数)−q^θ(x,A) 在这种实现里“下一状态部分”不回传梯度。
为简单,我们就这么做:只对当前 Q 值 q ^ θ ( x , A ) \hat{q}_\theta(\mathbf{x}, A) q^θ(x,A) 求导。
小结
- ∇ θ L ( θ ) ≈ δ × [ − ∇ θ q ^ θ ( x , A ) ] \nabla_\theta L(\theta) \approx \delta \times \bigl[-\,\nabla_\theta \hat{q}_\theta(\mathbf{x}, A)\bigr] ∇θL(θ)≈δ×[−∇θq^θ(x,A)].
6.2 梯度下降更新
更新公式:
θ ← θ − α ∇ θ L ( θ ) . \theta \leftarrow \theta - \alpha \,\nabla_\theta L(\theta). θ←θ−α∇θL(θ).
带入上面近似:
θ ← θ − α δ [ − ∇ θ q ^ θ ( x , A ) ] = θ + α δ ∇ θ q ^ θ ( x , A ) . \theta \leftarrow \theta - \alpha\,\delta \,\bigl[-\nabla_\theta \hat{q}_\theta(\mathbf{x}, A)\bigr] = \theta + \alpha\,\delta \,\nabla_\theta \hat{q}_\theta(\mathbf{x}, A). θ←θ−αδ[−∇θq^θ(x,A)]=θ+αδ∇θq^θ(x,A).
由于 α = 0.01 \alpha=0.01 α=0.01, δ = 2.0146 \delta=2.0146 δ=2.0146,剩下就是计算 ∇ θ q ^ θ ( x , A = a 1 ) \nabla_\theta \hat{q}_\theta(\mathbf{x}, A=a_1) ∇θq^θ(x,A=a1)。这涉及到对 W 1 , b 1 , W 2 , b 2 W_1, b_1, W_2, b_2 W1,b1,W2,b2 做反向传播。下面我们只展示核心思路,不手算全部梯度细节——现实中由深度学习框架(如 PyTorch、TensorFlow)自动完成。
大体流程:
- 输出层: q ^ θ ( x , a 1 ) = z o u t , 1 \hat{q}_\theta(\mathbf{x}, a_1)=z_{out,1} q^θ(x,a1)=zout,1,梯度 ∂ z o u t , 1 / ∂ W 2 \partial z_{out,1}/\partial W_2 ∂zout,1/∂W2 与 ∂ z o u t , 1 / ∂ b 2 \partial z_{out,1}/\partial b_2 ∂zout,1/∂b2 依赖于隐藏层 h \mathbf{h} h。
- 隐藏层:再把梯度传回去,计算 ∂ z o u t , 1 / ∂ W 1 \partial z_{out,1}/\partial W_1 ∂zout,1/∂W1 等,因为 h \mathbf{h} h = ReLU( z 1 \mathbf{z}_1 z1),其中 z 1 = W 1 x + b 1 \mathbf{z}_1=W_1\mathbf{x}+b_1 z1=W1x+b1。
- 最后:更新每个参数,形如
W 2 ← W 2 + α δ ∂ q ^ θ ( x , a 1 ) ∂ W 2 , … W_2 \leftarrow W_2 + \alpha\,\delta \,\frac{\partial \hat{q}_\theta(\mathbf{x}, a_1)}{\partial W_2}, \quad\ldots W2←W2+αδ∂W2∂q^θ(x,a1),…
在实际代码中,这都是自动微分搞定。我们这里只要明白:每个参数都会被往“让 q ^ θ ( x , a 1 ) \hat{q}_\theta(\mathbf{x}, a_1) q^θ(x,a1) 更接近 TD 目标”的方向调整。
7. 更新平均奖励 R ˉ \bar{R} Rˉ
按照“value-based reward centering”伪代码,还要更新 R ˉ \bar{R} Rˉ。
令 R ˉ ← R ˉ + η α δ _ m e a n \bar{R} \leftarrow \bar{R} + \eta\alpha\,\delta\_mean Rˉ←Rˉ+ηαδ_mean。
- 这里 δ _ m e a n \delta\_mean δ_mean 是对一个 batch 的平均。我们示例 batch size=1,所以 δ _ m e a n = δ = 2.0146 \delta\_mean=\delta=2.0146 δ_mean=δ=2.0146。
- α = 0.01 \alpha=0.01 α=0.01, η = 1 \eta=1 η=1,则
R ˉ ← 5 + 0.01 × 2.0146 = 5 + 0.020146 ≈ 5.020146. \bar{R} \leftarrow 5 + 0.01\times 2.0146 = 5 + 0.020146 \approx 5.020146. Rˉ←5+0.01×2.0146=5+0.020146≈5.020146. - 表示由于本次样本的 TD 误差为正,说明我们的“中心化奖励”在估计上偏低,于是稍微提高 R ˉ \bar{R} Rˉ(从5到5.020146)。
8. 结果与意义
-
神经网络参数 θ \theta θ 的意义:
- θ \theta θ 包含了所有层的权重和偏置。它决定了给定状态 x \mathbf{x} x 时,各动作的 Q 值输出。
- 当我们执行梯度下降时,其实是在“微调”这些参数,以减少 δ 2 \delta^2 δ2(TD 误差的平方),让 Q 值逼近我们想要的目标。
-
为什么梯度下降?
- 因为我们的损失函数 L ( θ ) = 1 2 δ 2 L(\theta)=\tfrac12\delta^2 L(θ)=21δ2 对 θ \theta θ 求导可得更新方向;更新后,网络输出的 q ^ θ ( x , a ) \hat{q}_\theta(\mathbf{x}, a) q^θ(x,a) 就会更接近“中心化奖励 + 折扣未来价值”。
-
数值更新后:
- θ \theta θ 中的所有参数( W 1 , b 1 , W 2 , b 2 W_1, b_1, W_2, b_2 W1,b1,W2,b2) 会小幅度调整;
- R ˉ \bar{R} Rˉ 也小幅度提高。
- 在多步迭代后, R ˉ \bar{R} Rˉ 收敛到策略的平均奖励水平,网络学习到一个Q值函数,不会出现因奖励有大常数偏移而导致的 Q 值无限膨胀。
-
非线性 vs. 线性:
- 跟线性Q-learning不同的是,这里 q ^ θ ( x , a ) \hat{q}_\theta(\mathbf{x}, a) q^θ(x,a) 是神经网络输出的一个非线性函数;我们需要用反向传播(backprop)来计算梯度。
- 在例子中,我们手动演示了如何做前向传播得到 Q 值,反向传播的梯度更新就由深度学习库自动计算了。
9. 小结
- θ \theta θ 是神经网络的所有可学习参数(权重、偏置等)。它把状态 x \mathbf{x} x 映射到各动作的Q值输出。
- 梯度下降:我们对 1 2 δ 2 \tfrac12 \delta^2 21δ2 做最小化,通过反向传播更新 θ \theta θ。其中 δ = ( R − R ˉ ) + γ max a Q θ ( x ′ , a ) − Q θ ( x , A ) \delta = (R - \bar{R}) + \gamma \max_a Q_\theta(\mathbf{x}',a) - Q_\theta(\mathbf{x},A) δ=(R−Rˉ)+γmaxaQθ(x′,a)−Qθ(x,A)。
- 示例:
- 前向传播:计算隐藏层 h \mathbf{h} h 和输出层 q θ ( x ) \mathbf{q}_\theta(\mathbf{x}) qθ(x),得出 q ^ θ ( x , a 1 ) \hat{q}_\theta(\mathbf{x}, a_1) q^θ(x,a1) 等值。
- 计算 δ ≈ 2.0146 \delta\approx2.0146 δ≈2.0146 并做梯度更新:让 q ^ θ ( x , a 1 ) \hat{q}_\theta(\mathbf{x}, a_1) q^θ(x,a1) 朝目标 ( R − R ˉ ) + γ max a q ^ θ ( x ′ , a ) (R-\bar{R}) + \gamma \max_a \hat{q}_\theta(\mathbf{x}',a) (R−Rˉ)+γmaxaq^θ(x′,a) 靠近。
- 同时更新平均奖励 R ˉ ← R ˉ + η α δ _ m e a n \bar{R}\leftarrow \bar{R} + \eta\alpha\,\delta\_mean Rˉ←Rˉ+ηαδ_mean。
- 意义:
- 通过“奖励中心化”,我们去掉了奖励中的大偏移,使 Q 值学习更稳定;
- 通过神经网络参数 θ \theta θ 的梯度下降,我们逐步逼近真正的Q值函数;
- 每次更新都在自动微分框架下完成,无需手动算所有梯度。
希望这个更细致的示例能帮你理解:
- θ \theta θ 就是神经网络所有可学习参数;
- 梯度下降如何基于 δ \delta δ 进行一次更新(反向传播);
- 奖励中心化对 TD 目标的影响,以及** R ˉ \bar{R} Rˉ** 的更新方式。
效果
- 本次更新后:
- 动作 a 1 a_1 a1 在状态 m a t h b f x mathbf{x} mathbfx 下的估计值会稍微增大(因为 δ \delta δ 为正);
- 平均奖励 R ˉ \bar{R} Rˉ 也稍微增大。
- 在多步迭代后, R ˉ \bar{R} Rˉ 将逐渐收敛到一个与策略性能相关的平均奖励水平,Q值在数值上会更集中于“相对奖励”的范围,不会因为大常数奖励或 γ \gamma γ 高而无限膨胀。
我们建议对附录C中的通用伪代码进行两个小但有用的优化。
Python代码可在以下地址获取: https://github.com/abhisheknaik96/continuing-rl-exps。
相关文章:
论文笔记(七十二)Reward Centering(四)
Reward Centering(四) 文章概括摘要附录A 伪代码 文章概括 引用: article{naik2024reward,title{Reward Centering},author{Naik, Abhishek and Wan, Yi and Tomar, Manan and Sutton, Richard S},journal{arXiv preprint arXiv:2405.09999…...

Matlab——图像保存导出成好看的.pdf格式文件
点击图像的右上角,点击第一个保存按钮键。...

官方文档学习TArray容器
一.TArray中的元素相等 1.重载一下 元素中的 运算符,有时需要重载排序。接下来,我们将id 作为判断结构体的标识。 定义结构体 USTRUCT() struct FXGEqualStructInfo {GENERATED_USTRUCT_BODY() public:FXGEqualStructInfo(){};FXGEqualStructInfo(in…...
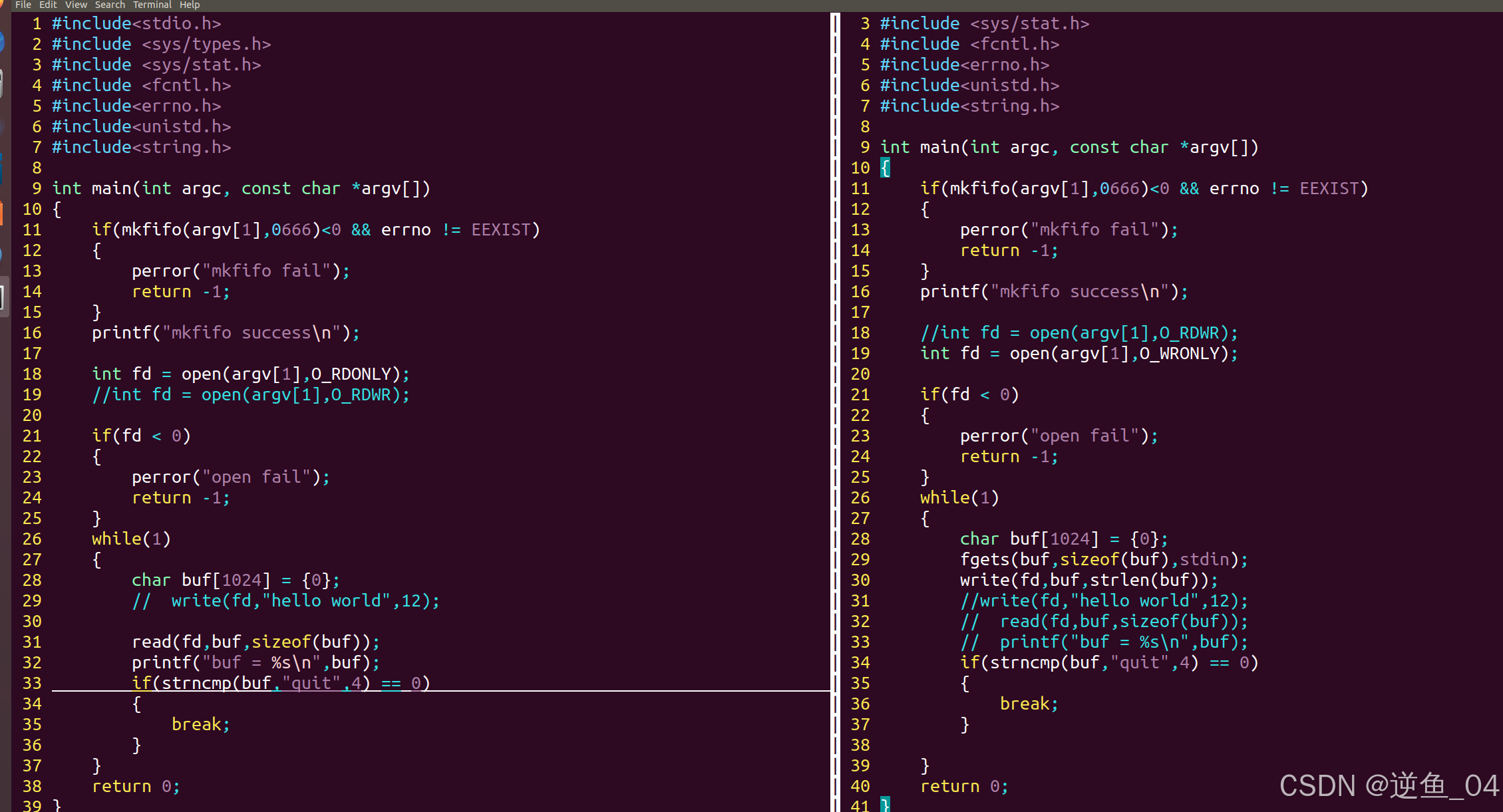
unxi-进程间通信
1.进程间通信实现方式 【1】同一主机 linux下通信方式: a.传统的进程间通信方式 管道 --- 进行数据传输的"管道" 无名管道 有名管道 信号 --- b.system v 进程间通信 (posix 进程间通信) 共享内存 (进程间…...

微型分组加密算法TEA、XTEA、XXTEA
微型分组加密算法TEA、XTEA、XXTEA TEA(Tiny Encryption Algorithm)算法是一种分组加密算法,由剑桥大学计算机实验室的David Wheeler和Roger Needham于1994年发明。TEA、XTEA、XXTEA算法采用64位的明文分组和128位的密钥。它使用Feistel…...

conda 基本命令
1、查询当前所有的环境 conda env list 2、创建虚拟环境 conda create -n 环境名 [pythonpython版本号] 其中[pythonpython版本号]可以不写 conda create -n test python3.12 我们输入conda env list看到我们的环境创建成功了,但是发现他是创建在我们默认的C盘的…...

详解 为什么 tcp 会出现 粘包 拆包 问题
TCP 会出现 粘包 和 拆包 问题,主要是因为 TCP 是 面向字节流 的协议,它不关心应用层发送的数据是否有边界,也不会自动分割或合并数据包。由于 TCP 的流控制和传输机制,数据可能在传输过程中被拆分成多个小的 TCP 包,或…...

Linus的基本命令
以下是一些常见的 Linux 命令: 一、文件和目录操作: - ls:列出目录中的文件和子目录,常用参数有 -a (显示所有文件,包括隐藏文件)、 -l (显示详细信息)、 -h ࿰…...

【Linux】缓冲区和文件系统
个人主页~ 缓冲区和文件系统 一、FILE结构1、fd2、缓冲区(一)有换行有return全部打印(二)无换行无return的C接口打印(三)无换行无return的系统调用接口打印(四)有换行无return的C接口…...

函数式编程:概念、特性与应用
1. 函数式编程简介 函数式编程,从名称上看就与函数紧密相关。它是一种我们常常使用却可能并未意识到的编程范式,关注代码的结构组织,强调一个纯粹但在实际中有些理想化的不可变世界,涉及数学、方程和副作用等概念,甚至…...

git中的merge和rebase的区别
在 Git 中,git merge 和 git rebase 都是用于整合分支变更的核心命令,但它们的实现方式和结果有本质区别。以下是两者的详细对比: 一、核心区别 特性git mergegit rebase历史记录保留分支拓扑,生成新的合并提交线性化历史&#x…...

【目标检测】目标检测中的数据增强终极指南:从原理到实战,用Python解锁模型性能提升密码(附YOLOv5实战代码)
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN…...

uniapp在app下使用mqtt协议!!!支持vue3
什么?打包空白?分享一下我的解决方法! 第一步 找大师算过了,装4.1版本运气好! 所以根目录执行命令… npm install mqtt4.1.0第二步 自己封装一个mqtt文件方便后期开坛做法! // utils/mqtt.js import mqt…...

VMware虚拟机17.5.2版本下载与安装(详细图文教程包含安装包)
文章目录 前言一、vmware虚拟机下载二、vmware虚拟机安装教程三、vmware虚拟机许可证 前言 VMware Workstation Pro 17 功能强大,广受青睐。本教程将带你一步步完成它的安装,简单易上手,助你快速搭建使用环境。 一、vmware虚拟机下载 VMwar…...

如何加固织梦CMS安全,防webshell、防篡改、防劫持,提升DedeCMS漏洞防护能力
织梦系统(DedeCMS)是一款非常知名的CMS系统,因其功能强大、结构科学合理,深受广大用户喜欢。 虽然织梦CMS(DedeCMS)非常优秀,但是为了保障网站安全,我们还是需要做一些必要的防护措…...

STM32的HAL库开发---ADC采集内部温度传感器
一、STM32内部温度传感器简介 二、温度计算方法 F1系列: 从数据手册中可以找到V25和Avg_Slope F4、F7、H7系列只是标准值不同,自行查阅手册 三、实验简要 1、功能描述 通过ADC1通道16采集芯片内部温度传感器的电压,将电压值换算成温度后&…...
)
Linux 命令大全完整版(12)
Linux 命令大全 5. 文件管理命令 ln(link) 功能说明:连接文件或目录。语 法:ln [-bdfinsv][-S <字尾备份字符串>][-V <备份方式>][--help][--version][源文件或目录][目标文件或目录] 或 ln [-bdfinsv][-S <字尾备份字符串>][-V…...

Python - 代码片段分享 - Excel 数据实时写入方法
文章目录 前言注意事项工具 pandas1. 简介2. 安装方式3. 简单介绍几个api 实战片段 - 实时写入Excel文件结束语 要么出众,要么出局 前言 我们在爬虫采集过程中,总是将数据解析抓取后统一写入Excel表格文件,如果在解析数据出现问题容易出现数据…...

(七)趣学设计模式 之 适配器模式!
目录 一、 啥是适配器模式?二、 为什么要用适配器模式?三、 适配器模式的实现方式1. 类适配器模式(继承插座 👨👩👧👦)2. 对象适配器模式(插座转换器 🔌…...

DeepSeek 细节之 MoE
DeepSeek 细节之 MoE DeepSeek 团队通过引入 MoE(Mixture of Experts,混合专家) 机制,以“分而治之”的思想,在模型容量与推理成本之间找到了精妙的平衡点,其中的技术实现和细节值得剖思 Transformer 演变…...

SAP Analysis Office 部署与维护实战指南
1. SAP Analysis Office 环境准备与兼容性检查 第一次部署SAP Analysis Office(AO)时,我遇到最头疼的问题就是环境兼容性。记得有次给客户装AO 2.8,装完才发现他们用的是Excel 2016最新版,结果插件根本加载不出来。后来…...

如何用Bulk Crap Uninstaller彻底清理Windows软件:免费高效的批量卸载工具指南
如何用Bulk Crap Uninstaller彻底清理Windows软件:免费高效的批量卸载工具指南 【免费下载链接】Bulk-Crap-Uninstaller Remove large amounts of unwanted applications quickly. 项目地址: https://gitcode.com/gh_mirrors/bu/Bulk-Crap-Uninstaller Bulk …...

从PC到手机:聊聊高通骁龙平台上的UEFI启动,和传统LK有啥不一样?
从PC到手机:高通骁龙平台UEFI启动架构深度解析 在移动设备启动流程的演进历程中,UEFI(统一可扩展固件接口)的引入堪称一场静默革命。作为曾经主导PC领域的启动标准,UEFI如今正在重塑Android设备的启动架构。对于熟悉Li…...

飞凌OK3568-C开发板音频调试实战:从DTS配置到amixer命令,搞定RK809 Codec录音放音
飞凌OK3568-C开发板音频调试实战:从DTS配置到amixer命令,搞定RK809 Codec录音放音 在嵌入式Linux开发中,音频功能的调试往往是让开发者头疼的环节之一。特别是当面对集成度高的PMIC芯片时,如何正确配置DTS、理解音频路径切换逻辑、…...

从零到精飞:APM多旋翼核心参数调校实战指南
1. APM飞控入门:从组装到基础参数设置 第一次接触APM飞控的新手常会被密密麻麻的参数表吓到。我刚开始调试植保无人机时,光是理解PID三个字母就花了整整一周。其实只要掌握核心逻辑,调参就像给汽车做四轮定位——有标准流程可循。 多旋翼飞控…...

别再被EMI困扰了!手把手教你理解并配置PCIE/SATA/USB3.0的SSC扩频时钟
高速接口EMI实战指南:SSC扩频时钟配置与参数优化 在硬件工程师的日常工作中,电磁干扰(EMI)问题就像一位不请自来的"隐形访客",总是在产品认证测试的关键时刻突然出现。特别是面对PCIE、SATA、USB3.0这类高速…...

【AGI能源治理黄金标准】:从IEEE P2857到中国《智能能源代理系统规范》强制实施前夜的关键适配指南
第一章:AGI能源治理黄金标准的全球演进与时代意义 2026奇点智能技术大会(https://ml-summit.org) 随着通用人工智能(AGI)从理论构想加速迈向系统级部署,其算力消耗已突破传统数据中心能效边界。全球头部研究机构与政策制定者正协…...

错过这轮AGI城市升级窗口期,你的城市将掉队至少7.2年——基于世界银行2023-2030跨区域效能衰减模型
第一章:AGI驱动的城市系统范式迁移 2026奇点智能技术大会(https://ml-summit.org) 传统城市操作系统依赖于预设规则、静态模型与人工干预的闭环控制逻辑,而AGI的深度认知能力、跨域泛化推理与实时因果建模,正从根本上重构城市系统的运行底层…...

Qwen3-VL-8B聊天系统应用:打造企业内部智能客服助手
Qwen3-VL-8B聊天系统应用:打造企业内部智能客服助手 1. 项目概述 Qwen3-VL-8B AI聊天系统是一款基于通义千问大语言模型的企业级智能对话解决方案。这个完整的Web应用系统集成了前端界面、反向代理服务器和vLLM推理后端,专为企业内部智能客服场景设计。…...

如何用键盘完全替代鼠标?Mouseable终极指南让你效率翻倍
如何用键盘完全替代鼠标?Mouseable终极指南让你效率翻倍 【免费下载链接】mouseable Mouseable is intended to replace a mouse or trackpad. 项目地址: https://gitcode.com/gh_mirrors/mo/mouseable 你是否曾经因为长时间使用鼠标而感到手腕酸痛ÿ…...