clickhouse--表引擎的使用
表引擎决定了如何存储表的数据。包括:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据。(默认是在安装路径下的 data 路径)
- 支持哪些查询以及如何支持。(有些语法只有在特定的引擎下才能用)
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关参数。
特别注意:引擎的名称大小写敏感, 驼峰命名。
①TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表,生产环境上作用有限。可以用于平时练习测试用。
如:
create table t_tinylog ( id String, name String) engine=TinyLog;
②Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过 10G/s)。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概 1 亿行)的场景。
③MergeTree
ClickHouse 中最强大的表引擎当属 MergeTree(合并树)引擎及该系列(*MergeTree)中的其他引擎,支持索引和分区,地位可以相当于 innodb 之于 Mysql。而且基于 MergeTree,还衍生除了很多小弟,也是非常有特色的引擎。
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
MergeTree 其实还有很多参数(绝大多数用默认值即可),但是三个参数是更加重要的,也涉及了关于 MergeTree 的很多概念。
- partition by 分区(可选)
-
作用
学过 hive 的应该都不陌生,分区的目的主要是降低扫描的范围,优化查询速度 -
如果不填
只会使用一个分区 —— all。 -
分区目录
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中。目录保存在本地磁盘 -
并行
分区后,面对涉及跨分区的查询统计,ClickHouse 会以分区为单位并行处理, 即一个线程处理一个分区内的数据。 -
数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作(等不及也可以手动通过 optimize 执行),把临时分区的数据,合并到已有分区中。
-
optimize table xxxx final;
- primary key 主键(可选)
ClickHouse 中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同 primary key 的数据的。
主键的设定主要依据是查询语句中的 where 条件。
根据条件通过对主键进行某种形式的二分查找,能够定位到对应的 index granularity,避免了全表扫描。
index granularity: 直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse 中的 MergeTree 默认是 8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。
稀疏索引:

- 稀疏索引的好处就是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行进行一点扫描。
-
order by(必选)
order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by 是 MergeTree 中唯一一个必填项,甚至比 primary key 还重要,因为当用户不设置主键的情况,很多处理会依照 order by 的字段进行处理(比如后面会讲的去重和汇总)。
要求:主键必须是 order by 字段的前缀字段。有点类似 SQL 索引中的最左前缀。
比如 order by 字段是 (id,sku_id) 那么主键必须是 id 或者(id,sku_id) -
二级索引(跳数索引)
目前在 ClickHouse 的官网上二级索引的功能在 v20.1.2.4 之前是被标注为实验性的,在这个版本之后默认是开启的。
老版本使用二级索引前需要增加设置
是否允许使用实验性的二级索引(v20.1.2.4 开始,这个参数已被删除,默认开启)。
set allow_experimental_data_skipping_indices=1;
创建测试表
create table t_order_mt2(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime,
INDEX a total_amount TYPE minmax GRANULARITY 5
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
最主要的是需要加上这一句:INDEX a total_amount TYPE minmax GRANULARITY 5
其中:
- INDEX a: 定义一个索引,并命名为 a
- total_amount: 索引字段名称
TYPE minmax: 定义类型, 保存最大最小值- GRANULARITY N:是设定二级索引对于一级索引粒度的粒度。一级索引会记录每个分区的最大最小值,二级索引就是在一级索引的基础上,取每 N 个分区合在一起的最大最小值。
- 数据 TTL(数据存活时间)
TTL 即 Time To Live,MergeTree 提供了可以管理数据表或者列的生命周期的功能。过期的数据不会立马处理,只是会做标记,等到合并时一起处理。
- 列级别 TTL
创建测试表
create table t_order_mt3(
id UInt32,
sku_id String,
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
在列后加上: TTL create_time+interval 10 SECOND,
其中:
- TTL:定义一个过期时间
- create_time:使用了当前表中的一个 Datetime 类型的列,TTL 中引用的字段不能是主键字段,且类型必须是 日期类型
- ± interval 10 SECOND:需要增加/减少的 时间长度 时间单位
注:如果在建表时没有加 TTL 配置,需要在建表之后加,那么则需要使用如下语法:
ALTER TABLE 表名MODIFY COLUMN列名 列数据类型 TTL d + INTERVAL 10 SECOND;
- 表级 TTL
与列级相同,在建表时与建表之后都有对应的语法进行设置。
(1)在建表时,写在 Order By 的后面
CREATE TABLE example_table
(d DateTime,a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH [DELETE],d + INTERVAL 1 WEEK TO VOLUME 'aaa',d + INTERVAL 2 WEEK TO DISK 'bbb';
该示例中的 [DELETE]、TO VOLUME……在下文"注意"中说明。
(2)在建表之后,使用 alter
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
表级的 TTL ,如果是按照表中字段值判断是否过期,那么不会整表删除,只会是某一行数据到期删某一行。
注意
涉及判断的字段必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
能够使用的时间单位:
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER YEAR
上文提到的 [DELETE]、TO VOLUME…… 表示的是过期之后,需要做的操作。可选的配置如下
- DELETE - 删除数据 (默认,不配置则删除);
- RECOMPRESS codec_name - 使用codec_name重新压缩数据部分;
- TO DISK ‘aaa’ - 将数据移动到磁盘 aaa 上
- TO VOLUME ‘bbb’ - 将数据移动到磁盘 bbb 上
- GROUP BY - 聚合过期行.
④ReplacingMergeTree
ReplacingMergeTree 是 MergeTree 的一个变种,它存储特性完全继承 MergeTree,只是多了一个去重的功能。 尽管 MergeTree 可以设置主键,但是 primary key 其实没有唯一约束的功能。如果你想处理掉重复的数据,可以借助这个 ReplacingMergeTree。去重按照order by的字段去重
-
去重时机
数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。 -
去重范围
如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重。
所以 ReplacingMergeTree 能力有限, ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
案例演示
创建表
create table t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
ReplacingMergeTree() 填入的参数为版本字段,重复数据保留版本字段值最大的。如果不填版本字段,默认按照插入顺序保留最后一条。
通过测试得到结论
实际上是使用 order by 字段作为唯一键
去重不能跨分区
只有同一批插入(新版本)或合并分区时才会进行去重
认定重复的数据保留,版本字段值最大的
如果版本字段相同则按插入顺序保留最后一笔
⑤ SummingMergeTree
对于不查询明细,只关心以维度进行汇总聚合结果的场景。如果只使用普通的MergeTree的话,无论是存储空间的开销,还是查询时临时聚合的开销都比较大。
ClickHouse 为了这种场景,提供了一种能够“预聚合”的引擎 SummingMergeTree。该引擎聚合的依据依然是 order by 的字段,相当于按照 order by 的字段做了一次 Group By。
案例演示
创建表
create table t_order_smt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =SummingMergeTree(total_amount)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id );
通过结果可以得到以下结论
- 以 SummingMergeTree()中指定的列作为汇总数据列
- 可以填写多列必须数字列,如果不填,以所有非维度列且为数字列的字段为汇总数据列
- 以 order by 的列为准,作为维度列
- 其他的列按插入顺序保留第一行
- 不在一个分区的数据不会被聚合
- 只有在同一批次插入(新版本)或分片合并时才会进行聚合
开发建议
设计聚合表的话,唯一键值、流水号可以去掉,所有字段全部是维度、度量或者时间戳。
问题
能不能直接执行以下 SQL 得到汇总值?
select total_amount from XXX where province_name=’’ and create_date=’xxx’
答:
不行,可能会包含一些还没来得及聚合的临时明细
如果要是获取汇总值,还是需要使用 sum 进行聚合,这样效率会有一定的提高,但本身 ClickHouse 是列式存储的,效率提升有限,不会特别明显。
select sum(total_amount) from province_name=’’ and create_date=‘xxx’
总结

相关文章:
clickhouse--表引擎的使用
表引擎决定了如何存储表的数据。包括: 数据的存储方式和位置,写到哪里以及从哪里读取数据。(默认是在安装路径下的 data 路径)支持哪些查询以及如何支持。(有些语法只有在特定的引擎下才能用)并发数据访问。索引的使用࿰…...

LeetCode刷题零碎知识点整理
系列博客目录 文章目录 系列博客目录 数组变量有length属性,String类的对象有length()方法。String s; s.split("\\s");不能去除头部空格,需要使用s s.trim();String类的对象有toCharArray()方法,List<>类型有toArray()方法…...

GLTFLoader.js和OrbitControls.js两个 JavaScript 文件都是 Three.js 生态系统中的重要组成部分
GLTFLoader.js和OrbitControls.js两个 JavaScript 文件都是 Three.js 生态系统中的重要组成部分: 1. GLTFLoader.js 作用 GLTFLoader.js 是 Three.js 库中的一个辅助加载器脚本,其主要功能是加载 GLB 或 GLTF 格式的 3D 模型。GLTF(GL Tra…...

大厂数据仓库数仓建模面试题及参考答案
目录 什么是数据仓库,和数据库有什么区别? 数据仓库的基本原理是什么? 数据仓库架构是怎样的? 数据仓库分层(层级划分),每层做什么?分层的好处是什么?数据分层是根据什么?数仓分层的原则与思路是什么? 数仓建模常用模型有哪些?区别、优缺点是什么?星型模型和雪…...

angular简易计算器
说明: 用angular实现计算器效果,ui风格为暗黑 效果图: step1: C:\Users\Administrator\WebstormProjects\untitled4\src\app\calnum\calnum.component.ts import { Component } from angular/core;Component({selector: app-calnum,import…...

谈谈 ES 6.8 到 7.10 的功能变迁(3)- 查询方法篇
上一篇咱们了解了 ES 7.10 相较于 ES 6.8 新增的字段类型,这一篇我们继续了解新增的查询方法。 Interval 间隔查询: 功能介绍 Interval 查询,词项间距查询,可以根据匹配词项的顺序、间距和接近度对文档进行排名。主要解决的查询…...

16、Python面试题解析:python中的浅拷贝和深拷贝
在 Python 中,浅拷贝(Shallow Copy) 和 深拷贝(Deep Copy) 是处理对象复制的两种重要机制,它们的区别主要体现在对嵌套对象的处理方式上。以下是详细解析: 1. 浅拷贝(Shallow Copy&a…...

游戏引擎学习第119天
仓库:https://gitee.com/mrxiao_com/2d_game_3 上一集回顾和今天的议程 如果你们还记得昨天的进展,我们刚刚完成了优化工作,目标是让某个程序能够尽可能快速地运行。我觉得现在可以说它已经快速运行了。虽然可能还没有达到最快的速度,但我们…...

爬虫解析库:Beautiful Soup的详细使用
文章目录 1. 安装 Beautiful Soup2. 基本用法3. 选择元素4. 提取数据5. 遍历元素6. 修改元素7. 搜索元素8. 结合 requests 使用9. 示例:抓取并解析网页10. 注意事项 Beautiful Soup 是一个用于解析 HTML 和 XML 文档的 Python 库,它提供了简单易用的 API…...

OpenHarmony-4.基于dayu800 GPIO 实践(2)
基于dayu800 GPIO 进行开发 1.DAYU800开发板硬件接口 LicheePi 4A 板载 2x10pin 插针,其中有 16 个原生 IO,包括 6 个普通 IO,3 对串口,一个 SPI。TH1520 SOC 具有4个GPIO bank,每个bank最大有32个IO: …...

【C++设计模式】观察者模式(1/2):从基础到优化实现
1. 引言 在 C 软件与设计系列课程中,观察者模式是一个重要的设计模式。本系列课程旨在深入探讨该模式的实现与优化。在之前的课程里,我们已对观察者模式有了初步认识,本次将在前两次课程的基础上,进一步深入研究,着重…...

《机器学习数学基础》补充资料:欧几里得空间的推广
在《机器学习数学基础》第 1 章介绍了向量空间,并且说明了机器学习问题通常是在欧几里得空间。然而,随着机器学习技术的发展,特别是 AI 技术开始应用于科学研究中,必然会涉及到其他类型的空间。本文即在《机器学习数学基础》一书所…...
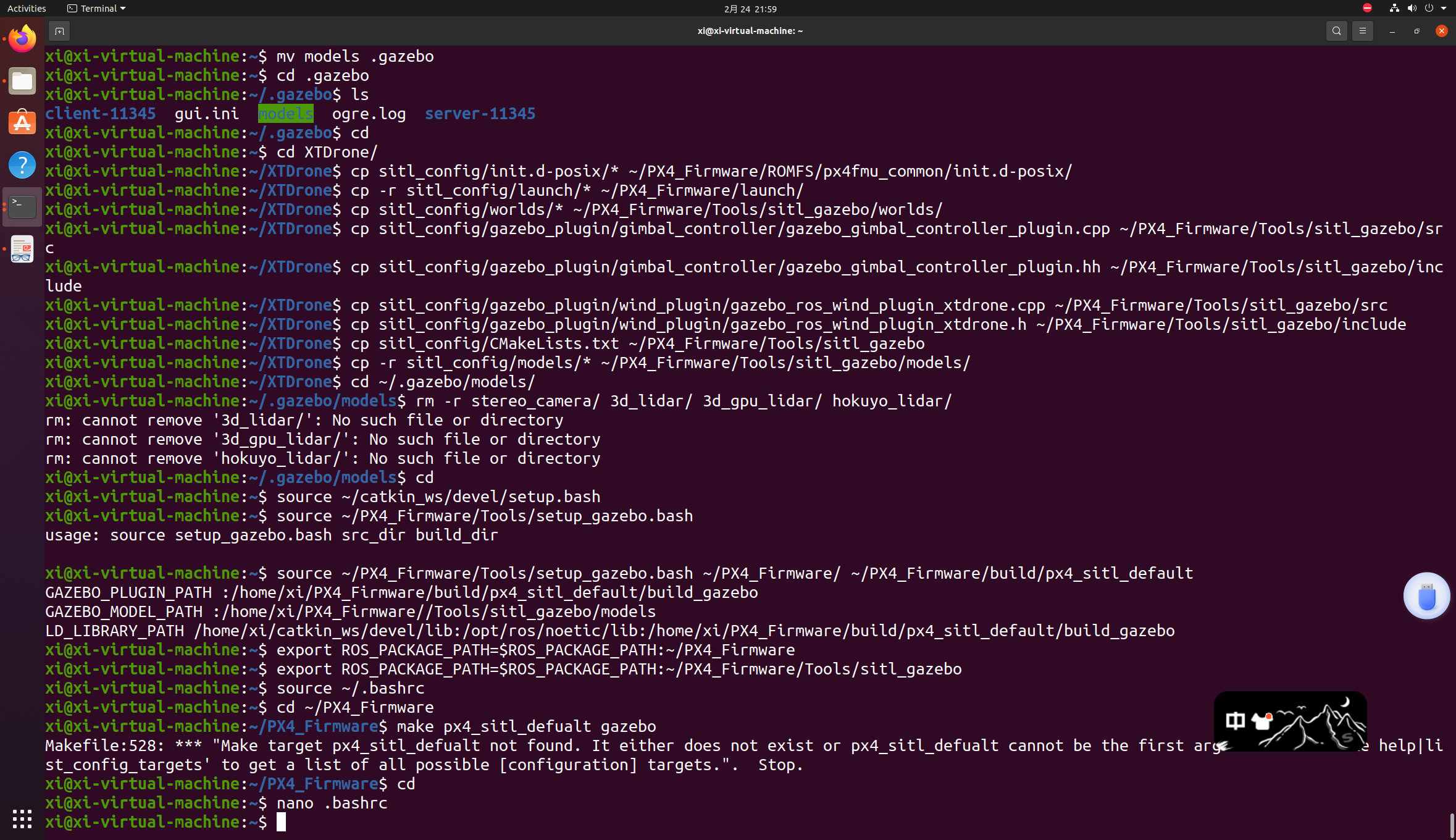
在配置PX4中出现的问题2
想要原教程的请看:第一次配置中出现的问题 前面一切正常(gazebo导入models那一步在刚刚解压好的文件夹里就删不掉stereo_camera等文件,ls打开也看不到,应该时我下的包里面本来就没有),到 make px4_sitl_def…...
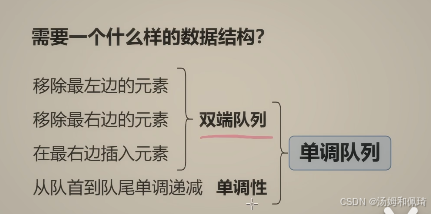
2025-2-24-4.9 单调栈与单调队列(基础题)
文章目录 4.9 单调栈与单调队列(基础题)单调栈739. 每日温度42. 接雨水单调队列239. 滑动窗口最大值 4.9 单调栈与单调队列(基础题) 很有趣的两个数据结构。 原视频讲解链接 单调栈 739. 每日温度 题目链接 给定一个整数数组 te…...

python绘图之swarmplot分布散点图
swarmplot 是 Seaborn 提供的一种用于展示分类数据分布的散点图。它的主要作用是将数据点按照分类变量(通常是离散变量)进行分组,并在每个分类中以一种非重叠的方式展示数据点的位置。这种可视化方式可以帮助我们直观地理解数据在不同分类下的…...
)
数据库之MySQL——事务(一)
1、MySQL之事务的四大特性(ACID)? 原子性(atomicity):一个事务必须视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操…...

Linux学习笔记之文件
1.文件 1.1文件属性 当我们创建文件时,文件就有了对应的属性,可以用mkdir创建目录,touch创建普通文件。用ls -al查看文件属性。 从上图可以看出目录或者文件的所有者,所属组,其他人权限,创建时间等信息。由…...

LLM学习
1、基础概念篇 大模型训练三部曲Pretraining SFT RLHF...
Classic Control Theory | 13 Complex Poles or Zeros (第13课笔记-中文版)
笔记链接:https://m.tb.cn/h.TtdexbP?tkeFAlejKBSzQhttps://m.tb.cn/h.TtdexbP?tkeFAlejKBSzQ...

给小米/红米手机root(工具基本为官方工具)——KernelSU篇
目录 前言准备工作下载刷机包xiaomirom下载刷机包【适用于MIUI和hyperOS】“hyper更新”微信小程序【只适用于hyperOS】 下载KernelSU刷机所需程序和驱动文件 开始刷机设置手机第一种刷机方式【KMI】推荐提取boot或init_boot分区 第二种刷机方式【GKI】不推荐 结语 前言 刷机需…...

SketchUp场景卡顿救星:用‘组件’和‘面片植物’优化大型场景的实战技巧
SketchUp大型场景优化实战:用组件与面片植物打造流畅工作流 当你的SketchUp模型开始像老式拖拉机一样嘎吱作响,旋转视图时卡成PPT,是时候重新思考建模策略了。我曾参与过一个占地12公顷的度假村项目,初始模型包含2000多棵3D树木和…...
)
别再为模型部署发愁了!手把手教你用torch.onnx.export把PyTorch模型转成ONNX(附常见报错解决)
从PyTorch到ONNX:模型部署实战指南与避坑手册 为什么ONNX成为模型部署的首选桥梁? 在深度学习项目的生命周期中,训练出一个高精度的模型只是完成了第一步。真正让模型产生商业价值的,是将它成功部署到生产环境中。而ONNXÿ…...

3小时变3分钟:Dify Workflow可视化开发终极指南
3小时变3分钟:Dify Workflow可视化开发终极指南 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Dify-Workfl…...

Manjaro新手避坑指南:从依赖缺失到签名错误,一次搞定所有安装报错
Manjaro新手避坑指南:从依赖缺失到签名错误,一次搞定所有安装报错 第一次打开Manjaro的终端,输入sudo pacman -S命令时,那种期待和忐忑交织的感觉我还记得很清楚。作为一个刚从Ubuntu转投Arch系的新手,我完全没预料到接…...

ZVS和ZCS到底怎么选?从无线充电和服务器电源两个真实案例,聊聊软开关技术的选型逻辑
ZVS与ZCS技术选型实战指南:从无线充电到服务器电源的设计哲学 在功率电子设计领域,工程师们常常面临一个关键抉择:选择零电压开关(ZVS)还是零电流开关(ZCS)?这个看似简单的技术决策&…...

USB-Disk-Ejector:重新定义Windows设备管理的终极革命
USB-Disk-Ejector:重新定义Windows设备管理的终极革命 【免费下载链接】USB-Disk-Ejector A program that allows you to quickly remove drives in Windows. It can eject USB disks, Firewire disks and memory cards. It is a quick, flexible, portable alterna…...

从不确定性到规律:随机信号的统计建模与工程应用
1. 随机信号:从噪声中寻找规律 第一次接触随机信号时,我盯着示波器上跳动的曲线发懵——这看起来就像一堆杂乱无章的毛线团。但导师告诉我:"这些看似混乱的波形里藏着宝藏,关键是要找到正确的解码方式。"十年后我才真正…...

51单片机按键控制LED的两种编程思路对比:数组映射 vs Switch语句,哪种更适合你?
51单片机按键控制LED的两种编程范式深度解析:数组映射与Switch语句的工程实践 当你在深夜调试一块布满LED的51单片机开发板时,是否曾为按键控制逻辑的代码结构纠结过?作为经历过数十个嵌入式项目的开发者,我发现数组映射和switch-…...

Matlab函数传参和返回值的‘黑魔法’:巧用逗号分隔列表处理可变参数
Matlab函数传参和返回值的‘黑魔法’:巧用逗号分隔列表处理可变参数 在Matlab编程中,处理可变数量的输入参数和返回值是每个中高级用户都会遇到的挑战。想象一下,当你需要设计一个像plot那样灵活的函数,能够接受任意数量的属性-值…...

深度解析:基于深度学习的远程生理信号监测技术实现与架构设计
深度解析:基于深度学习的远程生理信号监测技术实现与架构设计 【免费下载链接】rppg Benchmark Framework for fair evaluation of rPPG 项目地址: https://gitcode.com/gh_mirrors/rpp/rppg 远程光电生理信号监测(rPPG)技术通过分析面…...