Python常见面试题的详解24
1. 如何对关键词触发模块进行测试
- 要点
-
功能测试:验证正常关键词触发、边界情况及大小写敏感性,确保模块按预期响应不同输入。
-
性能测试:关注响应时间和并发处理能力,保证模块在不同负载下的性能表现。
-
兼容性测试:测试不同输入方式、操作系统和浏览器下模块的工作情况,提升其通用性。
python
import time
import threading# 关键词触发模块示例
keyword_mapping = {"hello": "Hello! How can I help you?","bye": "Goodbye! Have a nice day."
}def keyword_trigger(keyword):if keyword in keyword_mapping:return keyword_mapping[keyword]return "No relevant response."# 功能测试 - 正常关键词触发
def test_normal_trigger():test_keyword = "hello"result = keyword_trigger(test_keyword)print(f"Testing normal keyword '{test_keyword}': {result}")# 功能测试 - 边界情况测试(假设关键词长度范围 1 - 10)
def test_boundary_trigger():short_keyword = "a"long_keyword = "a" * 10print(f"Testing short keyword '{short_keyword}': {keyword_trigger(short_keyword)}")print(f"Testing long keyword '{long_keyword}': {keyword_trigger(long_keyword)}")# 功能测试 - 大小写敏感性测试
def test_case_sensitivity():test_keyword = "Hello"result = keyword_trigger(test_keyword)print(f"Testing case - sensitive keyword '{test_keyword}': {result}")# 性能测试 - 响应时间测试
def test_response_time():test_keyword = "bye"start_time = time.time()response = keyword_trigger(test_keyword)end_time = time.time()print(f"Response time for keyword '{test_keyword}': {end_time - start_time} seconds")# 性能测试 - 并发测试
def concurrent_trigger(keyword):result = keyword_trigger(keyword)print(f"Concurrent test result for '{keyword}': {result}")def test_concurrency():threads = []keyword = "hello"for _ in range(10): # 模拟 10 个并发请求thread = threading.Thread(target=concurrent_trigger, args=(keyword,))threads.append(thread)thread.start()for thread in threads:thread.join()# 兼容性测试 - 模拟不同输入方式(文件输入)
def test_compatibility_file_input():with open('test_keywords.txt', 'w') as f:f.write("hello\nbye")with open('test_keywords.txt', 'r') as f:for line in f:keyword = line.strip()result = keyword_trigger(keyword)print(f"Testing keyword from file '{keyword}': {result}")if __name__ == "__main__":test_normal_trigger()test_boundary_trigger()test_case_sensitivity()test_response_time()test_concurrency()test_compatibility_file_input()
- 补充知识点
-
可以引入更多的关键词规则,如支持关键词的模糊匹配,使用正则表达式来处理更复杂的关键词匹配逻辑。
-
对于并发测试,可以使用专业的性能测试工具如
locust进行更全面的性能分析,模拟大量用户的并发请求。 -
在兼容性测试方面,可以进一步测试不同编码格式的文件输入,以及在不同 Python 版本下的兼容性。
2. 说明测试人员在软件开发过程中的任务
- 要点
-
需求分析阶段:参与评审,从测试角度确保需求完整、准确、可测试,并理解软件功能与非功能需求。
-
测试计划阶段:制定测试计划,明确范围、方法、进度,确定所需资源。
-
测试设计阶段:依据需求和设计文档设计全面的测试用例,准备各类测试数据。
-
测试执行阶段:执行用例,记录结果,发现并跟踪缺陷,推动问题解决。
-
测试总结阶段:分析结果,评估软件质量,编写详细测试报告。
python
import datetime# 模拟测试计划制定
class TestPlan:def __init__(self, scope, method, schedule, resources):self.scope = scopeself.method = methodself.schedule = scheduleself.resources = resourcesdef print_plan(self):print(f"Test Scope: {self.scope}")print(f"Test Method: {self.method}")print(f"Test Schedule: {self.schedule}")print(f"Test Resources: {self.resources}")# 模拟测试用例设计
class TestCase:def __init__(self, case_id, description, input_data, expected_output):self.case_id = case_idself.description = descriptionself.input_data = input_dataself.expected_output = expected_outputdef print_case(self):print(f"Test Case ID: {self.case_id}")print(f"Description: {self.description}")print(f"Input Data: {self.input_data}")print(f"Expected Output: {self.expected_output}")# 模拟测试执行和结果记录
class TestExecution:def __init__(self, test_case):self.test_case = test_caseself.actual_output = Noneself.result = Noneself.execution_time = Nonedef execute(self):# 这里简单模拟执行,实际中应调用被测试的功能self.actual_output = f"Simulated output for {self.test_case.input_data}"self.result = self.actual_output == self.test_case.expected_outputself.execution_time = datetime.datetime.now()print(f"Test Case ID: {self.test_case.case_id}, Result: {'Pass' if self.result else 'Fail'}")# 模拟测试总结
class TestSummary:def __init__(self, test_executions):self.test_executions = test_executionsself.passed_count = sum([1 for exec in test_executions if exec.result])self.failed_count = len(test_executions) - self.passed_countdef print_summary(self):print(f"Total Test Cases: {len(self.test_executions)}")print(f"Passed: {self.passed_count}")print(f"Failed: {self.failed_count}")print("Overall Software Quality: Good" if self.failed_count == 0 else "Needs Improvement")# 制定测试计划
scope = "User registration and login functions"
method = "Functional testing"
schedule = "Week 1 - Design test cases, Week 2 - Execute tests"
resources = "Test environment: Local server, Test tools: Selenium"
test_plan = TestPlan(scope, method, schedule, resources)
test_plan.print_plan()# 设计测试用例
test_case_1 = TestCase(1, "Register a new user", {"username": "testuser", "password": "testpass"}, "Registration successful")
test_case_2 = TestCase(2, "Login with valid credentials", {"username": "testuser", "password": "testpass"}, "Login successful")
test_case_1.print_case()
test_case_2.print_case()# 执行测试用例
executions = []
for test_case in [test_case_1, test_case_2]:execution = TestExecution(test_case)execution.execute()executions.append(execution)# 测试总结
summary = TestSummary(executions)
summary.print_summary()
- 补充知识点
-
可以将测试计划、用例、执行结果等信息存储到数据库中,方便进行更复杂的管理和查询。
-
引入测试框架如
unittest或pytest来更规范地组织和执行测试用例。 -
在测试总结阶段,可以生成更详细的报告,如 HTML 格式的报告,包含每个测试用例的详细信息和统计图表。
3. 一条软件 Bug 记录都包含了哪些内容?
- 要点
软件 Bug 记录涵盖基本信息(编号、标题、发现时间、发现人)、问题描述(重现步骤、实际结果、预期结果)、环境信息(操作系统、浏览器等)、严重程度和优先级,还可附带相关附件。
python
import datetimeclass BugRecord:def __init__(self, bug_id, title, found_time, finder, steps, actual_result, expected_result, os, browser, severity, priority, attachments=None):self.bug_id = bug_idself.title = titleself.found_time = found_timeself.finder = finderself.steps = stepsself.actual_result = actual_resultself.expected_result = expected_resultself.os = osself.browser = browserself.severity = severityself.priority = priorityself.attachments = attachments if attachments else []def print_bug_record(self):print(f"Bug ID: {self.bug_id}")print(f"Title: {self.title}")print(f"Found Time: {self.found_time}")print(f"Finder: {self.finder}")print(f"Steps to Reproduce: {self.steps}")print(f"Actual Result: {self.actual_result}")print(f"Expected Result: {self.expected_result}")print(f"Operating System: {self.os}")print(f"Browser: {self.browser}")print(f"Severity: {self.severity}")print(f"Priority: {self.priority}")if self.attachments:print(f"Attachments: {', '.join(self.attachments)}")# 创建一个 Bug 记录
bug = BugRecord(bug_id=1,title="Login button not working",found_time=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),finder="John",steps="Open the website -> Click on the login button",actual_result="Nothing happens when clicking the login button",expected_result="The login form should pop - up",os="Windows 10",browser="Chrome",severity="High",priority="High",attachments=["screenshot.png"]
)
bug.print_bug_record()
- 补充知识点
-
可以实现一个 Bug 管理系统,将 Bug 记录存储到数据库中,支持 Bug 的添加、修改、删除、查询等操作。
-
为 Bug 记录添加更多的状态信息,如已分配、已修复、已验证等,方便跟踪 Bug 的处理流程。
-
可以通过邮件或消息通知机制,及时将 Bug 的状态变化通知相关人员。
4. 说明黑盒测试和白盒测试的优缺点
- 要点
-
黑盒测试:优点是不依赖代码、从用户角度测试、适用于各种软件;缺点是难以发现内部缺陷、测试用例设计困难、无法进行覆盖测试。
-
白盒测试:优点是能发现内部缺陷、可进行覆盖测试、有助于代码优化;缺点是依赖代码、测试成本高、不能完全保证功能正确性。
python
import unittest
import coverage# 示例函数
def add_numbers(a, b):return a + b# 黑盒测试示例
class BlackBoxTest(unittest.TestCase):def test_add_numbers(self):test_inputs = [(1, 2), (0, 0), (-1, 1)]for input_pair in test_inputs:result = add_numbers(*input_pair)expected = input_pair[0] + input_pair[1]self.assertEqual(result, expected)# 白盒测试示例
# 这里使用 coverage.py 来统计代码覆盖率
cov = coverage.Coverage()
cov.start()suite = unittest.TestSuite()
suite.addTest(BlackBoxTest("test_add_numbers"))
runner = unittest.TextTestRunner()
runner.run(suite)cov.stop()
cov.report()
- 补充知识点
-
对于黑盒测试,可以使用数据驱动测试的方法,通过读取外部数据文件(如 CSV、JSON)来生成更多的测试用例。
-
白盒测试方面,可以结合静态代码分析工具如
pylint或flake8来发现代码中的潜在问题。 -
可以使用更复杂的测试框架和工具,如
pytest来提高测试效率和可维护性。
5. 请列出至少 5 项你所知道的软件测试种类
- 要点
常见软件测试种类包括功能测试、性能测试、兼容性测试、安全测试、易用性测试、可靠性测试、单元测试、集成测试、系统测试和验收测试。
python
import unittest
import time# 示例函数
def multiply_numbers(a, b):return a * b# 功能测试示例
class FunctionalTest(unittest.TestCase):def test_multiply(self):test_inputs = [(2, 3), (0, 5), (-1, 4)]for input_pair in test_inputs:result = multiply_numbers(*input_pair)expected = input_pair[0] * input_pair[1]self.assertEqual(result, expected)# 性能测试示例
def performance_test():start_time = time.time()for _ in range(1000):multiply_numbers(2, 3)end_time = time.time()print(f"Performance test: {end_time - start_time} seconds for 1000 calls")# 单元测试示例
if __name__ == '__main__':suite = unittest.TestSuite()suite.addTest(FunctionalTest("test_multiply"))runner = unittest.TextTestRunner()runner.run(suite)performance_test()
- 补充知识点
-
对于性能测试,可以使用专业的性能测试工具如
locust或JMeter来模拟大量用户的并发请求,进行更全面的性能分析。 -
兼容性测试可以使用
Selenium框架来测试不同浏览器和操作系统下的软件表现。 -
安全测试可以使用
OWASP ZAP等工具来检测软件的安全漏洞。
6. 说明Alpha 测试与 Beta 测试的区别
- 要点
-
Alpha 测试:在开发或内部测试环境进行,由开发团队或内部人员执行,目的是全面测试和调试软件。
-
Beta 测试:在实际用户环境进行,由真实用户参与,重点是收集用户反馈和发现实际使用中的问题。
python
# 示例软件功能
def software_function(data):return data.upper()# Alpha 测试
alpha_testers = ["Alice", "Bob"]
alpha_test_data = ["hello", "world"]
alpha_results = []
for tester in alpha_testers:for data in alpha_test_data:result = software_function(data)alpha_results.append((tester, data, result))print(f"Alpha Test by {tester} - Input: {data}, Output: {result}")# Beta 测试
beta_users = ["Eve", "Charlie"]
beta_test_data = ["python", "programming"]
beta_feedbacks = []
for user in beta_users:for data in beta_test_data:result = software_function(data)feedback = input(f"Beta Test by {user} - Input: {data}, Output: {result}. Please provide feedback: ")beta_feedbacks.append((user, data, result, feedback))print(f"Feedback from {user}: {feedback}")# 分析测试结果
print("\nAlpha Test Results:")
for tester, data, result in alpha_results:print(f"{tester} - Input: {data}, Output: {result}")print("\nBeta Test Feedbacks:")
for user, data, result, feedback in beta_feedbacks:print(f"{user} - Input: {data}, Output: {result}, Feedback: {feedback}")
- 补充知识点
-
可以使用数据库来存储 Alpha 测试和 Beta 测试的结果和反馈,方便进行数据分析和统计。
-
开发一个简单的 Web 界面,让用户更方便地参与 Beta 测试和提交反馈。
-
对反馈进行分类和整理,使用自然语言处理技术来分析用户反馈,提取有价值的信息。
7. 什么是 Bug?一个 bug report 应包含哪些关键字
- 要点
Bug 是软件不符合预期行为的问题,如电商网站购物车数量更新问题。Bug 报告应包含重现步骤、实际结果、预期结果、严重程度、优先级和环境信息等关键字。
python
# 示例函数,存在 Bug
def divide_numbers(a, b):return a / b# 发现 Bug
try:result = divide_numbers(5, 0)
except ZeroDivisionError:# 模拟 Bug 报告bug_report = {"重现步骤": "调用 divide_numbers 函数,传入参数 (5, 0)","实际结果": "抛出 ZeroDivisionError 异常","预期结果": "应该给出合理的错误提示,而不是抛出异常","严重程度": "高","优先级": "高","环境信息": "Python 3.10"}for
8. 如何找出数组中出现次数超过一半的数字
- 要点
此问题可以使用摩尔投票法来高效解决。其核心思路是在遍历数组的过程中,维护一个候选元素和一个计数。当计数为 0 时,更换候选元素;若当前元素与候选元素相同则计数加 1,不同则减 1。由于目标数字出现次数超过一半,最后剩下的候选元素即为所求。
python
def majorityElement(nums):# 初始化计数为 0count = 0# 初始化候选元素为 Nonecandidate = None# 遍历数组中的每个数字for num in nums:# 当计数为 0 时,更新候选元素为当前数字if count == 0:candidate = num# 如果当前数字等于候选元素,计数加 1if num == candidate:count += 1# 否则计数减 1else:count -= 1return candidate# 测试示例
nums = [3, 2, 3]
print(majorityElement(nums))
- 补充知识点
1. 输入验证:在函数开始处添加对输入数组的验证,确保数组不为空。
python
def majorityElement(nums):if not nums:return Nonecount = 0candidate = Nonefor num in nums:if count == 0:candidate = numif num == candidate:count += 1else:count -= 1return candidate
2. 其他方法实现:可以使用哈希表来统计每个数字出现的次数,然后找出出现次数超过一半的数字。
python
def majorityElement(nums):num_count = {}for num in nums:if num in num_count:num_count[num] += 1else:num_count[num] = 1half_length = len(nums) // 2for num, count in num_count.items():if count > half_length:return numreturn None
9. 如何求 100 以内的质数
- 要点
质数是指大于 1 且只能被 1 和自身整除的正整数。判断一个数是否为质数,可以检查它是否能被 2 到其平方根之间的数整除。通过遍历 2 到 100 的每个数,利用质数判断函数找出所有质数。
python
def is_prime(num):# 小于 2 的数不是质数if num < 2:return False# 检查从 2 到 num 的平方根之间的数是否能整除 numfor i in range(2, int(num**0.5) + 1):if num % i == 0:return Falsereturn True# 使用列表推导式找出 100 以内的质数
primes = [i for i in range(2, 101) if is_prime(i)]
print(primes)
- 补充知识点
1. 指定范围的质数查找:将代码封装成函数,接受起始和结束范围作为参数,以查找指定范围内的质数。
python
def find_primes_in_range(start, end):def is_prime(num):if num < 2:return Falsefor i in range(2, int(num**0.5) + 1):if num % i == 0:return Falsereturn Truereturn [i for i in range(start, end + 1) if is_prime(i)]# 测试示例
print(find_primes_in_range(10, 50))
2. 埃拉托斯特尼筛法:这是一种更高效的质数筛选算法。
python
def sieve_of_eratosthenes(n):primes = [True] * (n + 1)p = 2while p * p <= n:if primes[p]:for i in range(p * p, n + 1, p):primes[i] = Falsep += 1result = []for p in range(2, n + 1):if primes[p]:result.append(p)return resultprint(sieve_of_eratosthenes(100))
10. 如何实现无重复字符的最长子串
- 要点
使用滑动窗口和哈希表来解决此问题。滑动窗口由左右指针界定,哈希表用于记录每个字符最后出现的位置。遍历字符串时,若遇到重复字符且该字符在当前窗口内,移动左指针到重复字符的下一个位置,同时更新哈希表和最大长度。
python
def lengthOfLongestSubstring(s):# 初始化哈希表,用于记录字符及其最后出现的位置char_index_map = {}# 初始化左指针为 0left = 0# 初始化最大长度为 0max_length = 0# 遍历字符串,右指针从 0 开始for right in range(len(s)):# 如果当前字符在哈希表中,且其最后出现的位置在左指针及之后if s[right] in char_index_map and char_index_map[s[right]] >= left:# 移动左指针到重复字符的下一个位置left = char_index_map[s[right]] + 1# 更新当前字符的最后出现位置char_index_map[s[right]] = right# 计算当前窗口的长度current_length = right - left + 1# 更新最大长度max_length = max(max_length, current_length)return max_length# 测试示例
s = "abcabcbb"
print(lengthOfLongestSubstring(s))
- 补充知识点
1. 优化空间复杂度:可以使用一个固定大小的数组来代替哈希表,以减少空间开销。
python
def lengthOfLongestSubstring(s):char_index = [-1] * 128left = 0max_length = 0for right in range(len(s)):index = ord(s[right])if char_index[index] >= left:left = char_index[index] + 1char_index[index] = rightmax_length = max(max_length, right - left + 1)return max_length
2. 返回最长子串:对代码进行扩展,不仅返回最长子串的长度,还返回具体的最长子串。
python
def lengthOfLongestSubstring(s):char_index_map = {}left = 0max_length = 0start = 0for right in range(len(s)):if s[right] in char_index_map and char_index_map[s[right]] >= left:left = char_index_map[s[right]] + 1char_index_map[s[right]] = rightcurrent_length = right - left + 1if current_length > max_length:max_length = current_lengthstart = leftreturn s[start:start + max_length]s = "abcabcbb"
print(lengthOfLongestSubstring(s))
11. 如何通过 2 个 5升和6 升的水壶从池塘得到 3 升水
- 要点
通过一系列倒水操作,利用 5 升和 6 升水壶的容量差,逐步调整两个水壶中的水量,最终在 6 升水壶中得到 3 升水。关键在于合理规划每次倒水的动作。
python
# 初始化 5 升水壶的水量为 0
jug_5 = 0
# 初始化 6 升水壶的水量为 0
jug_6 = 0
# 用于记录操作步骤的列表
steps = []# 开始操作,直到 6 升水壶中有 3 升水
while jug_6 != 3:if jug_6 == 0:# 如果 6 升水壶为空,将其装满jug_6 = 6steps.append("Fill the 6 - liter jug")elif jug_5 == 5:# 如果 5 升水壶已满,将其倒掉jug_5 = 0steps.append("Empty the 5 - liter jug")elif jug_6 > 0 and jug_5 < 5:# 如果 6 升水壶有水且 5 升水壶未满,从 6 升水壶向 5 升水壶倒水pour = min(5 - jug_5, jug_6)jug_5 += pourjug_6 -= poursteps.append(f"Pour water from the 6 - liter jug to the 5 - liter jug: {pour} liters")# 输出操作步骤
for step in steps:print(step)
print(f"Finally, the 6 - liter jug contains {jug_6} liters of water.")
- 补充知识点
1. 通用化解决方案:将代码封装成函数,接受两个水壶的容量和目标水量作为参数,以解决更一般的水壶倒水问题。
python
def get_target_water(capacity_1, capacity_2, target):jug_1 = 0jug_2 = 0steps = []while jug_1 != target and jug_2 != target:if jug_2 == 0:jug_2 = capacity_2steps.append(f"Fill the {capacity_2}-liter jug")elif jug_1 == capacity_1:jug_1 = 0steps.append(f"Empty the {capacity_1}-liter jug")elif jug_2 > 0 and jug_1 < capacity_1:pour = min(capacity_1 - jug_1, jug_2)jug_1 += pourjug_2 -= poursteps.append(f"Pour water from the {capacity_2}-liter jug to the {capacity_1}-liter jug: {pour} liters")final_jug = 1 if jug_1 == target else 2for step in steps:print(step)print(f"Finally, the {capacity_1 if final_jug == 1 else capacity_2}-liter jug contains {target} liters of water.")# 测试示例
get_target_water(5, 6, 3)
2. 使用图论方法:可以将水壶的状态看作图中的节点,倒水操作看作边,使用广度优先搜索(BFS)算法来寻找从初始状态到目标状态的最短路径,以得到最优解。
友情提示:本文已经整理成文档,可以到如下链接免积分下载阅读
https://download.csdn.net/download/ylfhpy/90435852
相关文章:

Python常见面试题的详解24
1. 如何对关键词触发模块进行测试 要点 功能测试:验证正常关键词触发、边界情况及大小写敏感性,确保模块按预期响应不同输入。 性能测试:关注响应时间和并发处理能力,保证模块在不同负载下的性能表现。 兼容性测试:测…...

手机打电话时如何识别对方按下的DTMF按键的字符-安卓AI电话机器人
手机打电话时如何识别对方按下的DTMF按键的字符 --安卓AI电话机器人 一、前言 前面的篇章中,使用蓝牙电话拦截手机通话的声音,并对数据加工,这个功能出来也有一段时间了。前段时间有试用的用户咨询说:有没有办法在手机上ÿ…...

RabbitMQ操作实战
1.RabbitMQ安装 RabbitMQ Windows 安装、配置、使用 - 小白教程-腾讯云开发者社区-腾讯云下载erlang:http://www.erlang.org/downloads/https://cloud.tencent.com/developer/article/2192340 Windows 10安装RabbitMQ及延时消息插件rabbitmq_delayed_message_exch…...

IDEA 2024.1 最新永久可用(亲测有效)
今年idea发布了2024.1版本,这个版本带来了一系列令人兴奋的新功能和改进。最引人注目的是集成了更先进的 AI 助手,它现在能够提供更复杂的代码辅助功能,如代码自动补全、智能代码审查等,极大地提升了开发效率。此外,用…...

【R包】pathlinkR转录组数据分析和可视化利器
介绍 通常情况下,基因表达研究如微阵列和RNA-Seq会产生数百到数千个差异表达基因(deg)。理解如此庞大的数据集的生物学意义变得非常困难,尤其是在分析多个条件和比较的情况下。该软件包利用途径富集和蛋白-蛋白相互作用网络&…...

RPA 与 AI 结合:开启智能自动化新时代
RPA 与 AI 结合:开启智能自动化新时代 在当今数字化快速发展的时代,企业面临着海量的数据处理和复杂的业务流程,如何提高效率、降低成本、优化业务流程成为了企业关注的焦点。而 RPA(Robotic Process Automation,机器…...

[免费]Springboot+Vue在线文档管理系统【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的SpringbootVue在线文档管理系统,分享下哈。 项目视频演示 【免费】SpringBootVue在线文档管理系统 Java毕业设计_哔哩哔哩_bilibili 项目介绍 随着科学技术的飞速发展,社会的方方面…...

内容选题与商业布局
内容选题与商业布局 提示词 1:人群链(User Chain)提示词 2:需求链(Demand Chain)提示词 3:环境 需求 优势 三要素提示词 4:垂直于“人性”而非只“赛道”提示词 5:基于…...

文字描边实现内黄外绿效果
网页使用 <!DOCTYPE html> <html> <head> <style> .text-effect {color: #ffd700; /* 黄色文字 */-webkit-text-stroke: 2px #008000; /* 绿色描边(兼容Webkit内核) */text-stroke: 2px #008000; /* 标准语法 *…...

网络协议 HTTP、HTTPS、HTTP/1.1、HTTP/2 对比分析
1. 基本定义 HTTP(HyperText Transfer Protocol) 应用层协议,用于客户端与服务器之间的数据传输(默认端口 80)。 HTTP/1.0:早期版本,每个请求需单独建立 TCP 连接,效率低。HTTP/1.1&…...

千峰React:Hooks(上)
什么是Hooks ref引用值 普通变量的改变一般是不好触发函数组件的渲染的,如果想让一般的数据也可以得到状态的保存,可以使用ref import { useState ,useRef} from reactfunction App() {const [count, setCount] useState(0)let num useRef(0)const h…...

salesforce 为什么无法关闭task,显示:insufficient access rights on object id
在 Salesforce 中,如果你在尝试关闭任务(Task)时遇到 “Insufficient access rights on object id” 错误,通常是由于以下几种可能的权限问题导致的: 1. 任务的所有权问题 Salesforce 中的任务(Task&…...

机器学习:强化学习的epsilon贪心算法
强化学习(Reinforcement Learning, RL)是一种机器学习方法,旨在通过与环境交互,使智能体(Agent)学习如何采取最优行动,以最大化某种累积奖励。它与监督学习和无监督学习不同,强调试错…...

MongoDB—(一主、一从、一仲裁)副本集搭建
MongoDB集群介绍: MongoDB 副本集是由多个MongoDB实例组成的集群,其中包含一个主节点(Primary)和多个从节点(Secondary),用于提供数据冗余和高可用性。以下是搭建 MongoDB 副本集的详细步骤&am…...

MyBatis TypeHandler 详解与实战:FastJson 实现字符串转 List
在 MyBatis 中,TypeHandler 是实现 Java 类型与数据库类型双向转换 的核心组件。无论是处理基础数据类型还是复杂的 JSON、枚举或自定义对象,它都能通过灵活的扩展机制满足开发需求。本文将通过一个 将数据库 JSON 字符串转换为 List<User> 的案例…...
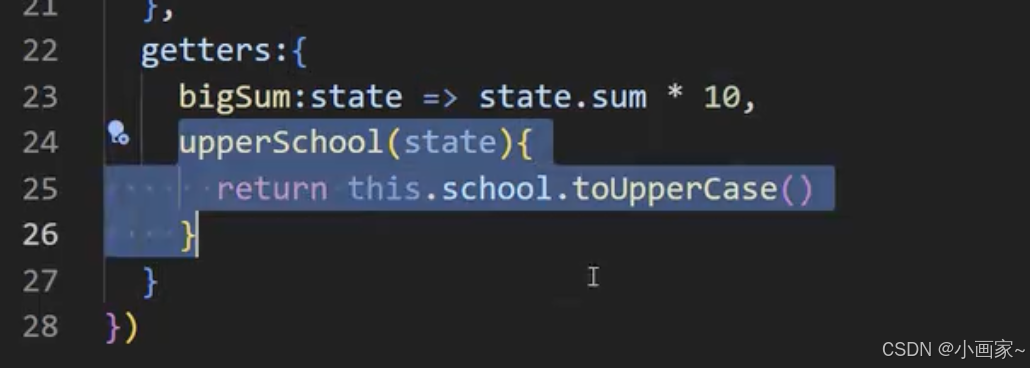
第二十八:5.5.【storeToRefs】5.6.【getters】
LoveTalk.vue: 调用: // 方法 const talkStore useTalkStore() function getLoveTalk(){ talkStore.getATalk() } 如果是要简短的形式调用: const talkStore useTalkStore() // user hooks 的形式调用 const {schoole,local} talkStore // …...

APISIX Dashboard上的配置操作
文章目录 登录配置路由配置消费者创建后端服务项目配置上游再创建一个路由测试 登录 http://192.168.10.101:9000/user/login?redirect%2Fdashboard 根据docker 容器里的指定端口: 配置路由 通过apisix 的API管理接口来创建(此路由,直接…...

MinIO在 Docker中修改登录账号和密码
MinIO在 Docker中修改登录账号和密码 随着云计算和大数据技术的快速发展,对象存储服务逐渐成为企业数据管理的重要组成部分。MinIO 作为一种高性能、分布式的对象存储系统,因其简单易用、高效可靠的特点而备受开发者青睐。然而,在实际应用中…...

英文论文查重,Turnitin和IThenticate两个系统哪个更合适?
Turnitin系统和IThenticate系统都是检测英文论文的查重系统,但是两者之间还是有一些不一样的。 下面针对这两个系统给大家具体分析一下。 一、Turnitin系统 Turnitin检测系统: https://truth-turnitin.similarity-check.com Turnitin是世界上主流的…...

pnpm的基本用法
以下是 pnpm 的核心命令和使用指南,涵盖从安装依赖到项目管理的常见操作: 1. 基础命令 (1) 安装依赖 pnpm install # 安装 package.json 中的所有依赖 pnpm install <包名> # 安装指定包(自动添加到 dependencies…...

PostgreSQL CASE语句深度解析:性能、类型与NULL安全实战指南
1. 为什么你必须真正吃透 PostgreSQL 的 CASE 语句——它远不止是 SQL 里的“if-else”翻译器在 PostgreSQL 实战中,我见过太多人把CASE当成一个语法糖:写几个WHEN...THEN,加个ELSE,再套个END,就以为搞定了。结果呢&am…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...

Jetson Orin上TVA模型DLA精准卸载配置
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...