【Elasticsearch】(Java 版)
Elasticsearch(Java 版)
文章目录
- Elasticsearch(Java 版)
- **1. Elasticsearch 简介**
- **1.1 什么是 Elasticsearch?**
- **1.2 核心概念**
- **2. 安装与配置**
- **2.1 环境要求**
- **2.2 安装步骤**
- **Linux/macOS**
- **Windows**
- **2.3 验证安装**
- **2.4 配置参数**
- **3. Java 客户端操作**
- **3.1 引入依赖**
- **3.2 创建客户端**
- **3.3 索引操作**
- **创建索引**
- **删除索引**
- **3.4 文档操作**
- **定义文档类**
- **插入文档**
- **查询文档**
- **更新文档**
- **删除文档**
- **3.5 批量操作**
- **4. 搜索与聚合**
- **4.1 查询 DSL**
- **简单匹配查询**
- **复合查询(Bool Query)**
- **聚合分析**
- **5. 性能优化**
- **5.1 分片与副本策略**
- **5.2 写入优化**
- **5.3 查询优化**
- **6. 集群管理**
- **6.1 查看集群健康状态**
- **7. 学习资源**
1. Elasticsearch 简介
1.1 什么是 Elasticsearch?
- 基于 Apache Lucene 的分布式搜索和分析引擎。
- 支持近实时(NRT)搜索、结构化查询、全文检索、复杂聚合分析。
- 适用于日志分析、监控系统、电商搜索、大数据分析等场景。
1.2 核心概念
- 文档(Document):数据的基本单元(JSON 格式)。
- 索引(Index):文档的集合(类似数据库中的表)。
- 分片(Shard):索引的横向拆分,支持分布式存储。
- 副本(Replica):分片的副本,提供高可用和负载均衡。
- 节点(Node):单个 ES 实例,多个节点组成集群(Cluster)。
- 倒排索引(Inverted Index):通过词项(Term)快速定位文档的数据结构。
2. 安装与配置
2.1 环境要求
- JDK 8 或更高版本。
- 推荐内存:4GB+,磁盘 SSD。
2.2 安装步骤
Linux/macOS
# 下载 Elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.10.0-linux-x86_64.tar.gz
tar -xzf elasticsearch-8.10.0-linux-x86_64.tar.gz
cd elasticsearch-8.10.0/# 启动单节点集群
./bin/elasticsearch
Windows
- 下载 ZIP 包并解压。
- 运行
bin\elasticsearch.bat。
2.3 验证安装
访问 http://localhost:9200,返回 JSON 信息即成功:
{"name": "node-1","cluster_name": "elasticsearch","version": { ... }
}
2.4 配置参数
修改 config/elasticsearch.yml:
cluster.name: my-cluster
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
discovery.type: single-node # 单节点模式
3. Java 客户端操作
3.1 引入依赖
在 pom.xml 中添加 Elasticsearch Java 客户端和 Jackson 依赖:
<dependency><groupId>co.elastic.clients</groupId><artifactId>elasticsearch-java</artifactId><version>8.10.0</version>
</dependency>
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.15.2</version>
</dependency>
3.2 创建客户端
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;public class ElasticsearchExample {public static void main(String[] args) {// 创建低级客户端,连接到本地 Elasticsearch 实例RestClient restClient = RestClient.builder(new HttpHost("localhost", 9200) // ES 服务器地址和端口).build();// 创建传输层,使用 Jackson 作为 JSON 处理器ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());// 创建 Elasticsearch Java 客户端ElasticsearchClient client = new ElasticsearchClient(transport);// 后续操作可以使用 client 对象进行}
}
3.3 索引操作
创建索引
// 创建名为 "products" 的索引
client.indices().create(c -> c.index("products"));
System.out.println("索引创建成功!");
删除索引
// 删除名为 "products" 的索引
client.indices().delete(c -> c.index("products"));
System.out.println("索引删除成功!");
3.4 文档操作
定义文档类
public class Product {private String name;private double price;private String category;// 构造函数、Getter 和 Setter 方法public Product(String name, double price, String category) {this.name = name;this.price = price;this.category = category;}// Getter 和 Setter 方法public String getName() { return name; }public void setName(String name) { this.name = name; }public double getPrice() { return price; }public void setPrice(double price) { this.price = price; }public String getCategory() { return category; }public void setCategory(String category) { this.category = category; }
}
插入文档
// 创建一个 Product 对象
Product product = new Product("Laptop", 999.99, "Electronics");// 将文档插入到 "products" 索引中,ID 为 "1"
client.index(i -> i.index("products") // 指定索引名称.id("1") // 指定文档 ID.document(product) // 指定文档内容
);
System.out.println("文档插入成功!");
查询文档
// 根据 ID 查询文档
GetResponse<Product> response = client.get(g -> g.index("products") // 指定索引名称.id("1"), // 指定文档 IDProduct.class // 指定返回的文档类型
);// 获取查询结果
Product product = response.source();
if (product != null) {System.out.println("查询结果:" + product.getName() + ", " + product.getPrice());
} else {System.out.println("未找到文档!");
}
更新文档
// 更新 ID 为 "1" 的文档
client.update(u -> u.index("products") // 指定索引名称.id("1") // 指定文档 ID.doc(new Product("Laptop", 899.99, "Electronics")), // 更新后的文档内容Product.class // 指定文档类型
);
System.out.println("文档更新成功!");
删除文档
// 删除 ID 为 "1" 的文档
client.delete(d -> d.index("products") // 指定索引名称.id("1") // 指定文档 ID
);
System.out.println("文档删除成功!");
3.5 批量操作
// 创建批量请求构建器
BulkRequest.Builder br = new BulkRequest.Builder();// 添加第一个文档
br.operations(op -> op.index(i -> i.index("products") // 指定索引名称.id("2") // 指定文档 ID.document(new Product("Phone", 599.99, "Electronics")) // 文档内容)
);// 添加第二个文档
br.operations(op -> op.index(i -> i.index("products") // 指定索引名称.id("3") // 指定文档 ID.document(new Product("Tablet", 299.99, "Electronics")) // 文档内容)
);// 执行批量操作
client.bulk(br.build());
System.out.println("批量操作完成!");
4. 搜索与聚合
4.1 查询 DSL
简单匹配查询
// 查询 "products" 索引中 name 字段包含 "Laptop" 的文档
SearchResponse<Product> response = client.search(s -> s.index("products") // 指定索引名称.query(q -> q // 定义查询条件.match(m -> m // 匹配查询.field("name") // 指定字段.query("Laptop") // 查询值)),Product.class // 指定返回的文档类型
);// 输出查询结果
for (Hit<Product> hit : response.hits().hits()) {System.out.println("查询结果:" + hit.source().getName());
}
复合查询(Bool Query)
// 查询 "products" 索引中 category 为 "Electronics" 且 price 大于等于 500 的文档
SearchResponse<Product> response = client.search(s -> s.index("products") // 指定索引名称.query(q -> q // 定义查询条件.bool(b -> b // 布尔查询.must(m -> m.match(t -> t.field("category").query("Electronics"))) // 必须匹配的条件.filter(f -> f.range(r -> r.field("price").gte(JsonData.of(500)))) // 过滤条件),Product.class // 指定返回的文档类型
);// 输出查询结果
for (Hit<Product> hit : response.hits().hits()) {System.out.println("查询结果:" + hit.source().getName() + ", " + hit.source().getPrice());
}
聚合分析
// 对 "products" 索引中的 price 字段进行平均值聚合
SearchResponse<Product> response = client.search(s -> s.index("products") // 指定索引名称.aggregations("avg_price", a -> a // 定义聚合.avg(avg -> avg.field("price")) // 计算 price 字段的平均值),Product.class // 指定返回的文档类型
);// 获取聚合结果
double avgPrice = response.aggregations().get("avg_price").avg().value();
System.out.println("平均价格:" + avgPrice);
5. 性能优化
5.1 分片与副本策略
- 分片数在创建索引后不可修改,需提前规划。
- 副本数可动态调整:
PUT /products/_settings { "number_of_replicas": 2 }。
5.2 写入优化
- 使用批量 API 减少请求次数。
- 调整
refresh_interval降低刷新频率。
5.3 查询优化
- 避免通配符查询(
*)。 - 使用
keyword类型做精确匹配。
6. 集群管理
6.1 查看集群健康状态
// 获取集群健康状态
HealthResponse response = client.cluster().health();
System.out.println("集群状态:" + response.status());
7. 学习资源
- 官方文档: https://www.elastic.co/guide
- 书籍: 《Elasticsearch 权威指南》
- 在线课程: Udemy 或 Coursera 上的 Elasticsearch 专项课程
通过本文档,您可以系统掌握 Elasticsearch 的核心功能与 Java 客户端操作。建议结合实际项目需求,进一步练习和优化代码。
相关文章:
)
【Elasticsearch】(Java 版)
Elasticsearch(Java 版) 文章目录 Elasticsearch(Java 版)**1. Elasticsearch 简介****1.1 什么是 Elasticsearch?****1.2 核心概念** **2. 安装与配置****2.1 环境要求****2.2 安装步骤****Linux/macOS****Windows** …...

DeepSeek在昇腾上的模型部署 - 常见问题及解决方案
2024年12月26日,DeepSeek-V3横空出世,以其卓越性能备受瞩目。该模型发布即支持昇腾,用户可在昇腾硬件和MindIE推理引擎上实现高效推理,但在实际操作中,部署流程与常见问题困扰着不少开发者。本文将为你详细阐述昇腾Dee…...

安全面试5
文章目录 sql的二次注入在linux下,现在有一个拥有大量ip地址的txt文本文档,但是里面有很多重复的,如何快速去重?在内网渗透中,通过钓鱼邮件获取到主机权限,但是发现内网拦截了tcp的出网流量,聊一…...

【Python量化金融实战】-第2章:金融市场数据获取与处理:2.1 数据源概览:Tushare、AkShare、Baostock、通联数据(DataAPI)
本章将详细介绍四大主流金融数据源(Tushare、AkShare、Baostock、通联数据(DataAPI)),分析其特点与适用场景,并通过实战案例展示数据获取与处理的全流程。 👉 点击关注不迷路 👉 点击…...
实现音频变调和变速播放)
Exoplayer(MediaX)实现音频变调和变速播放
在K歌或录音类应用中变调是个常见需求,比如需要播出萝莉音/大叔音等。变速播放在影视播放类应用中普遍存在,在传统播放器Mediaplayer中这两个功能都比较难以实现,特别在低版本SDK中,而Exoplayer作为google官方推出的Mediaplayer替…...
服务器间迁移conda环境
注意:可使用迁移miniconda文件 or 迁移yaml文件两种方式,推荐前者,基本无bug! 一、迁移miniconda文件: 拷贝旧机器的miniconda文件文件到新机器: 内网拷贝:scp -r mazhf192.168.1.233:~/miniconda3 ~/ 外…...

docker高级
文章目录 1.Docker Compose1.1 介绍1.2 compose文件1.3 常用命令1.4 安装1.5 项目说明和构建1.5.1 手工启动1.5.2 compose 编排启动1.5.3 完善 compose.yml1.5.4 加入前端容器 2.UI管理平台2.1 portainer 3.镜像发布3.1 阿里云3.2 Docker Registry3.2.1 介绍3.2.2 安装3.2.3 测…...

Redis Stream基本使用及应用场景
一、概念 Redis Streams是Redis5.0提供的一种消息队列机制,支持多播的可持久化的消息队列,用户实现发布订阅的功能,借鉴了kafka设计。 二、常用命令 命令名称描述XADD key ID field value [field value ...]添加一条消息 key:St…...
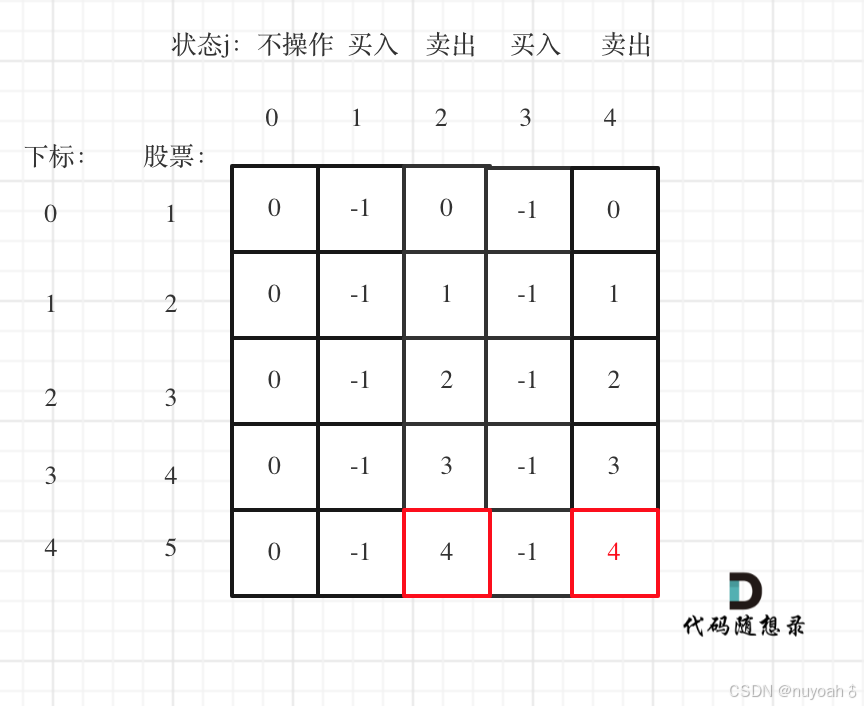
DAY40|动态规划Part08|LeetCode: 121. 买卖股票的最佳时机 、 122.买卖股票的最佳时机II 、 123.买卖股票的最佳时机III
目录 LeetCode:121. 买卖股票的最佳时机 暴力解法 贪心法 动态规划法 LeetCode:122.买卖股票的最佳时机II 基本思路 LeetCode: 买卖股票的最佳时机III、IV 基本思路 C代码 LeetCode:121. 买卖股票的最佳时机 力扣题目链接 文字讲解:121. 买卖股票的最佳时…...

【安装及调试旧版Chrome + 多版本环境测试全攻略】
👨💻 安装及调试旧版Chrome 多版本环境测试全攻略 🌐 (新手友好版 | 覆盖安装/运行/调试全流程) 🕰️ 【背景篇】为什么我们需要旧版浏览器测试? 🌍 🌐 浏览器世界的“…...

【Linux】进程间通信——命名管道
文章目录 命名管道什么是命名管道**命名管道 vs. 无名管道**如何创建命名管道 用命名管道实现进程间通信MakefileComm.hppServer.hppClient.hppServer.cppClient.cpp 效果总结 命名管道 什么是命名管道 命名管道,也称为 FIFO(First In First Out&#…...

Qt在Linux嵌入式开发过程中复杂界面滑动时卡顿掉帧问题分析及解决方案
Qt在Linux嵌入式设备开发过程中,由于配置较低,加上没有GPU,我们有时候会遇到有些组件比较多的复杂界面,在滑动时会出现掉帧或卡顿的问题。要讲明白这个问题还得从CPU和GPU的分工说起。 一、硬件层面核心问题根源剖析 CPU&#x…...

AI学习第六天-python的基础使用-趣味图形
在 Python 编程学习过程中,turtle库是一个非常有趣且实用的工具,它可以帮助我们轻松绘制各种图形。结合for循环、random模块以及自定义方法等知识点,能够创作出丰富多彩的图案。下面就来分享一下相关的学习笔记。 一、基础知识点回顾 &…...

[VMware]卸载VMware虚拟机和Linux系统ubuntu(自记录版)
记录一下,不是教程,只是防止我做错了可以回溯一下 我打开vscode,就会跳出下图 虚拟机,Linux还是很久之前学习安装的,种途可能卸载过(不太记得了),现在尝试彻底卸载 彻底卸载VMware虚拟机的详细步骤-CSDN博客虚拟机Vmware 转移 克隆 卸载及移除Linux系统_克隆的虚拟机怎么移除-…...

J-LangChain,用Java实现LangChain编排!轻松加载PDF、切分文档、向量化存储,再到智能问答
Java如何玩转大模型编排、RAG、Agent??? 在自然语言处理(NLP)的浪潮中,LangChain作为一种强大的模型编排框架,已经在Python社区中广受欢迎。然而,对于Java开发者来说,能…...

Cuppa CMS v1.0 任意文件读取(CVE-2022-25401)
漏洞简介: Cuppa CMS v1.0 administrator/templates/default/html/windows/right.php文件存在任意文件读取漏洞 漏洞环境: 春秋云镜中的漏洞靶标,CVE编号为CVE-2022-25401 漏洞复现 弱口令行不通 直接访问administrator/templates/defau…...

可以免费无限次下载PPT的网站
前言 最近发现了一个超实用的网站,想分享给大家。 在学习和工作的过程中,想必做PPT是一件让大家都很头疼的一件事。 想下载一些PPT模板减少做PPT的工作量,但网上大多精美的PPT都是需要付费才能下载使用。 即使免费也有次数限制࿰…...

STM32中使用PWM对舵机控制
目录 1、硬件JIE 2、PWM口配置 3、角度转换 4、main函数中应用 5、工程下载连接 1、硬件介绍 单片机:STM32F1 舵机:MG995 2、PWM口配置 20毫秒的PWM脉冲占空比,对舵机控制效果较好 计算的公式: PSC、ARR值的选取…...

使用插件 `vue2-water-marker`添加全局水印
使用插件 vue2-water-marker添加全局水印 效果图 1、安装插件 npm install vue2-water-marker --save2、全局注册 // main.js import Vue from vue import Vue2WaterMarker from vue2-water-markerVue.use(Vue2WaterMarker)3、在组件中使用 <template><div id&q…...

MySQL表约束的种类与应用
在MySQL数据库中,表约束是确保数据完整性的关键。约束限制了可以在表中插入或更新的数据类型,保证数据的准确性和可靠性。了解MySQL中的各种表约束对于数据库设计和数据维护至关重要。以下是MySQL支持的主要表约束类型及其应用的详细介绍。 1. 主键约束…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...

因果推断与机器学习融合:量化分析社会运动中镇压与抗议的动态关系
1. 项目概述:当数据科学遇见社会运动如果你研究过社会运动,尤其是那些看似突然爆发、席卷全国的抗议浪潮,你可能会被一个核心问题困扰:国家机器的镇压,究竟是浇灭火焰的冷水,还是火上浇油的催化剂ÿ…...

如何快速掌握MPC视频渲染器:面向初学者的完整教程
如何快速掌握MPC视频渲染器:面向初学者的完整教程 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 想要在Windows系统上获得影院级的视频播放体验吗?MPC…...

中小企无需重型数据中台:轻量化数据体系搭建完整方案
过去几年,“数据中台”一度成为企业数字化的标配热词。大量中小企业盲目跟风搭建重型数据中台,投入高额成本、耗费数月甚至数年周期,最终落地效果极差:功能冗余、运维复杂、使用率低、投入产出比失衡。大量项目最终沦为“摆设式中…...

告别KITTI!用TartanAir数据集在Unreal Engine+AirSim里复现那些让VSLAM算法“翻车”的雨天和黑夜
超越KITTI:用TartanAir数据集在虚拟极端环境中锤炼VSLAM算法当视觉SLAM算法在KITTI数据集上取得95%的准确率时,开发者们常常会松一口气——直到这些算法被部署到真实世界的雨夜街道上。突然之间,那些在阳光明媚的德国道路上表现优异的特征点检…...

Taotoken的Token Plan套餐如何帮助项目更可控地预估成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的Token Plan套餐如何帮助项目更可控地预估成本 对于项目管理者或独立开发者而言,在集成大模型能力时…...

实战教程:5步构建基于YOLOv5的FPS游戏智能瞄准系统
实战教程:5步构建基于YOLOv5的FPS游戏智能瞄准系统 【免费下载链接】FPSAutomaticAiming 基于yolov5的FPS游戏AI。 项目地址: https://gitcode.com/gh_mirrors/fp/FPSAutomaticAiming FPSAutomaticAiming是一个基于YOLOv5深度学习算法的FPS游戏自动瞄准系统&…...
函数的计算原理(附绘图代码))
从复平面几何到Python代码:可视化理解NumPy中angle()函数的计算原理(附绘图代码)
从复平面几何到Python代码:可视化理解NumPy中angle()函数的计算原理(附绘图代码) 在数学和工程领域,复数不仅是抽象的概念,更是解决实际问题的有力工具。当我们谈论复数68j时,它不仅仅是一个符号组合——在…...

SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析
SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass SafeExamBrowser&…...

2026年新能源人才全球本地化策略
导读:报告基于领英行业洞察,聚焦 2026 年全球新能源行业发展格局、中国企业出海现状、人才供需痛点及全球化人才本地化落地策略,为新能源企业海外人才招聘、培养与组织管理提供完整解决方案。关注公众号:【互联互通社区】…...