系统架构设计师-第3章 数据库设计
【本章学习建议】
根据考试大纲,本章主要考查系统架构设计师单选题,预计考5分左右,以及案例分析1题,25分。对应第二版教材2.3.3小节以及第6章,主要考点在第6章,这里一起合并到本章课程中。
3.1 数据库基本概念
数据(Data),是描述事物的符号记录,是数据库中存储的基本对象。数据的种类:文本、图形、图像、音频、视频、学生的档案记录、货物的运输情况等。
数据库(DataBase,DB),是长期存储在计算机内、有组织的、可共享的大量数据的集合。其特点:数据间联系密切;冗余度小;独立性高;易扩展;可为各类用户共享。
数据库系统(DataBase System,DBS)是一个采用了数据库技术,有组织地、动态地存储大量相关联数据,从而方便多用户访问的计算机系统。其由数据库、硬件、软件和人员组成。
数据库管理系统(DataBase Management System,DBMS)主要实现对共享数据有效地组织、管理和存取。其主要功能包括数据定义(Data Definition Language,DDL)、数据库操纵(Data Manipulation Language,DML)、数据库运行管理、数据组织、存储和管理、数据库的建立和维护、网络通信等。
DBMS的分类:关系数据库系统(Relation DataBase System,RDBS)、面向对象的数据库系统(Object-Oriented DataBase System,OODBS)、对象关系数据库系统(Object-Oriented Relation DataBase System,ORDBS)。
3.1.1 数据库三级模式
1. 内模式
也称存储模式,是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式,定义所有的内部记录类型、索引和文件的组织方式以及数据控制方面的细节。一个数据库只有一个内模式。对应数据库中的物理存储文件。
2. 概念模式
也称模式,是数据库中全部数据的逻辑结构和特征的描述。一个数据库只有一个概念模式。对应数据库中的基本表。
3. 外模式
也称用户模式或子模式,是用户与数据库系统的接口,是用户需要使用的部分数据的描述。一个数据库可以有多个外模式。对应数据库中的视图。
4. 数据库的两级映像
(1)模式/内模式映像:实现了概念模式和内模式间的相互转换,是表和数据的物理存储之间的映射,保证了数据的物理独立性。
(2)外模式/模式映像:实现了外模式和概念模式间的相互转换,是视图和表之间的映射,保证数据的逻辑独立性。
数据的独立性:
(1)物理独立性。物理独立性是指用户的应用程序与存储在磁盘上的数据库中的数据是相互独立的。当数据的物理存储改变时,应用程序不需要改变。物理独立性存在于概念模式和内模式之间的映射转换,说明物理组织发生变化时应用程序的独立程度。
(2)逻辑独立性。逻辑独立性是指用户的应用程序与数据库中的逻辑结构是相互独立的。当数据的逻辑结构改变时,应用程序不需要改变。逻辑独立性存在于外模式和概念模式之间的映射转换,说明概念模式发生变化时应用程序的独立程度。


3.1.2 数据库设计的基本步骤
一般将数据库设计分为如下6个阶段:
(1)用户需求分析。即分析数据存储的要求,产出物有数据流图、数据字典、需求说明书。获得用户对系统的三个要求:信息要求、处理要求、系统要求。
(2)概念结构设计。就是设计E-R图,也即实体-联系图。工作步骤包括:选择局部应用、逐一设计分E-R图、E-R图合并。分E-R图进行合并时,它们之间存在的冲突主要有以下3类。
·属性冲突。同一属性可能会存在于不同的分E-R图中。
·命名冲突。相同意义的属性,在不同的分E-R图上有着不同的命名,或是名称相同的属性在不同的分E-R 图中代表着不同的意义。
·结构冲突。同一实体在不同的分E-R图中有不同的属性,同一对象在某一分E-R图中被抽象为实体而在另一分E-R图中又被抽象为属性。
(3)逻辑结构设计。将E-R图,转换成关系模式。工作步骤包括:确定数据模型、将E-R图转换成为指定的数据模型、确定完整性约束和确定用户视图。
(4)物理结构设计。是逻辑模型在计算机中的具体实现方案。步骤包括确定数据分布、存储结构和访问方式。
(5)数据库实施阶段。根据逻辑设计和物理设计阶段的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行。
(6)数据库运行和维护阶段。数据库应用系统经过试运行即可投入运行,但该阶段需要不断地对系统进行评价、调整与修改。

3.2 数据模型
3.2.1 基本概念
1. 数据模型的定义
数据模型是对现实世界数据特征的抽象。最常用的数据模型分为概念数据模型和基本数据模型。
(1)概念数据模型:也称信息模型,是按用户的观点对数据和信息建模,是用户和数据库设计人员交流的语言,主要用于数据库设计。这类模型中最著名的是实体-联系模型,简称E-R模型。
(2)基本数据模型:它是按计算机系统的观点对数据建模,是现实世界数据特征的抽象,用于DBMS的实现。
2. 数据模型的三要素
(1)数据结构(所研究对象类型的集合);
(2)数据操作(对数据库中各种对象的实例允许执行的操作集合);
(3)数据的约束条件(一组完整性规则的集合)。
3.2.2 E-R模型
E-R模型,就是实体-联系模型,用来描述现实世界的概念模型(接近于人的思维方式,容易理解),其中有三个主要的概念:实体、联系和属性。
1. 实体
用矩形表示,每个实体由一组属性表示,包括候选键、主键、外键。实体集是指具有相同属性的实体集合。
候选键:能唯一地标识一行元组的属性集。
主键:从候选键中选一个作为主键。
外键:在另一个关系模式中充当主键的属性。
2. 联系
用菱形表示,实体集之间的对应关系称为联系,分为一对一(1:1)、一对多(1:n或1:*)、多对多(m:n或*:*)。
①一对一联系(1:1)。实体集A中的一个实体最多只与实体集B中的一个实体相联系,反之亦然。
②一对多联系(1:n或1:*)。实体集A中的一个实体可与实体集B中的多个实体相联系。
③多对多联系(m:n或*:*)。实体集A中的多个实体可与实体集B中的多个实体相联系。多对多的联系会产生一个新的关系模式,此关系模式的属性由联系的两个实体的主键以及自己的特有属性所组成。
1:1:一个学校只有一名校长,而每位校长只在一个学校工作。
1:n或1:*:一个学校有很多学生,而每个学生只在一个学校上课。
m:n或*:*:一名学生可以选修多门课程,而一门课程也可以由多名学生选修。

3. 属性
用椭圆表示,是实体某方面的特性。E-R模型中的属性分为:
①简单和复合属性:简单属性是原子的、不可再分的,复合属性可以划分为多个子属性,如通信地址。
②单值和多值属性:对于一个特定的实体都只有一个单独的值(单值属性)。例如,对于一个特定的员工,只对应一个员工号、员工姓名。而员工可能有0个、1个或多个亲属,那么员工的亲属姓名可能有多个,这样的属性称为多值属性。
③NULL属性:某个属性没有值或属性值未知时,使用NULL值,表示无意义或不知道。
④派生属性:派生属性可以从其他属性得来。例如,职工实体集中有“参加工作时间”和“工作年限”属性,那么“工作年限”的值可以由当前时间和参加工作时间得到。“工作年限”就是一个派生属性。
弱实体集:一个实体的存在必须以另一个实体为前提,这类实体称为弱实体集。例如:职工的家属必须以职工在职为前提,依赖于职工。
4. 实体-联系方法


3.3 关系代数
3.3.1 关系数据库的基本概念
1. 属性和域
一个现实中的实体(事物)常用若干特征来描述,这些特征称为属性。每个属性的取值范围对应的集合称为该属性的域。
例如:员工(员工号,姓名,性别,参加工作时间,部门号)
2. 笛卡儿积与关系



3. 关系的相关名词
(1)候选码(Candidate Key):若关系中的某一属性或属性组的值能唯一地标识一个元组,则称该属性或属性组为候选码。
(2)主码(Primary Key):若一个关系有多个候选码,则选定其中一个为主码。
(3)主属性(Non-Key attribute):包含在任何候选码中的诸属性称为主属性。不包含在任何候选码中的属性称为非码属性。
(4)外码(Foreign Key):如果关系模式R中的属性或属性组不是该关系的主码,但它是其他关系的主码,那么该属性或属性组是关系模式R的外码。
员工(员工号,姓名,性别,参加工作时间,部门号),部门(部门号,名称,电话,负责人)
4. 关系的三种类型
(1)基本关系。通常又称为基本表,它是实际存在的表,是实际存储数据的逻辑表示。
(2)查询表。查询表是查询结果对应的表。
(3)视图表。视图表是由基本表或其他视图表导出的表。由于它本身不独立存储在数据库中,数据库中只存放它的定义,所以常称为虚表。
5. 关系数据库模式
关系的描述称为关系模式(Relation Schema),可以形式化地表示为:

其中,R表示关系名;U是组成该关系的属性名集合;D是属性的域;dom是属性向域的映像集合;F为属性间数据的依赖关系集合。
通常将关系模式简记为:

其中,R为关系名,
为属性名或域名,属性向域的映像常常直接说明属性的类型、长度。通常在关系模式主属性上加下划线表示该属性为主码属性。
员工(员工号,姓名,性别,参加工作时间,部门号)
E-R图转换为关系模式:
首先,每个实体都要转换为一个关系模式;然后对于联系:
(1)一对一,两端实体中的任意一个实体的主键加入到另一个实体中作为外键;
(2)一对多,一端实体的主键加入到多端实体中作为外键;
(3)多对多,多对多的联系会产生一个新的关系模式,此关系模式的属性由联系的两个实体的主键以及自己的特有属性所组成。
6. 完整性约束
完整性规则提供了一种手段来保证当用户对数据库做修改时不会破坏数据的一致性。防止对数据的意外破坏。关系模型的完整性规则是对关系的某种约束条件。关系的完整性分为三类:
①实体完整性:关系的主属性不能取空。
②参照完整性:外键的值或者为空,或者必须等于对应关系中的主键值。
员工(员工号,姓名,性别,参加工作时间,部门号),部门(部门号,名称,电话,负责人)
③用户定义完整性:根据语义要求所自定义的约束条件。
7. 关系运算
关系操作的特点是操作对象和操作结果都是集合。关系代数运算符有4类:集合运算符、专门的关系运算符、算术比较符和逻辑运算符。

3.3.2 5种基本的关系代数运算
关系模式在代数运算时可以理解为数据库表的运算。
1. 并(Union)
关系R与S的属性及属性的个数相同。并的结果为属于R或属于S的元组构成的集合(元组要去重)。

2. 差(Difference)
关系R与S的属性及属性的个数相同。R−S差的结果为属于R但不属于S的元组构成的集合。

3. 广义笛卡尔积(Extended Cartesian Product)
如果关系模式R中有n个属性,关系模式S中有m个属性,则广义笛卡尔积的结果中有(n+m)个属性,其中前n个属性来自R,后m个属性来自S。如果R中有k1个元组,S中有k2个元组,则运算结果又k1*k2个元组。

4. 投影(Projection)
从关系的垂直方向进行运算。在关系R中挑选若干属性列A组成新的关系。

5. 选择(Selection)
从关系的水平方向进行运算,从关系R中选择满足条件的元组。

其中,F中运算对象是属性名(或列的序号)或者常量(用单引号括起来,如’1’表示数字1)、算术运算符(<、≤、>、≥、≠)、逻辑运算符(∧、∨、¬)。
3.3.3 扩展的关系代数运算
1. 交(Intersection)
关系R与S的属性及属性的个数相同。关系R与S的交是由属于R同时又属于S的元组构成的集合。

2. 连接(Join)
连接分为连接、等值连接和自然连接3种。连接运算是从两个关系R和S的笛卡尔积中选取满足条件的元组。
①连接:从关系R与S的笛卡尔积中选取属性间满足一定条件的元组。


| A | B | C | A | C | D | |
| a | b | c | a | c | d | |
| b | a | d | d | f | g | |
| c | d | e | b | d | g | |
| d | f | g | 关系S | |||
| 关系R | ||||||

3. 除(Division)
除运算是同时从关系的水平方向和垂直方向进行运算。

练习:设有关系R、S如下图所示,求RS。
| A | B | C | D | C | D | |
| a | b | c | d | c | d | |
| a | b | e | f | e | f | |
| a | b | h | k | |||
| b | d | e | f | |||
| b | d | d | I | |||
| c | k | c | d | |||
| c | k | e | f | |||
| 关系R | ||||||

4. 广义投影(Generalized Projection)
允许在投影列表中使用算术运算,是对投影运算的补充。


5. 外连接(Outer Join)
在自然连接中关系R与S的一些元组因为没有公共属性会被抛弃。使用外连接就可以避免这样的丢失。外连接运算就是将自然连接时舍弃的元组也放入新关系,并在新增加的属性上填入空值。

3.4 关系数据库SQL语言
SQL是结构化查询语言的简称,是关系数据库中最普遍使用的语言,包括数据查询、数据操纵、数据定义和数据控制,是一种通用的、功能强大的关系数据库标准语言。
SQL语言支持关系数据库的三级模式。基本表和视图都是表,基本表是存储在数据库中的表,而视图是虚表,是从基本表或其他视图导出的表。数据库中只存放视图的定义,不存放视图的数据。用户可用SQL语言对视图或表进行查询等操作。

索引建立与删除:
数据库中索引的作用:①通过创建唯一性索引,保证数据记录的唯一性;②大大加快数据的检索速度;③加速表与表之间的连接;④在使用Order By和Group By子句中进行检索数据时,可以显著减少查询中分组和排序的时间;⑤使用索引可以在检索数据的过程中使用优化隐藏器,提高系统性能。
索引分为聚簇索引和非聚簇索引。聚簇索引是指索引表中索引项的顺序与表中记录的物理顺序一致的索引。
3.5 关系数据库设计基本理论
3.5.1 函数依赖
关系数据库设计的方法之一就是设计满足合适范式的模式。关系数据库规范化理论主要包括数据依赖、范式和模式设计方法。其中核心基础是数据依赖,数据依赖中最重要、最基本的就是函数依赖。
(1)函数依赖
设R(U)是属性集U上的关系模式,X、Y是U的子集。若对R(U)的任何一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称X函数决定Y或Y函数依赖于X,记作X→Y。
(2)部分函数依赖
如果X→Y,但Y不完全函数依赖于X,则称Y对X部分函数依赖。
例子:(A,B)能确定C,A也能确定C,即(A,B)属性集中的部分属性(A)就可以确定C,则C部分函数依赖于(A,B)。

(3)传递函数依赖

函数依赖求候选键:从一个或一组属性出发,通过函数依赖集中的依赖关系,能决定关系模式中的其他所有属性,则这个属性或属性组为候选键。
·求候选键最稳靠的办法是图示法。图示法求候选键的过程如下:
(1)将关系的函数依赖关系用“有向图”的方式表示。
(2)找出入度为0的属性,并以该属性集合为起点,尝试遍历有向图,若能正常遍历图中所有结点,则该属性集即为关系模式的候选键。
(3)若入度为0的属性集不能遍历图中所有结点,则需要尝试性的将一些中间结点(既有入度,也有出度的结点)并入度为0的属性集中,直至该属性集合能遍历所有结点,则该属性集合为候选键。
·函数依赖求候选键第二种方法:根据依赖集,找出从未在右边出现过的属性,必然是候选键之一,以该属性为基础,根据依赖集依次扩展,看能否遍历所有属性,若无法遍历所有属性,则将无法遍历到的属性加入候选键中。
(4)函数依赖的公理系统(Armstrong公理系统)
设关系模式R(U,F),其中U为属性集,F是U上的一组函数依赖,那么有以下推理规则:
·A1自反律:若Y⊆X⊆U,则X→Y为F所蕴涵。
·A2增广律:若X→Y为F所蕴涵,且Z⊆U,则XZ→YZ为F所蕴涵。
·A3传递律:若X→Y,Y→Z为F所蕴涵,则X→Z为F所蕴涵。
根据以上三条推理规则,又可推出以下三条推理规则:
·合并规则: 若X→Y,X→Z,则X→YZ为F所蕴含。
·伪传递规则: 若X→Y,WY→Z,则XW→Z为F所蕴含。
·分解规则: 若X→Y,Z⊆Y,则X→Z为F所蕴含。
3.5.2 规范化
关系数据库设计的方法之一就是设计满足适当范式的模式,通常可以通过判断分解后的模式达到几范式来评价模式规范化的程度。范式有:
![]()
,其中级别越高,模式规范化程度也就越高。
1. 1NF(第一范式)
定义:若关系模式R的每一个分量是不可再分的数据项,则关系模式R属于第一范式。即属性是原子不可再分的。
1NF存在的问题:数据冗余、插入异常、删除异常等问题。
2. 2NF(第二范式)

3. 3NF(第三范式)

4. BCNF(巴克斯范式)
BCNF是修正的第三范式。规定了每个属性(包括主属性)都不传递依赖于码。即当3NF消除了主属性对码的部分函数依赖和传递函数依赖,则称为BCNF。
5. 4NF(第四范式)
4NF主要是消除了多值依赖。
3.5.3 模式分解
1. 分解
模式分解:将一个关系模式分解为多个子模式。
模式分解就是模式规范化的工具,模式分解使用无损连接和保持函数依赖来衡量模式分解后是否导致原有模式中部分信息丢失。
2. 无损连接

3. 保持函数依赖

3.6 数据库的控制功能
3.6.1 事务管理
事务是DBMS的基本工作单位,是由用户定义的一个操作序列。
事务的定义语句有:Begin Transaction(事务开始)、Commit(事务提交,表示事务成功地结束)、Rollback(事务回滚,表示事务非成功地结束)。
事务的ACID性质:
(1)原子性(Atomicity):要么都做,要么都不做。
(2)一致性(Consistency):事务执行的结果必须从一个一致性状态转到另一个一致性状态。中间状态对外不可见。
(3)隔离性(Isolation): 事务之间相互隔离,互不干扰。
(4)持久性(Durability):事务成功提交后,对数据库的更新操作是永久有效的。
3.6.2 并发控制
并发操作就是在多用户系统中,可能出现多个事务同时操作同一数据的情况。并发操作会导致3种数据不一致的问题:
1. 丢失修改(丢失更新)
当两个事务T1和T2读入同一数据做修改,并发执行时,T1把T2或T2把T1的修改结果覆盖掉,造成了数据的丢失更新问题,导致数据不一致。
| T1 | T2 |
| Read(X); | |
| Read(X); | |
| X:=X-10; | |
| Write(X); | |
| X:=X-20; | |
| Write(X); |
2. 不可重复读
事务T1读取了数据R,事务T2读取并更新了数据R。当事务T1再读取数据R以进行核对时,得到的两次读取数据不一致。
| T1 | T2 |
| 读取X=20; | |
| 读取Y=10; | |
| 求和=30; | |
| 读取X=20; | |
| X:=X-10; | |
| 写X=10; | |
| 读取X=10; | |
| 读取Y=10; | |
| 求和=20;(验证不对) |
3. 读脏数据
事务T1更新了数据R,事务T2读取了更新后的数据R,事务T1由于某种原因被撤销,进行了事务回滚,数据R恢复原值,事务T2读取了脏数据。
| T1 | T2 |
| Read(X); | |
| X:=X-10; | |
| Write(X); | |
| Read(X); | |
| (对X的处理操作) | |
| Rollback; |
造成以上3种数据不一致的主要原因是事务的并发操作破坏了事务的隔离性。
4. 并发控制技术
并发控制的主要技术是封锁(Lock)技术。
| 基本封锁类型 | 特点 |
| 排他锁(X锁) | 事务T对数据A加X锁: (1)只允许事务T读取、修改数据A; (2)只有等该锁解除之后,其他事务才能够对数据A加任何锁类型。 |
| 共享锁(S锁) | 解决了X锁太严格,不允许其他事务并发读的问题。 事务T对数据A加S锁,则: (1)只允许事务T读取数据A但不能够修改; (2)可允许其他事务对其加S锁,但不允许加X锁。 |
3.7 数据库安全
1. 数据库的故障类型
①事务内部故障:如运算溢出、除零错误、并发事务发生死锁等;
②系统故障:也称为软故障,是指造成系统停运的事件,如CPU故障、OS故障、突然停电等;
③介质故障:也称为硬故障,如磁盘损坏等;
④计算机病毒。
2. 数据库的备份方法
数据库的转储分为静态转储和动态转储,海量转储、增量转储和差量转储,以及日志文件。
·静态转储:即冷备份,指在转储期间不允许对数据库进行任何存取、修改操作。
优点是非常快速、容易归档(直接物理复制操作)。
缺点是只能提供到某一时间点上的恢复,不能做其他工作,不能按表或按用户恢复。
·动态转储:即热备份,在转储期间允许对数据库进行存取、修改操作,因此,转储和用户事务可以并发执行。
优点是可在表空间或数据库文件级备份,数据库仍可使用,可达到秒级恢复。
缺点是不能出错,否则后果严重,若热备份不成功,所得结果几乎全部无效。
·海量转储(完全转储):是指每次转储全部数据库。
·增量转储:是指每次只转储上次转储后更新过的数据,用于数据库很大,事务处理频繁的场景。
·差量转储:是对最近一次数据库完全备份以来发生的数据变化进行备份,优点是速度快,占用较小的时间和空间。
·日志文件:在事务处理过程中,DBMS把事务开始、事务结束以及对数据库的插入、删除和修改的每一次操作写入日志文件。一旦发生故障,DBMS的恢复子系统利用日志文件撤销事务对数据库的改变,回退到事务的初始状态。
数据仓库(补充)
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。

OLAP服务器:联机分析处理服务器,快速汇总大量数据并进行高效查询分析,为分析人员提供决策支持。
数据仓库与数据库的对比如下表所示:
| 数据仓库 | 数据库 |
| 面向主题的 | 面向事务的 |
| 数据结构是集成的,具有一致性 | 数据结构更为复杂 |
| 是静态的历史数据,只能定期添加、刷新 | 是动态变化的,业务发生,数据就更新 |
| 存储历史数据 | 存储实时、在线数据 |
| 设计需要引入冗余 | 设计尽量避免冗余 |
分布式数据库(补充)
分布式数据库通常使用较小的计算机系统,每台计算机可以单独放在一个地方,每台计算机中都可能有DBMS的一份完整拷贝副本或部分拷贝副本,并具有自己局部的数据库,位于不同地点的许多计算机通过网络互相连接,共同组成一个完整的、全局的逻辑上集中、物理上分布的大型数据库。
分布式数据库的核心:
(1)数据分片:突破中心化数据库单机的容量限制,将数据分散到多节点,以更灵活、高效的方式来处理数据。分片方式包括:①水平分片:按行进行数据分割,数据被分割为一个个数据组,分散到不同节点上;②垂直分片:按列进行数据分割,一个数据表的模式被切割为多个子模式。
(2)数据同步:由于数据库理论传统上是建立在单机数据库基础上,而引入分布式理论后,一致性原则被打破。因此需要引入数据库同步技术来帮助数据库恢复一致性。
分布式数据库的分布透明性:
·分片透明性:用户或应用程序不需要知道逻辑上访问的表具体是如何分块存储的。
·位置透明性:用户或应用程序不关心数据存放的物理位置。
·逻辑透明性:用户或应用程序无需知道局部使用的是哪种数据模型。
·复制透明性:用户或应用程序不关心复制的数据从何而来。
分布式数据库的特点:高可扩展性、高并发性、高可用性。
大数据(补充)
大数据的4V特征:大量化(Volume)、多样化(Variety)、价值密度低(Value)、快速化(Velocity)。
要处理大数据,一般使用集成平台,称为大数据处理系统,其特征为:高度可扩展性、高性能、高度容错、支持异构环境、较短的分析延迟、易用且开放的接口、较低成本、向下兼容性。
相关文章:
系统架构设计师-第3章 数据库设计
【本章学习建议】 根据考试大纲,本章主要考查系统架构设计师单选题,预计考5分左右,以及案例分析1题,25分。对应第二版教材2.3.3小节以及第6章,主要考点在第6章,这里一起合并到本章课程中。 3.1 数据库基本…...

SAP MDG —— MDG on S/4HANA 2023 FPS03 创新汇总
文章目录 MDG 基于SAP S/4HANA 2023 FPS03的创新BP/C/S:消息控制BP/C/S:手工分配数据控制者MDG-F:使用S/4扩展数据校验功能生成式AI可用于协助自定义对象的数据变更/同时可总结批量变更的内容 MDG 基于SAP S/4HANA 2023 FPS03的创新 由于从S…...

软考中级-数据库-3.2 数据结构-数组和矩阵
数组 一维数组是长度固定的线性表,数组中的每个数据元素类型相同。n维数组是定长线性表在维数上的扩张,即线性表中的元素又是一个线性表。 例如一维数组a[5][a1,a2,a3,a4,a5] 二维数组a[2][3]是一个2行2列的数组 第一行[a11,a12,a13] 第二行[a21,a22,a23…...

有符号数和无符号数的加减运算
一、无符号数的加减运算 加法 规则:直接按二进制逐位相加,若最高位产生进位(即结果超出(2^n)范围),则结果对(2^n)取模((n)为位数)。示例(8位无符号数): (200 …...
动态链接器(十):重定位
ELF文件中有许多种类型的重定位条目,这些重定位条目指导动态链接器在加载或运行时解析符号地址,确保程序能够正确地引用动态库中的函数和变量。 本文主要介绍那些与动态链接有关的重定位条目(主要介绍Rela相关的,Rel相关的不作介…...

EGO-Planner的无人机视觉选择(yolov5和yolov8)
EGO-Planner的无人机视觉选择(yolov5和yolov8) 效果 yolov5检测效果 yolov8检测效果 一、YOLOv8 vs YOLOv5:关键差异解析 1. 训练效率:为何YOLOv8更快? 架构轻量化 YOLOv8采用C2f模块(Cross Stage Partia…...
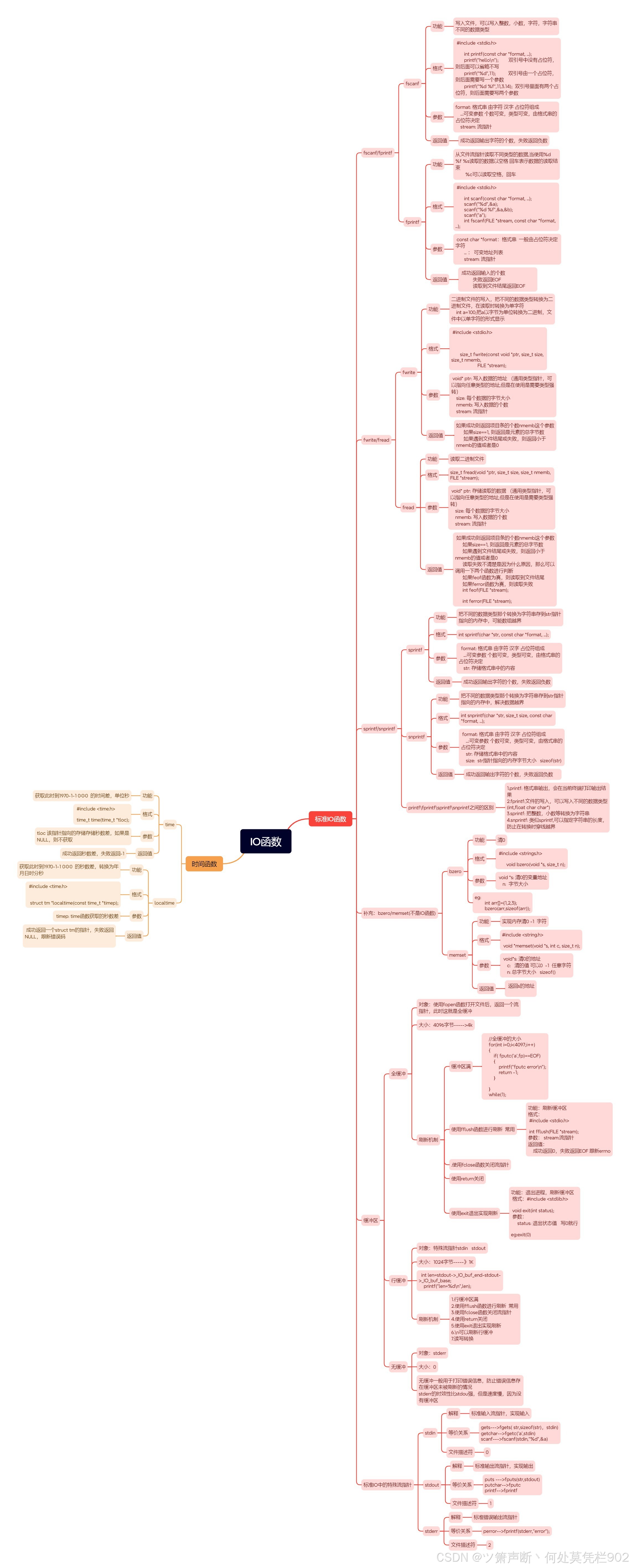
IO标准函数和时间函数
1、将当前的时间写入到time. txt的文件中,如果ctrlc退出之后,在再次执行支持断点续写 1.2022-04-26 19:10:20 2.2022-04-26 19:10:21 3.2022-04-26 19:10:22 //按下ctrlc停止,再次执行程序 4.2022-04-26 20:00:00 5.2022-04-26 20:00:0…...

为AI聊天工具添加一个知识系统 之133 详细设计之74通用编程语言 之4 架构及其核心
本篇继续讨论 通用编程语言。 说明:本阶段的所有讨论都是围绕这一主题展开的,但前面的讨论分成了三个大部分(后面列出了这一段的讨论题目的归属关系)-区别distinguish(各别): 文化和习俗。知识…...

【零基础到精通Java合集】第二十三集:G1收集器深度解析
课程标题:G1收集器深度解析——面向大内存与低延迟的现代垃圾回收器(15分钟) 目标:掌握G1核心设计思想、运行机制与调优策略,理解其如何平衡吞吐量与低延迟 0-1分钟:课程引入与G1设计目标 以“城市交通智能调度”类比G1核心思想:将堆内存划分为多个区域(Region),动…...
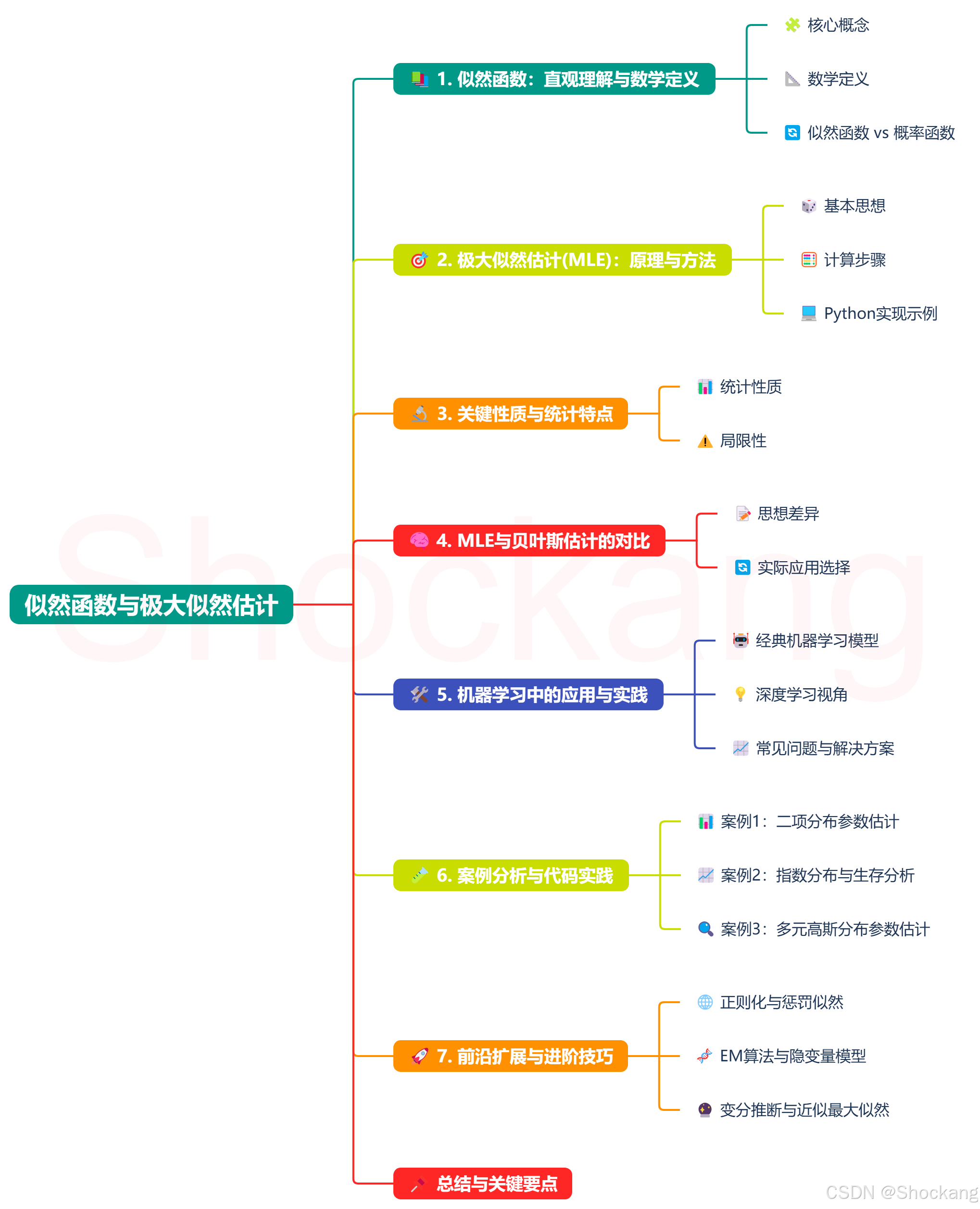
似然函数与极大似然估计
前言 本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见《机器学习数学通关指南》 正文 📚 1. 似然函数&a…...
详解)
QSFP(Quad Small Form-factor Pluggable)详解
1. QSFP的定义 QSFP(Quad Small Form-factor Pluggable)是一种四通道热插拔光模块/电模块,专为高速网络传输设计。其名称中的“Quad”表示模块集成4个独立通道,每个通道支持1Gbps至10Gbps速率(总带宽可达40Gbps&#…...

WDM_OTN_基础知识_波分系统基本构成-无源器件
在波分系统中通常将发光,对光进行放大以及产生光电转换的器件称之为有源器件,例如光放,激光器,与此相反,将那些不发光,不对光进行放大,也不产生光电转换的器件称之为无源器件,波分系统中的无源器…...

【音视频】ffmpeg音视频处理基本流程
一、ffmpeg音视频处理基本流程 首先先看两条命令 ffmpeg -i 1.mp4 -acodec copy -vcodec libx264 -s 1280x720 2.flv ffmpeg -i 1.mp4 -acodec copy -vcodec libx265 -s 1280x720 3.mkv-i :表示输入源,这里是1.mp4,是当前路径下的视频文件-acodec copy…...

【网络编程】之TCP实现客户端远程控制服务器端及断线重连
【网络编程】之TCP实现客户端远程控制服务器端及断线重连 TCP网络通信实现客户端简单远程控制主机基本功能演示通信过程代码实现服务器模块执行命令模块popen系列函数 客户端模块服务器主程序 windows作为客户端与服务器通信#pragma comment介绍 客户端使用状态机断线重连代码实…...

云原生容器编排:构建智能弹性应用的自动化引擎
引言:重构应用部署范式 Google Borg系统管理着超2500万容器实例,每日处理200亿个任务。阿里巴巴双十一使用Kubernetes实现300万Pod秒级弹性,资源利用率达65%。CNCF 2023报告显示全球Kubernetes生产采用率突破92%,CRI-O容器启动速…...

centos虚拟机安装
以下是一个详细的 VMware CentOS 虚拟机安装教程,结合了最新的信息和步骤: 一、准备工作 1. 下载 VMware 软件 访问 VMware 官方网站:VMware Workstation 官网。点击“现在安装”并下载适合您操作系统的 VMware Workstation。 2. 下载 Ce…...
社会力模型:Social force model for pedestrian dynamics
Social Force Model——社会力模型-CSDN博客 简介: 时间:1995 期刊:《Physical Review E》 作者:Dirk Helbing and Peter Molnar 摘要: 提出一种描述行人运动的“社会力模型”。认为行人的运动可看作是受到一系列…...

机器学习数学通关指南
✨ 写在前面 💡 在代码的世界里沉浸了十余载,我一直自诩逻辑思维敏捷,编程能力不俗。然而,当我初次接触 DeepSeek-R1 并领略其清晰、系统的思考过程时,我不禁为之震撼。那一刻,我深刻意识到:在A…...

【Mac】2025-MacOS系统下常用的开发环境配置
早期版本的一个环境搭建参考 1、brew Mac自带终端运行: /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" Installation successful!成功后运行三行命令后更新环境(xxx是mac的username&a…...
与栈(Stack)的区别)
# C# 中堆(Heap)与栈(Stack)的区别
在 C# 中,堆和栈是两种不同的内存分配机制,它们在存储位置、生命周期、性能和用途上存在显著差异。理解堆和栈的区别对于优化代码性能和内存管理至关重要。 1. 栈(Stack) 1.1 定义 栈是一种后进先出(LIFO࿰…...

效率翻倍!OrCAD Capture CIS创建复杂元器件库的实战技巧:LM358与多Part器件管理
效率翻倍!OrCAD Capture CIS创建复杂元器件库的实战技巧:LM358与多Part器件管理 在电子设计领域,元器件库的管理水平直接影响设计效率。许多工程师在使用OrCAD Capture CIS时,面对LM358这类多Part器件或更复杂的异构元件时&#x…...

【Perplexity阅读推荐查询实战指南】:20年AI工具专家亲授5大精准筛选技巧,错过再等一年
更多请点击: https://kaifayun.com 第一章:Perplexity阅读推荐查询的核心价值与适用场景 Perplexity 作为一款基于大语言模型的实时问答与研究工具,其“阅读推荐查询”能力并非简单的内容聚合,而是融合语义理解、来源可信度评估…...

不止于测试:用GStreamer打造你的树莓派低成本视频监控/图传系统
树莓派视频监控实战:用GStreamer构建低成本图传系统 树莓派搭配普通USB摄像头能做什么?大多数人可能只想到简单的视频采集测试。但如果你掌握GStreamer这个多媒体框架的进阶用法,就能将它变成一套功能完整的视频监控或无线图传系统。本文将彻…...

Vidupe:3步快速清理重复视频的终极免费解决方案
Vidupe:3步快速清理重复视频的终极免费解决方案 【免费下载链接】vidupe Vidupe is a program that can find duplicate and similar video files. V1.211 released on 2019-09-18, Windows exe here: 项目地址: https://gitcode.com/gh_mirrors/vi/vidupe 您…...

智能视觉瞄准系统:基于YOLOv8的高效游戏辅助解决方案
智能视觉瞄准系统:基于YOLOv8的高效游戏辅助解决方案 【免费下载链接】RookieAI_yolov8 基于yolov8实现的AI自瞄项目 AI self-aiming project based on yolov8 项目地址: https://gitcode.com/gh_mirrors/ro/RookieAI_yolov8 RookieAI_yolov8是一个基于先进视…...

Komanda代码嵌入功能详解:Gist、JSFiddle和Twitter无缝集成
Komanda代码嵌入功能详解:Gist、JSFiddle和Twitter无缝集成 【免费下载链接】komanda The IRC Client For Developers 项目地址: https://gitcode.com/gh_mirrors/ko/komanda Komanda作为一款面向开发者的IRC客户端,提供了强大的代码嵌入功能&…...

测试TVS:SP0503BAHTG
简 介: 本文测试了SP0503BAHTG三通道TVS二极管阵列的特性。通过设计测试电路板,测量了该器件对1kHz正弦波的限幅效果,测得反向导通电压约-0.8V,顶部饱和电压6.3V。在1MHz高频测试中观察到快速响应特性,通过矩形波上升沿…...

给程序员和数据分析师的气象学入门:搞懂城市边界层,让你的天气API数据不再‘失真’
给程序员和数据分析师的气象学入门:搞懂城市边界层,让你的天气API数据不再‘失真’ 当你在调用天气API时,是否遇到过这样的困惑:明明获取的是同一个城市的温度数据,为什么市中心的气温总比郊区高出几度?为什…...

Python跨平台应用开发终极指南:用Flet框架轻松构建桌面、移动和Web应用
Python跨平台应用开发终极指南:用Flet框架轻松构建桌面、移动和Web应用 【免费下载链接】flet Build realtime web, mobile and desktop apps in Python only. No frontend experience required. 项目地址: https://gitcode.com/gh_mirrors/fl/flet 你是否曾…...

谷歌报告:AI 加速云攻击,企业需自动化防御应对第三方漏洞与身份入侵
AI 加速攻击,云端企业成重灾区 2026 年 3 月,谷歌安全调查人员和工程师团队发布《云威胁展望报告》,基于 2025 年下半年的观察得出结论:AI 正助力攻击者以前所未有的速度利用漏洞,如今大多数云攻击目标是薄弱的第三方软…...