小白入坑向:Java 全栈系统性学习推荐路线之一
文章目录
- 一、 引言
- 1.1 学习路径:
- 1.2 技术栈全景概述
- 1.3 前沿技术与趋势预判
- 二、 前端篇
- 2.1 基础知识
- 2.2 进阶技术
- 2.3 前端框架与工具
- 三、 后端篇
- 3.1 Java 基础
- 3.2 进阶与新特性
- 四、 企业级框架与开发工具
- 4.1 构建与项目管理
- 4.2 核心框架
- 4.3 数据持久层
- 4.4 微服务与分布式架构
- 4.5 开发工具与中间件
- 五、 数据库与 SQL 优化
- 5.1 数据库基础
- 5.2 SQL 优化策略
- 5.3 分库分表与分布式数据库
- 六、 系统架构与 DevOps 整合
- 6.1 分布式系统设计
- 6.2 DevOps 实践
- 七、 未来趋势与前瞻性技术
- 7.1 大数据与实时处理
- 7.2 知识图谱与数据驱动决策
- 7.3 大模型开发
- 7.4 云原生架构
- 八、 总结与学习路线图
一、 引言
1.1 学习路径:
-
目标:
- 掌握前端与后端核心技术,构建完整的 Java 全栈开发体系,以此有些技术虽然目前开发不会用,但为了有完整的体系认知,我建议还是系统的学习一下。
- 理解各技术组件的内在联系和应用场景,实现从单页应用到企业级分布式系统的跨越。
- 培养解决实际业务问题的能力,通过实践与项目驱动学习。
-
规划方法:
- 阶段性目标:基础知识、进阶技能、整合应用与前沿趋势,每阶段均设置明确的学习里程碑。
- 工具与资源:使用线上教程、官方文档、开源项目和技术博客,结合 IDE(如 IntelliJ IDEA、VS Code)与版本控制工具(Git)进行实践,让然b站也有很多的教程。
- 反馈与迭代:定期总结、编写博客、参与技术社区讨论,不断反思与优化学习路径。
我的相关专栏:Java+SSM+DB
前端/Vue3
我的专栏差不多是按照这些流程,在细化一些写的;当然技术是更新换代很快(当然活下来的技术,肯定简化了之前开发带来的问题),所以我的建议是系统性的学习完后,在实际的开发过程中以官方文档+“大模型老师”下快速的学习。
项目照网上学即可,b站或者什么云盘资源的网站,就能下载相关的资料,或者github,这些东西很多。
1.2 技术栈全景概述
-
前端技术:
- HTML5:标记语言,负责构建页面的结构,强调语义化标签以提升搜索引擎优化(SEO)与无障碍性。
- CSS3:样式描述语言,用于页面的布局、排版与响应式设计,支持 Flex 和 Grid 布局。
- JavaScript:脚本语言,实现页面动态效果与交互逻辑。
- ES6+:现代 JavaScript 标准,新增箭头函数、模板字符串、解构赋值等,提高代码简洁性与可维护性。
-
前端框架与工具:
- Vue3:渐进式前端框架,支持组合式 API 与选项式 API,两者各有优势,适应不同开发场景。
- Vue Router 与 Pinia:分别负责路由管理与状态管理,确保单页面应用的数据流畅与组件间数据共享。
- 构建工具:Node.js 与 NPM 提供运行时环境与包管理,Vue CLI 与 Vite 则分别支持传统与极速开发构建流程。
- UI 组件库:ElementPlus 提供企业级 UI 组件,助力快速构建一致性界面。
-
后端技术(后续章节详解):
- Java 核心语法、面向对象编程、JVM 调优等。
- Spring 全家桶、SSM 体系、Spring Boot 与 Spring Cloud 组件,支撑企业级应用。
- 数据库技术、分布式系统架构、DevOps 实践等。
1.3 前沿技术与趋势预判
-
云原生与微服务:
- 通过容器化(Docker、Kubernetes)实现应用部署与弹性扩展。
- 微服务架构与 API 网关在企业级系统中将更普遍,推动分布式事务与数据一致性方案的发展。
-
大数据与人工智能:
- 数据驱动决策和实时数据处理,推动流处理框架(如 Apache Kafka、Spark Streaming)的应用。
- 大模型开发与知识图谱构建将成为智能化决策系统的关键技术。
-
前端发展趋势:
- 更注重组件化、模块化和渐进增强,借助现代化构建工具(Vite)实现更快的开发响应。
- WebAssembly 等新技术将进一步扩展前端应用的边界。
二、 前端篇
2.1 基础知识
HTML5
-
定义与作用:
- HTML5 是最新的超文本标记语言标准,用于构建网页的结构与内容。
- 强调语义化标签(如
<header>、<nav>、<article>等),有助于搜索引擎优化(SEO)和提高页面可访问性。
-
关键知识点:
- 文档结构(
<html>、<head>、<body>) - 常用标签与属性
- 多媒体标签(
<video>、<audio>) - 表单元素与验证
- 文档结构(
CSS3
-
定义与作用:
- CSS3 是层叠样式表的最新标准,用于描述网页内容的外观与布局。
- 支持响应式设计,通过媒体查询适配不同设备。
-
关键知识点:
- 选择器与优先级
- 盒模型及布局原理
- Flex 布局与 Grid 布局:前者适用于一维布局,后者擅长二维布局。
- 动画与过渡效果
- 响应式设计与媒体查询
JavaScript
-
定义与作用:
- JavaScript 是一种解释性编程语言,用于实现网页的交互效果与动态数据处理。
- 可在浏览器中直接运行,配合 HTML 与 CSS 实现前端逻辑。
-
关键知识点:
- 基础语法:变量声明(var、let、const)、数据类型(数字、字符串、布尔、null、undefined、对象、数组)
- 运算符、流程控制语句(if-else、switch、for/while 循环)
- 函数与作用域
- 基本事件处理(点击、悬停、输入等)
- DOM 操作基础(获取、修改、添加与删除节点)
2.2 进阶技术
ES6+ 特性
-
定义与作用:
- ECMAScript 6(简称 ES6)及后续版本引入了大量新语法和特性,旨在提升 JavaScript 的可读性、简洁性与开发效率。
-
关键知识点:
- 箭头函数:简化函数表达式,绑定上下文;
- 模板字符串:使用反引号定义字符串,支持嵌入变量;
- 解构赋值:快速提取数组与对象中的值;
- 扩展运算符:用于数组和对象的合并与复制;
- Promise 与 async/await:处理异步操作,避免回调地狱,提升代码可维护性。
DOM 操作与 BOM
-
DOM(文档对象模型):
- 定义:一种将 HTML、XML 文档表示为对象树的标准,允许程序动态访问和更新文档内容。
- 关键操作:节点选择(如
document.getElementById、document.querySelector)、节点操作(增删改查)、事件绑定与处理。
-
BOM(浏览器对象模型):
- 定义:提供与浏览器窗口交互的对象模型,如
window、navigator、location等。 - 关键操作:浏览器信息获取、页面跳转、弹窗处理、定时任务设置(
setTimeout、setInterval)。
- 定义:提供与浏览器窗口交互的对象模型,如
异步请求
-
定义与作用:
- 异步请求技术允许浏览器在不刷新整个页面的情况下与服务器交换数据,从而实现动态更新内容。
-
关键知识点:
- AJAX:异步 JavaScript 与 XML,传统实现方式,通过 XMLHttpRequest 对象发起请求;
- Fetch API:现代浏览器内置的接口,提供基于 Promise 的网络请求;
- Axios:基于 Promise 的 HTTP 客户端,支持拦截器、取消请求和响应转换,适合复杂项目需求。
-
最佳实践:
- 处理跨域请求、错误捕获与重试机制
- 优化请求性能,避免不必要的网络调用
2.3 前端框架与工具
Vue3 框架核心概念
- 定义与作用:
- Vue3 是一种渐进式前端框架,通过组件化开发提升代码复用性和维护性。
- 组合式 API 与 选项式 API:
- 组合式 API 提供更灵活的逻辑复用方式,适用于大型项目;
- 选项式 API 则更易于上手,适合中小型项目。
- 生命周期:组件创建、更新与销毁过程中提供的钩子函数,便于开发者控制组件行为。
路由管理
-
定义与作用:
- 路由管理负责控制单页面应用中的页面切换与导航。
- Vue Router 提供动态路由匹配、嵌套路由以及路由传值等功能,确保页面状态的同步管理。
-
关键知识点:
- 路由配置、命名路由
- 嵌套路由与动态路由参数
- 导航守卫与懒加载
状态管理
-
定义与作用:
- 状态管理用于维护组件之间共享的数据和状态,避免数据不一致问题。
- Pinia:现代化状态管理库,轻量、直观,相较于传统的 Vuex 拥有更清晰的 API 设计与调试体验。
-
关键知识点:
- 状态的定义与变更
- 模块化管理与持久化策略
- 调试工具的使用
UI 组件集成
-
定义与作用:
- UI 组件库(如 ElementPlus)提供一整套预制的、风格统一的界面组件,减少重复造轮子。
-
关键知识点:
- 常用组件:按钮、表单、表格、对话框等
- 主题定制与响应式设计
- 与 Vue 组件的无缝集成
构建工具
- 定义与作用:
- 构建工具用于管理项目依赖、自动化打包与部署,提高开发效率。
- Node.js 与 NPM:Node.js 提供 JavaScript 的运行环境,NPM 作为包管理器,负责安装、更新与管理第三方模块。
- Vue CLI 与 Vite:
- Vue CLI 提供全面的项目脚手架,适合复杂项目的脚本配置;
- Vite 以极速冷启动和热更新著称,适用于现代前端开发场景。
版本控制
- 定义与作用:
- 版本控制系统(如 Git)用于跟踪代码变更,协助团队进行协同开发。
- 关键知识点:
- 基本命令:commit、push、pull、merge
- 分支管理策略:如 Git Flow、Feature Branch 模型
- 协作开发与代码冲突解决
三、 后端篇
3.1 Java 基础
语言核心
-
表达式:
- 计算逻辑的基本构成单元,包含算术、关系、逻辑运算符。
- 示例:
a + b,a > b && c < d。
-
流程控制:
- 条件语句:
if、else if、switch; - 循环语句:
for、while、do-while。 - 控制跳转:
break、continue、return。
- 条件语句:
-
数组:
- 数据存储结构,用于存储同一数据类型的多个元素;
- 一维与多维数组的声明、初始化、遍历。
-
方法:
- 方法的定义、调用、重载(同一方法名不同参数列表);
- 递归调用、参数传递(基本类型传值与对象引用传递)。
面向对象
-
类与对象:
- 类是对象的模板,定义属性与行为;
- 对象是类的实例化,通过构造函数进行初始化。
-
封装:
- 数据隐藏,通过访问修饰符(private、public、protected)控制访问权限;
- 提供 getter 与 setter 方法进行数据交互。
-
继承:
- 通过关键字
extends实现代码复用,子类继承父类的属性与方法; - 使用
super调用父类构造函数或方法。
- 通过关键字
-
多态:
- 同一接口,不同实现,运行时动态绑定;
- 通过方法重写(Override)实现运行时多态性。
-
抽象类与接口:
- 抽象类:包含抽象方法和具体实现,不能实例化;
- 接口:定义行为规范,Java 8 后支持默认方法和静态方法,常用于解耦和实现回调。
基础类库
-
Object 类:
- 所有类的根类,常用方法包括
equals()、hashCode()、toString(); - 重写这些方法以满足自定义业务需求。
- 所有类的根类,常用方法包括
-
集合框架:
- List:有序集合,常用实现如
ArrayList(动态数组)和LinkedList(链表结构); - Set:不允许重复元素,常用实现如
HashSet(基于哈希表)、TreeSet(基于红黑树); - Map:键值对存储结构,常用实现如
HashMap、TreeMap; - 性能与线程安全对比:例如
HashMap非线程安全,而ConcurrentHashMap则支持高并发场景。
- List:有序集合,常用实现如
-
工具类:
- 常用工具类如
java.util.Arrays和java.util.Collections提供排序、查找、反转等常用操作; - Apache Commons、Guava 等第三方库进一步扩展工具方法。
- 常用工具类如
异常处理
-
异常分类:
- 检查型异常(Checked Exception):必须捕获或声明抛出;
- 非检查型异常(Unchecked Exception):继承自
RuntimeException,不强制捕获。
-
try-catch:
- 捕获异常,提供容错处理;
- 可嵌套使用以处理不同异常层次。
-
try-with-resources:
- 自动管理资源(如文件、数据库连接)的关闭,避免资源泄露;
- 适用于实现了
AutoCloseable接口的对象。
-
自定义异常:
- 继承
Exception或RuntimeException,根据业务需求设计异常信息; - 提高代码可读性与错误定位能力。
- 继承
反射机制
-
获取 Class 对象:
- 使用
Class.forName("全类名")、对象.getClass()、类名.class等方式。
- 使用
-
动态调用:
- 通过反射创建对象、调用方法、访问或修改字段;
- 提高代码的灵活性,常用于框架和容器中(如 Spring)。
-
注解解析:
- 自定义注解与使用内置注解,通过反射读取注解信息,完成自动化配置与依赖注入;
- 例如
@Override、@Deprecated及自定义业务注解。
3.2 进阶与新特性
Java 8+ 新特性
-
Lambda 表达式:
- 函数式编程的核心,简化匿名内部类,实现代码简洁化;
- 示例:
(a, b) -> a + b。
-
Stream API:
- 用于对集合进行复杂数据处理,如过滤、映射、归约等操作;
- 支持顺序与并行流,利用多核处理器提升性能。
-
Optional:
- 用于避免空指针异常的容器类;
- 提供链式调用方法,如
ifPresent()、orElse(),实现惰性求值。
并发编程
-
多线程创建:
- Thread 类:通过继承
Thread类,重写run()方法; - Runnable 接口:实现
Runnable接口,适合多个线程共享资源; - Callable 接口:支持返回结果与异常处理,结合
Future获取异步结果。
- Thread 类:通过继承
-
线程安全:
- 使用同步方法、同步块;
Lock接口(如ReentrantLock)提供更灵活的锁机制;- 使用原子变量类(如
AtomicInteger)避免加锁操作。
-
ThreadLocal:
- 实现线程局部变量,保证每个线程持有独立变量副本,解决线程间共享数据带来的并发问题。
-
并发集合:
- 专门设计用于多线程环境,如
ConcurrentHashMap、CopyOnWriteArrayList; - 解决传统集合在并发操作下的安全问题。
- 专门设计用于多线程环境,如
JVM 内部原理
-
内存模型:
- JVM 内存结构包括堆、栈、方法区(或元空间)、本地方法栈等;
- 理解各区域作用,帮助优化内存使用。
-
垃圾回收机制:
- 不同垃圾收集器(Serial、Parallel、CMS、G1)的工作原理及适用场景;
- 调整 JVM 参数(如
-Xmx、-Xms、-XX:+UseG1GC)优化 GC 性能。
-
内存泄漏排查与调优:
- 使用工具(如 JVisualVM、MAT、JProfiler)检测内存泄漏;
- 分析对象生命周期、GC 日志,及时释放无用资源。
数据结构与算法
-
常用算法:
- 排序算法:快速排序、归并排序、冒泡排序等;
- 查找算法:二分查找、哈希查找等。
-
集合框架性能对比:
- 比较不同集合(List、Set、Map)的时间复杂度与空间效率;
- 分析适用场景,选择最优数据结构。
-
数据处理思路:
- 复杂度分析:时间复杂度和空间复杂度的基本概念;
- 优化策略:减少不必要的遍历、使用缓存、采用并行处理等。
设计模式
这里推荐《大话设计模式》:

当然不止以下这些,这里建议学习熟悉即可,因为框架已经包含了,但要是提升的话,建议深入的研究一下。
-
创建型模式:
- 单例模式:确保类仅有一个实例,并提供全局访问点;
- 工厂模式:通过工厂类实例化对象,降低耦合;
- 抽象工厂模式、建造者模式:应对更复杂对象创建需求。
-
结构型模式:
- 适配器模式:将一个接口转换成客户希望的另一个接口;
- 装饰器模式:动态地给对象添加职责;
- 代理模式:为其他对象提供代理以控制对其的访问。
-
行为型模式:
- 观察者模式:对象之间一对多的依赖关系,自动通知更新;
- 策略模式:定义一系列算法,封装各自实现并可互换;
- 模板方法模式:在父类中定义算法骨架,子类实现细节;
- 责任链模式:请求在多个对象间传递,直到处理为止。
-
应用实践:
- 分析各设计模式在实际项目中的应用场景;
- 分享优化建议,讨论其扩展性与维护性优势。
四、 企业级框架与开发工具
4.1 构建与项目管理
Maven
- 定义与作用:
- Maven 是基于 POM(Project Object Model)的项目管理工具,主要用于自动化构建、依赖管理和生命周期管理。
- 关键技术点:
- 项目构建:利用 Maven 的生命周期(如 compile、test、package、install、deploy)实现自动化构建。
- 依赖管理:在
pom.xml文件中配置依赖项,自动从中央仓库或私服下载和管理第三方库,确保项目环境一致性。 - 常用插件:包括 Compiler Plugin(编译)、Surefire Plugin(单元测试)、Shade Plugin(打包),帮助简化构建过程。
- 实践工具:
- 集成开发环境(IDE)如 IntelliJ IDEA 或 Eclipse 提供 Maven 插件,方便管理和调试项目。
4.2 核心框架
Spring 核心
- 定义与作用:
- Spring 框架为企业级应用提供了全面的支持,其核心功能主要包括 IOC(控制反转)容器、AOP(面向切面编程)、依赖注入以及事务管理。
- 关键技术点:
- IOC 容器:通过反转控制实现对象的自动管理与装配,降低模块间的耦合度。
- AOP 实现:模块化横切关注点(如日志、权限校验、事务处理),增强代码的可维护性。
- 依赖注入:通过构造器或 Setter 方法自动注入对象依赖,提升代码的灵活性。
- 事务管理:通过声明式事务配置(基于注解或 XML),保障数据操作的原子性与一致性。
- 实践案例:
- 使用 Spring Boot 进一步简化 Spring 的配置与部署,实现快速开发与集成。
Spring MVC
- 定义与作用:
- Spring MVC 是基于 MVC(Model-View-Controller)架构的 Web 框架,用于构建灵活、解耦的 Web 应用。
- 关键技术点:
- 请求映射:利用
@RequestMapping、@GetMapping、@PostMapping等注解将 URL 映射到控制器方法。 - 控制器:接收并处理 HTTP 请求,调用业务逻辑后返回视图或数据。
- 拦截器:通过 HandlerInterceptor 对请求进行预处理与后处理,如安全认证、日志记录。
- 视图解析:结合模板引擎(如 Thymeleaf、Freemarker)实现动态页面渲染。
- 数据绑定:自动将请求参数绑定到 Java 对象,并支持数据校验与格式转换。
- 请求映射:利用
- 应用优势:
- 实现前后端分离,提高代码复用性与系统可维护性。
Spring Boot
- 定义与作用:
- Spring Boot 是对 Spring 框架的进一步封装,旨在通过自动配置和约定优于配置的理念,大幅简化项目初始化和开发流程。
- 关键技术点:
- 自动配置:根据项目依赖自动装配所需的组件,减少冗余配置。
- Starter 模块:提供预设的依赖集合,快速搭建项目基础架构。
- 配置管理:支持 YAML 和 properties 配置文件,便于统一管理应用参数。
- 内嵌容器:集成 Tomcat、Jetty 或 Undertow,无需额外部署,适合微服务架构。
- 工具与实践:
- 使用 Spring Initializr 快速生成项目结构;集成 DevTools 实现热部署,加速开发迭代。
SSM 整合
- 定义与作用:
- SSM 整合指将 Spring、Spring MVC 与 MyBatis 组合使用,构建一个高内聚、低耦合的企业级 Web 应用。
- 关键技术点:
- 整合机制:利用 Spring 管理对象生命周期与事务,Spring MVC 负责请求分发与视图处理,MyBatis 处理数据持久化。
- 配置重点:数据源配置、事务管理配置、Mapper 扫描等确保各层之间的无缝衔接。
- 实践优势:
- 提高系统的可维护性和扩展性,同时便于团队协同开发与持续集成。
4.3 数据持久层
JDBC
- 定义与作用:
- JDBC(Java Database Connectivity)是 Java 提供的标准 API,用于连接和操作关系型数据库。
- 关键技术点:
- 数据库连接:通过
DriverManager获取连接,支持常见数据库如 MySQL、Oracle、PostgreSQL。 - 事务处理:手动管理提交与回滚,确保数据一致性。
- 基础操作:执行 SQL 查询与更新,实现数据的增删改查(CRUD)。
- 数据库连接:通过
- 实践优化:
- 利用 Spring 提供的 JDBC Template 封装模板代码,简化开发工作。
MyBatis
- 定义与作用:
- MyBatis 是一种优秀的持久层框架,通过 XML 或注解方式将 SQL 与 Java 对象进行映射,简化数据库操作。
- 关键技术点:
- 核心配置:配置数据源、事务管理与 SQL 映射文件。
- 映射文件:定义 SQL 语句与 Java 对象之间的映射规则,自动化数据转换。
- 动态 SQL:利用
<if>、<choose>、<foreach>等标签根据条件生成灵活 SQL。 - 缓存机制:实现一级缓存以减少数据库访问次数;支持 Enum 映射和自定义 TypeHandler 以满足特殊数据类型需求。
- 实践工具:
- 使用 MyBatis Generator 自动生成实体类、Mapper 接口和映射文件,加速开发流程。
MyBatis-Plus
- 定义与作用:
- MyBatis-Plus 是 MyBatis 的增强工具,提供更多便捷功能以提高开发效率。
- 关键技术点:
- 通用 CRUD:内置 Mapper 接口自动实现常见的 CRUD 操作。
- 代码生成:根据数据库表结构自动生成代码,降低重复劳动。
- 乐观锁:通过版本号机制,防止并发修改导致的数据冲突。
- 多租户支持:在多租户架构中,自动添加租户标识,实现数据隔离。
- 集成实践:
- 无缝集成 Spring Boot,通过简单配置即可开启各项功能。
4.4 微服务与分布式架构
Spring Cloud
- 定义与作用:
- Spring Cloud 为微服务架构提供一站式解决方案,简化服务注册、配置管理、负载均衡、熔断等复杂问题。
- 关键技术点:
- 服务注册与发现:使用 Eureka 实现服务的注册、监控与负载均衡,确保系统高可用。
- 配置中心:集中管理各服务的配置,支持动态刷新和版本控制。
- API 网关:利用 Zuul 或 Spring Cloud Gateway 实现请求转发、安全认证和限流管理。
- 负载均衡:通过 Ribbon 集成,实现客户端负载均衡,将请求分散到各个服务实例。
- 服务熔断:集成 Hystrix 或 Resilience4j,预防单个服务故障蔓延至整个系统。
- 实践案例:
- 构建微服务集群,实现服务自动注册、配置中心管理和高可用负载均衡。
分布式事务
- 定义与作用:
- 分布式事务用于解决跨服务数据一致性问题,确保在多服务调用过程中数据的可靠传递和一致性。
- 关键技术点:
- Saga 模式:将全局事务拆分为一系列局部事务,通过补偿机制进行数据回滚。
- 事件溯源:记录业务状态的每一次变更,便于重放和恢复。
- 分布式锁:利用 Redis、ZooKeeper 等工具,实现跨服务资源锁定,防止并发冲突。
- 实践要点:
- 根据业务场景选择合适的事务模型,平衡系统性能与数据一致性要求。
4.5 开发工具与中间件
接口文档工具:Swagger
- 定义与作用:
- Swagger 是一款开源工具,用于设计、构建和自动生成 RESTful API 的交互式文档。
- 关键技术点:
- 集成 Spring Boot,通过注解(如
@Api、@ApiOperation)描述接口信息; - 自动生成并实时预览接口文档,支持在线测试和版本控制。
- 集成 Spring Boot,通过注解(如
代码简化工具:Lombok
- 定义与作用:
- Lombok 利用注解自动生成 Getter、Setter、构造方法等常见代码,极大减少样板代码。
- 关键技术点:
- 通过
@Data、@Builder、@AllArgsConstructor等注解,实现代码的简化和提高可读性; - 配合 IDE 插件,确保代码提示与自动生成功能正常工作。
- 通过
缓存策略:Redis
- 定义与作用:
- Redis 是一款高性能的开源内存数据库,支持键值存储和多种数据结构,常用于实现分布式缓存。
- 关键技术点:
- 数据一致性:采用主从复制和持久化策略,确保数据在高并发下保持一致。
- 缓存穿透:使用布隆过滤器或缓存空值,防止非法请求穿透到数据库。
- 缓存雪崩与击穿:设置合理的过期策略与互斥锁,分散缓存失效时的压力。
任务调度:Quartz
- 定义与作用:
- Quartz 是一款功能丰富的任务调度框架,支持定时任务、重复任务及复杂调度策略。
- 关键技术点:
- 配置任务触发器、作业详情和调度器,实现灵活的任务调度;
- 支持集群部署,满足分布式环境下的任务调度需求。
CI/CD 工具:Jenkins
- 定义与作用:
- Jenkins 是一款开源自动化服务器,用于构建持续集成(CI)和持续交付(CD)的全流程自动化。
- 关键技术点:
- 配置流水线(Pipeline),通过脚本自动化代码构建、测试和部署;
- 集成 Git、Maven、Docker 等工具,实现端到端自动化流程。
数据导入导出:EasyExcel
- 定义与作用:
- EasyExcel 是基于 Apache POI 封装的 Excel 处理工具,支持高效读取和写入大数据量 Excel 文件。
- 关键技术点:
- 高性能处理大规模数据,降低内存占用;
- 支持复杂数据格式的导入导出,适用于报表生成、数据迁移等业务场景。
消息中间件:MQTT 及其他消息队列
- 定义与作用:
- 消息中间件用于解耦系统,实现异步处理、流量削峰和系统解耦。
- 关键技术点:
- MQTT:轻量级发布/订阅协议,适用于物联网(IoT)及实时通信场景;
- 其他消息队列:如 Kafka、RabbitMQ,提供高吞吐量、持久化、消息确认机制,确保消息可靠传输;
- 支持集群部署与高可用架构,满足企业级应用需求。
五、 数据库与 SQL 优化
5.1 数据库基础
SQL 语法
-
DDL(数据定义语言):
- 用于定义数据库结构,例如创建、修改、删除数据库对象(表、索引、视图)。
- 关键语句:
CREATE、ALTER、DROP。
-
DML(数据操作语言):
- 用于对数据进行增删改查操作。
- 关键语句:
INSERT、UPDATE、DELETE、SELECT。
-
DCL(数据控制语言):
- 用于定义数据库访问权限。
- 关键语句:
GRANT、REVOKE。
-
TCL(事务控制语言):
- 用于管理数据库事务,确保数据操作的完整性。
- 关键语句:
COMMIT、ROLLBACK、SAVEPOINT。
事务管理
-
ACID 原则:
- 原子性(Atomicity):事务是一个不可分割的工作单元,要么全部完成,要么全部失败。
- 一致性(Consistency):事务执行前后数据库必须保持一致状态。
- 隔离性(Isolation):并发事务互不干扰,各自独立运行。
- 持久性(Durability):事务提交后,对数据的修改是永久性的。
-
BASE 理论:
- 用于分布式系统,强调“基本可用(Basically Available)”、“软状态(Soft state)”、“最终一致性(Eventual consistency)”,作为对 ACID 理论的补充。
-
事务隔离级别:
- 读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)、串行化(Serializable),不同级别平衡并发性能与数据一致性。
数据库设计
- 规范化设计:
- 将数据拆分成多个表以消除冗余,常见范式包括 1NF、2NF、3NF、BCNF 等。
- 表结构设计:
- 合理设计字段类型、主键、索引;
- 关注数据存储效率与查询性能。
- 数据关联及约束:
- 使用外键、唯一约束、检查约束等维护数据完整性;
- 建立合理的表间关系(如一对一、一对多、多对多)。
5.2 SQL 优化策略
查询执行原理
- SQL 书写顺序 vs. 实际执行顺序:
- 虽然 SQL 语句书写顺序通常为
SELECT→FROM→WHERE→GROUP BY→HAVING→ORDER BY,但实际执行顺序可能有所不同,理解这一点有助于优化查询。
- 虽然 SQL 语句书写顺序通常为
- WHERE 与 HAVING 的区别:
- WHERE:在数据分组前过滤行,适用于行级过滤;
- HAVING:在数据分组后过滤聚合结果,适用于分组级别的条件判断。
索引优化
- 单列索引:
- 针对单一字段建立索引,提高该字段查询速度。
- 复合索引:
- 针对多个字段建立组合索引,需注意字段顺序与最左匹配原则。
- 全文索引:
- 适用于大文本数据的关键词搜索,常用于搜索引擎应用。
- 聚簇索引:
- 按照索引顺序物理存储数据(如 InnoDB 的主键索引),适用于范围查询。
- 实践工具:
- 使用
EXPLAIN语句分析查询计划,判断索引使用情况并进行调整。
- 使用
性能优化
- JOIN 策略:
- 优化多表连接,选择合适的 JOIN 类型(INNER、LEFT、RIGHT JOIN 等);
- 尽量减少子查询,多使用 JOIN 或临时表。
- 避免 SELECT * :
- 指定所需字段,降低数据传输和解析负担。
- 使用 LIMIT:
- 限制返回数据行数,减少不必要的数据处理。
- 子查询与 JOIN 替换技巧:
- 在某些场景下,将子查询改写为 JOIN 可提升性能;
- 分析数据量与执行计划,选择最优查询方式。
5.3 分库分表与分布式数据库
分库分表概述
- 分库:
- 将数据按一定规则拆分到多个数据库服务器中,以分散单库压力和提高并发处理能力。
- 分表:
- 将单个表的数据按照业务或数据量拆分成多个物理表,优化查询性能和写入效率。
- 常见策略:
- 水平拆分(按行分割):基于某个字段(如用户ID)的范围或哈希值进行拆分;
- 垂直拆分(按列分割):将不同业务模块或字段拆分到不同表中,实现功能模块化。
分布式数据库实践
- 数据分片(Sharding):
- 利用算法(哈希、范围、目录)将数据均匀分布到多个节点上;
- 需设计全局唯一标识符和数据路由规则。
- 分布式事务:
- 跨库/跨表操作的数据一致性保障,常用方案包括两阶段提交(2PC)、TCC 模式、Saga 模式等。
- 中间件支持:
- 使用分库分表中间件(如 MyCAT、ShardingSphere)实现透明化管理和路由,降低开发复杂度。
- 数据复制与同步:
- 实现主从复制、读写分离,提高系统的高可用性;
- 结合缓存(如 Redis)与消息队列缓解高并发下的压力。
- 分布式数据库架构:
- 针对大规模数据和高并发应用,设计数据分布、查询优化、故障恢复机制,确保系统性能和数据一致性。
六、 系统架构与 DevOps 整合
6.1 分布式系统设计
微服务架构
- 定义与作用:
- 微服务架构将单体应用拆分为多个独立的小服务,每个服务专注于单一业务功能,可独立部署、扩展和维护。
- 关键技术点:
- 服务拆分:采用领域驱动设计(DDD),根据业务领域划分服务,实现高内聚低耦合;
- 服务网关:利用 API 网关(如 Spring Cloud Gateway 或 Zuul)统一管理请求路由、认证、流量控制及安全防护;
- 负载均衡:采用客户端负载均衡(例如 Ribbon)或服务注册与发现机制(例如 Eureka),将请求均衡分发到各服务实例;
- 容错机制:引入熔断器(如 Hystrix 或 Resilience4j)、重试与降级策略,防止单个服务故障扩散,保障系统整体稳定性。
- 实践工具与案例:
- Spring Cloud 提供的各组件实现微服务架构;
- 使用 Docker 容器化部署各个微服务,借助 Kubernetes 管理集群,实现自动扩展与故障恢复。
数据一致性
- 定义与作用:
- 分布式系统中的数据一致性解决方案确保在跨多个服务和数据库操作时,数据状态保持正确且一致。
- 关键技术点:
- 分布式事务:采用两阶段提交(2PC)、TCC 模式或 Saga 模式,协调跨服务数据操作,确保事务的原子性;
- CAP 理论:理解一致性(Consistency)、可用性(Availability)与分区容错性(Partition tolerance)之间的权衡,设计合理的系统架构;
- 最终一致性方案:在高并发场景下,允许短暂的数据不一致,通过异步消息和补偿机制,实现数据在一定时间内达到一致状态。
- 实践工具与案例:
- 使用消息队列(如 Kafka 或 RabbitMQ)实现数据的异步同步;
- 结合 Redis 缓存和分布式锁(如基于 ZooKeeper 或 Redis 实现)保障关键业务数据的一致性。
6.2 DevOps 实践
CI/CD 流程
- 定义与作用:
- 持续集成(CI)与持续交付(CD)旨在通过自动化构建、测试和部署,实现代码快速迭代与高质量交付。
- 关键技术点:
- 版本管理:采用 Git 进行代码管理,确保多人协同开发及版本控制;
- 自动化构建:使用 Maven 或 Gradle 结合 Jenkins 等工具配置流水线,实现代码编译、单元测试和静态代码检查;
- 持续集成:自动执行测试用例,及时反馈代码质量问题,确保每次提交均可安全集成;
- 持续部署:利用自动化脚本和容器化技术,将代码自动部署到开发、测试或生产环境中,缩短上线周期。
- 实践工具与案例:
- Jenkins、GitLab CI、Travis CI 等自动化工具;
- Docker 化环境确保不同阶段的一致性和稳定性。
环境管理
- 定义与作用:
- 环境管理确保开发、测试、预生产及生产环境配置一致,降低因环境差异导致的问题。
- 关键技术点:
- Linux 基础:掌握常用命令、文件系统操作、网络配置,为服务器运维与部署打好基础;
- 环境变量配置:通过 Shell 脚本或配置管理工具,设置与管理环境变量,确保关键参数一致;
- Shell 脚本应用:编写自动化脚本处理部署、备份、监控及日志收集,提升运维效率。
- 实践工具与案例:
- Bash、Ansible、Chef、Puppet 等自动化运维工具,用于批量配置与环境同步。
容器化部署(选修)
- 定义与作用:
- 容器化技术通过轻量级虚拟化,实现应用与其依赖环境的打包,确保跨平台一致运行。
- 关键技术点:
- Docker 基础:构建与管理 Docker 镜像,实现应用的快速部署与隔离;
- 容器编排:利用 Kubernetes 实现容器集群的管理、自动扩展、负载均衡及故障恢复;
- 编排工具:借助 Docker Compose、Helm 等工具,简化复杂微服务部署。
- 实践工具与案例:
- Docker、Kubernetes、Docker Compose、Helm,帮助构建高效灵活的容器化部署方案。
日志与监控
- 定义与作用:
- 日志与监控系统用于实时跟踪应用状态,及时发现并解决性能瓶颈和系统故障。
- 关键技术点:
- 分布式日志系统:集中收集各服务日志,支持日志聚合、搜索与分析,常用解决方案包括 ELK(Elasticsearch、Logstash、Kibana)或 EFK(Elasticsearch、Fluentd、Kibana)堆栈;
- 链路追踪:通过分布式追踪(如 Zipkin 或 Jaeger),记录跨服务调用链,快速定位故障根源;
- 性能监控与报警:利用监控系统(如 Prometheus 与 Grafana)实时采集系统指标,设置报警规则,确保系统稳定运行。
- 实践工具与案例:
- ELK/EFK 堆栈用于日志处理;
- Prometheus、Grafana 实现指标监控与数据可视化;
- Zipkin 或 Jaeger 实现分布式链路追踪。
七、 未来趋势与前瞻性技术
7.1 大数据与实时处理
流处理架构、数据湖、分布式计算
- 流处理架构:
- 定义与作用:实时处理大量数据流,实现低延迟数据分析与决策。
- 关键技术与工具:
- Apache Kafka:高吞吐量分布式消息系统,用于数据传输与流处理。
- Apache Flink/Storm:实时流处理引擎,支持复杂事件处理和窗口计算。
- Spark Streaming:利用微批处理架构实现近实时数据处理。
- 数据湖:
- 定义与作用:集中存储结构化与非结构化数据,支持大数据分析和机器学习。
- 关键技术与工具:
- Hadoop HDFS:分布式存储系统,用于构建数据湖。
- AWS S3、Azure Data Lake:云端数据湖解决方案。
- 分布式计算:
- 定义与作用:将计算任务分布到多台机器上并行处理,提升大规模数据处理效率。
- 关键技术与工具:
- Apache Hadoop MapReduce:分布式计算框架,通过 Map 与 Reduce 任务处理大数据。
- Apache Spark:内存计算框架,支持批处理与流处理,提高计算速度。
7.2 知识图谱与数据驱动决策
数据建模、语义分析、图数据库应用
- 数据建模:
- 定义与作用:构建数据之间的逻辑关系与结构,帮助企业形成清晰的数据视图。
- 关键技术:ER 图、UML 类图、RDF 模型。
- 语义分析:
- 定义与作用:理解数据背后的语义关系,实现自然语言处理与智能搜索。
- 关键技术与工具:
- 自然语言处理(NLP):如 spaCy、NLTK,进行文本解析和语义标注。
- 机器学习:借助 TensorFlow、PyTorch 构建语义模型。
- 图数据库应用:
- 定义与作用:基于图结构存储数据,适合存储复杂关联关系,如社交网络、推荐系统。
- 关键技术与工具:
- Neo4j:主流图数据库,支持 Cypher 查询语言。
- Amazon Neptune:云原生图数据库,支持 RDF 和 Property Graph 模型。
7.3 大模型开发
多语言互操作、GraalVM 优化、性能调优实践
- 多语言互操作:
- 定义与作用:实现不同编程语言之间的互联互通,提升系统的灵活性与扩展性。
- 关键技术:
- GraalVM:多语言虚拟机,支持 Java、JavaScript、Python、Ruby 等语言之间的互操作。
- JNI(Java Native Interface):实现 Java 与其他本地代码(如 C/C++)的交互。
- GraalVM 优化:
- 定义与作用:利用 GraalVM 提供的 JIT 编译与 AOT 编译优势,提升运行时性能。
- 关键技术与实践:
- 配置 GraalVM 环境,优化内存管理与并发性能;
- 利用 Polyglot API 实现多语言数据交互与性能监控。
- 性能调优实践:
- 关键策略:通过基准测试、性能监控、内存分析,识别瓶颈;
- 工具支持:JVisualVM、JProfiler、GraalVM 自带的性能分析工具。
7.4 云原生架构
Serverless 架构、无状态服务、云平台集成趋势
- Serverless 架构:
- 定义与作用:无需管理底层服务器资源,通过事件驱动实现按需自动扩展。
- 关键技术与工具:
- AWS Lambda、Azure Functions、Google Cloud Functions:云平台提供的 Serverless 计算服务。
- 支持自动缩放与计量计费,降低运维成本。
- 无状态服务:
- 定义与作用:服务实例不保留客户端状态,使得负载均衡与横向扩展更加容易。
- 关键技术:
- 利用缓存(如 Redis)存储会话信息;
- 设计 RESTful API,实现无状态通信。
- 云平台集成趋势:
- 定义与作用:整合多种云服务(计算、存储、网络、安全等),构建高效、弹性云原生应用。
- 关键技术与工具:
- 容器服务(如 Kubernetes、Docker Swarm)与 Serverless 相结合;
- 云原生数据库、消息队列和监控工具的无缝集成;
- 利用 CI/CD 工具自动化部署云原生应用,实现持续交付。
八、 总结与学习路线图
技术栈整合:全链路知识框架归纳
- 全链路知识框架:
- 将前端、后端、企业级框架、数据库、系统架构与 DevOps 及未来技术有机结合,构成完整的技术体系。
- 归纳各技术之间的内在联系及边界,形成整体解决方案,便于项目落地与团队协作。
- 工具与实践:
- 整合 IDE(如 IntelliJ IDEA、VS Code)、版本控制、自动化构建工具和监控系统,形成闭环管理体系。
自驱式学习:实践驱动、案例导向、技术分享
- 实践驱动:
- 强调通过项目实践、实验验证及错误修正,不断提升技术能力。
- 推荐参与开源项目、线上编程挑战和技术社区讨论。
- 案例导向:
- 通过典型企业级案例(如电商平台、分布式系统、实时数据处理)剖析技术实现与优化方案。
- 分析成功案例与失败教训,形成系统化思考。
- 技术分享:
- 鼓励编写博客、举办技术讲座与线上分享,将个人经验和实践总结公开传播,促进知识沉淀与交流。
前瞻性规划:技术趋势预判、战略布局、持续更新与优化
- 技术趋势预判:
- 关注大数据、人工智能、区块链、物联网及云原生架构等前沿技术的最新动态。
- 定期评估技术发展趋势,适时调整学习与应用策略。
- 战略布局:
- 根据企业业务需求和技术生态构建长期技术路线图,进行战略性技术储备与落地。
- 制定多阶段技术规划,从初级、中级到高级逐步推进。
- 持续更新与优化:
- 建立持续集成、自动化测试与实时监控机制,保障技术系统的动态升级与高效运行;
- 定期回顾与迭代,优化系统架构与技术细节,确保始终处于行业领先地位。
相关文章:
小白入坑向:Java 全栈系统性学习推荐路线之一
文章目录 一、 引言1.1 学习路径:1.2 技术栈全景概述1.3 前沿技术与趋势预判 二、 前端篇2.1 基础知识2.2 进阶技术2.3 前端框架与工具 三、 后端篇3.1 Java 基础3.2 进阶与新特性 四、 企业级框架与开发工具4.1 构建与项目管理4.2 核心框架4.3 数据持久层4.4 微服务…...

云原生存储架构:构建数据永续的新一代存储基础设施
引言:重新定义数据基础设施边界 蚂蚁集团基于Ceph构建的全闪存存储集群达到EB级规模,单集群IOPS突破1亿,延迟稳定在200μs内。Snowflake的存储计算分离架构使其数据湖查询速度提升14倍,存储成本降低82%。Gartner预测到2025年70%企…...

QTableWidget之表格列的隐藏与显示(折叠)
今天晚上花点时间研究一下表格列的显隐问题(类似与excel的隐藏列功能),在网络上搜罗了一通资料,没现成的例子作为借鉴,只能自己研究编写了。现在将过程记录下来,以便日后翻阅。 首先声明:因为时…...

Leetcode3146. 两个字符串的排列差
题目描述: 给你两个字符串 s 和 t,每个字符串中的字符都不重复,且 t 是 s 的一个排列。 排列差 定义为 s 和 t 中每个字符在两个字符串中位置的绝对差值之和。 返回 s 和 t 之间的 排列差 。 代码思路: 建立字符位置映射&…...

二百八十五、华为云PostgreSQL——建分区表并设置主键
一、目的 在PostgreSQL里建表,设置主键,三个字段确认数据的唯一性。设置分区字段,按月分区 二、PostgreSQL版本 三、PostgreSQL 9.2.4 版本缺点 在 PostgreSQL 9.2.4 中,虽然你可以创建分区表,但需要注意的是&#…...

系统架构设计师-第3章 数据库设计
【本章学习建议】 根据考试大纲,本章主要考查系统架构设计师单选题,预计考5分左右,以及案例分析1题,25分。对应第二版教材2.3.3小节以及第6章,主要考点在第6章,这里一起合并到本章课程中。 3.1 数据库基本…...

SAP MDG —— MDG on S/4HANA 2023 FPS03 创新汇总
文章目录 MDG 基于SAP S/4HANA 2023 FPS03的创新BP/C/S:消息控制BP/C/S:手工分配数据控制者MDG-F:使用S/4扩展数据校验功能生成式AI可用于协助自定义对象的数据变更/同时可总结批量变更的内容 MDG 基于SAP S/4HANA 2023 FPS03的创新 由于从S…...

软考中级-数据库-3.2 数据结构-数组和矩阵
数组 一维数组是长度固定的线性表,数组中的每个数据元素类型相同。n维数组是定长线性表在维数上的扩张,即线性表中的元素又是一个线性表。 例如一维数组a[5][a1,a2,a3,a4,a5] 二维数组a[2][3]是一个2行2列的数组 第一行[a11,a12,a13] 第二行[a21,a22,a23…...

有符号数和无符号数的加减运算
一、无符号数的加减运算 加法 规则:直接按二进制逐位相加,若最高位产生进位(即结果超出(2^n)范围),则结果对(2^n)取模((n)为位数)。示例(8位无符号数): (200 …...
动态链接器(十):重定位
ELF文件中有许多种类型的重定位条目,这些重定位条目指导动态链接器在加载或运行时解析符号地址,确保程序能够正确地引用动态库中的函数和变量。 本文主要介绍那些与动态链接有关的重定位条目(主要介绍Rela相关的,Rel相关的不作介…...

EGO-Planner的无人机视觉选择(yolov5和yolov8)
EGO-Planner的无人机视觉选择(yolov5和yolov8) 效果 yolov5检测效果 yolov8检测效果 一、YOLOv8 vs YOLOv5:关键差异解析 1. 训练效率:为何YOLOv8更快? 架构轻量化 YOLOv8采用C2f模块(Cross Stage Partia…...
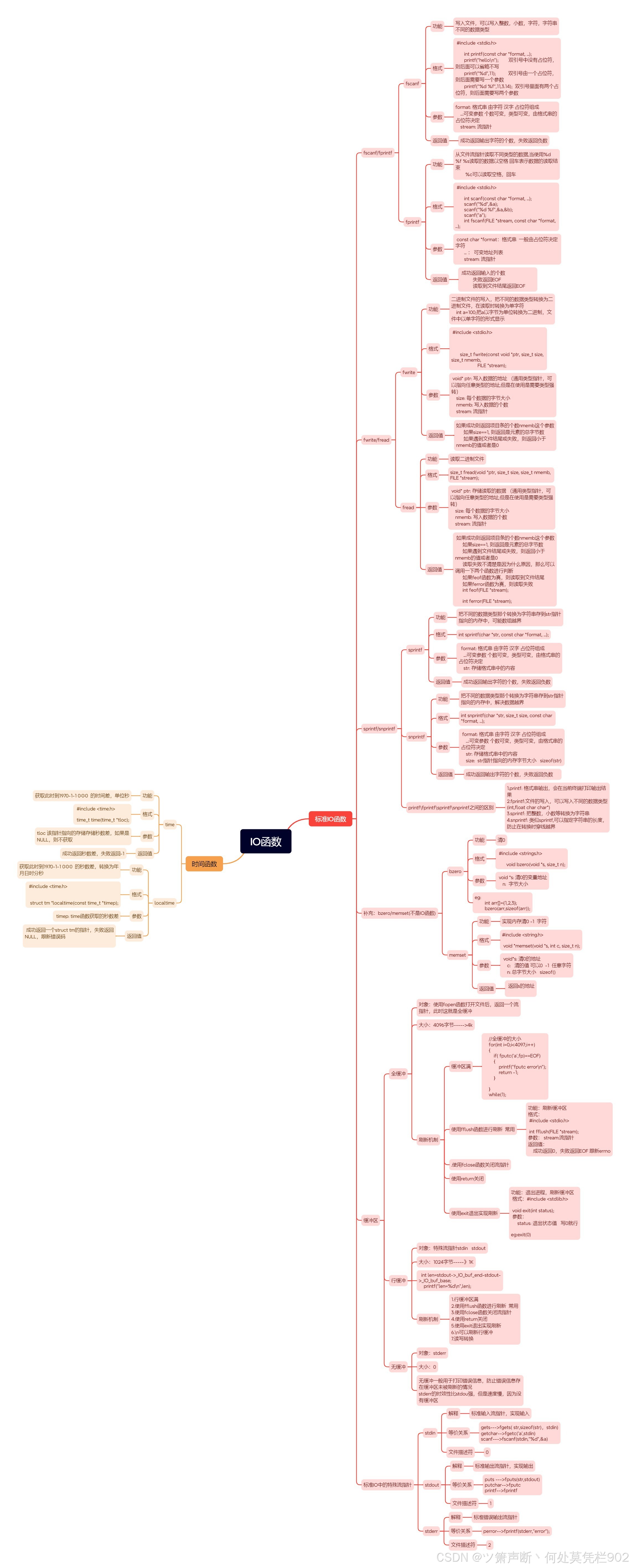
IO标准函数和时间函数
1、将当前的时间写入到time. txt的文件中,如果ctrlc退出之后,在再次执行支持断点续写 1.2022-04-26 19:10:20 2.2022-04-26 19:10:21 3.2022-04-26 19:10:22 //按下ctrlc停止,再次执行程序 4.2022-04-26 20:00:00 5.2022-04-26 20:00:0…...

为AI聊天工具添加一个知识系统 之133 详细设计之74通用编程语言 之4 架构及其核心
本篇继续讨论 通用编程语言。 说明:本阶段的所有讨论都是围绕这一主题展开的,但前面的讨论分成了三个大部分(后面列出了这一段的讨论题目的归属关系)-区别distinguish(各别): 文化和习俗。知识…...

【零基础到精通Java合集】第二十三集:G1收集器深度解析
课程标题:G1收集器深度解析——面向大内存与低延迟的现代垃圾回收器(15分钟) 目标:掌握G1核心设计思想、运行机制与调优策略,理解其如何平衡吞吐量与低延迟 0-1分钟:课程引入与G1设计目标 以“城市交通智能调度”类比G1核心思想:将堆内存划分为多个区域(Region),动…...
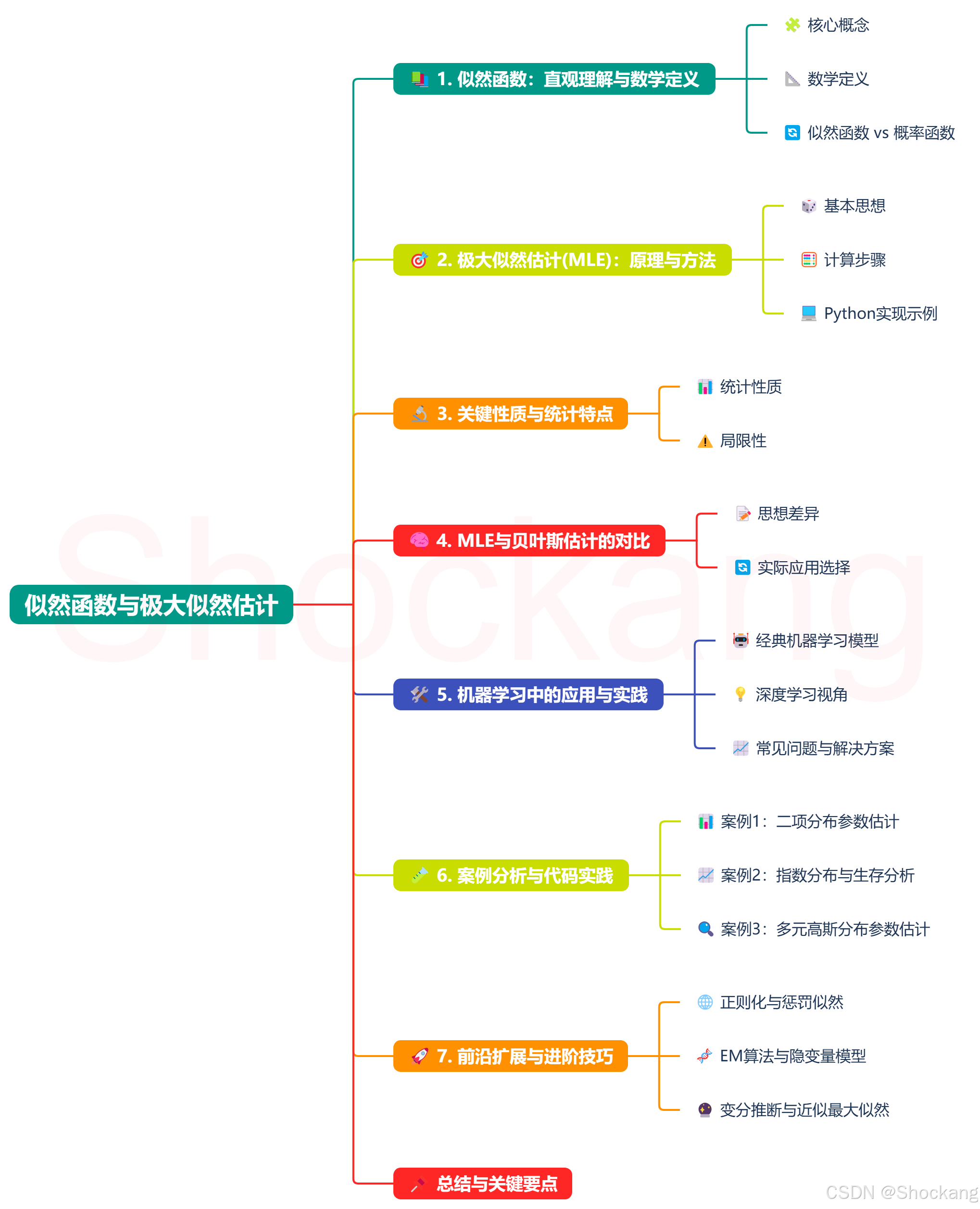
似然函数与极大似然估计
前言 本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见《机器学习数学通关指南》 正文 📚 1. 似然函数&a…...
详解)
QSFP(Quad Small Form-factor Pluggable)详解
1. QSFP的定义 QSFP(Quad Small Form-factor Pluggable)是一种四通道热插拔光模块/电模块,专为高速网络传输设计。其名称中的“Quad”表示模块集成4个独立通道,每个通道支持1Gbps至10Gbps速率(总带宽可达40Gbps&#…...

WDM_OTN_基础知识_波分系统基本构成-无源器件
在波分系统中通常将发光,对光进行放大以及产生光电转换的器件称之为有源器件,例如光放,激光器,与此相反,将那些不发光,不对光进行放大,也不产生光电转换的器件称之为无源器件,波分系统中的无源器…...

【音视频】ffmpeg音视频处理基本流程
一、ffmpeg音视频处理基本流程 首先先看两条命令 ffmpeg -i 1.mp4 -acodec copy -vcodec libx264 -s 1280x720 2.flv ffmpeg -i 1.mp4 -acodec copy -vcodec libx265 -s 1280x720 3.mkv-i :表示输入源,这里是1.mp4,是当前路径下的视频文件-acodec copy…...

【网络编程】之TCP实现客户端远程控制服务器端及断线重连
【网络编程】之TCP实现客户端远程控制服务器端及断线重连 TCP网络通信实现客户端简单远程控制主机基本功能演示通信过程代码实现服务器模块执行命令模块popen系列函数 客户端模块服务器主程序 windows作为客户端与服务器通信#pragma comment介绍 客户端使用状态机断线重连代码实…...

云原生容器编排:构建智能弹性应用的自动化引擎
引言:重构应用部署范式 Google Borg系统管理着超2500万容器实例,每日处理200亿个任务。阿里巴巴双十一使用Kubernetes实现300万Pod秒级弹性,资源利用率达65%。CNCF 2023报告显示全球Kubernetes生产采用率突破92%,CRI-O容器启动速…...

这个AI助手不让你教它,它自己来了解你
这个AI助手不让你教它,它自己来了解你OpenHuman:9700 Star,GitHub霸榜的秘密最近GitHub Trending上冒出来一个项目,连续霸榜多天,Star数蹭蹭往上涨。我点进去看了一眼,思路跟之前那些Agent工具完全不一样。…...

避坑指南:在VisDrone上训练YOLOv7时,我遇到的过拟合与数据增强那些坑
VisDroneYOLOv7实战避坑手册:从数据增强到过拟合的深度调优 第一次在VisDrone数据集上跑YOLOv7时,我盯着验证集mAP0.5从0.4缓慢爬到0.5就停滞不前,而训练集指标却一路飙升到0.9——典型的过拟合现象。更讽刺的是,当我尝试将图片切…...

如何彻底解决Cursor AI试用限制:开源技术方案深度解析
如何彻底解决Cursor AI试用限制:开源技术方案深度解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tri…...

独立开发者如何借助Taotoken管理多个AI侧项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken管理多个AI侧项目 作为一名独立开发者,同时维护多个使用大模型的小型项目是常态。你可能有…...

Taotoken在应对大模型API服务波动时的路由与容灾机制体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken在应对大模型API服务波动时的路由与容灾机制体验 1. 背景与观测场景 在开发实践中,我们时常会遇到依赖的某个…...

代码随想录算法训练营第六十天|Bellman_ford 队列优化算法、Bellman_ford之判断负权回路、bellman_ford之单源有限最短路
参考文章均来自代码随想录 Bellman_ford 队列优化算法 参考文章链接 对第 59天中的题目进行优化 详细见参考文章推理步骤 还是用邻接表 #include <iostream> #include <vector> #include <queue> #include <list> #include <climits> using …...

RISC-V开放架构如何重塑垂直半导体商业模式
1. 从边缘到中心:RISC-V的崛起与半导体模式的裂变最近和几位在芯片设计公司工作的老朋友聊天,话题总绕不开RISC-V。十年前,当我们还在讨论ARM和x86谁主沉浮时,RISC-V还只是学术界论文里的一个概念。如今,它已经成了行业…...

给企业主机穿上安全防护“黄金甲”,打造金城汤池
主机安全主要的风险来源——漏洞众所周知,软件是构成数字世界的基础,但是软件都是人为编写的,与一切皆可编程相对应的是,一切软件都存在漏洞。平均每千行代码就有4-6个安全缺陷,漏洞是网络安全的命门。但是,…...
初始化二维数组,这3个细节新手必看)
别再踩坑了!用Java Arrays.fill()初始化二维数组,这3个细节新手必看
Java二维数组初始化陷阱:为什么Arrays.fill()会让你掉坑里? 刚接触Java二维数组时,很多人会想当然地认为Arrays.fill()是个万能初始化工具,直到某天在算法题中遇到一个诡异的Bug——明明只修改了矩阵的某一行,所有行却…...

Faster-Whisper + WebSocket实战:给你的Unity游戏或应用加上实时语音交互
Faster-Whisper WebSocket全链路实战:构建Unity实时语音交互系统 在游戏和交互式应用开发中,语音交互正成为提升用户体验的关键功能。想象一下玩家通过语音指令控制角色、VR环境中自然对话交互,或是教育软件中实时语音反馈的场景——这些都需…...