PyTorch 中结合迁移学习和强化学习的完整实现方案
结合迁移学习(Transfer Learning)和强化学习(Reinforcement Learning, RL)是解决复杂任务的有效方法。迁移学习可以利用预训练模型的知识加速训练,而强化学习则通过与环境的交互优化策略。以下是如何在 PyTorch 中结合迁移学习和强化学习的完整实现方案。
1. 场景描述
假设我们有一个任务:训练一个机器人手臂抓取物体。我们可以利用迁移学习从一个预训练的视觉模型(如 ResNet)中提取特征,然后结合强化学习(如 DQN)来优化抓取策略。
2. 实现步骤
步骤 1:加载预训练模型(迁移学习)
- 使用 PyTorch 提供的预训练模型(如 ResNet)作为特征提取器。
- 冻结预训练模型的参数,只训练后续的强化学习部分。
import torch
import torchvision.models as models
import torch.nn as nn# 加载预训练的 ResNet 模型
pretrained_model = models.resnet18(pretrained=True)# 冻结预训练模型的参数
for param in pretrained_model.parameters():param.requires_grad = False# 替换最后的全连接层以适应任务
pretrained_model.fc = nn.Identity() # 移除最后的分类层
步骤 2:定义强化学习模型
- 使用深度 Q 网络(DQN)作为强化学习算法。
- 将预训练模型的输出作为状态输入到 DQN 中。
class DQN(nn.Module):def __init__(self, input_dim, output_dim):super(DQN, self).__init__()self.fc1 = nn.Linear(input_dim, 128)self.fc2 = nn.Linear(128, 64)self.fc3 = nn.Linear(64, output_dim)def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))return self.fc3(x)
步骤 3:结合迁移学习和强化学习
- 将预训练模型的输出作为 DQN 的输入。
- 定义完整的训练流程。
import numpy as np
from collections import deque
import random# 定义超参数
state_dim = 512 # ResNet 输出的特征维度
action_dim = 4 # 动作空间大小(如上下左右)
gamma = 0.99 # 折扣因子
epsilon = 1.0 # 探索率
epsilon_min = 0.01
epsilon_decay = 0.995
batch_size = 64
memory = deque(maxlen=10000)# 初始化模型
dqn = DQN(state_dim, action_dim)
optimizer = torch.optim.Adam(dqn.parameters(), lr=0.001)
criterion = nn.MSELoss()# 定义训练函数
def train_dqn():if len(memory) < batch_size:return# 从记忆池中采样batch = random.sample(memory, batch_size)states, actions, rewards, next_states, dones = zip(*batch)states = torch.tensor(np.array(states), dtype=torch.float32)actions = torch.tensor(np.array(actions), dtype=torch.long)rewards = torch.tensor(np.array(rewards), dtype=torch.float32)next_states = torch.tensor(np.array(next_states), dtype=torch.float32)dones = torch.tensor(np.array(dones), dtype=torch.float32)# 计算当前 Q 值current_q = dqn(states).gather(1, actions.unsqueeze(1))# 计算目标 Q 值next_q = dqn(next_states).max(1)[0].detach()target_q = rewards + (1 - dones) * gamma * next_q# 计算损失并更新模型loss = criterion(current_q.squeeze(), target_q)optimizer.zero_grad()loss.backward()optimizer.step()# 更新探索率global epsilonepsilon = max(epsilon_min, epsilon * epsilon_decay)
步骤 4:与环境交互
- 使用预训练模型提取状态特征。
- 根据 DQN 的策略选择动作,并与环境交互。
def choose_action(state):if np.random.rand() < epsilon:return random.randrange(action_dim)state = torch.tensor(state, dtype=torch.float32).unsqueeze(0)q_values = dqn(state)return torch.argmax(q_values).item()def preprocess_state(image):# 使用预训练模型提取特征with torch.no_grad():state = pretrained_model(image)return state.numpy()# 模拟与环境交互
for episode in range(1000):state = env.reset()state = preprocess_state(state)total_reward = 0while True:action = choose_action(state)next_state, reward, done, _ = env.step(action)next_state = preprocess_state(next_state)# 存储经验memory.append((state, action, reward, next_state, done))total_reward += rewardstate = next_state# 训练 DQNtrain_dqn()if done:print(f"Episode: {episode}, Total Reward: {total_reward}")break
3. 优化与扩展
- 改进 DQN:使用 Double DQN、Dueling DQN 或 Prioritized Experience Replay 提高性能。
- 多任务学习:结合多个预训练模型,适应更复杂的任务。
- 分布式训练:使用 Ray 或 Horovod 加速训练过程。
- 可视化:使用 TensorBoard 监控训练过程。
4. 总结
通过结合迁移学习和强化学习,可以利用预训练模型的知识加速训练,并通过与环境的交互优化策略。在 PyTorch 中,可以通过加载预训练模型、定义 DQN 模型、与环境交互以及训练模型来实现这一目标。这种方法适用于机器人控制、游戏 AI 等复杂任务。
相关文章:

PyTorch 中结合迁移学习和强化学习的完整实现方案
结合迁移学习(Transfer Learning)和强化学习(Reinforcement Learning, RL)是解决复杂任务的有效方法。迁移学习可以利用预训练模型的知识加速训练,而强化学习则通过与环境的交互优化策略。以下是如何在 PyTorch 中结合…...

大语言模型学习--本地部署DeepSeek
本地部署一个DeepSeek大语言模型 研究学习一下。 本地快速部署大模型的一个工具 先根据操作系统版本下载Ollama客户端 1.Ollama安装 ollama是一个开源的大型语言模型(LLM)本地化部署与管理工具,旨在简化在本地计算机上运行和管理大语言模型…...

Linux:vim快捷键
Linux打开vim默认第一个模式是:命令模式! 命令模式快捷键操作: gg:光标快速定位到最开始 shift g G:光标快速定位到最结尾 n shift g n G:光标快速定位到第n行 shift 6 ^:当前行开始 …...

Unity 对象池技术
介绍 是什么? 在开始时初始化若干对象,将它们存到对象池中。需要使用的时候从对象池中取出,使用完后重新放回对象池中。 优点 可以避免频繁创建和销毁对象带来性能消耗。 适用场景 如果需要对某种对象进行频繁创建和销毁时,例…...

算法1-4 凌乱的yyy / 线段覆盖
题目描述 现在各大 oj 上有 n 个比赛,每个比赛的开始、结束的时间点是知道的。 yyy 认为,参加越多的比赛,noip 就能考的越好(假的)。 所以,他想知道他最多能参加几个比赛。 由于 yyy 是蒟蒻,…...
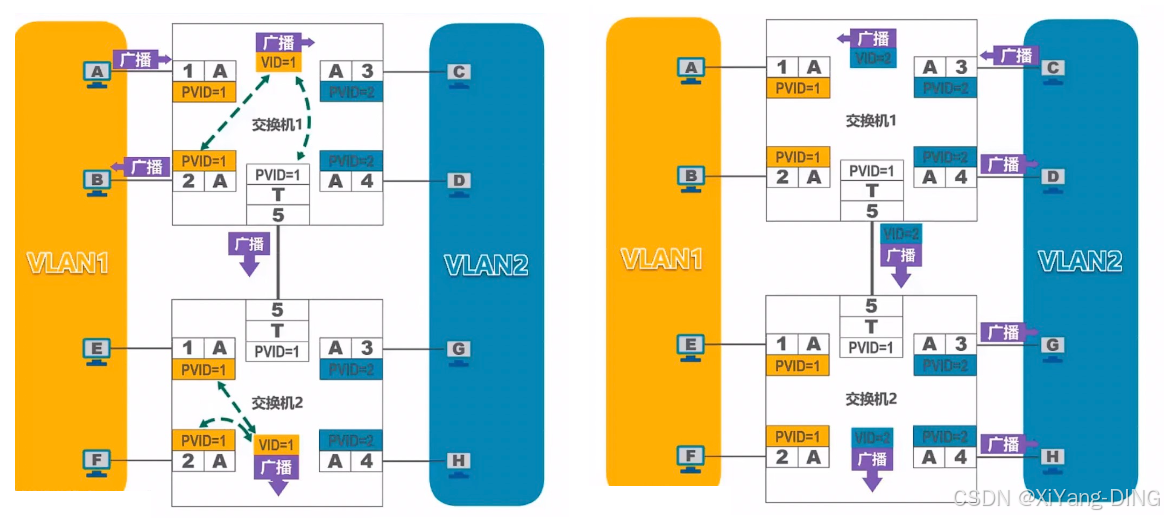
【计网】数据链路层
数据链路层 3.1 数据链路层概述3.2 封装成帧3.3 差错检测3.4 可靠传输3.4.1 可靠传输的概念3.4.2 可靠传输的实现机制 - 停止等待协议3.4.3 可靠传输的实现机制 -回退N帧协议3.4.4 可靠传输的实现机制 -选择重传协议 3.5 点对点协议3.5.1 帧格式3.5.2 透明传输 3.6 媒体接入控制…...

javaweb自用笔记:Vue
Vue 什么是vue vue案例 1、引入vue.js文件 2、定义vue对象 3、定义vue接管的区域el 4、定义数据模型data 5、定义视图div 6、通过标签v-model来绑定数据模型 7、{{message}}直接将数据模型message展示出来 8、由于vue的双向数据绑定,当视图层标签input里的…...

CSS Overflow 属性详解
CSS Overflow 属性详解 在网页设计和开发中,CSS Overflow 属性是一个非常重要的特性,它决定了当内容超出其容器大小时应该如何处理。本文将详细介绍 CSS Overflow 属性的相关知识,包括其语法、作用、常用属性值以及一些实际应用场景。 1. CSS Overflow 属性概述 CSS Over…...

沃丰科技结合DeepSeek大模型技术落地与应用前后效果对比
技术突破:DeepSeek算法创新,显著降低了显存占用和推理成本。仅需少量标注数据即可提升推理能力。这种突破减少了对海量数据的依赖,削弱了数据垄断企业的优势! 商业模式颠覆:DeepSeek选择完全开源模式,迫使…...

突破光学成像局限:全视野光学血管造影技术新进展
全视野光学血管造影(FFOA)作为一种实时、无创的成像技术,能够提取生物血液微循环信息,为深入探究生物组织的功能和病理变化提供关键数据。然而,传统FFOA成像方法受到光学镜头景深(DOF)的限制&am…...

2.反向传播机制简述——大模型开发深度学习理论基础
在深度学习开发中,反向传播机制是训练神经网络不可或缺的一部分。它让模型能够通过不断调整权重,从而将预测误差最小化。本文将从实际开发角度出发,简要介绍反向传播机制的核心概念、基本流程、在现代网络中的扩展,以及如何利用自…...

机器学习校招面经二
快手 机器学习算法 一、AUC(Area Under the ROC Curve)怎么计算?AUC接近1可能的原因是什么? 见【搜广推校招面经四】 AUC 是评估分类模型性能的重要指标,用于衡量模型在不同阈值下区分正负样本的能力。它是 ROC 曲线…...

Spring Boot如何利用Twilio Verify 发送验证码短信?
Twilio提供了一个名为 Twilio Verify 的服务,专门用于处理验证码的发送和验证。这是一个更为简化和安全的解决方案,适合需要用户身份验证的应用。 使用Twilio Verify服务的步骤 以下是如何在Spring Boot中集成Twilio Verify服务的步骤: 1.…...

毕业项目推荐:基于yolov8/yolo11的苹果叶片病害检测识别系统(python+卷积神经网络)
文章目录 概要一、整体资源介绍技术要点功能展示:功能1 支持单张图片识别功能2 支持遍历文件夹识别功能3 支持识别视频文件功能4 支持摄像头识别功能5 支持结果文件导出(xls格式)功能6 支持切换检测到的目标查看 二、数据集三、算法介绍1. YO…...

Linux的用户与权限--第二天
认知root用户(超级管理员) root用户用于最大的系统操作权限 普通用户的权限,一般在HOME目录内部不受限制 su与exit命令 su命令: su [-] 用户名 -符号是可选的,表示切换用户后加载环境变量 参数为用户名,…...

【Flink银行反欺诈系统设计方案】1.短时间内多次大额交易场景的flink与cep的实现
【flink应用系列】1.Flink银行反欺诈系统设计方案 1. 经典案例:短时间内多次大额交易1.1 场景描述1.2 风险判定逻辑 2. 使用Flink实现2.1 实现思路2.2 代码实现2.3 使用Flink流处理 3. 使用Flink CEP实现3.1 实现思路3.2 代码实现 4. 总结 1. 经典案例:短…...

HashMap的table数组何时初始化?默认容量和扩容阈值是多少?
HashMap 的 table 数组何时初始化? 答案: table 数组在第一次调用 put() 方法时初始化。 为什么? HashMap 为了节省内存,采用了“懒加载”机制。即使用 new HashMap() 创建对象时,只是计算了参数(如容量、…...

基于CURL命令封装的JAVA通用HTTP工具
文章目录 一、简要概述二、封装过程1. 引入依赖2. 定义脚本执行类 三、单元测试四、其他资源 一、简要概述 在Linux中curl是一个利用URL规则在命令行下工作的文件传输工具,可以说是一款很强大的http命令行工具。它支持文件的上传和下载,是综合传输工具&…...

docker学习笔记(1)从安装docker到使用Portainer部署容器
docker学习笔记第一课 先交代背景 docker宿主机系统:阿里云ubuntu22.04 开发机系统:win11 docker镜像仓库:阿里云,此阿里云与宿主机系统没有关系,是阿里云提供的一个免费的docker仓库 代码托管平台:github&…...

数据集/API 笔记:新加坡PSI(空气污染指数)API
data.gov.sg 数据范围:2016年2月 - 2025年3月 1 获取API方式 curl --request GET \--url https://api-open.data.gov.sg/v2/real-time/api/psi 2 返回数据 API 的数据结构可以分为 3 大部分: 区域元数据(regionMetadata) →…...

5分钟掌握碧蓝航线自动化脚本:解放双手的智能游戏助手终极指南
5分钟掌握碧蓝航线自动化脚本:解放双手的智能游戏助手终极指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你…...

实测测评|零注册AI PDF翻译工具:保留排版\+OCR无损翻译,替代DeepL/谷歌翻译
在日常开发、学术科研、外文文献研读场景中,PDF翻译一直是高频刚需痛点。市面上主流的翻译工具普遍存在排版错乱、OCR收费、文件大小受限、强制登录注册等问题,尤其是学术论文、带表格/公式的技术手册、扫描版外文资料,翻译后的可用性极差。 …...

CircuitMind框架:突破LLM在数字电路设计中的布尔优化障碍
1. 项目概述:CircuitMind框架的创新价值在数字电路设计领域,布尔优化一直是硬件工程师面临的核心挑战。传统设计流程中,工程师需要手动应用卡诺图、奎因-麦克拉斯基算法等技巧来优化门级网表,这一过程既耗时又高度依赖专家经验。近…...
)
STM32F030 HAL库驱动W25Q16实战:从数据手册到SPI读写代码(附避坑指南)
STM32F030 HAL库驱动W25Q16实战:从数据手册到SPI读写代码(附避坑指南) 1. 理解W25Q16存储芯片的核心特性 W25Q16作为一款16Mbit容量的SPI Flash存储器,在嵌入式系统中扮演着重要角色。这款芯片采用标准的SPI接口,支持单…...

STM32 SPI驱动W25Q128 Flash避坑指南:CubeMX配置与轮询读写实战
STM32 SPI驱动W25Q128 Flash避坑指南:CubeMX配置与轮询读写实战 嵌入式开发中,SPI接口的Flash存储器因其高速、稳定和易用性而广受欢迎。W25Q128作为一款128Mbit容量的SPI Flash芯片,在数据存储、固件升级等场景中扮演着重要角色。然而&#…...

训练和微调
训练和微调微调本质上就是在调整(更新)模型的参数。当我们说“调整参数”时,指的是调整神经网络内部数以亿计的权重(Weights)和偏置(Biases)。全量微调(Full Fine-Tuning)…...
)
软件工程师视角下的MV与TVA(11)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

推荐五家SF6在线监测报警系统
在有六氟化硫气体存在的场所,如小区配电室、变电站、电厂等,SF6在线监测报警系统起着至关重要的作用。它能实时监测现场气体浓度,在浓度超标时第一时间发出报警信号,及时消除隐患。今天就为大家推荐五家SF6在线监测报警系统品牌&a…...

出口欧美设备机箱:必须符合HASCO模架与DME顶针标准
在出口欧美市场的设备机箱领域,符合HASCO模架与DME顶针标准是至关重要的。这不仅关乎产品的质量和性能,还影响着企业在国际市场的竞争力。本文将深入探讨这一标准的重要性,并结合深圳市机汇五金制品有限公司(以下简称“机汇五金”…...

压接 vs 焊接:高速连接器组装工艺的选型指南与实战对比
摘要/前言在通信设备、工业控制及数据中心硬件设计中,连接器的组装工艺选择直接影响产品的可靠性、可维护性与生产良率。压接(Press-Fit)与焊接(Soldering)是当前通孔连接器最主要的两种电气互连方式。压接依靠过盈配合…...