Linux - 进程通信
一、管道
管道是一种进程间通信(IPC)机制,用于在进程之间传递数据。它的本质是操作系统内核维护的一个内存缓冲区,配合文件描述符进行数据的读写。尽管管道的核心是内存缓冲区,但操作系统通过对管道的实现,让它看起来像文件一样可以用文件操作接口(如 read 和 write)来操作。因此,管道是一种特殊的文件,但并不用于数据的持久化存储。
1) 命名管道匿名管道
-
匿名管道:只能在具有亲缘关系的进程(如父进程和子进程)之间使用的通信机制。
-
用于单个父进程及其子进程之间的通信。
-
数据流仅在相关进程间传递,不会涉及文件系统。
-
pipe: 创建匿名管道int pipe(int pipefd[2])int pipefd[2]; pipe(pipefd);pipefd:一个包含两个文件描述符的数组,pipefd[0](读端),pipefd[1](写端)。- 返回值:
0表示成功,-1表示出错并设置errno。
-
-
命名管道:一种持久化的管道,它通过文件系统提供了一种通信接口,支持无亲缘关系的进程间通信。
-
mkfifo:系统调用用于创建命名管道文件。Bash:mkfifo [filename]mkfifo mypipe // 创建名为mypipe的命名管道CPP:int mkfifo(const char *pathname, mode_t mode)mkfifo("mypipe", 0644); // 创建名为mypipe的管道pathname:要创建的命名管道的路径名。mode:指定创建的命名管道的权限(与文件权限相同,例如0644表示所有者读写,组和其他用户只读)。- 返回值:
0表示成功,-1表示出错并设置errno
-
unlink:系统调用用于删除文件或目录的链接。Bash:unlink [filename]unlink myfifo // 删除名为mypipe的管道CPP:int unlink(const char* pathname)unlink("mypipe"); // 删除名为mypipe的管道-
pathname:要删除的文件或命名管道路径名。 -
返回值:
0表示成功,-1表示出错并设置errno
-
-
2) 管道的特点
-
顺序读写
- 管道数据是以字节流的形式从写端流入,从读端流出。
- 只能按顺序读写,不支持随机访问。
- 管道没有文件指针的概念,也不支持
seek操作。
-
一次性传递
- 数据通过管道从一个进程传递到另一个进程,读完即消失,无法重复读取。
- 这意味着管道是临时的,不具备存储能力。
-
半双工通信
- 管道默认是半双工的,数据只能在一个方向上传递(从写端到读端)。
- 如果需要双向通信,可以创建两个管道,分别用于发送和接收。
-
基于文件描述符
- 管道的读端和写端分别对应两个文件描述符,这两个文件描述符在相关的进程之间共享。
- 管道的创建会返回一个文件描述符数组。
- 进程退出管道也会自然而然释放。
-
容量有限
-
管道的内存缓冲区大小是有限的(通常由操作系统设置,默认 4KB 或 64KB)。
-
如果写端写入的数据超过缓冲区容量,写操作会阻塞,直到读端读取部分数据为止。
-
当读取管道时,如果管道缓冲区中没有数据,读取的进程会阻塞,直到有数据写入为止。
-
-
面向字节流
- 数据在写入管道时,会以字节为单位依次写入缓冲区,读端以相同的顺序读取。
- 发送的数据没有明确的边界标记,读写操作只知道字节数量,而不是具体的内容分隔。
- 管道不关心数据的具体格式(如文本、二进制、结构化数据等),只负责传输字节。
- 如果需要有特定的格式或分隔符,程序需要自行定义和解析。
- 面向字节流意味着管道只能按照写入数据的顺序读取,不能像文件一样支持随机访问(比如指定偏移量读取)。
父子进程之间协同工作时,会通过同步和互斥机制来协调资源访问,从而确保管道文件的数据传输安全可靠。
PIPE_BUF:是一个与管道相关的重要常量,定义了管道的写入操作可以原子性完成的最大数据量。
- 如果写入的字节数 ≤
PIPE_BUF,系统保证整个写入操作不会被其他进程的写入操作打断。- 如果写入的字节数 >
PIPE_BUF,系统可能会分成多个写操作,此时其他进程的写入可能会插入其中。管道的4种情况:
- 读写端正常,管道如果为空,读端就要阻塞。
- 读写端正常,管道如果已满,写端就要阻塞。
- 读端正常,写端关闭,读端就会读到0,表明读到结尾,不会被阻塞。
- 写端关闭,读端正常,操作系统会通过信号
13-SIGPIPE杀掉正在写入的进程。
3) 匿名管道与命名管道的比较
| 特性 | 匿名管道 | 命名管道 |
|---|---|---|
| 创建方式 | 使用 pipe() 创建 | 使用 mkfifo() 或 mknod() 创建 |
| 通信范围 | 仅限具有亲缘关系的进程 | 支持无亲缘关系的进程通信 |
| 存在时间 | 进程退出后自动销毁 | 文件存在于文件系统中,需手动删除 |
| 访问方式 | 基于文件描述符 | 通过文件路径访问 |
| 容量限制 | 操作系统设置的缓冲区大小(如 4KB/64KB) | 操作系统设置的缓冲区大小 |
| 双向通信 | 需要创建两个匿名管道 | 需要创建两个命名管道 |
C 风格的可变参数函数使用头文件
<cstdarg>中提供的宏,主要有以下几个步骤:
- 使用
...标记函数支持可变参数。- 使用
va_list类型声明参数列表。- 使用
va_start初始化参数列表。- 使用
va_arg依次读取参数。- 使用
va_end清理参数列表。#include <iostream> #include <cstdarg> // 包含可变参数相关的宏using namespace std;// 求多个数的和 int sum(int count, ...) {va_list args; // 声明参数列表va_start(args, count); // 初始化参数列表,count 是最后一个固定参数int total = 0;for (int i = 0; i < count; ++i) {total += va_arg(args, int); // 获取下一个参数}va_end(args); // 清理参数列表return total; }int main() {cout << sum(3, 1, 2, 3) << endl; // 输出 6cout << sum(5, 1, 2, 3, 4, 5) << endl; // 输出 15return 0; }
二、共享内存
System V 共享内存是一种进程间通信(IPC)机制,它允许多个进程共享一块内存区域。通过这种机制,进程可以高效地交换数据,因为它避免了进程间的复制开销。
1) 共享内存系统调用
-
ftok():用于生成 唯一标识符 的函数,通常在 IPC(进程间通信,如共享内存、信号量、消息队列)中使用。key_t ftok(const char *pathname, int proj_id)key_t key = ftok(".", 65);pathname:一个现有文件的路径名,必须是文件系统中实际存在的文件,通常会选择如/tmp或程序目录下的文件。proj_id:用户自定义的值,用于确保生成的标识符在相同路径下依然唯一。- 返回值:返回一个
key_t类型的唯一标识符(通常为整数类型),失败返回-1,并设置errno。
-
shmget(): 创建共享内存段(share memory get)int shmget(key_t key, size_t size, int shmflg)// 创建一个共享内存段,大小为 1024 字节,权限为 0664 int shmid = shmget(key, 1024, IPC_CREAT | 0666);-
key:获取共享内存的时的唯一标识,创建时key就必须存在了。 -
size:共享内存段的大小。 -
shmflg:权限标志,类似文件权限。IPC_CREAT:如果指定的key不存在,创建一个新的 IPC 对象(共享内存段、消息队列或信号量),如果已存在,则会返回已有共享内段的标识符。IPC_EXCL:不单独使用,配合IPC_CREAT使用,即IPC_CREAT | IPC_EXCL,确保申请的共享内存是新的。如果指定的key对应的共享内存段已存在,返回错误,并设置errno为EEXIST。- 权限设置:
0666、0664。
-
返回值:共享内存段的唯一标识符(
shmid),失败返回 -1。
-
为什么不由操作系统统一生成key?
-
如果操作系统随机生成
key,多个进程就需要额外的机制来共享这个key,导致复杂性增加。 -
程序重启时,如何保证仍能访问之前创建的 IPC 资源?而
ftok的机制可以确保基于相同路径和proj_id得到相同的key。 -
系统生成的
key可能会因时间或使用条件导致冲突,而ftok的方案让开发者可以根据路径和proj_id手动控制唯一性。
-
-
key与shmid的关系-
两个程序想要获得一个共享内存段,我不需要去知道这个共享数据段的
shmid是多少,我们两个约定好文件名,和指定的proj_id,用ftok生成对应对的唯一标识符,然后交给操作系统,操作系统统一维护共享内存段,返回给我他维护下的shmid,后续我用这个shmid操作就好。 -
key在操作系统内标定唯一性。 -
shmid在进程内,表示资源的唯一性。 -
只需要记住:
key是给程序员用的,shmid是给系统用的!
-
-
-
shmat():将共享内存挂载到进程地址空间(shared memory attach)void* shmat(int shmid, const void* shmaddr, int shmflg)// 将共享内存段附加到地址空间 char* str = (char*) shmat(shmid, NULL, 0);-
shmid:shmget()返回的共享内存段标识符。 -
shmaddr: 指定共享内存的附加地址,一般传NULL。 -
shmflg: 附加标志,通常为 0。 -
返回值:挂接到的进程空间地址。
-
-
shmdt():将共享内存段与当前进程脱离(shared memory detach)int shmdt(const void* shmaddr)// 分离共享内存段 shmdt(str);-
shmaddr:shmat()返回的共享内存地址。 -
返回值:成功返回 0,失败返回 -1。
-
-
shmctl():控制共享内存(shared memory control)int shmctl(int shmid, int cmd, struct shmid_ds* buf)// 删除共享内存段 shmctl(shmid, IPC_RMID, NULL);-
shmid:shmget()返回的共享内存段标识符。 -
cmd: 命令,如IPC_RMID用于删除共享内存段。IPC_RMID:删除共享内存段。IPC_STAT:把shmid_ds结构中的数据设置为共享内存当前的关联值。IPC_SET:在进程有足够权限的前提下,把共享内存的当前关联值设置为shmid_ds数据结构种给出的值。
-
buf: 结构体指针,用于传递控制信息,删除时可为NULL。 -
返回值:
-
创建和写入共享内存:
#include <sys/ipc.h> #include <sys/shm.h> #include <stdio.h> #include <string.h>int main() {key_t key = ftok("shmfile", 65); // 生成唯一的键值int shmid = shmget(key, 1024, 0666 | IPC_CREAT); // 创建共享内存段char* str = (char*) shmat(shmid, NULL, 0); // 将共享内存段附加到地址空间printf("Write Data: ");fgets(str, 1024, stdin); // 写入共享内存printf("Data written in memory: %s\n", str);shmdt(str); // 分离共享内存段return 0;读取共享内存:
#include <sys/ipc.h> #include <sys/shm.h> #include <stdio.h>int main() {key_t key = ftok("shmfile", 65); // 生成相同的键值int shmid = shmget(key, 1024, 0666); // 获取共享内存段char* str = (char*) shmat(shmid, NULL, 0); // 将共享内存段附加到地址空间printf("Data read from memory: %s\n", str);shmdt(str); // 分离共享内存段shmctl(shmid, IPC_RMID, NULL); // 删除共享内存段return 0; }
2) 共享内存原理
-
创建共享内存
- 调用
shmget()创建共享内存段。 - 操作系统为共享内存段分配物理内存并生成一个唯一标识符(
shmid)。 - 系统维护一个共享内存段表(通常是内核数据结构的一部分),记录共享内存的元数据,例如大小、权限和引用计数等。
-
元数据存储 内核使用结构体
shmid_ds保存共享内存段的元信息,例如:struct shmid_ds {struct ipc_perm shm_perm; // 权限信息,存储了keysize_t shm_segsz; // 内存段大小time_t shm_atime; // 上次附加时间time_t shm_dtime; // 上次分离时间time_t shm_ctime; // 创建时间pid_t shm_cpid; // 创建共享内存的进程IDpid_t shm_lpid; // 最后访问共享内存的进程IDshmatt_t shm_nattch; // 当前附加到该共享内存段的进程数(即调用 shmat() 的进程数量)... }; -
ipcs:查看创建的共享内存ipcs [options]ipcs -m-m:仅显示共享内存的状态。-q:仅显示消息队列的状态。-s:仅显示信号量的状态。
- 调用
-
内存映射
- 调用
shmat()时,操作系统将共享内存段的物理页映射到调用进程的虚拟地址空间。 - 操作系统修改页表,将进程的虚拟地址指向共享内存的物理地址。
- 返回的虚拟地址可以被进程直接访问,就像操作普通变量一样。
- 调用
-
多进程访问
- 不同进程调用
shmat()后,它们的虚拟地址空间都指向同一块物理内存。 - 通过修改物理内存,数据可被所有附加该共享内存段的进程访问。
- 不同进程调用
-
分离与清理
- 分离共享内存段
- 调用
shmdt()将共享内存从进程的虚拟地址空间解除映射。 - 物理内存仍然存在,只要引用计数大于 0。
- 调用
- 删除共享内存段
- 调用
shmctl()使用IPC_RMID命令删除共享内存段。 - 只有当所有进程都分离后,操作系统才会释放关联的物理内存。
- 调用
-
ipcrm:删除特定共享内存段ipcrm -m [shmid]
- 分离共享内存段
3) 共享内存的特点
共享内存的主要特点是高效、直接、低开销的进程间数据共享,但同时它也带来了进程间同步和安全性的问题,要求合理的同步机制来避免数据冲突和不一致。
-
高效的通信方式
- 共享内存是进程间通信中最快的一种方式,因为它不需要通过内核进行数据的复制。数据在共享内存区域中直接共享,避免了进程间复制数据的开销。
- 进程可以直接读写共享内存中的数据,而不需要进行数据的传输,减少了上下文切换的次数。
-
内存区共享
- 多个进程可以将同一块物理内存映射到各自的虚拟地址空间中。这样,它们就可以通过访问这块共享的内存区域来交换数据。
- 每个进程都有对共享内存的映射副本,它们可以像访问普通内存一样进行读写操作。
-
需要同步机制
-
虽然多个进程可以共享内存中的数据,但这也带来了一些问题,比如竞争条件(race condition)和数据不一致(即使共享内存不写入任何数据也可以读取)。
-
因此,使用共享内存时,通常需要额外的同步机制,如信号量、互斥锁或条件变量,来确保访问共享内存的进程之间的协调,避免同时修改同一数据而导致的不一致。
-
-
内存保护和访问权限
- 共享内存区的访问权限可以通过操作系统的控制机制进行管理。不同进程可以拥有不同的访问权限(如读写、只读、只写等)。
- 操作系统会保证进程在访问共享内存时不会越界访问或者破坏其他进程的数据。
-
生命周期管理
- 共享内存的生命周期通常由操作系统来管理。一旦创建共享内存段,操作系统会分配一块物理内存区域,并允许多个进程映射和使用这块内存。进程可以通过
shmdt(解除映射)操作来分离共享内存,但共享内存本身在进程终止后并不会自动销毁,通常需要通过shmctl或类似函数来删除。 - 共享内存段的生命周期由调用
shmctl的进程控制(即谁创建谁负责删除)
- 共享内存的生命周期通常由操作系统来管理。一旦创建共享内存段,操作系统会分配一块物理内存区域,并允许多个进程映射和使用这块内存。进程可以通过
三、信号量
信号量(Semaphore)是进程间通信的一种重要机制,用于解决同步和互斥问题。它广泛应用于多线程编程和多进程编程中,帮助实现对共享资源的访问控制。
1) 信号量系统调用
-
semget(): 创建和获取信号量集(semaphore get)int semget(key_t key, int nsems, int semflg)// 创建一个信号量,权限为 0666 int semid = semget(IPC_PRIVATE, 1, IPC_CREAT | 0666);-
key:获取信号量时的唯一标识,创建时key就必须存在了。 -
nsems:信号量集中的信号量个数。 -
shmflg:权限标志,类似文件权限。IPC_CREAT:如果指定的key不存在,创建一个新的 IPC 对象(共享内存段、消息队列或信号量),如果已存在,则会返回已有共享内段的标识符。IPC_EXCL:不单独使用,配合IPC_CREAT使用,即IPC_CREAT | IPC_EXCL,确保申请的共享内存是新的。如果指定的key对应的共享内存段已存在,返回错误,并设置errno为EEXIST。- 权限设置:
0666、0664。
-
返回值:共享内存段的唯一标识符(
semid),失败返回 -1。
-
-
semctl():对信号量进行控制操作,包括初始化、获取值、删除等。int semctl(int semid, int semnum, int cmd, ...)// 初始化信号量值为 1 semctl(semid, 0, SETVAL, 1);// 删除信号量 semctl(semid, 0, IPC_RMID);semid:信号量集的标识符。semnum:信号量的索引(从 0 开始)。cmd:控制命令SETVAL:设置信号量的值。cppGETVAL:获取信号量的值。IPC_RMID:删除信号量集。
- 可选参数
arg:根据cmd的不同,可以是int或union semun类型的值。 - 返回值:根据命令不同返回值不同,失败返回
-1。
-
semop():对信号量执行操作,如 P 操作(wait)或 V 操作(signal)。int semop(int semid, struct sembuf *sops, size_t nsops)struct sembuf p_op = {0, -1, 0}; // P 操作 struct sembuf v_op = {0, 1, 0}; // V 操作 // 执行 P 操作 semop(semid, &p_op, 1); // 临界区代码// 执行 V 操作 semop(semid, &v_op, 1);-
semid:信号量集的标识符。 -
sops:操作数组,类型为struct sembuf。// 结构定义 struct sembuf {unsigned short sem_num; // 信号量索引short sem_op; // 操作值 (-1: P 操作, +1: V 操作)short sem_flg; // 操作标志(如 SEM_UNDO) }; -
nsops:操作的个数。 -
返回值:成功返回
0,失败返回-1.
-
进程通信的本质:让不同进程看到同一份资源。
相关文章:

Linux - 进程通信
一、管道 管道是一种进程间通信(IPC)机制,用于在进程之间传递数据。它的本质是操作系统内核维护的一个内存缓冲区,配合文件描述符进行数据的读写。尽管管道的核心是内存缓冲区,但操作系统通过对管道的实现,…...

使用 Arduino 的 WiFi 控制机器人
使用 Arduino 的 WiFi 控制机器人 这次我们将使用 Arduino 和 Blynk 应用程序制作一个 Wi-Fi 控制的机器人。这款基于 Arduino 的机器人可以使用任何支持 Wi-Fi 的 Android 智能手机进行无线控制。 为了演示 Wi-Fi 控制机器人,我们使用了一个名为“Blynk”的 Andr…...

网络安全等级保护2.0 vs GDPR vs NIST 2.0:全方位对比解析
在网络安全日益重要的今天,各国纷纷出台相关政策法规,以加强信息安全保护。本文将对比我国网络安全等级保护2.0、欧盟的GDPR以及美国的NIST 2.0,分析它们各自的特点及差异。 网络安全等级保护2.0 网络安全等级保护2.0是我国信息安全领域的一…...

verb words
纠正correct remedy 修正modify 协商 confer 磋商/谈判 negotiate 通知notice notify *宣布announce 声明declare 宣告 declare *颁布 promulgate /introduce 协调coordinate 评估evaluate assess 撤离evacuate *规定stipulate 参与participate, 涉及refer…...

unity console日志双击响应事件扩展
1 对于项目中一些比较长的日志,比如前后端交互协议具体数据等,这些日志内容可能会比较长,在unity控制面板上查看不是十分方便,我们可以对双击事件进行扩展,将日志保存到一个文本中,然后用系统默认的文本查看…...
)
维度建模维度表技术基础解析(以电商场景为例)
维度建模维度表技术基础解析(以电商场景为例) 维度表是维度建模的核心组成部分,其设计直接影响数据仓库的查询效率、分析灵活性和业务价值。本文将从维度表的定义、结构、设计方法及典型技术要点展开,结合电商场景案例,深入解析其技术基础。 1. 维度表的定义与作用 定义…...

Leetcode 264-丑数/LCR 168/剑指 Offer 49
题目描述 我们把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。 示例: 说明: 1 是丑数。 n 不超过1690。 题解 动态规划法 根据题意,每个丑数都可以由其他较小的丑数通过乘以 2 或 3 或 5 得到…...

阿里云MaxCompute面试题汇总及参考答案
目录 简述 MaxCompute 的核心功能及适用场景,与传统数据仓库的区别 解释 MaxCompute 分层架构设计原则,与传统数仓分层有何异同 MaxCompute 的存储架构如何实现高可用与扩展性 解析伏羲(Fuxi)分布式调度系统工作原理 盘古(Pangu)分布式存储系统数据分片策略 计算与存…...

笔记:Directory.Build.targets和Directory.Build.props的区别
一、目的:分享Directory.Build.targets和Directory.Build.props的区别 Directory.Build.targets 和 Directory.Build.props 是 MSBuild 的两个功能,用于在特定目录及其子目录中的所有项目中应用共享的构建设置。它们的主要区别在于应用的时机和用途。 二…...

istio入门到精通-2
上部分讲到了hosts[*] 匹配所有的微服务,这部分细化一下 在 Istio 的 VirtualService 配置中,hosts 字段用于指定该虚拟服务适用的 目标主机或域名。如果使用具体的域名(如 example.com),则只有请求的主机 域名与 exa…...

第5章:vuex
第5章:vuex 1 求和案例 纯vue版2 vuex工作原理图3 vuex案例3.1 搭建vuex环境错误写法正确写法 3.2 求和案例vuex版细节分析源代码 4 getters配置项4.1 细节4.2 源代码 5 mapState与mapGetters5.1 总结5.2 细节分析5.3 源代码 6 mapActions与mapMutations6.1 总结6.2…...
]第5章 列表 元组 字符串)
[Python入门学习记录(小甲鱼)]第5章 列表 元组 字符串
第5章 列表 元组 字符串 5.1 列表 一个类似数组的东西 5.1.1 创建列表 一个中括号[ ] 把数据包起来就是创建了 number [1,2,3,4,5] print(type(number)) #返回 list 类型 for each in number:print(each) #输出 1 2 3 4 5#列表里不要求都是一个数据类型 mix [213,"…...

Docker 学习(四)——Dockerfile 创建镜像
Dockerfile是一个文本格式的配置文件,其内包含了一条条的指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。有了Dockerfile,当我们需要定制自己额外的需求时,只需在D…...

Java多线程与高并发专题——为什么 Map 桶中超过 8 个才转为红黑树?
引入 JDK 1.8 的 HashMap 和 ConcurrentHashMap 都有这样一个特点:最开始的 Map 是空的,因为里面没有任何元素,往里放元素时会计算 hash 值,计算之后,第 1 个 value 会首先占用一个桶(也称为槽点ÿ…...
LeetCode hot 100—二叉树的中序遍历
题目 给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。 示例 示例 1: 输入:root [1,null,2,3] 输出:[1,3,2]示例 2: 输入:root [] 输出:[]示例 3: 输入:root […...

代码随想录算法训练营第35天 | 01背包问题二维、01背包问题一维、416. 分割等和子集
一、01背包问题二维 二维数组,一维为物品,二维为背包重量 import java.util.Scanner;public class Main{public static void main(String[] args){Scanner scanner new Scanner(System.in);int n scanner.nextInt();int bag scanner.nextInt();int[…...
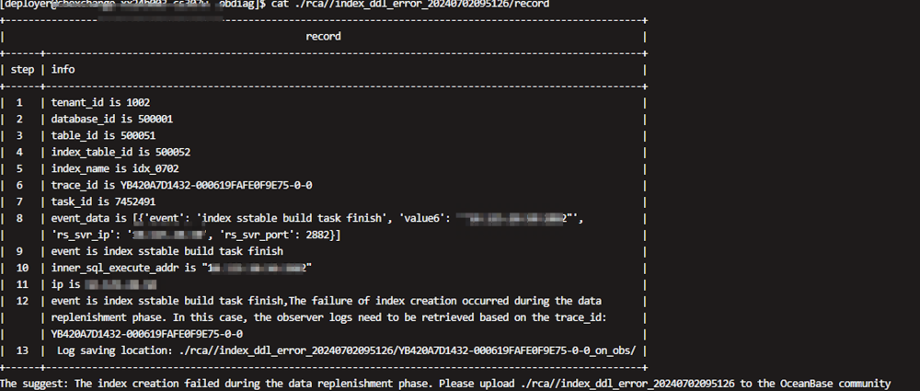
与中国联通技术共建:通过obdiag分析OceanBase DDL中的报错场景
中国联通软件研究院(简称联通软研院)在全面评估与广泛调研后,在 2021年底决定采用OceanBase 作为基础,自研分布式数据库产品CUDB(即China Unicom Database,中国联通数据库)。目前,该…...

IDEA 接入 Deepseek
在本篇文章中,我们将详细介绍如何在 JetBrains IDEA 中使用 Continue 插件接入 DeepSeek,让你的 AI 编程助手更智能,提高开发效率。 一、前置准备 在开始之前,请确保你已经具备以下条件: 安装了 JetBrains IDEA&…...

斗地主小游戏
<!DOCTYPE html> <html><head><meta charset="utf-8"><title>斗地主</title><style>.game-container {width: 1000px;height: 700px;margin: 0 auto;position: relative;background: #35654d;border-radius: 10px;padding…...

如何改变怂怂懦弱的气质(2)
你是否曾经因为害怕失败而逃避选择?是否因为不敢拒绝别人而让自己陷入困境?是否因为过于友善而被人轻视?如果你也曾为这些问题困扰,那么今天的博客就是为你准备的。我们将从行动、拒绝、自我认知、实力提升等多个角度,…...

Python网络编程利器:pincer中间件框架的设计原理与应用实践
1. 项目概述与核心价值最近在折腾一个游戏服务器的网络通信模块,偶然间在GitHub上看到了一个名为“pincer”的项目,作者是TheOneWhoAlwaysWatches。这个项目名挺有意思,直译过来是“钳子”或“夹子”,在计算机领域,尤其…...

2026年5月第3周 AI技术周报
5.11 - 5.17 | OpenAI大重组、谷歌视频模型泄露、GitHub Skills生态大爆发本周概览各位开发者好!本周(5月11日-17日)的AI圈可以用四个字形容——「卷到飞起」 OpenAI一口气宣布IPO前大规模重组,合并ChatGPT、Codex、API三大产品线…...

NotebookLM隐私策略更新暗藏玄机:2024年Q2 TOS第4.7.2条修订背后,3类原始文档正被静默提取用于模型微调?
更多请点击: https://intelliparadigm.com 第一章:NotebookLM隐私数据安全 NotebookLM 是 Google 推出的基于用户上传文档构建个性化 AI 助手的工具,其核心优势在于“本地文档理解”,但所有文档均需上传至 Google 云端处理。这意…...

MTKClient终极指南:解锁联发科芯片调试的专业解决方案
MTKClient终极指南:解锁联发科芯片调试的专业解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient作为一款专为联发科(MediaTek)芯片设计的…...

从开源物理拼图游戏学习Unity 2D物理引擎与游戏架构设计
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“openclaw-puzzle-game”。光看名字,你可能会觉得这又是一个普通的开源拼图游戏,但点进去仔细研究后,我发现它的设计思路和实现方式,对于想学习游戏开…...

多智能体系统架构设计:从核心原理到AgentOrg工程实践
1. 项目概述:从“AgentOrg”看智能体组织架构的工程实践最近在开源社区里看到一个挺有意思的项目,叫“Angelopvtac/AgentOrg”。光看这个名字,可能有点抽象,但如果你正在捣鼓大语言模型应用,尤其是想构建一个能协同工作…...

SQL学习指南——背景知识
关系型数据库中每个数据表都包含能够唯一标识某一行的信息(称为主键 primary key),以及完整描述实体所需的额外信息 一些数据表中还包含了导航到其他数据表的信息,这些列称为外键(foreign key) 术语术语定义实体数据库…...

给UE4蓝图和C++开发者的Lua/UnLua入门:什么时候该用,怎么设计架构?
UE4架构设计指南:何时引入Lua与UnLua的最佳实践 当你在UE4项目中频繁修改玩法逻辑时,是否经历过这样的困境:每次调整都需要重新编译C代码,等待时间从几分钟到几小时不等;或者蓝图节点越连越多,最终变成难以…...

影刀RPA跨境店群运营架构:多账号环境隔离与 Python 高并发调度系统实战
关于我一个曾经死磕底层算法、痴迷于压榨软硬件性能、满脑子分布式高可用架构的资深开发者,最后跑去给跨境工作室的“Boss”写店群底层自动化调度系统这件事。 很多以前在技术圈里混的同行,或者是看着我一路从 ImageTransPro 图像处理软件 1.0 重构做到…...

2026年十大最佳地区搜索排名优化工具:权威榜单赋能企业高效增长
本文全面梳理了2026年十大主流地区搜索排名优化工具的核心功能与应用价值,旨在为本地企业提供客观、实用的选型参考。通过对各工具地域关键词布局、多平台同步能力及实时数据监控等关键模块的解析,结合具体参数指标与套餐定价,系统呈现不同场…...