Java多线程与高并发专题——为什么 Map 桶中超过 8 个才转为红黑树?
引入
JDK 1.8 的 HashMap 和 ConcurrentHashMap 都有这样一个特点:最开始的 Map 是空的,因为里面没有任何元素,往里放元素时会计算 hash 值,计算之后,第 1 个 value 会首先占用一个桶(也称为槽点)位置,后续如果经过计算发现需要落到同一个桶中,那么便会使用链表的形式往后延长,俗称“拉链法”。
当链表长度大于或等于阈值(默认为 8)的时候,如果同时还满足容量大于或等于MIN_TREEIFY_CAPACITY(默认为 64)的要求,就会把链表转换为红黑树。同样,后续如果由于删除或者其他原因调整了大小,当红黑树的节点小于或等于 6 个以后,又会恢复为链表形态。
更多的时候我们会关注,为何转为红黑树以及红黑树的一些特点,可是为什么转化的这个阈值要默认设置为 8 呢?
原因梳理
要想知道为什么设置为 8,那首先我们就要知道为什么要转换,因为转换是第一步。
每次遍历一个链表,平均查找的时间复杂度是 O(n),n 是链表的长度。红黑树有和链表不一样的查找性能,由于红黑树有自平衡的特点,可以防止不平衡情况的发生,所以可以始终将查找的时间复杂度控制在 O(log(n))。最初链表还不是很长,所以可能 O(n) 和 O(log(n)) 的区别不大,但是如果链表越来越长,那么这种区别便会有所体现。所以为了提升查找性能,需要把链表转化为红黑树的形式。
那为什么不一开始就用红黑树,反而要经历一个转换的过程呢?
我们可以从HashMap源码中的备注看到解释:
Implementation notes.
This map usually acts as a binned (bucketed) hash table, but when bins get too large, they are transformed into bins of TreeNodes, each structured similarly to those in java.util.TreeMap. Most methods try to use normal bins, but relay to TreeNode methods when applicable (simply by checking instanceof a node). Bins of TreeNodes may be traversed and used like any others, but additionally support faster lookup when overpopulated. However, since the vast majority of bins in normal use are not overpopulated, checking for existence of tree bins may be delayed in the course of table methods.
Tree bins (i.e., bins whose elements are all TreeNodes) are ordered primarily by hashCode, but in the case of ties, if two elements are of the same "class C implements Comparable<C>", type then their compareTo method is used for ordering. (We conservatively check generic types via reflection to validate this -- see method comparableClassFor). The added complexity of tree bins is worthwhile in providing worst-case O(log n) operations when keys either have distinct hashes or are orderable, Thus, performance degrades gracefully under accidental or malicious usages in which hashCode() methods return values that are poorly distributed, as well as those in which many keys share a hashCode, so long as they are also Comparable. (If neither of these apply, we may waste about a factor of two in time and space compared to taking no precautions. But the only known cases stem from poor user programming practices that are already so slow that this makes little difference.)
Because TreeNodes are about twice the size of regular nodes, we use them only when bins contain enough nodes to warrant use (see TREEIFY_THRESHOLD). And when they become too small (due to removal or resizing) they are converted back to plain bins. In usages with well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution (http://en.wikipedia.org/wiki/Poisson_distribution) with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance, the expected occurrences of list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)). The first values are:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
The root of a tree bin is normally its first node. However, sometimes (currently only upon Iterator.remove), the root might be elsewhere, but can be recovered following parent links (method TreeNode.root()).
All applicable internal methods accept a hash code as an argument (as normally supplied from a public method), allowing them to call each other without recomputing user hashCodes. Most internal methods also accept a "tab" argument, that is normally the current table, but may be a new or old one when resizing or converting.
When bin lists are treeified, split, or untreeified, we keep them in the same relative access/traversal order (i.e., field Node.next) to better preserve locality, and to slightly simplify handling of splits and traversals that invoke iterator.remove. When using comparators on insertion, to keep a total ordering (or as close as is required here) across rebalancings, we compare classes and identityHashCodes as tie-breakers.
The use and transitions among plain vs tree modes is complicated by the existence of subclass LinkedHashMap. See below for hook methods defined to be invoked upon insertion, removal and access that allow LinkedHashMap internals to otherwise remain independent of these mechanics. (This also requires that a map instance be passed to some utility methods that may create new nodes.)
The concurrent-programming-like SSA-based coding style helps avoid aliasing errors amid all of the twisty pointer operations.
翻译:
实现说明:
该映射通常作为一个分桶(基于桶的)哈希表来运作,但当桶变得过大时,它们会被转换成由 TreeNodes 组成的桶,每个 TreeNodes 的结构与 java.util.TreeMap 中的类似。大多数方法会尽量使用常规桶,但在适用时(通过检查节点的实例类型)会将操作委托给 TreeNode 方法。由 TreeNodes 组成的桶可以像其他任何桶一样被遍历和使用,但当桶中元素过多时,它们还能支持更快的查找。然而,由于在正常使用中绝大多数桶都不会元素过多,因此在表方法的执行过程中,对树桶的检查可能会被延迟。
树桶(即,其元素全部为 TreeNodes 的桶)主要按 hashCode 排序,但如果两个元素的 hashCode 相同且它们的类型是 “实现 Comparable 接口的类 C”,则会使用它们的 compareTo 方法进行排序。(我们通过反射谨慎地检查通用类型以确认这一点 —— 参见 comparableClassFor 方法)。树桶的额外复杂性在提供最坏情况下 O(log n) 操作方面是值得的,前提是键的哈希值不同或者键是可排序的。因此,当 hashCode() 方法返回的值分布不佳(无论是意外还是恶意的),以及许多键共享一个 hashCode(只要它们也是 Comparable 的)时,性能可以优雅地 degradation(原文如此,应为 “降级” 之意)。(如果这些情况都不适用,与不采取预防措施相比,我们可能会在时间和空间上浪费大约两倍的开销。但目前已知的情况源于用户编程实践不佳,这些实践已经如此缓慢,以至于这一点几乎没有区别。)
由于 TreeNodes 的大小大约是普通节点的两倍,因此只有当桶中的节点数量足够多时才会使用它们(参见 TREEIFY_THRESHOLD)。当它们变得太小(由于删除或调整大小)时,它们会被转换回普通桶。在用户 hashCode 分布良好的情况下,树桶很少被使用。理想情况下,在随机 hashCode 的情况下,根据默认的 0.75 的调整大小阈值,桶中节点的频率遵循平均参数约为 0.5 的泊松分布(<http://en.wikipedia.org/wiki/Poisson_distribution>),尽管由于调整大小的粒度较大,方差也很大。忽略方差,大小为 k 的列表的预期出现次数为(exp(-0.5)pow(0.5,k)/ factorial(k))。前几个值是:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
树桶的根通常是其第一个节点。然而,有时侯(目前仅在 Iterator.remove 时),根可能在其他地方,但可以通过父链接找到(方法 TreeNode.root())。
所有适用的内部方法都接受一个哈希码作为参数(通常由公共方法提供),以便它们可以在不重新计算用户哈希码的情况下互相调用。大多数内部方法还接受一个 “tab” 参数,通常是当前表,但在调整大小或转换时可能是新的或旧的表。
当桶列表被树化、拆分或退树化时,我们保持它们的相对访问 / 遍历顺序(即,字段 Node.next)以更好地保持局部性,并稍微简化处理拆分和遍历的操作,这些操作可能会调用 iterator.remove。在插入时使用比较器时,为了在重新平衡期间保持总顺序(或尽可能接近此处所需的顺序),我们将类和 identityHashCode 作为决胜条件进行比较。
由于存在子类 LinkedHashMap,所以普通模式和树模式之间的使用和转换变得复杂。参见下面的钩子方法,这些方法被定义为在插入、删除和访问时调用,使得 LinkedHashMap 的内部可以独立于这些机制。(这也要求将地图实例传递给一些可能创建新节点的实用方法。)
这种类似并发编程的 SSA 基于编码风格有助于在所有复杂的指针操作中避免别名错误。
其中我用红色加粗标识了重点内容,其中第一句的意思是单个 TreeNode 需要占用的空间大约是普通 Node 的两倍,所以只有当包含足够多的Nodes 时才会转成 TreeNodes,而是否足够多就是由 TREEIFY_THRESHOLD 的值决定的。而当桶中节点数由于移除或者 resize 变少后,又会变回普通的链表的形式,以便节省空间。
通过查看源码可以发现,默认是链表长度达到 8 就转成红黑树,而当长度降到 6 就转换回去,这体现了时间和空间平衡的思想,最开始使用链表的时候,空间占用是比较少的,而且由于链表短,所以查询时间也没有太大的问题。可是当链表越来越长,需要用红黑树的形式来保证查询的效率。对于何时应该从链表转化为红黑树,需要确定一个阈值,这个阈值默认为 8,并且在源码中也对选择 8 这个数字做了说明,正是红色加粗标识内容的后一句。它的意思是如果 hashCode 分布良好,也就是 hash 计算的结果离散好的话,那么红黑树这种形式是很少会被用到的,因为各个值都均匀分布,很少出现链表很长的情况。在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.00000006。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从链表向红黑树的转换。
但是,HashMap 决定某一个元素落到哪一个桶里,是和这个对象的 hashCode 有关的,JDK 并不能阻止我们用户实现自己的哈希算法,如果我们故意把哈希算法变得不均匀,例如:
@Override
public int hashCode() {return 1;
}
这里 hashCode 计算出来的值始终为 1,那么就很容易导致 HashMap 里的链表变得很长。让我们来看下面这段代码:
/*** HashMapDemo 类用于演示 HashMap 的使用。* 该类包含一个测试方法,用于测试在 HashMap 中存储对象的行为。*/
public class HashMapDemo {/*** 测试方法,用于演示向 HashMap 中插入大量对象的情况。* 此方法创建一个初始容量为 1 的 HashMap,并向其中插入 1000 个 HashMapDemo 实例。* 由于重写了 hashCode 方法,所有实例的哈希码都相同。*/public static void main(String[] args) {// 创建一个初始容量为 1 的 HashMap,键的类型为 HashMapDemo,值的类型为 IntegerHashMap map = new HashMap<HashMapDemo,Integer>(1);// 循环 1000 次,每次创建一个新的 HashMapDemo 实例并插入到 HashMap 中for (int i = 0; i < 1000; i++) {// 创建一个新的 HashMapDemo 实例HashMapDemo hashMapDemo1 = new HashMapDemo();// 将新实例作为键,值为 null 插入到 HashMap 中map.put(hashMapDemo1, null);}// 输出运行结束信息System.out.println("运行结束");}/*** 重写 hashCode 方法,确保所有 HashMapDemo 实例的哈希码都为 1。* * @return 固定返回 1*/@Overridepublic int hashCode() {return 1;}
}在这个例子中,我们建了一个 HashMap,并且不停地往里放入值,所放入的 key 的对象,它的hashCode 是被重写过得,并且始终返回 1。这段代码运行时,如果通过 debug 让程序暂停在System.out.println("运行结束") 这行语句,我们观察 map 内的节点,可以发现已经变成了TreeNode,而不是通常的 Node,这说明内部已经转为了红黑树。

事实上,链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低,而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。
通常如果 hash 算法正常的话,那么链表的长度也不会很长,那么红黑树也不会带来明显的查询时间上的优势,反而会增加空间负担。所以通常情况下,并没有必要转为红黑树,所以就选择了概率非常小,小于千万分之一概率,也就是长度为 8 的概率,把长度 8 作为转化的默认阈值。
所以如果平时开发中发现 HashMap 或是 ConcurrentHashMap 内部出现了红黑树的结构,这个时候往往就说明我们的哈希算法出了问题,需要留意是不是我们实现了效果不好的 hashCode 方法,并对此进行改进,以便减少冲突。
相关文章:
Java多线程与高并发专题——为什么 Map 桶中超过 8 个才转为红黑树?
引入 JDK 1.8 的 HashMap 和 ConcurrentHashMap 都有这样一个特点:最开始的 Map 是空的,因为里面没有任何元素,往里放元素时会计算 hash 值,计算之后,第 1 个 value 会首先占用一个桶(也称为槽点ÿ…...
LeetCode hot 100—二叉树的中序遍历
题目 给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。 示例 示例 1: 输入:root [1,null,2,3] 输出:[1,3,2]示例 2: 输入:root [] 输出:[]示例 3: 输入:root […...

代码随想录算法训练营第35天 | 01背包问题二维、01背包问题一维、416. 分割等和子集
一、01背包问题二维 二维数组,一维为物品,二维为背包重量 import java.util.Scanner;public class Main{public static void main(String[] args){Scanner scanner new Scanner(System.in);int n scanner.nextInt();int bag scanner.nextInt();int[…...
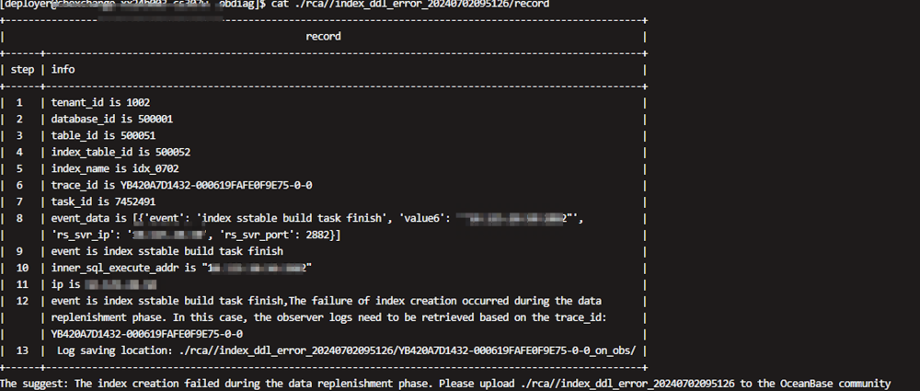
与中国联通技术共建:通过obdiag分析OceanBase DDL中的报错场景
中国联通软件研究院(简称联通软研院)在全面评估与广泛调研后,在 2021年底决定采用OceanBase 作为基础,自研分布式数据库产品CUDB(即China Unicom Database,中国联通数据库)。目前,该…...

IDEA 接入 Deepseek
在本篇文章中,我们将详细介绍如何在 JetBrains IDEA 中使用 Continue 插件接入 DeepSeek,让你的 AI 编程助手更智能,提高开发效率。 一、前置准备 在开始之前,请确保你已经具备以下条件: 安装了 JetBrains IDEA&…...

斗地主小游戏
<!DOCTYPE html> <html><head><meta charset="utf-8"><title>斗地主</title><style>.game-container {width: 1000px;height: 700px;margin: 0 auto;position: relative;background: #35654d;border-radius: 10px;padding…...

如何改变怂怂懦弱的气质(2)
你是否曾经因为害怕失败而逃避选择?是否因为不敢拒绝别人而让自己陷入困境?是否因为过于友善而被人轻视?如果你也曾为这些问题困扰,那么今天的博客就是为你准备的。我们将从行动、拒绝、自我认知、实力提升等多个角度,…...

C# OnnxRuntime部署DAMO-YOLO人头检测
目录 说明 效果 模型信息 项目 代码 下载 参考 说明 效果 模型信息 Model Properties ------------------------- --------------------------------------------------------------- Inputs ------------------------- name:input tensor:Floa…...

基于GeoTools的GIS专题图自适应边界及高宽等比例生成实践
目录 前言 一、原来的生成方案问题 1、无法自动读取数据的Bounds 2、专题图高宽比例不协调 二、专题图生成优化 1、直接读取矢量数据的Bounds 2、专题图成果抗锯齿 3、专题成果高宽比例自动调节 三、总结 前言 在当今数字化浪潮中,地理信息系统(…...

各种DCC软件使用Datasmith导入UE教程
3Dmax: 先安装插件 https://www.unrealengine.com/zh-CN/datasmith/plugins 左上角导出即可 虚幻中勾选3个插件,重启引擎 左上角选择文件导入即可 Blender导入Datasmith进UE 需要两个插件, 文章最下方链接进去下载安装即可 一样的,直接导出,然后UE导入即可 C4D 直接保存成…...

尚硅谷爬虫note15
一、当当网 1. 保存数据 数据交给pipelines保存 items中的类名: DemoNddwItem class DemoNddwItem(scrapy.Item): 变量名 类名() book DemoNddwItem(src src, name name, price price)导入: from 项目名.items import 类…...

云原生系列之本地k8s环境搭建
前置条件 Windows 11 家庭中文版,版本号 23H2 云原生环境搭建 操作系统启用wsl(windows subsystem for linux) 开启wsl功能,如下图 安装并开启github加速器 FastGithub 2.1 下载地址:点击下载 2.2 解压安装文件fastgithub_win-x64.zip 2…...

关于tomcat使用中浏览器打开index.jsp后中文显示不正常是乱码,但英文正常的问题
如果是jsp文件就在首行加 “<% page language"java" contentType"text/html; charsetUTF-8" pageEncoding"UTF-8" %>” 如果是html文件 在head标签加入: <meta charset"UTF-8"> 以jsp为例子,我们…...

mysql foreign_key_checks
foreign_key_checks是一个用于设置是否在DML/DDL操作中检查外键约束的系统变量。该变量默认启用,通常在正常操作期间启用以强制执行参照完整性。 功能描述 foreign_key_checks用于控制是否在DML(数据操纵语言)和DDL(数据定义…...

开发环境搭建-06.后端环境搭建-前后端联调-Nginx反向代理和负载均衡概念
一.前后端联调 我们首先来思考一个问题 前端的请求地址是:http://localhost/api/employee/login 后端的接口地址是:http://localhost:8080/admin/employee/login 明明请求地址和接口地址不同,那么前端是如何请求到后端接口所响应回来的数…...

REST API前端请求和后端接收
1、get请求,带"?" http://localhost:8080/api/aop/getResult?param123 GetMapping("getResult")public ResponseEntity<String> getResult(RequestParam("param") String param){return new ResponseEntity<>("12…...
开展)
道可云人工智能每日资讯|《奇遇三星堆》VR沉浸探索展(淮安站)开展
道可云元宇宙每日简报(2025年3月5日)讯,今日元宇宙新鲜事有: 《奇遇三星堆》VR沉浸探索展(淮安站)开展 近日,《奇遇三星堆》VR沉浸探索展(淮安站)开展。该展将三星堆文…...

服务器数据恢复—raid5阵列中硬盘掉线导致上层应用不可用的数据恢复案例
服务器数据恢复环境&故障: 某公司一台服务器,服务器上有一组由8块硬盘组建的raid5磁盘阵列。 磁盘阵列中2块硬盘的指示灯显示异常,其他硬盘指示灯显示正常。上层应用不可用。 服务器数据恢复过程: 1、将服务器中所有硬盘编号…...

【Pandas】pandas Series swaplevel
Pandas2.2 Series Computations descriptive stats 方法描述Series.argsort([axis, kind, order, stable])用于返回 Series 中元素排序后的索引位置的方法Series.argmin([axis, skipna])用于返回 Series 中最小值索引位置的方法Series.argmax([axis, skipna])用于返回 Series…...

esp32s3聊天机器人(二)
继续上文,硬件软件准备齐全,介绍一下主要用到的库 sherpa-onnx 开源的,语音转文本、文本转语音、说话人分类和 VAD,关键是支持C#开发 OllamaSharp 用于连接ollama,如其名C#开发 虽然离可玩还有一段距离࿰…...
)
数据标准化(拟合的时候使用非常重要)
一、函数作用这个函数是数据标准化(Z-Score 标准化) 函数,专门对两组数据 x_raw(自变量)做标准化处理,并返回标准化后的数据 记录标准化参数的对象。具体做了这 4 件事:计算 x_raw 的均值和标准…...

API Key认证系统设计:企业级API开放平台实践
API Key认证系统设计:企业级API开放平台实践 摘要:当AI应用从内部工具转向对外开放时,如何确保接口安全、防止滥用并实现精细化权限控制?本文基于一个真实的跑步教练AI项目,详细解析如何构建一套生产级的API Key认证系…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

别再手动算位宽了!Vivado FIR IP核的位宽计算逻辑与配置避坑指南
Vivado FIR IP核位宽计算实战:从黑盒解析到精准配置 在FPGA数字信号处理领域,FIR滤波器作为基础构建模块,其性能表现直接影响整个系统的信号处理质量。而位宽配置这个看似简单的参数,往往成为项目后期调试阶段的"隐形杀手&qu…...

高效跨平台游戏模组下载:WorkshopDL完全指南
高效跨平台游戏模组下载:WorkshopDL完全指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在Epic Games Store、GOG或其他非Steam平台购买了游戏࿰…...

终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼
终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中疯狂上跳的枪口而…...

从开源物理拼图游戏学习Unity 2D物理引擎与游戏架构设计
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“openclaw-puzzle-game”。光看名字,你可能会觉得这又是一个普通的开源拼图游戏,但点进去仔细研究后,我发现它的设计思路和实现方式,对于想学习游戏开…...

构建个人代码仓库:提升开发效率的实践指南
1. 项目概述:一个面向21世纪开发者的代码仓库最近在GitHub上看到一个挺有意思的项目,叫“21st-dev/1code”。光看这个名字,你可能觉得有点抽象,但点进去之后,我发现它其实是一个挺有想法的代码仓库。这个项目没有复杂的…...

基于Taotoken统一API开发支持多模型切换的智能对话应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基于Taotoken统一API开发支持多模型切换的智能对话应用 应用场景类,场景是开发一个需要支持用户自由选择或系统自动切换…...

Arm Cortex-A35 Cycle Model技术解析与SoC集成实战
1. Arm Cortex-A35 Cycle Model技术解析在SoC设计领域,虚拟平台验证已成为不可或缺的关键环节。作为Armv8-A架构中的能效比优化核心,Cortex-A35处理器通过Cycle Model提供了RTL级精度的硬件行为模拟能力。我在多个车载SoC项目中验证发现,其Cy…...