尚硅谷爬虫note15
一、当当网
1. 保存数据
数据交给pipelines保存
items中的类名: DemoNddwItem
class DemoNddwItem(scrapy.Item):变量名 = 类名()
book = DemoNddwItem(src = src, name = name, price = price)
导入:
from 项目名.items import 类名
from demo_nddw.items import NddwSpider
2. yield
return一个返回值
yield book:
获取一个book,就将book交给pipelines
3. pipelines(管道):
想使用管道,必须在settings中开启管道:
如何开启——》解除管道的注释即可开启管道


管道可以有很多个
管道是有优先级的:
优先级范围:1~1000
值越小,优先级越高
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass DemoNddwPipeline:
#爬虫文件开始前执行的方法def open_spider(self, spider)self.fp('book.json', 'w', encoding='utf-8')# items:yield后面的book对象def process_item(self, item, spider):
# #以下模式不推荐:因为每传进一个对象,就打开一次文件,对文件的操作过于频繁
# #2个方法
# #1)爬虫文件开始前执行的方法
# def open_spider(self,spider)
# self.fp('book.json','w',encoding = 'utf-8')
# #2)爬虫文件执行完成后执行的方法
# def close_spider(self,spider)
# self.fp.close()
# # 中间
# self.fp.write(str(item))#将数据保存到文件中# (1)write方法必须是一个字符串强制转换:fp.write(item)——》fp.write(str(item))# (2)w模式会每一个对象都打开一次文件,后面打开的会覆盖前面打开的,然后关闭:将w模式改为a(追加)模式:解决:‘w’——》‘a’#不推荐的模式# with open('book.json','a',encoding='utf-8') as fp:# fp.write(str(item))
#中间self.fp.write(str(item))return item
#爬虫文件执行完成后执行的方法
def close_spider(self,spider)self.fp.close()
不推荐的模式:
# #以下模式不推荐:因为每传进一个对象,就打开一次文件,对文件的操作过于频繁#将数据保存到文件中# (1)write方法必须是一个字符串强制转换:fp.write(item)——》fp.write(str(item))# (2)w模式会每一个对象都打开一次文件,后面打开的会覆盖前面打开的,然后关闭:将w模式改为a(追加)模式:解决:‘w’——》‘a’#不推荐的模式# with open('book.json','a',encoding='utf-8') as fp:# fp.write(str(item))
2个方法:
# #2个方法
# #1)爬虫文件开始前执行的方法
# def open_spider(self,spider)
# self.fp('book.json','w',encoding = 'utf-8')
# #2)爬虫文件执行完成后执行的方法
# def close_spider(self,spider)
# self.fp.close()
# # 中间
# self.fp.write(str(item))复制items中的类名:DemoNddwItem
导入ddw中,
from demo_nddw.items import DemoNddwItem
并在ddw中使用
book = DemoNddwItem(src = src, name = name, price = price)ddw.py
import scrapy
from demo_nddw.items import DemoNddwItemclass NddwSpider(scrapy.Spider):name = "nddw"allowed_domains = ["category.dangdang.com"]start_urls = ["https://category.dangdang.com/cp01.07.30.00.00.00.html"]def parse(self, response):# pass# src、name、price都有共同的li标签# 所有的selector对象,都可以再次调用xpath方法li_list = response.xpath('//ul[@id = "component_59"]/li')for li in li_list:# .extract()提取数据# 有data-original,src用data-original替代src = li.xpath('.//img/@data-original').extract_first()# 第一张图片和其他图片标签不一样,第一张图片的src是可以使用的 其他图片的地址是data-originalif src:src = srcelse:# 用srcsrc = li.xpath('.//img/@src').extract_first()alt = li.xpath('.//img/@alt').extract_first()price = li.xpath('.//p[@class = "price"]/span[1]/text()').extract_first()print(src, name, price)book = DemoNddwItem(src = src, name = name, price = price)# yield:return一个返回值#获取一个book,就将book交给pipelinesyield book# pipelines(管道):想使用管道,必须在settings中开启管道:如何开启——》解除管道的注释即可开启
# ITEM_PIPELINES = {
# "demo_nddw.pipelines.DemoNddwPipeline": 300,
# }
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass DemoNddwItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# pass# 图片# src = // ul[ @ id = "component_59"] / li // img / @ srcsrc = scrapy.Field()# 名字# alt = // ul[ @ id = "component_59"] / li // img / @ altname = scrapy.Field()# 价格# price = //ul[@id = "component_59"]/li//p[@class = "price"]/span[1]/text()price = scrapy.Field()
4. scrapy使用步骤
1)在终端中创建项目
scrapy startproject 项目名
2)切换到项目下的spiders目录
cd 项目名\项目名\spider
3)在spiders中创建文件
scrapy genspider 文件名
4)运行
scrapy crawl 文件名
相关文章:
尚硅谷爬虫note15
一、当当网 1. 保存数据 数据交给pipelines保存 items中的类名: DemoNddwItem class DemoNddwItem(scrapy.Item): 变量名 类名() book DemoNddwItem(src src, name name, price price)导入: from 项目名.items import 类…...

云原生系列之本地k8s环境搭建
前置条件 Windows 11 家庭中文版,版本号 23H2 云原生环境搭建 操作系统启用wsl(windows subsystem for linux) 开启wsl功能,如下图 安装并开启github加速器 FastGithub 2.1 下载地址:点击下载 2.2 解压安装文件fastgithub_win-x64.zip 2…...

关于tomcat使用中浏览器打开index.jsp后中文显示不正常是乱码,但英文正常的问题
如果是jsp文件就在首行加 “<% page language"java" contentType"text/html; charsetUTF-8" pageEncoding"UTF-8" %>” 如果是html文件 在head标签加入: <meta charset"UTF-8"> 以jsp为例子,我们…...

mysql foreign_key_checks
foreign_key_checks是一个用于设置是否在DML/DDL操作中检查外键约束的系统变量。该变量默认启用,通常在正常操作期间启用以强制执行参照完整性。 功能描述 foreign_key_checks用于控制是否在DML(数据操纵语言)和DDL(数据定义…...

开发环境搭建-06.后端环境搭建-前后端联调-Nginx反向代理和负载均衡概念
一.前后端联调 我们首先来思考一个问题 前端的请求地址是:http://localhost/api/employee/login 后端的接口地址是:http://localhost:8080/admin/employee/login 明明请求地址和接口地址不同,那么前端是如何请求到后端接口所响应回来的数…...

REST API前端请求和后端接收
1、get请求,带"?" http://localhost:8080/api/aop/getResult?param123 GetMapping("getResult")public ResponseEntity<String> getResult(RequestParam("param") String param){return new ResponseEntity<>("12…...
开展)
道可云人工智能每日资讯|《奇遇三星堆》VR沉浸探索展(淮安站)开展
道可云元宇宙每日简报(2025年3月5日)讯,今日元宇宙新鲜事有: 《奇遇三星堆》VR沉浸探索展(淮安站)开展 近日,《奇遇三星堆》VR沉浸探索展(淮安站)开展。该展将三星堆文…...

服务器数据恢复—raid5阵列中硬盘掉线导致上层应用不可用的数据恢复案例
服务器数据恢复环境&故障: 某公司一台服务器,服务器上有一组由8块硬盘组建的raid5磁盘阵列。 磁盘阵列中2块硬盘的指示灯显示异常,其他硬盘指示灯显示正常。上层应用不可用。 服务器数据恢复过程: 1、将服务器中所有硬盘编号…...

【Pandas】pandas Series swaplevel
Pandas2.2 Series Computations descriptive stats 方法描述Series.argsort([axis, kind, order, stable])用于返回 Series 中元素排序后的索引位置的方法Series.argmin([axis, skipna])用于返回 Series 中最小值索引位置的方法Series.argmax([axis, skipna])用于返回 Series…...

esp32s3聊天机器人(二)
继续上文,硬件软件准备齐全,介绍一下主要用到的库 sherpa-onnx 开源的,语音转文本、文本转语音、说话人分类和 VAD,关键是支持C#开发 OllamaSharp 用于连接ollama,如其名C#开发 虽然离可玩还有一段距离࿰…...
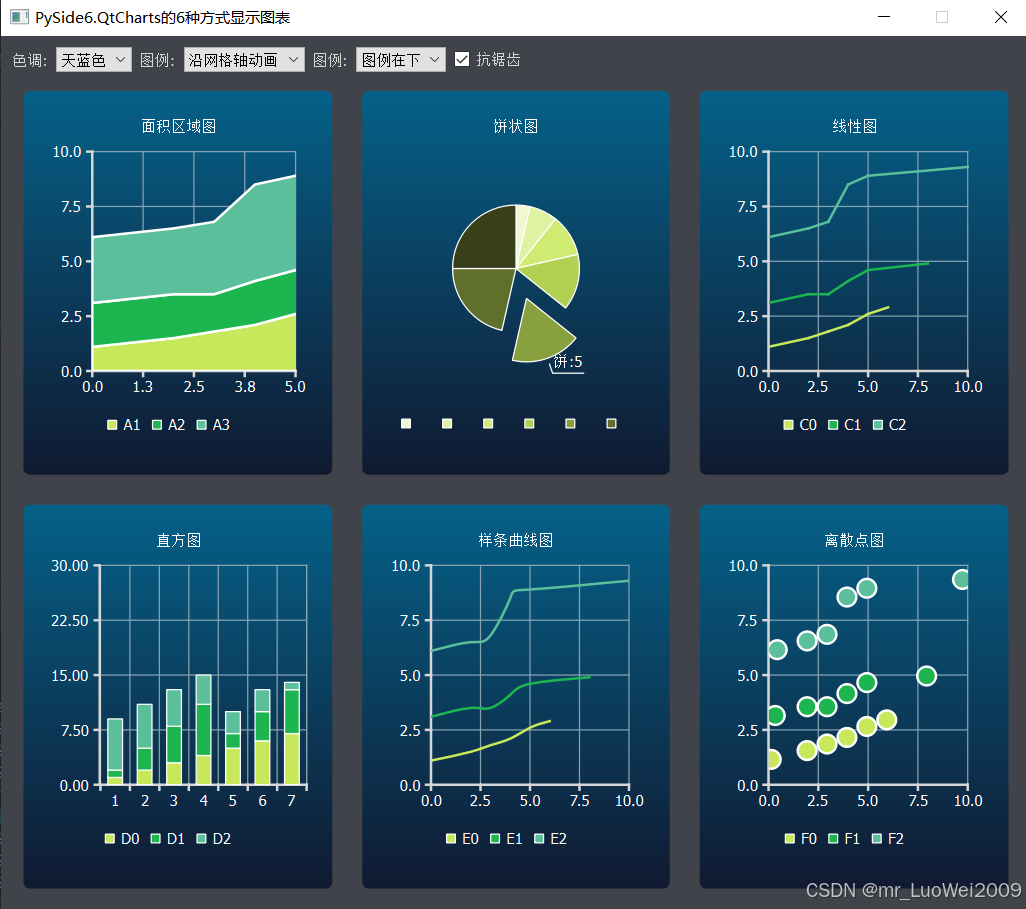
pyside6学习专栏(九):在PySide6中使用PySide6.QtCharts绘制6种不同的图表的示例代码
PySide6的QtCharts类支持绘制各种型状的图表,如面积区域图、饼状图、折线图、直方图、线条曲线图、离散点图等,下面的代码是采用示例数据绘制这6种图表的示例代码,并可实现动画显示效果,实际使用时参照代码中示例数据的格式将实际数据替换即可…...

DVI分配器2进4出,2进8出,2进16出,120HZ
DVI(Digital Visual Interface)分配器GEFFEN/HDD系列是一种设备,它能够将一个DVI信号源的内容复制到多个显示设备上。根据您提供的信息,这里我们关注的是具有2个输入端口和多个(4个、8个或16个)输出端口的D…...

迷你世界脚本文字板接口:Graphics
文字板接口:Graphics 彼得兔 更新时间: 2024-08-27 11:12:18 具体函数名及描述如下: 序号 函数名 函数描述 1 makeGraphicsText(...) 创建文字板信息 2 makeflotageText(...) 创建漂浮文字信息 3 makeGraphicsProgress(...) 创建进度条信息…...

5分钟速览深度学习经典论文 —— attention is all you need
《Attention is All You Need》是一篇极其重要的论文,它提出的 Transformer 模型和自注意力机制不仅推动了 NLP 领域的发展,还对整个深度学习领域产生了深远影响。这篇论文的重要性体现在其开创性、技术突破和广泛应用上,是每一位深度学习研究…...
Cursor + IDEA 双开极速交互
相信很多开发者朋友应该和我一样吧,都是Cursor和IDEA双开的开发模式:在Cursor中快速编写和生成代码,然后在IDEA中进行调试和优化 在这个双开模式的开发过程中,我就遇到一个说大不大说小不小的问题: 得在两个编辑器之间来回切换查…...
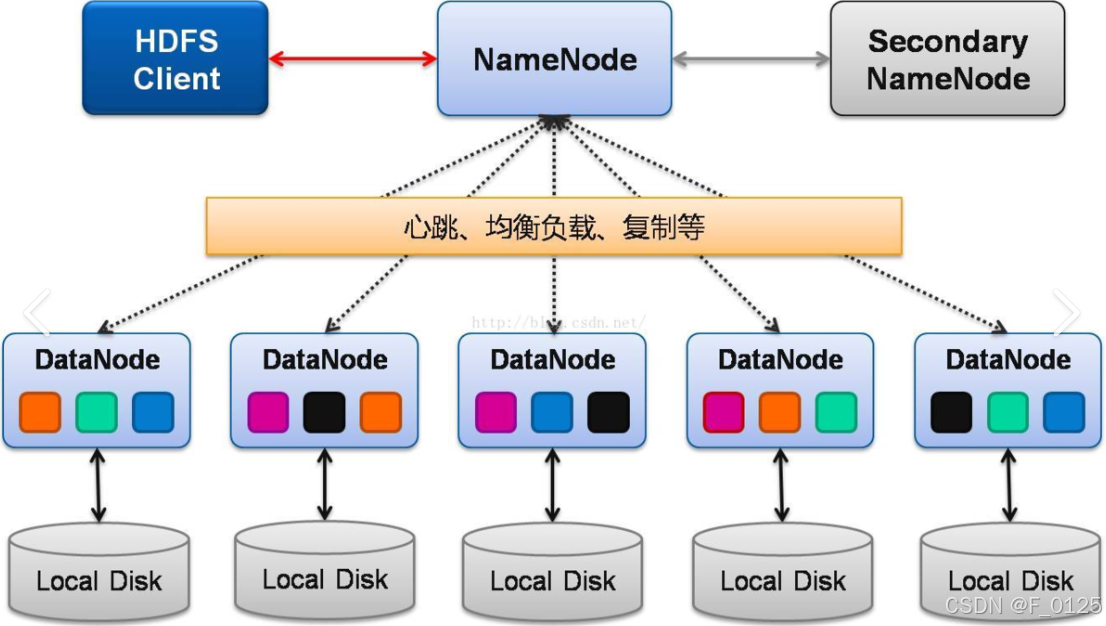
HDFS的设计架构
HDFS 是 Hadoop 生态系统中的分布式文件系统,设计用于存储和处理超大规模数据集。它具有高可靠性、高扩展性和高吞吐量的特点,适合运行在廉价硬件上。 1. HDFS 的设计思想 HDFS 的设计目标是解决大规模数据存储和处理的问题,其核心设计思想…...

为wordpress自定义一个留言表单并可以在后台进行管理的实现方法
要为WordPress添加留言表单功能并实现后台管理,你可以按照以下步骤操作: 1. 创建留言表单 首先,你需要创建一个留言表单。可以使用插件(如Contact Form 7)或手动编写代码。 使用Contact Form 7插件 安装并激活Contact Form 7插件。 创建…...
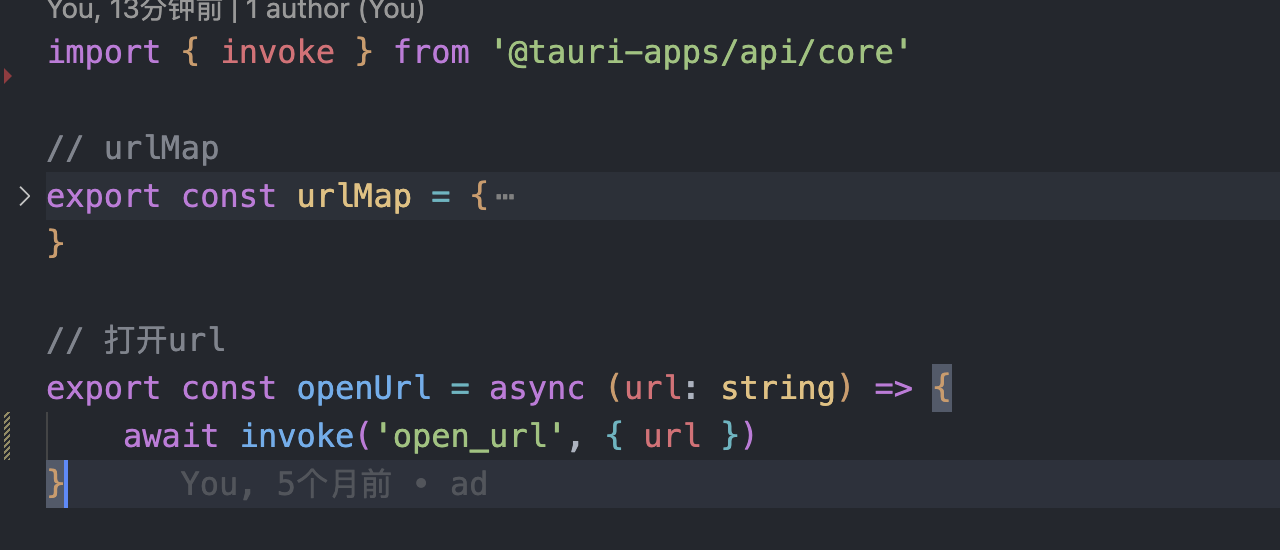
tauri-plugin-shell插件将_blank的a标签用浏览器打开了,,,解决办法
不要使用这个插件,这个插件默认会将网页中a标签为_blank的使用默认浏览器打开,但是这种做法在我的程序里不是很友好,我需要自定义这种行为,当我点击我自己的链接的时候,使用默认浏览器打开,当点击别的链接的…...

【大模型基础_毛玉仁】1.1 基于统计方法的语言模型
【大模型基础_毛玉仁】1.1 基于统计方法的语言模型 1.语言模型基础1.1 基于统计方法的语言模型1.1.1 n-grams 语言模型1.1.2 n-grams 的统计学原理 1.语言模型基础 语言是概率的。语言模型(LanguageModels, LMs)旨在准确预测语言符号的概率。 将按照语…...

使用 Docker 部署 RabbitMQ 并实现数据持久化
非常好!以下是一份完整的 Docker 部署 RabbitMQ 的博客文档,包含从安装到问题排查的详细步骤。你可以直接将其发布到博客中。 使用 Docker 部署 RabbitMQ 并实现数据持久化 RabbitMQ 是一个开源的消息队列系统,广泛应用于分布式系统中。使用…...

基于Node.js与Socket.IO构建开源实时聊天应用:从架构到部署
1. 项目概述:一个为纯净对话而生的开源聊天应用在信息过载的今天,我们每天被各种应用的通知、广告和复杂功能所包围。对于即时通讯这类高频使用的工具,这种“臃肿感”尤为明显。你是否也怀念过早期聊天软件那种简洁、纯粹、专注于信息交换本身…...

【多智能体】多智能体多视角三维空间定位的神经动力学方法【含Matlab源码 15447期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab武动乾坤博客之家💞…...

3分钟掌握APK Installer:在Windows电脑上轻松安装安卓应用的终极方案
3分钟掌握APK Installer:在Windows电脑上轻松安装安卓应用的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想在Windows电脑上直接运行An…...

量子电路反编译与遗传编程在量子计算中的应用
1. 量子电路反编译:从黑箱到透明设计的革命性跨越量子计算正经历着从实验室走向实际应用的关键转型期。在这个被称为"嘈杂中等规模量子"(NISQ)的时代,量子架构搜索(QAS)已成为设计高效量子算法的…...

Python网络编程利器:pincer中间件框架的设计原理与应用实践
1. 项目概述与核心价值最近在折腾一个游戏服务器的网络通信模块,偶然间在GitHub上看到了一个名为“pincer”的项目,作者是TheOneWhoAlwaysWatches。这个项目名挺有意思,直译过来是“钳子”或“夹子”,在计算机领域,尤其…...

AI技能实战指南:从提示工程到RAG与LoRA微调全流程解析
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的仓库,叫tqviet1978/ai-skills。光看名字,你可能会觉得这又是一个关于“AI技能”的泛泛而谈的教程合集。但点进去仔细研究后,我发现它的定位非常精准,更像是一个为开发者、技…...

NCM解密终极指南:3步释放网易云音乐到任何播放器
NCM解密终极指南:3步释放网易云音乐到任何播放器 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在特定应用中播放?当你想要将音乐迁移到其他设…...

告别手改脚本!用CANoe Panel面板做个变量控制台,测试效率翻倍
告别手改脚本!用CANoe Panel面板打造智能变量控制台 在车载网络测试领域,效率提升往往隐藏在那些被忽视的日常操作细节中。当测试工程师频繁打开CAPL脚本修改超时阈值、调整诊断ID或切换测试模式时,不仅打断了工作流,更在团队协作…...

从零构建AOD-Net:PyTorch实战图像去雾模型开发全流程
1. 环境准备与数据理解 在开始构建AOD-Net之前,我们需要先搭建好开发环境。推荐使用Anaconda创建独立的Python环境,避免与其他项目产生依赖冲突。这里我选择Python 3.8和PyTorch 1.12的组合,这个版本经过实测在图像处理任务中表现稳定。 安装…...

如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南
如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Ass…...