【决策树】分类属性的选择
文章目录
- 1.信息增益(ID3)
- 2.信息增益率(C4.5)
- 3.基尼指数(CART)
- ps.三者对比
实现决策树算法最关键的一点就是如何从所有的特征属性中选择一个最优的属性对样本进行分类,这种最优可以理解为希望划分后每种类别中的样本尽可能同类,也就是足够“纯净”。
1.信息增益(ID3)
需要先了解信息墒,墒表示一个系统内部的混乱程度,墒越大越混乱。信息墒的公式:

信息墒的最大值,就是当各类样本出现的比例相同时出现,代入公式可求。
对于公式的理解直接看deepseek的回答,比较准确形象:通俗理解信息墒的公式。

了解了信息墒的含义,假设现在有一个样本空间D,信息墒为E。D根据特征属性x可以划分为 D1, D2, D3 三个子样本空间,各个子样本空间样本数占总样本空间比例 k1, k2, k3,每个子样本空间根据公式也可以计算出自己的信息墒,假设为 E1, E2, E3,那么以这个特征属性划分后D的信息墒为 各个子样本空间信息墒*权重 之和,即 k1*E1 + k2*E2 + k3 *E3,这个值越大,表示用特征属性x对样本空间划分后的分类效果越差。越小表示分类效果越好,能更有效地将数据划分为纯度更高的子集。因此,需要做的就是计算出每个特征属性划分后的信息墒,优先用信息墒最小的那个特征属性划分,此时能获得最大的信息增益。
然后在子样本空间中用剩下的特征属性重复这个流程,循环往复…,得到一棵分类效果最好的树。
下面是周志华机器学习书中对信息增益的定义:

2.信息增益率(C4.5)
信息增益的选择方式倾向于选择属性值较多的属性,因为这样划分后子空间的信息墒最小,信息增益最大,但容易造成过拟合模型返回能力差的问题,比如在用户的(id、性别、年龄、体重、各种检查指标…)中拿用户的id去预测是否患病,准确但没有意义。
此时通过在上一步信息增益的基础上,除以一个属性固有值(类似于墒值),来平衡属性值较多的属性的信息增益。
这个属性固有值的公式是:

a表示特征属性,V表示值类型的数量,D表示总样本数,Dv表示每个取值下样本数量。
对于这个公式的理解:信息增益中属性固有信息的公式及理解。
所以信息增益率的公式为:

根据增益率对划分属性的选择,

对这种“启发式选择”的理解。
3.基尼指数(CART)
基尼指数属于CART算法,但CRAT算法并不只有基尼指数一种实现方式(分类: 基尼指数;回归: 均方误差)。 见【4.三者对比】部分

上图中4.5基尼值的公式中, p k p_k pk为第k类样本占总样本的比例, p k ′ p_{k'} pk′为非k类样本占的比例( 1 − p k 1-p_k 1−pk)。
为什么这个公式可以反映样本空间的混乱程度?
首先 p k p_k pk的取值在0-1,且所有可能的 p k p_k pk之和等于1。
明显当所有类别占比相等时最混乱,假设对于二分类,此时对于k1、k2,所占总样本的比例 p k 1 p_{k_1} pk1 p k 2 p_{k_2} pk2都为0.5,对应的 p k 1 ′ p_{k_1'} pk1′ p k 2 ′ p_{k_2'} pk2′也都为0.5,因此 ∑ k = 1 ∣ y ∣ p k 2 \sum\limits_{k=1}^{|y|} p_k^2 k=1∑∣y∣pk2= 0. 5 2 0.5^2 0.52+ 0. 5 2 = 0.5 0.5^2=0.5 0.52=0.5,基尼指数= 1 − 0.5 = 0.5 1-0.5=0.5 1−0.5=0.5。
当增大一个 p k p_k pk时,另一个 p k p_k pk必然减少,当对 p k p_k pk进行平方运算时,大的 p k p_k pk增大的那部分必然会大于小的 p k p_k pk减少的那部分,所以 ∑ k = 1 ∣ y ∣ p k 2 \sum\limits_{k=1}^{|y|} p_k^2 k=1∑∣y∣pk2一定会变得更大,所以最终的基尼值 1 − ∑ k = 1 ∣ y ∣ p k 2 1-\sum\limits_{k=1}^{|y|} p_k^2 1−k=1∑∣y∣pk2减少。
eg: p k 1 p_{k_1} pk1=0.6, p k 2 p_{k_2} pk2=0.4, ∑ k = 1 ∣ y ∣ p k 2 \sum\limits_{k=1}^{|y|} p_k^2 k=1∑∣y∣pk2= 0. 6 2 0.6^2 0.62+ 0. 4 2 = 0.52 0.4^2=0.52 0.42=0.52,基尼指数= 1 − 0.52 = 0.48 1-0.52=0.48 1−0.52=0.48。
而下面属性a的基尼指数公式,其实是度量用a属性划分后的所有子样本空间中各自的混乱程度,然后乘以各个子样本空间在总样本空间的占比权重,最后汇总求和。所以可以说公式表示的含义是:用a属性对总样本空间进行划分后,总样本空间的混乱程度。
因此属性a划分后基尼值越小,表示样本空间越“纯净”,也就是分类效果越好。
需要注意的是:虽然基尼指数的公式理论上支持多分类,但算法实现中只会二分类,递归的生成二叉树。 分类过程中会在每个候选属性中枚举遍历找到基尼指数最小的最优组合,然后找出全局最优划分组合,该组合对应的属性和划分方式作为该节点的划分属性和分类的方式。
对基尼指数的公式及理解。
ps.三者对比

主要关注为什么CART可以做回归,而另外两种实现方式不支持。
因为上面两种核心都是要通过目标值的分类,进而知道概率计算墒值,只支持目标值为离散型变量。
而CART算法中,可以通过调整属性划分时的依据公式(均方差),尝试找到每个候选属性的最优分隔组合,这个分割组合要满足分隔后的两个子集的加权均方误差最小(目标值的均方误差),然后选择最优的那个候选属性划分。之后重复迭代下去…
当做回归预测时,最终落到哪个分类,直接返回这个类别的均值就行。
相关文章:
【决策树】分类属性的选择
文章目录 1.信息增益(ID3)2.信息增益率(C4.5)3.基尼指数(CART)ps.三者对比 实现决策树算法最关键的一点就是如何从所有的特征属性中选择一个最优的属性对样本进行分类,这种最优可以理解为希望划…...
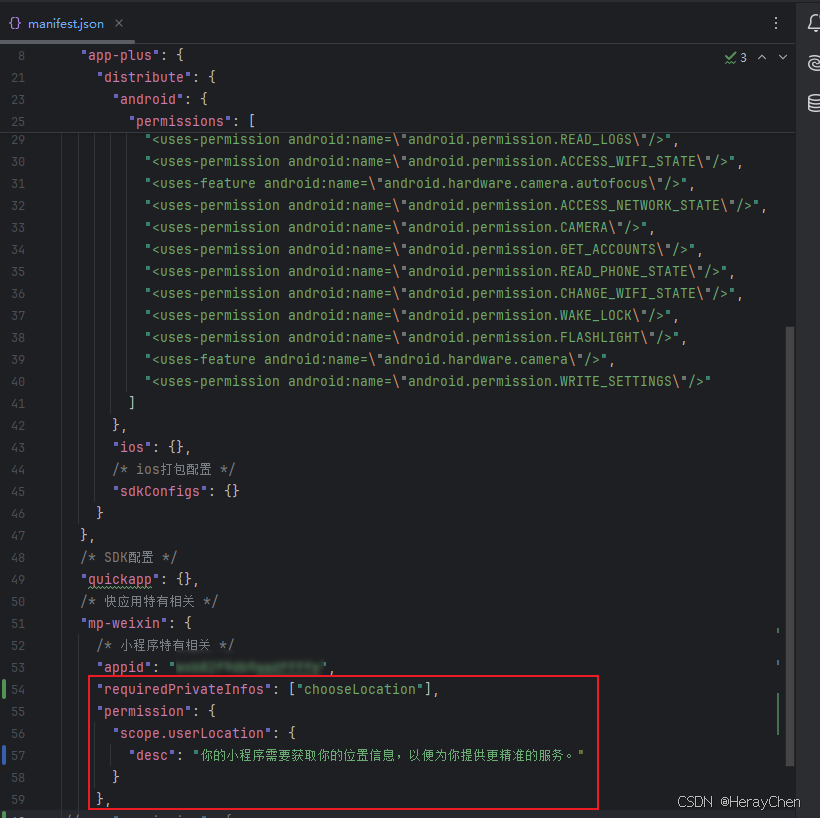
uniapp vue3 微信小程序 uni.chooseLocation使用
申请 先要去微信公众平台申请使用接口 开通成功之后就可以在项目中配置使用了 配置 配置manifest.json "mp-weixin": {/* 小程序特有相关 */"requiredPrivateInfos": ["chooseLocation"],"permission": {"scope.userLocati…...

9. Flink的性能优化
1. Flink的资源和代码优化 1.1 slot资源配置 Flink中具体跑任务的进程叫TaskManager,TM进程又会根据配置划分出诺干个TaskSlot,它是具体运行SubTask的地方。slot是Flink用来隔离各个subtask的资源集合,这里的资源一把指内存,TCP…...

十二、OSG学习笔记-Control
上一章节: 十一、OSG学习笔记-操作系统接口-CSDN博客https://blog.csdn.net/weixin_36323170/article/details/145891502 本章节代码: OsgStudy/Controls CuiQingCheng/OsgStudy - 码云 - 开源中国https://gitee.com/cuiqingcheng/osg-study/tree/ma…...

集群、分布式与微服务架构 区别
集群、分布式与微服务架构:概念解析与核心差异 在构建现代软件系统时,集群架构、分布式系统和微服务架构是三种常见的技术方案。它们常被混淆,但各自解决的问题、设计理念和应用场景截然不同。本文将从基础概念出发,深入分析三者…...

如何使用SSH命令安全连接并转发端口到远程服务器
ssh -p 22546 rootconnect.westc.gpuhub.com d6IS/mQKq/iG ssh -CNgv -L 6006:127.0.0.1:6006 rootconnect.westc.gpuhub.com -p 22546 第一条命令:用于登录远程服务器,进行交互式操作。第二条命令:用于建立 SSH 隧道,进行端口转…...

【Java 基础】-- 设计模式
目录 Java 设计模式详解 1. 设计模式定义 2. 设计模式示例 2.1 单例模式(Singleton Pattern) 2.2 工厂模式(Factory Pattern) 2.3 观察者模式(Observer Pattern) 2.4 代理模式(Proxy Pat…...
)
ComfyUI进阶学习全指南(2025年最新版)
ComfyUI进阶学习全指南(2025年最新版) 一、自定义节点与扩展管理 1.1 自定义节点安装与维护 ComfyUI的核心竞争力在于其可扩展性。通过安装第三方节点模块,用户可实现超分辨率修复、骨骼绑定动画生成等高级功能。安装方式主要分为三种&…...

Linux和gcc/g++常用命令总结
目录 Linux命令总结 文件操作相关命令 ls cd pwd cp mv rm cat mkdir rmdir touch 文本处理操作命令 grep awk sed 进程管理操作相关命令 ps top htop kill pkill killall chmod chown 网络操作相关命令 ping ifconfig netstat ss lsof curl …...
)
uniapp封装路由管理(兼容Vue2和Vue3)
1:uniapp已经有路由管理了为什么还要二次封装路由? 简化配置和调用增强灵活性和可扩展性实现统一的功能和策略提升开发效率和团队协作 2. 增强灵活性和可扩展性 灵活配置:二次封装允许开发者根据实际需求灵活配置路由参数,如跳…...
π0源码解析——一个模型控制7种机械臂:对开源VLA sota之π0源码的全面分析,含我司的部分落地实践
前言 ChatGPT出来后的两年多,也是我疯狂写博的两年多(年初deepseek更引爆了下),比如从创业起步时的15年到后来22年之间 每年2-6篇的,干到了23年30篇、24年65篇、25年前两月18篇,成了我在大模型和具身的原始技术积累 如今一转眼…...

【C++】Class(1)
《C程序设计基础教程》——刘厚泉,李政伟,二零一三年九月版,学习笔记 文章目录 1、类的定义1.1、结构体和类1.2、基本概念1.3、成员函数的定义1.4、内联成员函数 2、对象2.1、对象的定义2.2、成员访问 3、构造函数3.1、构造函数的定义3.2、子…...

doris: Oracle
Apache Doris JDBC Catalog 支持通过标准 JDBC 接口连接 Oracle 数据库。本文档介绍如何配置 Oracle 数据库连接。 使用须知 要连接到 Oracle 数据库,您需要 Oracle 19c, 18c, 12c, 11g 或 10g。 Oracle 数据库的 JDBC 驱动程序,您可以从 Maven 仓库…...

Android14 OTA差分包升级报Package is for source build
制作好差分包,使用adb线刷模式验证ota升级,出现E:Package is for source build错误 使用adb方式验证 进入recovery模式 adb reboot recovery稍等一会界面会提示 Now send the package you want to apply to the device with "adb sidelaod <…...

双向选择排序算法
一 概述 双向选择排序(又称鸡尾酒选择排序)是选择排序的优化版本,核心改进在于每轮遍历同时确定未排序部分的最小值和最大值,分别交换到序列两端,从而减少遍历轮数。 二 时间复杂度 时间复杂度为(O(n^2)),但实际比较次数约为标准选择排序的 (1/2)。 三 C++实现代…...

Node.js setImmediate 教程
Node.js setImmediate 教程 简介 setImmediate() 是 Node.js 环境中的一个函数,用于安排一个回调函数在当前事件循环周期结束后立即执行。它提供了一种在当前操作完成后,但在任何 I/O 事件或定时器触发之前执行代码的方法。 基本用法 setImmediate((…...

MyBatis @Param 注解详解:多参数传递与正确使用方式
Param 注解主要用于 MyBatis 进行参数传递时给 SQL 语句中的参数 起别名,通常用于 多参数 方法,使参数在 XML Mapper 文件或注解 SQL 语句中更清晰易用。 1. 基本用法 在 Mapper 接口中使用 Param 来为参数命名,避免 MyBatis 解析时出现参数…...

Spring实战spring-ai运行
目录 1. 配置 2 .搭建项目 3. 查看对应依赖 3.1 OpenAI 依赖 3.2 配置 OpenAI API 密钥 application.properties application.yml 4. openai实战 5. 运行和测试 6. 高级配置 示例:配置模型和参数 解释: 7. 处理异常和错误 示例:…...
)
STL:C++的超级工具箱(一)
书接上回,内存管理和指针:C的双刃手术刀(一)-CSDN博客,在上篇我们聊到了什么是内存,堆栈,内存管理和智能指针相关的内容,接下来让我们一起去看看STL是什么吧。 第一步:提…...

leetcode349 两个数组的交集
求两个数组的交集,直白点儿就是【nums2 的元素是否在 nums1 中】。 在一堆数中查找一个数,当然是扔出哈希。碰到这种对目前来说是未知数值大小的情况,我们可以使用集合 set 来解决。 使用数组来做哈希的题目,是因为题目都限制了数…...

开源智能体技术解析:从LangChain到自主抓取,构建自动化工作流
1. 项目概述:从“Awesome”列表看开源智能体生态的演进 最近在梳理一些前沿的自动化工具链时,又翻到了 mergisi/awesome-openclaw-agents 这个仓库。对于长期关注AI Agent(智能体)和自动化工作流开发的同行来说,这类…...

3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南
3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否在使用Windows 11 24H2 LT…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南
5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否遇到过这样的困扰?精心编写的A…...
)
【稀缺首发】Midjourney达达主义风格提示工程白皮书:含89组对比实验数据+12个独家种子编号(限前500名下载)
更多请点击: https://intelliparadigm.com 第一章:达达主义在AI图像生成中的哲学解构 达达主义并非技术流派,而是一场对逻辑、秩序与意义权威的激进质疑——这一精神正悄然渗透至当代AI图像生成的核心机制中。当Stable Diffusion接收“一只会…...

NCM格式转换实战指南:ncmdumpGUI全面解析
NCM格式转换实战指南:ncmdumpGUI全面解析 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾为网易云音乐下载的NCM格式音乐无法在其他设备播…...
)
设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测)
更多请点击: https://intelliparadigm.com 第一章:设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测) Midjourney v6.1…...

基于意图与技能解耦的智能对话系统构建指南
1. 项目概述:一个意图与技能驱动的AI对话引擎最近在折腾AI应用开发,特别是对话型AI助手时,发现一个核心痛点:如何让AI不仅能理解用户说了什么(意图识别),还能精准地调用相应的功能(技…...

Midjourney像素艺术提示词工程:98%新手忽略的4个隐藏权重指令,实测提升风格还原度320%
更多请点击: https://intelliparadigm.com 第一章:Midjourney像素艺术提示词工程的底层逻辑重构 像素艺术在 Midjourney 中并非天然适配的生成模态,其高精度、低分辨率、强风格约束的特性与扩散模型默认的连续性渲染范式存在根本张力。要实现…...

Apache Burr框架:构建可观测有状态数据应用的核心原理与实践
1. 项目概述:一个用于构建和评估数据产品的Python框架如果你正在处理数据密集型应用,比如推荐系统、个性化广告或者任何需要根据用户行为实时调整策略的场景,你肯定遇到过这样的困境:模型训练和离线评估做得再好,一旦上…...