STL:C++的超级工具箱(一)
书接上回,内存管理和指针:C++的双刃手术刀(一)-CSDN博客,在上篇我们聊到了什么是内存,堆栈,内存管理和智能指针相关的内容,接下来让我们一起去看看STL是什么吧。
第一步:提问
STL 是什么?
想象一下:你有一个万能工具箱,里面装满了各种现成的工具(锤子、螺丝刀、扳手…),这些工具能帮你快速完成特定任务。
STL 就是这样的工具箱,但它针对的是 “数据结构”和“算法”。
- 数据结构:比如动态数组 (
vector)、哈希表 (unordered_map)、链表 (list) 等,用来存储和组织数据。 - 算法:比如排序 (
sort)、查找 (find)、合并 (merge) 等,用来操作数据。
STL 的核心价值:不用自己造轮子,直接调用这些工具就能写出高效代码!
STL 最常用的四个模块是:
| 组件 | 作用 | 类似现实中的什么? |
|---|---|---|
| 容器 | 存储数据的容器(如 vector) | 书包、书架、快递箱 |
| 算法 | 操作容器数据的工具(如 sort) | 计算器、清洁工、厨师 |
| 迭代器 | 在容器中“移动”的指针 | 手指、遥控器、游戏手柄 |
| 仿函数 | 行为像函数的类或对象 | 自定义规则的小助手 |
STL的数据结构(容器),容器是数据存储的核心
1. 序列式容器(数据的“线性仓库”)
| 容器 | 关键特点 | 适合场景 | 代码示例 |
|---|---|---|---|
vector | 动态数组,支持快速随机访问 | 需要频繁随机读写的场景 | std::vector<int> v = {1,2,3}; |
list | 双向链表,插入删除快 | 频繁中间插入/删除的场景 | std::list<int> l; l.push_back(4); |
deque | 双端队列,两端操作高效 | 队列或栈的扩展场景 | std::deque<int> dq; dq.push_front(5); |
std::vector——动态数组
动态数组是什么?我们来看一个对比:
静态数组 vs 动态数组:
-
静态数组:大小固定,内存一次性分配(比如
int arr[5])。- 缺点:装不下更多东西,也不能随便改变大小。
// 静态数组越界会崩溃! int arr[3] = {1,2,3}; arr[4] = 4; // 未定义行为!
- 缺点:装不下更多东西,也不能随便改变大小。
-
动态数组:大小可变,运行时动态分配内存(比如
std::vector)。- 优点:像“伸缩的乐高盒子”,能根据需求自动调整大小。
动态数组的核心原理
1. 内存管理
动态数组本质是一块连续的内存空间,但会 预留额外空间(capacity)以应对未来的增长。
-
类比:租了一个可扩建的仓库,初始容量小,但可以不断扩建。
std::vector<int> v; // 空仓库,容量为0 v.push_back(1); // 扩建仓库,容量变为1 v.push_back(2); // 可能再次扩建(容量翻倍)
2. 关键操作
| 操作 | 作用 | 时间复杂度 |
|---|---|---|
|
| 在末尾添加元素 | 平均 O(1) |
|
| 删除末尾元素 | O(1) |
|
| 强制调整大小 | O(n)(可能移动元素) |
|
| 预留内存空间 | O(1) |
为什么
push_back()是均摊 O(1)`?
-
像“分期扩建仓库”:每次扩容时容量翻倍,摊薄到每次操作的代价为 O(1)。
-
例如:连续插入 8 次元素,可能只扩建 3 次(1→2→4→8)。
-
既然动态数组可以自己扩充,为啥还有
reserve()呢?
reserve() 是做什么?
核心功能:
提前为动态数组(如 std::vector)预留内存空间,避免后续插入元素时频繁重新分配内存和复制数据。
类比:
假设你要开一个 “可容纳100人的会议室”,但一开始只有10人参会。如果你提前预订好100人的场地:
-
优点:后续有人加入时,无需再换场地(省时间)。
-
缺点:如果最终只有50人,可能浪费空间。
reserve(100) 就是类似“提前预订100人场地”。
为什么需要 reserve()?
1. 性能优化
-
没有
reserve()的情况:
每次push_back()导致容量不足时,会重新分配更大的内存,并将原有数据复制到新内存。
代价:频繁的内存分配和数据复制(尤其大数据量时非常耗时)。 -
有
reserve()的情况:
提前分配足够内存,后续插入只需在预留空间内操作,避免重新分配和复制。
示例:插入100万整数
std::vector<int> v;// 方式1:不使用 reserve()
for (int i = 0; i < 1e6; ++i) {v.push_back(i); // 可能多次扩容(如1→2→4→8...→足够大)
}// 方式2:使用 reserve()
v.reserve(1e6);
for (int i = 0; i < 1e6; ++i) {v.push_back(i); // 仅分配一次内存
}2. 控制内存占用
-
自动扩容策略:
vector的默认扩容方式是 容量翻倍(如从1→2→4→8...)。
如果最终只需要100元素,但初始容量为1,会导致多次扩容,最终容量可能是128(超过需求)。 -
使用
reserve():直接分配所需容量(如100),避免浪费内存。
reserve() 的关键细节
| 方法 | 作用 | 是否改变元素个数? |
|---|---|---|
|
| 预留至少 | 否(只影响容量) |
|
| 调整元素个数到 | 是 |
示例:
std::vector<int> v;
v.reserve(10); // 容量变为10,元素个数仍为0
v.push_back(1); // 元素个数变为1,容量仍足够
v.resize(5); // 元素个数变为5,未超出容量,无需改动实际场景:为什么要用 reserve()?
场景1:读取大规模数据
从文件或网络读取大量数据时,若不提前 reserve(),可能导致:
-
频繁内存重新分配:程序卡顿甚至崩溃(尤其在数据量极大时)。
-
内存浪费:自动扩容后的容量远超实际需求。
解决方案:
std::vector<int> data;
data.reserve(1000000); // 提前预留100万空间
// 读取数据并 push_back...场景2:性能敏感型应用
游戏开发、实时系统等对时间要求高的场景,reserve() 可显著减少运行时开销。
reserve() 的使用原则
-
当你知道最终数据量(或上限)时:提前
reserve()以优化性能。 -
当你需要避免内存浪费时:如果最终数据量远小于默认扩容后的容量,手动
reserve()可节省内存。 -
不需要时不要用:如果数据量不确定,或小规模操作,
reserve()可能反而增加初始化开销。
动态数组 vs 静态数组
| 特性 | 动态数组( | 静态数组 |
|---|---|---|
| 大小可变 | 支持运行时调整(自动扩容) | 大小固定(编译期确定) |
| 内存分配 | 连续内存,但可能多次重新分配 | 单次分配,连续内存 |
| 访问速度 | 支持随机访问(O(1)) | 支持随机访问(O(1)) |
| 中间插入/删除 | O(n) 时间复杂度(需移动元素) | 不允许(越界错误) |
关键区别:
-
动态数组通过 “预留空间” 和 “惰性扩容” 平衡性能与灵活性。
-
静态数组像“固定尺寸的盒子”,适合已知大小的数据。
std::list——双向链表
什么是双向链表?
核心概念:
双向链表是一种 线性数据结构,每个节点包含 值 和 两个指针(分别指向“前一个节点”和“后一个节点”)。
- 类比:想象一列火车,每节车厢(节点)既能看到前面的车厢(前驱指针),也能看到后面的车厢(后继指针)
为了更好理解,我们先来看看链表是什么?
链表是一种 线性数据结构,由若干“节点”(Node)通过“指针”(Pointer)串联而成,每个节点存储 值 和 下一个节点的位置。
- 类比:想象一条由珍珠串成的项链,每颗珍珠(节点)上刻有信息(值),并通过绳结(指针)连接到下一颗珍珠。
双向链表的结构:
- 特点:节点包含 前驱指针(
prev)和 后继指针(next),支持双向遍历。 - 结构:
struct Node {int value;Node* prev;Node* next;Node(int val) : value(val), prev(nullptr), next(nullptr) {} }; - 类比:一条双向的马路,可自由来往。
示意图:
A <-> B <-> C <-> D双向链表的关键特性
| 属性 | 说明 |
|---|---|
| 节点结构 | 每个节点包含 value、prev(前驱指针)、next(后继指针)。 |
| 插入/删除 | 支持在任意位置快速插入/删除节点(只需调整相邻节点的指针)。 |
| 遍历方向 | 可从前向后或从后向前遍历。 |
| 内存分配 | 节点分散在内存中,非连续存储。 |
C++ STL 中的链表
STL 提供了 std::list(基于双向链表),简化了链表操作:
- 核心方法:
std::list<int> lst; lst.push_back(1); // 添加元素到末尾 lst.insert(lst.begin(), 2); // 在开头插入元素 auto it = lst.find(3); // 查找元素 if (it != lst.end()) {lst.erase(it); // 删除元素 } - 遍历方式:
for (auto num : lst) { // 范围for循环std::cout << num << " "; }
std::list 的为什么好用?
1. 对内存的零碎兼容性
-
适用场景:内存碎片化严重时(如嵌入式系统),链表能高效利用零散内存。
2. 高效的中间操作(目前看这个就够了)
-
插入/删除示例:
std::list<int> scores = {10, 20, 30, 40}; // 在 20 和 30 之间插入 25 auto it = scores.find(20); scores.insert(it, 25); // 结果:[10, 20, 25, 30, 40] // 删除 30 it = scores.find(30); scores.erase(it); // 结果:[10, 20, 25, 40]
3. 并发友好
-
双向链表支持:在多线程环境下,修改链表时只需锁定部分节点,而非整个容器。
std::list 的实际应用场景
-
动态队列/栈:
std::list<int> queue;//用list 去实现队列,FIFO queue.push_back(1); queue.push_back(2); std::cout << queue.front() << std::endl; // 输出 1 queue.pop_front(); // 队列变为 [2] -
LRU 缓存:
当缓存满时,删除最久未使用的元素(需双向遍历和快速删除)。std::list<std::pair<int, std::string>> cache; cache.push_back({1, "Data1"}); cache.push_back({2, "Data2"}); // 删除末尾元素(LRU 策略) cache.pop_back(); -
多级分类菜单:
如电商网站的商品分类导航(父类和子类双向关联)。
std::list 的常见坑点
1. 不能随机访问
-
错误用法:
std::list<int> lst = {1, 2, 3}; std::cout << lst[2]; // 编译错误!list 不支持随机访问 -
正确做法:
auto it = lst.begin(); std::advance(it, 2); // 移动到第三个元素 std::cout << *it << std::endl; // 输出 3
2. 内存泄漏风险
-
手动管理节点时(如 C 风格链表)需释放内存,但
std::list会自动管理节点生命周期。
std::list 的核心思想是:
-
用双向链表实现动态数据的高效操作,牺牲随机访问性能换取插入/删除的灵活性。
-
适用场景:需要频繁修改元素顺序或大小,但对随机访问要求不高的场景。
现在试着用你自己的话解释:
-
如果有一个需要频繁在中间插入和删除元素的列表,你会选
std::vector还是std::list?为什么? -
std::list的双向遍历能力在实际开发中有哪些具体用途?
std::deque——双端队列
什么是双端队列?
核心定义:
双端队列(Deque,Double-Ended Queue)是一种 线性数据结构,允许在 两端(头部和尾部)进行 高效的插入和删除操作,同时支持 随机访问。
类比:
想象一个 两端都能打开的购物车,你可以:
-
从前面装商品(
push_front), -
从后面装商品(
push_back), -
从前面取商品(
pop_front), -
从后面取商品(
pop_back), -
还能直接查看中间某个位置的物品(随机访问)。
std::deque 的核心特性
1. 双端高效操作
-
插入/删除:在头部或尾部插入、删除元素的时间复杂度均为 O(1)。
-
随机访问:通过索引直接访问元素的时间复杂度为 O(1)(类似数组)。
2. 内存连续性
-
数据存储在 连续的内存块 中,像一块完整的“内存蛋糕”。
-
优点:CPU 缓存友好,访问速度极快。
3. 动态大小
-
支持运行时动态调整大小,无需提前分配固定容量。
std::deque vs std::vector vs std::list
| 特性 |
|
|
|
|---|---|---|---|
| 头部/尾部操作 | O(1) 时间复杂度 |
| 双向链表,任意位置 O(1) |
| 随机访问 | 支持 O(1) | 支持 O(1) | 不支持(O(n)) |
| 内存分配 | 连续内存块 | 连续内存块 | 分散内存块 |
| 适用场景 | 需要两端操作且随机访问的场景 | 需要尾部操作和随机访问的场景 | 需要任意位置插入/删除的场景 |
std::deque 的底层实现
1. 内存布局
-
由多个 固定大小的块(Block)组成,每个块存储一定数量的元素。
-
优点:支持高效的头部和尾部操作,无需移动整个数组。
示意图:
[Block1] <-> [Block2] <-> ... <-> [BlockN]2. 关键操作
std::deque<int> dq;// 插入元素到两端
dq.push_front(1); // [1]
dq.push_back(2); // [1, 2]// 删除元素
dq.pop_front(); // []
dq.pop_back(); // []// 访问元素
std::cout << dq.front() << std::endl; // 1 (头部)
std::cout << dq.back() << std::endl; // 2 (尾部)
std::cout << dq[0] << std::endl; // 直接索引访问std::deque 的实际应用场景
1. 滑动窗口最大值
-
维护一个固定大小的窗口,快速获取当前窗口的最大值。
#include <iostream> #include <deque> #include <vector>int main() {const int k = 3; // 定义窗口大小std::vector<int> nums = {2, 1, 5, 6, 2, 3};std::deque<int> dq; // 存储元素索引// 错误处理:验证窗口大小有效性if (k <= 0 || k > nums.size()) {std::cerr << "Invalid window size!" << std::endl;return 1;}for (int i = 0; i < nums.size(); ++i) {// 维护单调递减队列while (!dq.empty() && nums[dq.back()] <= nums[i])dq.pop_back();dq.push_back(i);// 移除超出窗口范围的元素while (dq.front() <= i - k)dq.pop_front();// 当窗口形成时输出当前窗口最大值if (i >= k - 1) {std::cout << "Window [" << (i - k + 1) << "-" << i << "] Max: " << nums[dq.front()] << std::endl;}}return 0; }
2. BFS 队列的优化
-
用
deque实现广度优先搜索(BFS),支持快速队首插入和队尾删除。#include <iostream> #include <deque> #include <limits>struct Node {int value; };void bfs() {std::deque<Node> q;if (q.max_size() == 0) {std::cerr << "队列无法分配内存" << std::endl;return;}q.push_back({1});int max_value = 10; // 假设我们希望在节点值达到10时停止遍历while (!q.empty() && q.front().value <= max_value) {Node node = q.front();q.pop_front();// 处理节点,这里简单地输出节点的值std::cout << "处理节点值: " << node.value << std::endl;if (node.value + 1 > max_value) {break; // 如果下一个节点的值会超过最大值,则提前停止}if (q.max_size() == q.size()) {std::cerr << "队列已满,无法添加新节点" << std::endl;break;}q.push_back({node.value + 1});} }
std::deque 的注意事项
1. 不要过度使用 resize()
-
resize(n)会调整容器大小,可能导致数据移动或重新分配内存。 -
替代方案:用
reserve()预留足够空间。
2. 中间插入/删除效率低
-
虽然
std::deque支持随机访问,但中间插入/删除的时间复杂度为 O(n)(需移动元素)。 -
适用场景:尽量避免在中间位置操作。
std::deque 的核心思想是:
-
用连续内存块模拟双端队列,平衡插入/删除效率和随机访问性能。
-
适用场景:需要频繁在两端操作数据,且需要快速访问任意位置的场景(如滑动窗口、消息队列)。
现在试着用你自己的话解释:
-
如果有一个需要频繁在头部和尾部添加/删除元素的列表,你会选
std::deque还是std::list?为什么? -
std::deque的随机访问特性在实际开发中有哪些具体用途?
2. 关联式容器(键值对存储)
关联容器(Associative Containers)是 STL 中用于 按关键字(Key)高效存储和检索数据 的容器,核心特点是 元素自动排序或哈希化(取决于具体容器)。
- 类比:想象一本电话簿,每个人的姓名是“关键字”(Key),电话号码是“值”(Value),你可以快速通过姓名查找号码。
关联容器的分类
1. 有序关联容器(基于红黑树)
| 容器 | 特点 | 底层实现 | 时间复杂度(操作) |
|---|---|---|---|
std::set | 唯一键,按键排序 | 红黑树(自平衡二叉搜索树) | O(log n) |
std::map | 键值对,按键排序 | 红黑树 | O(log n) |
std::multiset | 允许重复键,按键排序 | 红黑树 | O(log n) |
std::multimap | 允许重复键的键值对,按键排序 | 红黑树 | O(log n) |
2.有序容器详解:std::set 和 std::map
1. std::set(唯一键集合)
- 核心用途:存储唯一元素,自动排序。
- 代码示例(核心代码,非完整示例,下同):
#include <set> std::set<int> scores = {90, 85, 95}; // 自动排序为 {85, 90, 95} scores.insert(88); // 插入新元素 → {85, 88, 90, 95} if (scores.find(90) != scores.end()) // 查找元素std::cout << "Found!" << std::endl;
2. std::map(键值对映射)
- 核心用途:按键存储键值对,键唯一且排序。
- 代码示例:
#include <map> std::map<std::string, int> student_scores; student_scores["Alice"] = 95; // 插入键值对 student_scores["Bob"] = 88; for (const auto& pair : student_scores) // 遍历(按键升序)std::cout << pair.first << ": " << pair.second << std::endl;
2. 无序关联容器(基于哈希表)
| 容器 | 特点 | 底层实现 | 时间复杂度(平均) |
|---|---|---|---|
std::unordered_set | 唯一键,无序存储 | 哈希表 | O(1) |
std::unordered_map | 键值对,无序存储 | 哈希表 | O(1) |
std::unordered_multiset | 允许重复键,无序存储 | 哈希表 | O(1) |
std::unordered_multimap | 允许重复键的键值对,无序存储 | 哈希表 | O(1) |
2.无序容器详解:std::unordered_set 和 std::unordered_map
1. std::unordered_set(唯一键哈希集合)
- 核心用途:快速查找唯一元素,不关心顺序。
- 代码示例:
#include <unordered_set> std::unordered_set<std::string> usernames; usernames.insert("Alice"); // 插入元素 if (usernames.contains("Bob")) // C++20 语法检查是否存在std::cout << "User exists!" << std::endl;
2. std::unordered_map(键值对哈希表)
- 核心用途:快速键值对查找,无需排序。
- 代码示例:
#include <unordered_map> std::unordered_map<int, std::string> id_to_name; id_to_name[1] = "Alice"; // 插入键值对 id_to_name[2] = "Bob"; std::cout << id_to_name[1] << std::endl; // 输出 Alice
注意:
现在试着回答:
set和map允许元素唯一,而unordered_*不保证唯一性(需要自己处理冲突)。unordered_*在数据量大时性能更优,但哈希冲突可能导致最坏 O(n) 时间复杂度。关联容器的核心思想是:
- 有序容器:用红黑树保证有序性和高效的范围查询,适合需要排序的场景。
- 无序容器:用哈希表实现快速查找,适合对顺序不敏感的高性能需求。
- 选择依据:是否需要排序、是否允许重复键、是否需要范围查询。
- 如果需要一个允许重复键且有序的容器,应该选哪个?
- 为什么
std::unordered_map的查找速度平均是 O(1)?
好了。今天就到这里,再见喽。
相关文章:
)
STL:C++的超级工具箱(一)
书接上回,内存管理和指针:C的双刃手术刀(一)-CSDN博客,在上篇我们聊到了什么是内存,堆栈,内存管理和智能指针相关的内容,接下来让我们一起去看看STL是什么吧。 第一步:提…...

leetcode349 两个数组的交集
求两个数组的交集,直白点儿就是【nums2 的元素是否在 nums1 中】。 在一堆数中查找一个数,当然是扔出哈希。碰到这种对目前来说是未知数值大小的情况,我们可以使用集合 set 来解决。 使用数组来做哈希的题目,是因为题目都限制了数…...

快速生成viso流程图图片形式
我们在写详细设计文档的过程中总会不可避免的涉及到时序图或者流程图的绘制,viso这个软件大部分技术人员都会使用,但是想要画的好看,画的科学还是比较难的,现在我总结一套比较好的方法可以生成好看科学的viso图(图片格式)。主要思…...

鸿蒙Android4个脚有脚线
效果 min:number122max:number150Row(){Stack(){// 底Text().border({width:2,color:$r(app.color.yellow)}).height(this.max).aspectRatio(1)// 长Text().backgroundColor($r(app.color.white)).height(this.max).width(this.min)// 宽Text().backgroundColor($r(app.color.w…...

【NetTopologySuite类库】geojson和shp互转,和自定义对象互转
geojson介绍 1. 示例 在visual studio中使用NuGet中安装了三个库(.net4.7.2环境): NetTopologySuite 2.5NetTopologySuite.IO.Esri.Shapefile 1.2NetTopologySuite.IO.GeoJSON 4.0 1.1 shp数据转geojson 先创建一个shp文件作为例子&…...

【哇! C++】类和对象(三) - 构造函数和析构函数
目录 一、构造函数 1.1 构造函数的引入 1.2 构造函数的定义和语法 1.2.1 无参构造函数: 1.2.2 带参构造函数 1.3 构造函数的特性 1.4 默认构造函数 二、析构函数 2.1 析构函数的概念 2.2 特性 如果一个类中什么成员都没有,简称为空类。 空类中…...

Ubuntu20.04本地配置IsaacLab 4.2.0的G1训练环境(一)
Ubuntu20.04本地配置IsaacLab的G1训练环境(一) 配置Omniverse环境配置IsaacSim配置IsaacLab 写在前面,如果Ubuntu剩余空间低于60G,则空间不足,除非你不需要资产包。但资产包中却包含了G1模型、Go2模型等机器人模型和代…...

浅谈汽车系统电压优缺点分析
汽车电气系统的电压等级选择直接影响整车性能、能效和兼容性。以下是 12V、24V、48V 系统的简单介绍,包括技术特点、优缺点及典型应用场景。 汽车电气系统的发展随着车辆电子设备的增多和对能效要求的提高,电压等级也在逐步提升,从传统的12V…...

Springboot基础篇(4):自动配置原理
1 自动配置原理剖析 1.1 加载配置类的源码追溯 自动配置的触发入口: SpringBootApplication 组合注解是自动配置的起点,其核心包含 EnableAutoConfiguration,该注解使用AutoConfigurationImportSelector 实现配置类的动态加载。 启动类的注…...
)
Dify 开源大语言模型应用开发平台使用(一)
文章目录 一、创建锂电池专业知识解答应用1.1 应用初始化二、核心功能模块详解2.1 知识库构建2.2 工作流与节点编排节点类型说明工作流设计示例:锂电池选型咨询2.3 变量管理三、测试与调试3.1 单元测试3.2 压力测试3.3 安全验证四、部署与优化建议4.1 部署配置4.2 持续优化结论…...

机器学习深度学习基本概念:logistic regression和softmax
逻辑回归用来处理二分类问题 softmax用来处理多分类问题:比如llm在generate的时候,每个batch里面的一个样本的一个一次generate就是softmax生成一个大小为vocab_size的向量的概率分布,然后再采样 逻辑回归(logistic regression&…...

OpenCV计算摄影学(16)调整图像光照效果函数illuminationChange()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 对选定区域内的梯度场应用适当的非线性变换,然后通过泊松求解器重新积分,可以局部修改图像的表观照明。 cv::illuminati…...

Git - 补充工作中常用的一些命令
Git - 补充工作中常用的一些命令 1 一些场景1.1 场景11.2 场景21.3 场景31.4 场景41.5 场景51.6 场景61.7 场景71.8 场景81.9 场景91.10 场景101.11 场景111.12 场景121.13 场景131.14 场景141.15 场景15 2 git cherry-pick \<commit-hash\> 和 git checkout branch \-\-…...

使用Python的requests库调用API并处理JSON响应的详细步骤
1. 安装request库 pip install requests 2. 发送GET请求 import requests# 定义API地址 url "https://api.example.com/data"# 发送GET请求 response requests.get(url)# 检查HTTP状态码 if response.status_code 200:# 解析JSON响应data response.json()prin…...
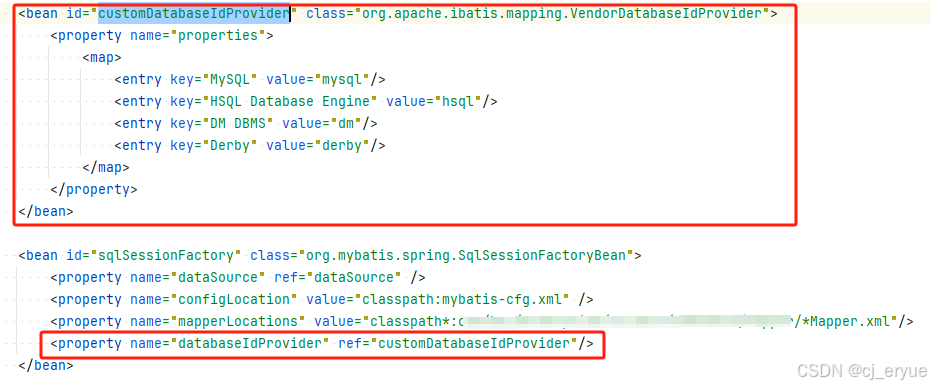
Mybatis如何通过databaseId属性支持不同数据库的不同语法
目录 一、前言 二、如何配置 三、源码解读 四、自定义 一、前言 在一次项目功能测试中,发现有个sql在其他嵌入式数据库中执行正常,但是在mysql中执行失败,发现是因为有个字段在mysql中是关键字,需要使用反引号(&…...

android edittext 防止输入多个小数点或负号
有些英文系统的输入法,或者定制输入法。使用xml限制不了输入多个小数点和多个负号。所以代码来控制。 一、通过XML设置限制 <EditTextandroid:id="@+id/editTextNumber"android:layout_width="wrap_content"android:layout_height="wrap_conten…...

windows部署spleeter 版本2.4.0:分离音频的人声和背景音乐
windows部署spleeter 版本2.4.0:分离音频的人声和背景音乐 一、Spleeter 是什么? Spleeter 是由法国音乐流媒体公司 Deezer 开发并开源的一款基于深度学习的音频分离工具。它能够将音乐中的不同音轨(如人声、鼓、贝斯、钢琴等)分…...
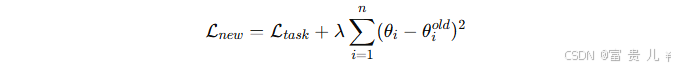
深度学习、宽度学习、持续学习与终身学习:全面解析与其在大模型方面的应用
目录 引言: 1. 深度学习(Deep Learning) 1.1 深度学习的基本概念 1.2 深度学习的数学原理 1.3 深度学习的特点 1.4 深度学习在大模型中的应用 2. 宽度学习(Wide Learning) 2.1 宽度学习的基本概念 2.2宽度学习…...

【量化科普】Arbitrage,套利
【量化科普】Arbitrage,套利 🚀量化软件开通 🚀量化实战教程 什么是套利? 套利(Arbitrage)是金融市场中的一种交易策略,指的是在不同市场或不同形式中同时买入和卖出相同或相似的金融产品&a…...

删除已加入 .gitignore却仍被git追踪的文件
.gitignore 文件只会影响未被跟踪的文件,而已经被 Git 跟踪的文件不会因为被添加到 .gitignore 而停止被跟踪。 eg:例如在创建.gitignore文件前,已经将sync.sh文件推送到远程分支,因此该文件已被git追踪。 去掉sync.sh文件追踪的步…...

Purpur性能调优实战指南:7大核心优化方案深度解析
Purpur性能调优实战指南:7大核心优化方案深度解析 【免费下载链接】Purpur Purpur is a drop-in replacement for Paper servers designed for configurability, and new fun and exciting gameplay features. 项目地址: https://gitcode.com/gh_mirrors/pu/Purpu…...

AI驱动博客平台CodeBlog-app:开发者技术分享的智能解决方案
1. 项目概述:一个为开发者而生的AI驱动博客平台最近在GitHub上看到一个挺有意思的开源项目,叫CodeBlog-ai/codeblog-app。光看名字,你可能会觉得这又是一个普通的博客系统,或者是一个AI写作工具。但当我深入去研究它的代码和设计理…...

ARMv8-AArch64 异常处理实战:从寄存器解析到调试技巧
1. ARMv8-AArch64异常处理入门指南 第一次接触ARMv8架构的异常处理时,我被那一堆寄存器搞得头晕眼花。ELR、ESR、FAR...这些缩写看起来就像天书一样。但经过几个实际项目的磨练后,我发现只要掌握几个关键点,异常处理其实并没有想象中那么难。…...

Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧
Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧 在高速PCB设计领域,Allegro 16.6作为行业标杆工具,其深度功能往往决定了设计效率的天花板。当面对BGA封装密度突破1000pin、信号速率迈入10Gbps时代的复杂主板时&#x…...

前端工程化实战:基于 Kelivo 模板的配置即代码与自动化工作流
1. 项目概述与核心价值最近在整理个人开发环境时,发现一个挺有意思的项目,叫Chevey339/kelivo。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它是一个围绕特定开发工具或框架进行深度定制、优化和功能增…...

如何免费高效优化电脑性能:UXTU终极调优指南
如何免费高效优化电脑性能:UXTU终极调优指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility Universal x86 Tuning…...

UVa 366 Cutting Up
题目描述 拼布者经常需要将布料切割成 111 \times 111 的小正方形。他们有一种特殊工具(旋转切割刀),可以一次切割多层布料,切割层数的上限由布料类型决定(题目输入的第一个参数 KKK)。切割时,无…...

Git Worktree CLI工具:告别分支切换焦虑,实现高效并行开发
1. 项目概述与核心价值如果你和我一样,长期在多个Git分支间穿梭,同时维护着几个不同的功能特性或修复补丁,那你一定对那种在分支间反复切换、代码状态混乱、甚至不小心提交到错误分支的“切分支焦虑症”深有体会。传统的git checkout或git sw…...

基于Python与Playwright的招聘信息自动化聚合与智能筛选工具实践
1. 项目概述:一个面向求职者的自动化信息聚合与投递工具最近在和一些做开发的朋友聊天,发现大家普遍有个痛点:找工作太费时间了。每天要在几个招聘App之间来回切换,重复筛选岗位、刷新列表、投递简历,机械性的操作占据…...
)
告别3D-DNA的卡顿:用Chromap+Yahs快速搞定植物Hi-C辅助组装(附完整代码)
植物基因组Hi-C辅助组装新方案:ChromapYahs全流程解析 在植物基因组研究中,Hi-C技术已成为提升组装连续性的重要手段。然而传统3D-DNA流程在植物数据上的表现常令研究者头疼——运行速度缓慢、内存占用高,且对植物特有的重复序列处理效果欠佳…...