【大模型基础_毛玉仁】1.4 语言模型的采样方法
【大模型基础_毛玉仁】1.4 语言模型的采样方法
- 1.4 语言模型的采样方法
- 1.4.1 概率最大化方法
- 1)贪心搜索(GreedySearch)
- 2)波束搜索(BeamSearch)
- 1.4.2 随机采样方法
- 1)Top-K 采样
- 2)Top-P 采样
- 3)Temperature 机制
1.4 语言模型的采样方法
语言模型的输出为一个向量,该向量的每一维代表着词典中对应词的概率。自回归范式的文本生成任务中:
-
语言模型解码:将向量解码为文本的过程。
-
两类主流的解码方法:(1).概率最大化方法; (2). 随机采样方法。
1.4.1 概率最大化方法
设词典D为 { w 1 , w 2 , w 3 , . . . , w N } \{w_1,w_2,w_3,...,w_N\} {w1,w2,w3,...,wN},第i轮自回归中输出的向量为 o i = { o i [ w d ] } d = 1 ∣ D ∣ o_i = \{o_i[w_d]\}_{d=1}^{|D|} oi={oi[wd]}d=1∣D∣,M轮自回归后生成的文本为 { w N + 1 , w N + 2 , w N + 3 , . . . , w N + M } \{w_{N+1},w_{N+2},w_{N+3},...,w_{N+M}\} {wN+1,wN+2,wN+3,...,wN+M}。生成文档的出现的概率计算如下:
P ( w N + 1 : N + M ) = ∏ i = N N + M − 1 P ( w i + 1 ∣ w 1 : i ) = ∏ i = N N + M − 1 o i [ w i + 1 ] P(w_{N+1:N+M}) = \prod_{i=N}^{N+M-1} P(w_{i+1}|w_{1:i}) = \prod_{i=N}^{N+M-1} o_i[w_{i+1}] P(wN+1:N+M)=i=N∏N+M−1P(wi+1∣w1:i)=i=N∏N+M−1oi[wi+1]
基于概率最大化的解码方法旨在最大化 P ( w N + 1 : N + M ) P(w_{N+1:N+M}) P(wN+1:N+M),本节将介绍两种常用的基于概率最大化的解码方法。
1)贪心搜索(GreedySearch)
贪心搜索在在每轮预测中都选择概率最大的词,即:
w i + 1 = arg m a x w ∈ D o i [ w ] w_{i+1} = \arg max_{w \in D} o_i[w] wi+1=argmaxw∈Doi[w]
- argmax 用于找出使得后面的函数达到最大值的变量。在这里,它用于选择使得 o i [ w ] o_i[w] oi[w] 最大的w。
贪心搜索只顾“眼前利益”,忽略了“远期效益”。当前概率大的词有可能导致后续的词概率都很小。贪心搜索容易陷入局部最优,难以达到全局最优解。
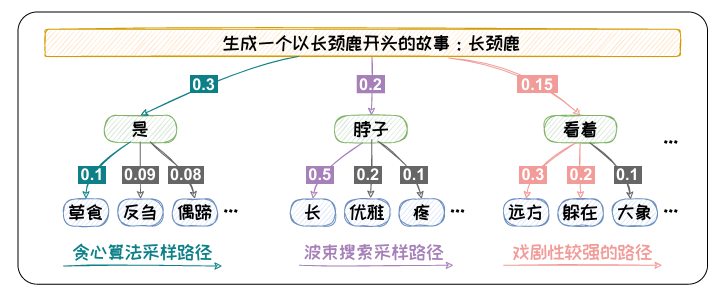
以图1.8为例,当输入为“生成一个以长颈鹿开头的故事:长颈鹿”时,预测第一个词为“是” 的概率最高,为0.3。但选定“是”之后,其他的词的概率都偏低。如果按照贪心 搜索的方式,我们最终得到的输出为“是草食”。其概率仅为0.03。而如果我们在 第一个词选择了概率第二的“脖子”,然后第二个词选到了“长”,最终的概率可 以达到0.1。
通过此例,可以看出贪心搜索在求解概率最大的时候容易陷入局部最 优。为缓解此问题,可以采用波束搜索(BeamSearch)方法进行解码。
图1.8: 贪心搜索与波束搜索对比以及概率最大化解码的潜在问题。
2)波束搜索(BeamSearch)
波束搜索在每轮预测中都先保留b个可能性最高的词 B i = { w i + 1 1 , w i + 1 2 , . . . , w i + 1 b } B_i = \{w_{i+1}^1, w_{i+1}^2, ..., w_{i+1}^b\} Bi={wi+11,wi+12,...,wi+1b}。
在结束搜索时,得到M个集合,即 { B i } i = 1 M \{B_i\}_{i=1}^M {Bi}i=1M。找出最优组合使得联合概率最大,即:
{ w N + 1 , . . . , w N + M } = arg m a x { w i ∈ B i for 1 ≤ i ≤ M } ∏ i = 1 M o N + i [ w i ] \{w_{N+1}, ..., w_{N+M}\} = \arg max_{\{w^i \in B_i \text{ for } 1 \leq i \leq M\}} \prod_{i=1}^M o_{N+i}[w^i] {wN+1,...,wN+M}=argmax{wi∈Bi for 1≤i≤M}i=1∏MoN+i[wi]
以图1.8为例,如果我们采用b=2的波束搜索方法,我们可以得到“是草食”,“是反刍”,“脖子长”,“脖子优雅”四个候选组合,对应的概率分别为:0.03,0.027,0.1,0.04。我们容易选择到概率最高的“脖子长”
但是,概率最大的文本通常是最为常见的文本。文本缺乏多样性。为了提升 生成文本的新颖度,我们可以在解码过程中加入一些随机元素。下节将对随机采样方法 进行介绍。
1.4.2 随机采样方法
为了增加生成文本的多样性,随机采样的方法在预测时增加了随机性。在每轮预测时,其先选出一组可能性高的候选词,然后按照其概率分布进行随机采样,采样出的词作为本轮的预测结果。
当前,主流的Top-K采样和Top-P采样方法分别通过指定候选词数量和划定候选词概率阈值的方法对候选词进行选择。在采样方法中加入Temperature 机制可以对候选词的概率分布进行调整。
1)Top-K 采样
Top-K采样:每轮预测都选K个概率最高的候选词,然后对这些词的概率用softmax函数进行归一化,得到分布函数:
p ( w i + 1 1 , … , w i + 1 K ) = { exp ( o i [ w i + 1 1 ] ) ∑ j = 1 K exp ( o i [ w i + 1 j ] ) , … , exp ( o i [ w i + 1 K ] ) ∑ j = 1 K exp ( o i [ w i + 1 j ] ) } p(w_{i+1}^1, \ldots, w_{i+1}^K) = \left\{ \frac{\exp(o_i[w_{i+1}^1])}{\sum_{j=1}^K \exp(o_i[w_{i+1}^j])}, \ldots, \frac{\exp(o_i[w_{i+1}^K])}{\sum_{j=1}^K \exp(o_i[w_{i+1}^j])} \right\} p(wi+11,…,wi+1K)={∑j=1Kexp(oi[wi+1j])exp(oi[wi+11]),…,∑j=1Kexp(oi[wi+1j])exp(oi[wi+1K])}
- e x p ( o i [ w i + 1 j ] ) exp(o_i[w_{i+1}^j]) exp(oi[wi+1j]):表示模型对候选词 w i + 1 j w_{i+1}^j wi+1j 的评分,通常是通过神经网络计算得到的。
然后根据该分布采样出本轮的预测的结果,即:
w i + 1 ∼ p ( w i + 1 1 , … , w i + 1 K ) w_{i+1} \sim p(w_{i+1}^1, \ldots, w_{i+1}^K) wi+1∼p(wi+11,…,wi+1K)
Top-K 采样可以有效的增加生成文本的新颖度。
两大致命缺陷:
-
当候选词的分布的方差较大时,可能会导致本轮预测选到概率较小、不符合常理的词,从而产生“胡言乱语”。
-
当候选词的分布的方差较小时,固定尺寸的候选集中无法容纳更多的具有相近概率的词,导致候选集不够丰富,从而导致所选词缺乏新颖性。
相较而言,Top-P(核采样)动态调整候选集大小,既能过滤低概率词避免荒谬输出,又能在分布平缓时纳入更多候选词,平衡合理性与多样性。
2)Top-P 采样
Top-P 采样的核心思想是:在每一步生成下一个词时,只从累积概率超过某个阈值 p 的最小单词集合中进行随机采样,而不考虑其他低概率的单词。
这种方法也被称为核采样(Nucleus Sampling),因为它只关注概率分布的核心部分,而忽略了尾部部分。
其设定阈值p来对候选集进行选取。其候选集可表示为 S p = { w i + 1 1 , w i + 1 2 , … , w i + 1 ∣ S p ∣ } S_p = \{w_{i+1}^1, w_{i+1}^2, \ldots, w_{i+1}^{|S_p|}\} Sp={wi+11,wi+12,…,wi+1∣Sp∣},其中,对 S p S_p Sp有, ∑ w ∈ S p o i [ w ] ≥ p \sum_{w \in S_p} o_i[w] \geq p ∑w∈Spoi[w]≥p。候选集中元素的分布服从:
p ( w i + 1 1 , … , w i + 1 ∣ S p ∣ ) = { exp ( o i [ w i + 1 1 ] ) ∑ j = 1 ∣ S p ∣ exp ( o i [ w i + 1 j ] ) , … , exp ( o i [ w i + 1 ∣ S p ∣ ] ) ∑ j = 1 ∣ S p ∣ exp ( o i [ w i + 1 j ] ) } p(w_{i+1}^1, \ldots, w_{i+1}^{|S_p|}) = \left\{ \frac{\exp(o_i[w_{i+1}^1])}{\sum_{j=1}^{|S_p|} \exp(o_i[w_{i+1}^j])}, \ldots, \frac{\exp(o_i[w_{i+1}^{|S_p|}])}{\sum_{j=1}^{|S_p|} \exp(o_i[w_{i+1}^j])} \right\} p(wi+11,…,wi+1∣Sp∣)={∑j=1∣Sp∣exp(oi[wi+1j])exp(oi[wi+11]),…,∑j=1∣Sp∣exp(oi[wi+1j])exp(oi[wi+1∣Sp∣])}
然后根据该分布采样出本轮的预测的结果,即:
w i + 1 ∼ p ( w i + 1 1 , … , w i + 1 ∣ S p ∣ ) w_{i+1} \sim p(w_{i+1}^1, \ldots, w_{i+1}^{|S_p|}) wi+1∼p(wi+11,…,wi+1∣Sp∣)
Top-P采样可以避免选到概率较小、不符合常理的词,从而减少“胡言乱语”
其还可以容纳更多的具有相近概率的词,增加文本的丰富度,改善“枯燥无趣”
3)Temperature 机制
Top-K 采样和 Top-P 采样的随机性由语言模型输出的概率决定,不可自由调整。引入Temperature 机制可以对解码随机性进行调节。
Temperature机制通过对Softmax 函数中的自变量进行尺度变换,然后利用Softmax函数的非线性实现对分布的控 制。设Temperature 尺度变换的变量为T。
引入Temperature 后,Top-K 采样的候选集的分布如下所示:
p ( w i + 1 1 , … , w i + 1 K ) = { exp ( o i [ w i + 1 1 ] T ) ∑ j = 1 K exp ( o i [ w i + 1 j ] T ) , … , exp ( o i [ w i + 1 K ] T ) ∑ j = 1 K exp ( o i [ w i + 1 j ] T ) } p(w_{i+1}^1, \ldots, w_{i+1}^K) = \left\{ \frac{\exp\left(\frac{o_i[w_{i+1}^1]}{T}\right)}{\sum_{j=1}^K \exp\left(\frac{o_i[w_{i+1}^j]}{T}\right)}, \ldots, \frac{\exp\left(\frac{o_i[w_{i+1}^K]}{T}\right)}{\sum_{j=1}^K \exp\left(\frac{o_i[w_{i+1}^j]}{T}\right)} \right\} p(wi+11,…,wi+1K)=⎩ ⎨ ⎧∑j=1Kexp(Toi[wi+1j])exp(Toi[wi+11]),…,∑j=1Kexp(Toi[wi+1j])exp(Toi[wi+1K])⎭ ⎬ ⎫
引入Temperature 后,Top-P 采样的候选集的分布如下所示:
p ( w i + 1 1 , … , w i + 1 ∣ S p ∣ ) = { exp ( o i [ w i + 1 1 ] T ) ∑ j = 1 ∣ S p ∣ exp ( o i [ w i + 1 j ] T ) , … , exp ( o i [ w i + 1 ∣ S p ∣ ] T ) ∑ j = 1 ∣ S p ∣ exp ( o i [ w i + 1 j ] T ) } p(w_{i+1}^1, \ldots, w_{i+1}^{|S_p|}) = \left\{ \frac{\exp\left(\frac{o_i[w_{i+1}^1]}{T}\right)}{\sum_{j=1}^{|S_p|} \exp\left(\frac{o_i[w_{i+1}^j]}{T}\right)}, \ldots, \frac{\exp\left(\frac{o_i[w_{i+1}^{|S_p|}]}{T}\right)}{\sum_{j=1}^{|S_p|} \exp\left(\frac{o_i[w_{i+1}^j]}{T}\right)} \right\} p(wi+11,…,wi+1∣Sp∣)=⎩ ⎨ ⎧∑j=1∣Sp∣exp(Toi[wi+1j])exp(Toi[wi+11]),…,∑j=1∣Sp∣exp(Toi[wi+1j])exp(Toi[wi+1∣Sp∣])⎭ ⎬ ⎫
容易看出:
-
当T >1时,Temperature机制会使得候选集中的词的概率差距减 小,分布变得更平坦,从而增加随机性。
-
当0<T<1时,Temperature机制会使得 候选集中的元素的概率差距加大,强者越强,弱者越弱,概率高的候选词会容易被 选到,从而随机性变弱。
Temperature机制可以有效的对随机性进行调节来满足不同的需求。
.
其他参考:【大模型基础_毛玉仁】系列文章
声明:资源可能存在第三方来源,若有侵权请联系删除!
相关文章:
【大模型基础_毛玉仁】1.4 语言模型的采样方法
【大模型基础_毛玉仁】1.4 语言模型的采样方法 1.4 语言模型的采样方法1.4.1 概率最大化方法1)贪心搜索(GreedySearch)2)波束搜索(BeamSearch) 1.4.2 随机采样方法1)Top-K 采样2)Top…...
[内网安全] Windows 本地认证 — NTLM 哈希和 LM 哈希
关注这个专栏的其他相关笔记:[内网安全] 内网渗透 - 学习手册-CSDN博客 0x01:SAM 文件 & Windows 本地认证流程 0x0101:SAM 文件简介 Windows 本地账户的登录密码是存储在系统本地的 SAM 文件中的,在登录 Windows 的时候&am…...

基于SNR估计的自适应码率LDPC编译码算法matlab性能仿真,对比固定码率LDPC的系统传输性能
目录 1.算法仿真效果 2.算法涉及理论知识概要 2.1 基于序列的SNR估计 2.2 基于SNR估计值进行码率切换 2.3 根据数据量进行码率切换 3.MATLAB核心程序 4.完整算法代码文件获得 1.算法仿真效果 matlab2022a仿真结果如下(完整代码运行后无水印)&…...

opencv 模板匹配方法汇总
在OpenCV中,模板匹配是一种在较大图像中查找特定模板图像位置的技术。OpenCV提供了多种模板匹配方法,通过cv2.matchTemplate函数实现,该函数支持的匹配方式主要有以下6种,下面详细介绍每种方法的原理、特点和适用场景。 1. cv2.T…...
Embedding技术:DeepWalkNode2vec
引言 在推荐系统中,Graph Embedding技术已经成为一种强大的工具,用于捕捉用户和物品之间的复杂关系。本文将介绍Graph Embedding的基本概念、原理及其在推荐系统中的应用。 什么是Graph Embedding? Graph Embedding是一种将图中的节点映射…...

微信小程序注册组件
在微信小程序中注册组件分为自定义组件的创建和全局/局部注册,下面为你详细介绍具体步骤和示例。 自定义组件的创建 自定义组件由四个文件组成,分别是 .js(脚本文件)、.json(配置文件)、.wxml(…...

【docker】安装mysql,修改端口号并重启,root改密
我的docker笔记 【centOS】安装docker环境,替换国内镜像 1. 配置镜像源 使用阿里云镜像加速器,编辑/etc/docker/daemon.json sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-EOF {"registry-mirrors": ["https:/…...

自定义wordpress三级导航菜单代码
首先,在你的主题functions.php文件中,添加以下代码以注册一个新的菜单位置: function mytheme_register_menus() {register_nav_menus(array(primary-menu > __(Primary Menu, mytheme))); } add_action(init, mytheme_register_menus); …...

洛谷 P1480 A/B Problem(高精度详解)c++
题目链接:P1480 A/B Problem - 洛谷 1.题目分析 1:说明这里是高精度除以低精度的形式,为什么不是高精度除以高精度的形式,是因为它很少见,它的模拟方式是用高精度减法来做的,并不能用小学列竖式的方法模拟…...

JAVA入门——网络编程简介
自己学习时的笔记,可能有点水( 以后可能还会补充(大概率不会) 一、基本概念 网络编程三要素: IP 设备在网络中的唯一标识 端口号 应用软件在设备中的唯一标识两个字节表示的整数,0~1023用于知名的网络…...

Ubuntu 合上屏幕 不待机 设置
有时候需要Ubuntu的机器合上屏幕的时候也能正常工作,而不是处于待机状态。 需要进行配置文件的设置,并重启即可。 1. 修改配置文件 /etc/systemd/logind.conf sudo vi /etc/systemd/logind.conf 然后输入i,进入插入状态,修改如…...

捣鼓180天,我写了一个相册小程序
🙋为什么要做土著相册这样一个产品? ➡️在高压工作之余,我喜欢浏览B站上的熊猫幼崽视频来放松心情。有天在家族群里看到了大嫂分享的侄女卖萌照片,同样感到非常解压。于是开始翻阅过去的聊天记录,却发现部分图片和视…...

短分享-Flink图构建
一、背景 通过简单的书写map、union、keyby等代码,Flink便能构建起一个庞大的分布式计算任务,Flink如何实现的这个酷炫功能呢?我们本次分享Flink做的第一步,将代码解析构建成图 源码基于Flink 2.10,书籍参考《Flink核…...

【监督学习】支持向量机步骤及matlab实现
支持向量机 (四)支持向量机1.算法步骤2. MATLAB 实现参考资料 (四)支持向量机 支持向量机(Support Vector Machine, SVM)是一种用于分类、回归分析以及异常检测的监督学习模型。SVM特别擅长处理高维空间的…...

机器学习-随机森林解析
目录 一、.随机森林的思想 二、随机森林构建步骤 1.自助采样 2.特征随机选择 3构建决策树 4.集成预测 三. 随机森林的关键优势 **(1) 减少过拟合** **(2) 高效并行化** **(3) 特征重要性评估** **(4) 耐抗噪声** 四. 随机森林的优缺点 优点 缺点 五.…...

Javaweb后端spring事务管理 事务四大特性ACID
2步操作,只能同时成功,同时失败,要放在一个事务中,最后提交事务或者回滚事务 事务控制 事务管理进阶 事务的注解 这是所有异常都会回滚 事务注解 事务的传播行为 四大特性...

在Spring Boot + MyBatis中优雅处理多表数据清洗:基于XML的配置化方案
问题背景 在实际业务中,我们常会遇到数据冗余问题。例如,一个公司表(sys_company)中存在多条相同公司名的记录,但只有一条有效(del_flag0),其余需要删除。删除前需将关联表…...

【无标题】四色拓扑模型与宇宙历史重构的猜想框架
### 四色拓扑模型与宇宙历史重构的猜想框架 --- #### **一、理论基础:四色拓扑与时空全息原理的融合** 1. **宇宙背景信息的拓扑编码** - **大尺度结构网络**:将星系团映射为四色顶点,纤维状暗物质结构作为边,构建宇宙尺度…...

[特殊字符] Django 常用命令
🚀 Django 常用命令大全:从开发到部署 Django 提供了许多实用的命令,可以用于 数据库管理、调试、测试、用户管理、运行服务器、部署 等。 本教程将详细介绍 Django 开发中最常用的命令,并提供 示例,帮助你更高…...

mysql中如何保证没有幻读发生
在 MySQL 中,幻读(Phantom Read)是指在一个事务中,两次相同的查询返回了不同的结果集,通常是由于其他事务插入或删除了符合查询条件的数据。为了保证没有幻读,MySQL 主要通过 事务隔离级别 和 锁机制 来实现…...

SimulinkVeriStandLabVIEW协同开发——从模型编译到交互式仪表盘部署
1. 工具链协同开发的核心价值 在电力电子和工业控制领域,快速原型开发往往需要跨越建模、实时测试和人机交互三个关键环节。Simulink、VeriStand和LabVIEW组成的工具链,就像汽车制造的流水线——Simulink是设计图纸的工程师,VeriStand是组装车…...

基于AI智能体的渗透测试框架:从自动化到智能协同的范式转变
1. 项目概述:一个面向渗透测试的智能体框架最近在整理自己的工具链时,发现了一个挺有意思的项目,叫GH05TCREW/pentestagent。乍一看这个名字,你可能会觉得这又是一个“缝合怪”式的自动化渗透工具,把Nmap、SQLmap之类的…...

从SD卡初始化到读写文件:一个完整嵌入式项目中的SDIO驱动避坑实践
从SD卡初始化到读写文件:嵌入式SDIO驱动实战全解析 在嵌入式系统开发中,SD卡因其高容量、低成本和便携性成为数据存储的首选方案。然而,看似简单的SD卡接口背后隐藏着复杂的初始化协议和时序要求。许多工程师在项目初期都会遇到SD卡无法识别、…...

符号链接批量管理工具 linko:声明式配置与自动化实践
1. 项目概述与核心价值最近在折腾一些自动化脚本和工具链,发现一个挺有意思的仓库:monsterxx03/linko。乍一看这个名字,你可能会有点懵,这到底是干嘛的?是链接管理工具,还是某种网络代理的客户端࿱…...

AI编程助手安全规则实战:从SQL注入防御到团队安全基线构建
1. 项目概述:当AI编程助手遇上安全红线最近在GitHub上看到一个挺有意思的项目,叫“cursor-security-rules”。光看名字,你大概能猜到它和Cursor这个AI编程工具有关,而且重点是“安全规则”。没错,这个项目本质上是一个…...
)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码) 科研图表的美观程度直接影响论文的第一印象,而三维柱状图在展示多维度数据时尤为常见。传统手动调整每个柱体的颜色、透明度、光照效果不仅耗时&#…...

Python Reddit数据采集与分析实战:从API调用到舆情监控
1. 项目概述与核心价值最近在开源社区里,一个名为openshrug/reddit-intel的项目引起了我的注意。乍一看,这像是一个针对 Reddit 平台的数据抓取或分析工具,但深入探究后,我发现它的定位远不止于此。它更像是一个为开发者、数据分析…...

Noto Emoji:专业解决跨平台表情符号渲染难题的终极方案
Noto Emoji:专业解决跨平台表情符号渲染难题的终极方案 【免费下载链接】noto-emoji Noto Emoji fonts 项目地址: https://gitcode.com/gh_mirrors/no/noto-emoji 在现代数字通信中,表情符号已成为不可或缺的语言元素,然而跨平台表情符…...

DIY智能电机推子:从闭环控制到MIDI交互的硬件实战
1. 项目概述与核心价值如果你玩过专业的音频混音台,或者在一些高端的灯光控制台上见过那种会自己“嗖”一下滑到指定位置的推子,那你一定对电机推子(Motorized Fader)不陌生。这东西的魅力在于,它既是精准的模拟输入设…...

OPAL:基于OPA的实时策略数据分发与权限治理实践
1. 项目概述:什么是OPAL,以及它解决了什么核心痛点?如果你在负责一个微服务架构或者分布式系统的权限管理,大概率遇到过这样的场景:每次权限策略有更新,都需要重启服务、重新部署,或者等待一个漫…...