Llama-Factory框架下的Meta-Llama-3-8B-Instruct模型微调
目录
引言
Llama - Factory 训练框架简介:
Meta - Llama - 3 - 8B - Instruct 模型概述:
Lora 方法原理及优势:
原理
优势
环境准备:
部署环境测试:
数据准备:
模型准备:
模型配置与训练:
微调效果展示与分析
模型导出:
基于sglang进行服务搭建:
服务测试:
总结:
参考链接:
引言
在自然语言处理领域,大语言模型不断演进,Meta 的 Llama 系列模型备受瞩目。其中 Meta - Llama - 3 - 8B - Instruct 模型具有 80 亿参数,在基础的语言理解和生成方面展现出了一定的能力。然而,为了使其更好地适应特定领域或任务,微调成为了关键步骤。Llama - Factory 作为一个强大的开源低代码大模型训练框架,集成了众多先进的微调方法和优化技术,为我们微调 Meta - Llama - 3 - 8B - Instruct 模型提供了便利。同时,Lora(Low - Rank Adaptation)方法因其在不改变预训练模型原始权重参数的情况下,通过引入小的可训练矩阵来实现模型微调,有效缓解内存和计算资源限制的优势,成为了我们本次微调的首选方法。
Llama - Factory 训练框架简介:
Llama - Factory 是由北航开源的低代码大模型训练框架,它在大模型训练领域有着显著的优势和丰富的功能。参考文章LLAMAFACTORY: Unified Efficient Fine-Tuning of 100+ Language Models(https://arxiv.org/pdf/2403.13372)

支持多种开源模型:该框架支持包括 Yuan2.0、Llama、LLaVA、Mistral、Mixtral - MOE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等多种开源大语言模型,具有广泛的适用性。
高效微调技术集成:集成了如 Lora、QLora 等高效微调技术,这些技术极大地优化了微调过程。以 Lora 为例,它通过在模型的某些层添加可训练的低秩矩阵,在几乎不增加计算复杂度的前提下,实现了对模型的有效微调。
可视化训练与推理平台:为开发者提供了可视化训练、推理平台,通过一键配置模型训练,能够实现零代码微调 LLM。这一特性使得非专业开发者也能轻松上手,进行模型的定制开发,大大降低了技术门槛。
多种训练模式:支持增量预训练、有监督微调、基于人类反馈的强化学习(RLHF)、直接偏好优化(DPO)等多种训练模式,满足不同场景下的需求。无论是想要对模型进行简单的领域适配,还是进行复杂的强化学习优化,Llama - Factory 都能提供相应的支持。
先进算法与实用技巧集成:集成了 GALORE、BADAM、DORA、LongLora、LlamaPro 等先进算法,以及 FlashAttention - 2、Unsloth、RoPEscaling 等实用技巧,提升训练效率和模型性能。这些算法和技巧从不同角度对训练过程进行优化,如提高计算效率、减少内存占用等。
实验监控与评估:提供 LlamaBoard、TensorBoard、WandB、MLflow 等多种实验监控工具,帮助开发者实时监控训练过程,评估模型性能。通过这些工具,开发者可以直观地看到模型在训练过程中的各项指标变化,如损失值、准确率等,从而及时调整训练策略。
Meta - Llama - 3 - 8B - Instruct 模型概述:
Meta - Llama - 3 - 8B - Instruct 是 Meta 开发的具有 80 亿参数的语言模型,它在经过预训练后,已经具备了对自然语言的基本理解和生成能力。该模型在多种自然语言处理任务上表现出了一定的潜力,如文本生成、问答系统、文本分类等。然而,由于其预训练数据和目标的通用性,在面对特定领域的专业任务时,往往需要进一步的微调来提升性能。例如,在医疗领域,它可能无法准确理解和回答专业的医学问题;在法律领域,对于法律条文的解读和应用也可能不够精准。因此,通过微调使其适应特定领域需求是充分发挥该模型潜力的重要途径。
Lora 方法原理及优势:
原理
Lora 方法的核心思想是在不改变预训练模型权重的基础上,为模型的每一层添加两个可训练的低秩矩阵。具体来说,对于模型中的每一个线性层,假设其输入为\(x\),原始的线性变换为\(y = Wx\),在应用 Lora 方法后,线性变换变为\(y = Wx + \Delta Wx\),其中\(\Delta W = BA\),\(A\)是一个从输入维度映射到低维空间的矩阵,\(B\)是一个从低维空间映射回输出维度的矩阵。通过这种方式,在训练过程中只需要更新\(A\)和\(B\)这两个低秩矩阵的参数,而不需要更新原始模型的权重\(W\),大大减少了需要训练的参数数量。
优势
减少内存占用:由于只需要存储和更新少量的低秩矩阵参数,相比于直接微调整个模型,Lora 方法显著减少了内存的占用。这对于在资源有限的设备上进行模型微调非常关键,使得开发者可以在普通的 GPU 甚至 CPU 上进行大模型的微调操作。
降低计算复杂度:在训练过程中,只对低秩矩阵进行计算和更新,计算量大幅降低。这不仅加快了训练速度,还降低了对计算资源的要求,使得微调过程更加高效。
快速部署:因为微调后的模型只增加了少量的低秩矩阵参数,模型的大小增加有限,这有利于模型的快速部署,特别是在对部署时间和资源有限制的场景中。
环境准备:
1.克隆 Llama - Factory 的 GitHub 仓库:在终端中使用以下命令将 Llama - Factory 的代码克隆到本地。
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git2.创建虚拟环境:建议使用 Python 的虚拟环境来管理项目依赖,以避免不同项目之间的依赖冲突。可以使用venv或conda来创建虚拟环境。使用conda创建虚拟环境的命令如下:
conda create -n llama-factory python = 3.123.激活虚拟环境:
conda activate llama-factory4.安装必要的依赖库:进入 Llama - Factory 项目目录,安装项目所需的依赖库。通常可以通过项目根目录下的requirements.txt文件来安装。
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
pip install -r requirements.txt
部署环境测试:
llamafactory-cli webui
数据准备:
训练主要用到2个开源数据集,分别是identity、alpaca_en_demo。
数据集保存在data目录下。
#identity.json数据格式,{"instruction": "hi","input": "","output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"},{"instruction": "hello","input": "","output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"},
#alpaca_en_demo数据格式
{"instruction": "Describe a process of making crepes.","input": "","output": "Making crepes is an easy and delicious process! Here are step-by-step instructions on how to make them:\n\n1. Assemble your ingredients. For basic crepes, you'll need: 1 cup all-purpose flour, 2 eggs, 1/2 cup milk, 1/2 cup water, 1/4 teaspoon salt, and 2 tablespoons melted butter.\n\n2. Mix the batter: In a large mixing bowl, whisk together the flour and the eggs. Gradually add the milk and water, stirring constantly to ensure that there are no lumps. Add salt and melted butter, and mix well.\n\n3. Let the batter rest: If you can, let the batter sit for an hour or so. This will help the flour to absorb the liquid and make the crepes more tender.\n\n4. Heat your pan: Preheat a non-stick pan over medium heat. Lightly butter the pan or use cooking spray to prevent the crepes from sticking.\n\n5. Pour the batter: Using a ladle or a measuring cup, pour a small amount of batter (about 1/4 cup) onto the center of the pan. Immediately tilt the pan in a circular motion to spread the batter evenly and thinly over the bottom of the pan.\n\n6. Cook the crepe: Cook the crepe for 1-2 minutes until the bottom is lightly golden. Carefully loosen the edges with a spatula and flip the crepe over to cook the other side for another minute.\n\n7. Remove and repeat: Gently slide the crepe onto a plate, and then repeat the process with the remaining batter. Remember to re-butter the pan between each crepe if necessary.\n\n8. Fill and serve: Fill your cooked crepes with your desired filling, such as fresh fruit, whipped cream, Nutella, or ham and cheese. Roll or fold, and serve immediately. Enjoy!"},{"instruction": "Transform the following sentence using a synonym: The car sped quickly.","input": "","output": "The car accelerated rapidly."},模型准备:
基于魔塔社区下载模型文件,下载链接魔搭社区
模型配置与训练:
修改examples/train_lora/llama3_lora_sft.yaml配置文件中的模型路径,
启动训练,
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml

微调效果展示与分析
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
在微调前,Meta - Llama - 3 - 8B - Instruct 模型生成的文本可能在特定领域的专业性和准确性上有所欠缺。例如,当要求生成关于心脏病治疗方案的文本时,原始模型可能生成一些比较通用但缺乏专业细节的内容。而经过基于医疗领域数据集的微调后,模型能够生成更专业、详细的内容,如具体的药物名称、治疗流程等。
模型导出:
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
基于sglang进行服务搭建:
python3 -m sglang.launch_server --model output/llama3_lora_sft --trust-remote-code --tp 2 --host 0.0.0.0
服务测试:
测试采用openai接口,包括正常请求测试和流式请求测试
import openaiclient = openai.Client(base_url="http://10.1.12.10:30000/v1", api_key="None")#正常请求
response = client.chat.completions.create(model="./output/llama3_lora_sft/",messages=[{"role": "user", "content": "如何预防肺癌?"},],temperature=0,max_tokens=4096,
)
print(response.choices[0].message.content)#流式请求
stream = client.chat.completions.create(model="./output/llama3_lora_sft/",messages=[{"role": "user", "content": "如何预防肺癌?"}],stream=True,
)
for chunk in stream:if chunk.choices[0].delta.content is not None:print(chunk.choices[0].delta.content, end="")
总结:
通过在 Llama - Factory 训练框架下使用 Lora 方法对 Meta - Llama - 3 - 8B - Instruct 模型进行微调,我们能够充分发挥该模型的潜力,使其更好地适应特定领域或任务的需求。Llama - Factory 提供的丰富功能和便捷的操作流程,以及 Lora 方法在减少内存占用和计算复杂度方面的优势,为模型微调提供了高效、可行的解决方案。在实际应用中,开发者可以根据具体需求,灵活运用这一技术,开发出更具针对性和高性能的语言模型。未来,随着技术的不断发展,我们期待能够看到更多基于此类方法的创新应用和更强大的模型出现。
参考链接:
https://github.com/hiyouga/LLaMA-Factory
LLaMA3微调实战:解锁Meta-Llama-3-8B-Instruct的无限潜力-百度开发者中心
相关文章:
Llama-Factory框架下的Meta-Llama-3-8B-Instruct模型微调
目录 引言 Llama - Factory 训练框架简介: Meta - Llama - 3 - 8B - Instruct 模型概述: Lora 方法原理及优势: 原理 优势 环境准备: 部署环境测试: 数据准备: 模型准备: 模型配置与训练࿱…...

MySQL进阶-分析查询语句EXPLAIN
概述 能做什么? 表的读取顺序 数据读取操作的操作类型 哪些索引可以使用 哪些索引被实际使用 表之间的引用 每张表有多少行被优化器查询 官网介绍 https://dev.mysql.com/doc/refman/5.7/en/explain-output.html https://dev.mysql.com/doc/refman/8.0/…...

Python 高级编程与实战:构建数据可视化应用
在前几篇文章中,我们探讨了 Python 的基础语法、面向对象编程、函数式编程、元编程、性能优化、调试技巧、数据科学、机器学习、Web 开发、API 设计、网络编程、异步IO、并发编程、设计模式与软件架构、性能优化与调试技巧、分布式系统、微服务架构、自动化测试框架以及 RESTf…...

学习threejs,Animation、Core、CustomBlendingEquation、Renderer常量汇总
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️Animation常量汇总1.1.1 循…...
)
Java直通车系列14【Spring MVC】(深入学习 Controller 编写)
目录 基本概念 编写 Controller 的步骤和要点 1. 定义 Controller 类 2. 映射请求 3. 处理请求参数 4. 调用业务逻辑 5. 返回响应 场景示例 1. 简单的 Hello World 示例 2. 处理路径变量和请求参数 3. 处理表单提交 4. 处理 JSON 数据 5. 异常处理 基本概念 Cont…...

【蓝桥杯集训·每日一题2025】 AcWing 5539. 牛奶交换 python
AcWing 5539. 牛奶交换 Week 3 3月6日 题目描述 农夫约翰的 N N N 头奶牛排成一圈,使得对于 1 , 2 , … , N − 1 1,2,…,N−1 1,2,…,N−1 中的每个 i i i,奶牛 i i i 右边的奶牛是奶牛 i 1 i1 i1,而奶牛 N N N 右边的奶牛是奶牛 …...

Mybatis缓存机制(一级缓存和二级缓存)
前言 为什么要学习Mybatis 缓存机制? 学习Mybatis 缓存机制,可以有效解决 数据库的压力,提高数据库的性能。 例如:你要 对tb_user 表 ,查询 所有用户的信息,并且多次查询所有用户信息。我们知道第一次查询表信息流…...

设计模式--单例模式
一、单例模式代码实现 public class DatabaseConnection {// 1. 私有静态实例变量private static DatabaseConnection instance;// 2. 私有构造函数,防止外部直接创建实例private DatabaseConnection() {// 初始化数据库连接System.out.println("Database con…...

ubuntu22.04本地部署OpenWebUI
一、简介 Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 AI 平台,旨在完全离线运行。它支持各种 LLM 运行器,如 Ollama 和 OpenAI 兼容的 API,并内置了 RAG 推理引擎,使其成为强大的 AI 部署解决方案。 二、安装 方法 …...
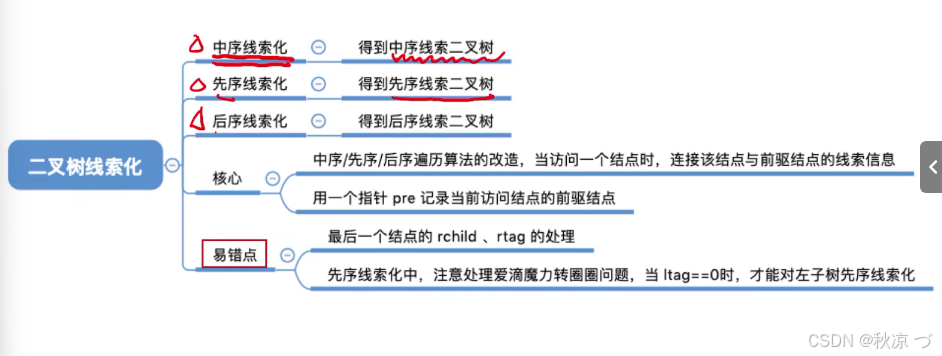
2025-3-7二叉树的线索化
一、中序线索化 代码其实就是和中序遍历相似,增加了两个标志位 ltag rtag。 完整的代码: 二、先序线索化: 三、后序线索化: 总结:其核心其实还是遍历算法的改造。 并且注意处理最后一个被访问的节点。...

以商业思维框架为帆,驭创业浪潮前行
创业者踏入商海,如同航海家奔赴未知海域,需有清晰的思维罗盘指引方向。图中“为什么—用什么—怎么做—何人做—投入产出”的商业框架,正是创业者破解商业谜题的密钥,从需求洞察到落地执行,为创业之路铺就逻辑基石。 …...

海思Hi3516DV300交叉编译opencv
OpenCV是一个开源的跨平台计算机视觉库,支持C、Python等多种语言,适用于图像处理、目标检测、机器学习等任务。其核心由C编写,高效轻量,提供实时视觉处理功能,广泛应用于工业自动化、医疗影像等领域。 1 环境准备 1…...
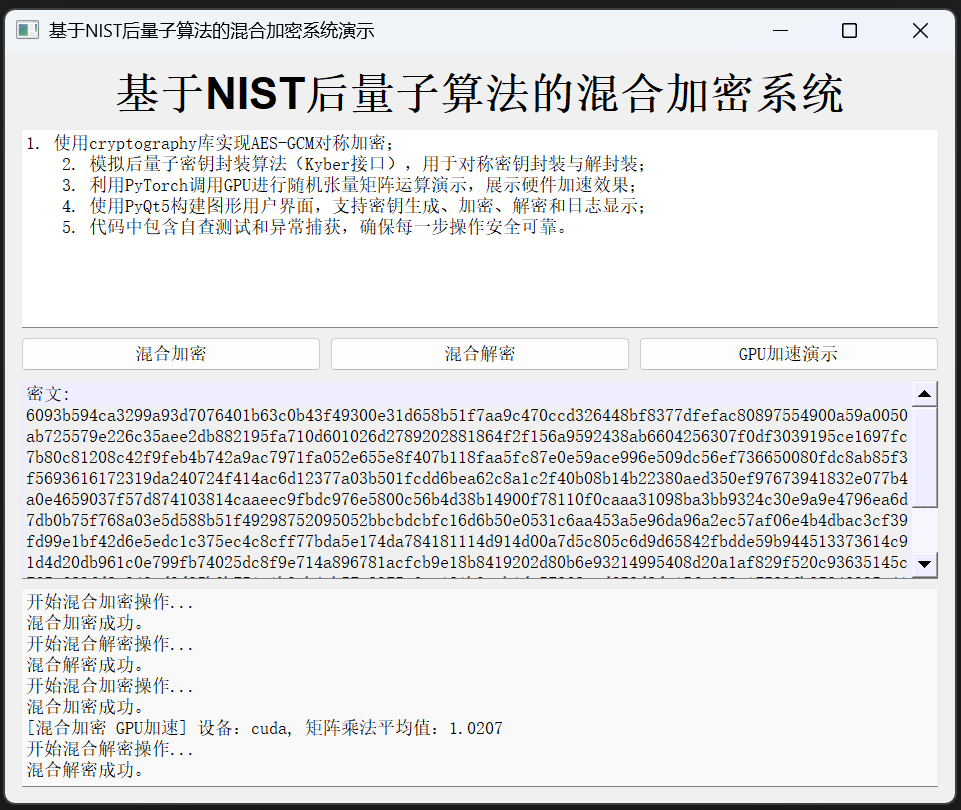
基于NIST后量子算法的混合加密系统
目录 基于NIST后量子算法的混合加密系统一、前言二、后量子密码学概述2.1 后量子密码学的背景2.2 NIST候选后量子算法 三、混合加密系统的设计原理3.1 混合加密的基本思想3.2 数学公式与证明3.3 混合加密系统的优势 四、工程实现与优化策略4.1 算法层面优化4.2 工程实现优化 五…...

uni-app 开发ios 使用testFlight 进行分发测试
一、生成ipa 首先你要生成一个ipa包,怎么生成这个包,可以在uniapp打包安卓和iOS包 二、上传到分发平台 在这里我使用的是Transporter ,当然你也可以看下其他分发平台 在mac电脑app store中下载Transporter,双击打开, 点击添加,将打包好的ipa文件放上去,注意打包的时…...
Node.js入门笔记2---下载安装Node.js
Node.js入门笔记2 Node.js下载并安装的步骤1.Node.js 环境的安装2. 区分 LTS 版本和 Current 版本的不同3.项目node管理版本工具4.Node.js 包管理工具5.MSI与ZIP文件格式的主要区别6. 选择好上面的内容,点击下载mis7. 环境配置 Node.js下载并安装的步骤 1.Node.js …...

基于微信小程序的超市购物系统+论文源码调试讲解
4 系统设计 超市购物系统的设计方案比如功能框架的设计,比如数据库的设计的好坏也就决定了该系统在开发层面是否高效,以及在系统维护层面是否容易维护和升级,因为在系统实现阶段是需要考虑用户的所有需求,要是在设计阶段没有经过…...

OpenCV视频解码实战指南
硬核解析OpenCV视频处理底层原理,从零实现高效视频解码流水线!附赠FFmpeg调优参数和异常帧处理方案,建议收藏备用。 📺 视频解码核心原理 视频容器 vs 编码格式 类型常见格式特点容器格式MP4/MKV/AVI/MOV存储封装格式࿰…...

Python的那些事第四十三篇:功能强大的测试框架pytest
pytest:功能强大的测试框架 摘要 本文旨在深入探讨 pytest 这一功能强大的测试框架。pytest 具有简单易用、功能丰富等特点,支持分布式测试、自动化测试用例发现等功能。本文将从 pytest 的基本概念、主要功能、使用方法等多个方面进行详细阐述,并通过具体的代码示例和表格…...
--前端性能优化(下))
工程化与框架系列(23)--前端性能优化(下)
前端性能优化(用户体验) 🎨 引言 用户体验(UX)性能优化是前端性能优化的重要组成部分。本文将探讨如何通过优化用户体验相关的性能指标,提升用户对应用的满意度,包括感知性能、交互响应、视觉…...

使用 Elasticsearch 进行集成测试初始化数据时的注意事项
作者:来自 Elastic piotrprz 在创建应该使用 Elasticsearch 进行搜索、数据聚合或 BM25/vector/search 的软件时,创建至少少量的集成测试至关重要。虽然 “模拟索引” 看起来很诱人,因为测试甚至可以在几分之一秒内运行,但它们实际…...

Java并发编程:CompletableFuture实战
Java并发编程:CompletableFuture实战 引言 Java 8引入的CompletableFuture是现代异步编程的重要工具,它不仅解决了Future的局限性,还提供了丰富的API用于组合、转换和处理异步结果。相比传统的Future,CompletableFuture支持流式调…...

从零构建AOD-Net:PyTorch实战图像去雾模型开发全流程
1. 环境准备与数据理解 在开始构建AOD-Net之前,我们需要先搭建好开发环境。推荐使用Anaconda创建独立的Python环境,避免与其他项目产生依赖冲突。这里我选择Python 3.8和PyTorch 1.12的组合,这个版本经过实测在图像处理任务中表现稳定。 安装…...

Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复“变砖“设备
Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复"变砖"设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器因固件升级失败、意外断电或系统崩…...
:Agentic RAG——让 Agent 主导检索过程)
RAG 系列(十七):Agentic RAG——让 Agent 主导检索过程
Pipeline RAG 的沉默失败 前面十几篇一直在优化一件事:怎么让检索结果更好。更好的分块、更精准的排序、更聪明的问法、CRAG 纠偏、Graph RAG 关系遍历…… 但有一件事始终没变:无论检索结果好不好,都会被传给 LLM 生成答案。 Pipeline RAG 的流程是线性的、固定的: 问…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题
终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 还在为学术论文翻译后排版全乱而烦恼吗?😫 技术文档翻…...

基于轨道模型构建现代化流程编排系统:从概念到实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫s4kuraN4gi/orbit-app。乍一看这个仓库名,可能很多人会有点懵,不知道它具体是做什么的。我花了一些时间深入研究,发现这是一个围绕“轨道”概念构建的现代化应用。这…...

VS Code光标主题定制指南:提升开发效率与视觉舒适度
1. 项目概述:一个为开发者量身定制的光标主题集合如果你和我一样,每天有超过8个小时的时间是在代码编辑器里度过的,那么你一定对那个在屏幕上闪烁的光标再熟悉不过了。它不仅仅是文本插入点,更是我们思维在数字世界中的延伸。然而…...

Vibe Coding Playbook:从环境到心流,打造高效愉悦的编程系统
1. 项目概述:一个关于“氛围感编程”的实践指南最近在GitHub上看到一个挺有意思的项目,叫“Vibe Coding Playbook”。乍一看这个标题,可能会有点摸不着头脑——“Vibe Coding”是什么?是某种新的编程范式吗?还是某种神…...

蜘蛛池技术解析:网站收录提速的关键工具与运营策略
在搜索引擎优化领域,蜘蛛池是助力网站收录提速的重要辅助工具,尤其适配新站、低权重站或海量内容站,能有效破解收录慢、收录少、深层页面难抓取等痛点。本文从技术原理、核心价值、搭建要点及合规运营策略四方面,全面解析蜘蛛池的…...