MySQL进阶-分析查询语句EXPLAIN
概述

能做什么?
表的读取顺序
数据读取操作的操作类型
哪些索引可以使用
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询
官网介绍
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html

版本情况
MySQL 5.6.3以前只能 EXPLAIN SELECT ;MYSQL 5.6.3以后就可以 EXPLAIN SELECT,UPDATE, DELETE
在5.7以前的版本中,想要显示 partitions 需要使用 explain partitions 命令;想要显示 filtered 需要使用 explain extended 命令。在5.7版本后,默认explain直接显示partitions和 filtered中的信息。
基本语法
EXPLAIN 或 DESCRIBE语句的语法形式如下:
EXPLAIN SELECT select_options
或者
DESCRIBE SELECT select_options
如果我们想看看某个查询的执行计划的话,可以在具体的查询语句前边加一个 EXPLAIN ,就像这样:
mysql> EXPLAIN SELECT 1;
EXPLAIN 语句输出的各个列的作用如下:

EXPLAIN各列作用
table
不论我们的查询语句有多复杂,里边儿 包含了多少个表 ,到最后也是需要对每个表进行 单表访问 的,所 以MySQL规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该 表的表名(有时不是真实的表名字,可能是简称)。
mysql > EXPLAIN SELECT * FROM s1;
这个查询语句只涉及对s1表的单表查询,所以
EXPLAIN输出中只有一条记录,其中的table列的值为s1,表明这条记录是用来说明对s1表的单表访问方法的。下边我们看一个连接查询的执行计划,可以看出这个连接查询的执行计划中有两条记录,这两条记录的table列分别是s1和s2,这两条记录用来分别说明对s1表和s2表的访问方法是什么。
mysql > EXPLAIN SELECT * FROM s1 INNER JOIN s2;
id
我们写的查询语句一般都以 SELECT 关键字开头,比较简单的查询语句里只有一个 SELECT 关键字,比如下边这个查询语句:
SELECT * FROM s1 WHERE key1 = 'a';稍微复杂一点的连接查询中也只有一个 SELECT 关键字,比如:
SELECT * FROM s1 INNER JOIN s2
ON s1.key1 = s2.key1
WHERE s1.common_field = 'a';但是下边两种情况下在一条查询语句中会出现多个SELECT关键字
- 当查询语句有子查询时
- 用union 来连接时

mysql > EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';
对于连接查询来说,一个SELECT关键字后边的FROM字句中可以跟随多个表,所以在连接查询的执行计划中,每个表都会对应一条记录,但是这些记录的id值都是相同的,比如:
mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2;

# 查询优化器可能对涉及子查询的查询语句进行重写,转变为多表查询的操作。
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key2 FROM s2 WHERE common_field = 'a');
可以看到,虽然我们的查询语句是一个子查询,但是执行计划中s1和s2表对应的记录的id值全部是1,这就表明查询优化器将子查询转换为了连接查询。
对于包含UNION子句的查询语句来说,每个SELECT关键字对应一个id值也是没错的,不过还是有点儿特别的东西,比方说下边的查询:
使用union是把多个查询的结果集合起来并对结果集中的记录进行去重,使用临时表的方式对结果集进行去重,所以在查询执行计划时就多了一条id为空的记录,表示这是为了合并两个查询的结果集而创建的。
# Union去重
mysql> EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;
mysql> EXPLAIN SELECT * FROM s1 UNION ALL SELECT * FROM s2;  小结:
小结:
id如果相同,可以认为是一组,从上往下顺序执行
在所有组中,id值越大,优先级越高,越先执行
关注点:id号每个号码,表示一趟独立的查询, 一个sql的查询趟数越少越好
select_type


- SIMPLE
查询语句中不包含UNION或者子查询的查询都算作是SIMPLE类型,比方说下边这个单表查询select_type的值就是SIMPLE:
mysql> EXPLAIN SELECT * FROM s1;
- PRIMARY
对于包含
UNION、UNION ALL或者子查询的大查询来说,它是由几个小查询组成的,其中最左边的那个查询的select_type的值就是PRIMARY。从结果中可以看到,最左边的小查询SELECT * FROM s1对应的是执行计划中的第一条记录,它的select_type的值就是PRIMARY。
mysql> EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;
- UNION
对于包含
UNION或者UNION ALL的大查询来说,它是由几个小查询组成的,其中除了最左边的那个小查询意外,其余的小查询的select_type值就是UNION,可以对比上一个例子的效果。
- UNION RESULT
MySQL 选择使用临时表来完成
UNION查询的去重工作,针对该临时表的查询的select_type就是UNION RESULT, 例子上边有。
- SUBQUERY
如果包含子查询的查询语句不能够转为对应的
semi-join的形式,并且该子查询是不相关子查询,并且查询优化器决定采用将该子查询物化的方案来执行该子查询时,该子查询的第一个SELECT关键字代表的那个查询的select_type就是SUBQUERY
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2) OR key3 = 'a';
- DEPENDENT SUBQUERY
当子查询是相关子查询的时候,即子查询内部与外部的表是有关联的
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2 WHERE s1.key2 = s2.key2) OR key3 = 'a';- DEPENDENT UNION
同关联子查询
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2 WHERE key1 = 'a' UNION SELECT key1 FROM s1 WHERE key1 = 'b');- DERIVED
从执行计划中可以看出,id为2的记录就代表子查询的执行方式,它的select_type是DERIVED, 说明该子查询是以物化的方式执行的。id为1的记录代表外层查询,大家注意看它的table列显示的是derived2,表示该查询时针对将派生表物化之后的表进行查询的。
mysql> EXPLAIN SELECT * FROM (SELECT key1, count(*) as c FROM s1 GROUP BY key1) AS derived_s1 where c > 1;
- MATERIALIZED
当查询优化器在执行包含子查询的语句时,选择将子查询物化之后的外层查询进行连接查询时,该子查询对应的
select_type属性就是DERIVED,比如下边这个查询:
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2);
type
执行计划的一条记录就代表着MySQL对某个表的 执行查询时的访问方法 , 又称“访问类型”,其中的 type 列就表明了这个访问方法是啥,是较为重要的一个指标。比如,看到type列的值是ref,表明MySQL即将使用ref访问方法来执行对s1表的查询。
完整的访问方法如下:
system , const , eq_ref , ref , fulltext , ref_or_null , index_merge , unique_subquery , index_subquery , range , index , ALL。
-
system
当表中只有一条记录并且该表使用的存储引擎的统计数据是精确的,比如MyISAM、Memory,那么对该表的访问方法就是system。比方说我们新建一个MyISAM表,并为其插入一条记录:
mysql> CREATE TABLE t(i int) Engine=MyISAM;
Query OK, 0 rows affected (0.05 sec)mysql> INSERT INTO t VALUES(1);
Query OK, 1 row affected (0.01 sec)然后我们看一下查询这个表的执行计划,可以看到type列的值就是system了,
mysql> EXPLAIN SELECT * FROM t;
-
const
当我们根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是const, 比如:
mysql> EXPLAIN SELECT * FROM s1 WHERE id = 10005;
-
eq_ref
在连接查询时,如果被驱动表是通过主键或者唯一二级索引列等值匹配的方式进行访问的(如果该主键或者唯一二级索引是联合索引的话,所有的索引列都必须进行等值比较)。则对该被驱动表的访问方法就是
eq_ref。从执行计划的结果中可以看出,MySQL打算将s2作为驱动表,s1作为被驱动表,重点关注s1的访问 方法是eq_ref,表明在访问s1表的时候可以通过主键的等值匹配来进行访问。
mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id;
-
ref
当通过普通的二级索引列与常量进行等值匹配时来查询某个表,那么对该表的访问方法就可能是ref,比方说下边这个查询:
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';
-
fulltext
全文索引
-
ref_or_null
当对普通二级索引进行等值匹配查询,该索引列的值也可以是
NULL值时,那么对该表的访问方法就可能是ref_or_null
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key1 IS NULL;
-
index_merge
一般情况下对于某个表的查询只能使用到一个索引,但单表访问方法时在某些场景下可以使用
Interseation、union、Sort-Union这三种索引合并的方式来执行查询。我们看一下执行计划中是怎么体现MySQL使用索引合并的方式来对某个表执行查询的。从执行计划的type列的值是index_merge就可以看出,MySQL 打算使用索引合并的方式来执行 对 s1 表的查询。
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key3 = 'a';
-
unique_subquery
类似于两表连接中被驱动表的
eq_ref访问方法,unique_subquery是针对在一些包含IN子查询的查询语句中,如果查询优化器决定将IN子查询转换为EXISTS子查询,而且子查询可以使用到主键进行等值匹配的话,那么该子查询执行计划的type列的值就是unique_subquery,比如下边的这个查询语句:
mysql> EXPLAIN SELECT * FROM s1 WHERE key2 IN (SELECT id FROM s2 where s1.key1 = s2.key1) OR key3 = 'a';
-
index_subquery
index_subquery与unique_subquery类似,只不过访问子查询中的表时使用的是普通的索引
range
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 IN ('a', 'b', 'c');
或者:
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 > 'a' AND key1 < 'b';
index
当我们可以使用索引覆盖,但需要扫描全部的索引记录时,该表的访问方法就是
index
mysql> EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a';
ALL
最熟悉的全表扫描,就不多说了,直接看例子:
mysql> EXPLAIN SELECT * FROM s1;
小结:
结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
其中比较重要的几个提取出来(见上图中的粗体)。SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,最好是 consts级别。(阿里巴巴 开发手册要求)
possible_keys和key
在EXPLAIN语句输出的执行计划中,
possible_keys列表示在某个查询语句中,对某个列执行单表查询时可能用到的索引有哪些。一般查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用。key列表示实际用到的索引有哪些,如果为NULL,则没有使用索引。执行计划的possible_keys列的值是idx_key1, idx_key3,表示该查询可能使用到idx_key1, idx_key3两个索引,然后key列的值是idx_key3,表示经过查询优化器计算使用不同索引的成本后,最后决定采用idx_key3。
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND key3 = 'a';
key_len
实际使用到的索引长度 (即:字节数),帮你检查是否充分的利用了索引,值越大越好,主要针对于联合索引,有一定的参考意义。
mysql> EXPLAIN SELECT * FROM s1 WHERE id = 10005;int 占四个字节

mysql> EXPLAIN SELECT * FROM s1 WHERE key2 = 10126;key2上有一个唯一性约束,是否为NULL占用一个字节,那么就是5个字节

mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';key1 VARCHAR(100) 一个字符占3个字节,100*3,是否为NULL占用一个字节,varchar的长度信息占两个字节。

mysql> EXPLAIN SELECT * FROM s1 WHERE key_part1 = 'a';
mysql> EXPLAIN SELECT * FROM s1 WHERE key_part1 = 'a' AND key_part2 = 'b';
ref
ref列展示得就是与索引列作等值匹配的数据结构是什么,到底是常数还是

mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';
可以看到ref列的值是const,表明在使用idx_key1索引执行查询时,与key1列作等值匹配的对象是一个常数,当然有时候更复杂一点:
mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id; 
mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s2.key1 = UPPER(s1.key1);
rows
预估的需要读取的记录条数,值越小越好。
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 > 'z';
filtered
某个表经过搜索条件过滤后剩余记录条数的百分比,如果使用的是索引执行的单表扫描,那么计算时需要估计出满足除使用到对应索引的搜索条件外的其他搜索条件的记录有多少条。
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND common_field = 'a';
对于单表查询来说,这个filtered的值没有什么意义,我们更关注在连接查询中驱动表对应的执行计划记录的filtered值,它决定了被驱动表要执行的次数 (即: rows * filtered)
mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.key1 = s2.key1 WHERE s1.common_field = 'a';从执行计划中可以看出来,查询优化器打算把
s1作为驱动表,s2当做被驱动表。我们可以看到驱动表s1表的执行计划的rows列为9688,filtered列为10.00,这意味着驱动表s1的扇出值就是9688 x 10.00% = 968.8,这说明还要对被驱动表执行大约968次查询。

Extra
顾名思义,
Extra列是用来说明一些额外信息的,包含不适合在其他列中显示但十分重要的额外信息。我们可以通过这些额外信息来更准确的理解MySQL到底将如何执行给定的查询语句。MySQL提供的额外信息有好几十个,我们就不一个一个介绍了,所以我们只挑选比较重要的额外信息介绍给大家。
No tables used
当查询语句没有FROM子句时将会提示该额外信息,比如:
mysql> EXPLAIN SELECT 1;
Impossible WHERE
当查询语句的WHERE子句永远为FALSE时将会提示该额外信息
mysql> EXPLAIN SELECT * FROM s1 WHERE 1 != 1;
Using where
表示该查询语句使用了非索引字段的查询条件,即使使用了索引,有非索引的查询条件也是如此。



mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' AND common_field = 'a'; 
No matching min/max row
当查询列表处有
MIN或者MAX聚合函数,但是并没有符合WHERE子句中的搜索条件的记录时。
mysql> EXPLAIN SELECT MIN(key1) FROM s1 WHERE key1 = 'abcdefg';
- Using index
当我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以使用覆盖索引的情况下,在
Extra列将会提示该额外信息。比方说下边这个查询中只需要用到idx_key1而不需要回表操作。
mysql> EXPLAIN SELECT key1 FROM s1 WHERE key1 = 'a';
Using index condition
有些搜索条件中虽然出现了索引列,但却不能使用到索引,比如下边这个查询:
SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';模糊查询会使索引失效,之前的处理是,先处理key1这个范围查询,然后立马根据范围查询所得到的二级索引去进行回文匹配。现在的处理逻辑是,处理完范围查询后,就对得到的二级索引判断是否满足模糊查询的条件,如果不符合的,就不进行回表操作,这样省略了大量回表操作,减少随机IO。 这个改进就是索引条件下推,当mysql使用了索引条件下推,就会显示
Using index condition


Using join buffer (Block Nested Loop)
在连接查询执行过程中,当被驱动表不能有效的利用索引加快访问速度,MySQL一般会为其分配一块名叫
join buffer的内存块来加快查询速度,也就是我们所讲的基于块的嵌套循环算法。
mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.common_field = s2.common_field;
Not exists
当我们使用左(外)连接时,如果
WHERE子句中包含要求被驱动表的某个列等于NULL值的搜索条件,而且那个列是不允许存储NULL值的,那么在该表的执行计划的Extra列就会提示这个信息。
mysql> EXPLAIN SELECT * FROM s1 LEFT JOIN s2 ON s1.key1 = s2.key1 WHERE s2.id IS NULL;
Using intersect(...) 、 Using union(...) 和 Using sort_union(...)
- 如果执行计划的
Extra列出现了Using intersect(...)提示,说明准备使用Intersect索引合并的方式执行查询,括号中的...表示需要进行索引合并的索引名称;- 如果出现
Using union(...)提示,说明准备使用Union索引合并的方式执行查询;- 如果出现
Using sort_union(...)提示,说明准备使用Sort-Union索引合并的方式执行查询。
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key3 = 'a';
Zero limit
当我们的LIMIT子句的参数为0时,表示压根儿不打算从表中读取任何记录,将会提示该额外信息
mysql> EXPLAIN SELECT * FROM s1 LIMIT 0;
Using filesort
有一些情况下对结果集中的记录进行排序是可以使用到索引的。如果在内存或者磁盘中进行排序那就统称为文件排序。需要注意的是,如果查询中需要使用
filesort的方式进行排序的记录非常多,那么这个过程是很耗费性能的,我们最好想办法将使用文件排序的执行方式改为索引进行排序。
mysql> EXPLAIN SELECT * FROM s1 ORDER BY key1 LIMIT 10;

mysql> EXPLAIN SELECT * FROM s1 ORDER BY common_field LIMIT 10;
-
Using temporary

mysql> EXPLAIN SELECT DISTINCT common_field FROM s1;
mysql> EXPLAIN SELECT common_field, COUNT(*) AS amount FROM s1 GROUP BY common_field;
执行计划中出现
Using temporary并不是一个好的征兆,因为建立与维护临时表要付出很大的成本的,所以我们最好能使用索引来替代掉使用临时表,比方说下边这个包含GROUP BY子句的查询就不需要使用临时表:
mysql> EXPLAIN SELECT key1, COUNT(*) AS amount FROM s1 GROUP BY key1;
相关文章:
MySQL进阶-分析查询语句EXPLAIN
概述 能做什么? 表的读取顺序 数据读取操作的操作类型 哪些索引可以使用 哪些索引被实际使用 表之间的引用 每张表有多少行被优化器查询 官网介绍 https://dev.mysql.com/doc/refman/5.7/en/explain-output.html https://dev.mysql.com/doc/refman/8.0/…...

Python 高级编程与实战:构建数据可视化应用
在前几篇文章中,我们探讨了 Python 的基础语法、面向对象编程、函数式编程、元编程、性能优化、调试技巧、数据科学、机器学习、Web 开发、API 设计、网络编程、异步IO、并发编程、设计模式与软件架构、性能优化与调试技巧、分布式系统、微服务架构、自动化测试框架以及 RESTf…...

学习threejs,Animation、Core、CustomBlendingEquation、Renderer常量汇总
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️Animation常量汇总1.1.1 循…...
)
Java直通车系列14【Spring MVC】(深入学习 Controller 编写)
目录 基本概念 编写 Controller 的步骤和要点 1. 定义 Controller 类 2. 映射请求 3. 处理请求参数 4. 调用业务逻辑 5. 返回响应 场景示例 1. 简单的 Hello World 示例 2. 处理路径变量和请求参数 3. 处理表单提交 4. 处理 JSON 数据 5. 异常处理 基本概念 Cont…...

【蓝桥杯集训·每日一题2025】 AcWing 5539. 牛奶交换 python
AcWing 5539. 牛奶交换 Week 3 3月6日 题目描述 农夫约翰的 N N N 头奶牛排成一圈,使得对于 1 , 2 , … , N − 1 1,2,…,N−1 1,2,…,N−1 中的每个 i i i,奶牛 i i i 右边的奶牛是奶牛 i 1 i1 i1,而奶牛 N N N 右边的奶牛是奶牛 …...

Mybatis缓存机制(一级缓存和二级缓存)
前言 为什么要学习Mybatis 缓存机制? 学习Mybatis 缓存机制,可以有效解决 数据库的压力,提高数据库的性能。 例如:你要 对tb_user 表 ,查询 所有用户的信息,并且多次查询所有用户信息。我们知道第一次查询表信息流…...

设计模式--单例模式
一、单例模式代码实现 public class DatabaseConnection {// 1. 私有静态实例变量private static DatabaseConnection instance;// 2. 私有构造函数,防止外部直接创建实例private DatabaseConnection() {// 初始化数据库连接System.out.println("Database con…...

ubuntu22.04本地部署OpenWebUI
一、简介 Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 AI 平台,旨在完全离线运行。它支持各种 LLM 运行器,如 Ollama 和 OpenAI 兼容的 API,并内置了 RAG 推理引擎,使其成为强大的 AI 部署解决方案。 二、安装 方法 …...
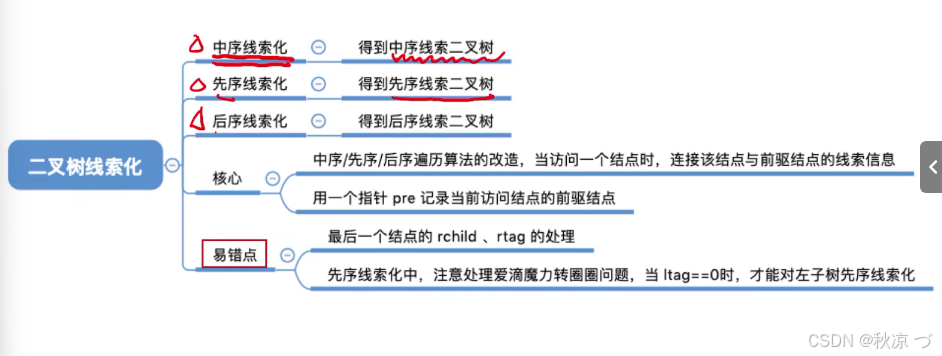
2025-3-7二叉树的线索化
一、中序线索化 代码其实就是和中序遍历相似,增加了两个标志位 ltag rtag。 完整的代码: 二、先序线索化: 三、后序线索化: 总结:其核心其实还是遍历算法的改造。 并且注意处理最后一个被访问的节点。...

以商业思维框架为帆,驭创业浪潮前行
创业者踏入商海,如同航海家奔赴未知海域,需有清晰的思维罗盘指引方向。图中“为什么—用什么—怎么做—何人做—投入产出”的商业框架,正是创业者破解商业谜题的密钥,从需求洞察到落地执行,为创业之路铺就逻辑基石。 …...

海思Hi3516DV300交叉编译opencv
OpenCV是一个开源的跨平台计算机视觉库,支持C、Python等多种语言,适用于图像处理、目标检测、机器学习等任务。其核心由C编写,高效轻量,提供实时视觉处理功能,广泛应用于工业自动化、医疗影像等领域。 1 环境准备 1…...
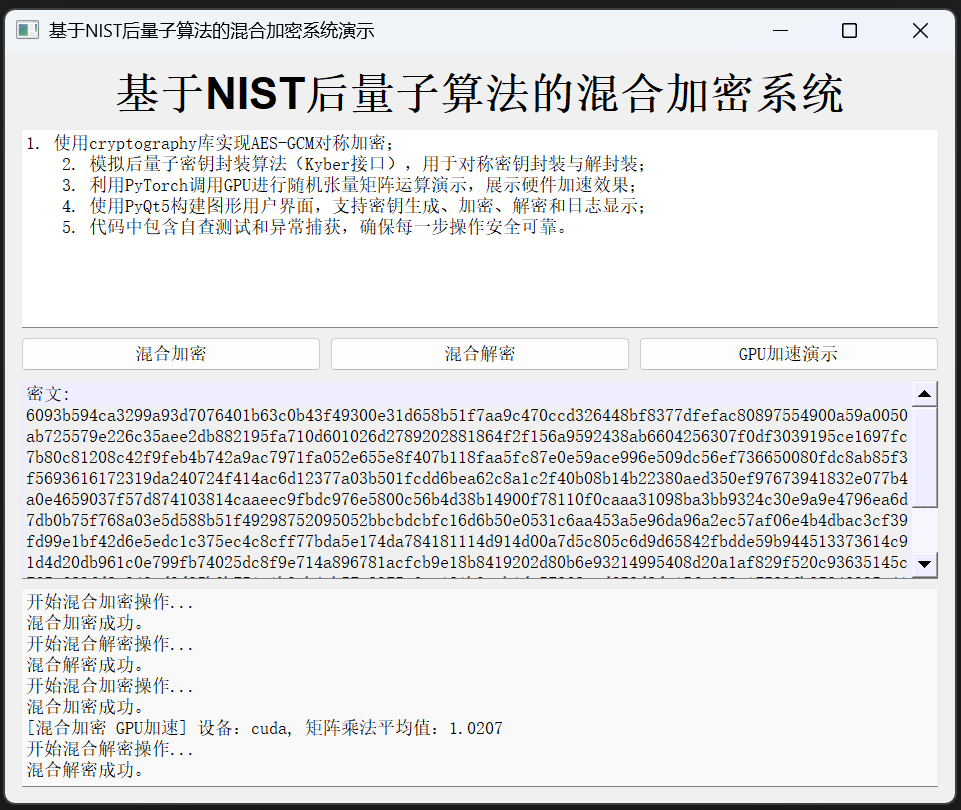
基于NIST后量子算法的混合加密系统
目录 基于NIST后量子算法的混合加密系统一、前言二、后量子密码学概述2.1 后量子密码学的背景2.2 NIST候选后量子算法 三、混合加密系统的设计原理3.1 混合加密的基本思想3.2 数学公式与证明3.3 混合加密系统的优势 四、工程实现与优化策略4.1 算法层面优化4.2 工程实现优化 五…...

uni-app 开发ios 使用testFlight 进行分发测试
一、生成ipa 首先你要生成一个ipa包,怎么生成这个包,可以在uniapp打包安卓和iOS包 二、上传到分发平台 在这里我使用的是Transporter ,当然你也可以看下其他分发平台 在mac电脑app store中下载Transporter,双击打开, 点击添加,将打包好的ipa文件放上去,注意打包的时…...
Node.js入门笔记2---下载安装Node.js
Node.js入门笔记2 Node.js下载并安装的步骤1.Node.js 环境的安装2. 区分 LTS 版本和 Current 版本的不同3.项目node管理版本工具4.Node.js 包管理工具5.MSI与ZIP文件格式的主要区别6. 选择好上面的内容,点击下载mis7. 环境配置 Node.js下载并安装的步骤 1.Node.js …...

基于微信小程序的超市购物系统+论文源码调试讲解
4 系统设计 超市购物系统的设计方案比如功能框架的设计,比如数据库的设计的好坏也就决定了该系统在开发层面是否高效,以及在系统维护层面是否容易维护和升级,因为在系统实现阶段是需要考虑用户的所有需求,要是在设计阶段没有经过…...

OpenCV视频解码实战指南
硬核解析OpenCV视频处理底层原理,从零实现高效视频解码流水线!附赠FFmpeg调优参数和异常帧处理方案,建议收藏备用。 📺 视频解码核心原理 视频容器 vs 编码格式 类型常见格式特点容器格式MP4/MKV/AVI/MOV存储封装格式࿰…...

Python的那些事第四十三篇:功能强大的测试框架pytest
pytest:功能强大的测试框架 摘要 本文旨在深入探讨 pytest 这一功能强大的测试框架。pytest 具有简单易用、功能丰富等特点,支持分布式测试、自动化测试用例发现等功能。本文将从 pytest 的基本概念、主要功能、使用方法等多个方面进行详细阐述,并通过具体的代码示例和表格…...
--前端性能优化(下))
工程化与框架系列(23)--前端性能优化(下)
前端性能优化(用户体验) 🎨 引言 用户体验(UX)性能优化是前端性能优化的重要组成部分。本文将探讨如何通过优化用户体验相关的性能指标,提升用户对应用的满意度,包括感知性能、交互响应、视觉…...

使用 Elasticsearch 进行集成测试初始化数据时的注意事项
作者:来自 Elastic piotrprz 在创建应该使用 Elasticsearch 进行搜索、数据聚合或 BM25/vector/search 的软件时,创建至少少量的集成测试至关重要。虽然 “模拟索引” 看起来很诱人,因为测试甚至可以在几分之一秒内运行,但它们实际…...

自然语言模型(NLP)介绍
一、自然语言模型概述 自然语言模型(NLP)通过模拟人类语言理解和生成能力,已成为人工智能领域的核心技术。近年来,以DeepSeek、GPT-4、Claude等为代表的模型在技术突破和应用场景上展现出显著优势。例如,DeepSeek通过…...

AI Agent Harness Engineering 产品经理指南:如何定义智能体的“人设”与能力边界?
AI Agent Harness Engineering 产品经理指南:如何定义智能体的「人设」与能力边界 关键词:AI Agent、智能体管控工程(Harness Engineering)、产品经理、人设对齐、能力边界、智能体治理、生成式AI落地 摘要 随着生成式AI技术的成熟,AI Agent已经从概念验证阶段进入大规…...

无线渗透测试框架Airecon:自动化工具链整合与实战应用
1. 项目概述与核心价值最近在整理自己的渗透测试工具箱时,又翻出了pikpikcu/airecon这个老伙计。说实话,在无线安全评估这个细分领域里,它可能不是名气最响的那个,但绝对是我个人在内部网络渗透和红队演练中最顺手、最高效的“组合…...

通达信数据解析终极指南:mootdx让金融数据获取变得如此简单
通达信数据解析终极指南:mootdx让金融数据获取变得如此简单 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易的世界里,获取准确、完整的市场数据是…...

VectorDBBench:向量数据库性能基准测试工具详解与实战
1. 项目概述:向量数据库性能测试的“瑞士军刀”如果你正在评估或使用向量数据库,那么你一定遇到过这个灵魂拷问:“这么多产品,到底哪个最适合我的场景?”是选名声在外的老牌劲旅,还是选后起之秀的专精选手&…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...

CFD工程师必看:TVD格式选型指南——从SUPERBEE到UMIST,哪个才是你的菜?
CFD工程师必看:TVD格式选型实战指南——从工程场景到最优解 在计算流体力学(CFD)的世界里,TVD格式就像赛车手的轮胎选择——没有绝对的好坏,只有场景的适配。当你在汽车外气动分析中遇到激波振荡,或在燃烧模拟中面临虚假扩散时&am…...

如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南
如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经历过手机丢失、微信重装后珍贵聊天…...

Arm Cortex-A35 Cycle Model技术解析与SoC集成实战
1. Arm Cortex-A35 Cycle Model技术解析在SoC设计领域,虚拟平台验证已成为不可或缺的关键环节。作为Armv8-A架构中的能效比优化核心,Cortex-A35处理器通过Cycle Model提供了RTL级精度的硬件行为模拟能力。我在多个车载SoC项目中验证发现,其Cy…...

Faderwave合成器:用16个推子实时绘制波形,打造硬件交互式音色
1. 项目概述:用16个推子“画”出你的声音如果你玩过合成器,肯定知道波形是声音的基石。正弦波的纯净、方波的硬朗、锯齿波的锋利,每一种经典波形都定义了合成器音色的灵魂。但你是否想过,如果能像画家调色一样,亲手“绘…...

避坑指南:在Python 3.7环境用ModelScope部署speech_campplus_sv_zh-cn_16k-common语音识别模型的完整流程
避坑指南:Python 3.7环境部署ModelScope语音识别模型的完整实践 在人工智能语音处理领域,说话人验证技术正逐渐成为身份认证和语音交互系统的核心组件。阿里云达摩院开源的speech_campplus_sv_zh-cn_16k-common模型作为轻量级解决方案,特别适…...