机器学习之强化学习
引言
在人工智能的众多分支中,强化学习(Reinforcement Learning, RL) 因其独特的学习范式而备受关注。与依赖标注数据的监督学习或探索数据结构的无监督学习不同,强化学习的核心是智能体(Agent)通过与环境的动态交互来学习最优策略。AlphaGo击败人类围棋冠军、自动驾驶汽车在复杂路况中决策、机器人灵活抓取物体——这些突破性成就的背后,都离不开强化学习的核心技术。本文将深入解析强化学习的核心原理、算法分类、应用场景及未来挑战,为读者呈现这一领域的全貌。

一、强化学习的核心原理
1.1 基本框架:智能体与环境的交互
强化学习的核心是**智能体(Agent)与环境(Environment)**的持续交互。智能体通过观察环境状态(State)选择行动(Action),环境则返回奖励(Reward)并更新状态。这种循环的目标是最大化智能体长期累积的奖励。
-
状态(State):描述环境的当前信息(如自动驾驶中的车辆位置、周围障碍物)。
-
行动(Action):智能体可执行的操作(如加速、转向)。
-
奖励(Reward):环境对智能体行动的即时反馈(如成功抵达终点得+1,碰撞得-1)。
1.2 核心目标:策略优化
智能体的目标是学习一个策略(Policy),即从状态到行动的最优映射。策略优化的核心数学工具是贝尔曼方程(Bellman Equation),它通过动态规划的思想将长期奖励分解为即时奖励与未来奖励的加权和:
其中,是状态价值函数,
是折扣因子(通常取值0.9~0.99),体现未来奖励的重要性。
二、强化学习的算法分类
根据学习方法的不同,强化学习算法可分为三类:
2.1 基于价值的方法(Value-Based)
通过估计状态或行动的价值(如Q值)间接优化策略。
-
Q-Learning:直接学习行动价值函数
,更新公式为:
-
Deep Q-Network (DQN):用神经网络近似Q值,引入经验回放(Experience Replay)和固定目标网络(Target Network)解决训练不稳定问题。
适用场景:离散行动空间(如游戏控制)。
2.2 基于策略的方法(Policy-Based)
直接优化策略函数 π(a∣s),适用于连续行动空间。
-
REINFORCE:通过蒙特卡洛采样估计梯度,更新策略参数。
-
PPO(Proximal Policy Optimization):通过限制策略更新的幅度,确保训练稳定性。
优势:能处理高维、连续动作(如机器人控制)。
2.3 演员-评论家方法(Actor-Critic)
结合价值函数与策略函数,Actor负责生成行动,Critic评估行动价值。
-
A3C(Asynchronous Advantage Actor-Critic):多线程异步更新,加速训练。
-
SAC(Soft Actor-Critic):引入熵正则化,鼓励探索。
特点:兼具价值与策略方法的优点,适合复杂任务。
三、强化学习的应用场景
3.1 游戏AI
-
AlphaGo & AlphaZero:通过自我对弈(Self-Play)在围棋、国际象棋等领域超越人类。
-
OpenAI Five:在Dota 2中击败职业选手,展现多智能体协作能力。
3.2 机器人控制
-
机械臂抓取:通过强化学习训练机器人适应不同形状物体的抓取策略。
-
双足机器人行走:波士顿动力(Boston Dynamics)的Atlas机器人通过RL实现复杂地形行走。
3.3 自动驾驶
-
路径规划:在动态环境中实时决策(如超车、避障)。
-
仿真训练:利用虚拟环境(如CARLA)加速算法迭代。
3.4 资源优化
-
能源管理:优化电网或数据中心的能源分配。
-
金融交易:通过强化学习制定高频交易策略。
四、强化学习的挑战与前沿方向
4.1 核心挑战
-
样本效率低:训练需大量交互数据(如AlphaGo需数百万局对弈)。
-
探索与利用的平衡:过度探索降低效率,过度利用易陷局部最优。
-
稀疏奖励问题:关键奖励信号稀少(如迷宫任务中仅终点有奖励)。
4.2 前沿研究方向
-
元强化学习(Meta-RL):让智能体快速适应新任务(如Few-Shot Learning)。
-
分层强化学习(Hierarchical RL):将复杂任务分解为子任务,提升可解释性。
-
多智能体强化学习(Multi-Agent RL):解决协作与竞争问题(如无人机编队)。
五、实践建议与工具
5.1 开发工具
-
OpenAI Gym:提供标准强化学习环境(如CartPole、Atari游戏)。
-
Stable Baselines3:集成PPO、DQN等主流算法的代码库。
-
PyTorch & TensorFlow:支持深度强化学习的框架。
5.2 调参技巧
-
探索率衰减:初期高探索率(如ε=1.0),后期逐步降低。
-
奖励设计:设计密集奖励函数(如分阶段奖励)加速训练。
-
并行化训练:使用A3C或分布式框架提升效率。
六、结语
强化学习凭借其与人类学习模式的相似性(试错与反馈),已成为解决复杂决策问题的利器。尽管面临样本效率、泛化能力等挑战,随着算法创新与算力提升,其在医疗、教育、工业等领域的应用前景广阔。未来,强化学习也必将成为通用人工智能(AGI)的核心技术之一,推动机器真正理解并适应动态世界。
相关文章:
机器学习之强化学习
引言 在人工智能的众多分支中,强化学习(Reinforcement Learning, RL) 因其独特的学习范式而备受关注。与依赖标注数据的监督学习或探索数据结构的无监督学习不同,强化学习的核心是智能体(Agent)通过与环境…...
基于 uni-app 和 Vue3 开发的汉字书写练习应用
基于 uni-app 和 Vue3 开发的汉字书写练习应用 前言 本文介绍了如何使用 uni-app Vue3 uview-plus 开发一个汉字书写练习应用。该应用支持笔画演示、书写练习、进度保存等功能,可以帮助用户学习汉字书写。 在线演示 演示地址: http://demo.xiyueta.com/case/w…...

每天五分钟深度学习PyTorch:向更深的卷积神经网络挑战的ResNet
本文重点 ResNet大名鼎鼎,它是由何恺明团队设计的,它获取了2015年ImageNet冠军,它很好的解决了当神经网络层数过多出现的难以训练的问题,它创造性的设计了跳跃连接的方式,使得卷积神经网络的层数出现了大幅度提升,设置可以达到上千层,可以说resnet对于网络模型的设计具…...
electron + vue3 + vite 主进程到渲染进程的单向通信
用示例讲解下主进程到渲染进程的单向通信 初始版本项目结构可参考项目:https://github.com/ylpxzx/electron-forge-project/tree/init_project 主进程到渲染进程(单向) 以Electron官方文档给出的”主进程主动触发动作,发送内容给渲…...

《白帽子讲 Web 安全》之身份认证
目录 引言 一、概述 二、密码安全性 三、认证方式 (一)HTTP 认证 (二)表单登录 (三)客户端证书 (四)一次性密码(OTP) (五)多因…...

postgrel
首先按照惯例,肯定是需要对PostgreSQL数据库进行一系列信息收集的,常用的命令有以下这些:-- 版本信息select version();show server_version;select pg_read_file(PG_VERSION, 0, 200);-- 数字版本信息包括小版号SHOW server_version_num;SEL…...
)
Java基础——java8+新特性——方法引用(::)
1. 什么是方法引用? 定义:Java 8 引入的语法糖,用于 简化 Lambda 表达式,直接引用已有的方法。 符号:使用 :: 双冒号操作符。 本质:将方法作为函数式接口的实例传。 2. 方法引用的四种类型 类型 语法 …...
基于SpringBoot的商城管理系统(源码+部署教程)
运行环境 数据库:MySql 编译器:Intellij IDEA 前端运行环境:node.js v12.13.0 JAVA版本:JDK 1.8 主要功能 基于Springboot的商城管理系统包含管理端和用户端两个部分,主要功能有: 管理端 首页商品列…...
uniapp实现的个人中心页面(仿小红书)
采用 uniapp 实现的一款仿小红书个人中心页面模板,支持vue2、vue3, 同时适配H5、小程序等多端多应用。 简约美观大方 可到插件市场下载尝试: https://ext.dcloud.net.cn/plugin?id22516 示例...
)
K8s面试题总结(十一)
1.如何优化docker镜像的大小? 使用多阶段构建(multi-stage build)选择更小的基础镜像(如alpine)减少镜像层数,合并RUN命令 2.请解释Docker中的网络模式(如bridge,host,none) Bridgeÿ…...
用CMake编译glfw进行OpenGL配置,在Visual Studio上运行
Visual Studio的下载 Visual Studio 2022 C 编程环境 GLFW库安装 GLFW官网地址 GLFW官网地址:https://www.glfw.org下载相应版本,如下图: CMake软件进行编译安装 下载CMake 下载的如果是源码包,需要下载CMake软件进行编译安装…...
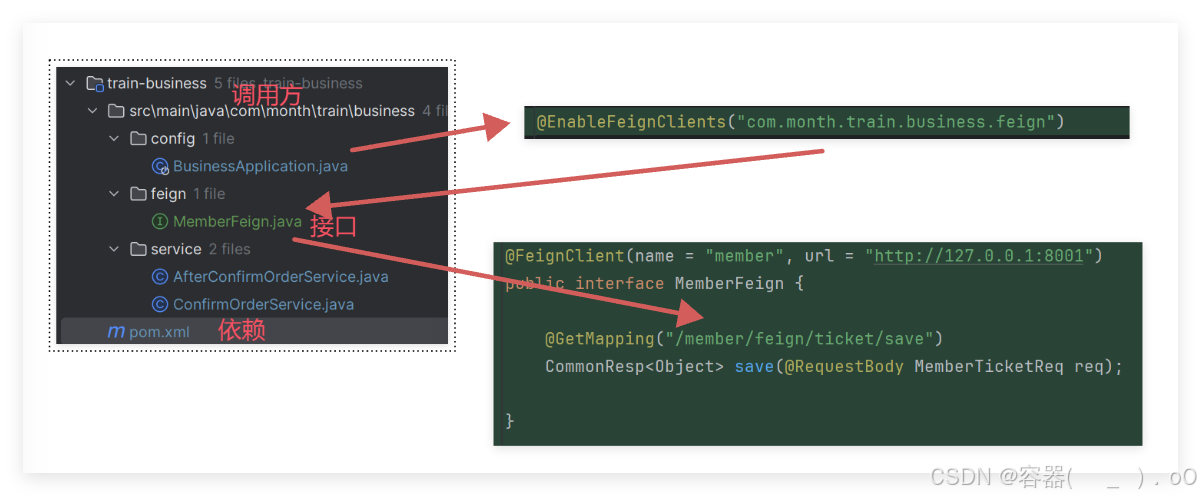
仿12306项目(4)
基本预定车票功能的开发 对于乘客购票来说,需要有每一个车次的余票信息,展示给乘客,供乘客选择,因此首个功能是余票的初始化,之后是余票查询,这两个都是控台端。对于会员端的购票,需要有余票查询…...
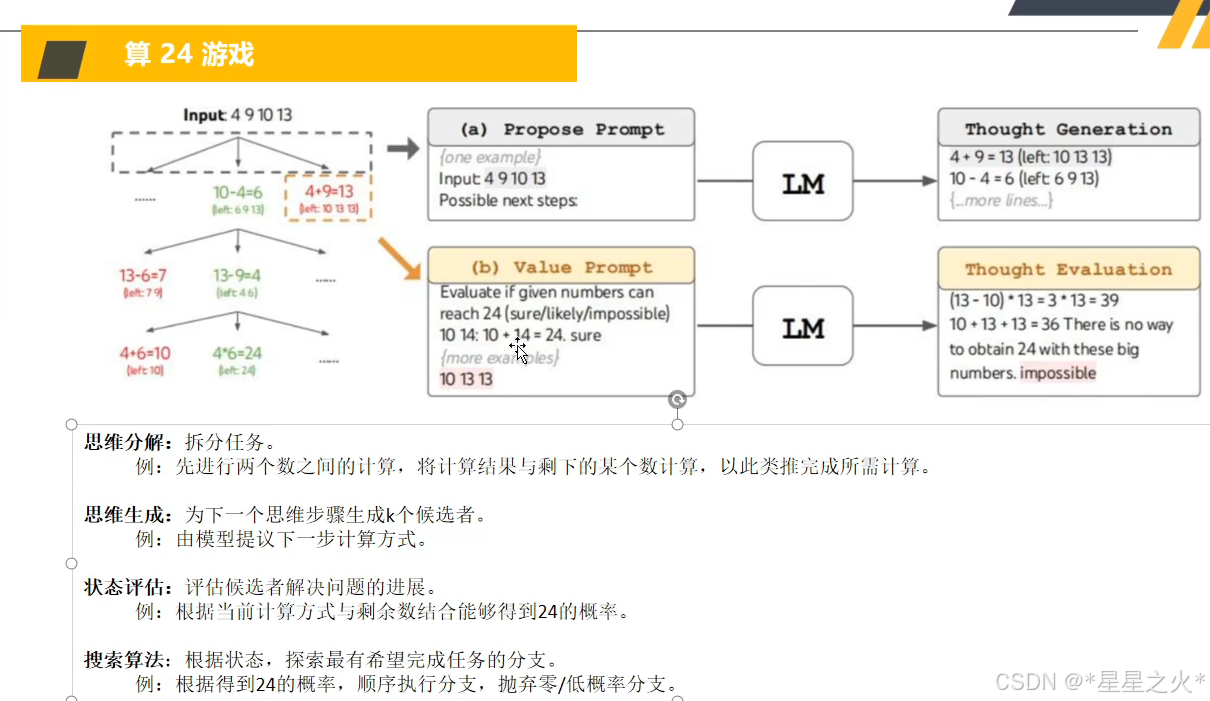
【GPT入门】第9课 思维树概念与原理
【GPT入门】第9课 思维树概念与原理 1.思维树概念与原理2. 算24游戏的方法 1.思维树概念与原理 思维树(Tree of Thought,ToT )是一种大模型推理框架,旨在解决更加复杂的多步骤推理任务,让大模型能够探索多种可能的解决…...

uniapp登录用户名在其他页面都能响应
使用全局变量 1、在APP.vue中定义一个全局变量,然后在需要的地方引用它; <script>export default {onLaunch: function() {console.log(App Launch)this.globalData { userInfo: {} };},onShow: function() {console.log(App Show)},onHide: fu…...
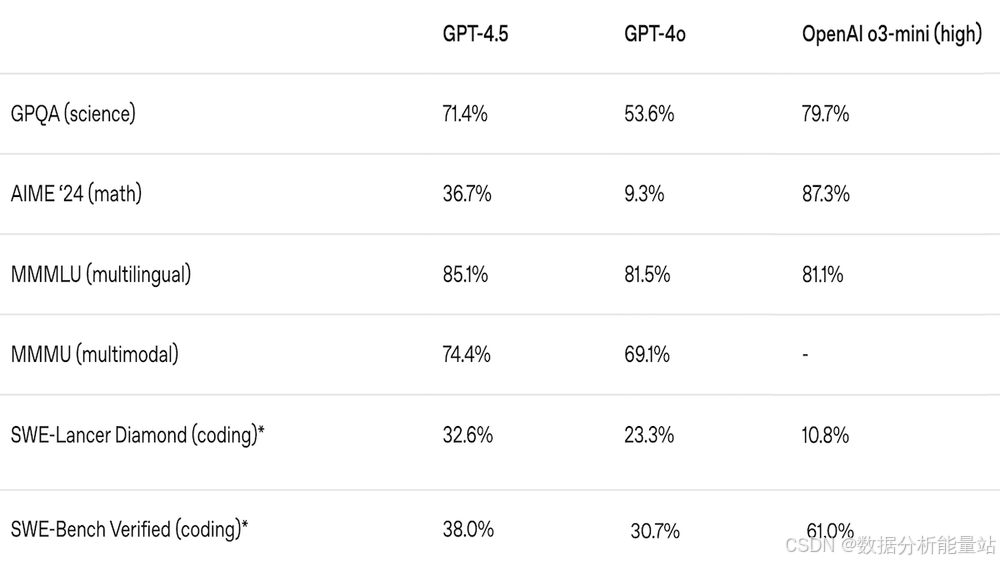
一周热点-OpenAI 推出了 GPT-4.5,这可能是其最后一个非推理模型
在人工智能领域,大型语言模型一直是研究的热点。OpenAI 的 GPT 系列模型在自然语言处理方面取得了显著成就。GPT-4.5 是 OpenAI 在这一领域的又一力作,它在多个方面进行了升级和优化。 1 新模型的出现 GPT-4.5 目前作为研究预览版发布。与 OpenAI 最近的 o1 和 o3 模型不同,…...
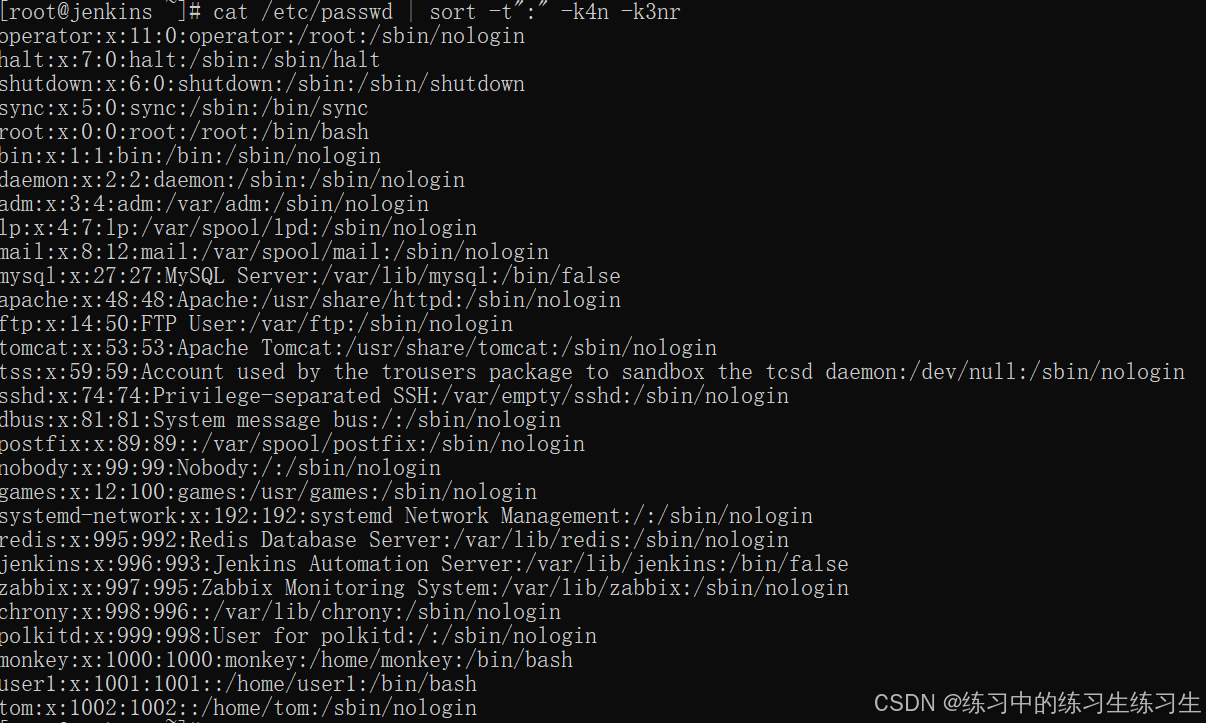
Linux基础--用户管理
目录 查看用户 使用命令: id 创建用户 使用命令: useradd 编辑 为用户设置密码 使用命令: passwd 编辑 删除用户 使用命令: userdel 创建用户组 使用命令: groupadd 删除用户组 使用命令: groupdel 用户设置 使用命令: usermod 将用户从组中去除 使用…...
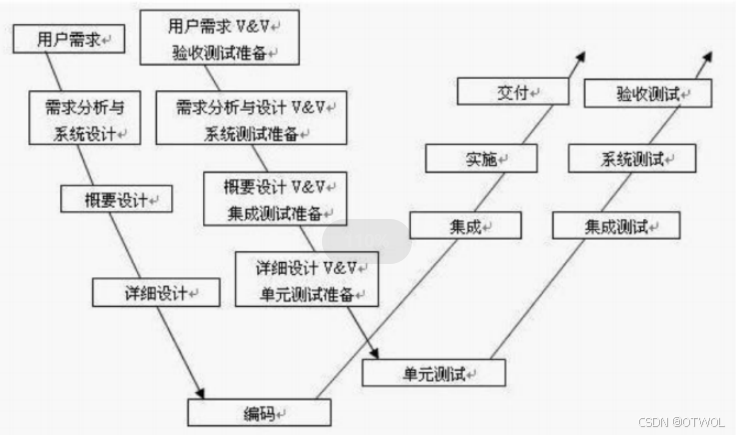
软件测试的基础入门(二)
文章目录 一、软件(开发)的生命周期什么是生命周期软件(开发)的生命周期需求分析计划设计编码测试运行维护 二、常见的开发模型瀑布模型流程优点缺点适应的场景 螺旋模型流程优点缺点适应的场景 增量模型和迭代模型流程适应的场景…...

【SpringMVC】深入解析@ RequestMapping 注解的概念及使用和 MVC 介绍
Spring Web MVC入门 1. Spring Web MVC 什么是 Spring Web MVC? MVC官方文档介绍 Spring Web MVC是Spring框架中的一个用来做网站开发的部分,它是基于Servlet技术的。 虽然它的正式名字叫“Spring Web MVC”,但大家一般都简称它“SpringMVC”…...

YOLOv8 自定义目标检测
一、引言 YOLOv8 不仅支持预训练模型的推理,还允许用户将其应用于自定义对象检测。本文将详细介绍如何使用 YOLOv8 训练一个新的模型,并在自定义数据集上进行对象检测。 二、数据集准备 1. 数据集格式 YOLOv8 支持多种数据集格式,包括 CO…...
抓包分析工具介绍
什么是抓包分析工具? 抓包分析工具,也称为网络数据包嗅探器或协议分析器,用于捕获和检查网络上传输的数据包。这些数据包包含了网络通信的详细信息,例如请求的资源、服务器的响应、HTTP 头信息、传输的数据内容等等。通过分析这些…...

3步掌握微信聊天记录导出:永久保存你的数字记忆
3步掌握微信聊天记录导出:永久保存你的数字记忆 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否担心手机丢失或更换时,珍贵的微信聊天记录会…...

基于RAG架构的本地知识库构建:从原理到Shannon实战
1. 项目概述:一个面向开发者的高效本地知识库构建工具最近在折腾个人知识管理和团队文档沉淀时,发现了一个挺有意思的开源项目,叫Shannon。这项目名挺有深意,取自信息论之父克劳德香农,一听就知道是跟信息处理和知识组…...
)
NotebookLM播客生成质量分析(行业首份LMM音频语义保真度测评报告)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM播客生成质量分析 NotebookLM 作为 Google 推出的实验性 AI 助手,其播客(Podcast)生成功能依托于对用户上传文档的理解与结构化重述。该功能并非端到端语音…...

量子纠缠蒸馏技术:原理、应用与最新进展
1. 量子纠缠蒸馏技术概述量子纠缠蒸馏(Quantum Entanglement Distillation)是量子信息科学中的一项基础性技术,其核心目标是从受噪声污染的混合态中提取出高纯度的纠缠态。这项技术最早由Bennett等人于1996年提出,现已成为构建量子…...

JDspyder终极指南:如何用Python自动化脚本实现京东茅台抢购
JDspyder终极指南:如何用Python自动化脚本实现京东茅台抢购 【免费下载链接】JDspyder 京东预约&抢购脚本,可以自定义商品链接 项目地址: https://gitcode.com/gh_mirrors/jd/JDspyder 在电商促销和限量商品抢购的激烈竞争中,手动…...

深度拆解GPT-Realtime-2:从“能听会说”到“听懂人话”,靠的是什么?
请你想象这个场景: 你打电话订酒店,中途改主意3次,还接了另一个电话。AI全程没让你重复一句话。——这就是GPT-Realtime-2做到的事。三大模型,三类场景的精准切割OpenAI此次发布的核心策略是专业化分工:GPT-Realtime-2…...

为 OpenClaw 配置 Taotoken 以驱动你的 AI 智能体工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 OpenClaw 配置 Taotoken 以驱动你的 AI 智能体工作流 如果你正在使用 OpenClaw 框架构建 AI 智能体,并且希望它能通…...

终极指南:如何用decimal.js解决JavaScript高精度计算难题
终极指南:如何用decimal.js解决JavaScript高精度计算难题 【免费下载链接】decimal.js An arbitrary-precision Decimal type for JavaScript 项目地址: https://gitcode.com/gh_mirrors/de/decimal.js 你知道吗?JavaScript在处理小数计算时有一个…...
)
ChatGPT Discord机器人开发全链路拆解(含Rate Limit绕过策略与上下文记忆优化)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT与Discord机器人开发全链路概览 构建一个能调用 ChatGPT 能力的 Discord 机器人,需跨越 API 集成、身份认证、消息路由与状态管理四大核心层。该链路并非单向调用,而是一…...

2026年测试工程师常用性能测试平台:高效办公与场景适配指南
测试工程师作为性能测试的核心执行者,对性能平台的需求聚焦于高效办公、功能全面、易用性强、问题定位精准四大维度。测试工程师日常工作涵盖脚本开发、场景编排、压测执行、监控分析、报告生成等多个环节,合适的性能平台,能够提升工作效率&a…...