Mysql配置文件My.cnf(my.ini)配置参数说明
一、my.cnf
配置文件路径:/etc/my.cnf,在调整了该文件内容后,需要重启mysql才可生效。
1、主要参数
| basedir = path | # | 使用给定目录作为根目录(安装目录)。 |
| datadir = path | # | 从给定目录读取数据库文件。 |
| pid-file= filename | # | 为mysqld程序指定一个存放进程ID的文件(仅适用于UNIX/Linux系统) |
| [mysqld] socket = /tmp/mysql.sock | # | MySQL客户程序与服务器之间的本地通信指定一个套接字文件(Linux下默认是 /var/lib/mysql/mysql.sock文件) |
| port = 3306 | # | 指定MsSQL侦听的端口 |
| key_buffer = 384M | # | key_buffer(键高速缓存)是用于索引块的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写)。索引块是缓冲的并且被所有的线程共享,key_buffer的大小视内存大小而定。 |
| table_cache= 512 | # | 为所有线程可以打开表的总数量。增加该值能增加mysqld要求的文件描述符的数量。可以避免频繁的打开数据表产生的开销。 |
| sort_buffer_size= 2M | # | 每个需要进行排序的线程分配该大小的一个缓冲区。增加这值加速ORDER BY或GROUP BY操作。 |
| read_buffer_size = 2M | # | 读查询操作所能使用的缓冲区大小。和 sort_buffer_size一样,该参数对应的分配内 存也是每连接独享。 |
| query_cache_size = 32M | # | 指定MySQL查询结果缓冲区的大小 |
| read_rnd_buffer_size= 8M | # | 改参数在使用行指针排序之后,随机读用的。 |
| myisam_sort_buffer_size =64M | # | MyISAM表发生变化时重新排序所需的缓冲 |
| thread_concurrency= 8 | # | 最大并发线程数,取值为服务器逻辑CPU数量 ×2,如果CPU支持H.T超线程,再×2 |
| thread_cache = 8 | # | 缓存可重用的线程数 |
| skip-locking | # | 避免MySQL的外部锁定,减少出错几率增强稳定性。 |
| [mysqldump] | # | 服务器和客户端之间最大能发送的可能信息包当MySQL客户端或mysqld服务器收到大于max_allowed_packet字节的信息包时,将发出“信息包过大”错误,并关闭连接。对于某些客户端,如果通信信息包过大,在执行查询期间,可能会遇到“丢失与MySQL服务器的连接”错误。如1153 - Got a packet bigger thanmax_allowed_packet' bytes |
| [myisamchk] |
|
|
2、其他可选参数
| back_log = 384 | # | 指定MySQL可能的连接数量。当MySQL主线程在很短时间内接收到非常多的连接请求,该参数生效,主线程花费很短时间检查连接并且启动一个新线程。back_log参数的值指出在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中。 |
| max_connections = n | # | MySQL服务器同时处理的数据库连接的最大数量(默认设置是100)。超过限制后会报 Too many connections 错误 |
| key_buffer_size = n | # | 用来存放索引区块的RMA值(默认设置是8M),增加它可得到更好处理的索引(对所有读和多重写) |
| record_buffer | # | 每个进行一个顺序扫描的线程为其扫描的每张表分配这个大小的一个缓冲区。如果你做很多顺序扫描,你可能想要增加该值。默认数值是131072(128K) |
| wait_timeout | # | 服务器在关闭它之前在一个连接上等待行动的秒数。 |
| interactive_timeout: | # | 服务器在关闭它前在一个交互连接上等待行动的秒数。一个交互的客户被定义为对 mysql_real_connect()使用 CLIENT_INTERACTIVE 选项的客户。 |
| skip-name-resolve | # | 禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求! |
| log-slow-queries = slow.log | # | 记录慢查询,然后对慢查询一一优化 |
| skip-innodb | # | 关闭不需要的表类型,如果你需要,就不要加上这个------跟踪并记录sql语句,在配置文件里加上如下 log=local.log |
二、my.ini
1、主要参数
| Client Section | # | 设置mysql客户端连接服务端时默认使用的端口 |
| [mysql] | # | 设置mysql客户端默认字符集 |
| port=3306 | # | mysql服务端默认监听(listen on)的TCP/IP端口 |
| basedir= path | # | 基准路径,其他路径都相对于这个路径 |
| datadir= path | # | mysql数据库文件所在目录 |
| character-set-server=latin1 | # | 服务端使用的字符集默认为8比特编码的latin1字符集 |
| default-storage-engine=INNODB | # | 创建新表时将使用的默认存储引擎 sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" # SQL模式为strict模式 |
| max_connections=100 | # | mysql服务器支持的最大并发连接数(用户数)。但总会预留其中的一个连接给管理员使用超级权限登录,即使连接数目达到最大限制。如果设置得过小而用户比较多,会经常出现“Too many connections”错误。 |
| query_cache_size=0 | # | 查询缓存大小,用于缓存SELECT查询结果。如果有许多返回相同查询结果的SELECT查询,并且很少改变表,可以设置 query_cache_size大于0,可以极大改善查询效率。而如果表数据频繁变化,就不要使用这个,会适得其反 |
| table_cache=256 | # | 这个参数在5.1.3之后的版本中叫做table_open_cache,用于设置table高速缓存的数量。由于每个客户端连接都会至少访问一个表,因此此参数的值与 Max_connections有关。当某一连接访问一个表时,MySQL会检查当前已缓存表的数量。如果该表已经在缓存中打开,则会直接访问缓存中的表已加快查询速度;如果该表未被缓存,则会将当前的表添加进缓存并进行查询。在执行缓存操作之前,table_cache用于限制缓存表的最大数目:如果当前已经缓存的表未达到table_cache,则会将新表添加进来;若已经达到此值,MySQL将根据缓存表的最后查询时间、查询率等规则释放之前的缓存。 |
| tmp_table_size=34M | # | 内存中的每个临时表允许的最大大小。如果 临时表大小超过该值,临时表将自动转为基 于磁盘的表(Disk Based Table)。 |
| thread_cache_size=8 | # | 缓存的最大线程数。当客户端连接断开时,如果客户端总连接数小于该值,则处理客户端任务的线程放回缓存。在高并发情况下,如果该值设置得太小,就会有很多线程频繁创建,线程创建的开销会变大,查询效率也会下降。一般来说如果在应用端有良好的多线程处理,这个参数对性能不会有太大的提高。 |
2、MyISAM相关参数
| myisam_max_sort_file_size=100G | # | mysql重建索引时允许使用的临时文件最大大小 |
| myisam_sort_buffer_size=68M | # |
|
| key_buffer_size=54M | # | Key Buffer大小,用于缓存MyISAM表的索引块。决定数据库索引处理的速度(尤其是索引读) |
| read_buffer_size=64K | # | 用于对MyISAM表全表扫描时使用的缓冲区大小。针对每个线程进行分配(前提是进行了全表扫描)。进行排序查询时,MySql会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySql会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。 |
| read_rnd_buffer_size=256K | # |
|
| sort_buffer_size=256K | # | connection级参数(为每个线程配置),500个线程将消耗500*256K的 |
3、InnoDB相关参数
| innodb_additional_mem_pool_size=3M | # | InnoDB用于存储元数据信息的内存池大小,般不需修改 |
| innodb_flush_log_at_trx_commit=1 | # | 事务相关参数,如果值为1,则InnoDB在每次commit都会将事务日志写入磁盘(磁盘IO消耗较大),这样保证了完全的ACID特性。而如果设置为0,则表示事务日志写入内存log和内存log写入磁盘的频率都为1次/秒。如果设为2则表示事务日志在每次commit都写入内存log,但内存log写入磁盘的频率为1次/秒。 |
| innodb_log_buffer_size=2M | # | InnoDB日志数据缓冲大小,如果缓冲满了,就会将缓冲中的日志数据写入磁盘(flush)。由于一般至少都1秒钟会写一次磁盘,所以 没必要设置过大,即使是长事务 |
| innodb_buffer_pool_size=105M | # | InnoDB使用缓冲池来缓存索引和行数据。 该值设为物理内存的80%。 |
| innodb_log_file_size=53M | # | 每一个InnoDB事务日志的大小。一般设为innodb_buffer_pool_size的25%到100% |
| innodb_thread_concurrency=9 | # | InnoDB内核最大并发线程数 |
相关文章:
配置参数说明)
Mysql配置文件My.cnf(my.ini)配置参数说明
一、my.cnf 配置文件路径:/etc/my.cnf,在调整了该文件内容后,需要重启mysql才可生效。 1、主要参数 basedir path # 使用给定目录作为根目录(安装目录)。 datadir path # 从给定目录读取数据库文件。 pid-file filename # 为mysq…...

聊天模型集成指南
文章目录 聊天模型集成指南Anthropic聊天模型集成PaLM2聊天模型PaLM2API的核心功能OpenAl聊天模型集成聊天模型集成指南 随着GPT-4等大语言模型的突破,聊天机器人已经不仅仅是简单的问答工具,它们现在广泛应用于客服、企业咨询、电子商务等多种场景,为用户提供准确、快速的反…...

搭建农产品管理可视化,助力农业智能化
利用图扑 HT 搭建农产品管理可视化平台,实现从生产到销售的全流程监控。平台通过物联网传感器实时采集土壤湿度、温度、光照等数据,支持智慧大棚的灌溉、施肥、病虫害防治等功能。同时,农产品调度中心大屏可展示市场交易数据、库存状态、物流…...

tee命令
tee 是一个在 Unix/Linux 系统中常用的命令,它用于读取标准输入(stdin),并将其内容同时输出到标准输出(stdout)和文件中。它常用于将命令的输出保存到文件的同时,也显示在终端屏幕上。 基本语法…...

国自然面上项目|基于海量多模态影像深度学习的肝癌智能诊断研究|基金申请·25-03-07
小罗碎碎念 今天和大家分享一个国自然面上项目,执行年限为2020.01~2023.12,直接费用为65万元。 该项目旨在利用多模态医学影像,通过深度学习技术,解决肝癌诊断中的难题,如影像的快速配准融合、海量特征筛选…...

「勾芡」和「淋明油」是炒菜收尾阶段提升菜品口感和观感的关键操作
你提到的「勾芡」和「淋明油」是炒菜收尾阶段提升菜品口感和观感的关键操作,背后涉及食品科学中的物理化学变化。以下从原理到实操的深度解析: 一、勾芡:淀粉的“精密控温游戏” 1. 科学原理 淀粉糊化(Gelatinization࿰…...

ROS云课三分钟-差动移动机器人导航报告如何撰写-及格边缘疯狂试探
提示词:基于如上所有案例并结合roslaunch teb_local_planner_tutorials robot_diff_drive_in_stage.launch和上面所有对话内容,设计一个差速移动机器人仿真实验,并完成报告的全文撰写。 差速移动机器人导航仿真实验报告 一、实验目的 验证 T…...

应用案例 | 精准控制,高效运行—宏集智能控制系统助力SCARA机器人极致性能
概述 随着工业4.0的深入推进,制造业对自动化和智能化的需求日益增长。传统生产线面临空间不足、效率低下、灵活性差等问题,尤其在现有工厂改造项目中,如何在有限空间内实现高效自动化成为一大挑战。 此次项目的客户需要在现有工厂基础上进行…...
蓝桥备赛(16)- 树
一、树的概念 1.1 树的定义 1)树型结构(一对多)是⼀类重要的非线性数据结构 2 )有⼀个特殊的结点,称为根结点,根结点没有前驱结点 3)除了根节点外 , 其余结点被分成 M(M…...
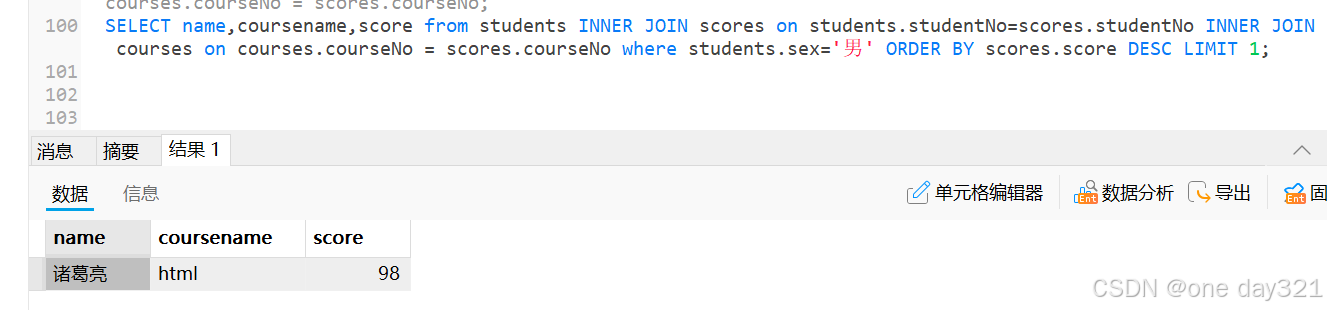
黑马测试mysql基础学习
视频来源:软件测试工程师所需的MySQL数据库技术,mysql系统精讲课后练习_哔哩哔哩_bilibili 环境准备: 虚拟机Linux服务器安装mysql数据库。本机安装Navicat。使Navicat连接虚拟机的数据库。(麻烦一点的是Navicat连接虚拟机的数据…...

ROS2-话题学习
强烈推荐教程: 《ROS 2机器人开发从入门到实践》3.2.2订阅小说并合成语音_哔哩哔哩_bilibili 构建功能包 # create package demo_python_pkg ros2 pkg create --build-type ament_python --license Apache-2.0 demo_python_pkg 自己写的代码放在./demo_python_pkg/…...

C++指针的基本认识
1.数组做函数参数 首先,所有传递给函数的参数都是通过传值方式进行的,传递给函数的都是参数的一份拷贝。 接着,当传递的参数是一个指向某个变量的指针时,函数将对该指针执行间接访问操作(拷贝指针,并访问所指向的内容),则函数就可以修改指向的变量。 2.一维数组 数组名…...

TypeScript系列06-模块系统与命名空间
1. ES 模块与 CommonJS 互操作性 1.1 模块解析策略 TypeScript 提供多种模块解析策略,每种策略针对不同的运行环境和开发场景优化: // tsconfig.json {"compilerOptions": {"moduleResolution": "node16", // 或 "…...
命令详解:zip)
Linux(Centos 7.6)命令详解:zip
1.命令作用 打包和压缩(存档)文件(package and compress (archive) files);该程序用于打包一组文件进行分发;存档文件;通过临时压缩未使用的文件或目录来节省磁盘空间;且压缩文件可以在Linux、Windows 和 macOS中轻松提取。 2.命…...
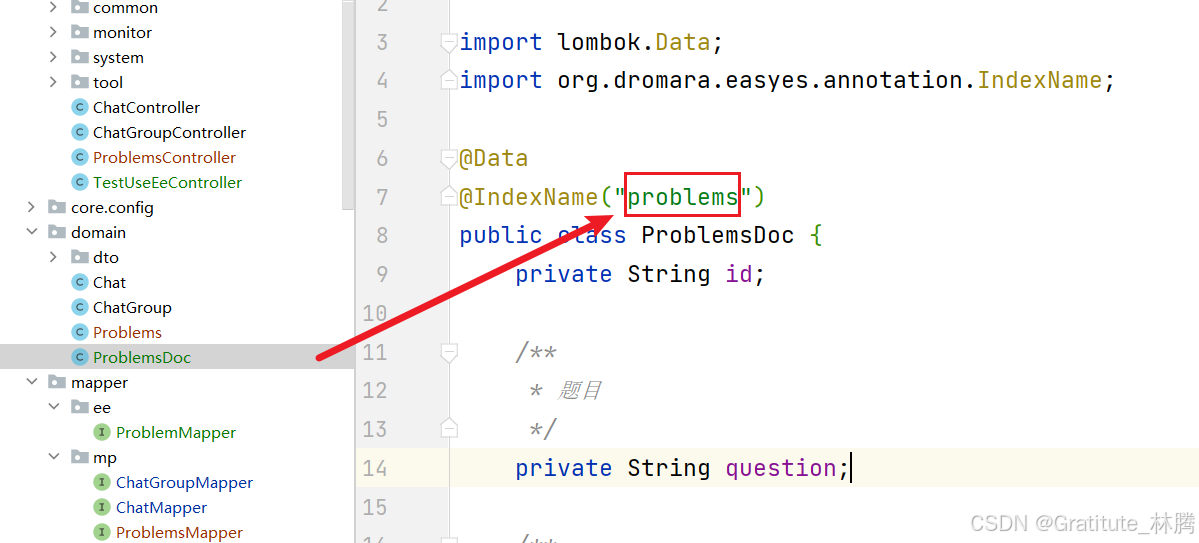
es-使用easy-es时如何指定索引库
在对应的实体类中,通过注解IndexName指定。 如上图,指定的索引库就是problems,那么之后我使用easy-es时都是针对该索引库进行增删改查。...

Redis-主从架构
主从架构 主从架构什么是主从架构基本架构 复制机制的工作原理1. 全量复制(Full Synchronization)2. 部分复制(Partial Synchronization)3. PSYNC2机制(Redis 4.0) 主从架构的关键技术细节1. 复制积压缓冲区…...

Java数据结构第二十期:解构排序算法的艺术与科学(二)
专栏:Java数据结构秘籍 个人主页:手握风云 目录 一、常见排序算法的实现 1.1. 直接选择排序 1.2. 堆排序 1.3. 冒泡排序 1.4. 快速排序 一、常见排序算法的实现 1.1. 直接选择排序 每⼀次从待排序的数据元素中选出最小的⼀个元素,存放在…...
inkscape裁剪svg
参考https://blog.csdn.net/qq_46049113/article/details/123824888,但是上个博主没有图片,不太直观,我补上。 使用inkscape打开需要编辑的图片。 在左边导航栏,点击矩形工具,创建一个矩形包围你想要保留的内容。 如果…...

类加载器加载过程
今天我们就来深入了解一下Java中的类加载器以及它的加载过程。 一、什么是类加载器? 在Java中,类加载器(Class Loader)是一个非常重要的概念。它负责将类的字节码文件(.class文件)加载到Java虚拟机&#x…...

Git基础之基本操作
文件的四种状态 Untracked:未追踪,如新建的文件,在文件夹中,没有添加到git库,不参与版本控制,通过git add将状态变为staged Unmodify:文件已入库,未修改,即版本库中的文件…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

Unity Visual Scripting不是拖拽玩具:中阶开发者的编程范式重构指南
1. 为什么Unity官方Visual Scripting不是“拖拽完就能跑”的玩具,而是一套需要重新理解的编程范式很多人第一次点开Unity的Visual Scripting(VS)面板时,看到那些五颜六色的节点和丝滑的连线,下意识觉得:“这…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...
)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)在科幻题材的游戏开发中,激光雷达扫描特效是营造科技感的经典元素。从《赛博朋克2077》的战术目镜到《看门狗》的环境扫描,这种动态…...