【C语言】自定义类型:结构体,联合,枚举(上)
前言:在C语言中除了我们经常使用的数据(int,float,double类型)等这些类型以外,还有一种类型就是自定义类型,它包括结构体,联合体,枚举类型。为什么要有这种自定义类型呢?假设我们想描述一本书,一个学生这时候使用上面那种单一内置类型是不行的所以为了解决这些问题C语言就增加了自定义类型。
文章目录
- 一,结构体
- 1,结构体的声明定义和初始化
- 2,特殊声明和初始化
- 1,特殊声明
- 2,特殊初始化
- 二,结构体成员访问操作符
- 1,直接访问
- 2,间接访问
- 三,结构体的自引用
- 四,结构体的内存对齐
- 1,对齐数
- 2,修改默认对齐数
- 五,结构体传参
- 六,结构体实现位段
- 1,什么是位段
- 2,位段的内存分配
- 3,位段的跨平台问题
- 4,位段的应用
- 5,使用位段的注意事项
一,结构体
那什么是结构体呢?
结构是⼀些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量,如: 标量、数组、指针,甚至是其他结构体。
看到结构体就想到了数组,为什么会想到数组呢?因为数组与其非常相似,下面我们用一张表格来看看结构体与数组的区别是什么:
| 结构体 | 数组 |
|---|---|
| 是一个集合 | 也是一个集合 |
| 有自己的成员 | 也有自己的成员 |
| 每个成员的类型不同 | 每个成员的类型相同 |
了解完以上的知识我们知道了结构体也与数组类似有自己的成员,但结构体每个成员的类型不同。那该如声明和初始化呢?
1,结构体的声明定义和初始化
struct tag
{member-list;
}varible-list;
什么意思呢?
- 首先
struct是结构体的关键字。 - 其次
tag是结构体类型的名字。 member-list就是成员列表包含一个或或者多个成员。-
varible-list结构体变量的列表(可以不用)。
下面举个例子我们来创建一个描述学生的结构体
#include<stdio.h>
//结构体变量定义
struct student//结构体的声明
{char name[10];int age;char sex[6];
}p1;//定义一个结构体变量 这是全局变量struct student s2={"lisi",20,"women"};//为全局变量初始化
//初始化
int main()
{//按照结构体成员顺序初始化struct student s1 = { "zhangsan",18,"man" };//不按照结构体成员顺序初始化 按照指定的顺序初始化struct student s3={.age=20,.name="wangwu",.sex="man"};printf("%s %d %s\n", s1.name, s1.age,s1.sex);printf("%s %d %s\n", s2.name, s2.age,s2.sex);return 0;
}

我们调试起来让大家看,s1和s2均已被初始化这里初始化我们依然也想数组初始化一样使用大括号{}。除了按照结构体成员初始化;还有按照指定顺序初始化,按照指定顺序初始化需要使用
. 操作符。
还有一点要注意就是p1这个结构体变量是在创建结构体的时候顺便创建的它与s1和s2本质上没有任何区别所以是可以省略的!
当然我们也可以打印让大家看看结果,但这就用到了 . 操作符 我们稍后会介绍。

介绍完结构体正常的定义以及初始化我们就介绍一下特殊情况的声明和初始化:
2,特殊声明和初始化
1,特殊声明
上面我们在创建结构体的时候会给结构体进行命名比如我们上面创建学生的结构体,那能不能不命名呢?答案是可以的,这就变成了一种匿名结构体类型,即对结构体进行特殊的声明。
举个例子:
struct //匿名结构体类型
{int n;char b;float c;
}x = {4,60,6.0};//定义一个结构体变量x struct //匿名结构体类型
{int n;char b;float c;
}*p;//定义一个结构体指针变量 与普通指针变量的创建一样int main()
{//struct x ={ 4,60,6.0 };//这样的操作可行吗?//struct s ={ 4,60,6.0 };//这样的操作可行吗?//p = &x;//这样的操作可行吗?printf("%d %d %f", x.n, x.b, x.c);return 0;
}
我们来解释一下上面的问题,首先
struct x与struct s来创建变量这样的操作是不可行的。因为使用的是匿名结构体,结构体都没有名字了所以是不能创建变量的;只有在匿名结构体创建之初让结构体顺带创建变量,结构体变量才能被创建,比如匿名结构体变量x。
再来说说初始化,既然匿名结构体的变量不能在main函数中创建自然也不能初始化了,要想给匿名结构体变量初始化只能在匿名结构体变量创建之初创建结构体变量然后给他初始化。
我们创建了两个匿名结构体,在第一个匿名结构体末尾创建了一个变量x,在第二个匿名结构体末尾创建了一个指针变量p,我们发现两个结构体的成员都相同说能不能将x的地址给p呢?
我们编译代码发现有警告说从*到*的类型不兼容,什么意思呢?
因为我们认为他们都是匿名结构体类型,类型相同;其次,他们的成员也相同就以为他们是相同的。其实不然,他们是两种不同的结构体类型,这也就得出了一个重要的结论就是,匿名结构体类型只能被使用一次(唯一性)!!!为什么这么说呢?因为按照我们平常创建的内置类型的变量,比如创建int a则a被创建出来他的类型就是不变的了,它不是只能使用一次可以使用多次且类型都是整型,不像匿名结构体类型,创建一个匿名结构体再创建一个与上一个相同的匿名结构体他们的类型就不一样了。

2,特殊初始化
想到函数可以嵌套,if语句可以嵌套,循环语句可以嵌套,那我们就会想到结构体能不能嵌套呢?答案也是可以的。
//定义一个描述学生的结构体
struct stu
{char name[10];int age;struct ID id;char sex[6];
};
struct Id
{char id[10];
};
int main()
{struct stu s1={"zhangsan",18,{"241603021"},"man"};printf("%s %d %s %s", s1.name, s1.age, s1.id.id, s1.sex);return 0;
}
以上面那个学生结构的例子再创建一个嵌套的结构体,在给嵌套结构体初始化的时候别忘记再加上一个{ }大括号。在访问id这个成员时,由于id又是一个结构体所以我们要用两次.id来得到第二个结构体的成员!
这就是特殊情况的初始化。
了解了以上的知识怎么使用这些结构体的成员呢?下面就来介绍一下结构体成员访问操作符。
二,结构体成员访问操作符
访问结构体成员有两种方式
- 一种是直接访问
- 一种是间接访问
1,直接访问
其实在上面我们就已经做了铺垫,使用过了 .操作符 这个操作符是专门用来访问结构体成员的操作符。举个例子:
struct S
{int a;char b[15];
};
int main()
{//为结构体成员初始化struct S s1 = { 20,"hello" };//打印更改前的数据printf("%d %s\n", s1.a, s1.b);//更改结构体成员的值s1.a = 40;//更改成员变量1的值strcpy(s1.b, "hello bit");//使用字符串拷贝函数 更改成员2//打印更改后的成员值printf("%d %s\n", s1.a, s1.b);return 0;
}

我们可以很直观的看到,成员已经被修改。
所以
.操作符的使用规则就是使用 **结构体变量.成员名**就可以得到结构体的成员变量了。
2,间接访问
我们前面已经学过了指针,并且知道指针可以间接的来访问内存,那我们是不是使用结构体指针就能间接访问结构体呢?没错,结构体的间接访问就是通过结构体指针来实现的但要借助一个操作符 -> ,怎么使用呢?举个例子:
struct S
{int x;int y;
};
int main()
{//创建一个结构体变量struct S s1 = { 10,20 };struct S* p = &s1;//将结构体变量s1的地址存到指针变量p里面去 然后使用结构体指针进行更改成员变量的值//打印更改前的数据printf("更改前:%d %d\n",p->x, p->y);//更该数据p->x = 30;p->y = 40;//打印更改后的数据printf("更改后:%d %d\n", p->x, p-> y);return 0;
}
从结果我们也能看到,结构体成员的值被修改了。
所以操作符
->使用的规则是结构体指针->成员名这样就拿到结构体成员的变量了,不知各位读者看出来没有,这种操作很形象形象,p->成员名很形象的展示了指针变量p指向了结构体的某某成员。
三,结构体的自引用
看到自引用我们就想到之前学的递归函数;递归函数就是可以自己调用自己;那结构体能不能自己引用自己呢?答案是可以的,那如何自引用呢?
举个例子:
定义一个链表的节点:
由于链表涉及数据结构的知识这里直接给出概念:
链表是一种常见的数据结构,由一个个节点组成,每个节点包含两部分:数据和指向下一个节点的指针。节点之间通过指针来建立联系,形成一个线性的数据序列。

struct Node
{int data;struct Node next;
};
我们来分析代码,这样的代码显然是不行的,首先节点包含数据和指针两个部分,但是上面的代码只有数据部分却没有指针,如果我们去计算这个结构体的大小会发现是计算不出来的,因为结构体一直包含一个跟他相同的结构体无限套娃无穷无尽。
那要如何更改呢?变成指针就好了:
struct Node
{int data;struct Node *next;
};
那下面的代码可行吗?
typedef struct
{ int data; Node* next;
}Node;
使用typedef重命名为Node然后再用Node去创建指针变量这样做可行吗?显然是不可行的前面也说过匿名结构体只能使用一次,再用Node去创建结构体指针的时候就会报错“Node未定义”。 要想修改也很简单定义结构体不要使用匿名结构体!
typedef struct NOde
{ int data; struct Node* next;
}Node;
四,结构体的内存对齐
1,对齐数
我们首先来看一段代码,下面代码计算结构体的大小等于多少呢?
#include<stdio.h>
struct S1 //创建一个结构体
{char a;int b;char c;
};
struct S2
{char a;char b;int c;
};
int main()
{printf("%zd\n",sizeof(struct S1));printf("%zd\n",sizeof(struct S2));return 0;
}
有些读者就疑惑了,不同样都是两个char类型一个int类型吗?再不济他们所占的内存因该也都是一样的才对?我们将结果打印出来:

答案完全与读者想的不一样,这是为什么呢?这就是因为结构体中存在内存对齐的现象这才导致了虽然结构体成员的类型均相同但计算的内存大小不同。
下面我们就来分析一下为什么得到这样的结果:
在分析之前我们先要了解结构体的对齐规则:
- 结构体的第⼀个成员对齐到和结构体变量起始位置偏移量为0的地址处
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。 对齐数 = 编译器默认的⼀个对齐数 与 该成员变量大小的较小值。(vs中默认对齐数是8)
- 结构体总大小为最大对齐数(结构体中每个成员变量都有⼀个对齐数,所有对齐数中最大的)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍。
光看文字可能不好理解我们直接配合代码画图来让大家更好的理解这些规则:
在此之前我们首先要知道结构体成员相较于结构体起始位置的偏移量,这就用到一个函数叫offsetof宏。在使用ofssetof宏时要包含头文件<stddef.h>。
struct S1 //创建一个结构体
{char a;int b;char c;
};
struct S2
{char a;char b;int c;
};
int main()
{struct S1 s1;printf("%d\n", offsetof(struct S1, a));printf("%d\n", offsetof(struct S1, b));printf("%d\n", offsetof(struct S1, c));return 0;
}

拿到了每个成员对于结构体其实位置的偏移量后我们就可以来分析结构体内存对齐了:

接着我们来分析S2:

再给出一个例子:
#include<stddef.h>
struct S3
{ double d; char c; int i;};
int main()
{//printf("%d\n", sizeof(struct S3));printf("%d\n",offsetof(struct S3,d));printf("%d\n",offsetof(struct S3,c));printf("%d\n",offsetof(struct S3,i));return 0;
}

看到这里有读者可能会疑惑,上面的代码都只用到了前撒种对齐规则并没给有用到第4种对齐规则,如果你能够问出这样的问题那就说明你看得很仔细,接下来我们就来说说第4种规则的情形:
struct S3
{double d;char c;int i;
};
struct S4
{ char c1; struct S3 s3; double d;
};
int main()
{//printf("%d\n", sizeof(struct S4));printf("%d\n",offsetof(struct S4,c1));printf("%d\n",offsetof(struct S4,s3));printf("%d\n",offsetof(struct S4,d));return 0;
}请问上面的代码结构体内存大小是多少呢?我们给出分析:

*
以上就是有关结构体的内存对齐。这时就会有人好奇说为什么会有结构体的内存对齐呢?这样做的意义是什么呢?
举个例子你就能明白了:

上面的例子很直观能感受到不对齐和对齐的区别,内存对齐比不对齐读取空间的效率更高。实际上结构体内存对齐还有其他的一些原因这里简单列举一些:
- 平台原因 (移植原因): 不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定 类型的数据,否则抛出硬件异常。
- 性能原因,即我们上面例子提到的为了能够让处理器更加高效的读取数据。
·总的来说结构体内存对齐就是用空间换取时间的做法,如果我们既想满足内存对齐又想尽量节省空间那么就要将空间小的成员尽量集中在一起,比如上面最开始分析的S1和S2仅仅是因为成员的位置不同就造成了内存的差异!
2,修改默认对齐数
上面我们说了我们既想满足内存对齐又想尽量节省空间那么就要将空间小的成员尽量集中在一起,那还有没有别的方法呢?或者说对齐数能不能修改呢?
答案是可以的,只需要一个#pragma这个预处理指令就可以完成了,下面看例子:
#include<stdio.h>
#include<stddef.h>
#pragma pack(2)//设置默认对齐数为2
struct S1
{char a;int b;char c;
};
#pragma pack()//取消设置的对齐数,还原为默认
int main()
{struct S1 s1;printf("%zd\n",sizeof(struct S1);
}

我看到S1的大小发生了改变,在还没修改对齐数之前结构体S1的大小为12,修改后变成了8,这就达到了节省空间的效果。具体分析可以参照上面的分析,分析方法一样这里就不再分析了。
·但有一点要注意的是,如果我们将默认对齐数修改成了1,此时就不对齐了;原因也很简单对齐数为1所有地址都是它的倍数所以结构体成员就是依次存放的,所以cpu在读取数据的时候由于不对齐可能读取2次,3次都有可能时间开销就会很大。
五,结构体传参
我们见过函数传参,数组传参,那结构体能不能进行传参呢?答案是可以的,来看个例子:
struct S
{int date[1000];int num;
};
void Print1(struct S s)
{printf("Print1:");int i = 0;for (i = 0;i < 5;i++){printf("%d", s.date[i]);}printf("\n");printf("%d\n", s.num);
}
void Print2(struct S* ps)
{printf("Print2:");int i = 0;for (i = 0;i < 5;i++){printf("%d", ps->date[i]);}printf("\n");printf("%d\n", ps->num);
}
int main()
{struct S s = { {1,2,3,4,5},100 };//写一个函数来打印结构体Print1(s);//传值调用//函数2Print2(&s);//传址调用return 0;
}
观察上面的代码是第一种传参好,还是第二种传参好呢?
答案是第二种即传址调用,在之前的文章给大家讲过传值调用形参是实参的一份临时拷贝,在上面的例子中Print1为了接实参需要临时开辟一个4000多字节的空间,而Print2只需要创建一个结构体指针变量来接收s的地址,而p本身的大小也就是4或8个字节(因为地址的大小就是4或8个字节)。所以从空间分配的角度,Print2更好。但这时可能有人担心传址调用结构体成员会被修改,其实我们只需要在指针变量前加上cont修饰就可以了,这点在指针篇也具体介绍过。
所以得出结论:结构体传参的时候,要传结构体的地址。
六,结构体实现位段
1,什么是位段
位段中的位说的就是二进制位,即一个比特位。
位段的声明和结构是类似的,有两个不同:
- 位段的成员必须是 int、unsigned int 或signed int ,在C99中位段成员的类型也可以 选择其他类型。
- 位段的成员名后边有⼀个冒号和⼀个数字。
举个例子:
struct A
{ int _a:2; int _b:5; int _c:10; int _d:30;
};
这就是位段,与结构体相比区别就是比结构体的成员多了冒号和数字,可能还是有人不理解为什么要这样做,没关系我们逐步探索。首先先将这个位段的大小打印出来:
struct A
{ int _a:2; int _b:5; int _c:10; int _d:30;
};
int main()
{printf("sizeof(struct A)");return 0;
}

看到这有人又会疑惑了,说4个整型打印出来的大小不应该是12吗?怎么会是8呢?所以这就要探究一下位段在内存中是怎样存放的了:
2,位段的内存分配
- 位段的成员可以是 int unsigned int signed int 或者是 char 等类型
- 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的⽅式来开辟的。
- 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使⽤位段。
举个例子:
struct S
{ char a:3; char b:4; char c:5; char d:4;
};
int main()
{struct S s = {0}; printf("%d\n", sizeof(struct S));s.a = 10; s.b = 12;s.c = 3; s.d = 4;return 0;
}
上面的代码的空间是如何开辟的?
我们给出分析:


通过结果我们可以看出是第二种的存储情况,但还没有分析完,开辟完空间后还需要将值给存放进去我们来看看是如何存放的:

我们调试一起来验证一下:

调试出来的结果与我们想的一样所以可以验证就是这样存放的。到这就可以回答我们上面的问题,位段就是通过限制二进制位来达到节省空间的目的,但前提是我们存储的数比较小。
比如10这个数能使用4个比特位去存就不用去花费32个比特位的空间去存放它。
3,位段的跨平台问题
- int 位段被当成有符号数还是⽆符号数是不确定的。
- 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机器会 出问题。
- 位段中的成员在内存中从左向右分配,还是从右向左分配,标准尚未定义。
- 当⼀个结构包含两个位段,第二个位段成员比较大,无法容纳于第⼀个位段剩余的位时,是舍弃 剩余的位还是利用,这是不确定的。
总结: 跟结构相比,位段可以达到同样的效果,并且可以很好的节省空间,但是有跨平台的问题存在。
4,位段的应用

5,使用位段的注意事项
在使用位段时要注意,有些成员的起始位置并不是某个字节的起始位置,那么这些位置是没有地址的。其实很好理解我们上面分析的都是比特位,比特位是没有地址的,计算机地址分配的最小内存是一个字节。
既然没有地址,那么自然就不能使用取地址&操作符了,所以不能对位段的成员使⽤&操作符,这样就不能使⽤scanf直接给位段的成员输⼊值,只能是先输⼊
放在⼀个变量中,然后赋值给位段的成员
举个例子:
struct A
{ int _a : 2; int _b : 5; int _c : 10; int _d : 30;
};
int main()
{ struct A sa = {0}; scanf("%d", &sa._b);//这是错误的 //正确的⽰范 int b = 0; scanf("%d", &b); sa._b = b; return 0;
}
好了以上就是本章的全部内容啦!
最后感谢能够看到这里的读者,如果我的文章能够帮到你那我甚是荣幸,文章有任何问题都欢迎指出!制作不易还望给一个免费的三连,你们的支持就是我最大的动力!

相关文章:
【C语言】自定义类型:结构体,联合,枚举(上)
前言:在C语言中除了我们经常使用的数据(int,float,double类型)等这些类型以外,还有一种类型就是自定义类型,它包括结构体,联合体,枚举类型。为什么要有这种自定义类型呢?假设我们想描…...

SQLiteStudio:一款免费跨平台的SQLite管理工具
SQLiteStudio 是一款专门用于管理和操作 SQLite 数据库的免费工具。它提供直观的图形化界面,简化了数据库的创建、编辑、查询和维护,适合数据库开发者和数据分析师使用。 功能特性 SQLiteStudio 提供的主要功能包括: 免费开源,可…...
配置参数说明)
Mysql配置文件My.cnf(my.ini)配置参数说明
一、my.cnf 配置文件路径:/etc/my.cnf,在调整了该文件内容后,需要重启mysql才可生效。 1、主要参数 basedir path # 使用给定目录作为根目录(安装目录)。 datadir path # 从给定目录读取数据库文件。 pid-file filename # 为mysq…...

聊天模型集成指南
文章目录 聊天模型集成指南Anthropic聊天模型集成PaLM2聊天模型PaLM2API的核心功能OpenAl聊天模型集成聊天模型集成指南 随着GPT-4等大语言模型的突破,聊天机器人已经不仅仅是简单的问答工具,它们现在广泛应用于客服、企业咨询、电子商务等多种场景,为用户提供准确、快速的反…...

搭建农产品管理可视化,助力农业智能化
利用图扑 HT 搭建农产品管理可视化平台,实现从生产到销售的全流程监控。平台通过物联网传感器实时采集土壤湿度、温度、光照等数据,支持智慧大棚的灌溉、施肥、病虫害防治等功能。同时,农产品调度中心大屏可展示市场交易数据、库存状态、物流…...

tee命令
tee 是一个在 Unix/Linux 系统中常用的命令,它用于读取标准输入(stdin),并将其内容同时输出到标准输出(stdout)和文件中。它常用于将命令的输出保存到文件的同时,也显示在终端屏幕上。 基本语法…...

国自然面上项目|基于海量多模态影像深度学习的肝癌智能诊断研究|基金申请·25-03-07
小罗碎碎念 今天和大家分享一个国自然面上项目,执行年限为2020.01~2023.12,直接费用为65万元。 该项目旨在利用多模态医学影像,通过深度学习技术,解决肝癌诊断中的难题,如影像的快速配准融合、海量特征筛选…...

「勾芡」和「淋明油」是炒菜收尾阶段提升菜品口感和观感的关键操作
你提到的「勾芡」和「淋明油」是炒菜收尾阶段提升菜品口感和观感的关键操作,背后涉及食品科学中的物理化学变化。以下从原理到实操的深度解析: 一、勾芡:淀粉的“精密控温游戏” 1. 科学原理 淀粉糊化(Gelatinization࿰…...

ROS云课三分钟-差动移动机器人导航报告如何撰写-及格边缘疯狂试探
提示词:基于如上所有案例并结合roslaunch teb_local_planner_tutorials robot_diff_drive_in_stage.launch和上面所有对话内容,设计一个差速移动机器人仿真实验,并完成报告的全文撰写。 差速移动机器人导航仿真实验报告 一、实验目的 验证 T…...

应用案例 | 精准控制,高效运行—宏集智能控制系统助力SCARA机器人极致性能
概述 随着工业4.0的深入推进,制造业对自动化和智能化的需求日益增长。传统生产线面临空间不足、效率低下、灵活性差等问题,尤其在现有工厂改造项目中,如何在有限空间内实现高效自动化成为一大挑战。 此次项目的客户需要在现有工厂基础上进行…...
蓝桥备赛(16)- 树
一、树的概念 1.1 树的定义 1)树型结构(一对多)是⼀类重要的非线性数据结构 2 )有⼀个特殊的结点,称为根结点,根结点没有前驱结点 3)除了根节点外 , 其余结点被分成 M(M…...
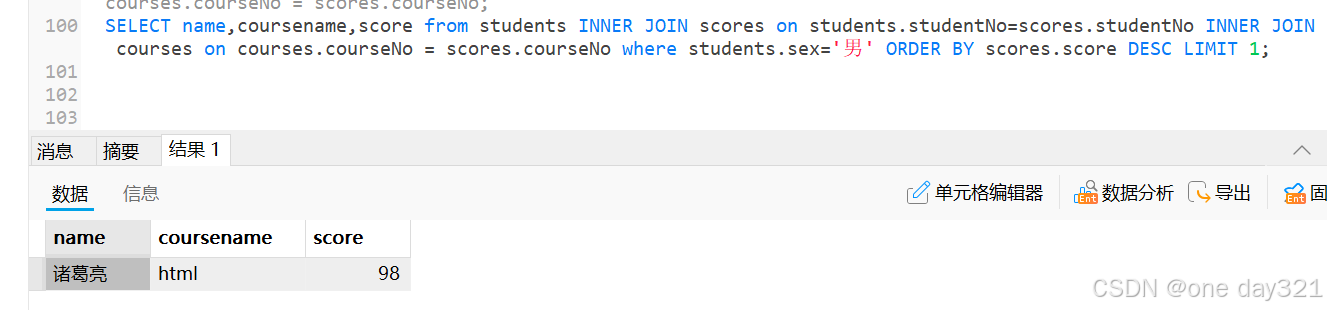
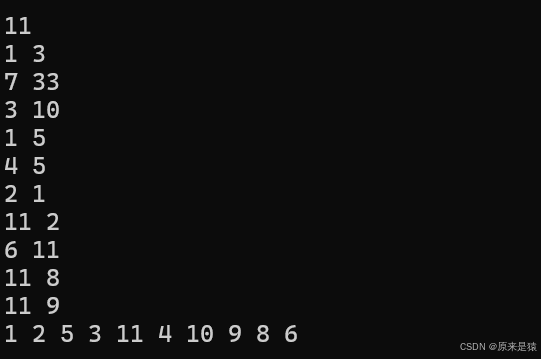
黑马测试mysql基础学习
视频来源:软件测试工程师所需的MySQL数据库技术,mysql系统精讲课后练习_哔哩哔哩_bilibili 环境准备: 虚拟机Linux服务器安装mysql数据库。本机安装Navicat。使Navicat连接虚拟机的数据库。(麻烦一点的是Navicat连接虚拟机的数据…...

ROS2-话题学习
强烈推荐教程: 《ROS 2机器人开发从入门到实践》3.2.2订阅小说并合成语音_哔哩哔哩_bilibili 构建功能包 # create package demo_python_pkg ros2 pkg create --build-type ament_python --license Apache-2.0 demo_python_pkg 自己写的代码放在./demo_python_pkg/…...

C++指针的基本认识
1.数组做函数参数 首先,所有传递给函数的参数都是通过传值方式进行的,传递给函数的都是参数的一份拷贝。 接着,当传递的参数是一个指向某个变量的指针时,函数将对该指针执行间接访问操作(拷贝指针,并访问所指向的内容),则函数就可以修改指向的变量。 2.一维数组 数组名…...

TypeScript系列06-模块系统与命名空间
1. ES 模块与 CommonJS 互操作性 1.1 模块解析策略 TypeScript 提供多种模块解析策略,每种策略针对不同的运行环境和开发场景优化: // tsconfig.json {"compilerOptions": {"moduleResolution": "node16", // 或 "…...
命令详解:zip)
Linux(Centos 7.6)命令详解:zip
1.命令作用 打包和压缩(存档)文件(package and compress (archive) files);该程序用于打包一组文件进行分发;存档文件;通过临时压缩未使用的文件或目录来节省磁盘空间;且压缩文件可以在Linux、Windows 和 macOS中轻松提取。 2.命…...
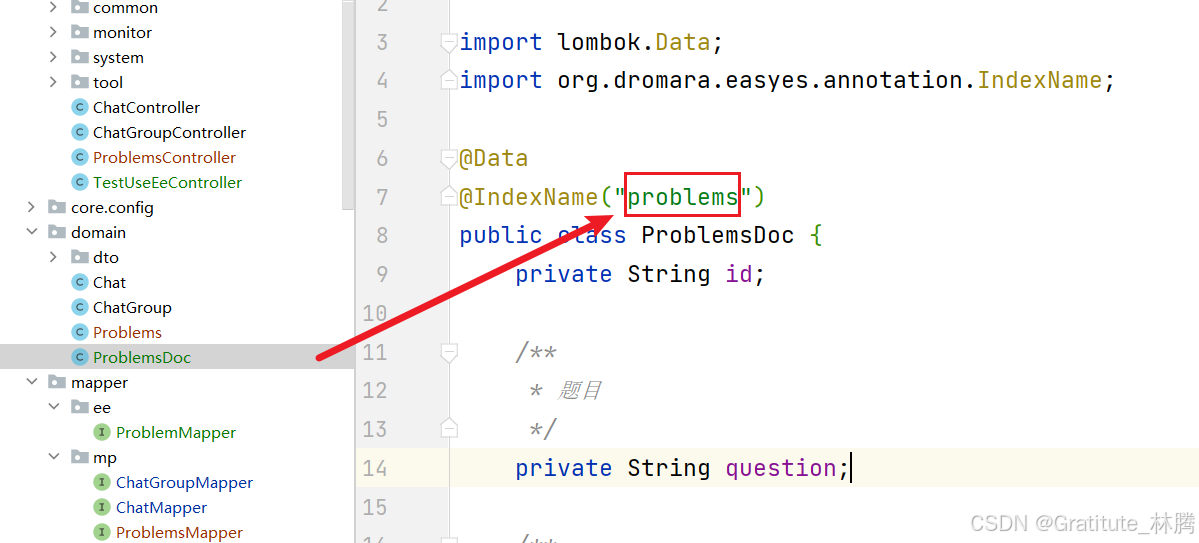
es-使用easy-es时如何指定索引库
在对应的实体类中,通过注解IndexName指定。 如上图,指定的索引库就是problems,那么之后我使用easy-es时都是针对该索引库进行增删改查。...

Redis-主从架构
主从架构 主从架构什么是主从架构基本架构 复制机制的工作原理1. 全量复制(Full Synchronization)2. 部分复制(Partial Synchronization)3. PSYNC2机制(Redis 4.0) 主从架构的关键技术细节1. 复制积压缓冲区…...

Java数据结构第二十期:解构排序算法的艺术与科学(二)
专栏:Java数据结构秘籍 个人主页:手握风云 目录 一、常见排序算法的实现 1.1. 直接选择排序 1.2. 堆排序 1.3. 冒泡排序 1.4. 快速排序 一、常见排序算法的实现 1.1. 直接选择排序 每⼀次从待排序的数据元素中选出最小的⼀个元素,存放在…...
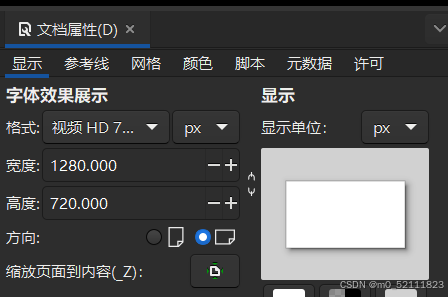
inkscape裁剪svg
参考https://blog.csdn.net/qq_46049113/article/details/123824888,但是上个博主没有图片,不太直观,我补上。 使用inkscape打开需要编辑的图片。 在左边导航栏,点击矩形工具,创建一个矩形包围你想要保留的内容。 如果…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

避坑指南:Unity动态加载模型时,TriLib插件材质丢失、缩放异常的5个常见问题解决
Unity动态加载模型避坑指南:TriLib插件材质丢失与缩放异常的深度解决方案当你在Unity项目中尝试使用TriLib插件动态加载外部模型时,是否遇到过这些令人抓狂的情况:模型加载后材质全部变成刺眼的粉红色,贴图神秘消失,或…...