PyTorch系列教程:编写高效模型训练流程
当使用PyTorch开发机器学习模型时,建立一个有效的训练循环是至关重要的。这个过程包括组织和执行对数据、参数和计算资源的操作序列。让我们深入了解关键组件,并演示如何构建一个精细的训练循环流程,有效地处理数据处理,向前和向后传递以及参数更新。
模型训练流程
PyTorch训练循环流程通常包括:
- 加载数据
- 批量处理
- 执行正向传播
- 计算损失
- 反向传播
- 更新权重
一个典型的训练流程将这些步骤合并到一个迭代过程中,在数据集上迭代多次,或者在训练的上下文中迭代多个epoch。

1. 搭建环境
在编写代码之前,请确保在本地环境中设置了PyTorch。这通常需要安装PyTorch和其他依赖项:
pip install torch torchvision
下面演示为建立一个有效的训练循环奠定了基本路径的示例。
2. 数据加载
数据加载是使用DataLoader完成的,它有助于数据的批量处理:
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])
data_train = datasets.MNIST(root='data', train=True, download=True, transform=transform)
train_loader = DataLoader(data_train, batch_size=64, shuffle=True)
DataLoader在这里被设计为以64个为单位的批量获取数据,在数据传递中进行随机混淆。
3. 模型初始化
一个使用PyTorch的简单神经网络定义如下:
import torch.nn as nn
import torch.nn.functional as Fclass SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(784, 128)self.fc2 = nn.Linear(128, 64)self.fc3 = nn.Linear(64, 10)def forward(self, x):x = x.view(-1, 784)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return F.log_softmax(x, dim=1)
这里,784指的是输入维度(28x28个图像),并创建一个输出大小为10个类别的顺序前馈网络。
4. 建立训练循环
定义损失函数和优化器:为了改进模型的预测,必须定义损失和优化器:
import torch.optim as optimmodel = SimpleNN()
criterion = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
5. 实现训练循环
有效的训练循环的本质在于正确的步骤顺序:
epochs = 5
for epoch in range(epochs):running_loss = 0for images, labels in train_loader:optimizer.zero_grad() # Zero the parameter gradientsoutput = model(images) # Forward passloss = criterion(output, labels) # Calculate lossloss.backward() # Backward passoptimizer.step() # Optimize weightsrunning_loss += loss.item()print(f"Epoch {epoch+1}/{epochs} - Loss: {running_loss/len(train_loader)}")
注意,每次迭代都需要重置梯度、通过网络处理输入、计算误差以及调整权重以减少该误差。
性能优化
使用以下策略提高循环效率:
-
使用GPU:将计算转移到GPU上,以获得更快的处理速度。如果GPU可用,使用to(‘cuda’)转换模型和输入。
-
数据并行:利用多gpu设置与dataparlele模块来分发批处理。
-
FP16训练:使用自动混合精度(AMP)来加速训练并减少内存使用,而不会造成明显的精度损失。
在 PyTorch 中使用 FP16(半精度浮点数)训练 可以显著减少显存占用、加速计算,同时保持模型精度接近 FP32。以下是详细指南:
1. FP16 的优势
- 显存节省:FP16 占用显存是 FP32 的一半(例如,1024MB 显存在 FP32 下可容纳约 2000 万参数,在 FP16 下可容纳约 4000 万)。
- 计算加速:NVIDIA 的 Tensor Core 支持 FP16 矩阵运算,速度比 FP32 快数倍至数十倍。
- 适合大规模模型:如 Transformer、Vision Transformer(ViT)等参数量大的模型。
2. 实现 FP16 训练的两种方式
(1) 自动混合精度(Automatic Mixed Precision, AMP)
PyTorch 的 torch.cuda.amp 自动管理 FP16 和 FP32,减少手动转换的复杂性。
python
import torch
from torch.cuda.amp import autocast, GradScalermodel = model.to("cuda") # 确保模型在 GPU 上
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
scaler = GradScaler() # 梯度缩放器for data, target in dataloader:data = data.to("cuda").half() # 输入转为 FP16target = target.to("cuda")with autocast(): # 自动切换 FP16/FP32 计算output = model(data)loss = criterion(output, target)scaler.scale(loss).backward() # 梯度缩放scaler.step(optimizer) # 更新参数scaler.update() # 重置缩放器
关键点:
autocast()内部自动将计算转换为 FP16(若 GPU 支持),梯度累积在 FP32。GradScaler()解决 FP16 下梯度下溢问题。
(2) 手动转换(低级用法)
直接将模型参数、输入和输出转为 FP16,但需手动管理精度和稳定性。
python
model = model.half() # 模型参数转为 FP16
for data, target in dataloader:data = data.to("cuda").half() # 输入转为 FP16target = target.to("cuda")output = model(data)loss = criterion(output, target)optimizer.zero_grad()loss.backward()optimizer.step()
缺点:
- 可能因数值不稳定导致训练失败(如梯度消失)。
- 不支持动态精度切换(如部分层用 FP32)。
3. FP16 训练的注意事项
(1) 设备支持
- NVIDIA GPU:需支持 Tensor Core(如 Volta 架构以上的 GPU,包括 Tesla V100、A100、RTX 3090 等)。
- AMD GPU:部分型号支持 FP16 计算,但 AMP 功能受限(需使用
torch.backends.cudnn.enabled = False)。
(2) 学习率调整
- FP16 的初始学习率通常设为 FP32 的 2~4 倍(因梯度放大),需配合学习率调度器(如
CosineAnnealingLR)。
(3) 损失缩放(Loss Scaling)
-
FP16 的梯度可能过小,导致
update()时下溢。解决方案:- 自动缩放:使用
GradScaler()(推荐)。 - 手动缩放:将损失乘以一个固定因子(如
1e4),反向传播后再除以该因子。
- 自动缩放:使用
(4) 模型初始化
- FP16 参数初始化值不宜过大,否则可能导致
nan。建议初始化时用 FP32,再转为 FP16。
(5) 检查数值稳定性
- 训练过程中监控损失是否为
nan或无穷大。 - 可通过
torch.set_printoptions(precision=10)打印中间结果。
4. FP16 vs FP32 精度对比
| 模型 | FP32 精度损失 | FP16 精度损失 |
|---|---|---|
| ResNet-18 | 微小 | 可忽略 |
| BERT-base | 微小 | ~1-2% |
| GPT-2 | 微小 | ~3-5% |
结论:多数任务中 FP16 的精度损失可接受,但需通过实验验证。
5. 常见错误及解决
| 错误现象 | 解决方案 |
|---|---|
RuntimeError: CUDA error: out of memory | 减少 batch size 或清理缓存 (torch.cuda.empty_cache()) |
nan 或 inf | 调整学习率、检查数据预处理、启用梯度缩放 |
InvalidArgumentError | 确保输入数据已正确转换为 FP16 |
- 推荐使用
autocast+GradScaler:平衡易用性和性能。 - 优先在 NVIDIA GPU 上使用:AMD GPU 的 FP16 支持较弱。
- 从小批量开始测试:避免显存不足或数值不稳定。
通过合理配置,FP16 可以在几乎不损失精度的情况下显著提升训练速度和显存利用率。
最后总结
高效的训练循环为优化PyTorch模型奠定了坚实的基础。通过遵循适当的数据加载过程,模型初始化过程和系统的训练步骤,你的训练设置将有效地利用GPU资源,并通过数据集快速迭代,以构建健壮的模型。
相关文章:
PyTorch系列教程:编写高效模型训练流程
当使用PyTorch开发机器学习模型时,建立一个有效的训练循环是至关重要的。这个过程包括组织和执行对数据、参数和计算资源的操作序列。让我们深入了解关键组件,并演示如何构建一个精细的训练循环流程,有效地处理数据处理,向前和向后…...

【面试】Zookeeper
Zookeeper 1、ZooKeeper 介绍2、znode 节点里面的存储3、znode 节点上监听机制4、ZooKeeper 集群部署5、ZooKeeper 选举机制6、何为集群脑裂7、如何保证数据一致性8、讲一下 zk 分布式锁实现原理吧9、Eureka 与 Zk 有什么区别 1、ZooKeeper 介绍 ZooKeeper 的核心特性 高可用…...

电力系统中各参数的详细解释【智能电表】
一、核心电力参数 电压 (Voltage) 单位:伏特(V) 含义:电势差,推动电流流动的动力 类型:线电压(三相系统)、相电压,如220V(家用)或380Vÿ…...
)
前端系统测试(单元、集成、数据|性能|回归)
有关前端测试的面试题 系统测试 首先,功能测试部分。根据资料,单元测试是验证最小可测试单元的正确性,比如函数或组件。都提到了单元测试的重要性,强调其在开发早期发现问题,并通过自动化提高效率。需要整合我搜索到的资料中的观点,比如单元测试的方法(接口测试、路径覆…...

软件开发过程总揽
开发模型 传统开发模型 瀑布模型 #mermaid-svg-yDNBSwh3gDYETWou {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-yDNBSwh3gDYETWou .error-icon{fill:#552222;}#mermaid-svg-yDNBSwh3gDYETWou .error-text{fill:#…...

VBA第二十期 VBA最简单复制整张表格Cells的用法
前面讲过复制整张表格的方法,使用语句Workbooks("实例.xlsm").Sheets("表格1").Copy Workbooks(wjm).Sheets(1)实现,这里用我们熟悉的Cells属性也可以实现整表复制。实例如下: Sheets("全部").Activate Cells…...

Redis为什么要自定义序列化?如何实现自定义序列化器?
在 Redis中,通常会使用自定义序列化器,那么,Redis为什么需要自定义序列化器,该如何实现它? 1、为什么需要自定义序列化器? 整体来说,Redis需要自定义序列化器,主要有以下几个原因&…...

Matlab:矩阵运算篇——矩阵数学运算
目录 1.矩阵的加法运算 实例——验证加法法则 实例——矩阵求和 实例——矩阵求差 2.矩阵的乘法运算 1.数乘运算 2.乘运算 3.点乘运算 实例——矩阵乘法运算 3.矩阵的除法运算 1.左除运算 实例——验证矩阵的除法 2.右除运算 实例——矩阵的除法 ヾ( ̄…...

手写一个Tomcat
Tomcat 是一个广泛使用的开源 Java Servlet 容器,用于运行 Java Web 应用程序。虽然 Tomcat 本身功能强大且复杂,但通过手写一个简易版的 Tomcat,我们可以更好地理解其核心工作原理。本文将带你一步步实现一个简易版的 Tomcat,并深…...

开发ai模型最佳的系统是Ubuntu还是linux?
在 AI/ML 开发中,Ubuntu 是更优选的 Linux 发行版,原因如下: 1. 开箱即用的 AI 工具链支持 Ubuntu 预装了主流的 AI 框架(如 TensorFlow、PyTorch)和依赖库,且通过 apt 包管理器可快速部署开发环境。 提…...

Scala 中生成一个RDD的方法
在 Scala 中,生成 RDD(弹性分布式数据集)的主要方法是通过 SparkContext(或 SparkSession)提供的 API。以下是生成 RDD 的常见方法: 1. 从本地集合创建 RDD 使用 parallelize 方法将本地集合(如…...
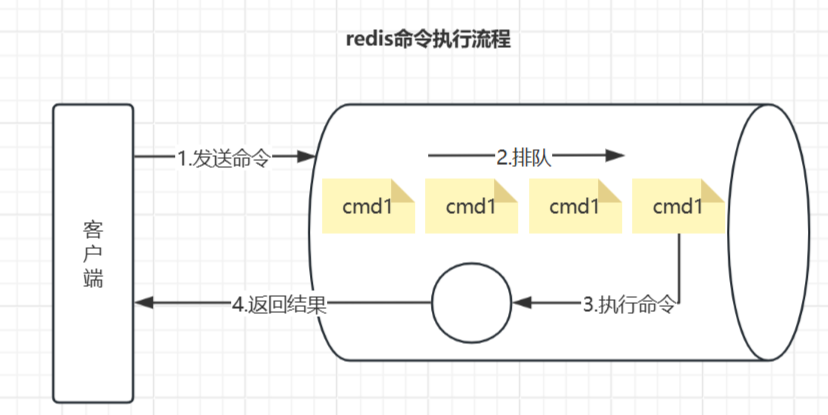
【redis】慢查询分析与优化
慢查询指在Redis中执行时间超过预设阈值的命令,其日志记录是排查性能瓶颈的核心工具。Redis采用单线程模型,任何耗时操作都可能阻塞后续请求,导致整体性能下降。 命令的执行流程 根据Redis的核心机制,命令执行流程可分为以下步骤…...

P8925 「GMOI R1-T2」Light 题解
P8925 「GMOI R1-T2」Light 让我们好好观察样例解释的这一张图: 左边第 1 1 1 个像到 O O O 点的距离 : L 2 2 L L\times22L L22L 右边第 1 1 1 个像到 O O O 点的距离 : R 2 2 R R\times22R R22R 左边第 2 2 2 个像到 O O O 点…...

Spring Boot + MyBatis + MySQL:快速搭建CRUD应用
一、引言 1. 项目背景与目标 在现代Web开发中,CRUD(创建、读取、更新、删除)操作是几乎所有应用程序的核心功能。本项目旨在通过Spring Boot、MyBatis和MySQL技术栈,快速搭建一个高效、简洁的CRUD应用。我们将从零开始ÿ…...

python中os库的常用举例
os 库是Python中用于与操作系统进行交互的标准库,以下是一些 os 库的常用示例: 获取当前工作目录 python import os current_dir os.getcwd() print(current_dir) os.getcwd() 函数用于获取当前工作目录的路径。 列出目录内容 python import os …...

Unity 通用UI界面逻辑总结
概述 在游戏开发中,常常会遇到一些通用的界面逻辑,它不论在什么类型的游戏中都会出现。为了避免重复造轮子,本文总结并提供了一些常用UI界面的实现逻辑。希望可以帮助大家快速开发通用界面模块,也可以在次基础上进行扩展修改&…...

Python3 与 VSCode:深度对比分析
Python3 与 VSCode:深度对比分析 引言 Python3 和 Visual Studio Code(VSCode)在软件开发领域扮演着举足轻重的角色。Python3 作为一门强大的编程语言,拥有丰富的库和框架,广泛应用于数据科学、人工智能、网络开发等多个领域。而 VSCode 作为一款轻量级且功能强大的代码…...

第五课:Express框架与RESTful API设计:技术实践与探索
在使用Node.js进行企业应用开发,常用的开发框架Express,其中的中间件、路由配置与参数解析、RESTful API核心技术尤为重要,本文将深入探讨它们在应用开发中的具体使用方法,最后通过Postman来对开发的接口进行测试。 一、Express中…...

Linux 内核自定义协议族开发:从 “No buffer space available“ 错误到解决方案
引言 在 Linux 内核网络协议栈开发中,自定义协议族(Address Family, AF)是实现新型通信协议或扩展内核功能的关键步骤。然而,开发者常因对内核地址族管理机制理解不足,遇到如 insmod: No buffer space available 的错误。本文将以实际案例为基础,深入分析错误根源,并提…...

html-列表标签和表单标签
一、列表标签 表格是用来显示数据的,那么列表就是用来布局的 列表最大的特点就是整齐、整洁、有序,它作为布局会更加自由和方便。 根据使用情景不同,列表可以分为三大类:无序列表、有序列表和自定义列表。 1.无序列表(重…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

Metabase:零代码 BI 数据可视化工具,自建数据看板
Metabase:零代码 BI 数据可视化工具,自建数据看板 在数据驱动决策的时代,能快速看到业务数据的变化趋势至关重要。然而,专业 BI 工具(如 Tableau、Power BI)价格昂贵,而让每个业务同学都学 SQL …...

全方位梳理 OpenClaw 部署与使用干货
OpenClaw 一键安装包|可视化部署,简化环境配置流程 ✨适配系统:Windows10/11 64 位 当前版本:v2.7.5(虾壳云版) ✨核心优势:全程可视化操作,不用命令行、不用手动配置 Python/Node…...