(ECCV2018)CBAM改进思路
论文链接:https://arxiv.org/abs/1807.06521
论文题目:CBAM: Convolutional Block Attention Module
会议:ECCV2018
论文方法
利用特征的通道间关系生成了一个通道注意图。 由于特征映射的每个通道被认为是一个特征检测器,通道注意力集中在给定输入图像的“什么”是有意义的。 为了有效地计算通道注意力,我们压缩了输入特征映射的空间维度。 对于空间信息的聚合,目前普遍采用平均池化方法。 除了之前的工作,我们认为最大池化收集了另一个关于不同对象特征的重要线索,以推断更精细的通道明智的注意力。 因此,作者同时使用平均池化和最大池化特征。
利用特征的空间间关系生成空间注意图。 与通道注意不同的是,空间注意关注的“在哪里”是信息部分,与通道注意是互补的。 为了计算空间注意力,首先沿着通道轴应用平均池化和最大池化操作,并将它们连接起来以生成有效的特征描述符。 沿着通道轴应用池操作可以有效地突出显示信息区域。 在连接的特征描述符上,应用卷积层生成空间注意映射Ms(F)∈RH×W,该映射编码强调或抑制的位置。

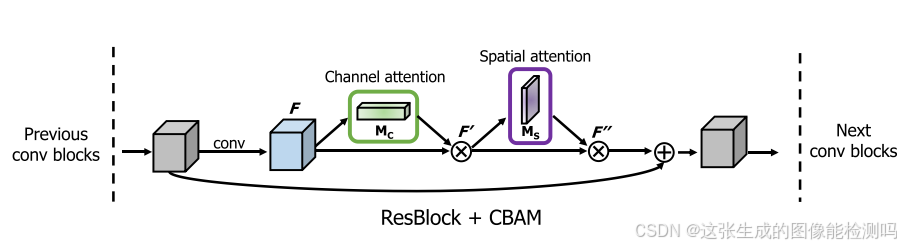
论文源代码
import torch
import torch.nn.functional as F
import torch.nn as nnclass ChannelAttention(nn.Module):def __init__(self, in_channels, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc = nn.Sequential(nn.Conv2d(in_channels, in_channels // ratio, 1, bias=False),nn.ReLU(inplace=True),nn.Conv2d(in_channels // ratio, in_channels, 1, bias=False)) self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc(self.avg_pool(x))max_out = self.fc(self.max_pool(x))out = avg_out + max_outout = self.sigmoid(out)return out * xclass SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)out = torch.cat([avg_out, max_out], dim=1)out = self.sigmoid(self.conv1(out))return out * xclass CBAM(nn.Module):def __init__(self, in_channels, ratio=16, kernel_size=3):super(CBAM, self).__init__()self.channelattention = ChannelAttention(in_channels, ratio=ratio)self.spatialattention = SpatialAttention(kernel_size=kernel_size)def forward(self, x):x = self.channelattention(x)x = self.spatialattention(x)return x
改进思路
1.通道注意力独立分支与批归一化
使用独立的FC层处理平均池化和最大池化,增强表达能力。
在FC层之间加入批归一化,加速训练收敛。
class ChannelAttention(nn.Module):def __init__(self, in_channels, ratio=16):super().__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)# 独立的全连接层分支self.fc_avg = nn.Sequential(nn.Conv2d(in_channels, in_channels//ratio, 1, bias=False),nn.BatchNorm2d(in_channels//ratio), # 添加BNnn.ReLU(inplace=True),nn.Conv2d(in_channels//ratio, in_channels, 1, bias=False),nn.BatchNorm2d(in_channels) # 输出层也可以考虑BN)self.fc_max = nn.Sequential(nn.Conv2d(in_channels, in_channels//ratio, 1, bias=False),nn.BatchNorm2d(in_channels//ratio),nn.ReLU(inplace=True),nn.Conv2d(in_channels//ratio, in_channels, 1, bias=False),nn.BatchNorm2d(in_channels))self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc_avg(self.avg_pool(x))max_out = self.fc_max(self.max_pool(x))out = self.sigmoid(avg_out + max_out)return x * out
2.空间注意力深度增强
使用多层卷积增加非线性。
引入残差连接提升梯度流动。
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()padding = kernel_size // 2self.conv = nn.Sequential(nn.Conv2d(2, 32, kernel_size, padding=padding, bias=False),nn.BatchNorm2d(32),nn.ReLU(inplace=True),nn.Conv2d(32, 1, kernel_size, padding=padding, bias=False), # 深层卷积nn.BatchNorm2d(1))self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)cat = torch.cat([avg_out, max_out], dim=1)out = self.conv(cat) + cat.mean(dim=1, keepdim=True) # 残差连接return x * self.sigmoid(out)3.动态比例调整、参数初始化优化、并行注意力融合
import torch
import torch.nn as nn
import torch.nn.functional as F# --------------------------
# 改进3:动态比例调整
# --------------------------
def get_ratio(in_channels, min_ratio=16):"""动态计算压缩比例,防止通道数过小时出现除零错误"""return max(in_channels // min_ratio, 4) # 保证最小分割比例为4# --------------------------
# 改进4:参数初始化优化
# --------------------------
def init_weights(m):"""He初始化 + 零偏置初始化"""if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)# --------------------------
# 改进1/3:通道注意力(包含动态比例调整)
# --------------------------
class ChannelAttention(nn.Module):def __init__(self, in_channels):super().__init__()ratio = get_ratio(in_channels) # 动态计算ratioself.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc = nn.Sequential(nn.Conv2d(in_channels, ratio, 1, bias=False),nn.BatchNorm2d(ratio),nn.ReLU(),nn.Conv2d(ratio, in_channels, 1, bias=False),nn.BatchNorm2d(in_channels))self.sigmoid = nn.Sigmoid()self.apply(init_weights) # 应用参数初始化def forward(self, x):avg_out = self.fc(self.avg_pool(x))max_out = self.fc(self.max_pool(x))weight = self.sigmoid(avg_out + max_out)return x * weight# --------------------------
# 改进1:空间注意力
# --------------------------
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()padding = kernel_size // 2self.conv = nn.Sequential(nn.Conv2d(2, 32, kernel_size, padding=padding, bias=False),nn.BatchNorm2d(32),nn.ReLU(),nn.Conv2d(32, 1, kernel_size, padding=padding, bias=False),nn.BatchNorm2d(1))self.sigmoid = nn.Sigmoid()self.apply(init_weights) # 应用参数初始化def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)cat = torch.cat([avg_out, max_out], dim=1)weight = self.sigmoid(self.conv(cat))return x * weight# --------------------------
# 改进5:并行注意力融合
# --------------------------
class CBAM(nn.Module):def __init__(self, in_channels, kernel_size=7):super().__init__()self.ca = ChannelAttention(in_channels)self.sa = SpatialAttention(kernel_size)self.apply(init_weights) # 整个模块应用初始化def forward(self, x):# 并行计算通道注意力和空间注意力ca_out = self.ca(x) # 通道注意力分支sa_out = self.sa(x) # 空间注意力分支# 残差连接融合 (原始特征 + 通道特征 + 空间特征)return x + ca_out + sa_out相关文章:
(ECCV2018)CBAM改进思路
论文链接:https://arxiv.org/abs/1807.06521 论文题目:CBAM: Convolutional Block Attention Module 会议:ECCV2018 论文方法 利用特征的通道间关系生成了一个通道注意图。 由于特征映射的每个通道被认为是一个特征检测器,通道…...

Python脚本,音频格式转换 和 视频格式转换
一、音频格式转换完整代码 from pydub import AudioSegment import osdef convert_audio(input_dir, output_dir, target_format):if not os.path.exists(output_dir):os.makedirs(output_dir)for filename in os.listdir(input_dir):if filename.endswith((.mp3, .wav, .ogg)…...

基于Spring Boot的高校就业招聘系统的设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

强化学习(赵世钰版)-学习笔记(4.值迭代与策略迭代)
本章是整个课程中,算法与方法的第一章,应该是最简单的入门方法。 上一章讲到了贝尔曼最优方程,其目的是计算出最优状态值,从而确定对应的最优策略。 而压缩映射理论推出了迭代算法 对初始值V0赋一个随机的初始值,算法最…...

Cursor安装配置
1.安装 通过网盘分享的文件:Cursor Setup 0.45.11 - x64.exe 链接: 百度网盘 请输入提取码 提取码: 6juv 2. 配置 选择AI工具的语言 输入AI工具的语言为 "中文" ,输入完语言之后,直接点击 "Continue" 下一步&#x…...

相机几何:从三维世界到二维图像的映射
本系列课程将带领读者开启一场独特的三维视觉工程之旅。我们不再止步于教科书式的公式推导,而是聚焦于如何将抽象的数学原理转化为可落地的工程实践。通过解剖相机的光学特性、构建成像数学模型、解析坐标系转换链条,直至亲手实现参数标定代码࿰…...

【GoTeams】-5:引入Docker
本文目录 1. Dokcer-compose回顾下Docker知识编写docker-compose.yaml运行docker 2. 部署go服务编写dockerfile 1. Dokcer-compose 这里简单先用一下win版本的Docker,后期开发好了部署的时候再移植到服务器下进行docker部署。 输入命令docker-compose version 就可…...

基金股票期权期货投资方式对比
以下是基金、股票、期权和期货的详细对比分析,涵盖定义、核心特点、优势、劣势、适用场景及相互区别: 一、基金 定义 基金是通过集合投资者的资金,由专业管理人(基金经理)进行多元化投资的金融工具。根据投资标的可分…...
大模型AI平台DeepSeek 眼中的SQL2API平台:QuickAPI、dbapi 和 Magic API 介绍与对比
目录 1 QuickAPI 介绍 2 dbapi 介绍 3 Magic API 介绍 4 简单对比 5 总结 统一数据服务平台是一种低代码的方式,实现一般是通过SQL能直接生成数据API,同时能对产生的数据API进行全生命周期的管理,典型的SQL2API的实现模式。 以下是针对…...
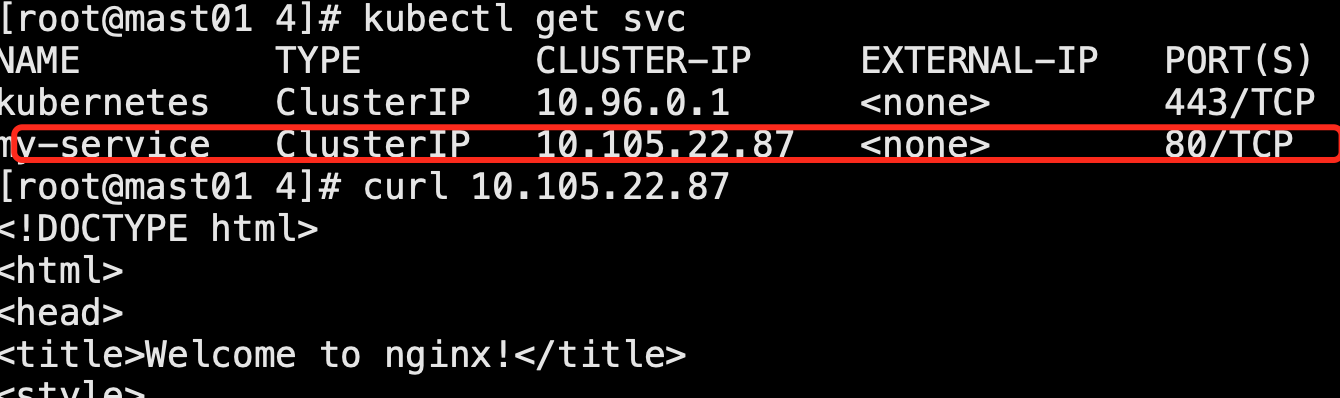
K8S学习之基础十九:k8s的四层代理Service
K8S四层代理Service 四层负载均衡Service 在k8s中,访问pod可以通过ip端口的方式,但是pod是由生命 周期的,pod在重启的时候ip地址往往会发生变化,访问pod就需要新的ip地址,这样就会很麻烦,每次pod地址改变就…...

揭开AI-OPS 的神秘面纱 第六讲 AI 模型服务层 - 开源模型选型与应用 (时间序列场景|图神经网络场景)
时间序列场景 AI 模型服务层 - 开源模型选型与应用 (时间序列场景) 在 AI-Ops 中,时间序列数据分析主要应用于以下场景: 指标预测: 预测 Metrics 指标 (例如 CPU 使用率、内存使用率、网络流量、请求延迟等) 的未来趋势,用于容量规划、资源调度、异常检测等。异常检测: 检…...

在Dify中访问Gemini等模型代理设置指南
问题背景 Google Gemini模型可纯免费使用,且性能也相当不错,一般个人使用或研究足够。但在在国内访问,需设置代理。在Docker部署Dify时,虽然按官方文档介绍设置代理环境变量,但实测发现并不生效。我们通过研究试验解决…...
MySQL的安装以及数据库的基本配置
MySQL的安装及配置 MySQL的下载 选择想要安装的版本,点击Download下载 Mysql官网下载地址: https://downloads.mysql.com/archives/installer/ MySQL的安装 选择是自定义安装,所以直接选择“Custom”,点击“Next” …...

设备树的组成
根节点下含有 compatile 属性的子节点 含有特定 compatile 属性的节点的子节点 如果一个节点的 compatile 属性,它的值是这 4 者之一:"simple-bus","simple-mfd","isa","arm,amba-bus", 那 么 它 的 子结点 (…...

C++入门——输入输出、缺省参数
C入门——输入输出、缺省参数 一、C标准库——命名空间 std C标准库std是一个命名空间,全称为"standard",其中包括标准模板库(STL),输入输出系统,文件系统库,智能指针与内存管理&am…...
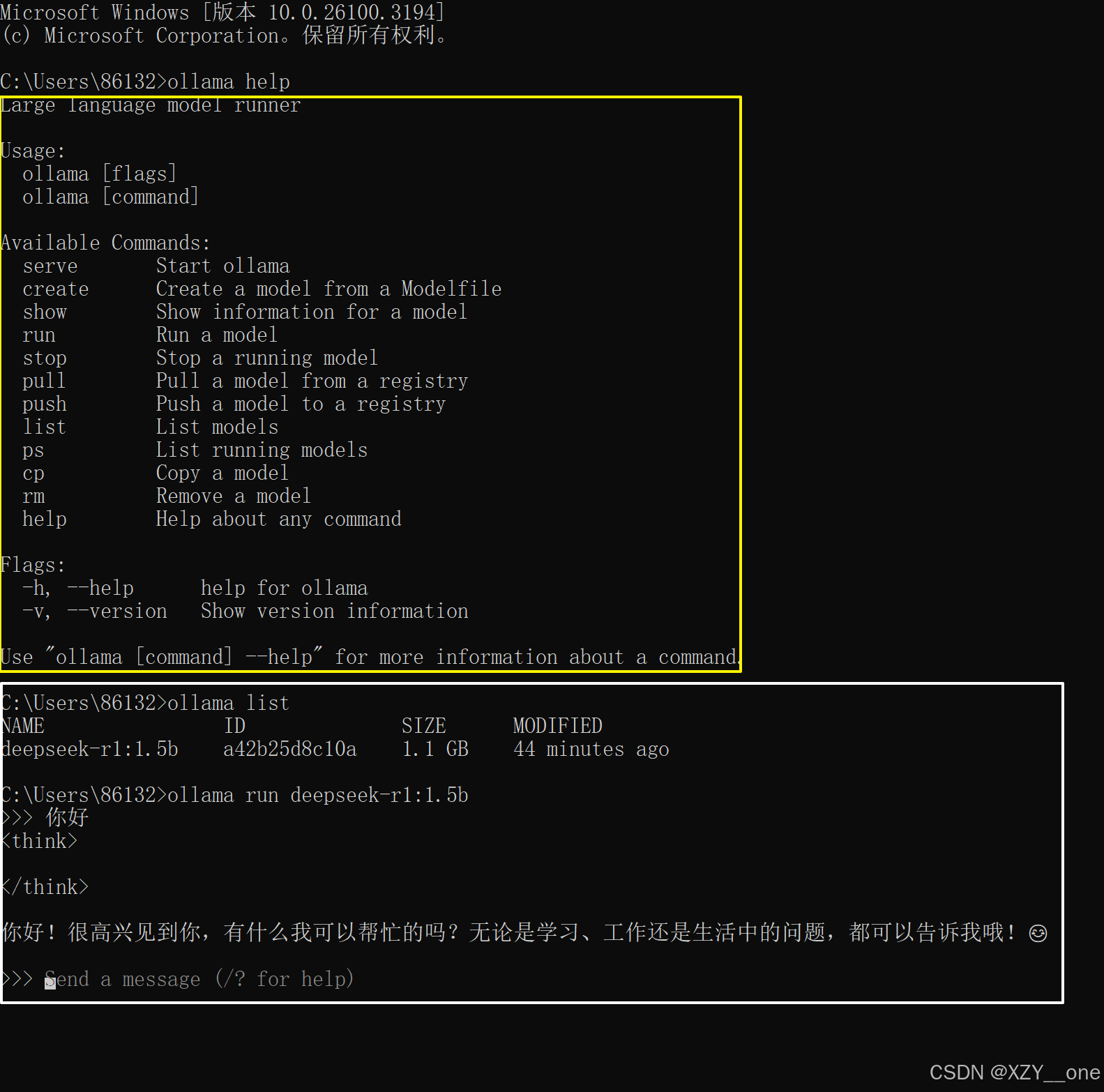
deepseek 本地部署
deepseek 本地部署 纯新手教学,手把手5分钟带你在本地部署一个私有的deepseek,再也不用受网络影响。流畅使用deepseek!!! 如果不想看文章,指路:Deep seek R1本地部署 小白超详细教程 ࿰…...
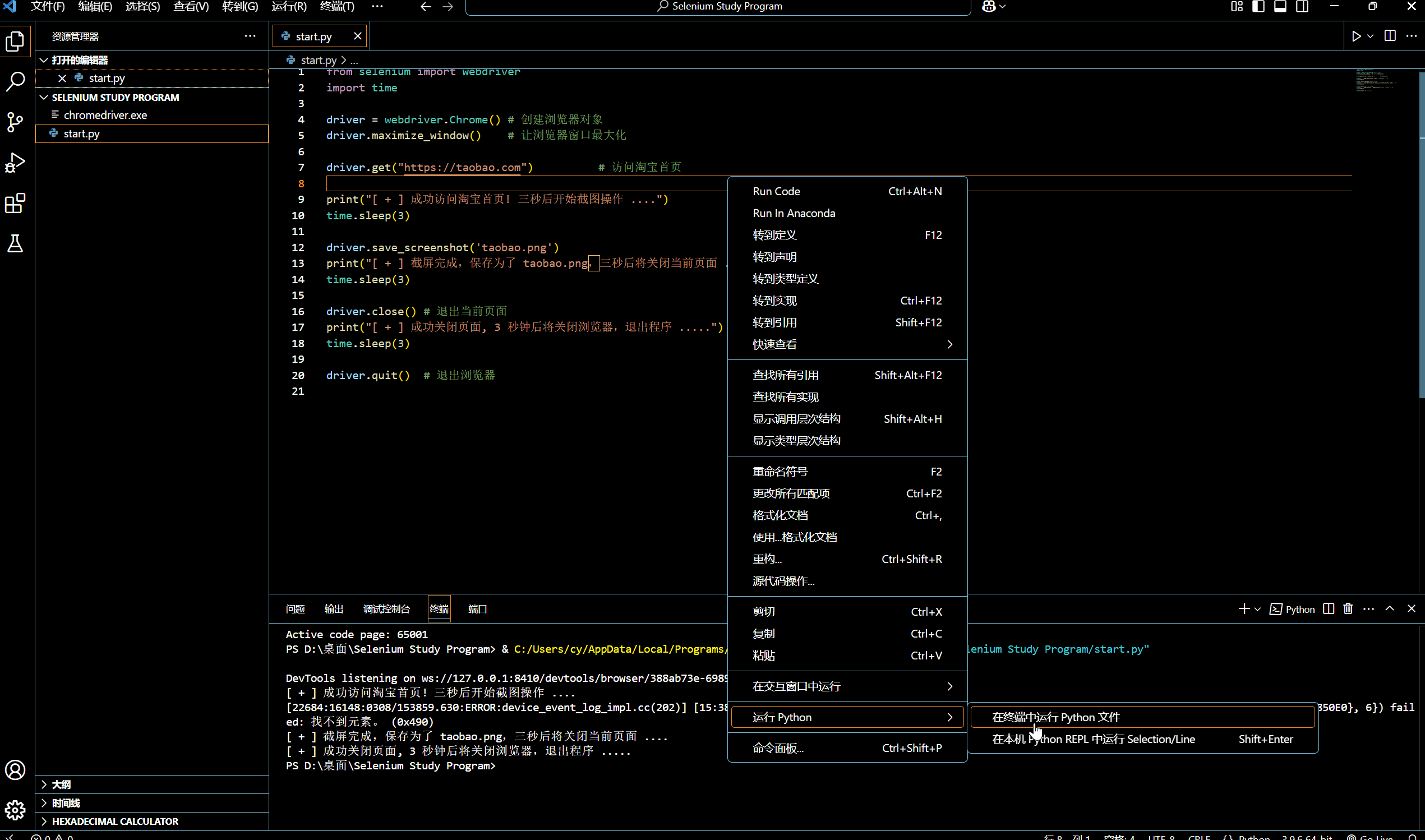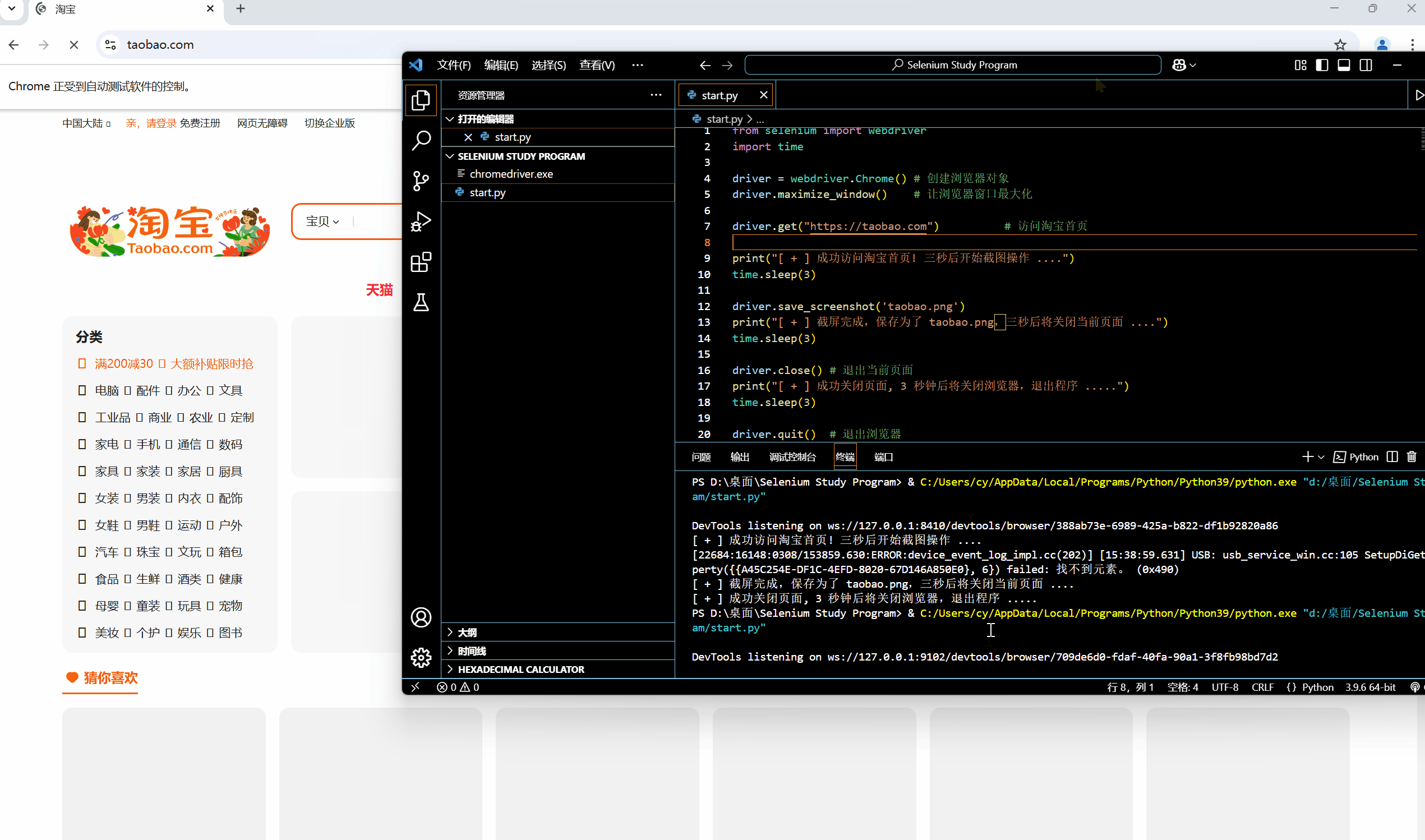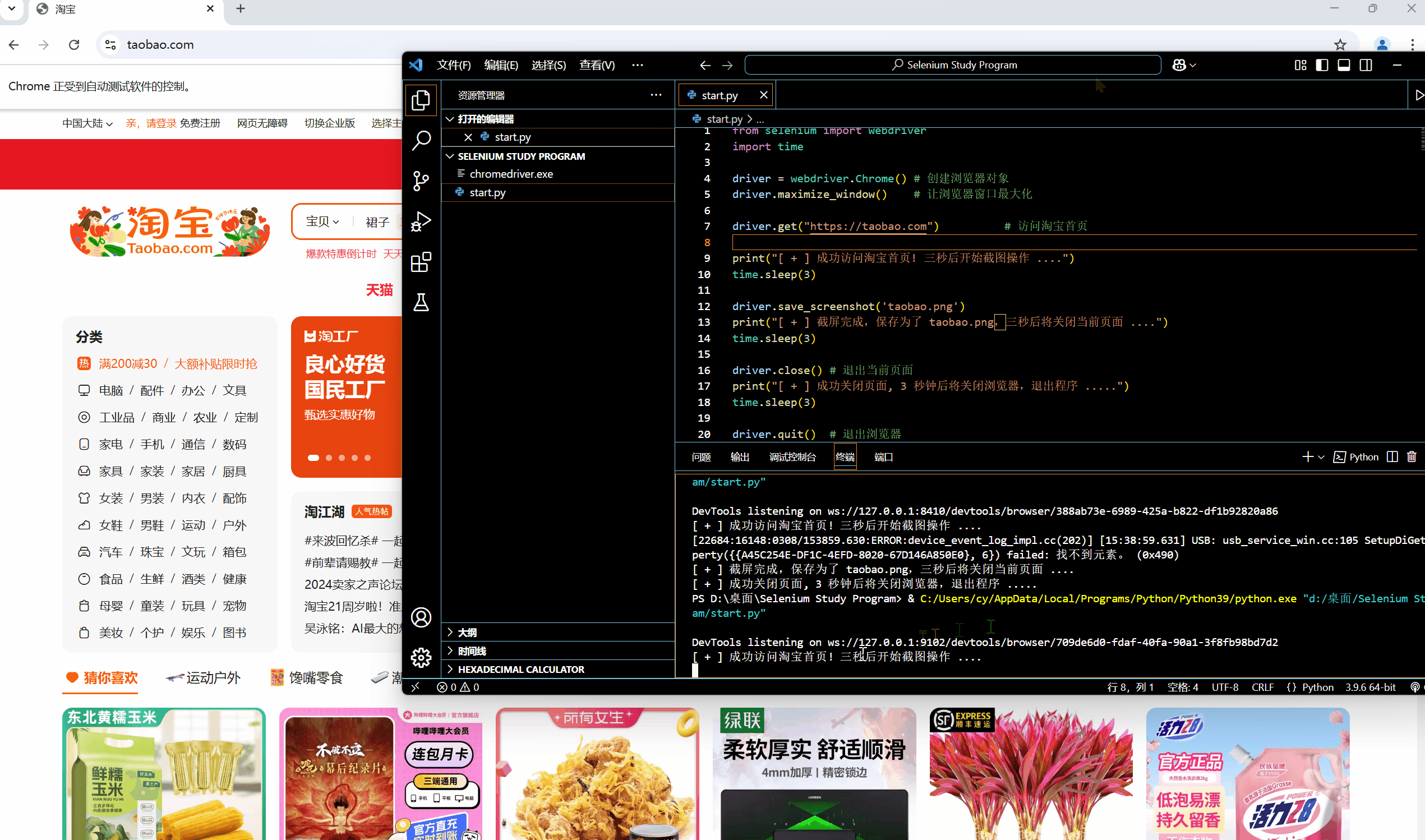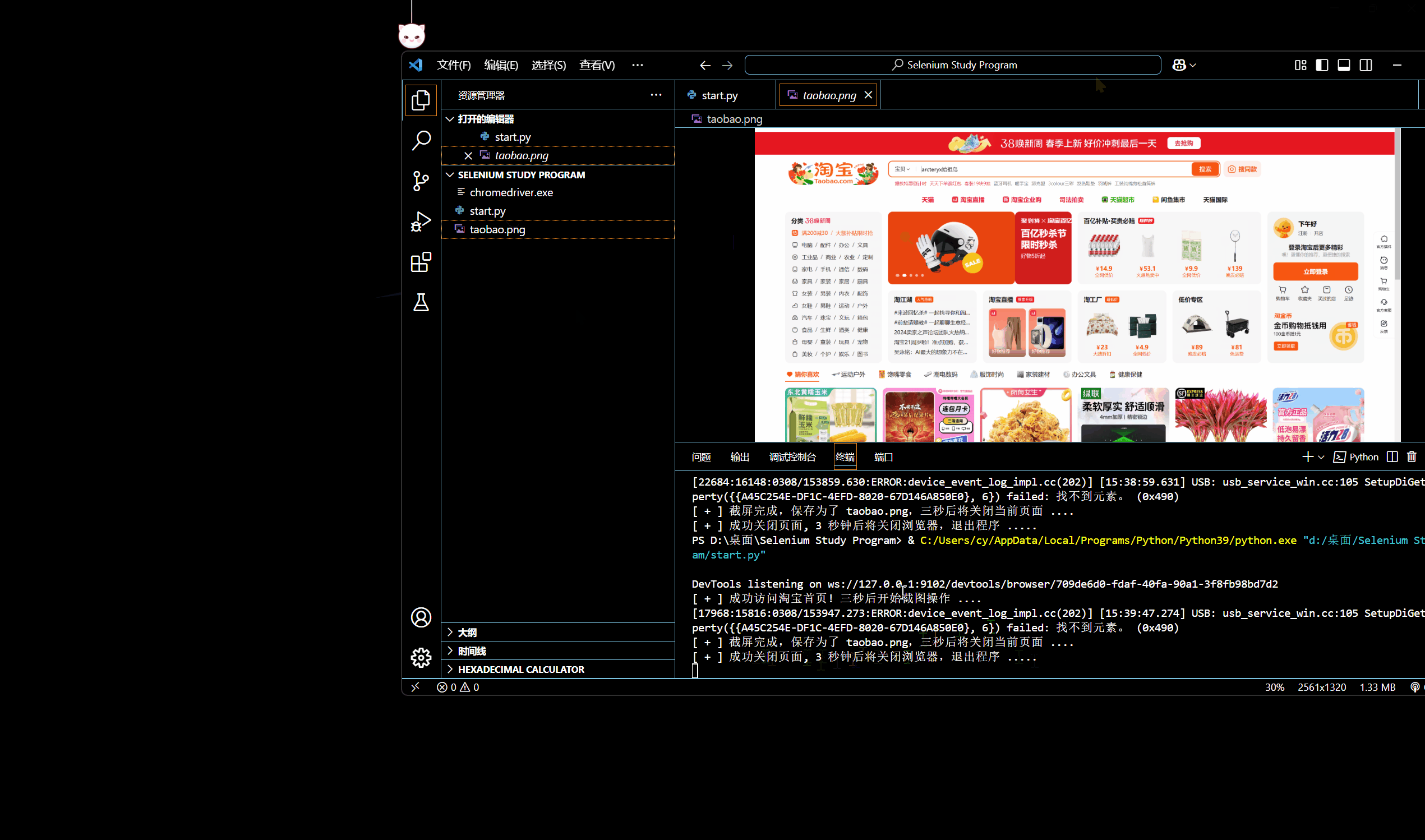
[网络爬虫] 动态网页抓取 — Selenium 入门操作
🌟想系统化学习爬虫技术?看看这个:[数据抓取] Python 网络爬虫 - 学习手册-CSDN博客 0x01:WebDriver 类基础属性 & 方法 为模仿用户真实操作浏览器的基本过程,Selenium 的 WebDriver 模块提供了一个 WebDriver 类…...
)
HTML 超链接(简单易懂较详细)
在 HTML 中,超链接是通过 <a> 标签(anchor tag)创建的。超链接允许用户通过点击文本、图像或其他元素跳转到另一个网页、文件或页面的特定部分。本文将详细介绍 HTML 超链接的语法、属性和应用场景。 一、基本语法 <a href"U…...

rpc和proto
rpc全称远程过程控制,说白了是一种对信息发送和接收的规则编写方法,来自google,这些规则会以protobuf代码存到proto文件里。我以autoGen中agent_worker.proto为例,大概长这样 syntax "proto3";package agents;option …...

OPENGLPG第九版学习 -颜色、像素和片元 PART1
文章目录 4.1 基本颜色理论4.2 缓存及其用途颜色缓存深度缓存 / z缓存 / z-buffer模板缓存 4.2.1 缓存的清除4.2.2 缓存的掩码 4.3 颜色与OpenGL4.3.1 颜色的表达与OpenGL4.3.2 平滑数据插值 4.4 片元的测试与操作4.4.1 剪切测试4.4.2 多重采样的片元操作4.4.3 模板测试模板查询…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案
如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX 还在为本地音乐库缺少歌词而烦恼吗࿱…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...

终极免费音乐解锁工具:5步轻松解密你的加密音乐文件
终极免费音乐解锁工具:5步轻松解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

基于PIC32单片机实现Android USB音频转SPDIF输出的DIY方案
1. 项目概述:为Android设备打造一个高保真SPDIF音频接口作为一名长期折腾嵌入式音频和家庭影院的玩家,我经常遇到一个痛点:手头那些性能不错的Android手机或平板,其内置的3.5mm耳机孔或者USB-C口的音频输出质量,在连接…...

API渗透测试:契约驱动的协议/语义/架构三层攻防
1. 为什么“API渗透测试”不是Web渗透的简单延伸?很多人刚接触API安全时,第一反应是:“不就是把Burp Suite抓到的HTTP请求换个参数发一发?跟测网页表单差不多。”我2018年第一次接手某金融类SaaS平台的API安全评估时,也…...

告别Selenium?手把手教你用Playwright录制脚本,5分钟搞定Web自动化测试
5分钟极速上手Playwright脚本录制:零代码实现Web自动化测试当产品经理突然丢给你一个刚上线的电商活动页,要求半小时内完成所有核心链路测试时,传统的手写Selenium脚本显然来不及。作为测试工程师,我最近发现微软开源的Playwright…...

智能体任务分配算法:从启发式到深度强化学习的演进与实践
1. 项目概述:从“谁来做”到“如何做得更好”的智能进化在机器人集群、无人机编队或是自动化仓储系统中,我们常常面临一个看似简单实则复杂的问题:眼前有一堆任务,手头有一群可用的智能体(机器人、无人机、服务器等&am…...