Python深度学习算法介绍
一、引言
深度学习是机器学习的一个重要分支,它通过构建多层神经网络结构,自动从数据中学习特征表示,从而实现对复杂模式的识别和预测。Python作为一门强大的编程语言,凭借其简洁易读的语法和丰富的库支持,成为深度学习领域的主流开发语言之一。本文将全面介绍Python深度学习中常见的算法及其应用。
二、基础概念
(一)神经网络
神经网络是深度学习的核心结构,由输入层、隐藏层和输出层组成,每个层包含多个神经元,神经元之间通过权重和偏置进行连接。输入层接收数据,隐藏层对数据进行处理和特征提取,输出层输出最终结果。通过调整权重和偏置,神经网络能够学习数据中的规律,从而实现对新数据的预测。
(二)前向传播与反向传播
前向传播是指输入数据通过神经网络逐层计算得到输出结果的过程。反向传播则是通过计算损失函数的梯度,调整网络中的权重和偏置,以优化模型性能。反向传播算法是深度学习训练过程中的关键环节,它利用链式法则计算梯度,从而实现对模型参数的更新。
(三)损失函数与优化算法
损失函数用于衡量模型预测值与真实值之间的差异,常见的损失函数包括均方误差损失、交叉熵损失等。优化算法则是通过调整模型参数,使损失函数最小化,常见的优化算法有梯度下降、随机梯度下降、Adam等。
三、常见深度学习算法
(一)前馈神经网络(Feedforward Neural Network)
前馈神经网络是最基本的神经网络结构,信息在神经元之间单向流动,没有循环连接。它由输入层、隐藏层和输出层组成,通过多层非线性变换学习数据表示。其训练过程通常通过反向传播算法进行。
使用Python和TensorFlow构建前馈神经网络的示例代码:
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense# 构建模型model = Sequential([Dense(64, activation='relu', input_shape=(100,)),Dense(64, activation='relu'),Dense(10, activation='softmax')])# 编译模型model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])# 训练模型model.fit(x_train, y_train, epochs=10, batch_size=32)(二)卷积神经网络(Convolutional Neural Network,CNN)
CNN主要用于处理图像和视频数据,利用卷积层和池化层进行特征提取。卷积层通过卷积核对图像进行扫描,提取局部特征;池化层则用于降低特征维度,减少计算量。通过多层卷积和池化操作,CNN能够自动学习图像的层次化特征表示,从而实现对图像的识别和分类。
使用Python和Keras构建CNN模型的示例代码:
from tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense# 构建模型model = Sequential([Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),MaxPooling2D((2, 2)),Conv2D(64, (3, 3), activation='relu'),MaxPooling2D((2, 2)),Flatten(),Dense(64, activation='relu'),Dense(10, activation='softmax')])# 编译模型model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型model.fit(x_train, y_train, epochs=10)(三)循环神经网络(Recurrent Neural Network,RNN)
RNN适用于处理序列数据,如自然语言处理和时间序列分析。它通过记忆单元捕捉时间依赖性,每个时刻的输入及之前时刻的状态经过精心映射,融合成隐藏状态,并在当前输入与前期状态的共同作用下,精准预测下一个时刻的输出。
使用Python和TensorFlow构建简单RNN模型的示例代码:
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import SimpleRNN, Dense# 构建模型model = Sequential([SimpleRNN(50, input_shape=(10, 1)),Dense(1)])# 编译模型model.compile(optimizer='adam', loss='mse')# 训练模型model.fit(x_train, y_train, epochs=10)(四)长短期记忆网络(Long Short-Term Memory,LSTM)
LSTM是RNN的一种改进,通过门控机制解决梯度消失问题,适用于长序列数据的处理。它引入了输入门、遗忘门和输出门,能够更好地控制信息的流动,从而实现对长期依赖关系的学习。
使用Python和Keras构建LSTM模型的示例代码:
from tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Dense# 构建模型model = Sequential([LSTM(50, input_shape=(10, 1)),Dense(1)])# 编译模型model.compile(optimizer='adam', loss='mse')# 训练模型model.fit(x_train, y_train, epochs=10)(五)门控循环单元(Gated Recurrent Unit,GRU)
GRU是LSTM的简化版本,它通过引入更新门和重置门,实现了与LSTM类似的长期依赖学习能力,同时减少了模型的复杂度和计算量。GRU在处理序列数据时表现出色,尤其适用于需要实时处理的场景。
使用Python和TensorFlow构建GRU模型的示例代码:
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import GRU, Dense# 构建模型model = Sequential([GRU(50, input_shape=(10, 1)),Dense(1)])# 编译模型model.compile(optimizer='adam', loss='mse')# 训练模型model.fit(x_train, y_train, epochs=10)- Transformer架构
Transformer架构是一种基于自注意力机制的神经网络架构,主要用于处理序列数据。它摒弃了传统的循环结构,通过自注意力机制并行处理序列中的所有元素,大大提高了计算效率。Transformer架构在自然语言处理领域取得了显著的成果,如BERT、GPT等模型均基于此架构。
使用Python和TensorFlow构建简单Transformer模型的示例代码:
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import MultiHeadAttention, Dense, Dropout, LayerNormalizationclass TransformerBlock(tf.keras.layers.Layer):def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):super(TransformerBlock, self).__init__()self.att = MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)self.ffn = tf.keras.Sequential([Dense(ff_dim, activation="relu"), Dense(embed_dim)])self.layernorm1 = LayerNormalization(epsilon=1e-6)self.layernorm2 = LayerNormalization(epsilon=1e-6)self.dropout1 = Dropout(rate)self.dropout2 = Dropout(rate)def call(self, inputs, training=False):attn_output = self.att(inputs, inputs)attn_output = self.dropout1(attn_output, training=training)out1 = self.layernorm1(inputs + attn_output)ffn_output = self.ffn(out1)ffn_output = self.dropout2(ffn_output, training=training)return self.layernorm2(out1 + ffn_output)# 构建模型model = Sequential([TransformerBlock(embed_dim=32, num_heads=2, ff_dim=32),Dense(1)])# 编译模型model.compile(optimizer='adam', loss='mse')# 训练模型model.fit(x_train, y_train, epochs=10)Transformer架构的核心是自注意力机制(Self-Attention),它允许模型在处理序列数据时,动态地关注序列中的不同部分,从而更好地捕捉长距离依赖关系。此外,Transformer还通过多头注意力(Multi-Head Attention)和位置编码(Positional Encoding)进一步提升了模型的性能。
(七)生成对抗网络(Generative Adversarial Networks,GANs)
GAN是一种由生成器(Generator)和判别器(Discriminator)组成的对抗模型。生成器的目标是生成与真实数据难以区分的假数据,而判别器的目标是区分真实数据和生成数据。通过生成器和判别器的对抗训练,GAN能够生成高质量的图像、音频等数据。
使用Python和TensorFlow构建简单GAN模型的示例代码:
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Flatten, Reshape, LeakyReLU# 定义生成器generator = Sequential([Dense(128, input_dim=100, activation=LeakyReLU(alpha=0.01)),Dense(784, activation='tanh'),Reshape((28, 28, 1))])# 定义判别器discriminator = Sequential([Flatten(input_shape=(28, 28, 1)),Dense(128, activation=LeakyReLU(alpha=0.01)),Dense(1, activation='sigmoid')])# 构建GAN模型class GAN(tf.keras.Model):def __init__(self, generator, discriminator):super(GAN, self).__init__()self.generator = generatorself.discriminator = discriminatordef compile(self, g_optimizer, d_optimizer, loss_fn):super(GAN, self).compile()self.g_optimizer = g_optimizerself.d_optimizer = d_optimizerself.loss_fn = loss_fndef train_step(self, real_images):batch_size = tf.shape(real_images)[0]noise = tf.random.normal(shape=(batch_size, 100))with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:generated_images = self.generator(noise, training=True)real_output = self.discriminator(real_images, training=True)fake_output = self.discriminator(generated_images, training=True)gen_loss = self.loss_fn(tf.ones_like(fake_output), fake_output)disc_loss = self.loss_fn(tf.ones_like(real_output), real_output) + self.loss_fn(tf.zeros_like(fake_output), fake_output)gradients_of_generator = gen_tape.gradient(gen_loss, self.generator.trainable_variables)gradients_of_discriminator = disc_tape.gradient(disc_loss, self.discriminator.trainable_variables)self.g_optimizer.apply_gradients(zip(gradients_of_generator, self.generator.trainable_variables))self.d_optimizer.apply_gradients(zip(gradients_of_discriminator, self.discriminator.trainable_variables))return {"gen_loss": gen_loss, "disc_loss": disc_loss}# 实例化并训练GAN模型gan = GAN(generator, discriminator)gan.compile(g_optimizer=tf.keras.optimizers.Adam(1e-4),d_optimizer=tf.keras.optimizers.Adam(1e-4),loss_fn=tf.keras.losses.BinaryCrossentropy(from_logits=True))gan.fit(x_train, epochs=10, batch_size=32)GAN的核心思想是通过生成器和判别器的对抗训练,使生成器能够生成与真实数据难以区分的假数据。GAN在图像生成、风格迁移等领域有着广泛的应用。
四、深度学习框架
Python提供了多种深度学习框架,用于简化模型的构建和训练过程。以下是一些常用的深度学习框架:
(一)TensorFlow
TensorFlow是Google开发的开源深度学习框架,支持多种平台和设备。它提供了丰富的API和工具,支持从简单的神经网络到复杂的模型的构建和训练。TensorFlow的2.x版本引入了Keras作为其高级API,使得模型的构建更加简洁易用。
(二)PyTorch
PyTorch是Facebook开发的开源深度学习框架,以其动态计算图和易用性而受到广泛欢迎。PyTorch支持动态图,允许用户在运行时修改计算图,这使得调试和实验更加方便。PyTorch还提供了丰富的工具和库,支持自然语言处理、计算机视觉等领域。
(三)Keras
Keras是一个高级深度学习框架,可以运行在TensorFlow、Theano等后端之上。Keras以简洁易用著称,提供了丰富的预定义层和模型,支持快速构建和训练深度学习模型。Keras还提供了大量的实用工具,如数据预处理、模型保存和加载等。
五、深度学习的应用领域
(一)计算机视觉
深度学习在计算机视觉领域取得了巨大的成功,包括图像分类、目标检测、语义分割等任务。卷积神经网络(CNN)是计算机视觉领域的主要模型,通过多层卷积和池化操作,能够自动学习图像的特征表示。
(二)自然语言处理
深度学习在自然语言处理(NLP)领域也有广泛的应用,包括机器翻译、情感分析、文本生成等任务。循环神经网络(RNN)、长短期记忆网络(LSTM)和Transformer架构是自然语言处理领域的常用模型,能够处理文本序列数据并捕捉长距离依赖关系。
(三)语音识别
深度学习在语音识别领域也有重要的应用,通过将语音信号转换为文本,实现语音交互和语音控制等功能。卷积神经网络和循环神经网络是语音识别领域的常用模型,能够处理语音信号的时序特征。
(四)强化学习
强化学习是一种通过与环境交互来学习最优策略的机器学习方法。深度学习与强化学习相结合,形成了深度强化学习,如AlphaGo等应用。深度强化学习在游戏、机器人控制等领域取得了显著的成果。
六、总结
Python深度学习算法涵盖了多种模型和框架,从简单的前馈神经网络到复杂的Transformer架构,从TensorFlow到PyTorch等框架,为开发者提供了丰富的选择。深度学习在计算机视觉、自然语言处理、语音识别等领域取得了巨大的成功,推动了人工智能技术的快速发展。随着硬件性能的提升和算法的不断改进,深度学习将在更多领域发挥重要作用,为人类社会带来更多的便利和创新。
相关文章:

Python深度学习算法介绍
一、引言 深度学习是机器学习的一个重要分支,它通过构建多层神经网络结构,自动从数据中学习特征表示,从而实现对复杂模式的识别和预测。Python作为一门强大的编程语言,凭借其简洁易读的语法和丰富的库支持,成为深度学…...

关于sqlalchemy的使用
关于sqlalchemy的使用 说明一、sqlachemy总体使用思路二、安装与创建库、连结库三、创建表、增加数据四、查询记录五、更新或删除六、关联表定义七、一对多关联查询八、映射类定义与添加记录 说明 本教程所需软件及库python3.10、sqlalchemy安装与创建库、连结库创建表、增加数…...
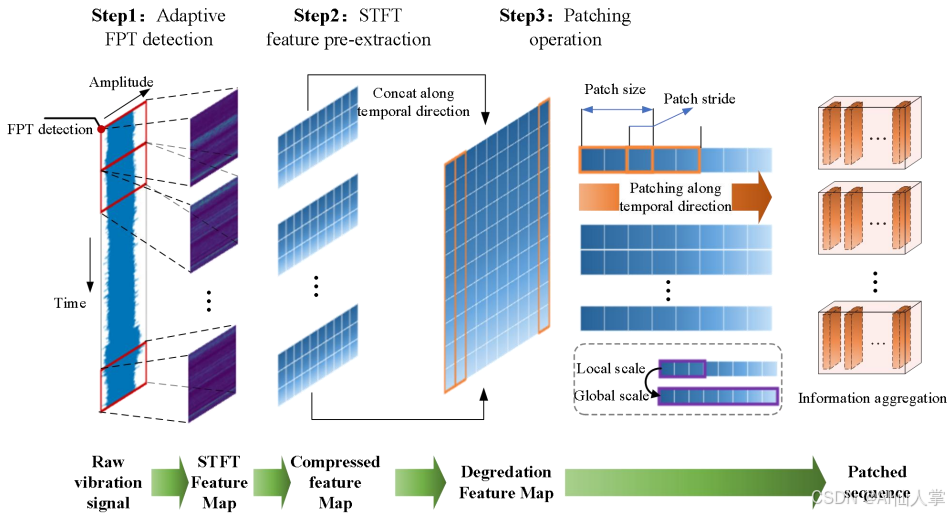
利用LLMs准确预测旋转机械(如轴承)的剩余使用寿命(RUL)
研究背景 研究问题:如何准确预测旋转机械(如轴承)的剩余使用寿命(RUL),这对于设备可靠性和减少工业系统中的意外故障至关重要。研究难点:该问题的研究难点包括:训练和测试阶段数据分布不一致、长期RUL预测的泛化能力有限。相关工作:现有工作主要包括基于模型的方法、数…...

深度学习 PyTorch 中 18 种数据增强策略与实现
深度学习pytorch之简单方法自定义9类卷积即插即用 数据增强通过对训练数据进行多种变换,增加数据的多样性,它帮助我们提高模型的鲁棒性,并减少过拟合的风险。PyTorch 提供torchvision.transforms 模块丰富的数据增强操作,我们可以…...

视觉图像处理
在MATLAB中进行视觉图像处理仿真通常涉及图像增强、滤波、分割、特征提取等操作。以下是一个分步指南和示例代码,帮助您快速入门: 1. MATLAB图像处理基础步骤 1.1 读取和显示图像 % 读取图像(替换为实际文件路径) img = imread(lena.jpg); % 显示原图 figure; subplot(2…...

深度学习与普通神经网络有何区别?
深度学习与普通神经网络的主要区别体现在以下几个方面: 一、结构复杂度 普通神经网络:通常指浅层结构,层数较少,一般为2-3层,包括输入层、一个或多个隐藏层、输出层。深度学习:强调通过5层以上的深度架构…...

Vue3、vue学习笔记
<!-- Vue3 --> 1、Vue项目搭建 npm init vuelatest cd 文件目录 npm i npm run dev // npm run _ 这个在package.json中查看scripts /* vue_study\.vscode可删 // vue_study\src\components也可删除(基本语法,不使用组件) */ // vue_study\.vscode\lau…...

python中C#类库调用+调试方法~~~
因为开发需要,我们经常会用C#来写一些库供python调用,但是在使用过程中难免会碰到一些问题,需要我们抽丝剥茧来解决~~~ 首先,我们在python中要想调用C#(基于.net)的dll,需要安装一个库,它就是 pythonnet …...

L33.【LeetCode笔记】循环队列(数组解法)
目录 1.题目 2.分析 方法1:链表 尝试使用单向循环链表模拟 插入节点 解决方法1:开辟(k1)个节点 解决方法2:使用变量size记录队列元素个数 获取队尾元素 其他函数的实现说明 方法2:数组 重要点:指针越界的解决方法 方法1:单独判断 方法2:取模 3.数组代码的逐步实现…...

css实现元素垂直居中显示的7种方式
文章目录 * [【一】知道居中元素的宽高](https://blog.csdn.net/weixin_41305441/article/details/89886846#_1) [absolute 负margin](https://blog.csdn.net/weixin_41305441/article/details/89886846#absolute__margin_2) [absolute margin auto](https://blog.csdn.net…...

【Python】Django 中的算法应用与实现
Django 中的算法应用与实现 在 Django 开发中,算法的应用可以极大地扩展 Web 应用的功能和性能。从简单的数据处理到复杂的机器学习模型,Django 都可以作为一个强大的后端框架来支持这些算法的实现。本文将介绍几种常见的算法及其在 Django 中的使用方法…...

Docker 运行 GPUStack 的详细教程
GPUStack GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。它具有广泛的硬件兼容性,支持多种品牌的 GPU,并能在 Apple MacBook、Windows PC 和 Linux 服务器上运行。GPUStack 支持各种 AI 模型,包括大型语言模型(LLMs&am…...
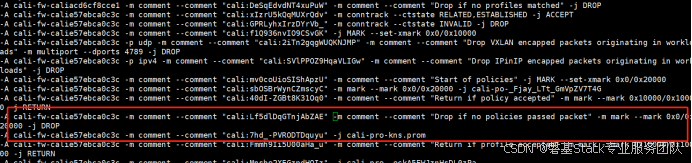
Kubernetes中的 iptables 规则介绍
#作者:邓伟 文章目录 一、Kubernetes 网络模型概述二、iptables 基础知识三、Kubernetes 中的 iptables 应用四、查看和调试 iptables 规则五、总结 在 Kubernetes 集群中,iptables 是一个核心组件, 用于实现服务发现和网络策略。iptables 通…...
解决VScode 连接不上问题
问题 :VScode 连接不上 解决方案: 1、手动杀死VS Code服务器进程,然后重新尝试登录 打开xshell ,远程连接服务器 ,查看vscode的进程 ,然后全部杀掉 [cxqiZwz9fjj2ssnshikw14avaZ ~]$ ps ajx | grep vsc…...

AI 驱动的软件测试革命:从自动化到智能化的进阶之路
🚀引言:软件测试的智能化转型浪潮 在数字化转型加速的今天,软件产品的迭代速度与复杂度呈指数级增长。传统软件测试依赖人工编写用例、执行测试的模式,已难以应对快速交付与高质量要求的双重挑战。人工智能技术的突破为测试领域注…...
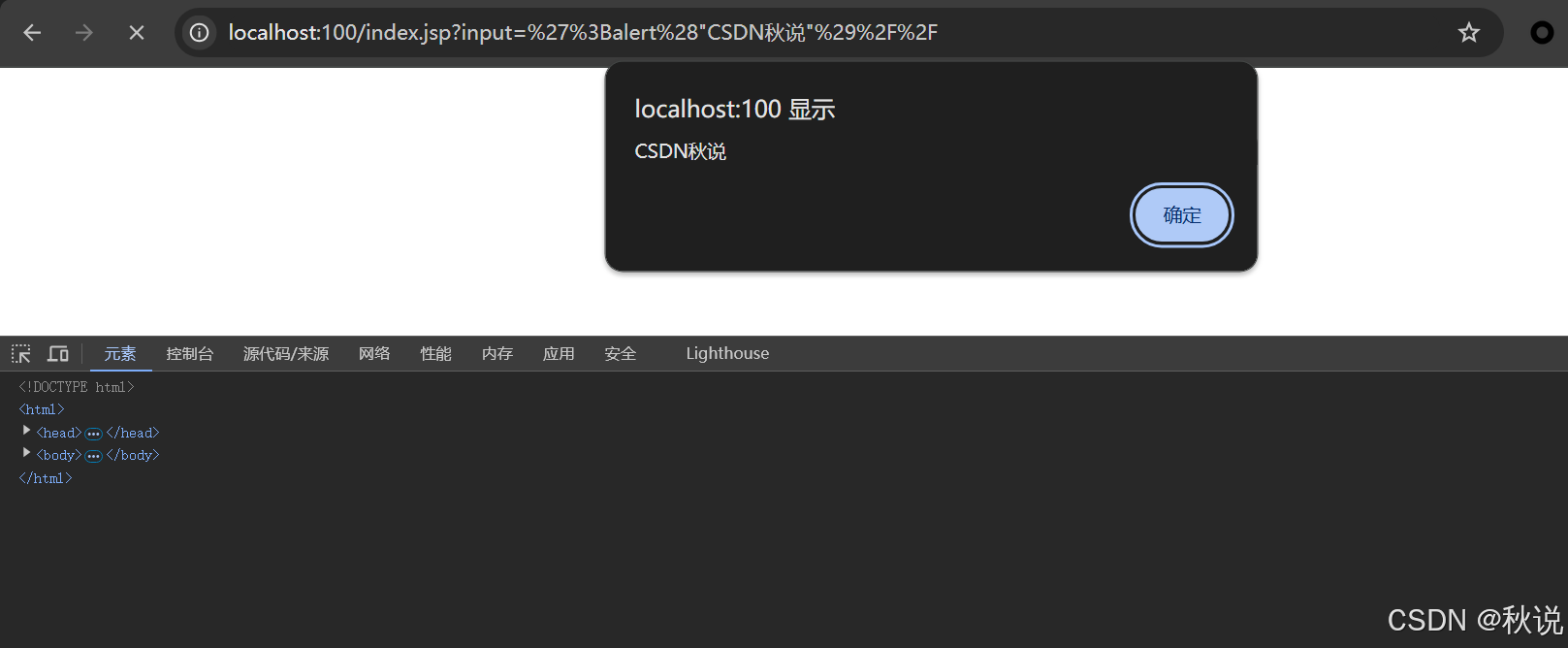
【Java代码审计 | 第六篇】XSS防范
文章目录 XSS防范使用HTML转义使用Content Security Policy (CSP)输入验证使用安全的库和框架避免直接使用用户输入构建JavaScript代码 XSS防范 使用HTML转义 在输出用户输入时,对特殊字符进行转义,防止它们被解释为HTML或JavaScript代码。 例如&…...

Android WebSocket工具类:重连、心跳、消息队列一站式解决方案
依赖库 使用 OkHttp 的WebSocket支持。 在 build.gradle 中添加依赖: implementation com.squareup.okhttp3:okhttp:4.9.3WebSocket工具类实现 import okhttp3.*; import android.os.Handler; import android.os.Looper; import android.util.Log;import java.ut…...

认识vue2脚手架
1.认识脚手架结构 使用VSCode将vue项目打开: package.json:包的说明书(包的名字,包的版本,依赖哪些库)。该文件里有webpack的短命令: serve(启动内置服务器) build命令…...
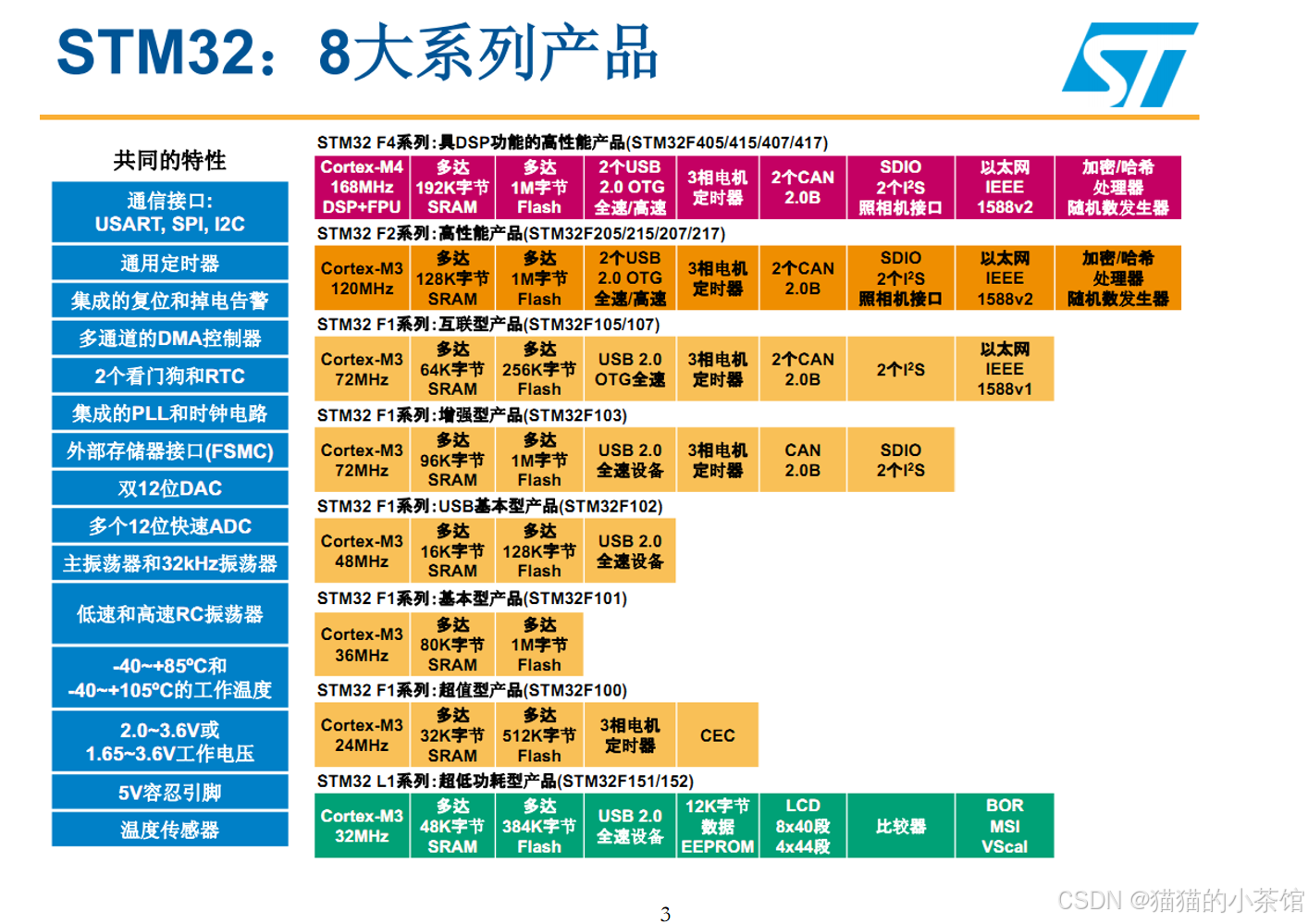
【STM32】STM32系列产品以及新手入门的STM32F103
📢 STM32F103xC/D/E 系列是一款高性能、低功耗的 32 位 MCU,适用于工业、汽车、消费电子等领域;基于 ARM Cortex-M3,主频最高 72MHz,支持 512KB Flash、64KB SRAM,适合复杂嵌入式应用,提供丰富的…...
<建模软件安装教程1>Blender4.2系列
Blender4.2安装教程 0注意:Windows环境下安装 第一步,百度网盘提取安装包。百度网盘链接:通过网盘分享的文件:blender.zip 链接: https://pan.baidu.com/s/1OG0jMMtN0qWDSQ6z_rE-9w 提取码: 0309 --来自百度网盘超级会员v3的分…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

还在古法编程?OpenAI Codex 全自动编程!稳定中转 Token 保姆级教程
OpenAI Codex 从安装到进阶实战|终端 AI 编程完全指南(2026 最新) 摘要:OpenAI Codex 是目前最强大的终端 AI 编程工具,支持代码生成、项目重构、Bug 修复、脚本自动化、批量代码优化等全场景能力。本文从零起步&…...

动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿
动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Anim…...
HSTracker:macOS上炉石传说玩家的免费智能助手终极指南
HSTracker:macOS上炉石传说玩家的免费智能助手终极指南 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker 还在为炉石传说对战中记不住对手卡牌而烦恼吗&#x…...