我的两个医学数据分析技术思路
我的两个医学数据分析技术思路
从临床上获得的或者公共数据库数据这种属于观察性研究,是对临床诊疗过程中自然产生的数据进行分析而获得疾病发生发展的规律等研究成果。再细分,可以分为独立危险因素鉴定和预测模型构建两种。
独立危险因素鉴定是一直以来的研究内容,目的是研究疾病预后的影响因素或者开发诊断指标,早期是通过统计学和逻辑回归模型等方法进行研究;而预测模型构建是后来出现的,把多个独立危险因素集中起来共同对疾病结局进行预测或者诊断疾病,达到更好地诊断和治疗疾病的目的。
数据分析技术新的发展也给以上两部分内容带来了新的面貌,这里总结个人在这两方面的分析技术思路,供大家借鉴。
机器学习算法主导的独立危险因素鉴定
这里的机器学习主要是指xgboost等非线性模型,传统的是使用多因素逻辑回归作为独立危险因素鉴定的最终结果,线性模型事先假定变量之间的关系是线性的被认为可能造成了分析结果的不准确,所以现在用xgboost等非线性模型来克服这个缺点,但是非线性模型就没有象OR值这样能反映变量间关联强度的指标,等到SHAP分析这样可以解释模型的工具出现之后,机器学习算法主导的独立危险因素鉴定才形成套路。
技术思路:
-
变量信息表(传统的表1),展示变量的分布信息(平均值和标准差等)
-
Boruta算法筛选变量,这是近年才流行的方法,微小的关联也能筛选出来,所以不担心遗漏有意义的变量。

-
构建xgboost等非线性模型并展示模型效能,这里良好的模型性能代表所选择的变量与结局变量之间有良好的相关性,在这个前提下,后续的分析才是有价值的。

-
SHAP分析展示变量的整体贡献,可以选择排名靠前的变量或者所有的变量进行后续的分析;

-
SHAP分析展示单个变量随变量值变化其对结局变量贡献(某变量的SHAP值)的变化,结合立方样条曲线拟合确定关键的点(SHAP值为0时对应的点和shap值大于0的曲线上的拐点)

-
SHAP分析展示变量间的交互作用,展示变量间的交互作用。

-
其它,可以加入传统的线性模型的分析方法以从不同方面展示独立危险因素;如果收集了同类变量,还可以比较同类变量之间与结局变量相关性的差异;如果得到的独立危险因素够多,可以进行预测模型的构建,否则也可以独立成文。
临床预测模型构建(从数据到应用)
临床预测模型在这里不多介绍。
技术思路:
-
变量的展示(表1)
-
Boruta,Lasso等方法选择变量,传统的通过单因素分析p值的半自动方法应该淘汰了。

-
模型构建和评价,评价包括内部评价和外部评价,ROC曲线和校准曲线等我们已经耳熟能详的指标。这里可以是单个模型,也可以是相似结局的一组模型。

-
SHAP分析等解释模型,这里以汇总结果为主,从整体评价变量对模型的贡献;

-
DCA分析,比较模型间的净收益以选择模型,或者变量间的净收益来评价变量;

-
构建列线图或者预测模型APP,如果是APP,推荐融入SHAP分析的个体评价,对单个预测结果进行解释,可以展示变量当前值对预测结果的贡献,在临床实践中可以解析为当前患者的病因是什么;

-
后续,确定后续的临床措施(预测模型阳性采取的检验或者治疗措施)并进行预测模型临床影响力评价(一般是随机对照试验)。
最后
当拿到一份数据,可以先做预分析,如果得到的相关变量较多,就可以做预测模型,如果不够多,就可以考虑独立危险因素分析。
个人感觉,数据分析类的研究关键在于数据,大样本,自己收集的,有特点的数据更容易做出有意义的研究。
相关文章:
我的两个医学数据分析技术思路
我的两个医学数据分析技术思路 从临床上获得的或者公共数据库数据这种属于观察性研究,是对临床诊疗过程中自然产生的数据进行分析而获得疾病发生发展的规律等研究成果。再细分,可以分为独立危险因素鉴定和预测模型构建两种。 独立危险因素鉴定是一直以…...
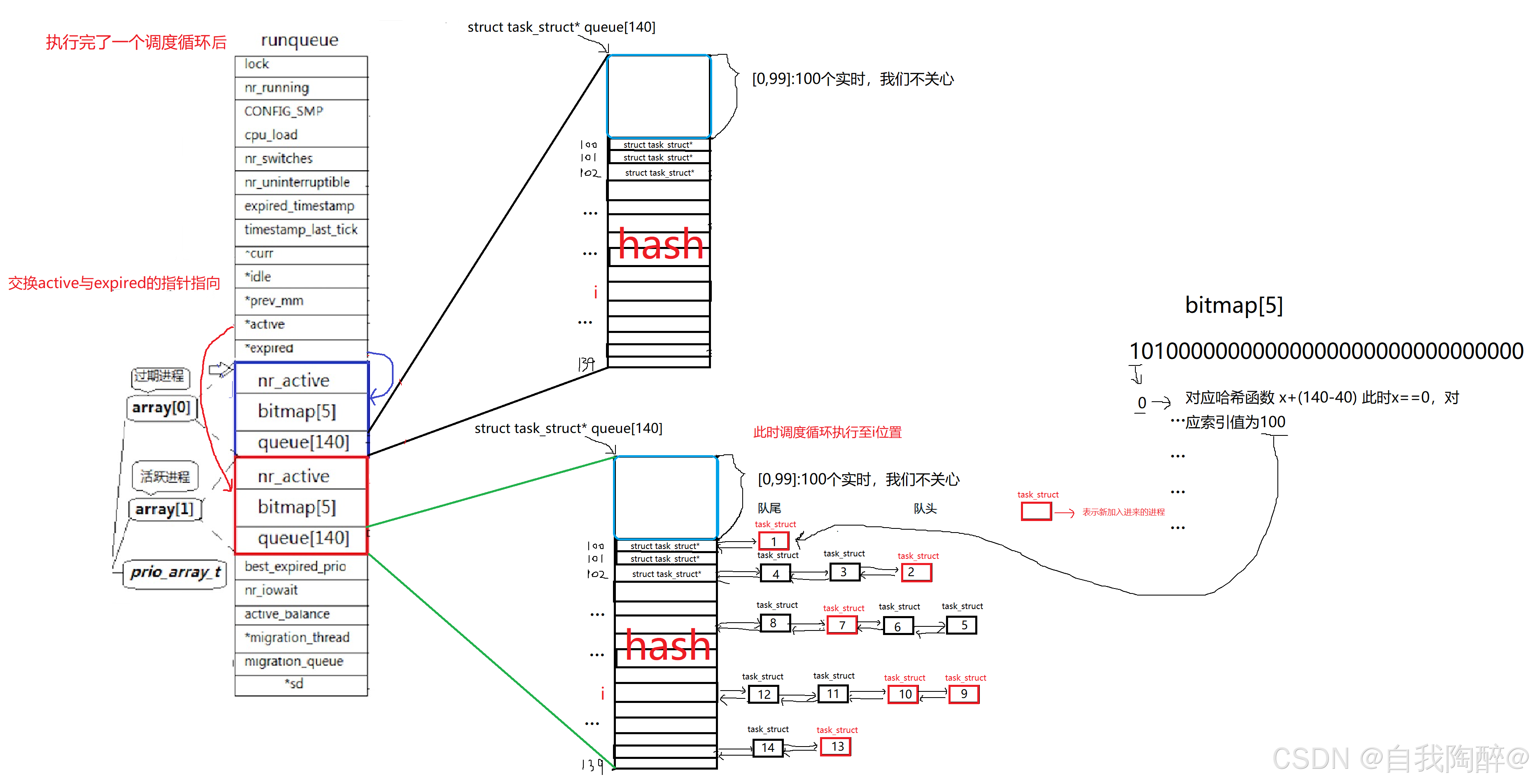
操作系统之进程状态、优先级和切换与调度
文章目录 1. 进程状态1.1 课本名词提炼1.2 运行&阻塞&挂起1.2.1 运行1.2.2 阻塞1.2.3 挂起 1.3 理解内核链表1.4 Linux中的内核解释1.5 进程状态的查看1.6 Z(zombie)——僵尸进程1.6.1 创建僵尸进程1.6.2 僵尸进程的危害 1.7 孤儿进程 2. 进程优先级2.1 基本概念2.2 查…...

[免费]微信小程序(图书馆)自习室座位预约管理系统(SpringBoot后端+Vue管理端)(高级版)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序(图书馆)自习室座位预约管理系统(SpringBoot后端Vue管理端)(高级版),分享下哈。 项目视频演示 【免费】微信小程序(图书馆)自习室座位预约管理系统(SpringBoot后端Vue管理端)(高级版…...

你使用过哪些 Java 并发工具类?
你的回答(口语化,面试场景) 面试官:你使用过哪些 Java 并发工具类? 你: 好的,我结合项目经验来说说常用的并发工具类: CountDownLatch 作用:等所有线程就绪后再触发任务…...

模板方法模式的C++实现示例
核心思想 模板方法设计模式是一种行为设计模式,它定义了一个算法的框架,并将某些步骤的具体实现延迟到子类中。通过这种方式,模板方法模式允许子类在不改变算法结构的情况下重新定义算法的某些步骤。 模板方法模式的核心在于: …...

国产编辑器EverEdit - 脚本(解锁文本编辑的无限可能)
1 脚本 1.1 应用场景 脚本是一种功能扩展代码,用于提供一些编辑器通用功能提供不了的功能,帮助用户在特定工作场景下提高工作效率,几乎所有主流的编辑器、IDE都支持脚本。 EverEdit的脚本支持js(语法与javascript类似)、VBScript两种编程…...

越早越好!8 个反直觉的金钱真相|金钱心理学
很多人都追求财富自由,但成功的人少之又少。 这可能是因为,人们往往忽略了一些金钱的真相和常识。 01 金钱常识 & 真相 为了构建健康的金钱观,我读了一本有点反直觉,有点像鸡汤,但都是财富真相的书。 来自 Morg…...

linux docker相关指令
1、镜像操作 0)、搜索:docker search 镜像名称 1)、拉取:docker pull 2)、推送:docker push 3)、查看:docker images 4)、查看所有镜像ID:d…...

实时采集到的语音进行语音识别
要在.NET Framework 4.8中使用C#实现离线实时语音识别,可以使用开源库Vosk(支持离线ASR)配合音频处理库NAudio。 步骤 1:安装依赖库 1.1. 安装NuGet包: - Install-Package NAudio(处理音频输入)…...

Ollama 本地部署 DeepSeek R1 及 Python 运行 open-webui 界面(windows)
DeepSeek R1 ollama open-webui 本地部署(windows) DeepSeek-R1本地部署配置要求 Github地址:https://github.com/deepseek-ai/DeepSeek-R1?tabreadme-ov-file 模型规模最低 GPU 显存推荐 GPU 型号纯 CPU 内存需求适用场景1.5B4GBRTX 3…...

牛客周赛:84:C:JAVA
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述 \hspace{15pt}本题为《D.小红的陡峭值(三)》的简单版本,两题的唯一区别在于本题的数据范围更小。 \hspace{15pt}小红定义一个字符串的陡峭值为&a…...

5. 前后端实现文件上传与解析
1. 说明 在实际开发中,比较常见的一个功能是需要在前端页面中选择系统中的某个文件上传到服务器中进行解析,解析后的文件内容可以用来在服务器中当作参数,或者传递给其它组件使用,或者需要存储到数据库中。所以本文就提供一种方式…...

SpringBoot 接入 豆包 火山方舟大模型
火山方舟控制台 开通模型推理、知识库 应用入口; 文档中心 各类接口说明及SDK 获取; 向量数据库VikingDB 文档 下翻找到有java操作案例; 实现目标功能效果: 通过SDK调用 豆包大模型,在代码内实现问答的效果…...

IDEA接入阿里云百炼中免费的通义千问[2025版]
安装deepseek 上一篇文章IDEA安装deepseek最新教程2025中说明了怎么用idea安装codeGPT插件,并接入DeepSeek,无奈接入的官方api已经不能使用了,所以我们尝试从其他地方接入 阿里云百炼https://bailian.console.aliyun.com/ 阿里云百炼是阿…...

下载kali linux遇到的一些问题
kali官网:kali官网跳转 问题一:未启动VM Service VMware Workstation 未能启动 VMware Authorization Service。您可以尝试手动启动VMware Authorization Service。如果此问题仍然存在,请联系VMware 支持部门。 解决办法: 步骤1…...

常见排序算法深度评测:从原理到10万级数据实战
常见排序算法深度评测:从原理到10万级数据实战 摘要 本文系统解析冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序、堆排序和基数排序8种经典算法,通过C语言实现10万随机数排序并统计耗时。测试显示:快速排序综合性能最优&…...
使用详解)
Scaled_dot_product_attention(SDPA)使用详解
在学习huggingFace的Transformer库时,我们不可避免会遇到scaled_dot_product_attention(SDPA)这个函数,它被用来加速大模型的Attention计算,本文就详细介绍一下它的使用方法,核心内容主要参考了torch.nn.functional中该函数的注释…...

Linux练级宝典->Linux进程概念介绍
目录 进程基本概念 PCB概念 task_struct tack_struct内容分类 PID和PPID fork函数创建子进程 进程优先级概念 4个名词 进程地址空间 进程地址空间的意义 内核进程调度队列 优先级 活动队列 过期队列 进程基本概念 一个正在执行的程序。担当分配系统资源的实体&#…...

OpenHarmony 5.0 mpegts封装的H265视频播放失败的解决方案
问题现象 OpenHarmony 5.0版本使用AVPlayer播放mpegts封装格式的H.265(HEVC)编码格式的视频时出现报错导致播放失败 问题原因 OpenHarmony 5.0版本AVPlayer播放器使用histreamer引擎,因为 libav_codec_hevc_parser.z.so 动态库未开源导致H265编码格式视频解析不到…...

Qt从入门到入土(九) -model/view(模型/视图)框架
简介 Qt的模型/视图(Model/View)架构是一种用于分离数据处理和用户界面展示的设计模式。它允许开发者将数据存储和管理(模型)与数据的显示和交互(视图)解耦,从而提高代码的可维护性和可扩展性。…...

被AI欺骗啦:一个有趣的三极直接耦合放大电路的调整
简 介: 本文探讨了一个三极直接耦合放大电路的设计问题。初始使用AI工具设计的电路参数看似可行,但仿真显示Q1晶体管处于异常工作状态(BC结正向偏置)。通过重新调整电阻参数,特别是将反馈电阻R8设为10MΩ后,…...

终极指南:如何使用qmcdump轻松解密QQ音乐加密音频文件
终极指南:如何使用qmcdump轻松解密QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...

DICOM文件里除了图像,还藏了哪些信息?一份给开发者的隐私与元数据解析指南
DICOM文件里除了图像,还藏了哪些信息?一份给开发者的隐私与元数据解析指南 医疗影像数据是AI模型训练和医疗信息系统开发的重要基础,但许多开发者往往只关注图像像素本身,忽略了DICOM文件中蕴含的丰富元数据。这些元数据不仅包含关…...

实战解析:用高斯过程回归搞定不确定性预测
1. 高斯过程回归能解决什么问题 我第一次接触高斯过程回归是在一个金融风控项目里。当时我们需要预测未来三个月的用户违约概率,但传统机器学习模型只能给出一个冰冷的数字预测,完全无法体现预测的可信程度。这就像天气预报只告诉你"明天会下雨&quo…...

测水位·报雨情·预洪水:水文监测站
水文监测站采用先进平面阵列雷达微波探测技术,设备悬空架设、非接触式采集河道水体数据。通过高精度雷达天线持续发射微波信号,穿透空气介质触达水面后反射回波,系统精准测算信号传播时长与多普勒频移变化,结合设备自带角度校准功…...
 ;ISRPPGFSPFR)
Ile-Ser-Bradykinin(T-Kinin) ;ISRPPGFSPFR
一、基础信息多肽名称:Ile-Ser-Bradykinin,别名 T-Kinin(T - 激肽) 三字母序列:Ile-Ser-Arg-Pro-Pro-Gly-Phe-Ser-Pro-Phe-Arg 单字母序列:ISRPPGFSPFR 氨基酸数量:11 aa 结构修饰:线…...

挖掘MCU硬件加速潜力:以R80515的Double DPTR和MDU为例,在Keil C51中开启性能外挂
挖掘MCU硬件加速潜力:R80515双DPTR与MDU在Keil C51中的实战优化 当你在Keil C51环境下为资源受限的8051架构编写代码时,是否曾为缓慢的数据搬运和复杂的数学运算而头疼?现代增强型8051内核如R80515通过硬件加速单元提供了突破性能瓶颈的可能…...

从单机到集群的基石:手把手配置ZooKeeper 3.5.8单机模式,为分布式应用铺路
从单机到集群的基石:手把手配置ZooKeeper 3.5.8单机模式,为分布式应用铺路 在分布式系统的世界里,协调服务就像交响乐团的指挥,确保每个乐器(节点)在正确的时间演奏正确的音符。ZooKeeper正是这样一个"…...

英雄联盟Akari助手:智能游戏伴侣让你的排位赛效率提升10倍
英雄联盟Akari助手:智能游戏伴侣让你的排位赛效率提升10倍 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中繁琐的…...

终极免费跨平台方案:3步将知网CAJ论文转换为可编辑PDF的完整指南
终极免费跨平台方案:3步将知网CAJ论文转换为可编辑PDF的完整指南 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitc…...