openEuler Linux 部署 HadoopHA
openEuler Linux 部署 HadoopHA
升级操作系统和软件
yum -y update
升级后建议重启
安装常用软件
yum -y install gcc gcc-c++ autoconf automake cmake make rsync vim man zip unzip net-tools zlib zlib-devel openssl openssl-devel pcre-devel tcpdump lrzsz tar wget
修改主机名
hostnamectl set-hostname hadoop
或者
vim /etc/hostname
spark01
reboot
修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens160
网卡 配置文件示例
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
NAME=ens160
UUID=943779e9-249c-44bb-b272-d49ea5831ed4
DEVICE=ens160
ONBOOT=yes
IPADDR=192.168.28.11
PREFIX=24
GATEWAY=192.168.28.2
DNS1=192.168.28.2
保存后
nmcli con up ens160
重启网络服务
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
vim /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
# SELINUX=enforcing
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
# SELINUXTYPE=targeted SELINUX=disabled
执行下面命令
setenforce 0
或者
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
创建软件安装目录并上传软件,配置环境变量
mkdir -p /opt/soft
cd /opt/soft
# 上传jdk zookeeper
tar -zxvf jdk-8u361-linux-x64.tar.gz
mv jdk1.8.0_361 jdk8
tar -zxvf hadoop-3.3.5.tar.gz
mv hadoop-3.3.5 hadoop3vim /etc/profileexport JAVA_HOME=/opt/soft/jdk8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/binexport HADOOP_HOME=/opt/soft/hadoop3export HADOOP_INSTALL=${HADOOP_HOME}
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoopexport HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root编辑完成后使用source命令使文件~/.bash_profile生效执行以下命令
source /etc/profile
检查环境变量
printenv
修改域名映射
vim /etc/hosts
192.168.28.11 spark01
192.168.28.12 spark02
192.168.28.13 spark03
修改后建议重启
修改Hadoop配置文件 在hadoop解压后的目录找到 etc/hadoop目录
cd /opt/soft/hadoop3
修改如下配置文件
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- workers
- mapred-site.xml
- yarn-site.xml
hadoop-env.sh 文件末尾追加
export JAVA_HOME=/opt/soft/jdk8
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=rootexport YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>fs.defaultFS</name><value>hdfs://puegg</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop_data</value></property><property><name>hadoop.http.staticuser.user</name><value>root</value></property><!-- HDFS连接zookeeper集群的地址和端口 --><property><name>ha.zookeeper.quorum</name><value>spark01:2181,spark02:2181,spark03:2181</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
</configuration>
hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 定义hdfs集群ID号 --><property><name>dfs.nameservices</name><value>puegg</value></property><!-- 定义hdfs集群中namenode的ID号 --><property><name>dfs.ha.namenodes.puegg</name><value>nn1,nn2</value></property><!-- 定义namenode的主机名和RPC协议的端口 --><property><name>dfs.namenode.rpc-address.puegg.nn1</name><value>spark01:8020</value></property><property><name>dfs.namenode.rpc-address.puegg.nn2</name><value>spark02:8020</value></property><!-- 定义namenode的主机名和HTTP协议的端口 --><property><name>dfs.namenode.http-address.puegg.nn1</name><value>spark01:9870</value></property><property><name>dfs.namenode.http-address.puegg.nn2</name><value>spark02:9870</value></property><!-- 定义共享edits的URL --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://spark01:8485;spark02:8485;spark03:8485/puegg</value></property><!-- 定义HDFS的客户端连接HDFS集群时返回active namenode地址 --><property><name>dfs.client.failover.proxy.provider.puegg</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- HDFS集群中两个namenode切换状态时的隔离方法 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- HDFS集群中两个namenode切换状态时的隔离方法的密钥 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- journalnode集群中用于保存edits文件的目录 --><property><name>dfs.journalnode.edits.dir</name><value>/opt/journalnode/data</value></property><!-- HA的HDFS集群自动切换namenode的开关--><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><property><name>dfs.safemode.threshold.pct</name><value>1</value><description>Specifies the percentage of blocks that should satisfythe minimal replication requirement defined by dfs.replication.min.Values less than or equal to 0 mean not to wait for any particularpercentage of blocks before exiting safemode.Values greater than 1 will make safe mode permanent.</description></property>:q!
</configuration>
workers
spark01
spark02
spark03
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property>
</configuration>
yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<property><name>yarn.resourcemanager.ha.enabled</name><value>true</value>
</property>
<property><name>yarn.resourcemanager.cluster-id</name><value>cluster1</value>
</property>
<property><name>yarn.resourcemanager.ha.rm-ids</name>
<property><name>yarn.resourcemanager.hostname.rm1</name><value>spark01</value>
</property>
<property><name>yarn.resourcemanager.hostname.rm2</name><value>spark02</value>
</property>
<property><name>yarn.resourcemanager.webapp.address.rm1</name><value>spark01:8088</value>
</property>
<property><name>yarn.resourcemanager.webapp.address.rm2</name><value>spark02:8088</value>
</property>
<property><name>yarn.resourcemanager.zk-address</name><value>spark01:2181,spark02:2181,spark03:2181</value>
</property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>配置ssh免密钥登录
创建本地秘钥并将公共秘钥写入认证文件
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 或者
ssh-copy-id spark01
ssh-copy-id spark02
ssh-copy-id spark03
scp -rv ~/.ssh root@spark02:~/
scp -rv ~/.ssh root@spark03:~/
# 远程登录自己
ssh spark01
# Are you sure you want to continue connecting (yes/no)? 此处输入yes
# 登录成功后exit或者logout返回
exit
拷贝配置文件分发到其它服务器或者使用脚本分发
scp -v /etc/profile root@spark02:/etc
scp -v /etc/profile root@spark03:/etc
scp -rv /opt/soft/hadoop3/etc/hadoop/* root@spark02:/opt/soft/hadoop3/etc/hadoop/
scp -rv /opt/soft/hadoop3/etc/hadoop/* root@spark03:/opt/soft/hadoop3/etc/hadoop/
在各服务器上使环境变量生效
source /etc/profile
Hadoop初始化
# 创建数据目录
mkdir -p /home/hadoop_data
1. 启动三个zookeeper:zkServer.sh start
2. 启动三个JournalNode:hadoop-daemon.sh start journalnode
7. 在其中一个namenode上格式化:hdfs namenode -format
8. 把刚刚格式化之后的元数据拷贝到另外一个namenode上a) 启动刚刚格式化的namenode :hadoop-daemon.sh start namenodeb) 在没有格式化的namenode上执行:hdfs namenode -bootstrapStandbyc) 启动第二个namenode: hadoop-daemon.sh start namenode
9. 在其中一个namenode上初始化hdfs zkfc -formatZK
10. 停止上面节点:stop-dfs.sh
11. 全面启动:start-dfs.sh
12. 启动resourcemanager节点 yarn-daemon.sh start resourcemanager
yarn --daemon starthttp://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.5.0.tar13、安全模式hdfs dfsadmin -safemode enter
hdfs dfsadmin -safemode leave14、查看哪些节点是namenodes并获取其状态
hdfs getconf -namenodes
hdfs haadmin -getServiceState spark0115、强制切换状态
hdfs haadmin -transitionToActive --forcemanual spark01
重点提示:
# 关机之前 依关闭服务
stop-yarn.sh
stop-dfs.sh
# 开机后 依次开启服务
start-dfs.sh
start-yarn.sh
或者
# 关机之前关闭服务
stop-all.sh
# 开机后开启服务
start-all.sh
#jps 检查进程正常后开启胡哦关闭在再做其它操作
相关文章:

openEuler Linux 部署 HadoopHA
openEuler Linux 部署 HadoopHA 升级操作系统和软件 yum -y update升级后建议重启 安装常用软件 yum -y install gcc gcc-c autoconf automake cmake make rsync vim man zip unzip net-tools zlib zlib-devel openssl openssl-devel pcre-devel tcpdump lrzsz tar wget修改…...
)
React-Hooks----useEffect()
文章目录前言用法前言 useEffect() 是 React 中最常用的 Hook 之一,它可以让函数组件拥有类似于类组件中 componentDidMount、componentDidUpdate 和 componentWillUnmount 生命周期函数的功能。 用法 useEffect() 接受两个参数 第一个参数是一个函数,…...

JavaWeb基础-汇总
SSM框架课程汇总01-MySQL基础02-MySQL高级03-JDBC04-JDBC练习05-Maven&Mybatis基础06-Mybatis练习07-JavaScript08-Web概述09-HTTP10-Tomcat11-Servlet12-Request&Response13-用户注册登录案例14-JSP15-JSP案例16-会话技术17-用户登录注册案例18-Filter19-Listener&…...

Niuke:JZ36.二叉树与双向链表
文章目录Niuke:JZ36.二叉树与双向链表题目描述示例思路分析代码实现Niuke:JZ36.二叉树与双向链表 题目描述 描述 输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。如下图所示 注意: 1.要求不能创建任何新的结点,只…...

javaScript---读懂promise、async/await
一、Promise Promise 是一个 Es 6 提供的类,目的是更加优雅地书写复杂的异步任务。可以解决嵌套式的回调地域问题,Promise 将嵌套格式的代码变成了顺序格式的代码。 //回调地域 setTimeout(function () {console.log("红灯");setTimeout(function () {console.lo…...
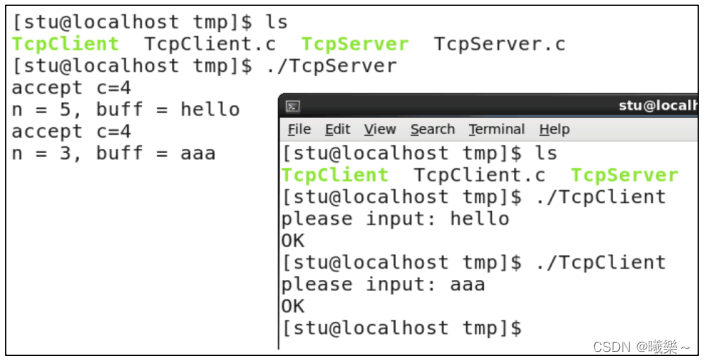
【Linux】TCP编程流程
TCP编程流程 socket()创建套接字,套接字TCP协议选择流式服务SOCK_STREAM。 bind()指定套接字使用的IP地址和端口。IP地址是自己主机地址,端口为一个16位的整形值。 listen()方法创建监听队列。监听队列分为存放未完成三次握手的连接和完成三次握手的连…...
SuperMap iDesktop 下载安装,生成本地瓦片,以及发布本地瓦片服务
SuperMap iDesktop 是插件式桌面GIS软件,提供基础版、标准版、专业版和高级版四个版本,具备二三维一体化的数据处理、制图、分析、海图、二三维标绘等功能,支持对在线地图服务的无缝访问及云端资源的协同共享,可用于空间数据的生产…...

【ONE·Data || 常见排序说明】
总言 数据结构基础:排序相关内容。 文章目录总言1、基本介绍2、插入排序2.1、直接插入排序:InsertSort2.1.1、单趟2.1.2、总趟2.2、希尔排序(缩小增量排序):ShellSort2.2.1、预排序1.0:单组分别排序2.…...

本节作业之跟随鼠标的天使、模拟京东按键输入内容、模拟京东快递单号查询
本节作业之跟随鼠标的天使、模拟京东按键输入内容、模拟京东快递单号查询1 跟随鼠标的天使2 模拟京东按键输入内容3 模拟京东快递单号查询1 跟随鼠标的天使 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><met…...

ChatGPT 被大面积封号,到底发生什么了?
意大利数据保护机表示 OpenAI 公司不但非法收集大量意大利用户个人数据,没有设立检查 ChatGPT 用户年龄的机制。 ChatGPT 似乎正在遭遇一场滑铁卢。 3月31日, 大量用户在社交平台吐槽,自己花钱开通的 ChatGPT 账户已经无法登录,更…...

教你精通JavaSE语法之第十一章、认识异常
一、异常的概念与体系结构 1.1异常的概念 在Java中,将程序执行过程中发生的不正常行为称为异常。比如之前写代码时经常遇到的: 1.算术异常 System.out.println(10 / 0); // 执行结果 Exception in thread "main" java.lang.ArithmeticExcep…...

display、visibility、opacity隐藏元素的区别
display、visibility、opacity隐藏元素的区别 display: none 事件监听:无法进行DOM事件监听。 元素从网页中消失,并且不占据位置再次从网页中出现会引起重排 进而引起重绘继承:不会被子元素继承,因为子元素也不被渲染。 visib…...

Linux Shell 实现一键部署tomcat10+java13
tomcat 前言 Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选。对于一个初学者来说,可以这样认为,当…...

软硬皆施,WMS仓库管理系统+PDA,实现效率狂飙
人工经验Excel表格,是传统第三方仓储企业常用的管理模式。在这种管理模式下,对仓库员工的Excel操作能力、业务经验和工作素养要求极高。一旦员工的经验能力不足,就会导致仓库业务运行不顺畅,效率低下,而员工也会因长时…...
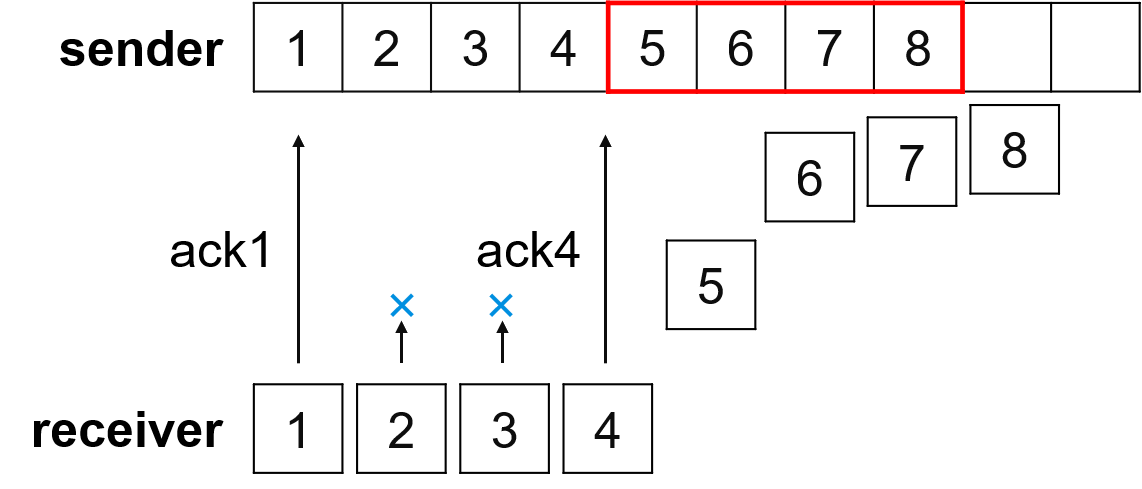
DJ3-2 传输层(第二节课)
目录 一、如何实现可靠数据传输 1. 需要解决地问题 2. 使用的描述方法 二、rdt1.0:完全可靠信道上的可靠数据传输 1. 前提条件 2. 有限状态机 FSM 三、rdt2.0:仅具有 bit 错误的信道上的可靠数据传输 1. 前提条件 2. 有限状态机 FSM 3. 停等协…...
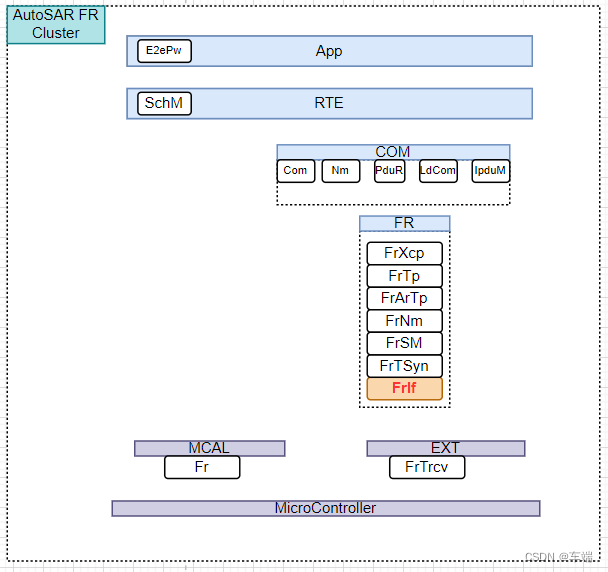
FrIf-FrIf功能模块概述和与底层驱动的交互
总目录链接==>> AutoSAR入门和实战系列总目录 总目录链接==>> AutoSAR BSW高阶配置系列总目录 文章目录 1 FlexRay 接口模块概述2 与FlexRay底层驱动的交互1 FlexRay 接口模块概述 FlexRay 接口模块通过 FlexRay 驱动程序模块间接与 FlexRay 控制器通信。 它…...
)
【LeetCode】前 K 个高频元素(堆)
目录 1.题目要求: 给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。 2.解题思路: 代码展示: 1.题目要求: 给你一个整数数组 nums 和一个整数 k ࿰…...
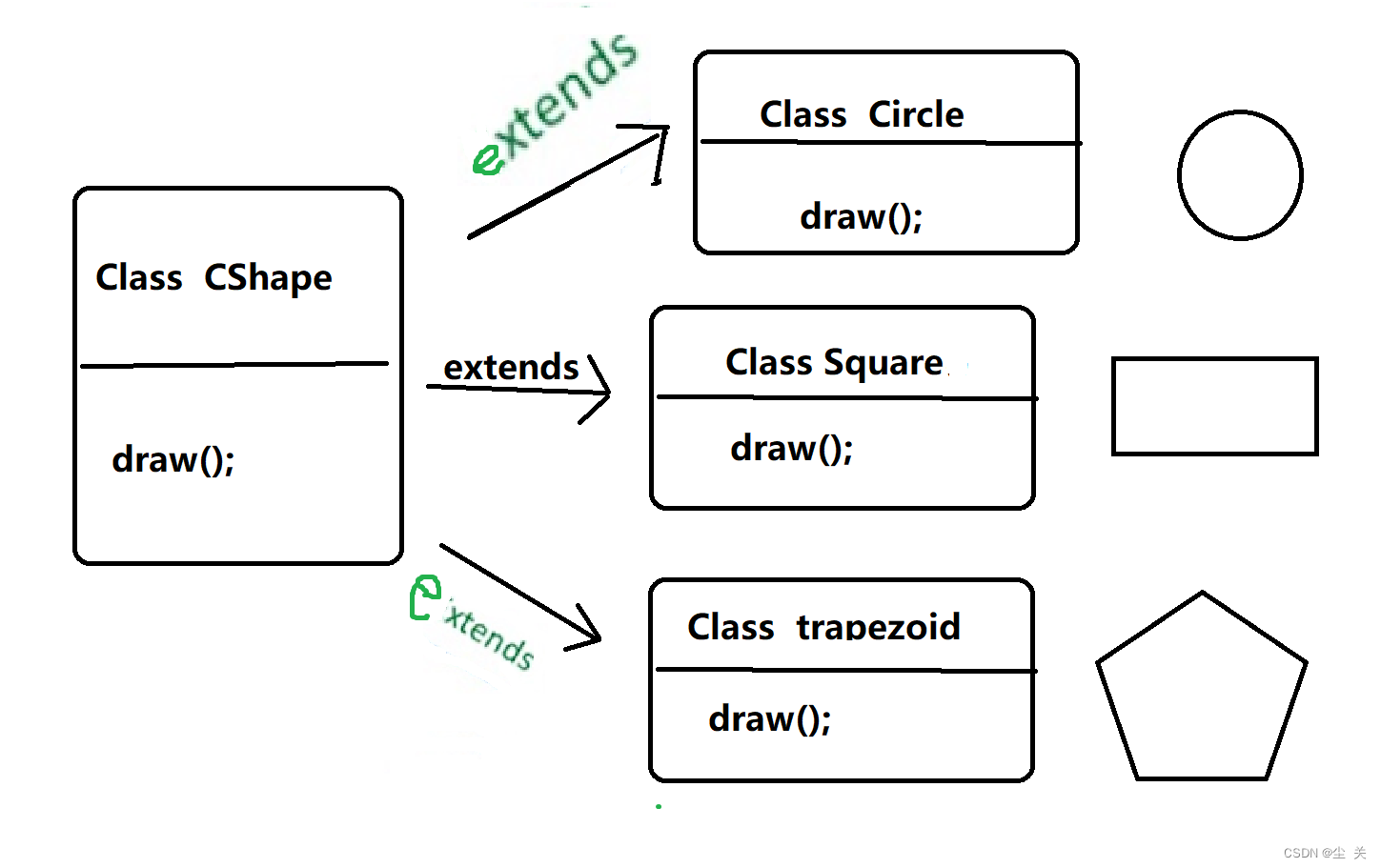
Java ---多态
(一)定义 官方:多态是同一个行为具有多个不同表现形式或形态的能力。多态就是同一个接口,使用不同的实例而执行不同操作。 生活中的多态,如图所示: 多态性是对象多种表现形式的体现。 现实中,…...

13个程序员常用开发工具用途推荐整理
作为一名刚入门的程序员,选择合适的开发工具可以提高工作效率,加快学习进度。在本文中,我将向您推荐10个常用的开发工具,并通过简单的例子和代码来介绍它们的主要用途。 1. Visual Studio Code Visual Studio Code(V…...
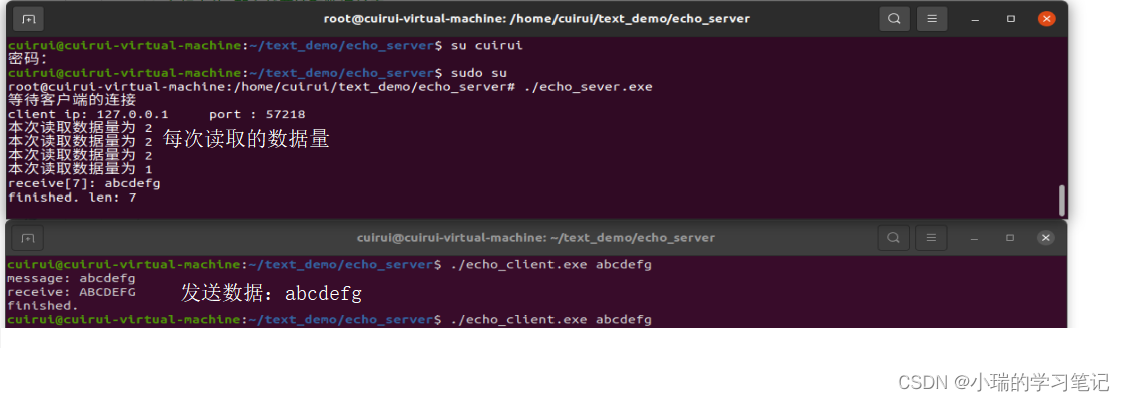
TCP分包和粘包
文章目录TCP分包和粘包TCP分包TCP 粘包分包和粘包解决方案:TCP分包和粘包 TCP分包 场景:发送方发送字符串”helloworld”,接收方却分别接收到了两个数据包:字符串”hello”和”world”发送端发送了数量较多的数据,接…...

Phi-3-mini-128k-instruct实战案例:中小企业技术文档自动解析与结构化提取
Phi-3-mini-128k-instruct实战案例:中小企业技术文档自动解析与结构化提取 1. 项目背景与价值 对于中小企业而言,技术文档管理一直是个令人头疼的问题。工程师们经常需要从大量PDF、Word文档中提取关键信息,手动整理成结构化数据。这个过程…...

高效管理惠普OMEN游戏本:OmenSuperHub全面解析与实战指南
高效管理惠普OMEN游戏本:OmenSuperHub全面解析与实战指南 【免费下载链接】OmenSuperHub 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub OmenSuperHub是一款专为惠普OMEN系列游戏本设计的轻量级系统管理工具,它通过替代原厂Omen Ga…...

避开这些坑!群晖+acme.sh申请Let’s Encrypt证书的完整指南
群晖NAS上零踩坑申请Lets Encrypt证书的终极实践手册 每次看到浏览器地址栏那个刺眼的"不安全"提示就浑身难受?作为群晖深度用户,我花了三个周末时间踩遍了所有证书申请的坑。从idn指令缺失到nss验证失败,从API调用超时到证书自动更…...
——GDI 设备上下文(HDC)完全指南)
通用GUI编程技术——Win32 原生编程实战(十八)——GDI 设备上下文(HDC)完全指南
通用GUI编程技术——Win32 原生编程实战(十八)——GDI 设备上下文(HDC)完全指南 前面一系列文章我们聊了对话框、控件、资源这些内容,我们的窗口已经能够显示各种控件了。但你可能已经发现了一个问题:我们所…...

IntelliJ Conf:JetBrains Koog Java原生AI Agent框架实战
文章目录前言:Java程序员的"Agent焦虑"终于有解了认识Koog:不是又一个LangChain的Java版环境准备:5分钟让项目跑起来实战:从Hello World到智能客服第一步:定义工具(Tool)第二步&#…...

轴承故障诊断实战:从振动信号到Python代码的完整分析流程
轴承故障诊断实战:从振动信号到Python代码的完整分析流程 在工业设备维护领域,轴承作为旋转机械的核心部件,其健康状态直接影响设备运行效率与安全性。传统的人工巡检方式已难以满足现代工业对故障预警的实时性需求,而基于振动信号…...

douyin-downloader:让每个人都能轻松获取无水印视频的技术利器
douyin-downloader:让每个人都能轻松获取无水印视频的技术利器 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 一、问题破局:揭开抖音内容获取的神秘面纱 1.1 内容获取的三大拦路虎 …...

Visual Studio 2019安装Python组件失败?教你手动定位installer目录完成安装
Visual Studio 2019安装Python组件失败的终极解决方案 当你在Visual Studio 2019中尝试安装Python组件时,突然遇到"安装程序不完整"的错误提示,这确实令人沮丧。作为一名长期使用VS进行Python开发的工程师,我完全理解这种中断对工作…...

51单片机Proteus仿真实战:从零构建流水灯系统
1. 环境准备:搭建51单片机开发环境 第一次接触51单片机的朋友可能会被各种工具软件搞晕,其实只需要两个核心工具就能完成流水灯仿真:Proteus和Keil。我刚开始学单片机时也踩过不少坑,这里把最稳定的版本和安装要点分享给大家。 Pr…...

Unity引擎开发过的VR大场景项目网络技术,资源处理及热更新方案的报价大概多少
根据最新的市场招标数据、行业报价案例和技术方案分析,针对VR大场景项目的网络技术、资源处理、热更新方案三大模块的报价,整理如下:一、网络技术方案报价 网络技术方案主要解决多人在线同步、远程渲染、低延迟通信等问题。方案类型技术选型报…...