mysql性能优化之explain分析执行计划
前言
在实际工作中,如果已经定位到某些具体的sql需要进行explain分析进而优化,可以直接使用explain+sql来分析其执行计划;如果还不能确定是哪些具体的sql语句需要进行explain分析进而优化,那么我们可以首先要定位哪些sql查询慢,性能低,消耗高;
定位低效sql
- 慢查询日志,可以通过开启慢查询日志来定位低效sql,它是通过设置慢查询时间阈值(默认是10s)或者设置查询没有走索引的sql记录到慢查询日志中;mysql性能优化之慢查询
- show processlist :慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题的时候查询慢查询日志并不能定位问题,可以使用
show processlist命令查看当前MySQL在进行的线程,包括线程的状态、是否锁表等,可以实时地查看 SQL的执行情况,同时对一些锁表操作进行优化。
explain介绍
使用explain分析执行计划实际上是:模拟优化器执行SQL语句;分析你的查询语句或是结构的性能瓶颈,使用方式
explain 需要分析的查询sql,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息, 而不是执行这条SQL 注意:如果 from 中包含子查询,仍会执行该子查询,将结果放入临时表中。
在mysql官网中与explain相关的文章也有很多,首推去官网阅读学习
了解查询执行计划
我们能通过explain + sql知道些什么了?
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询 …
话不多说,直接拿一条sql使用explain来分析一下,并对它的一些参数进行解读;
为了测试,有2张表emp和dept;

explain select * from dept;

+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 498343 | 100 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
1 row in set
字段解读
| 字段 | 含义 |
|---|---|
| id | select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 |
| select_type | 表示 SELECT 的类型,常见的取值有:1.SIMPLE(简单表,即不使用表连接或者子查询)、2.PRIMARY(主查询,即外层的查询)、3.UNION(UNION 中的第二个或者后面的查询语句)、4.SUBQUERY(子查询中的第一个 SELECT)等 |
| table | 输出结果集的表 |
| type | 表示表的连接类型,性能由好到差的连接类型为( system —> const -----> eq_ref ------> ref-------> ref_or_null----> index_merge —> index_subquery -----> range -----> index ------>all ) |
| possible_keys | 表示查询时,可能使用的索引 |
| key | 表示实际使用的索引 |
| key_len | 索引字段的长度 |
| rows | 扫描行的数量 |
| extra | 执行情况的说明和描述 |
id
id 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。id 情况有三种:
- id 相同,表示加载表的顺序是从上到下。
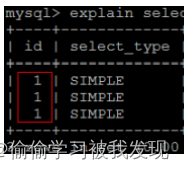
- id 不同,id值越大,优先级越高,越先被执行。
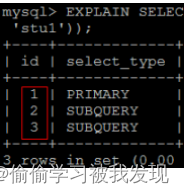
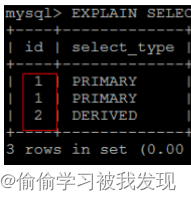
- id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
select_type
数据读取操作的操作类型,查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
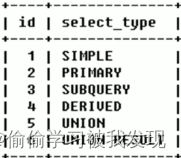
| select_type | 含义 |
|---|---|
| SIMPLE | 简单的select查询,查询中不包含子查询或者UNION |
| PRIMARY | 查询中若包含任何复杂的子查询,最外层查询标记为该标识 |
| SUBQUERY | 在SELECT 或 WHERE 列表中包含了子查询 |
| DERIVED | 在FROM 列表中包含的子查询,被标记为 DERIVED(衍生) MYSQL会递归执行这些子查询,把结果放在临时表中 |
| UNION | 若第二个SELECT出现在UNION之后,则标记为UNION ; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为 : DERIVED |
| UNION RESULT | 从UNION表获取结果的SELECT |
table
显示执行的表名,这一列表示 explain 的一行正在访问哪个表。
当 from 子句中有子查询时,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查询。 当有 union 时,UNION RESULT 的 table 列的值为<union id1,id2>,id1和id2表示参与 union 的 select 行id。
type
type 显示的是访问类型。
结果值从最好到最坏依次是:
null> system > const > eq_ref > ref > range > index > all
在实际工作中,我认为:查询sql至少达到 range 级别。
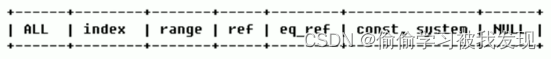
| type | 含义 |
|---|---|
| null | MySQL不访问任何表,索引,直接返回结果 |
| system | 表只有一行记录(等于系统表),这是const类型的特例,一般不会出现 |
| const | 表示通过索引一次就找到了,const 用于比较primary key 或者 unique 索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL 就能将该查询转换为一个常量。const于将"主键" 或 “唯一” 索引的所有部分与常量值进行比较 |
| eq_ref | 类似ref,区别在于使用的是唯一索引,使用主键的关联查询,关联查询出的记录只有一条。常见于主键或唯一索引扫描 |
| ref | 表之间的引用,显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回所有匹配某个单独值的所有行(多个) |
| range | 只检索给定返回的行,使用一个索引来选择行。 where 之后出现 between , < , > , in 等操作。 |
| index | index 与 ALL的区别为 index 类型只是遍历了索引树, 通常比ALL 快, ALL 是遍历数据文件。 |
| all | 将遍历全表以找到匹配的行 |
key
| key | 含义 |
|---|---|
| possible_keys | 哪些索引可以使用,显示可能应用在这张表的索引, 一个或多个 |
| key | 哪些索引被实际使用,实际使用的索引, 如果为NULL,则没有使用索引 |
| key_len | 消耗的字节数,表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前 提下,长度越短越好 |
rows
每张表有多少行被优化器查询,根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数(越小越好)。
extra
其他的额外的执行计划信息,在该列展示 。
| extra | 含义 |
|---|---|
| using filesort | 需要优化,说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取, 称为“文件排序”, 效率低。 |
| using temporary | 需要优化,使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于 order by 和group by; 效率低 |
| using index | 表示相应的select操作使用了覆盖索引, 避免访问表的数据行, 效率不错。 |
相关文章:
mysql性能优化之explain分析执行计划
前言 在实际工作中,如果已经定位到某些具体的sql需要进行explain分析进而优化,可以直接使用explainsql来分析其执行计划;如果还不能确定是哪些具体的sql语句需要进行explain分析进而优化,那么我们可以首先要定位哪些sql查询慢&…...
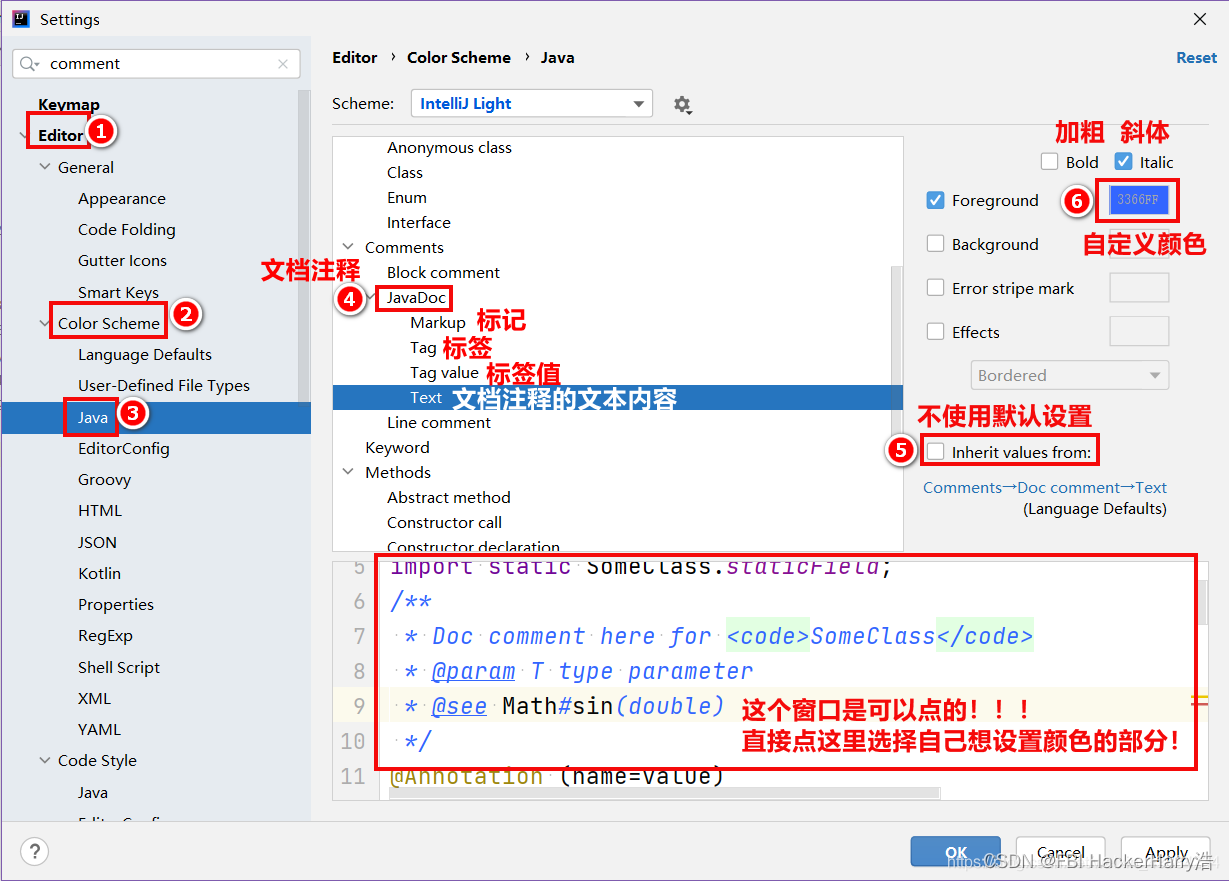
IDEA修改关键字和注释颜色
IDEA修改关键字和注释颜色 目录IDEA修改关键字和注释颜色1.修改关键字的默认颜色2.修改注释的默认颜色2.1 修改单行注释的颜色2.2 修改多行注释的颜色2.3 修改文档注释的颜色很多小白在刚刚使用IDEA的时候还不是很熟练 本文主要给大家提供一些使用的小技巧,希望能帮…...

数据库总结/个人总结
目录数据库数据和信息Data数据数据库数据库管理系统总结常见的数据库管理系统关系型数据库连接查询交叉连接、笛卡尔积内连接左连接右连接嵌套查询Jar在Java项目中使用.jar文件JDBC核心接口单表查询SQL注入简化JDBC视图View创建视图使用视图删除视图事务transaction事务的特性A…...

【Maven】开发自己的starter依赖
【Maven】开发自己的starter依赖 文章目录【Maven】开发自己的starter依赖1. 准备工作1.1 创建一个项目1.2 修改pom文件1.3 修改项目结构2. 动手实现2.1 创建客户端类2.2 创建配置类2.3 配置路径2.4 下载到本地仓库3. 测试1. 准备工作 1.1 创建一个项目 打开idea,…...

JVM与Java体系
JVM体系跟着尚硅谷的康师傅学习 JVM内存与垃圾回收概述 除了大部分的Java开发 人员,除了会在项目中使用到与Java平台相关的框架,与API,对于Java的虚拟机了解甚少。但是也需要我们知道如何处理OOM,SOF异常,除了…...
【C++笔试强训】第十二天
选择题 解析:引用:引用是对象的别名,并没有开辟属于自己的空间,两者同用一块内存,引用值改变也会引起引用对象值的改变; 引用在声明的时候必须要初始化,而指针不用,指针可以为空指针…...

C# | 使用DataGridView展示JSON数组
C# | 使用DataGridView展示JSON数组 文章目录C# | 使用DataGridView展示JSON数组前言实现原理实现过程完整源码前言 你想展示一个复杂的JSON数组数据吗?但是你却不知道该如何展示它,是吗?没问题,因为本文就是为解决这个问题而生的…...

Python入门到高级【第四章】
预计更新第一章. Python 简介 Python 简介和历史Python 特点和优势安装 Python 第二章. 变量和数据类型 变量和标识符基本数据类型:数字、字符串、布尔值等字符串操作列表、元组和字典 第三章. 控制语句和函数 分支结构:if/else 语句循环结构&#…...

【ChatGPT】ChatGPT 能否取代程序员?
Yan-英杰的主页 悟已往之不谏 知来者之可追 C程序员,2024届电子信息研究生 目录 前言: ChatGPT 的优势 自然语言的生成 文本自动生成 建立了更人性化的人机交互 ChatGPT 的局限性 算法的解释能力较差 程序的可实现性较差 缺乏优化和质量控制 程序员相较于 …...

英飞凌Tricore问题排查01_Det/Reset/Trap排查宝典
目录 1.概述2. 排查方法总览(流程图)3. 进Det排查方法4. 进Reset/Trap排查4.1 通过ErrorHook/ProtectionHook排查4.2. 通过BTV寄存器排查Trap方法4.3 借助英飞凌寄存器排查4.3.1 借助Reset状态寄存器4.3.2 SMU触发的复位4.3.3 CPU触发的复位1.概述 大家在软件开发过程中,可…...

第六章 共享模型之 无锁
JUC并发编程系列文章 http://t.csdn.cn/UgzQi 文章目录JUC并发编程系列文章前言一、问题的引出如何保证取款方法的线程安全解决方案一、使用synchronized锁住临界区代码解决方案二、无锁(AtomicInteger 原子整数类)二、CAS 与 volatileAtomicInteger . compareAndSet( ) 方法的…...

2023Q2押题,华为OD机试用Python实现 -【机智的外卖员】
最近更新的博客 华为 od 2023 | 什么是华为 od,od 薪资待遇,od 机试题清单华为 OD 机试真题大全,用 Python 解华为机试题 | 机试宝典【华为 OD 机试】全流程解析+经验分享,题型分享,防作弊指南华为 od 机试,独家整理 已参加机试人员的实战技巧本篇题解:机智的外卖员 题目…...
)
【华为OD机试真题】密室逃生游戏(javapython)
密室逃生游戏 题目 小强增在参加《密室逃生》游戏,当前关卡要求找到符合给定 密码 K(升序的不重复小写字母组 成) 的箱子, 并给出箱子编号,箱子编号为 1~N 。 每个箱子中都有一个 字符串 s ,字符串由大写字母、小写字母、数字、标点符号、空格组成, 需要在这些字符串中…...
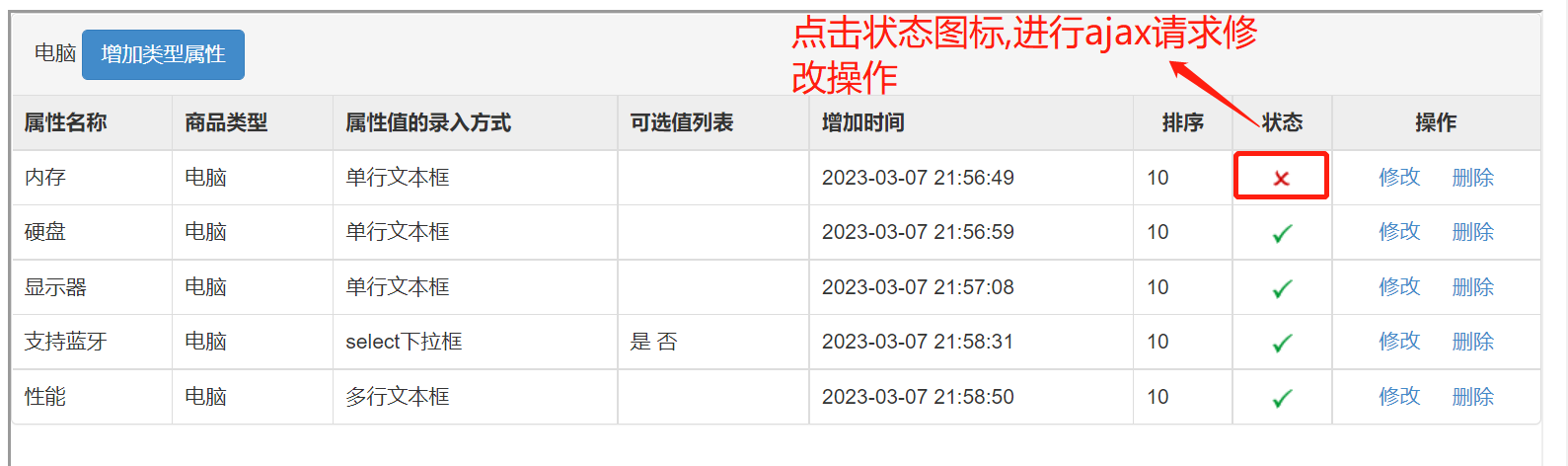
[golang gin框架] 17.Gin 商城项目-商品分类模块, 商品类型模块,商品类型属性模块功能操作
一.商品分类的增、删、改、查,以及商品分类的自关联1.界面展示以及操作说明列表商品分类列表展示说明:(1).增加商品分类按钮(2).商品分类,以及子分类相关数据列表展示(3).排序,状态,修改,删除操作处理 新增编辑删除修改状态,排序2.创建商品分类模型在controllers/admin下创建Go…...

Redis安装-使用包管理安装Redis
这种在Linux上使用apt-get包管理器安装Redis的方式称为“包管理安装”。这种安装方式使用操作系统的官方软件库来获取和安装软件包,可以自动处理软件包的依赖关系,并确保软件包与系统其他部分兼容。这是一种安全、可靠且方便的安装方式,适用于…...
HTML属性的概念和使用
通过前面的学习,我们已经对 HTML标签 有了简单的认识,知道可以在标签中可以添加一些属性,这些属性包含了标签的额外信息,例如: href 属性可以为 <a> 标签提供链接地址;src 属性可以为 <img> 标…...
ChatGPT基础知识系列之一文说透ChatGPT
ChatGPT基础知识系列之一文说透ChatGPT OpenAI近期发布聊天机器人模型ChatGPT,迅速出圈全网。它以对话方式进行交互。以更贴近人的对话方式与使用者互动,可以回答问题、承认错误、挑战不正确的前提、拒绝不适当的请求。高质量的回答、上瘾式的交互体验,圈内外都纷纷惊呼。 …...
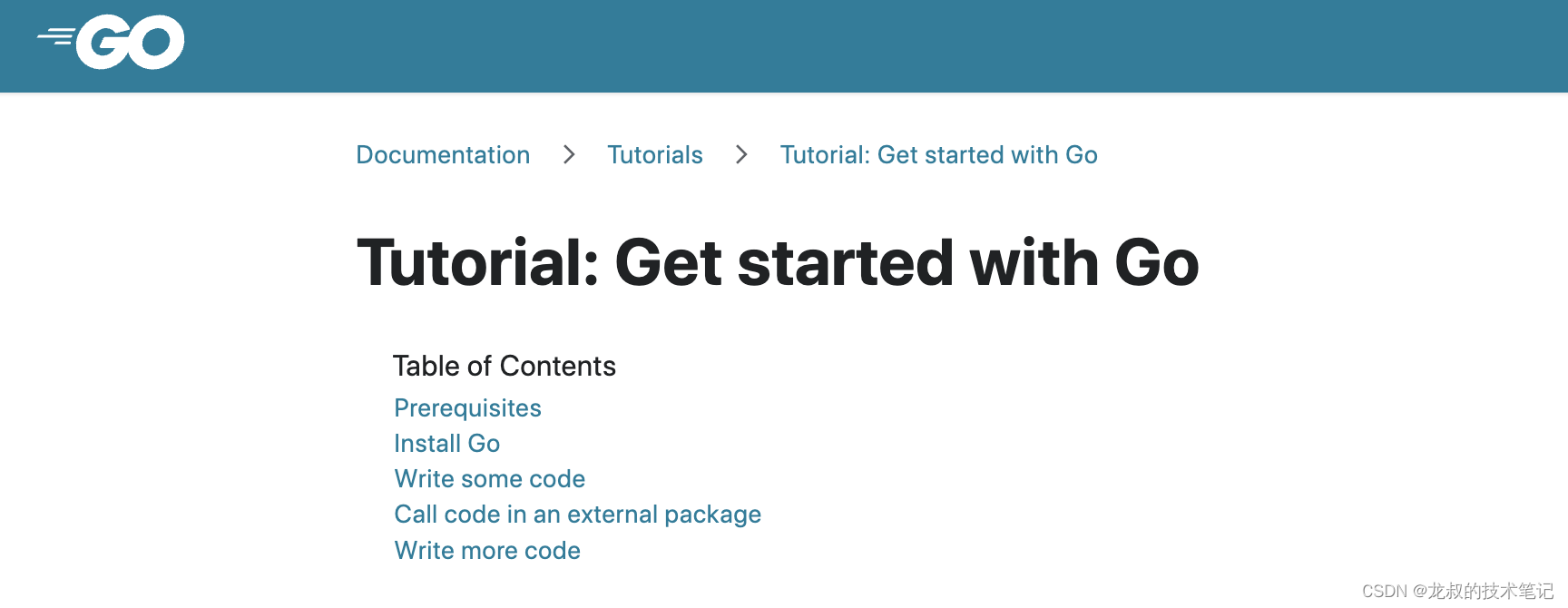
‘go install‘ requires a version when current directory is not in a module
背景 安装好环境之后,跑个helloworld看看 目录结构 workspacepathsrchellohelloworld.go代码: package mainimport "fmt"func main() { fmt.Println("Hello World") }1.使用 go run 命令 - 在命令提示符旁,输入 go …...

蓝桥杯嵌入式第十三届(第二套客观题)
文章目录 前言一、题目1二、题目2三、题目3四、题目4五、题目5六、题目6七、题目7八、题目8九、题目9十、题目10总结前言 本篇文章继续讲解客观题。 一、题目1 这个其实属于送分题,了解嵌入式或者以后想要入行嵌入式的同学应该都对嵌入式特点有所了解。 A. 采用专用微控制…...

FFmpeg进阶:各种输入输出设备
文章目录查看设备列表输入设备介绍输出设备介绍查看设备列表 我们可以通过ffmpeg自带的工具查看系统支持的设备列表信息, 对应的指令如下所示: ffmpeg -devices输入设备介绍 通过配置ffmpeg的输入设备,我们可以访问系统中的某个多媒体设备的数据。下面详细介绍一下各个系统中…...

打破数据标注瓶颈:Label Studio如何让AI训练效率提升300%?
打破数据标注瓶颈:Label Studio如何让AI训练效率提升300%? 【免费下载链接】label-studio Label Studio is a multi-type data labeling and annotation tool with standardized output format 项目地址: https://gitcode.com/GitHub_Trending/la/labe…...

别再让PowerBI报告挤成一团了!用按钮+书签,一个页面搞定趋势和明细分析
PowerBI交互设计进阶:用按钮与书签打造空间魔术 当业务分析报告遇上数据爆炸时代,信息过载与界面拥挤成为每个分析师挥之不去的噩梦。我曾见过某零售企业的季度分析仪表板——12个图表密密麻麻挤在A4纸大小的画布上,趋势线相互缠绕ÿ…...
)
从锡膏印刷到炉温曲线:手把手调试你的第一条SMT生产线(避坑指南)
从锡膏印刷到炉温曲线:手把手调试你的第一条SMT生产线(避坑指南) 第一次接手SMT生产线调试时,我盯着那台二手贴片机的报警提示,手心全是汗。钢网上残留的锡膏像在嘲笑我的无知,而流水线上堆积的PCB板则不断…...

2026年网络安全报告
2026年网络安全报告 2026年网络安全报告分析了2025年全球网络威胁形势,指出攻击速度和规模加快,人工智能、身份滥用等技术被攻击者整合,同时预测了2026年行业趋势并给出首席信息安全官建议。 网络安全趋势 不止电子邮件:多渠道…...

管人对账累垮人?巨有科技智慧市集系统一招减负
从城市商圈到景区古镇,从乡村田园到文创园区,各类市集遍地开花,但管理难题始终是制约行业发展的最大瓶颈。人工登记杂乱、对账结算繁琐、现场管控滞后、数据完全空白,一场中型市集就要耗费大量人力物力,大型市集更是纠…...
)
5分钟搞定:用OpenAI Function Calling自动生成Python函数(附Gmail API实战代码)
5分钟实战:用OpenAI Function Calling生成Gmail自动化脚本 每次对接Gmail API都要翻文档写重复代码?试试这个方案——用自然语言描述需求,让AI直接生成可运行的生产级代码。下面这段完整代码就是AI生成的成果,包含错误处理、类型…...
)
不止于公式:用国民技术N32G45x定时器实现精准时间片调度(附代码)
不止于公式:用国民技术N32G45x定时器实现精准时间片调度(附代码) 在嵌入式系统开发中,定时器是最基础也最强大的外设之一。对于国民技术N32G45x系列微控制器而言,其丰富的定时器资源(TIM2/3/4等)…...

SWF逆向工程行业报告:JPEXS Free Flash Decompiler市场份额2025深度分析
SWF逆向工程行业报告:JPEXS Free Flash Decompiler市场份额2025深度分析 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler 在Flash技术逐渐退出主流但仍有大量历史资产需要维护…...

解锁自定义键盘体验:用Vial-QMK打造个性化配置指南
解锁自定义键盘体验:用Vial-QMK打造个性化配置指南 【免费下载链接】vial-qmk QMK fork with Vial-specific features. 项目地址: https://gitcode.com/gh_mirrors/vi/vial-qmk 核心价值:为什么选择Vial-QMK定制键盘? 在机械键盘的世…...

PFC颗粒流代码模拟岩石预制裂隙与完整岩石单轴压缩对比分析
PFC颗粒流代码 pfc离散元岩石预制裂隙,裂隙岩石与完整岩石单轴压缩代码,可出各种裂隙形式,可分析应力应变曲线图,裂隙发育与数量,能量变化,简易声发射分析等做岩石单轴压缩离散元模拟的,谁没为…...