Python入门到高级【第四章】
预计更新
第一章. Python 简介
- Python 简介和历史
- Python 特点和优势
- 安装 Python
第二章. 变量和数据类型
- 变量和标识符
- 基本数据类型:数字、字符串、布尔值等
- 字符串操作
- 列表、元组和字典
第三章. 控制语句和函数
- 分支结构:if/else 语句
- 循环结构:for 和 while 循环
- 函数
- 参数传递与返回值
- Lambda 表达式
第四章. 模块和文件 IO
- 模块的概念
- 导入模块
- 文件 IO
- 序列化和反序列化
第五章. 异常处理
- 异常简介
- try/except 语句
- 自定义异常
第六章. 面向对象编程
- 类和对象
- 继承和多态
- 属性和方法
- 抽象类和接口
第七章. 正则表达式
- 正则表达式概述
- 匹配和搜索
- 替换和分割
第八章. 并发编程
- 多线程
- 多进程
- 协程和异步编程
第九章. 数据库编程
- 关系型数据库介绍
- 使用 SQLite 数据库
- 使用 MySQL 数据库
- 使用 PostgreSQL 数据库
第十章. 网络编程
- Socket 编程简介
- TCP Socket 编程
- UDP Socket 编程
- HTTP 编程
第十一章. Web 开发框架 Flask
- Flask 简介
- 安装 Flask
- 路由和视图函数
- 模板和静态文件
第十二章. 数据分析和科学计算
- NumPy 基础
- Pandas 基础
- Matplotlib 基础
第十三章 机器学习入门
- 机器学习概述
- 监督学习和非监督学习
- Scikit-Learn 简介
- 利用 Scikit-Learn 进行数据预处理和模型训练
第十四章. 自然语言处理
- 自然语言处理概述
- 中文分词和处理
- 文本分类和情感分析
第十五章. 游戏开发与 Pygame
- Pygame 简介
- Pygame 基础
- 开发一个简单的游戏
第四章. 模块和文件 IO- 模块的概念- 导入模块- 文件 IO- 序列化和反序列化
模块的概念
在Python编程中,模块是指一个包含Python代码的文件,可以包含变量、函数、类等定义。其作用是将相关代码组织在一起,提供代码复用性和可维护性,并避免命名空间冲突问题。
本文将详细介绍Python模块的概念、使用方法以及一些与模块有关的高级特性。
一、模块的概念
Python中的模块就是一个包含Python代码的文件,其中可以包含变量、函数、类等定义,也可以包含一些执行语句。每个模块都有自己的命名空间,因此不同模块中的同名对象不会发生冲突。
Python标准库中包含了很多常用的模块,如os、sys、re等,这些模块可以直接导入到Python程序中使用。同时,Python还支持自定义模块,我们可以根据实际需求创建一个或多个模块文件,并将其中的代码封装成为一个独立的模块。
二、模块的使用方法
Python中使用import关键字来导入一个模块,并将其中定义的变量、函数、类等对象引入到当前作用域中。具体的导入语法如下:
import module_name
其中“module_name”是要导入的模块名称。例如,以下代码导入了Python标准库中的os模块:
import os
在导入了一个模块之后,我们就可以使用其中定义的变量、函数或类了。例如,以下代码使用os模块中的getcwd()函数获取当前工作目录,并输出到控制台:
import oscurrent_dir = os.getcwd()
print(current_dir)
除了直接导入一个模块外,Python还支持一些其他的导入方式,如使用from关键字导入模块中的特定对象:
from module_name import object_name
其中“module_name”是要导入的模块名称,“object_name”是该模块中要导入的特定对象的名称。例如,以下代码从os模块中导入了chdir()函数,并将其重命名为cd():
from os import chdir as cdcd('/opt')
同时,Python还支持使用*通配符导入模块中的所有对象,不建议在实际开发中使用。这种导入方式可能会导致命名空间冲突等问题。
三、模块的高级特性
- 命名空间和作用域
每个模块都有自己独立的命名空间,其中定义的变量、函数、类等对象只在该命名空间内可见,不会对其他模块产生影响。因此,在编写模块时需要注意命名空间的设计,避免命名冲突等问题。
同时,在Python中还存在作用域的概念,不同作用域内定义的变量、函数等对象也有不同的可见性。其中,全局作用域是指在程序执行过程中始终存在的命名空间,而局部作用域则是指在函数执行过程中临时创建的命名空间。在访问一个变量时,Python会按照作用域链来查找该变量,首先在当前作用域内查找,如果没有找到则向上一级作用域继续查找,直至找到为止。
- __name__属性
每个模块都有一个特殊的__name__属性,用于标识该模块的名称。当一个模块被导入时,其__name__属性值为模块的名称;当一个模块被直接执行时,其__name__属性值为’ main’。我们可以利用这个特性来编写一些可复用的代码,同时也可以在模块被直接执行时执行一些特定的操作。
例如,以下代码定义了一个名为“my_module”的模块,并在其中定义了一个函数“hello()”,该函数会输出一条问候语。同时,在模块被直接执行时,会输出一条提示信息。
def hello():print('Hello, world!')if __name__ == '__main__':print('This module is being executed directly.')
在另一个Python程序中,我们可以使用import语句导入这个模块,并调用其中定义的函数:
import my_modulemy_module.hello()
在执行这段代码时,Python会首先导入名为“my_module”的模块,并执行其中的代码。当我们调用hello()函数时,它会输出一条问候语。而由于在模块被直接执行时会输出一条提示信息,因此在上面的代码中不会执行这条提示信息。
- 包的概念
除了单独的模块文件外,Python还支持将多个相关的模块组织成为一个包。包是一种带有层次结构的模块命名空间,其中可以包含多个子模块、子包等,以便更好地组织和管理相关代码。
一个Python包通常是一个包含__init__.py文件的目录,其中__init__.py文件用于指定该目录为一个包,并可以进行一些初始化操作。例如,我们可以在__init__.py文件中导入该包的子模块或子包,以便在使用该包时可以直接从包级别访问其子模块或子包。
以下是一个包的示例结构:
my_package/__init__.pymodule1.pymodule2.pysubpackage/__init__.pymodule3.py
在这个示例中,my_package是一个包目录,其中包含了__init__.py文件和两个模块文件module1.py和module2.py,以及一个名为subpackage的子包目录。subpackage目录同样包含了一个__init__.py文件,以及一个名为module3.py的模块文件。
我们可以使用import语句导入一个包或其中的模块或子包。例如,以下代码导入了my_package包及其子模块,以及subpackage子包中的module3模块:
import my_package.module1
from my_package import module2
from my_package.subpackage import module3
在导入一个包或模块时,Python会执行该模块中的所有代码,并将其中定义的对象引入到当前作用域中。
四、总结
本文介绍了Python模块的概念、使用方法以及一些高级特性。Python模块是一个包含Python代码的文件,可以包含变量、函数、类等定义,并提供了代码组织、复用和可维护性的好处。同时,Python还支持自定义模块和包,以便更好地组织和管理相关代码。在实际开发中,我们应该根据需要灵活使用Python模块的各种功能,以提高程序的可读性、可扩展性和可维护性。
导入模块
在Python编程中,模块是指一个包含Python代码的文件或目录,可以包含变量、函数、类等定义。导入模块是将某个模块中的定义导入到当前程序中以供使用的过程。Python提供了多种导入模块的方式,本文将详细介绍这些方式以及它们的优缺点。
一、import语句
在Python中,最常用的导入模块的方式是使用import语句。import语句用于从一个模块中导入所有的对象或者选择性地导入部分对象,其基本语法如下:
import module_name [as alias]
from module_name import object_name [as alias]
其中,module_name代表要导入的模块名,object_name则代表要导入的对象名。如果需要给导入的模块或对象起别名,可以使用as关键字指定别名。
- 导入整个模块
当我们需要导入一个完整的模块时,可以使用import语句,并指定要导入的模块名称,例如:
import math
这样就会将math模块中的所有定义导入到当前程序中,并可以直接使用这些定义。
- 选择性地导入模块中的对象
有时候我们只需要使用模块中的部分定义,而不是全部导入,此时可以使用from关键字,并指定要导入的对象名称,例如:
from math import pi, sqrt
这样就只会导入math模块中的pi和sqrt两个对象,并可以直接使用它们。
- 给导入的模块或对象起别名
在某些情况下,我们需要给导入的模块或对象起一个更容易识别的名称,此时可以使用as关键字指定别名。例如:
import math as m
from math import pi as p
这样就将math模块和其中的pi对象分别起别名为m和p,并可以使用这些别名来访问这些对象。
二、sys.path路径
在Python程序中,当我们使用import语句导入一个模块时,Python会到sys.path变量所列出的路径中去查找该模块。sys.path是一个Python列表,包含了一系列用于搜索模块的目录。
我们可以通过以下代码获取当前Python解释器使用的sys.path值:
import sysprint(sys.path)
输出结果如下:
['', '/usr/local/lib/python36.zip', '/usr/local/lib/python3.6','/usr/local/lib/python3.6/lib-dynload', '/usr/local/lib/python3.6/site-packages']
这里的空字符串’'表示当前工作目录,其余的路径则包括了Python标准库、第三方库以及用户自定义模块所在的路径。
如果我们需要在程序中添加新的模块搜索路径,可以通过修改sys.path列表来实现。例如:
import syssys.path.append('/path/to/my/module')
这样就会将’/path/to/my/module’路径添加到sys.path变量中,使得Python可以在该路径下查找模块。
需要注意的是,修改sys.path变量可能会对程序产生不可预料的影响,因此建议尽可能使用相对路径来引用自定义模块,避免修改sys.path变量。
三、包的导入
除了单独的模块文件外,Python还支持将多个相关的模块组织成为一个包。包是一种带有层次结构的模块命名空间,其中可以包含多个子模块、子包等,以便更好地组织和管理相关代码。
在导入一个包时,Python会先查找该包所在的目录,并在其中查找__init__.py文件。如果找到了这个文件,那么Python就会将该目录视为一个包,并将其中定义的变量、函数、类等对象导入到当前作用域中。如果在__init__.py文件中又导入了其他模块或子包,则也会递归地执行这些模块或子包的__init__.py文件。
例如,假设我们有如下目录结构:
my_package/__init__.pymodule1.pymodule2.pysubpackage/__init__.pymodule3.py
若要导入my_package包及其子模块和子包中的所有对象,可以使用以下语句:
import my_package
这样就会将my_package包中的所有定义导入到当前作用域中,并可以直接使用这些定义。
若只需要导入my_package包中的module1和module2两个模块,可以使用以下语句:
from my_package import module1, module2
这样就只会导入module1和module2两个模块中的所有定义,并可以直接使用这些定义。
若需要导入my_package包中的subpackage子包及其中的module3模块,可以使用以下语句:
from my_package.subpackage import module3
这样就只会导入module3模块中的所有定义,并可以直接使用这些定义。
四、动态导入
除了静态导入外,Python还支持在程序运行时动态地导入模块。动态导入可以使得程序更加灵活,也可以根据运行时条件来决定是否导入某个模块,从而提高程序的性能和扩展性。
Python中可以使用__import__()函数来动态地导入模块,其基本语法如下:
__import__(name[, globals[, locals[, fromlist[, level]]]])
其中,name代表要导入的模块名称,可以是字符串或元组类型。fromlist则用于指定要导入的对象列表,如果不指定则默认导入整个模块。level参数用于指定相对导入的深度,常用值为0、1、2,表示绝对导入、相对导入和绝对导入加上相对导入两种方式。
例如,以下代码动态导入了一个名为“module_name”的模块,并将其中定义的变量“var”赋值给变量“my_var”:
module_name = 'my_module'
module = __import__(module_name)
my_var = module.var
在实际开发中,动态导入通常用于实现插件化架构或延迟加载等功能。需要注意的是,动态导入可能会带来一些安全风险,因此应该对导入的模块进行适当的验证和限制。
五、总结
本文介绍了Python中导入模块的多种方式,包括静态导入、sys.path路径、包的导入以及动态导入。在实际开发中,我们应根据实际情况选择合适的导入方式,以提高程序的可读性、可扩展性和可维护性。同时,我们也需要遵循一些最佳实践,如避免修改sys.path变量、使用相对路径来引用自定义模块等,以保证程序的安全性和可靠性。
文件 IO
在Python编程中,文件IO是一种常见的操作,用于读写文件或处理文件数据。Python提供了多种文件IO相关的函数和方法,本文将详细介绍这些函数和方法,并提供一些实际应用场景的示例。
一、文件打开和关闭
在进行文件IO操作前,我们需要使用open()函数打开文件,并指定文件名和打开模式。open()函数的基本语法如下:
file = open(file_path[, mode[, buffering]])
其中,file_path为要打开的文件路径(相对路径或绝对路径),mode为打开模式,可以是’r’表示只读模式,'w’表示可写模式,'a’表示追加模式,'x’表示排他模式,'b’表示二进制模式,‘t’表示文本模式,’+'表示读写模式等。buffering则用于指定缓冲区大小,常用值为0(无缓冲)、1(行缓冲)或大于1的整数(缓冲大小)。
例如,以下代码以只读模式打开一个名为“test.txt”的文件:
file = open('test.txt', 'r')
在使用完一个文件后,我们需要使用close()方法关闭该文件。close()方法会释放文件的所有资源,并确保文件内容已被保存到磁盘上。例如:
file.close()
需要注意的是,如果在使用完一个文件后忘记关闭它,可能会导致资源泄漏或文件损坏,因此建议尽可能使用with语句来自动关闭文件。
二、文件读取和写入
在打开一个文件后,我们可以使用read()方法来读取文件中的内容。read()方法会从当前位置开始读取指定长度(或者全部)的数据,并将其以字符串或字节串的形式返回。例如:
file = open('test.txt', 'r')
content = file.read()
print(content)
file.close()
这里的read()方法将读取整个文件的内容,然后将其以字符串的形式返回,并赋值给变量content。
类似地,我们也可以使用write()方法向文件中写入数据。write()方法会将指定的字符串或字节串写入到文件中,并返回写入的字节数。例如:
file = open('test.txt', 'w')
file.write('Hello, world!')
file.close()
这里的write()方法将把字符串“Hello, world!”写入到名为“test.txt”的文件中。
需要注意的是,当我们使用write()方法写入文件时,如果文件已经存在,则该方法会清空并覆盖原有的文件内容。如果希望保留原有内容并在其后面追加新的内容,可以使用追加模式’a’打开文件,并使用write()方法写入新的内容。例如:
file = open('test.txt', 'a')
file.write('This is a new line.')
file.close()
这里的write()方法将在原有内容的末尾添加字符串“This is a new line.”。
三、文件指针和读写位置
在对一个文件进行读写时,Python会使用一个文件指针来记录当前读写的位置。文件指针会随着读写操作的进行而不断移动,以指示下一次读写的位置。
在打开一个文件后,文件指针通常位于文件的开始位置(偏移量为0)。我们可以使用seek()方法来移动文件指针到指定位置,其基本语法如下:
file.seek(offset[, whence])
其中,offset表示要移动的偏移量,whence则用于指定移动的方式,0表示从文件开头计算偏移量,1表示从当前位置计算偏移量,2表示从文件末尾计算偏移量。默认值为0。
例如,以下代码将从文件的第10个字节处开始读取3个字节的内容:
`` file = open(‘test.txt’, ‘r’)
file.seek(10)
content = file.read(3)
print(content)
file.close()
这里的seek()方法将文件指针移动到偏移量为10的位置处,然后读取3个字节的内容(即从第10个字节开始读取)。
在写入文件时,文件指针通常会随着写入操作而不断向后移动。我们可以使用tell()方法来获取当前文件指针的位置,其基本语法如下:
position = file.tell()
例如,以下代码将以追加模式打开文件,并使用tell()方法获取当前文件指针的位置:
file = open('test.txt', 'a')
position = file.tell()
print(position)
file.write('This is a new line.')
file.close()
这里的tell()方法将返回当前文件指针的位置(即文件的末尾),并将字符串“This is a new line.”添加到文件的末尾。
四、文件迭代器
除了read()方法外,我们还可以使用文件对象作为迭代器来逐行读取文件中的数据。在使用文件迭代器时,Python会自动按行读取文件内容,并将每一行以字符串的形式返回。例如:
file = open('test.txt', 'r')
for line in file:print(line.strip())
file.close()
这里的文件迭代器会逐行读取文件“test.txt”的内容,并使用strip()方法去掉每一行的空白符,然后将每一行打印出来。
需要注意的是,使用文件迭代器时可能会导致内存占用过高或程序运行缓慢,特别是当文件较大时。此时我们建议使用readline()方法或readlines()方法来逐行读取文件,以提高程序的性能和可靠性。
五、with语句
在对文件进行操作时,为了避免忘记关闭文件或引发异常等问题,我们建议使用with语句来自动管理文件对象的生命周期。with语句会自动调用close()方法,并确保文件对象被安全地关闭,从而避免资源泄漏等问题。例如:
with open('test.txt', 'r') as file:content = file.read()print(content)
这里的with语句将打开文件“test.txt”,并将其作为文件对象file的值传给语句块中的代码。在with语句块执行完毕后,Python会自动调用file.close()方法,从而关闭文件。
需要注意的是,使用with语句时,不需要显式地调用close()方法,否则可能会导致文件已经关闭但仍然尝试调用close()方法而引发异常。
六、二进制文件处理
除了文本文件外,Python还可以处理二进制文件(如图片、音频、视频等)。对于二进制文件,我们通常会使用二进制模式’b’来打开文件,并使用bytes类型来读写文件数据。例如:
with open('image.jpg', 'rb') as file:data = file.read()print(len(data))
这里的二进制文件“image.jpg”将以二进制模式打开,并使用bytes类型来读取文件数据。需要注意的是,二进制文件的读写通常需要一定的专业知识和技能,否则可能会引发数据损坏或读写错误等问题。
七、总结
本文介绍了Python中文件IO的基本操作,包括文件打开和关闭、文件读取和写入、文件指针和读写位置、文件迭代器以及with语句等。在实际应用中,我们应根据实际需求选择合适的文件IO方式,同时遵循一些最佳实践,如及时关闭文件对象、使用迭代器来逐行读取大文件数据等,以提高程序的性
序列化和反序列化
在Python编程中,序列化和反序列化是一种常见的操作,用于将Python对象转换为字节流或字符串数据,并在需要时重新将其还原为原始对象。Python提供了多种序列化和反序列化相关的库和函数,本文将详细介绍这些库和函数的使用方法,并提供一些实际应用场景的示例。
一、序列化
序列化是指将Python对象转换为可保存或传输的字节流或字符串数据的过程。在Python语言中,我们通常使用pickle模块或json模块来进行序列化操作。
- pickle模块
pickle模块可以将Python对象转换为二进制数据,并存储到文件或内存中。它支持几乎所有Python对象,包括自定义类和函数等。pickle模块的基本用法如下:
import pickle# 将Python对象序列化并保存到文件中
with open('data.pkl', 'wb') as file:data = {'name': 'Alice', 'age': 20}pickle.dump(data, file)# 从文件中读取二进制数据并反序列化为Python对象
with open('data.pkl', 'rb') as file:data = pickle.load(file)print(data)
这里的dump()方法将字典类型的data对象序列化为二进制数据,并写入到名为“data.pkl”的文件中。而load()方法则从文件中读取二进制数据并反序列化为Python对象,即字典类型的data对象,并将其打印出来。
需要注意的是,pickle模块序列化出的数据只能在Python环境中使用,并且存在一定的安全性风险,因此不建议直接从未知源加载pickle数据。
- json模块
json模块可以将Python对象转换为JSON格式的字符串,并进行存储或传输。它支持常用的Python数据类型,如列表、字典、数字、布尔值、字符串等。json模块的基本用法如下:
import json# 将Python对象序列化为JSON格式字符串
data = {'name': 'Alice', 'age': 20}
json_str = json.dumps(data)
print(json_str)# 将JSON格式字符串反序列化为Python对象
data = json.loads(json_str)
print(data)
这里的dumps()方法将字典类型的data对象序列化为JSON格式字符串,并赋值给变量json_str。而loads()方法则将JSON格式字符串反序列化为Python对象,即字典类型的data对象,并将其打印出来。
需要注意的是,json模块序列化出的数据是跨平台通用的,并且不会包含Python特有的功能和信息,因此更加安全可靠。
二、反序列化
反序列化是指将二进制数据或JSON格式字符串转换为Python对象的过程。在Python语言中,我们通常使用pickle模块或json模块来进行反序列化操作。
- pickle模块
pickle模块可以将二进制数据反序列化为Python对象。它的基本用法已在上文中介绍,这里不再赘述。
需要注意的是,在反序列化过程中,我们需要确保读取的数据来源可靠,并且未被篡改或损坏,否则可能会导致程序崩溃或安全性问题。
- json模块
json模块可以将JSON格式字符串反序列化为Python对象。它的基本用法已在上文中介绍,这里不再赘述。
需要注意的是,在反序列化过程中,我们需要确保读取的数据格式正确并符合标准,否则可能会导致解析错误或数据不完整等问题。
三、实际应用场景
序列化和反序列化在Python编程中有广泛应用,下面我们将介绍一些实际应用场景及其相关的序列化和反序列化方法。
- 缓存数据
在Web应用程序中,缓存是一种常见的性能优化手段,可以加速数据访问和响应速度。Python提供了多种缓存库和框架,如Memcached、Redis等,并支持使用pickle模块或json模块来进行数据序列化和反序列化操作。
以下示例演示了如何使用redis-py库和pickle模块在Redis数据库中存储和读取Python对象:
import redis
import pickle# 连接Redis服务器
client = redis.StrictRedis(host='localhost', port=6379, db=0)# 将Python对象序列化为二进制数据并保存到Redis中
data = {'name': 'Alice', 'age': 20}
key = 'user_data'
value = pickle.dumps(data)
client.set(key, value)# 从Redis中读取二进制数据并反序列化为Python对象
value = client.get(key)
data = pickle.loads(value)
print(data)
这里的StrictRedis类是redis-py库中的一个核心类,用于连接和操作Redis服务器。在上述代码中,我们先将Python对象data序列化为二进制数据,并使用set()方法将其保存到Redis数据库中。然后,我们使用get()方法获取数据,并使用loads()方法将二进制数据反序列化为Python对象data。
- RPC调用
RPC(Remote Procedure Call)是一种常见的分布式系统通信方式,可以使得不同计算机之间的程序可以像调用本地函数一样进行交互。在Python编程中,我们可以使用多种RPC框架和协议,如XML-RPC、JSON-RPC、gRPC等,并支持使用pickle模块或json模块来进行数据序列化和反序列化操作。
以下示例演示了如何使用xmlrpc库和pickle模块进行RPC调用:
import xmlrpc.client
import pickle# 连接XML-RPC服务器
server = xmlrpc.client.ServerProxy('http://localhost:8000')# 将Python对象序列化为二进制数据并传输到XML-RPC服务器
data = {'name': 'Alice', 'age': 20}
value = pickle.dumps(data)
result = server.echo(value)# 从XML-RPC服务器返回的二进制数据反序列化为Python对象
data = pickle.loads(result)
print(data)
这里的ServerProxy类是xmlrpc.client库中的一个核心类,用于连接和操作XML-RPC服务器。在上述代码中,我们先将Python对象data序列化为二进制数据,并使用echo()方法将其传输到XML-RPC服务器上。然后,我们从服务器返回的二进制数据result中,使用loads()方法将其反序列化为Python对象data。
需要注意的是,在RPC调用中,我们需要注意数据格式和类型的一致性,否则可能会导致通信失败或数据解析错误等问题。
- 数据存储
在数据存储和处理方面,Python提供了多种数据库和文件系统接口,如SQLite、MySQL、PostgreSQL、MongoDB等,并支持使用pickle模块或json模块来进行数据序列化和反序列化操作。
以下示例演示了如何使用sqlite3库和pickle模块在SQLite数据库中存储和读取Python对象:
import sqlite3
import pickle# 连接SQLite数据库
conn = sqlite3.connect('example.db')# 创建数据表并插入一条记录
cursor = conn.cursor()
cursor.execute('''CREATE TABLE users (id INTEGER PRIMARY KEY, data BLOB)''')
data = {'name': 'Alice', 'age': 20}
value = pickle.dumps(data)
cursor.execute("INSERT INTO users (data) VALUES (?)", (value,))
conn.commit()# 从数据表中读取二进制数据并反序列化为Python对象
cursor.execute("SELECT data FROM users WHERE id = 1")
result = cursor.fetchone()[0]
data = pickle.loads(result)
print(data)# 关闭数据库连接
conn在上述代码中,我们先连接SQLite数据库,并创建一个名为“users”的数据表。然后,我们将Python对象data序列化为二进制数据,并使用execute()方法将其插入到数据表中。接下来,我们使用execute()方法和fetchone()方法从数据表中获取数据,并使用loads()方法将二进制数据反序列化为Python对象data。需要注意的是,在数据存储和处理方面,我们需要选择合适的库和适当的数据格式,并严格遵守数据类型和格式规范,以确保数据的一致性和安全性。4. 状态保持在Web应用程序中,状态保持是一种常见的技术手段,可以使得用户在不同页面和操作之间保持一定的状态和信息,如登录状态、购物车数据等。Python提供了多种状态保持机制和库,如session、cookie、Redis等,并支持使用pickle模块或json模块来进行数据序列化和反序列化操作。以下示例演示了如何使用django框架和json模块进行用户登录状态保持:import json
from django.contrib.sessions.backends.db import SessionStore
创建会话对象
session = SessionStore()
将Python对象序列化为JSON格式字符串并保存到会话中
data = {‘username’: ‘Alice’, ‘is_login’: True}
value = json.dumps(data)
session[‘user_info’] = value
session.save()
从会话中读取JSON格式字符串并反序列化为Python对象
value = session.get(‘user_info’)
data = json.loads(value)
print(data)
这里的SessionStore类是django.contrib.sessions.backends.db库中的一个核心类,用于创建和操作用户会话对象。在上述代码中,我们先创建了一个名为“session”的会话对象,并将Python对象data序列化为JSON格式字符串并保存到其属性中。然后,我们从会话对象中获取数据,并使用loads()方法将其反序列化为Python对象data。需要注意的是,在状态保持方面,我们需要选择合适的机制和库,并注意数据的安全性和有效期限等问题,以确保用户信息和状态的正确性和可靠性。总结本文介绍了Python中序列化和反序列化的基本概念、方法和应用场景,并提供了一些相关的示例代码。希望本文能够对读者理解和使用Python中的序列化和反序列化功能有所帮助。在实际编程中,读者可以根据具体需求和情况选择合适的库和方法,并注意数据的一致性、安全性和可靠性等方面的问题。相关文章:

Python入门到高级【第四章】
预计更新第一章. Python 简介 Python 简介和历史Python 特点和优势安装 Python 第二章. 变量和数据类型 变量和标识符基本数据类型:数字、字符串、布尔值等字符串操作列表、元组和字典 第三章. 控制语句和函数 分支结构:if/else 语句循环结构&#…...

【ChatGPT】ChatGPT 能否取代程序员?
Yan-英杰的主页 悟已往之不谏 知来者之可追 C程序员,2024届电子信息研究生 目录 前言: ChatGPT 的优势 自然语言的生成 文本自动生成 建立了更人性化的人机交互 ChatGPT 的局限性 算法的解释能力较差 程序的可实现性较差 缺乏优化和质量控制 程序员相较于 …...

英飞凌Tricore问题排查01_Det/Reset/Trap排查宝典
目录 1.概述2. 排查方法总览(流程图)3. 进Det排查方法4. 进Reset/Trap排查4.1 通过ErrorHook/ProtectionHook排查4.2. 通过BTV寄存器排查Trap方法4.3 借助英飞凌寄存器排查4.3.1 借助Reset状态寄存器4.3.2 SMU触发的复位4.3.3 CPU触发的复位1.概述 大家在软件开发过程中,可…...

第六章 共享模型之 无锁
JUC并发编程系列文章 http://t.csdn.cn/UgzQi 文章目录JUC并发编程系列文章前言一、问题的引出如何保证取款方法的线程安全解决方案一、使用synchronized锁住临界区代码解决方案二、无锁(AtomicInteger 原子整数类)二、CAS 与 volatileAtomicInteger . compareAndSet( ) 方法的…...

2023Q2押题,华为OD机试用Python实现 -【机智的外卖员】
最近更新的博客 华为 od 2023 | 什么是华为 od,od 薪资待遇,od 机试题清单华为 OD 机试真题大全,用 Python 解华为机试题 | 机试宝典【华为 OD 机试】全流程解析+经验分享,题型分享,防作弊指南华为 od 机试,独家整理 已参加机试人员的实战技巧本篇题解:机智的外卖员 题目…...
)
【华为OD机试真题】密室逃生游戏(javapython)
密室逃生游戏 题目 小强增在参加《密室逃生》游戏,当前关卡要求找到符合给定 密码 K(升序的不重复小写字母组 成) 的箱子, 并给出箱子编号,箱子编号为 1~N 。 每个箱子中都有一个 字符串 s ,字符串由大写字母、小写字母、数字、标点符号、空格组成, 需要在这些字符串中…...
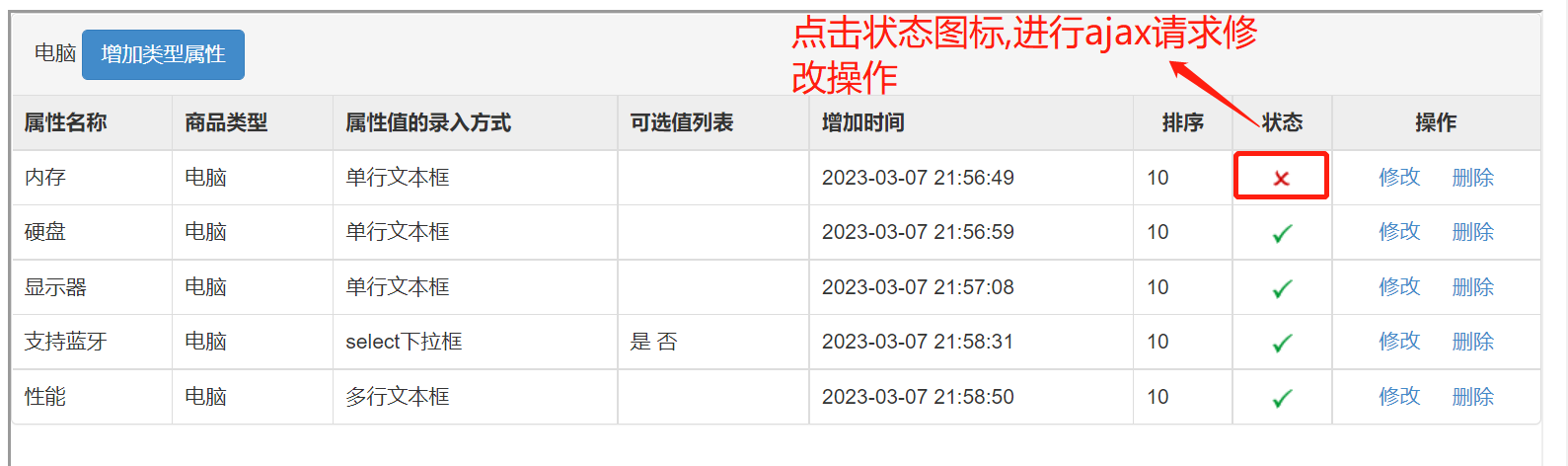
[golang gin框架] 17.Gin 商城项目-商品分类模块, 商品类型模块,商品类型属性模块功能操作
一.商品分类的增、删、改、查,以及商品分类的自关联1.界面展示以及操作说明列表商品分类列表展示说明:(1).增加商品分类按钮(2).商品分类,以及子分类相关数据列表展示(3).排序,状态,修改,删除操作处理 新增编辑删除修改状态,排序2.创建商品分类模型在controllers/admin下创建Go…...

Redis安装-使用包管理安装Redis
这种在Linux上使用apt-get包管理器安装Redis的方式称为“包管理安装”。这种安装方式使用操作系统的官方软件库来获取和安装软件包,可以自动处理软件包的依赖关系,并确保软件包与系统其他部分兼容。这是一种安全、可靠且方便的安装方式,适用于…...
HTML属性的概念和使用
通过前面的学习,我们已经对 HTML标签 有了简单的认识,知道可以在标签中可以添加一些属性,这些属性包含了标签的额外信息,例如: href 属性可以为 <a> 标签提供链接地址;src 属性可以为 <img> 标…...
ChatGPT基础知识系列之一文说透ChatGPT
ChatGPT基础知识系列之一文说透ChatGPT OpenAI近期发布聊天机器人模型ChatGPT,迅速出圈全网。它以对话方式进行交互。以更贴近人的对话方式与使用者互动,可以回答问题、承认错误、挑战不正确的前提、拒绝不适当的请求。高质量的回答、上瘾式的交互体验,圈内外都纷纷惊呼。 …...
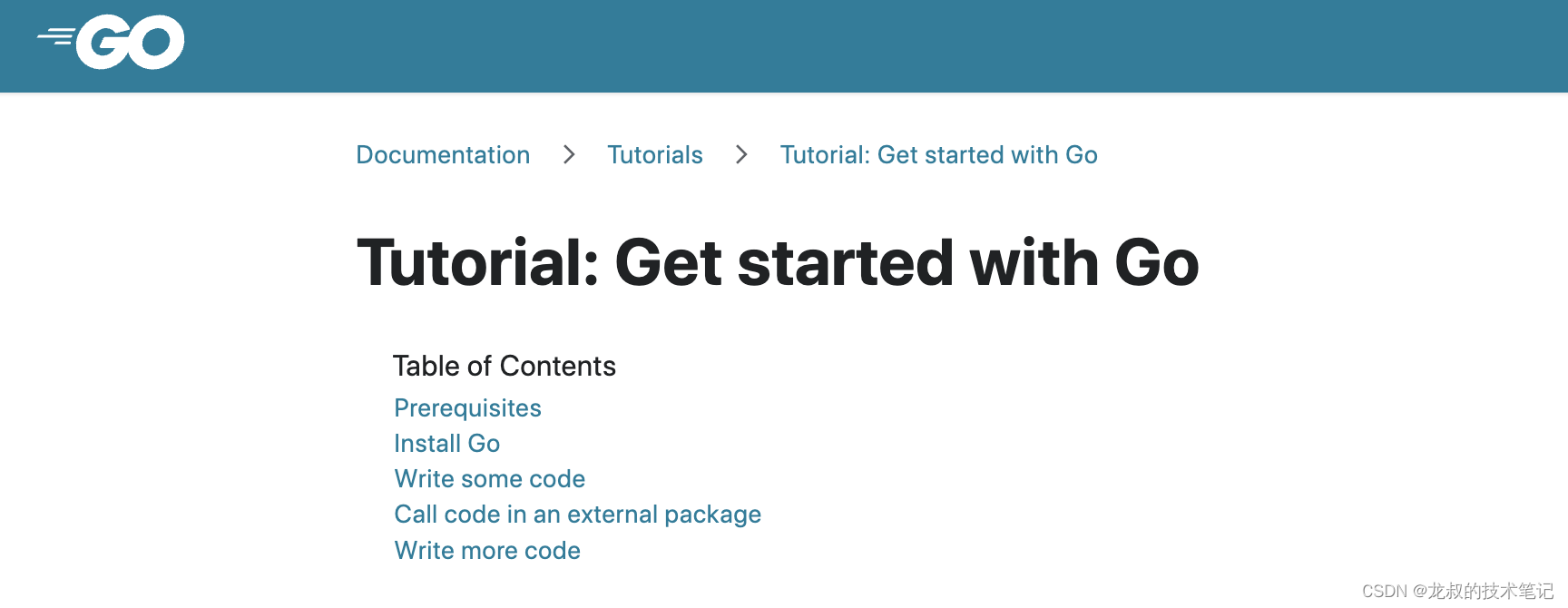
‘go install‘ requires a version when current directory is not in a module
背景 安装好环境之后,跑个helloworld看看 目录结构 workspacepathsrchellohelloworld.go代码: package mainimport "fmt"func main() { fmt.Println("Hello World") }1.使用 go run 命令 - 在命令提示符旁,输入 go …...

蓝桥杯嵌入式第十三届(第二套客观题)
文章目录 前言一、题目1二、题目2三、题目3四、题目4五、题目5六、题目6七、题目7八、题目8九、题目9十、题目10总结前言 本篇文章继续讲解客观题。 一、题目1 这个其实属于送分题,了解嵌入式或者以后想要入行嵌入式的同学应该都对嵌入式特点有所了解。 A. 采用专用微控制…...

FFmpeg进阶:各种输入输出设备
文章目录查看设备列表输入设备介绍输出设备介绍查看设备列表 我们可以通过ffmpeg自带的工具查看系统支持的设备列表信息, 对应的指令如下所示: ffmpeg -devices输入设备介绍 通过配置ffmpeg的输入设备,我们可以访问系统中的某个多媒体设备的数据。下面详细介绍一下各个系统中…...

使用Shell笔记总结
一、变量 1、定义变量不加$符号,使用变量要用$;等号两边不能直接接空格符;通常大写字符为系统默认变量,自行设定变量可以使用小写字符。 2、双引号内的特殊字符如 $ 等,可以保有其符号代表的特性,即可以有…...

反常积分的审敛法
目录 无穷先的反常积分的审敛法 定理1:比较判别法 例题: 比较判别法的极限形式: 例题: 定理3:绝对收敛准则 例题: 无界函数的反常积分收敛法 例题: 无穷先的反常积分的审敛法 定理1&#x…...
(附python示例代码))
python实战应用讲解-【numpy专题篇】numpy常见函数使用示例(十三)(附python示例代码)
目录 Python numpy.ma.mask_or()函数 Python numpy.ma.notmasked_contiguous函数 Python numpy.ma.notmasked_edges()函数 Python numpy.ma.where()函数 Python Numpy MaskedArray.all()函数 Python Numpy MaskedArray.anom()函数 Python Numpy MaskedArray.any()函数 …...
—— 桥接模式)
Java设计模式(十九)—— 桥接模式
桥接模式定义如下:将抽象部分与它的实现部分分离,使它们都可以独立地变化。 适合桥接模式的情景如下: 不希望抽象和某些重要的实现代码是绑定关系,可运行时动态决定抽象和实现者都可以继承的方式独立的扩充,程序在运行…...

多线程并发安全问题
文章目录并发安全问题线程安全性死锁定义实现一个死锁查看死锁解决死锁其他线程安全问题单例模式并发安全问题 线程安全性 线程安全是指我们所写的代码在并发情况下使用时,总是能表现出正确的行为;反之,未实现线程安全的代码,表…...

P1005 [NOIP2007 提高组] 矩阵取数游戏
题目描述 帅帅经常跟同学玩一个矩阵取数游戏:对于一个给定的 ��nm 的矩阵,矩阵中的每个元素 ��,�ai,j 均为非负整数。游戏规则如下: 每次取数时须从每行各取走一个元素ÿ…...
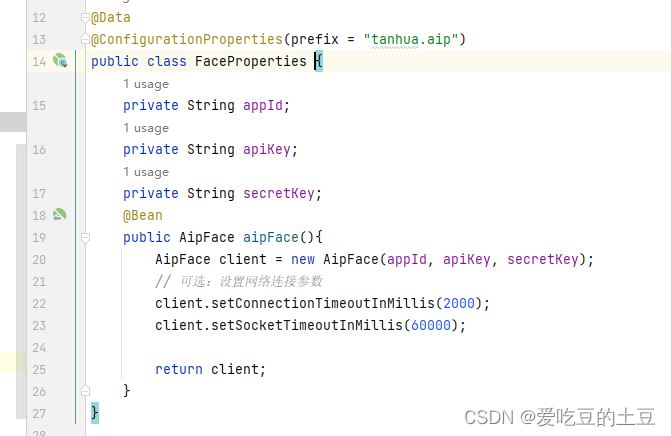
百度云【人脸识别】
目录 1:百度云【人脸识别云服务】 2:Java-SDK文档 3:项目中测试 1:百度云【人脸识别云服务】 人脸识别云服务 包含实名认证、人脸对比、人脸搜索、活体检测等能力。灵活应用于金融、泛安防等行业场景,满足身份核验…...

PhysX帧分配器:一帧一擦的高效艺术
写满就擦,擦完再写,永不停歇引子:数学老师的白板 还记得高中数学课吗? 老师走进教室,面前是一块干干净净的白板。他开始讲解——写公式、画图形、列步骤,白板渐渐被填满。下课铃响,老师拿起板擦…...

收藏!小白也能看懂的大模型如何改写工业效率?
收藏!小白也能看懂的大模型如何改写工业效率? 本文介绍了中控技术的TPT大模型在工业生产中的应用,它通过实时监控、自动计算最优参数和风险预警,帮助企业提升效率、降低成本。与互联网领域的AI应用不同,工业AI的价值更…...

解锁AMD锐龙隐藏性能:SMUDebugTool深度调校实战指南
解锁AMD锐龙隐藏性能:SMUDebugTool深度调校实战指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitc…...

PMOD接口概述
简介 PMOD接口外设模块特点:低频,少量IO引脚。 两种物理规格:6针接口(4IO, 1VCC, 1GND)、12针接口(8IO, 2VCC, 2GND)。 支持的接口协议:SPI、I2C、UART、I2C、H桥、GPIO。 外设模块与主机连接方式:模块直连主机、通过6Pin或12Pin线缆或者12Pin转双6Pin分叉线缆。 外设…...
Pixel Fashion Atelier惊艳案例:‘赛博神社’主题皮装在明亮城镇UI下的生成
Pixel Fashion Atelier惊艳案例:‘赛博神社’主题皮装在明亮城镇UI下的生成 1. 项目概览 Pixel Fashion Atelier(像素时装锻造坊)是一款基于Stable Diffusion与Anything-v5的图像生成工作站。与传统AI工具不同,它采用了复古日系…...

基于粒子群优化算法的永磁同步电机PMSM参数辨识:‘粒子群迭代‘至‘再次循环或结束
基于粒子群优化算法的永磁同步电机PMSM参数辨识 关键词:永磁同步电机 粒子群优化算法 参数辨识 ① 粒子群迭代 ②更新速度并对速度进行边界处理 ③更新位置并对位置进行边界处理 ④进行自适应变异 ⑤进行约束条件判断并计算新种群各个个体位置的适应度 ⑥新适应度与…...
)
数据清洗避坑指南:缺失值和异常值处理的5个常见错误(附真实案例)
数据清洗避坑指南:缺失值和异常值处理的5个常见错误(附真实案例) 在电商平台的用户行为分析中,我们曾遇到一个诡异现象:某促销活动页面的转化率突然飙升到98%。进一步排查发现,是爬虫程序将未加载完成的页…...

D-Net:动态大内核与特征融合如何革新三维医学影像分割?
1. 为什么医学影像分割需要动态大内核? 医学影像分割就像给CT或MRI照片上的器官、肿瘤画精确边界线。传统方法像用固定倍数的放大镜观察——要么看不清细节(小内核),要么错过整体结构(大内核)。我在处理腹…...

python-flask-djangol框架的婚恋相亲交友网站
目录技术选型与框架对比核心功能模块设计数据库模型示例(Django ORM)安全防护措施部署方案开发路线图项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术选型与框架对比 Flask:轻量级框架&a…...

如何用League-Toolkit提升你的英雄联盟游戏体验
如何用League-Toolkit提升你的英雄联盟游戏体验 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾经在英雄联盟游戏中感到效…...