【C++】STL之stack、queue的使用和模拟实现+优先级队列(附仿函数)+容器适配器详解
之前的一段时间,我们共同学习了STL中一些容器,如string、vector和list等等。本章我们将步入新阶段的学习——容器适配器。本章将详解stack、queue的使用和模拟实现+优先级队列(附仿函数)+容器适配器等。
目录
(一)stack的使用和模拟实现
(1)stack的使用
1、stack的介绍
2、stack的使用
(2)经典OJ题(最小栈、栈的弹出与压入序列、逆波兰表达式)
(3)stack的模拟实现
(二)queue的使用和模拟实现
(1)queue的使用
1、queue的介绍
2、queue的使用
(2)queue的模拟实现
(三)优先级队列(priority_queue)的使用、介绍和模拟实现
(1)优先级队列的介绍
(2)优先级队列的使用
(3)仿函数的介绍
(4)优先级队列的模拟实现
(四)容器适配器
(1)容器适配器的定义
(2)stack、queue的底层架构——deque
(3)deque的介绍
(一)stack的使用和模拟实现
(1)stack的使用
1、stack的介绍
stack文档![]()
stack文档
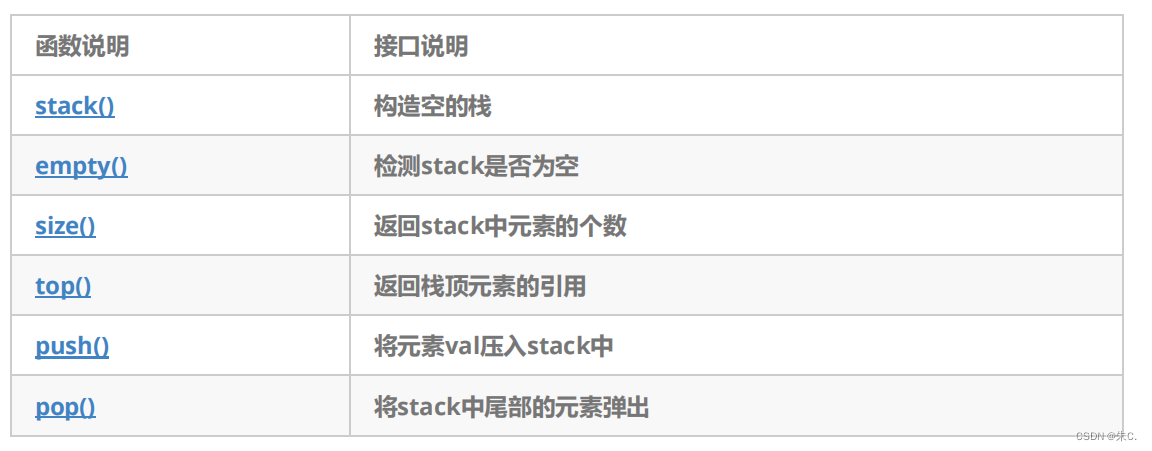
- empty:判空操作
- back:获取尾部元素操作
- push_back:尾部插入元素操作
- pop_back:尾部删除元素操作
2、stack的使用
我们查文档得:

其实这些操作我们在C语言数据结构中已经详细学过了,这里主要是复习一下。
操作大家都很熟悉啦,这里作者就浅浅演示一下如何历遍栈中的元素吧。
历遍栈中元素:
void test_stack(){std::stack<int, vector<int>> s;s.push(1);s.push(2);s.push(3);s.push(4);while (!s.empty()){cout << s.top() << " ";s.pop();} cout << endl;}
输出为:4 3 2 1
(2)经典OJ题(最小栈、栈的弹出与压入序列、逆波兰表达式)
力扣![]() https://leetcode.cn/problems/min-stack/
https://leetcode.cn/problems/min-stack/
这道题我们要着重考虑的是如何获取栈中最小的元素。
思路:
- 设计两个栈,一个普通栈实现正常的插入删除操作,一个最小栈——为空时入一个数,后续栈中元素插入时比栈顶元素小的才可以进去最小栈,因为栈符合先进后出规则,这样操作后,最小栈的栈顶元素就是最小数。
- pop操作是如果普通栈栈顶元素和最小栈相同,则一起弹出,如果不同,普通栈弹出即可。
- top操作是直接获取普通栈栈顶元素即可。
代码:
class MinStack {
public:MinStack() {}void push(int val) {_st.push(val);if(_minst.empty()||val<=_minst.top()){_minst.push(val);}}void pop() {if(_minst.top()==_st.top()){_st.pop();_minst.pop();}else_st.pop();}int top() {
return _st.top();}int getMin() {
return _minst.top();}private:stack<int> _st;stack<int> _minst;
};
===============================================================
栈的压入、弹出序列_牛客题霸_牛客网【牛客题霸】收集各企业高频校招笔面试题目,配有官方题解,在线进行百度阿里腾讯网易等互联网名企笔试面试模拟考试练习,和牛人一起讨论经典试题,全面提升你的技术能力![]() https://www.nowcoder.com/practice/d77d11405cc7470d82554cb392585106?tpId=13&&tqId=11174&rp=1&ru=/activity/oj&qru=/ta/coding-interviews/question-ranking
https://www.nowcoder.com/practice/d77d11405cc7470d82554cb392585106?tpId=13&&tqId=11174&rp=1&ru=/activity/oj&qru=/ta/coding-interviews/question-ranking


这和我们数据结构中的一类选择题很像。
思路为:
题目要我们判断两个序列是否符合入栈出栈的次序,我们就可以用一个栈来模拟。对于入栈序列,只要栈为空,序列肯定要依次入栈。那什么时候出来呢?自然是遇到一个元素等于当前的出栈序列的元素,那我们就放弃入栈,让它先出来。
写法:
我们创建一个栈,按照入栈顺序入,每次入栈时对比栈顶和出栈顺序是否一样,一样则弹出(出栈的序列往后加一),然后进行下一次循环比对。最后判断栈是否为空即可或者是否走到了出栈序列的末尾。
class Solution {
public:bool IsPopOrder(vector<int> pushV,vector<int> popV) {int pushi=0;int popi=0;stack<int> st;while(pushi<pushV.size()){st.push(pushV[pushi++]);while(!st.empty()&&st.top()==popV[popi]){st.pop();popi++;}}return popi==popV.size();}
};===============================================================
力扣![]() https://leetcode.cn/problems/evaluate-reverse-polish-notation/
https://leetcode.cn/problems/evaluate-reverse-polish-notation/


前言:我们平时的运算表达式都是中缀表达式,如:![]()
中缀表达式我们人可以看懂,但机器不能,所以要设计一套机器能读懂的表达式,即逆波兰表达式,也称后缀表达式。
上面的中缀表示式转化成后缀表达式是2 1 + 3 *
转化流程如下:
我们有固定的一套逻辑:
- 遇到操作数,输出/存储
- 遇到操作符,跟栈顶操作符比较 a.栈为空或者比栈顶优先级高 – 入栈 b.比栈顶运算符优先级低或者一样 – 出栈顶操作符 -->然后跳到2、继续比较(依次再执行 a.b.)
- 后一个运算符来确定前一个运算符的优先级
- 最后将栈中操作符全部出栈
流程图:

那么逆波兰表达式怎么求值呢?
逆波兰表达式求值过程也相对固定,用到了我们的栈:
- 操作数,入栈
- 操作符,取连续两个栈顶数据运算,运算结果继续入栈,最后的结果就在栈里面
这道题的思路就是这样,代码如下:
class Solution {
public:int evalRPN(vector<string>& tokens) {stack<int> s1;
for(int i=0;i<tokens.size();i++)
{if(tokens[i]=="+"||tokens[i]=="-"||tokens[i]=="*"||tokens[i]=="/"){
int right=s1.top();
s1.pop();
int left=s1.top();
s1.pop();if(tokens[i]=="+")s1.push(left+right);if(tokens[i]=="-")s1.push(left-right);if(tokens[i]=="*")s1.push(left*right);if(tokens[i]=="/")s1.push(left/right);}else{s1.push(stoi(tokens[i]));}}return s1.top();}};(3)stack的模拟实现
amespace zc
{
template<class T, class Container =vector<T>>
class stack
{
public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}const T& top(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;
};
(二)queue的使用和模拟实现
(1)queue的使用
1、queue的介绍
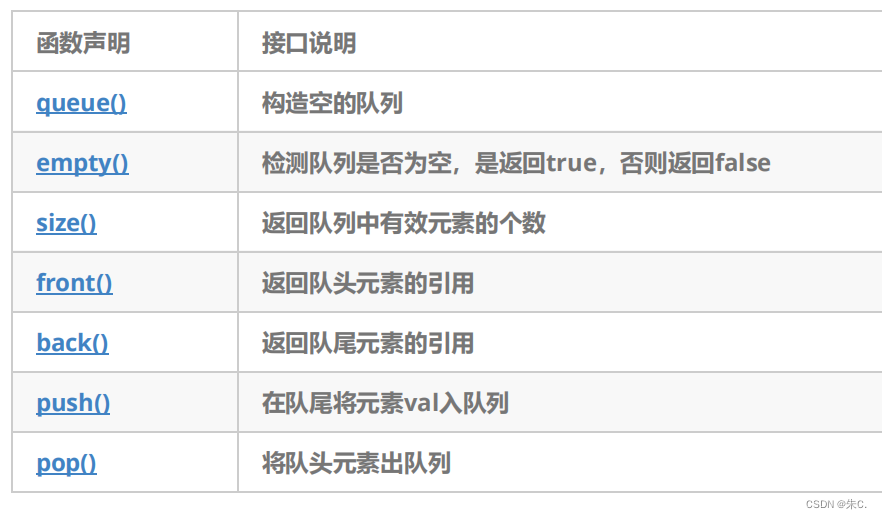
- empty:检测队列是否为空
- size:返回队列中有效元素的个数
- front:返回队头元素的引用
- back:返回队尾元素的引用
- push_back:在队列尾部入队列
- pop_front:在队列头部出队列

2、queue的使用
我们查文档得:

这些接口的使用方法:
使用的代码:
void test_queue()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);//不支持迭代器了,因为栈让随便遍历是不好的//后进先出不好保证,性质就无法维护了while (!q.empty()){cout << q.front() << " ";q.pop();}cout << endl;
}
输出的结果1 2 3 4(符合先进先出)
(2)queue的模拟实现
namespace zc
{template<class T, class Container =list<T>>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}const T& front(){return _con.front();}const T& back(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;};(三)优先级队列(priority_queue)的使用、介绍和模拟实现
(1)优先级队列的介绍
- empty():检测容器是否为空
- size():返回容器中有效元素个数
- front():返回容器中第一个元素的引用
- push_back():在容器尾部插入元素
- pop_back():删除容器尾部元素
(2)优先级队列的使用
我们查文档可知:

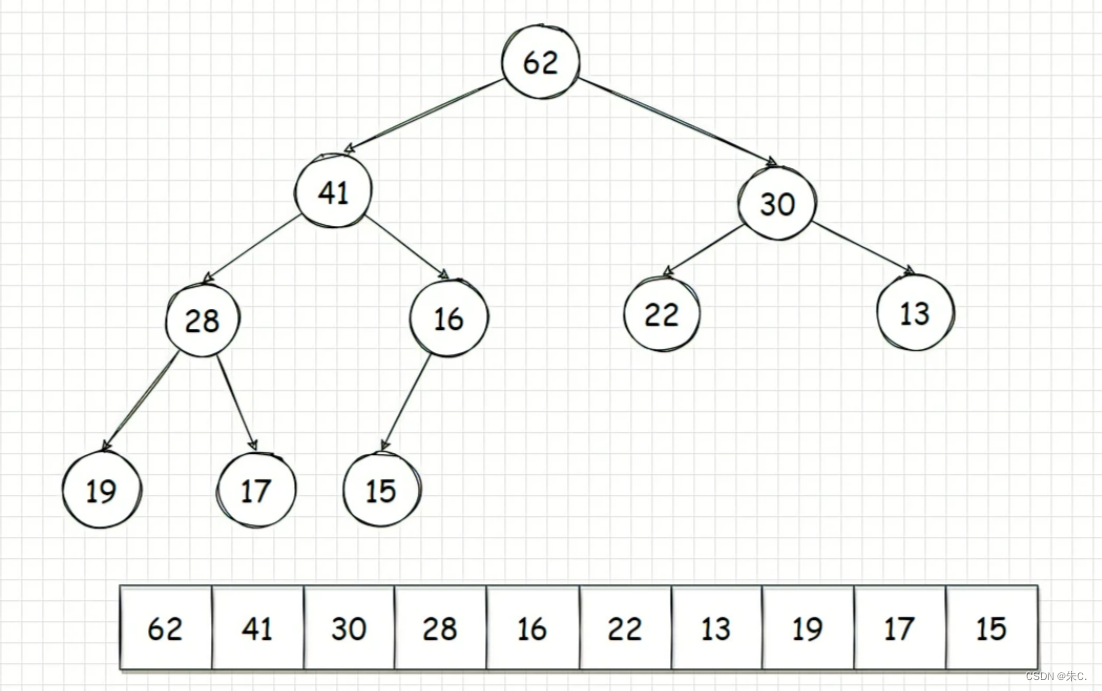
操作使用代码:
//底层是个堆(默认是个大堆) -- 底层用了vector
void test_priority_queue()
{//greater库里写好了的仿函数priority_queue<int, vector<int>, greater<int>> pq;pq.push(2);pq.push(5);pq.push(1);pq.push(6);pq.push(8);while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;}
注意:
默认仿函数传的是less 仿函数,默认是大堆
- 优先级队列默认大的优先级高,传的是less仿函数,底层是一个大堆
- 想控制成小的优先级高,传greater仿函数,底层是一个小堆,这个是反过来的
- 算是设计的一个失误,但是我们没有质疑的能力,大家记住即可。
![]()
说到这里,什么是仿函数呢???这个模板参数的本质是什么呢?我们来进一步的探索:
(3)仿函数的介绍
仿函数 – 更高维度的泛型思想(不仅是数据类型的控制,更是逻辑的控制)
在使用仿函数之前,我们要包一下头文件#include< functional > 这个头文件
什么是仿函数:
看着像函数名,其实是个对象, 可以像调用函数一样去使用,实际上调用的是运算符重载。
我们以greater为例:
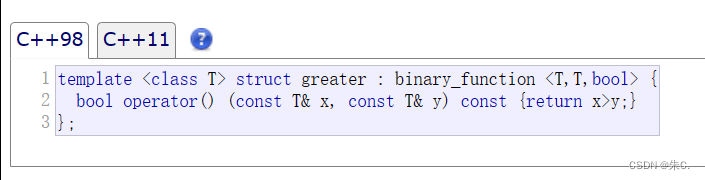
他是一个类,类中重载了(),所以可以像调用函数一样来调用这个类对象。
我们以sort函数为例:

这里就用到了仿函数(其实有点类似函数指针)
- 默认排的是升序 – 默认传的是less
- 我们还可以自己写仿函数,然后传过去
注意:
- 当我们要给一个顺序表排序的时候,当每个元素都是内置类型时,直接用库里的仿函数就可以
- 但是要排的元素是自定义类型的时候,就需要我们自己写一个仿函数了
例:
我们自定义一个日期类,这里要用到仿函数就必须我们呢自己重载>、<了:
class Date{public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}friend ostream& operator<<(ostream& _cout, const Date& d){_cout << d._year << "-" << d._month << "-" << d._day;return _cout;}private:int _year;int _month;int _day;};class PDateLess{public:bool operator()(const Date* p1, const Date* p2){return *p1 < *p2;}};class PDateGreater{public:bool operator()(const Date* p1, const Date* p2){return *p1 > *p2;}};void test_priority_queue2(){// 大堆,需要用户在自定义类型中提供<的重载priority_queue<Date> date;date.push(Date(2023,4,1));date.push(Date(2023, 4, 7));date.push(Date(2023, 4, 2));date.push(Date(2023, 4, 4));while (!date.empty()){cout << date.top()<< " ";date.pop();}cout << endl;priority_queue<Date*,vector<Date*>,PDateGreater> date1;date1.push(new Date(2023, 4, 1));date1.push(new Date(2023, 4, 7));date1.push(new Date(2023, 4, 2));date1.push(new Date(2023, 4, 4));cout << *(date1.top()) << endl;}补充:
- 只是一个普通类,重载了括号,可以像函数一样使用所以叫仿函数
- 是一个空类,只有一个字节
(4)优先级队列的模拟实现
其实主要就是堆的模拟实现的底层构想————>之前博主的博文:堆的模拟实现
主要是插入push的操作和弹出pop的操作的实现方法:
- push:我们把元素插入尾端,然后进行向上调整,也就是把它和它的父亲节点比较交换,直到找到资格核实的位置;
- pop:我们为了顺利把顶元素弹出,可以把顶部元素和末尾元素交换,然后弹出,然后再对交换上去的元素进行向下调整。
namespace zc
{//仿函数/函数对象template<class T>struct less{bool operator()(const T& x,const T& y){return x < y;}};template<class T>struct greater{bool operator()(const T& x, const T& y){return x > y;}};template<class T,class Container=vector<T>,class Compare=less<T>>class priority_queue{public:void adjust_up(int child){int parent = (child - 1) / 2;Compare com;while (child>0){if (com(_con[parent],_con[child])){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}void adjust_down(int parent){int child = parent * 2 + 1;while (child < _con.size()){Compare com;if (child + 1 < _con.size() && com(_con[child], _con[child + 1])){child++;}if (com(_con[parent], _con[child])){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}}void push(const T& x){_con.push_back(x);adjust_up(_con.size()-1);}const T& top(){return _con[0];}size_t size(){return _con.size();}void pop(){swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);}bool empty(){return _con.empty();}private:Container _con;};(四)容器适配器
(1)容器适配器的定义
(2)stack、queue的底层架构——deque



(3)deque的介绍
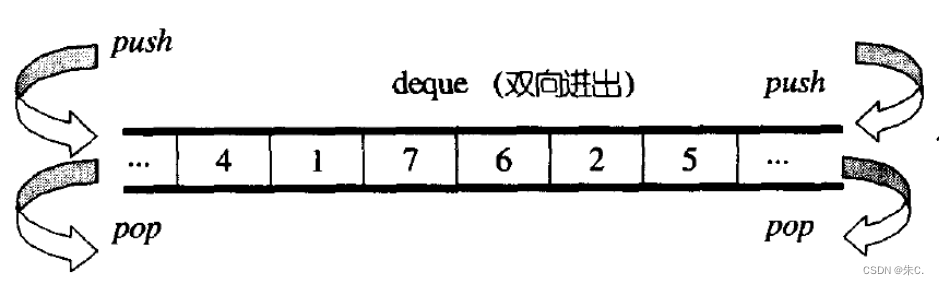
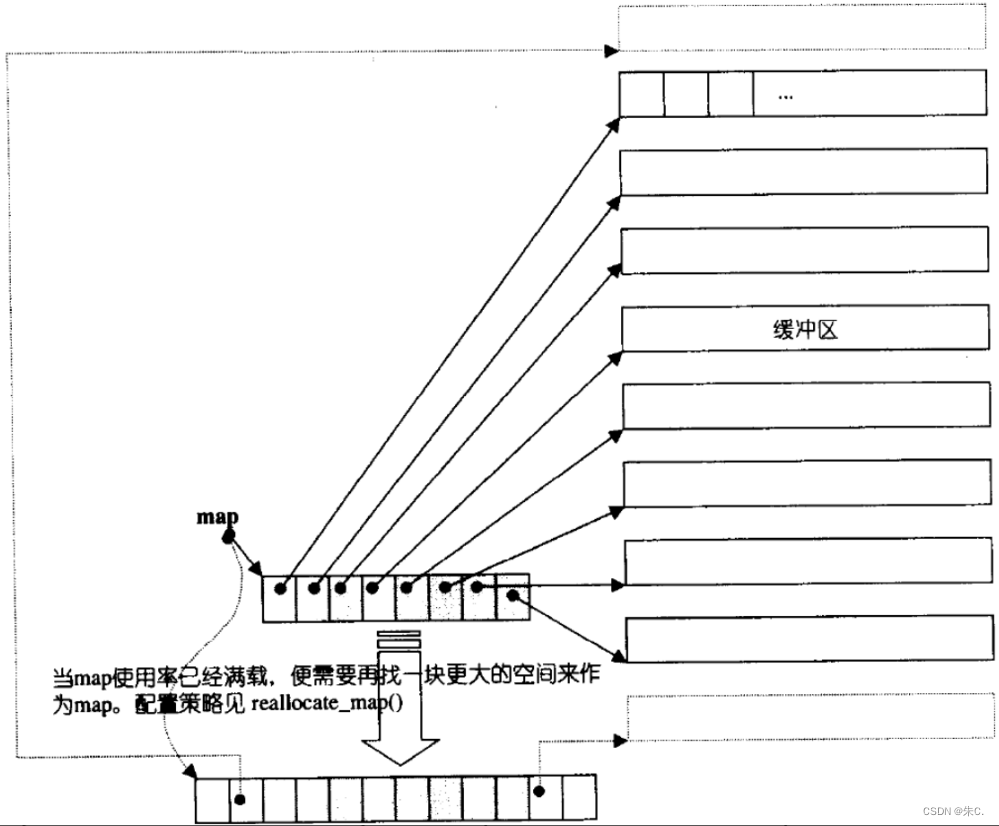
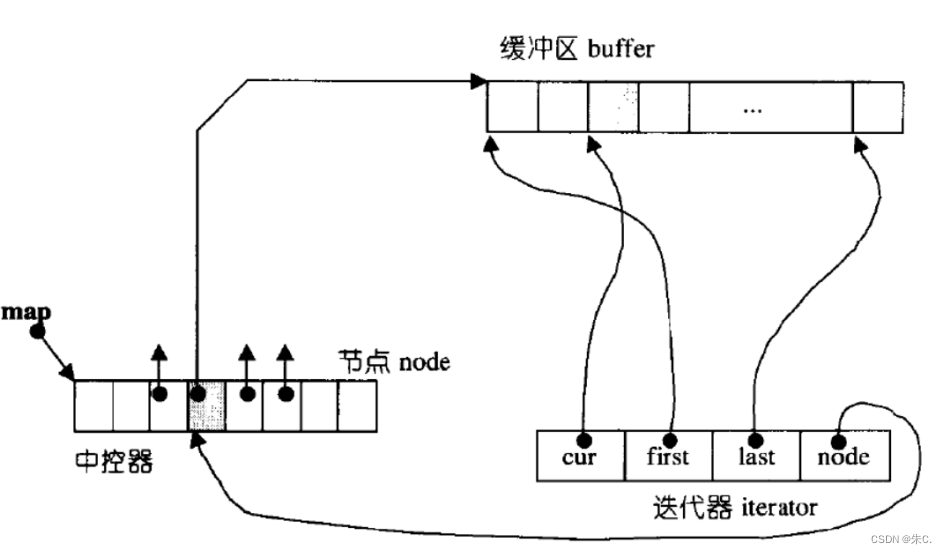
那deque是如何借助其迭代器维护其假想连续的结构呢?
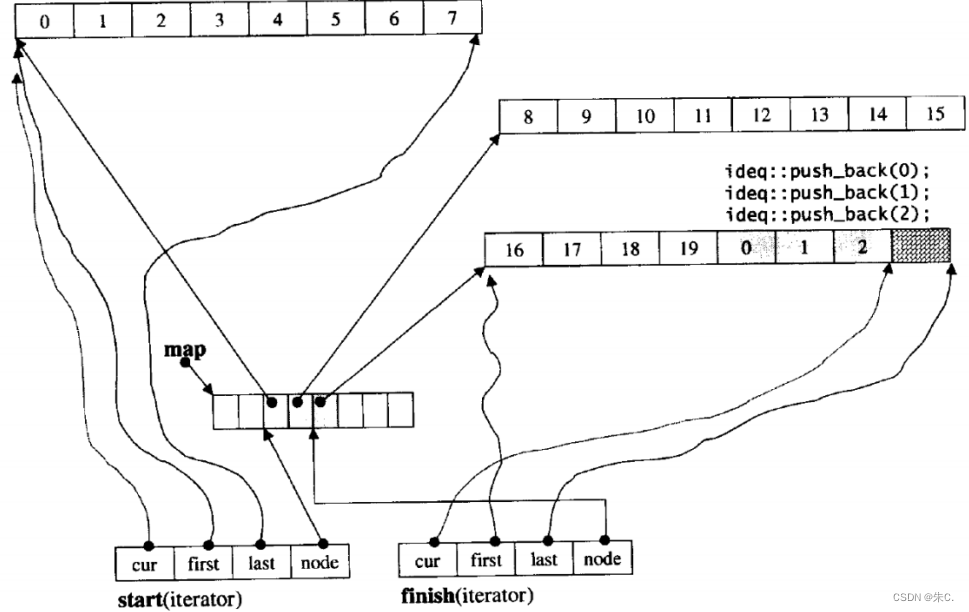
- 与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
- 与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
- 1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长 时,deque不仅效率高,而且内存使用率高。 结合了deque的优点,而完美的避开了其缺陷。
所以库中stack和queue的容器适配器接口是deque,而不是vector和list:
stack为例:
namespace zc
{
template<class T, class Container =deque<T>>
class stack
{
public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}const T& top(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;
};
相关文章:
【C++】STL之stack、queue的使用和模拟实现+优先级队列(附仿函数)+容器适配器详解
之前的一段时间,我们共同学习了STL中一些容器,如string、vector和list等等。本章我们将步入新阶段的学习——容器适配器。本章将详解stack、queue的使用和模拟实现优先级队列(附仿函数)容器适配器等。 目录 (一&…...

第⑦讲:Ceph集群RGW对象存储核心概念及部署使用
文章目录1.RadosGW对象存储核心概念1.1.什么是RadosGW对象存储1.2.RGW对象存储架构1.3.RGW对象存储的特点1.4.对象存储中Bucket的特性1.4.不同接口类型的对象存储访问对比2.在集群中部署RadosGW对象存储组件2.1.部署RGW组件2.2.集群中部署完RGW组件后观察集群的信息状态2.3.修改…...
从异步到promise
一,背景 1.1,js的单线程 这一切,要从js诞生之初说起,因为js是单线程的语言。 js单线程原因:作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程&…...

Linux系统中进行JDK环境的部署
一、为什么需要部署JDK。 JDK:Java Development Kit,是用于Java语言开发的环境。 部署JDK不需要懂得Java语言,只需要掌握Linux相关命令即可。 二、部署版本与环境。 系统:安装在VMware环境下的CentOS7.6; JDK版本&a…...

Leetcode.1033 移动石子直到连续
题目链接 Leetcode.1033 移动石子直到连续 Rating : 1421 题目描述 三枚石子放置在数轴上,位置分别为 a,b,c。 每一回合,你可以从两端之一拿起一枚石子(位置最大或最小),并将其放入…...
【Java】在SpringBoot中使用事务注解(@Transactional)时需要注意的点
在SpringBoot中使用事务注解(Transactional)时需要注意的点Transactional是什么使用事务注解(Transactional)时需要注意的点Transactional是什么 Transactional是Spring框架提供的一个注解,用于声明事务边界和配置事务…...

找到序列最高位的1和最高位的0并输出位置
前言: 该题为睿思芯科笔试题,笔试时长20分钟。 题目描述 接口如下: module first_1_and_0#(parameter WIDTH 8 )(input [WIDTH-1:0] data_in ,input target ,output exist ,outpu…...

面试总结sdiugiho
一、进程与线程的区别 进程: 一个在内存中运行的应用程序,每个进程都有自己独立的一块内存空间,一个进程可以有多个线程; windows 任务管理器中 一个 exe 就是一个进程。 线程: 进程中的一个执行任务(控制…...
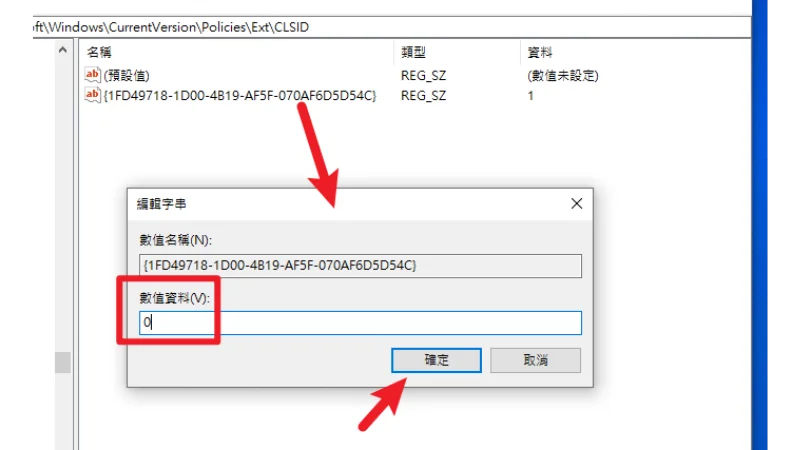
WIN10無法再使用 IE 瀏覽器打开网页解决办法
修改 Registry(只適用 Win10) 微軟已於 2023 年 2 月 14 日永久停用 Internet Explorer,會透過 Edge 的更新讓使用者開啟 IE 時自動導向 Edge,其餘如工作列上的圖示,使用的方法則是透過「品質更新」的 B 更新來達成&am…...

搭建SpringBoot和Mysql Demo
1. 引言 在上一篇文章中,介绍了如何搭建一个SpringBoot项目;本篇文章,在上一篇文章的基础上,接着介绍下怎样实现SpringBoot和MySQL的整合。在后端开发中,数据库开发是绕不开的话题,开发中很多的时间都是在…...
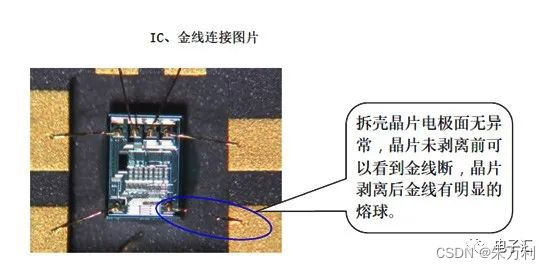
晶振03——晶振烧坏的原因
晶振03——晶振烧坏的原因 首先要清楚的一件事情是:晶振分为无源晶振与有源晶振两大类。基于这两类晶振的内部结构与工作原理的差异,晶振被烧坏的情况也要分为两大类: 针对无源晶振被烧坏的情况有以下两点: 1、手焊操作不当 假…...

项目管理的难点
一、项目团队建设 建设一支高效的项目团队,明确团队队员的职责是项目经理进行项目管理的首要条件,也是项目目标能否实现的关键。 1.1 学会放权 任何人都不能掌握所有的知识和技能,要敢于相信别人,让别人去做。 放权就要选择最…...

day22 ● 235. 二叉搜索树的最近公共祖先 ● 701.二叉搜索树中的插入操作 ● 450.删除二叉搜索树中的节点
问题: ● 235. 二叉搜索树的最近公共祖先 ● 701.二叉搜索树中的插入操作 ● 450.删除二叉搜索树中的节点 首先,二叉搜索树是一种常见的数据结构,它具有以下特点: 每个节点最多有两个子节点,分别为左子节点和右子节…...

ChatGPT 这个风口,普通人怎么抓住?
最近在测试ChatGPT不同领域的变现玩法,有一些已经初见成效,接下来会慢慢分享出来。 今天先给大家分享一个,看完就能直接上手的暴力引流玩法。 所需工具: 1)ChatGPT(最好是plus版,需要保证快速…...

Python代码规范:企业级代码静态扫描-代码规范、逻辑、语法、安全检查,以及代码规范自动编排(2)
本篇将总结实际项目开发中Python代码规范检查、自动编排的一些工具,特点,使用方法,以及如何在Pycharm中集成这些工具,如autoflake、yapf、black、isort、autopep8代码规范和自动编排工具。上一篇总结的pylint、pyproject-flake8、…...

acme.sh从 letsencrypt 生成SSL免费证书并自动更新证书
acme.sh 实现了 acme 协议, 可以从 letsencrypt 生成免费的证书 ACME 协议: Automatic Certificate Management Environment 自动化证书管理环境 文档: github: https://github.com/acmesh-official/acme.shgitee: https://gitee.com/neilpang/acme.sh中文文档: https://git…...
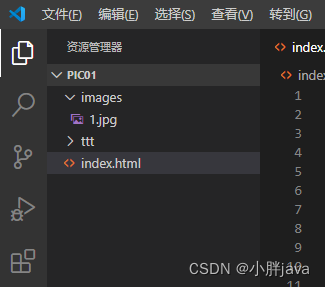
基于html+css的evenly布局
准备项目 项目开发工具 Visual Studio Code 1.44.2 版本: 1.44.2 提交: ff915844119ce9485abfe8aa9076ec76b5300ddd 日期: 2020-04-16T16:36:23.138Z Electron: 7.1.11 Chrome: 78.0.3904.130 Node.js: 12.8.1 V8: 7.8.279.23-electron.0 OS: Windows_NT x64 10.0.19044 项目…...

【从零开始学习 UVM】10.5、UVM TLM —— UVM TLM Blocking Get Port
文章目录 UVM TLM Get Port Example1. 创建一个发送方类,其端口类型为 uvm_blocking_get_imp3. 创建接收器类,等待 get 方法。4. 在更高层次上连接端口及其实现Get端口阻塞行为任何组件都可以通过 TLM get 端口请求从另一个组件接收事务。发送组件应定义获取端口的实现。该实…...
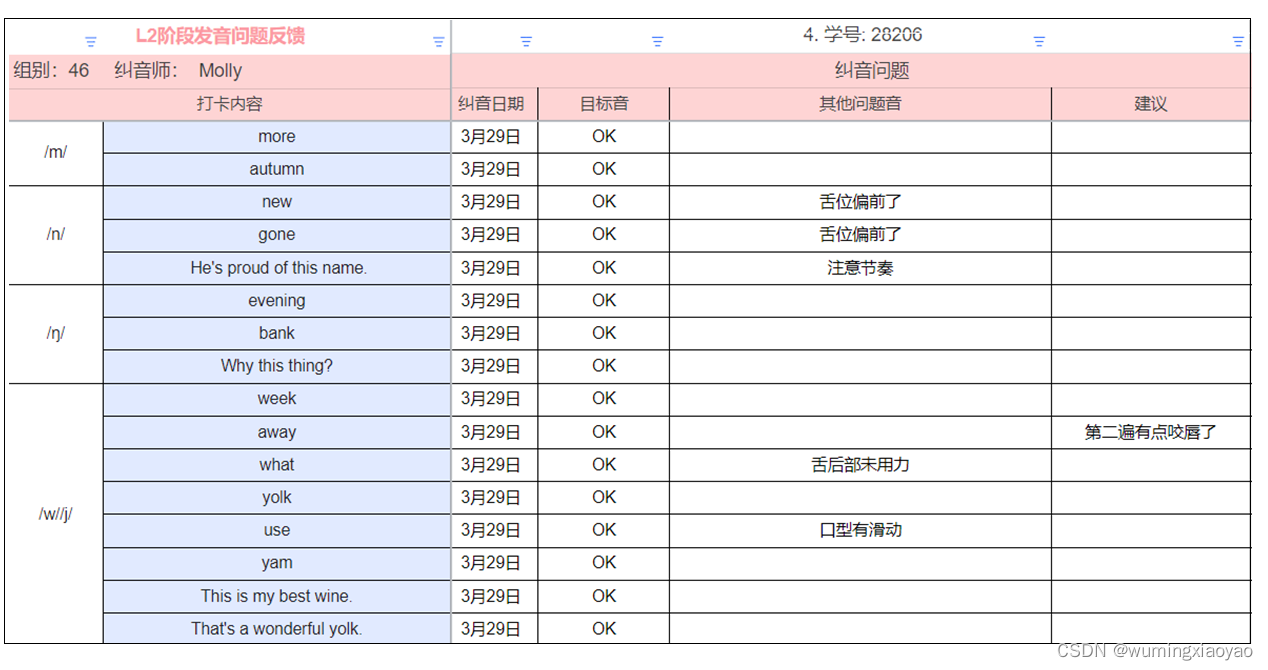
English Learning - L2 第 10 次小组纠音 辅音 [m] [n] [ŋ] 半元音 [w] [j] 2023.3.29 周三
English Learning - L2 第 10 次小组纠音 辅音 [m] [n] [ŋ] [w] [j] 2023.3.29 周三共性问题more Autumn [ɔː] 舌位偏前gone evening 前后鼻音不分Hes proud of this name 双元音缺乏滑动感bank thing 中的后鼻音发成前鼻音week what yolk 元音 [iː] [ɒ] 舌位偏前 [əʊ] …...

从零开始实现一个C++高性能服务器框架----环境变量模块
此项目是根据sylar框架实现,是从零开始重写sylar,也是对sylar丰富与完善 项目地址:https://gitee.com/lzhiqiang1999/server-framework 简介 项目介绍:实现了一个基于协程的服务器框架,支持多线程、多协程协同调度&am…...

2. Linux桌面环境介绍
2. Liunx桌面环境介绍 桌面介绍终端设置 设置终端属性:字体快捷键: 新建终端(ctrlaltN)新建标签(ctrlaltT)背景和锁屏设置语言和输入法设置课后作业 系统开机、关机账户的注销、锁屏打开常用程序࿰…...

Connect to Oracle Database with JDBC Driver
1. Overview The Oracle Database is one of the most popular relational databases. In this tutorial, we’ll learn how to connect to an Oracle Database using a JDBC Driver. 2. The Database To get us started, we need a database. If we don’t have access to …...

线程池:Java 并发编程的核心武器
线程池:Java 并发编程的"核心武器" 线程池是管理和复用线程的高级工具,它能显著提高程序性能,避免频繁创建和销毁线程的开销。 为什么需要线程池? 没有线程池的问题 // 传统方式:来一个任务创建一个线程 pub…...

质子交换膜燃料电池Comsol完整版仿真模型:涵盖两相流非等温雾状流道、液态水相变及扩散项,考...
质子交换膜燃料电池仿真Comsol完整版 虽然氢电发文量多了,但是氢电模型复杂程度和别的领域没法比,两相流非等温的氢燃料电池,跑通的都得好几千的,这个模型的流道和内侧都是多相流,这个里面是雾状流的流道,目…...

使用Dependency Check命令行工具高效检测Java项目中的安全漏洞
1. 为什么Java开发者需要关注依赖库安全? 如果你是一名Java开发者,可能经常遇到这样的情况:项目运行得好好的,突然某天系统被入侵了,排查半天才发现是某个第三方库存在安全漏洞。这种情况在现实开发中并不少见…...

SeqGPT-560M中文理解深度测评:对古汉语、方言、行业黑话的泛化能力分析
SeqGPT-560M中文理解深度测评:对古汉语、方言、行业黑话的泛化能力分析 1. 模型背景与核心能力 SeqGPT-560M是阿里达摩院推出的零样本文本理解模型,专门针对中文场景优化,无需训练即可完成文本分类和信息抽取任务。这个560M参数的轻量级模型…...

别再死记硬背了!用Python手把手教你实现数据库闭包自动计算器
用Python实现数据库闭包计算器:从理论到实战的自动化工具 闭包计算是数据库原理中的核心算法,但传统教材往往停留在抽象描述和手工演算阶段。作为曾经被各种箭头符号和递归推导折磨过的开发者,我决定用Python打造一个能自动计算闭包并可视化步…...

vLLM-v0.17.1惊艳效果:束搜索+并行采样在长文本生成中的稳定性展示
vLLM-v0.17.1惊艳效果:束搜索并行采样在长文本生成中的稳定性展示 1. vLLM框架核心能力概览 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,其最新版本v0.17.1在长文本生成稳定性方面取得了显著突破。这个开源项目最初由加州大学伯克利分校…...
)
FINCH聚类算法实战:5分钟搞定无参数聚类(附Python代码)
FINCH聚类算法实战:5分钟搞定无参数聚类(附Python代码) 在数据科学和机器学习领域,聚类分析一直是探索性数据分析的重要工具。传统聚类方法如K-means、DBSCAN等虽然广泛应用,但都面临一个共同挑战:需要人工…...

十大经典排序算法解析与实现
## 1. 十大经典排序算法技术解析### 1.1 算法分类体系 排序算法可分为两大技术类别:**比较类排序**: - 通过元素间比较确定相对次序 - 时间复杂度下限为O(nlogn) - 典型代表:快速排序、堆排序、归并排序**非比较类排序**: - 不依赖…...