LinkedHashMap源码分析以及LRU的应用
LinkedHashMap源码分析以及LRU的应用
LinkedHashMap简介
LinkedHashMap我们都知道是在HashMap的基础上,保证了元素添加时的顺序;除此之外,它还支持LRU可以当做缓存中心使用
源码分析目的
-
分析保持元素有序性是如何实现的
-
LRU是如何实现的
源码分析
有序性的实现
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>{transient LinkedHashMap.Entry<K,V> head;transient LinkedHashMap.Entry<K,V> tail;final boolean accessOrder;static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}}Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {}void afterNodeAccess(Node<K,V> p) { }void afterNodeInsertion(boolean evict) { }void afterNodeRemoval(Node<K,V> p) { }
}
LinkedHashMap继承自HashMap,并主要重写了HashMap中四个方法,分别是newNode、afterNodeAccess、afterNodeInsertion、afterNodeRemoval,这几个方法分别会在HashMap创建元素、访问元素、添加元素、删除元素之后回调;LinkedHashMap主要通过这几个方法,构建成双向链表将元素连接起来,从而实现顺序访问的目的。
-
变量head和tail分别指向第一个元素和最后一个元素
-
添加的元素会包装成
Entry对象,Entry继承自HashMap.Node,在此基础上增加before和after变量用于指向当前元素的前后两个元素形成链式结构 -
accessOrder:true表示对元素根据LRU来排序,也就是最近访问过的放链表尾部,最后访问过的放链表头部,默认为false
添加元素
在LinkedHashMap中并没有重写HashMap的put方法,根据HashMap的put方法源码可以知道当添加一个元素时会调用newNode方法去创建一个Node对象,接着会调用afterNodeInsertion方法,我们先来看看LinkedHashMap是如何重写这两个方法的:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {LinkedHashMap.Entry<K,V> p =new LinkedHashMap.Entry<K,V>(hash, key, value, e);linkNodeLast(p);return p;
}private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {LinkedHashMap.Entry<K,V> last = tail;tail = p;if (last == null)head = p;else {p.before = last;last.after = p;}
}
- 在创建元素节点时,会先创建一个
LinkedHashMap.Entry节点,然后将该元素添加链表的尾部
void afterNodeInsertion(boolean evict) { // possibly remove eldestLinkedHashMap.Entry<K,V> first;if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}
}
-
元素添加后,会调用
afterNodeInsertion方法,LinkedHashMap重写该方法后,根据removeEldestEntry方法决定是否要将表头元素删除,这里主要是为了支持LRU,如果该方法返回true,则表示缓存已满,会移除链表头元素 -
其中
evict变量在HashMap中的解释是,如果false表示创建模式,也就是反序列化时初始化HashMap数据时调用的put方法
获取元素
public V get(Object key) {Node<K,V> e;if ((e = getNode(hash(key), key)) == null)return null;if (accessOrder)afterNodeAccess(e);return e.value;
}void afterNodeAccess(Node<K,V> e) { // move node to lastLinkedHashMap.Entry<K,V> last;if (accessOrder && (last = tail) != e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.after = null;if (b == null)head = a;elseb.after = a;if (a != null)a.before = b;elselast = b;if (last == null)head = p;else {p.before = last;last.after = p;}tail = p;++modCount;}
}
LinkedHashMap重写了HashMap的get方法,主要是为了在获取元素后,根据accessOrder变量来判断是否要根据LRU调整元素位置;默认为false,所以获取元素后顺序是不会变的,也就是保证了原有的顺序;
但是如果要作为LRU缓存中心来存储数据,则需要设置为true,接着调用重写了HashMap的afterNodeAccess方法,对元素位置进行调整,其实也就是将当前访问的元素移动到链表的尾部
移除元素
void afterNodeRemoval(Node<K,V> e) { // unlinkLinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.before = p.after = null;if (b == null)head = a;elseb.after = a;if (a == null)tail = b;elsea.before = b;
}
在元素移除后,需要将该元素从双向链表中移除,逻辑也是比较简单
遍历集合
LinkedHashMap重写了Map相关集合遍历的方法,比如entrySet、keySet等,让外部能够根据双向链表顺序访问到元素
public Set<Map.Entry<K,V>> entrySet() {Set<Map.Entry<K,V>> es;return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;
}final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> {public final int size() { return size; }public final void clear() { LinkedHashMap.this.clear(); }public final Iterator<Map.Entry<K,V>> iterator() {return new LinkedEntryIterator();}public final boolean contains(Object o) {if (!(o instanceof Map.Entry))return false;Map.Entry<?,?> e = (Map.Entry<?,?>) o;Object key = e.getKey();Node<K,V> candidate = getNode(hash(key), key);return candidate != null && candidate.equals(e);}public final boolean remove(Object o) {if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>) o;Object key = e.getKey();Object value = e.getValue();return removeNode(hash(key), key, value, true, true) != null;}return false;}public final Spliterator<Map.Entry<K,V>> spliterator() {return Spliterators.spliterator(this, Spliterator.SIZED |Spliterator.ORDERED |Spliterator.DISTINCT);}public final void forEach(Consumer<? super Map.Entry<K,V>> action) {if (action == null)throw new NullPointerException();int mc = modCount;for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)action.accept(e);if (modCount != mc)throw new ConcurrentModificationException();}
}
LRU的支持
LinkedHashMap天生支持LRU,可以用于作为LRU缓存中心,当LinkedHashMap创建时可以传入参数将成员变量accessOrder设置为true;表示需要根据元素访问来调整顺序;
public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder) {super(initialCapacity, loadFactor);this.accessOrder = accessOrder;
}
这样当访问元素时会将该元素移动到队尾,经过多次访问后,最近访问的元素到了队尾,而最早访问元素则到了队头;
public V get(Object key) {Node<K,V> e;if ((e = getNode(hash(key), key)) == null)return null;if (accessOrder)afterNodeAccess(e);//移动到队尾return e.value;
}
当插入元素时提供了一个方法removeEldestEntry用于根据当前最大缓存容量来决定是否要删除队头元素
void afterNodeInsertion(boolean evict) { // possibly remove eldestLinkedHashMap.Entry<K,V> first;if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;
}
所以创建LRU的缓存中心只需要两步:
-
创建LinkedHashMap时设置
accessOrder为true -
重写
removeEldestEntry方法,在该方法中,如果当前元素个数大于最大允许的缓存元素个数,则返回true已移除双向链表中的头元素
简单LRU缓存中心实现:
public class LruCacheCenter<K, V> extends LinkedHashMap<K, V> {private int mMaxCacheSize;//最大缓存个数public LruCacheCenter() {this(MAX_CACHE_NUM);}public LruCacheCenter(int maxCacheSize) {super(maxCacheSize, 0.75f, true);//accessOrder设置为truethis.mMaxCacheSize = maxCacheSize;}@Overrideprotected boolean removeEldestEntry(Map.Entry<K, V> eldest) {return size() > mMaxCacheSize;}
}
相关文章:

LinkedHashMap源码分析以及LRU的应用
LinkedHashMap源码分析以及LRU的应用 LinkedHashMap简介 LinkedHashMap我们都知道是在HashMap的基础上,保证了元素添加时的顺序;除此之外,它还支持LRU可以当做缓存中心使用 源码分析目的 分析保持元素有序性是如何实现的 LRU是如何实现的…...

【每日一题Day166】LC1053交换一次的先前排列 | 贪心
交换一次的先前排列【LC1053】 给你一个正整数数组 arr(可能存在重复的元素),请你返回可在 一次交换(交换两数字 arr[i] 和 arr[j] 的位置)后得到的、按字典序排列小于 arr 的最大排列。 如果无法这么操作,…...

Canal增量数据订阅和消费——原理详解
文章目录 简介工作原理MySQL主备复制原理canal 工作原理Canal-HA机制应用场景同步缓存 Redis /全文搜索 ES下发任务数据异构简介 canal 翻译为管道,主要用途是基于 MySQL 数据库的增量日志 Binlog 解析,提供增量数据订阅和消费。 早期阿里巴巴因为杭州和美国双机房部署,存…...

为什么要使用线程池
Java线程的创建非常昂贵,需要JVM和OS(操作系统)配合完成大量的工作: (1)必须为线程堆栈分配和初始化大量内存块,其中包含至少1MB的栈内存。 (2)需要进行系统调用,以便在OS(操作系统)…...

在云服务部署前后端以及上传数据库
1.上传数据库(sql文件) 首先建立一个目录,用于存放要部署的sql文件,然后在此目录中进入mysql 进入后建立一个数据库,create database 数据库名 完成后,通过select * from 表名可以查到数据说明导入成功。 2.部署Maven后端 将Ma…...

Onedrive for Business迁移方案 | 分享一
文章目录 前言 一、Onedrive for Business迁移方案应用范围? 1.准备目标平台 2.导出源平台数据 <...

pt01数据类型、语句选择
python01 pycharm常用快捷键 (1) 移动到本行开头:home键 (2) 移动到本行末尾:end键盘 (3) 注释代码:ctrl / (4) 复制行:ctrl d #光标放行上 (5) 删除行:shift delete (6) 选择列:shift alt 鼠标左键…...
ChatGPT 存在很大的隐私问题
当 OpenAI 发布时 2020 年 7 月的 GPT-3,它提供了用于训练大型语言模型的数据的一瞥。 根据一篇技术论文,从网络、帖子、书籍等中收集的数百万页被用于创建生成文本系统。 在此数据中收集的是您在网上分享的一些关于您自己的个人信息,这些数据现在让 O…...
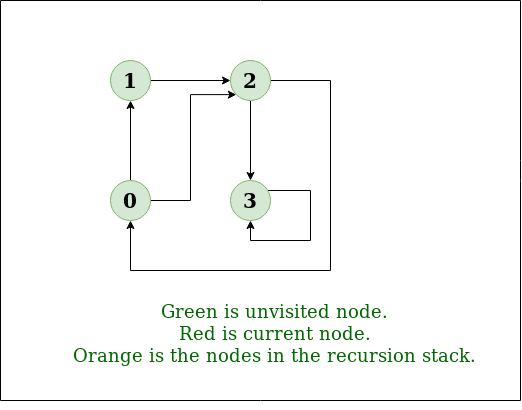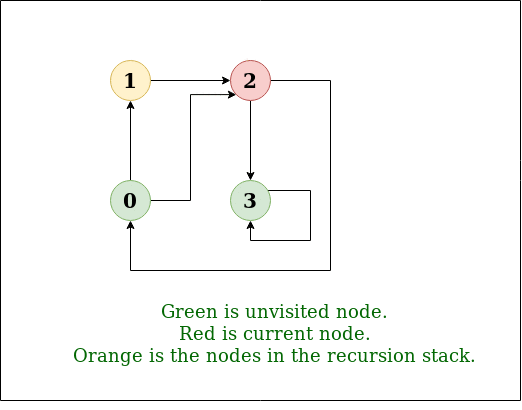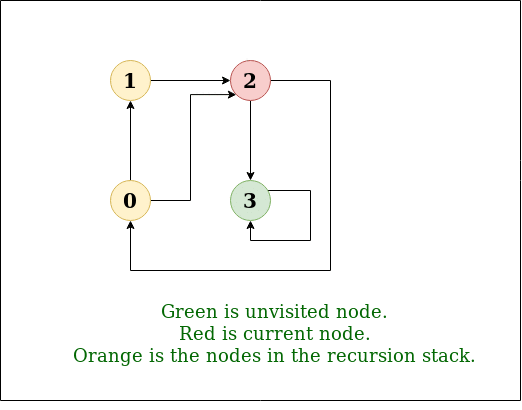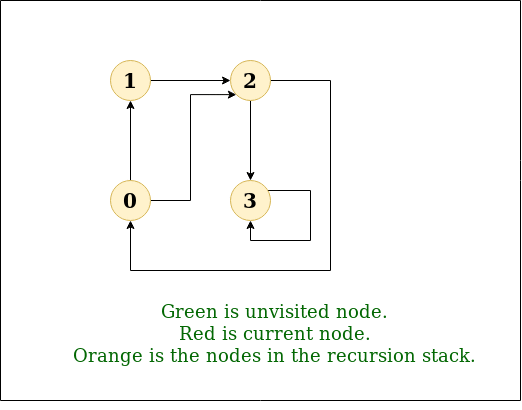
图的迭代深度优先遍历
图的深度优先遍历(或搜索)类似于树的深度优先遍历(DFS)。这里唯一的问题是,与树不同,图可能包含循环,因此一个节点可能会被访问两次。为避免多次处理一个节点,请使用布尔访问数组。 例子: 输入: n = 4, e = 6 0 -> 1, 0 -> 2, 1 -> 2, 2 -> 0, …...

华为OD机试-开放日活动-2022Q4 A卷-Py/Java/JS
某部门开展Family Day开放日活动,其中有个从桶里取球的游戏,游戏规则如下:有N个容量一样的小桶等距排开,且每个小桶都默认装了数量不等的小球, 每个小桶装的小球数量记录在数组 bucketBallNums 中,游戏开始时,要求所有…...

两亲性聚合物:Lauric acid PEG Maleimide,Mal-PEG-Lauric acid,月桂酸PEG马来酰亚胺,试剂知识分享
Lauric acid PEG Maleimide,Lauric acid PEG Mal| 月桂酸PEG马来酰亚胺 | CAS:N/A | 端基取代率:95%一、试剂参数信息: 外观(Appearance):灰白色/白色固体或粘性液体取决于分子量 溶解性&am…...

FB使用入口点函数例子
一、DLL的入口点 1.1 VFB的自带DLL模式入口 FB是把代码转成C(GCC编译)或者汇编(GAS编译)后编译的,本身就有一个main函数,所以在程序里其实不需要入口点,直接写就可以顺序执行,而有的…...
学习周报4/9
文章目录前言文献阅读摘要简介方法结论时间序列预测总结前言 本周阅读文献《Improving LSTM hydrological modeling with spatiotemporal deep learning and multi-task learning: A case study of three mountainous areas on the Tibetan Plateau》,文章主要基于…...

49天精通Java,第14天,Java泛型方法的定义和使用
目录一、基本介绍1、Java泛型的基本语法格式为:2、在使用泛型时,还需要注意以下几点:二、泛型的优点1、类型安全2、消除强制类型转换3、更高的效率4、潜在的性能收益三、常见泛型字母含义四、使用泛型时的注意事项五、泛型的使用1、泛型类2、…...

20230402英语学习
reasonable adj.合理的;通情达理的;明智的,理智的 abstract adj.抽象的,理论的 reflection n.反射; 映像, 倒影; 反映; 表达, 抒发; (长相等)酷似的人; 惟妙惟肖的事物; 深思; 考虑 instruction n.教授; 教导, 指导; 指示, 命令…...
SpringCloud)
Java知识复习(十七)SpringCloud
1、什么是微服务架构 微服务架构就是将单体的应用程序分成多个应用程序,这多个应用程序就成为微服务,每个微服务运行在自己的进程中,并使用轻量级的机制通信这些服务围绕业务能力来划分,并通过自动化部署机制来独立部署。这些服务…...
MySQL 数据库操作
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、关系模型二、数据库的操作 创建数据库查看数据库选择数据库删除数据库三、MySQL 数据库命名规范总结一、关系模型 关系数据库是建立在关系模型上的。而关系模…...

Cesium更换地球背景
设置背景图片 #cesiumContainer {width: 100%;height: 100%;background-image: url("/assets/image/背景.png"); }设置渲染, 用来去掉地球表面的大气效果的黑圈问题 this.viewer new Cesium.Viewer("cesiumContainer", {......// 设置渲染orderIndepe…...

测试人员的瓶颈期
测试人员的瓶颈期 做测试久了,会在所难免地碰到职业瓶颈期,这很正常,从事任何职业的工作人员都会遇到,关键是要看你如何去克服它。对优秀的软件测试人员来讲,除了要具备全面的技能、丰富的经验、良好的心理素质&#x…...

HTML5 <form> 标签
HTML5 <form> 标签 实例 带有两个输入字段和一个提交按钮的 HTML 表单: <form action"demo_form.php" method"get">First name: <input type"text" name"fname"><br>Last name: <input type&qu…...
)
收藏备用!小红书二面大模型面试题:Agent 基本架构核心组件详解(小白也能看懂)
很多程序员和大模型小白反馈,最近小红书二面被问到了一道高频题:「Agent 的基本架构由哪些核心组件构成?」,这道题看似基础,却能快速考察对 Agent 核心逻辑的理解,不管是面试还是日常学习都必须掌握。今天就…...

Phi-4-reasoning-vision-15B在金融图表分析中的实战:趋势识别与异常定位
Phi-4-reasoning-vision-15B在金融图表分析中的实战:趋势识别与异常定位 1. 金融图表分析的挑战与机遇 金融从业者每天需要分析大量图表数据,从K线图到财务报表,从趋势分析到异常检测。传统的人工分析方法存在三个明显痛点: 效…...

零基础玩转BEYOND REALITY Z-Image:手把手教你搭建高精度文生图引擎
零基础玩转BEYOND REALITY Z-Image:手把手教你搭建高精度文生图引擎 1. 引言:为什么选择BEYOND REALITY Z-Image 在当今AI图像生成领域,BEYOND REALITY Z-Image以其卓越的写实表现力脱颖而出。这款基于Z-Image-Turbo底座和BEYOND REALITY S…...

AI印象派艺术工坊WebUI定制:前端界面修改实战案例
AI印象派艺术工坊WebUI定制:前端界面修改实战案例 1. 引言 你有没有想过,自己也能像艺术家一样,把随手拍的照片变成一幅幅精美的画作?素描、彩铅、油画、水彩,这些听起来需要多年绘画功底才能完成的作品,…...

多无人机协同打击任务分配方法
随着无人机技术的不断成熟和完善,其军事应用的优势日益显现,近年来其在军事冲突中 所发挥的作用更使人们认识到,无人机在未来战争中将成为重要的军事装备。随着无人机在军 事中的大量应用,无人机集群协同执行任务将成为典型的应用…...

毕业季求生指南:用百考通AI重塑你的论文写作全流程
深夜的电脑屏幕前,面对空白的文档和堆积如山的文献,你是否感到无从下手?当查重率居高不下、导师的修改意见密密麻麻时,是否渴望一种更智能的解决方案?本文将为你揭示一个学术写作的新可能。 01 开题之困:从…...

避开这些坑!算法工程师自学必备的5个高效学习法与工具推荐
避开这些坑!算法工程师自学必备的5个高效学习法与工具推荐 1. 为什么大多数自学算法工程师会失败? 在咖啡馆见到老张时,他正对着电脑屏幕上的LeetCode题目发呆。这位转行学习算法的前机械工程师已经坚持了8个月,但最近一次面试还是…...

14届蓝桥杯省赛Java A 组Q4~Q5
题目链接: Q4 蓝桥云课:棋盘 洛谷:P13879 [蓝桥杯 2023 省 Java A] 棋盘 Q5 蓝桥云课:互质数的个数 洛谷:P13880 [蓝桥杯 2023 省 Java A] 互质数的个数 算法原理: Q4解法:前缀和差分 时间…...

春节不用愁对联:春联生成模型实战,3步生成专属春联
春节不用愁对联:春联生成模型实战,3步生成专属春联 1. 传统年味遇上AI科技 每到春节,家家户户贴春联是延续千年的传统习俗。一副好春联既要对仗工整,又要寓意吉祥,还要符合自家特色,这让不少人为之头疼。…...

nlp_structbert_sentence-similarity_chinese-large赋能智能客服:精准匹配用户问题与知识库
nlp_structbert_sentence-similarity_chinese-large赋能智能客服:精准匹配用户问题与知识库 你有没有遇到过这样的情况?在某个App里找客服,输入了一大段问题,结果机器人回复的答案要么是“牛头不对马嘴”,要么就是让你…...