如何在千万级数据中查询 10W 的数据并排序
前言
在开发中遇到一个业务诉求,需要在千万量级的底池数据中筛选出不超过 10W 的数据,并根据配置的权重规则进行排序、打散(如同一个类目下的商品数据不能连续出现 3 次)。
下面对该业务诉求的实现,设计思路和方案优化进行介绍,对「千万量级数据中查询 10W 量级的数据」设计了如下方案
-
多线程 + CK 翻页方案
-
ES
scroll scan深翻页方案 -
ES + Hbase 组合方案
-
RediSearch + RedisJSON 组合方案
初版设计方案
整体方案设计为:
-
先根据配置的「筛选规则」,从底池表中筛选出「目标数据」
-
在根据配置的「排序规则」,对「目标数据」进行排序,得到「结果数据」
技术方案如下:
-
每天运行导数任务,把现有的千万量级的底池数据(
Hive表)导入到 Clickhouse 中,后续使用 CK 表进行数据筛选。 -
将业务配置的筛选规则和排序规则,构建为一个「筛选 + 排序」对象
SelectionQueryCondition。 -
从 CK 底池表取「目标数据」时,开启多线程,进行分页筛选,将获取到的「目标数据」存放到
result列表中。//分页大小 默认 5000 int pageSize = this.getPageSize(); //页码数 int pageCnt = totalNum / this.getPageSize() + 1;List<Map<String, Object>> result = Lists.newArrayList(); List<Future<List<Map<String, Object>>>> futureList = new ArrayList<>(pageCnt);//开启多线程调用 for (int i = 1; i <= pageCnt; i++) {//将业务配置的筛选规则和排序规则 构建为 SelectionQueryCondition 对象SelectionQueryCondition selectionQueryCondition = buildSelectionQueryCondition(selectionQueryRuleData);selectionQueryCondition.setPageSize(pageSize);selectionQueryCondition.setPage(i);futureList.add(selectionQueryEventPool.submit(new QuerySelectionDataThread(selectionQueryCondition))); }for (Future<List<Map<String, Object>>> future : futureList) {//RPC 调用List<Map<String, Object>> queryRes = future.get(20, TimeUnit.SECONDS);if (CollectionUtils.isNotEmpty(queryRes)) {// 将目标数据存放在 result 中result.addAll(queryRes);} }对目标数据
result进行排序,得到最终的「结果数据」。
CK分页查询
在「初版设计方案」章节的第 3 步提到了「从 CK 底池表取目标数据时,开启多线程,进行分页筛选」。此处对 CK 分页查询进行介绍。
封装了 queryPoolSkuList 方法,负责从 CK 表中获得目标数据。该方法内部调用了 sqlSession.selectList 方法。
public List<Map<String, Object>> queryPoolSkuList( Map<String, Object> params ) {List<Map<String, Object>> resultMaps = new ArrayList<>();QueryCondition queryCondition = parseQueryCondition(params);List<Map<String, Object>> mapList = lianNuDao.queryPoolSkuList(getCkDt(),queryCondition);if (CollectionUtils.isNotEmpty(mapList)) {for (Map<String,Object> data : mapList) {resultMaps.add(camelKey(data));}}return resultMaps;
}// lianNuDao.queryPoolSkuList@Autowired
@Qualifier("ckSqlNewSession")
private SqlSession sqlSession;public List<Map<String, Object>> queryPoolSkuList( String dt, QueryCondition queryCondition ) {queryCondition.setDt(dt);queryCondition.checkMultiQueryItems();return sqlSession.selectList("LianNu.queryPoolSkuList",queryCondition);
}sqlSession.selectList 方法中调用了和 CK 交互的 queryPoolSkuList 查询方法,部分代码如下。
<select id="queryPoolSkuList" parameterType="com.jd.bigai.domain.liannu.QueryCondition" resultType="java.util.Map">select sku_pool_id,item_sku_id,skuPoolName,price,......businessTypefrom liannu_sku_pool_indicator_allwheredt=#{dt}and<foreach collection="queryItems" separator=" and " item="queryItem" open=" " close=" " ><choose><when test="queryItem.type == 'equal'">${queryItem.field} = #{queryItem.value}</when>......</choose></foreach><if test="orderBy == null">group by sku_pool_id,item_sku_id</if><if test="orderBy != null">group by sku_pool_id,item_sku_id,${orderBy} order by ${orderBy} ${orderAd}</if><if test="limitEnd != 0">limit #{limitStart},#{limitEnd}</if>
</select>可以看到,在 CK 分页查询时,是通过 limit #{limitStart},#{limitEnd} 实现的分页。
limit 分页方案,在「深翻页」时会存在性能问题。初版方案上线后,在 1000W 量级的底池数据中筛选 10W 的数据,最坏耗时会达到 10s~18s 左右。
使用ES Scroll Scan 优化深翻页
对于 CK 深翻页时候的性能问题,进行了优化,使用 Elasticsearch 的 scroll scan 翻页方案进行优化。
另外,ES 面试题整理发了,如果你近期准备面试跳槽,建议在Java面试库小程序在线刷题,涵盖 2000+ 道 Java 面试题,几乎覆盖了所有主流技术面试题。
ES的翻页方案
ES 翻页,有下面几种方案
-
from+size翻页 -
scroll翻页 -
scroll scan翻页 -
search after翻页
| 翻页方式 | 性能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
scroll | 中 | 解决了深度分页问题 | 需要维护一个 scrollId(快照版本),无法反应数据的实时性;可排序,但无法跳页查询 | 查询海量数据 |
scroll scan | 中 | 基于 scroll 方案,进一步提升了海量数据查询的性能 | 无法排序,其余缺点同 scroll | 查询海量数据 |
search after | 高 | 性能最好,不存在深度分页问题,能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段。连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 | 不适用于大幅度跳页查询,适用于海量数据的分页 |
对上述几种翻页方案,查询不同数目的数据,耗时数据如下表。
| ES 翻页方式 | 1-10 | 49000-49010 | 99000-99010 |
|---|---|---|---|
| from + size | 8ms | 30ms | 117ms |
| scroll | 7ms | 66ms | 36ms |
| search_after | 5ms | 8ms | 7ms |
耗时数据
此处,分别使用 Elasticsearch 的 scroll scan 翻页方案、初版中的 CK 翻页方案进行数据查询,对比其耗时数据。


如上测试数据,可以发现,以十万,百万,千万量级的底池为例
-
底池量级越大,查询相同的数据量,耗时越大
-
查询结果 3W 以下时,ES 性能优;查询结果 5W 以上时,CK 多线程性能优
ES+Hbase组合查询方案
在「使用 ES Scroll Scan 优化深翻页」中,使用 Elasticsearch 的 scroll scan 翻页方案对深翻页问题进行了优化,但在实现时为单线程调用,所以最终测试耗时数据并不是特别理想,和 CK 翻页方案性能差不多。
在调研阶段发现,从底池中取出 10W 的目标数据时,一个商品包含多个字段的信息(CK 表中一行记录有 150 个字段信息),如价格、会员价、学生价、库存、好评率等。对于一行记录,当减少获取字段的个数时,查询耗时会有明显下降。如对 sku1的商品,从之前获取价格、会员价、学生价、亲友价、库存等 100 个字段信息,缩减到只获取价格、库存这两个字段信息。
如下图所示,使用 ES 查询方案,对查询同样条数的场景(从千万级底池中筛选出 7W+ 条数据),获取的每条记录的字段个数从 32 缩减到 17,再缩减到 1个(其实是两个字段,一个是商品唯一标识 sku_id,另一个是 ES 对每条文档记录的 doc_id)时,查询的耗时会从 9.3s 下降到 4.2s,再下降到 2.4s。
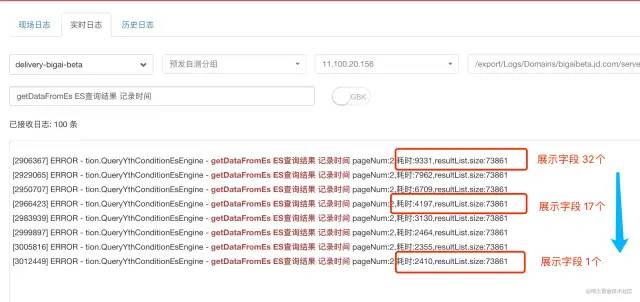
从中可以得出如下结论
-
一次 ES 查询中,若查询字段和信息较多,
fetch阶段的耗时,远大于query阶段的耗时。 -
一次 ES 查询中,若查询字段和信息较多,通过减少不必要的查询字段,可以显著缩短查询耗时。
下面对结论中涉及的 query 和 fetch 查询阶段进行补充说明。
另外,ES 面试题整理发了,如果你近期准备面试跳槽,建议在Java面试库小程序在线刷题,涵盖 2000+ 道 Java 面试题,几乎覆盖了所有主流技术面试题。
在 ES 中,搜索一般包括两个阶段,query 和 fetch 阶段
query 阶段
-
根据查询条件,确定要取哪些文档(
doc),筛选出文档 ID(doc_id)
fetch 阶段
-
根据
query阶段返回的文档 ID(doc_id),取出具体的文档(doc)
ES的filesystem cache
-
ES 会将磁盘中的数据自动缓存到
filesystem cache,在内存中查找,提升了速度 -
若
filesystem cache无法容纳索引数据文件,则会基于磁盘查找,此时查询速度会明显变慢 -
若数量两过大,基于「ES 查询的的 query 和 fetch 两个阶段」,可使用 ES + HBase 架构,保证 ES 的数据量小于
filesystem cache,保证查询速度
组合使用Hbase
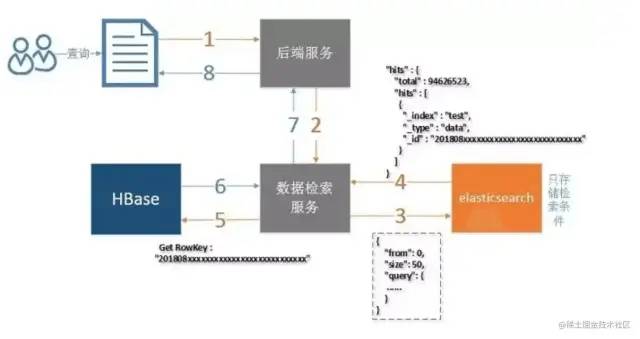
在上文调研的基础上,发现「减少不必要的查询展示字段」可以明显缩短查询耗时。沿着这个优化思路,参照参考链接 ref-1,设计了一种新的查询方案
-
ES 仅用于条件筛选,ES 的查询结果仅包含记录的唯一标识
sku_id(其实还包含 ES 为每条文档记录的doc_id) -
Hbase 是列存储数据库,每列数据有一个
rowKey。利用rowKey筛选一条记录时,复杂度为O(1)。(类似于从HashMap中根据key取value) -
根据 ES 查询返回的唯一标识
sku_id,作为 Hbase 查询中的rowKey,在O(1)复杂度下获取其他信息字段,如价格,库存等。
使用 ES + Hbase 组合查询方案,在线上进行了小规模的灰度测试。在 1000W 量级的底池数据中筛选 10W 的数据,对比 CK 翻页方案,最坏耗时从 10~18s 优化到了 3~6s 左右。
也应该看到,使用 ES + Hbase 组合查询方案,会增加系统复杂度,同时数据也需要同时存储到 ES 和 Hbase。
RediSearch+RedisJSON优化方案
RediSearch 是基于 Redis 构建的分布式全文搜索和聚合引擎,能以极快的速度在 Redis 数据集上执行复杂的搜索查询。RedisJSON 是一个 Redis 模块,在 Redis 中提供 JSON 支持。RedisJSON 可以和 RediSearch 无缝配合,实现索引和查询 JSON 文档。
根据一些参考资料,RediSearch + RedisJSON 可以实现极高的性能,可谓碾压其他 NoSQL 方案。在后续版本迭代中,可考虑使用该方案来进一步优化。
下面给出 RediSearch + RedisJSON 的部分性能数据。
RediSearch 性能数据
在同等服务器配置下索引了 560 万个文档 (5.3GB),RediSearch 构建索引的时间为 221 秒,而 Elasticsearch 为 349 秒。RediSearch 比 ES 快了 58%。
数据建立索引后,使用 32 个客户端对两个单词进行检索,RediSearch 的吞吐量达到 12.5K ops/sec,ES 的吞吐量为 3.1K ops/sec,RediSearch 比ES 要快 4 倍。同时,RediSearch 的延迟为 8ms,而 ES 为 10ms,RediSearch 延迟稍微低些。
| 对比 | Redisearch | Elasticsearch |
|---|---|---|
| 搜索引擎 | 专用引擎 | 基于 Lucene 引擎 |
| 编程语言 | C 语言 | Java |
| 存储方案 | 内存 | 磁盘 |
| 协议 | Redis 序列化协议 | HTTP |
| 集群 | 企业版支持 | 支持 |
| 性能 | 简单查询高于 ES | 复杂查询时高于 RediSearch |
RedisJSON 性能数据
根据官网的性能测试报告,RedisJson + RedisSearch 可谓碾压其他 NoSQL
-
对于隔离写入(isolated writes),RedisJSON 比 MongoDB 快 5.4 倍,比 ES 快 200 倍以上
-
对于隔离读取(isolated reads),RedisJSON 比 MongoDB 快 12.7 倍,比 ES 快 500 倍以上
在混合工作负载场景中,实时更新不会影响 RedisJSON 的搜索和读取性能,而 ES 会受到影响。
-
RedisJSON 支持的操作数/秒比 MongoDB 高约 50 倍,比 ES 高 7 倍/秒。
-
RedisJSON 的延迟比 MongoDB 低约 90 倍,比 ES 低 23.7 倍。
此外,RedisJSON 的读取、写入和负载搜索延迟,在更高的百分位数中远比 ES 和 MongoDB 稳定。当增加写入比率时,RedisJSON 还能处理越来越高的整体吞吐量。而当写入比率增加时,ES 会降低它可以处理的整体吞吐量。
总结
本文从一个业务诉求触发,对「千万量级数据中查询 10W 量级的数据」介绍了不同的设计方案。对于「在 1000W 量级的底池数据中筛选 10W 的数据」的场景,不同方案的耗时如下
-
多线程 + CK 翻页方案,最坏耗时为 10s~18s
-
单线程 + ES
scroll scan深翻页方案,相比 CK 方案,并未见到明显优化 -
ES + Hbase 组合方案,最坏耗时优化到了 3s~6s
-
RediSearch + RedisJSON 组合方案,后续会实测该方案的耗时
相关文章:
如何在千万级数据中查询 10W 的数据并排序
前言 在开发中遇到一个业务诉求,需要在千万量级的底池数据中筛选出不超过 10W 的数据,并根据配置的权重规则进行排序、打散(如同一个类目下的商品数据不能连续出现 3 次)。 下面对该业务诉求的实现,设计思路和方案优…...

RocketMQ消息文件过期原理
文章目录 消费完后的消息去哪里了?什么时候清理物理消息文件?这样设计带来的好处跳过历史消息的处理所有的消费均是客户端发起Pull请求的,告诉消息的offset位置,broker去查询并返回。但是有一点需要非常明确的是,消息消费后,消息其实并没有物理地被清除,这是一个非常特殊…...
Docker容器理解
目录 目录 一:简单理解操作系统 操作系统: 内核: 内核空间和用户空间: 二:简单理解文件系统 1:什么是文件系统 2:什么是root文件系统 三:docker 1:docker镜像 2&…...

SpringBoot 整合knife4j
文章目录SpringBoot 整合knife4j引入knife4j注解案例knife4j增强功能接口添加作者资源屏蔽访问页面加权控制接口排序分组排序请求参数缓存过滤请求参数禁用调试禁用搜索框SpringBoot 整合knife4j Knife4j是一款基于Swagger 2的在线API文档框架 在Spring Boot中,使…...
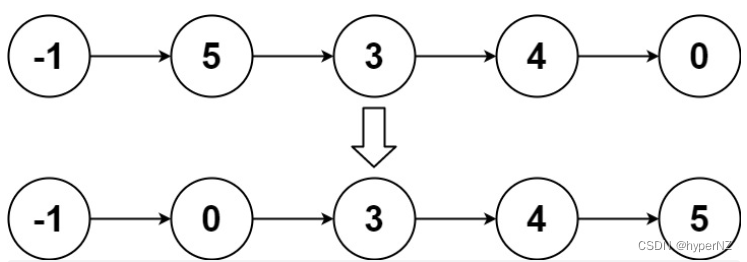
73-归并排序练习-LeetCode148排序链表
题目 给你链表的头结点 head ,请将其按升序排列并返回排序后的链表 。 示例 1: 输入:head [4,2,1,3] 输出:[1,2,3,4] 示例 2: 输入:head [-1,5,3,4,0] 输出:[-1,0,3,4,5] 示例 3ÿ…...

Hystrix学习笔记
Hystrix 官方文档: https://github.com/Netflix/Hystrix/wiki 是什么 In a distributed environment, inevitably some of the many service dependencies will fail. Hystrix is a library that helps you control the interactions between these distributed …...
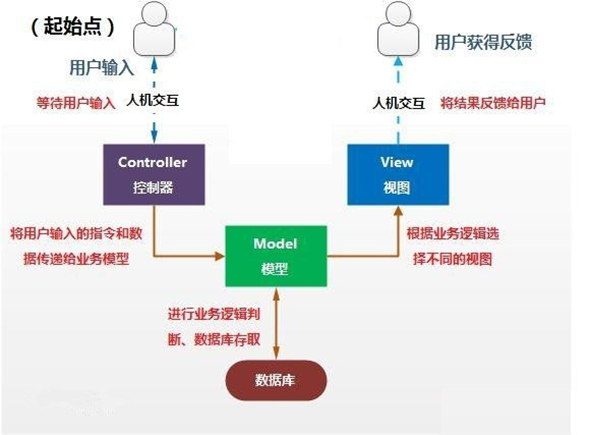
面向对象编程(基础)8:关键字:package、import
目录 8.1 package(包) 8.1.1 语法格式 说明: 8.1.2 包的作用 8.1.3 应用举例 举例2:MVC设计模式 8.1.4 JDK中主要的包介绍 8.2 import(导入) 8.2.1 语法格式 8.2.2 应用举例 8.2.3 注意事项 8.1 package(包) package,称为包&#x…...

【机器学习】P10 从头到尾实现一个线性回归案例
这里写自定义目录标题(1)导入数据(2)画出城市人口与利润图(3)计算损失值(4)计算梯度下降(5)开始训练(6)画出训练好的模型(…...
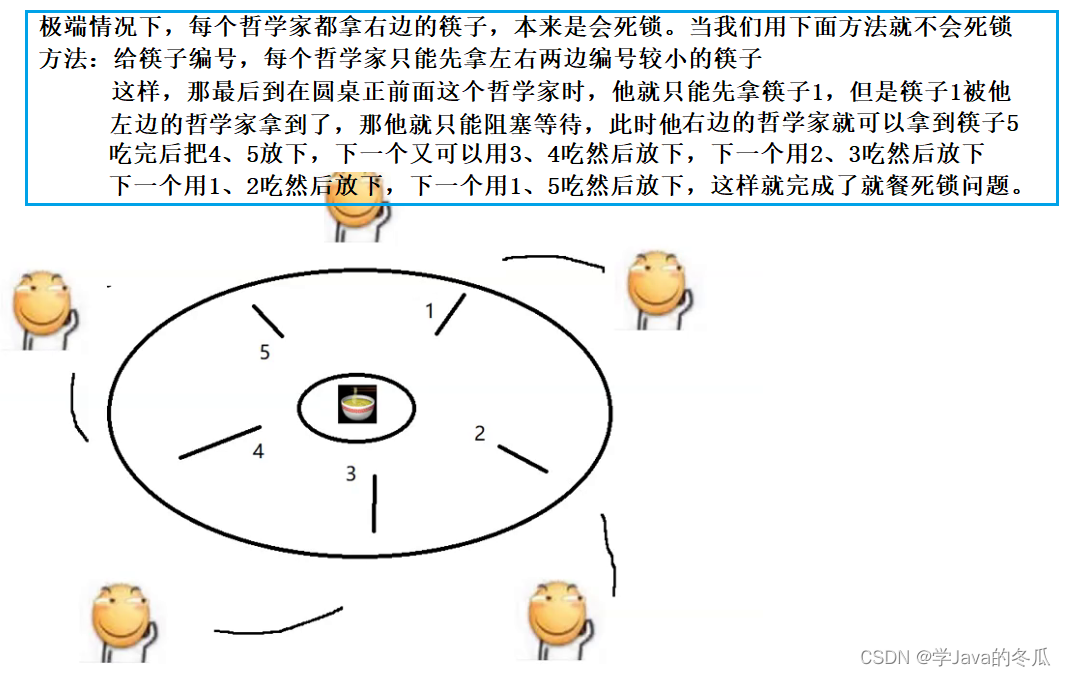
【Java EE】-多线程编程(四) 死锁
作者:学Java的冬瓜 博客主页:☀冬瓜的主页🌙 专栏:【JavaEE】 分享:2023.3.31号骑行的照片再发一次(狗头)。 主要内容:什么是死锁?不可重入可重入、死锁的三个典型情况:1、一个线程一…...
)
学习数据结构第1天(数据结构的基本概念)
数据结构的基本概念基本概念和术语数据结构的三要素经典试题基本概念和术语 1.数据 数据是信息的载体,是描述客观事物属性的数、字符以及所有能输入到计算机中并被计算机程序识别和处理的符号的集合。数据是计算机程序加工的原料。 2.数据元素 数据元素是数据的基本…...

南大通用数据库-Gbase-8a-学习-33-空洞率查询与解决方法
目录 一、个人理解 二、存储过程 三、虚机测试 四、解决方法 1、重建表 2、shrink space 一、个人理解 空洞率的产生是由于delete语句并不会真实的删除数据,只是在数据上打了一个不可见标签,但实际还是占用着相应的存储空间。 二、存储过程 自定义…...
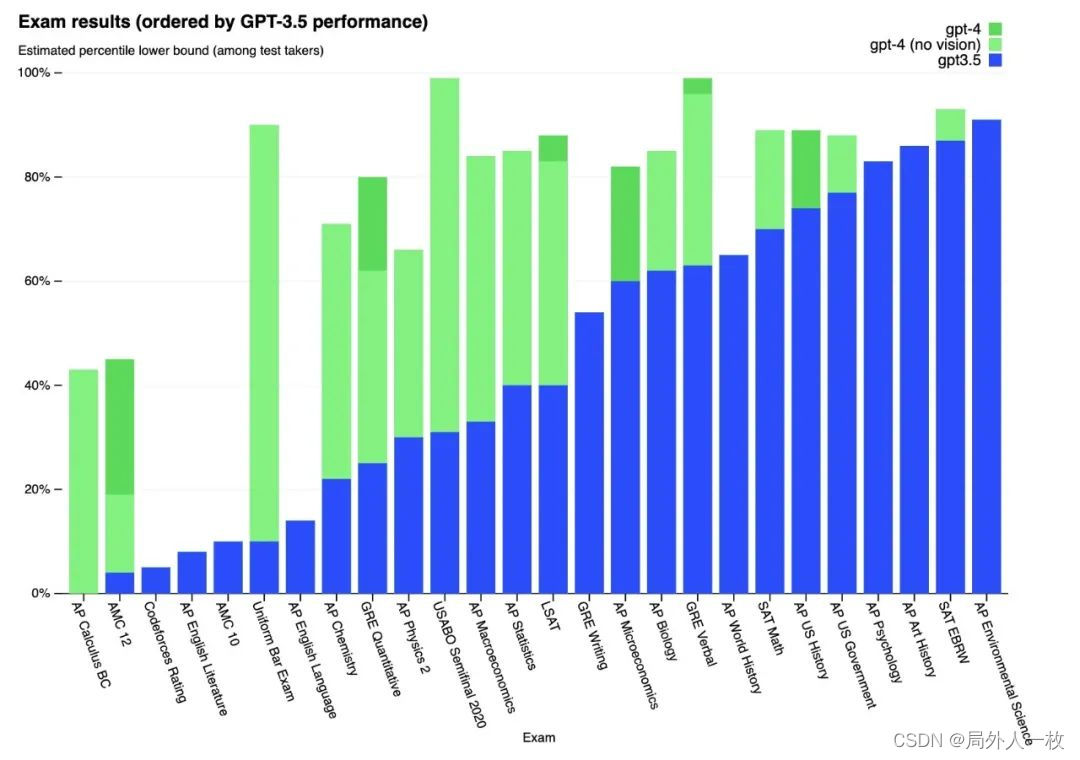
为什么我们认为GPT是一个技术爆炸
从23年初,ChatGPT火遍全球,通过其高拟人化的回答模式,大幅提升了人机对话的体验和效率,让用户拥有了一个拥有海量知识的虚拟助手,根据UBS发布的研究报告显示,ChatGPT在1月份的月活跃用户数已达1亿ÿ…...

程序员如何能提高自己的编程水平?
这些实用的小建议,能帮你迅速地提高编程水平: 不要做无意义的奋斗 拒绝喊口号和无意义的奋斗,包括但不限于: ①做了计划表却从未有执行的一天; ②每天都是最早来、最晚走,但是工作进度趋近于0;…...
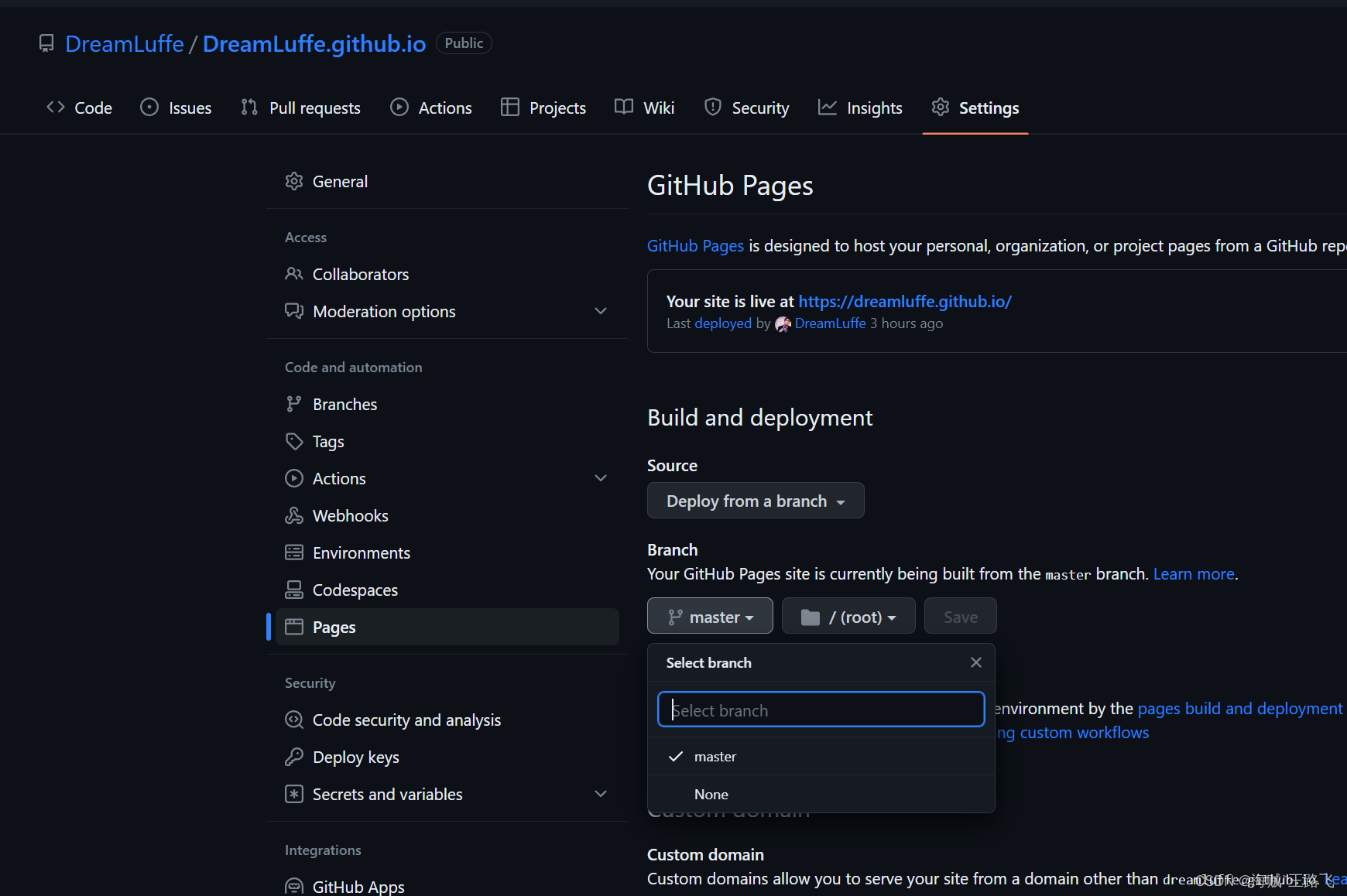
从零使用vuepress搭建个人博客部署.github.io
前言 记录小白如何搭建个人博客 github部署的博客👉: DreamLuffe的博客 netilify部署的博客:👉:DreamLuffe的博客 个人博客搭建实战 网上有很多优秀的开源博客页面,我们就直接安装好,再继续…...
Python 进阶指南(编程轻松进阶):十一、注释、文档字符串和类型提示
原文:http://inventwithpython.com/beyond/chapter11.html 源代码中的注释和文档可能和代码一样重要。原因是软件是永远不会完成的;无论是添加新功能还是修复错误,您总是需要做出改变。但是你不能改变代码,除非你理解它࿰…...

python item()方法
Python中有很多方法来解决一些简单的问题,其中最常见的就是用 item ()方法来完成。item ()方法的全称是item-process (),该方法用来对对象进行创建、删除、改变、添加、更新等操作。…...

【day2】Android Jetpack Compose环境搭建
【day2】Android Jetpack Compose环境搭建 以下是适用于 Jetpack Compose 的环境要求: Android Studio 版本:4.2 Canary 15 或更高版本Gradle 版本:7.0.0-beta02 或更高版本Android 插件版本:4.2.0-beta15 或更高版本Kotlin 版本…...

stable-diffusion安装和简单测试
参考: https://github.com/CompVis/stable-diffusion 理解DALLE 2, Stable Diffusion和 Midjourney的工作原理 Latent Diffusion Models论文解读 【生成式AI】淺談圖像生成模型 Diffusion Model 原理 【生成式AI】Stable Diffusion、DALL-E、Imagen 背後…...
(附MATLAB代码实现))
MATLAB算法实战应用案例精讲-【智能优化算法】 基于帕累托包络的选择算法II(PESA-II)(附MATLAB代码实现)
目录 前言 知识储备 数据包络分析(DEA) 特点 名词解释 类型介绍 案例简介 软件操作(SPSSPRO)...

【华为机试真题详解JAVA实现】—坐标移动
目录 一、题目描述 二、解题代码 一、题目描述 开发一个坐标计算工具, A表示向左移动,D表示向右移动,W表示向上移动,S表示向下移动。从(0,0)点开始移动,从输入字符串里面读取一些坐标,并将最终输入结果输出到输出文件里面。 输入: 合法坐标为A(或者D或者W或者S) +…...

技术竞赛之道:从创新构想到落地执行的实战心法
技术竞赛之道:从创新构想到落地执行的实战心法 【免费下载链接】A-to-Z-Resources-for-Students ✅ Curated list of resources for college students 项目地址: https://gitcode.com/GitHub_Trending/at/A-to-Z-Resources-for-Students 在当今技术驱动的时…...

影刀经验库共建:5个岗位提效的RPA模板分享
影刀RPA岗位提效模板分享影刀RPA(机器人流程自动化)能够显著提升企业运营效率,尤其在重复性高、规则明确的任务中表现突出。以下是5个适用于不同岗位的RPA模板,帮助团队快速实现自动化提效。财务岗位:自动化发票处理通…...

AI做表工具三强对决:Excel-Agent、ChatExcel、Excel 原生 Agent,谁才是职场数据处理真王者?
当 AI 遇上 Excel,传统制表、数据清洗、复杂分析的低效困局被彻底打破。当前市场上,Excel-Agent、ChatExcel、Excel 原生 Agent 模式 是 AI 表格领域的三大主流选择,但三者在技术逻辑、使用体验、数据安全、实战效能上差异显著。作为专为 Exc…...

科哥Image-to-Video镜像实战:从零开始制作你的第一个AI视频
科哥Image-to-Video镜像实战:从零开始制作你的第一个AI视频 1. 前言:为什么选择科哥的Image-to-Video镜像? 想象一下,你有一张美丽的风景照片,如果能把它变成一段生动的视频该有多好?这就是Image-to-Vide…...

网盘直链解析技术指南:突破下载限制的高效解决方案
网盘直链解析技术指南:突破下载限制的高效解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自用,去推广…...

OrangePi 镜像烧录全攻略:从工具选择到实战避坑
1. 烧录工具选择与对比 第一次接触OrangePi开发板时,最让我头疼的就是镜像烧录工具的选择。市面上工具五花八门,每个教程推荐的软件都不一样。经过多次实测,我总结出三款最靠谱的烧录工具,它们各有特点: Win32DiskImag…...

设计师不用写代码了?实测TRAE SOLO Builder如何将Figma稿秒变可交互网页
设计师如何用TRAE SOLO Builder实现零代码网页开发 在数字产品设计领域,设计师与开发者之间的协作断层长期存在。设计精美的Figma稿转化为实际网页时,往往面临还原度不足、交互细节丢失等问题。TRAE SOLO Builder的出现,正在重新定义设计到开…...

从HPA到DepMap:手把手教你用蛋白质和细胞系数据,为你的单基因故事补充关键实验证据
从HPA到DepMap:数据驱动的单基因研究实验设计指南 当你在实验室里凝视着那个刚刚从测序数据中脱颖而出的候选基因时,是否曾为如何设计后续验证实验而犹豫不决?现代生物学研究早已告别了"试错式"的实验盲选时代。本文将带你系统掌握…...

Matlab Simulink代码生成全流程解析
matlab simulink代码生成 包括:环境配置,参数与信号配置,函数名配置,数据管理,代码生成,以及代码优化等 文档63页在工程领域,利用Matlab Simulink进行代码生成是一项极为实用的技能,…...

AI 模型推理引擎性能比较
AI模型推理引擎性能比较:解锁高效计算的秘密 在人工智能技术快速发展的今天,AI模型推理引擎的性能直接决定了实际应用的效率和成本。无论是云端服务还是边缘设备,选择一款高效的推理引擎可以大幅提升响应速度、降低资源消耗。本文将从计算速…...