爬虫:栖落的电影网站,利用requests和re模块
这是栖落的电影网站地址:https://xxx.xxx
进入网页,显示:
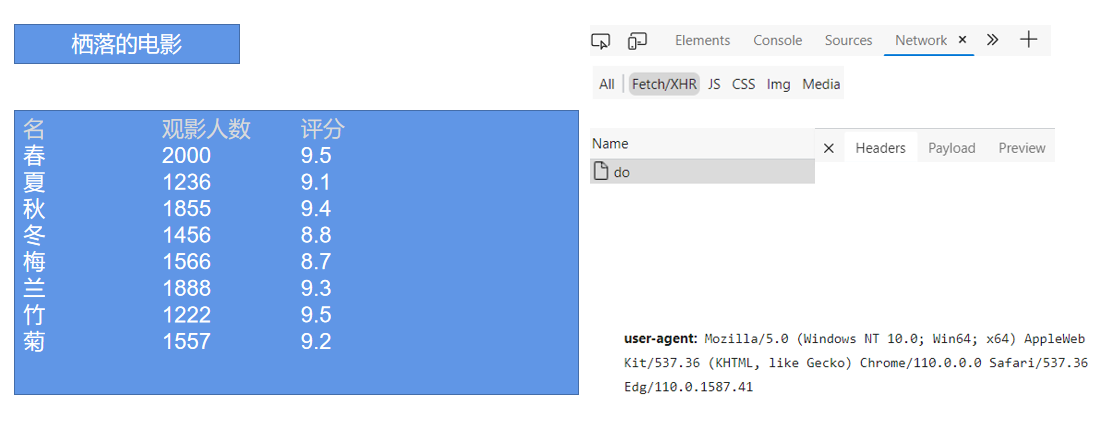
爬取目标:电影的名称、观影人数和评分。
易知本网站的url
url = "https://xxx.xxx"
本网站会识别出headers中的python请求而拒绝访问,所以需要更改headers当中的信息
user-agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/11.0.1587.41
对应的代码为:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/11.0.1587.41"
}
选中目标
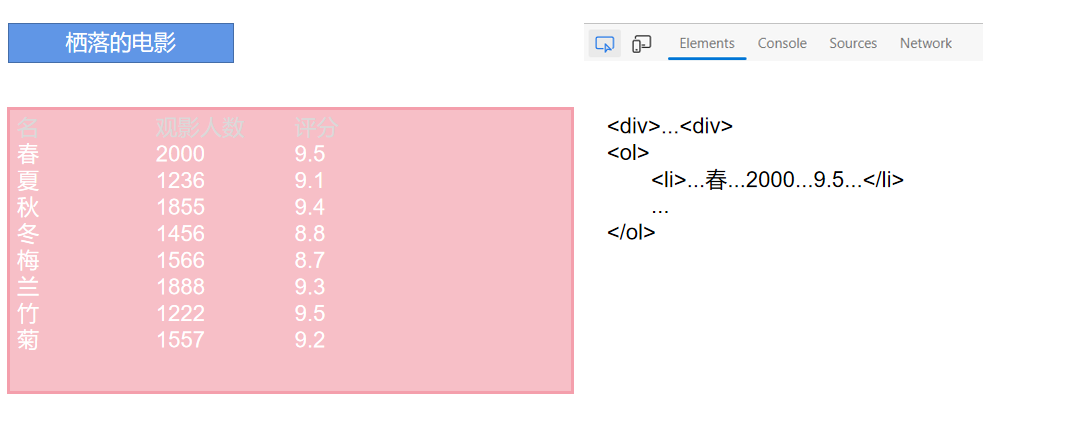
利用正则表达式匹配相应的信息。
obj = re.compile(r'<li>.*?标志1.*?标志2.*?标志1.*?标志2.*?标志1.*?标志2.*?</li>',re.S)
红色的.*?匹配需要的信息,其余的过滤掉多余的信息,各个标志为.*?的左右端的关键信息,r为requests模块返回的text文本。
并且我们需要为匹配的信息赋予相应的意义,即名、观影人数和评分。
利用(?<别名>)
obj = re.compile(r'<li>.*?标志1(?P<name>.*?)标志2.*?标志1(?P<num>.*?)标志2.*?标志1<?P<score>.*?)标志2.*?</li>',re.S)
把匹配的对象放入list中以便遍历。
result = obj.finditer(r)
遍历且以一定格式输出。
for it in result:
print("{:<10s}{:<5s{<5s}".format(it.group("name"),it.group("num"),it.group("score")))
参考代码:
import requests
import re#获取页面信息
url = "https://xxx.xxx"
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/11.0.1587.41"
}
r = requests.get(url,headers=headers)
r = r.text
#print(r)
#解析页面
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<br>(?P<num>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</li>',re.S)
#匹配
result = obj.finditer(r)
#输出
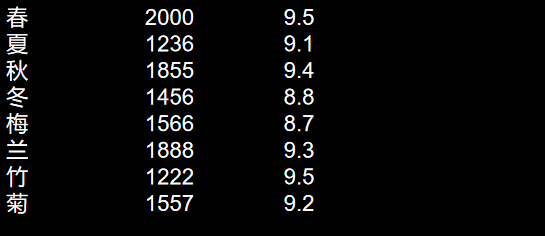
for it in result:print("{:<10s}{:<5s{<5s}".format(it.group("name"),it.group("num"),it.group("score")))输出结果:
小结:
如何爬取本站?
- 确定url
- 更改headers
- 请求页面信息
- 正则匹配
- 输出
提问 :
re.compile是啥?
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象。
语法格式如下:re.compile(pattern,[flags])
参数:
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I :忽略大小写
- re.L :表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M :多行模式
- re.S :即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U :表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X :为了增加可读性,忽略空格和 # 后面的注释
finditer是啥?
finditer 返回一个可迭代对象
相关文章:
爬虫:栖落的电影网站,利用requests和re模块
这是栖落的电影网站地址:https://xxx.xxx 进入网页,显示: 爬取目标:电影的名称、观影人数和评分。 易知本网站的url url "https://xxx.xxx" 本网站会识别出headers中的python请求而拒绝访问,所以需要更改…...

使用burpsuite抓包 + sql工具注入 dvwa靶场
使用burpsuite抓包 sql工具注入 dvwa靶场 记录一下自己重新开始学习web安全之路②。 一、准备工作 1.工具准备 sqlmap burpsuite 2.浏览器准备 火狐浏览器 设置代理。 首先,先设置一下火狐浏览器的代理 http代理地址为127.0.0.0.1 ,端口为8080 …...
树与图中的dfs和bfs—— AcWing 846. 树的重心 AcWing 847. 图中点的层次
一、AcWing 846. 树的重心1.1题目1.2思路分析题意:什么是树的重心?树的重心是指,删除某个结点后剩下的最大连通子树的结点数目最小,如下图是根据样列生成的树,若删除结点1,则剩下三个子树最大的是中间那颗结…...

从零开始学数据分析之数据分析概述
当今世界对信息技术的依赖程度在不断加深,每天都会有大量的数据产生,我们经常会感到数据越来越多,但是要从中发现有价值的信息却越来越难。 这里所说的信息,可以理解为对数据集处理之后的结果,是从数据集中提炼出的可…...

十五载厚积薄发,电信级分布式数据库是这样炼成
所在论坛:数据库技术创新&云原生论坛 分享时段:2.18 10:00-10:30 分享主题:大规模并行处理:AntDB分布式演进之路 分享嘉宾:沈夺,亚信科技AntDB数据库内核开发工程师 由中国开源软件推进联盟Postgre…...

Centos调整分区存储大小
将/home下900G转移到/目录下 1、查看分区大小:df -hl 2、备份home文件:tar cvf /run/home.tar /home 3、终止home文件进程(切换到非home路径下执行这个命令):fuser -km /home 3.1、如果没有fuser,在线安装…...
)
华为OD机试真题JAVA实现【单词接龙】真题+解题思路+代码(20222023)
华为OD机试真题JAVA实现【单词接龙】真题+解题思路+代码(2022&2023) 🔥系列专栏 华为OD机试(JAVA)真题目录汇总华为OD机试(Python)真题目录汇总华为OD机试(C++)真题目录汇总华为OD机试(JavaScript)真题目录汇总文章目录 🔥系列专栏题目输入输出示例一输入输…...

Mapbox Style 规范
Mapbox致力于打造全球最漂亮的个性化地图。 中文官网经常打不开所以做下记录,方便查阅。 Web 端 API Mapbox GL JS 的地图样式规范 Style 的各个配置项: (必填项会加上 * ,方便根据目录进行查看) 配置项:1.…...
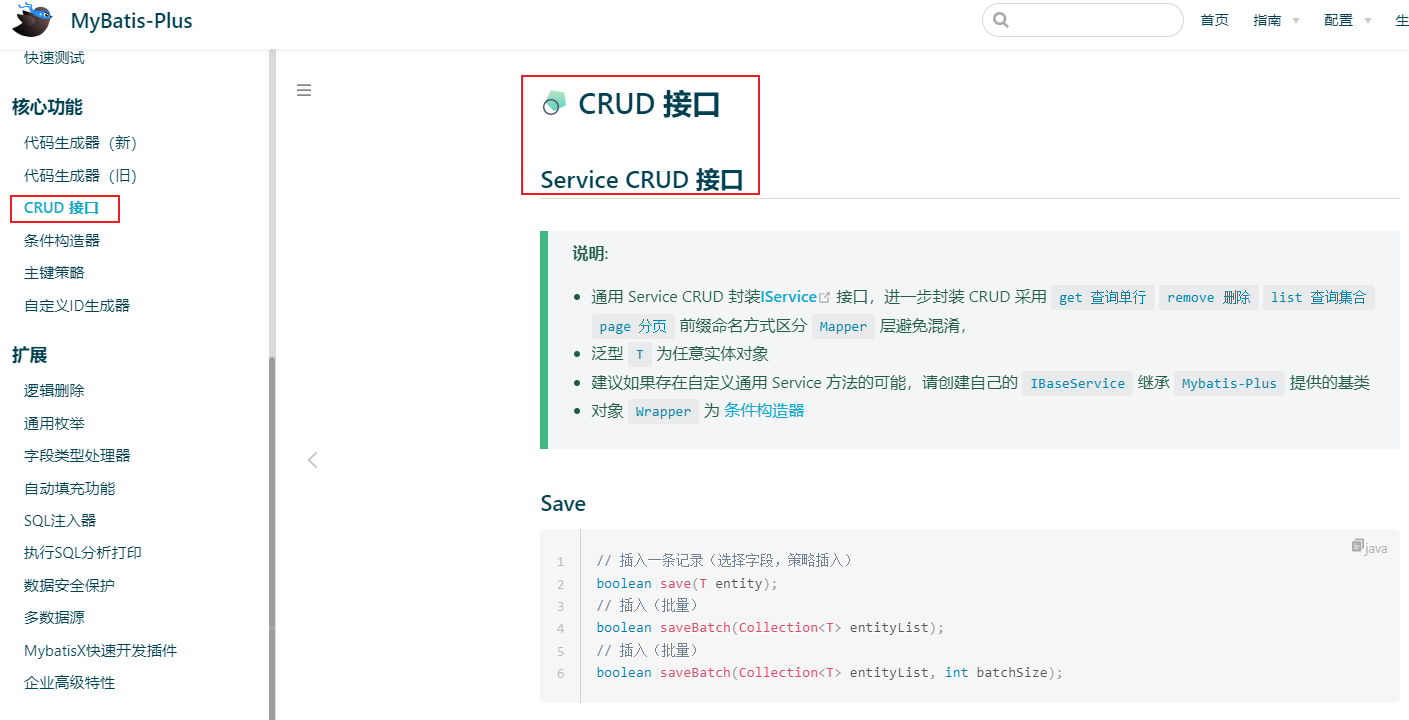
Java开发学习(五十)----MyBatisPlus快速开发之代码生成器解析
1、代码生成器原理分析 造句: 我们可以往空白内容进行填词造句,比如: 在比如: 观察我们之前写的代码,会发现其中也会有很多重复内容,比如: 那我们就想,如果我想做一个Book模块的开发,是不是只需要将红色部分的内容全部…...
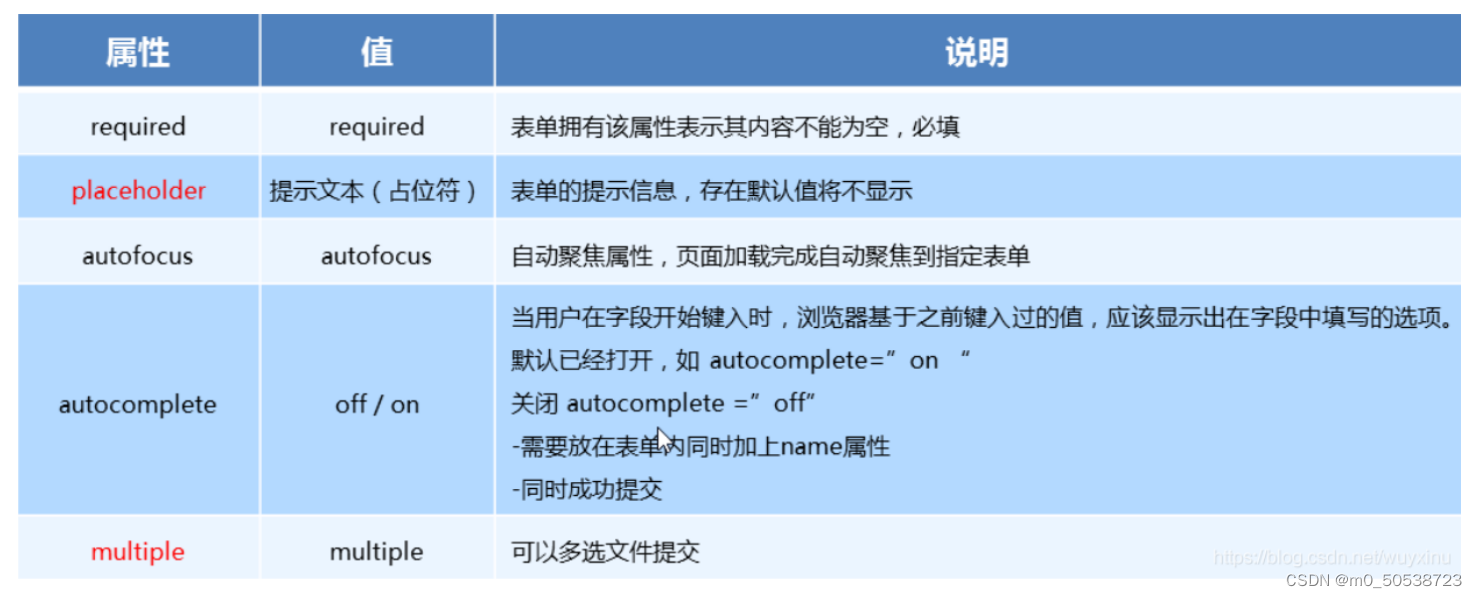
HTML学习
文章目录基础知识什么是HTMLW3C标准在IDEA中创建一个html文件HTML的基本结构网页基本信息网页的基本标签图像标签链接标签文本链接图片链接图片格式锚链接功能性链接其他基本标签块元素和行内元素标签对照表列表HTML3种列表有序列表无序列表定义列表HTML学习中的误区表格标签基…...

Java最新学习路线
Java语言是目前流行的互联网等企业的开发语言,是市面上很多程序员喜欢并且在用的程序设计语言。关于学习java,有一部分人是为了就业或自己创业,而大多数人是希望使用java这个开发语言用来工作,开发出计算机后端系统,利…...
腾讯xSRC[linux+docker]搭建教程
腾讯xSRC[linuxdocker]搭建教程 1.下载镜像 docker pull xsrc/xsrc:v1.0.12.启动镜像 1️⃣启动镜像 docker run -it -d --name xsrc_web -p 60080:80 -p 63306:3306 --privilegedtrue xsrc/xsrc:v1.0.1注意将3306端口映射到8806端口,以便于远程连接访问容器内数…...
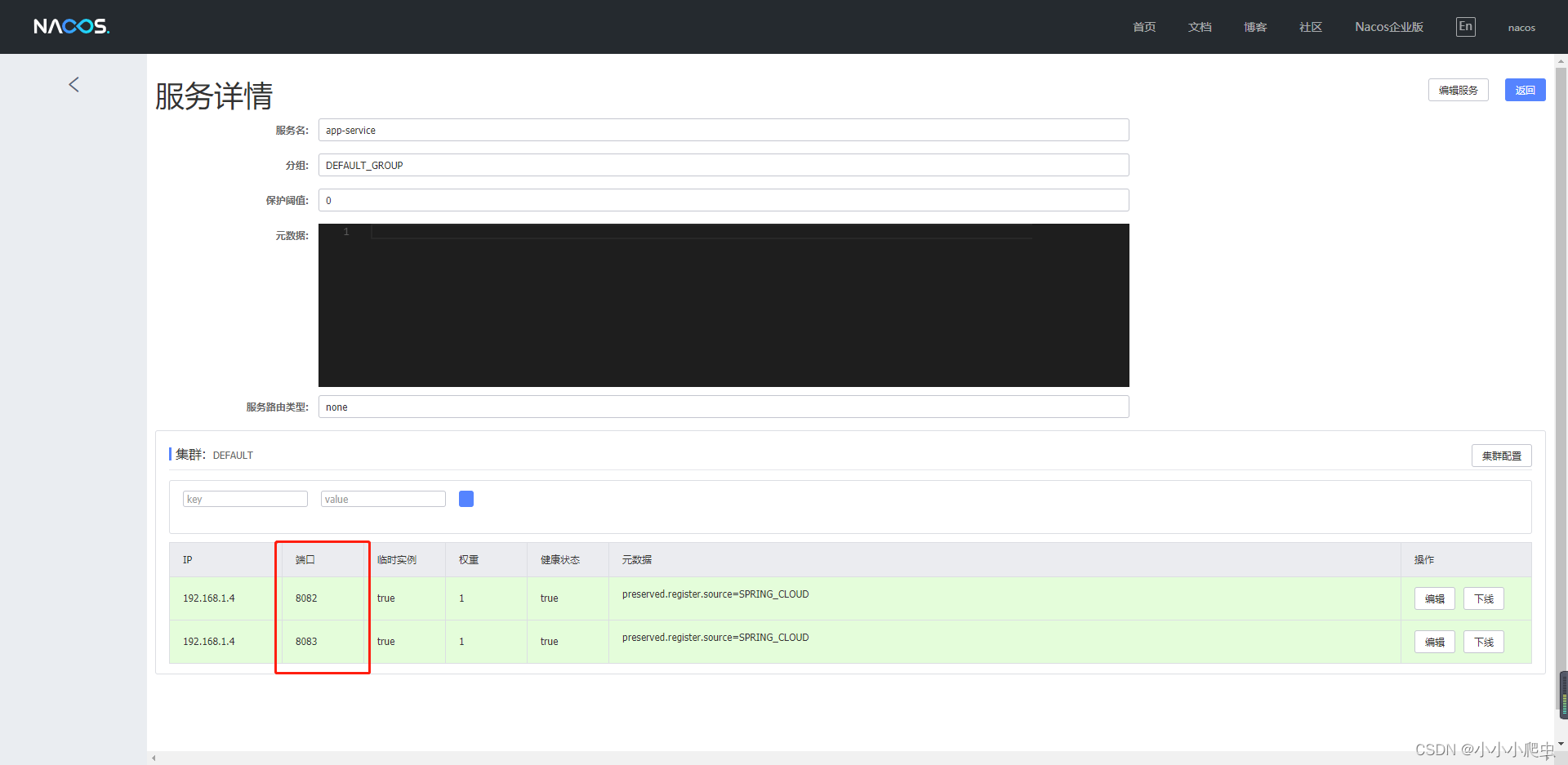
springcloud - 2021.0.3版本 - (一)服务注册nacos+feign
一,注册中心 最新版使用的是nacos,可替换为eureka,zookeeper,使用方式大同小异,这里不做扩展。 下载安装:(有机会重装时再补上) 管理页面:http://localhost:8848/naco…...
)
C++教程(初级,有基础)
C教程(初级,有基础) #include <iostream> using namespace std; int main() { /*对应printf("")*/cout << "Hello, world!" << endl;//cout << "Hello, world!" << "\n&q…...

字符编码及转换
什么是字符编码字符编码(Character encoding)也称字集码,是把字符集中的字符,编码为指定集合中的某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储或者…...
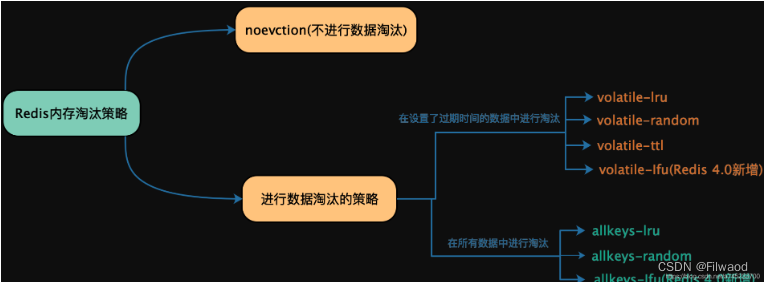
redis原理
文章目录一、Redis数据结构1.1.动态字符串SDS1.2 intset1.3 Dict1.4 ZipList1.5 QuickList1.6 SkipList1.7 RedisObject二、Redis五大基本数据类型底层2.1.String2.2.List2.3.Set2.4.ZSet2.4.Hash三、Redis网络模型3.1.用户空间和内核空间3.2.阻塞IO3.3.非阻塞IO3.4.IO多路复用…...
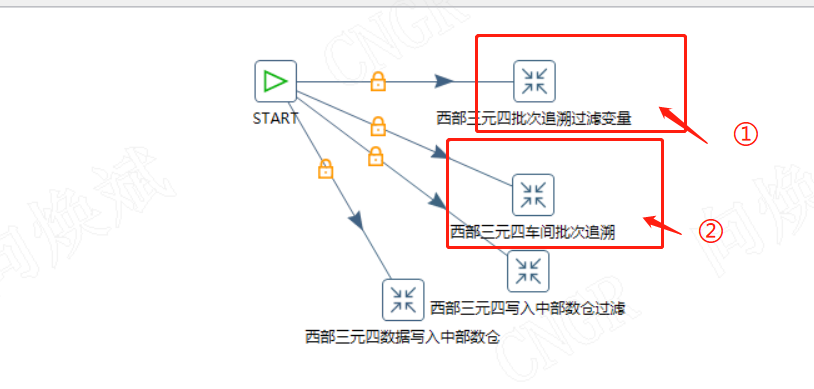
kettle开发-Day37-SQ索引优化
前言:在上一个生产项目中,有个单表数据超249G了,里面存储的数据时间跨度就1年左右,那为啥会出现这种情况呢?数据来源为,一个生产基地所有电表的每分钟读数,一个基地大概500个电表左右࿰…...

【camera之3a】AE
文章目录sensorAEsensor 分辨率 常见分辨率的感性表述即30万、100万、200万,正确表述应为0.3M、1M、2M,其中M代表百万,是像素单位。sensor分辨率即指在单位面积上,像素的个数,数值越大 ,则代表像素点越多&…...

Docker-Consul概述以及集群环境搭建
一、Docker consul概述容器服务更新与发现:先发现再更新,发现的是后端节点上容器的变化(registrator),更新的是nginx配置文件(agent)egistrator:是consul安插在docker容器里的眼线&a…...
性能技术分享|Jmeter+InfluxDB+Grafana搭建性能平台(四)
四、Jmeter配置InfluxDB4.1 后端监听器(BackendListener)介绍1、什么是后端监听器(BackendListener)?源码给出的解释是:BackendListener是一种异步监听并获取到测试结果的实现类。也就是说发出的如http等响应请求的结果,都会被封装在SampleRe…...

某恶意软件样本逆向分析报告
1.概述样本来源:微步在线恶意软件名称:刘文博-关于北京体彩中心的问题反馈.exesha256:c28d23d8658abc1f5683c6b50239d5593eb7a274a3abec56124d7fb43fec1b642.行为分析该程序图标设为word文档图标,实际为exe文件,诱骗受…...

LabVIEW循环进阶:隧道模式与移位寄存器的实战解析
1. LabVIEW循环基础回顾与隧道模式初探 在LabVIEW编程中,For循环是最基础也是最常用的结构之一。很多初学者都能轻松掌握循环次数N和循环索引i的基本用法,但当涉及到数据进出循环时的处理方式,往往会遇到困惑。这就是我们今天要重点讨论的隧…...

Linux小白避坑指南:Resilio Sync安装后权限配置与Web界面访问失败的常见问题解决
Linux权限迷宫:Resilio Sync安装后的深度避坑实战 当8888端口沉默时:一次真实的故障排查记录 上周五晚上11点,我正准备将团队的设计素材库同步到本地开发环境。按照官方文档,我在Ubuntu 22.04上顺利安装了Resilio Sync,…...

终极Windows激活解决方案:3分钟永久激活Windows和Office的完整指南
终极Windows激活解决方案:3分钟永久激活Windows和Office的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经遇到过这样的场景:新安装的Windows系统弹出…...

【最新v2.7.1 版本安装包】OpenClaw 新手部署全攻略,无需命令零代码一键安装保姆级
Windows 一键部署 OpenClaw 教程|5 分钟搞定本地 AI 智能体,告别复杂配置 核心亮点 零代码门槛|全程可视化|无需手动配置运行环境|内置全部运行依赖|28 万 Tokens 额度 前言 2026 年开源圈热度居高不下…...

怎样高效管理微信社交网络:5个微信工具箱实用技巧完整指南
怎样高效管理微信社交网络:5个微信工具箱实用技巧完整指南 【免费下载链接】wechat-toolbox WeChat toolbox(微信工具箱) 项目地址: https://gitcode.com/gh_mirrors/we/wechat-toolbox 微信工具箱(wechat-toolbox…...
:当TTS调用量突破500万/月,这3个架构断层将触发收入增长断崖)
ElevenLabs商业规模化陷阱(内部白皮书节选):当TTS调用量突破500万/月,这3个架构断层将触发收入增长断崖
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs Growing Business ElevenLabs 已从语音合成初创公司快速演进为全球 AI 语音基础设施的关键提供者,其业务增长体现在 API 调用量年增超 320%、企业客户数突破 12,000 家ÿ…...

EMAC寄存器配置与网络性能优化实战
1. EMAC寄存器概述与核心功能以太网媒体访问控制器(EMAC)是现代嵌入式系统中实现网络通信的核心硬件模块,其寄存器配置直接决定了数据传输的可靠性、实时性和效率。作为硬件与协议栈之间的桥梁,EMAC通过精心设计的寄存器组实现了对…...
)
基于微信小程序的家政服务预约系统(30291)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

Armv8/v9架构中的A64系统指令与预测限制机制详解
1. A64系统指令概述在Armv8/v9架构中,A64系统指令(System Instructions)是处理器特权级别操作的核心机制。这些指令运行在EL1及以上异常级别,用于控制系统寄存器、内存管理单元、虚拟化扩展和安全状态等关键功能。与常规数据处理指令不同,系统…...