kettle开发-Day37-SQ索引优化
前言:
在上一个生产项目中,有个单表数据超249G了,里面存储的数据时间跨度就1年左右,那为啥会出现这种情况呢?数据来源为,一个生产基地所有电表的每分钟读数,一个基地大概500个电表左右,然后乘以1天24小时,一天1440分钟,一年365天,所以就出现了前面说的单表超249G的情况。真的是单表顶10库。因业务部门想看到每个时间点的电耗来安排排产,虽然当时满足了业务需求,但随着时间的推移对应数据量是越来越大,前端查询和后端数据抽取的耗时越来越大,因此怎么让如果大表实现快速的数据分析和数据处理呢?更换非关系型数据库?分表分库?
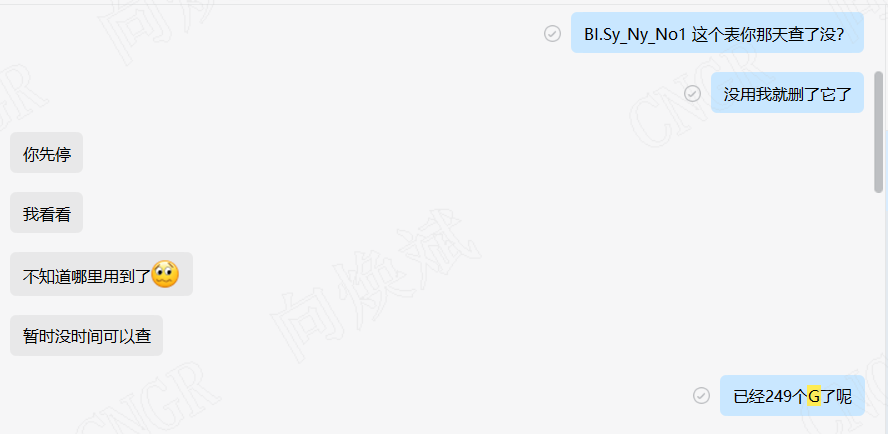
十二亿七千六百零四万三千五百三十五数据量
一、亿级数据处理
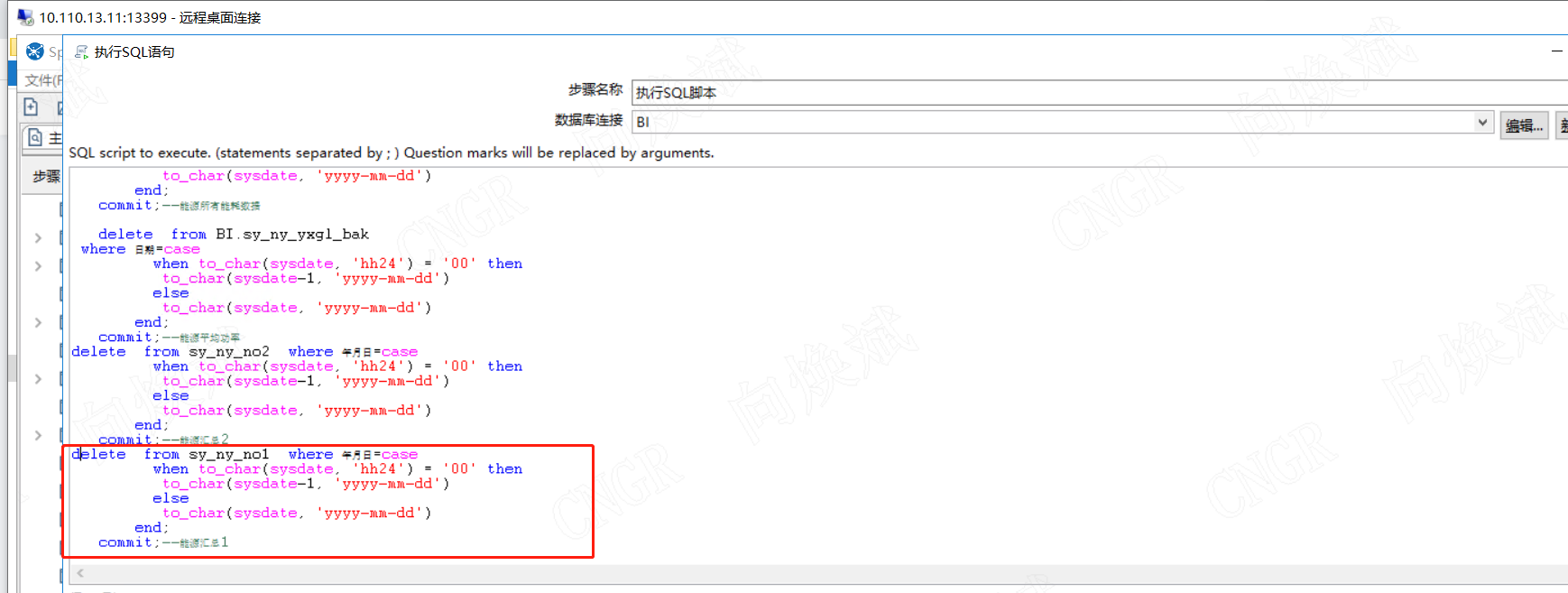
如上图所示,目前数据量已经是13亿左右,因此此时我们进行数据删除、更新、排序、分组等耗时会比较长。但我们看电耗都是默认看最新的读数,因此我们必然需要用到排序操作,因此怎么在0.1s内完成亿级的数据排序呢?同样的我们知道在kettle做数据抽取时,我们经常更新当日数据时,会进行先delete后insert的操作,如我们更新2023年2月13日16点的数据,我们需先删除2023年2月13日0点至16点的当天数据,再插入2023年2月13日的数据。(这是网上经典的kettle数据处理方案)。但是实际情况下,我们删除带条件的亿级数据时耗时最小在10分钟以上。再包括插入数据的时间,我们至少要10分钟才能完成一个表的数据处理,这在实际应用情况下,是必然不能接受的,因为业务需要看到1分钟的数据变化,因此我们需要将作业执行的耗时控制在1分钟之内,并且在前端数据分析展现速度控制在3秒以内,因为用户的耐心阀值为3秒。
二、方案与效果对比
下面我们分析最常用的三种kettle数据处理方案,并进行方案对比。
方案 | 效果分析 | 应用场景 |
插入更新 | 无删除、不影响前端展现、耗时长 | 需有标准主键,每次更新数据量在5千行内。 |
先delete后insert | 目标表数据在100万行内,不影响前端展现,效率是插入更新的100倍以上 | 每次更新数据量在1-10万行内,目标表总数据量在100万行内。 |
插入变量范围数据 | 开发相对复杂、基本在2s内可完成作业,只需读取源表数据耗时,插入更新基本无耗时 | 适合有明确主键的场景,适合任何场景,但需在源表做好规范,源表有对应主键或者联合主键。 |
2.1原因分析
kettle的工作原理是定时处理数据流,数据是以数据流的形式在kettle作业中执行,数据流耗时主要表现在源表读取耗时、分组、求和等计算耗时、update、delete、insert数据库耗时。插入耗时最短、其次为查询耗时,因采用数据流的形式,当将批量的数据保存至数据流中时,可在零点几秒内完成亿万级数据插入。因此想达到效率最大化,我们在数据处理时只采用插入操作。
2.2案例分析
我们进行数据处理时,需要的不仅仅是速度快,而且需要精准。因此我们怎么避免冗余的数据呢?特别是在亿万级数据时,快速定位需要删除的数据。因此此时我们需要做的是,找出有规律的主键,如时间,如我们源数据库中,数据已更新至2023年2月13日15:56:45时,现在时间是2023年2月13日18:07:32因此从数据分析的角度分析,我们只需更新2023年2月13日15:56:45至2023年2月13日18:07:32的数据即可。因此我们需快速定位至2023年2月13日15:56:45的主键,然后在插入数据时,查询大于2023年2月13日15:56:45主键的数据即可完成我们的目的了。
2.3步骤分解
从上面可知,我们需要做两步操作:
1、第一步是快速找出2023年2月13日15:56:45的主键(读目标表)
2、插入2023年2月13日15:56:45至现在(2023年2月13日18:07:32)的数据
因此我们在读取最新主键时耗时需可知在0.1内,插入数据耗时控制在2s内,这样我们就可以将整个数据处理耗时控制在3秒内,并不影响前端展现,且数据精确。
2.4实现思路
从前面可知,我们一直在强调快速和定位,因此此时让我们想到了数据库一个常用功能就是索引。因为索引就是为了快速和定位而生。因此我们只需要在我们查询和过滤的字段上加上索引,我们就可以在0.1s内完成数据的快速定位。

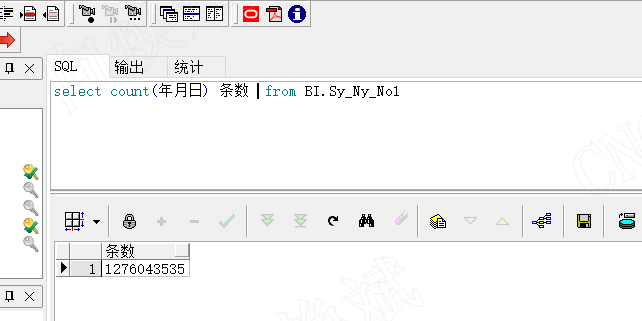
为了方便大家的理解,我在上面的13亿数据表中,增加了年月日的字段索引,看我们查找出最大的年月日需要多少耗时,对应增加索引的语句为,create index seq_name on table (column_name)。如增加BI.SY_NY_NO1表索引语句为create index seq_SY_NY_NO1 on BI.SY_NY_NO1(年月日)。

如上图所示我们查询出最新的年月日只需用了0.052秒,稳稳控制在0.1s内,如果我没告诉你它数据量在13亿,你肯定觉得它数据量在1万以内,这就是索引带来的改变。
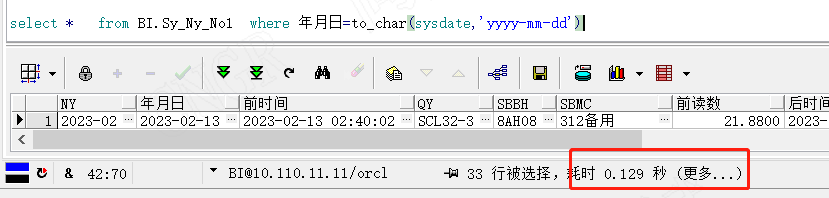
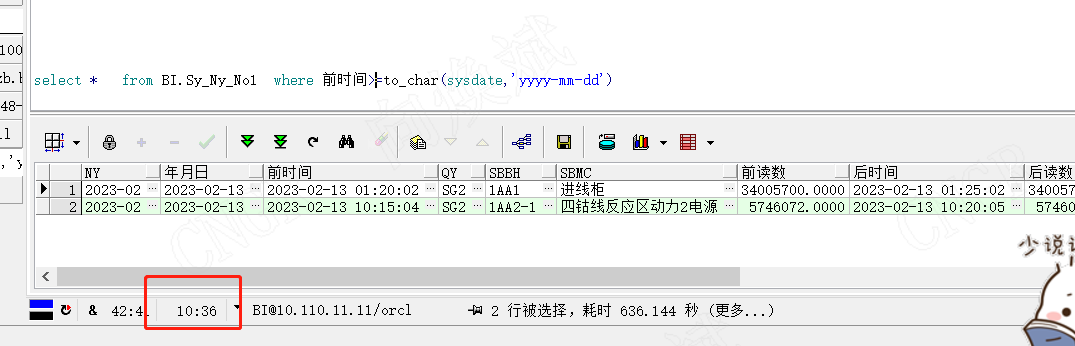
同样我们在0.1秒左右完成了最新数据的过滤,这就是索引带来的改变,当然为了区分效果我们使用另外一个不带索引的字段来过滤看下效果。如下图所示使用了10分36秒才过滤出我们需要的数据。对应效率提高(10x60+36)/0.129=3069倍。
三、实际应用
从上面我们了解到,索引可以快速提高查询效率,因此我们在数据分析、数据抽取的时候怎么灵活应用索引呢?
3.1数据分析应用
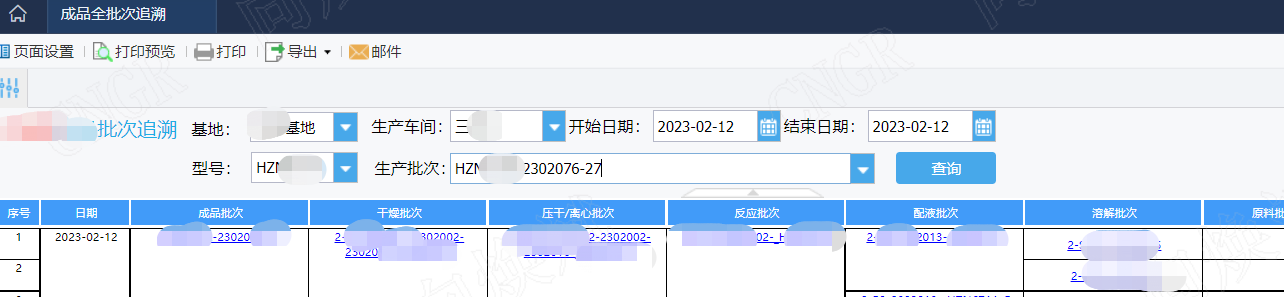
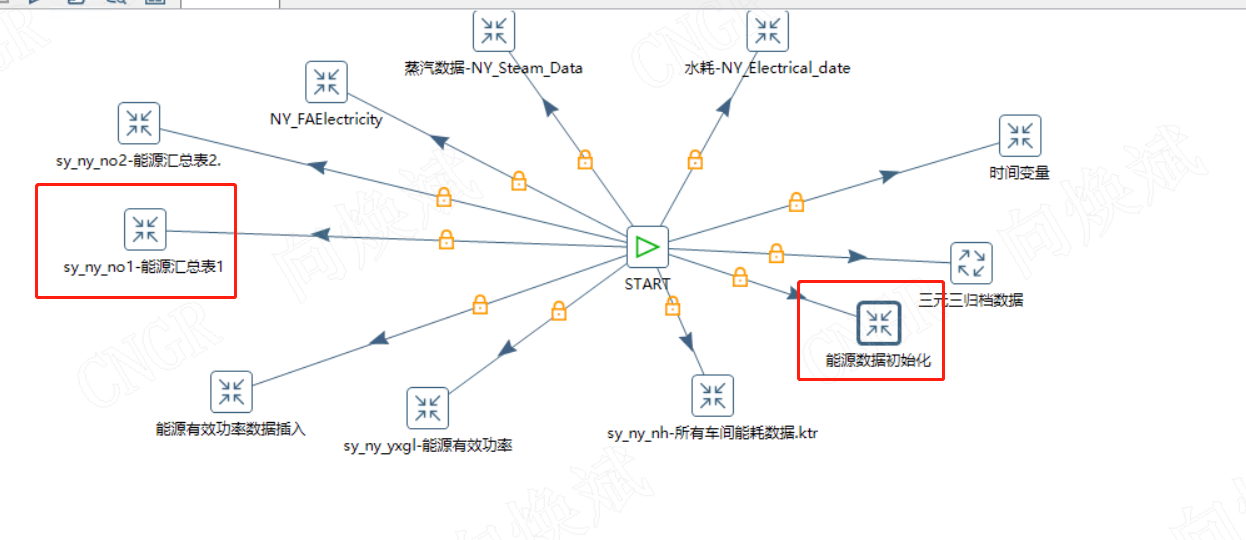
如我们在做生产的批次追溯时,我们需要查看整个过程任何时间段的批次的数据追溯,从前端展现来看,对应涉及的字段较多,涉及的展现逻辑较复杂,那我们怎么在最短的时间(3S)内完成数据分析呢?因此我们在前端的控件加载耗时控制在1秒内,因对应的生产批次需根据前面的基地、车间、日期、型号进行过滤,因此我们需增加基地、车间、日期、型号的索引,对应展示的明细表需根据基地、车间、日期、型号、批次进行过滤,因此此时我们需增加基地、车间、日期、型号、批次的索引。。不难发现我们为了完成这个需求,我们需要增加很多索引组,这就是为什么前面那个亿万级表通过年月日查询很快,但通过另外一个字段查询就大打折扣的原因,因此,此时我们需根据需求进行联合索引的创建来大大提高展现效率。如下图所示在表中增加了三组索引,这样在前端展现就能在3s内完成任一时间的数据分析了。

3.2数据抽取应用
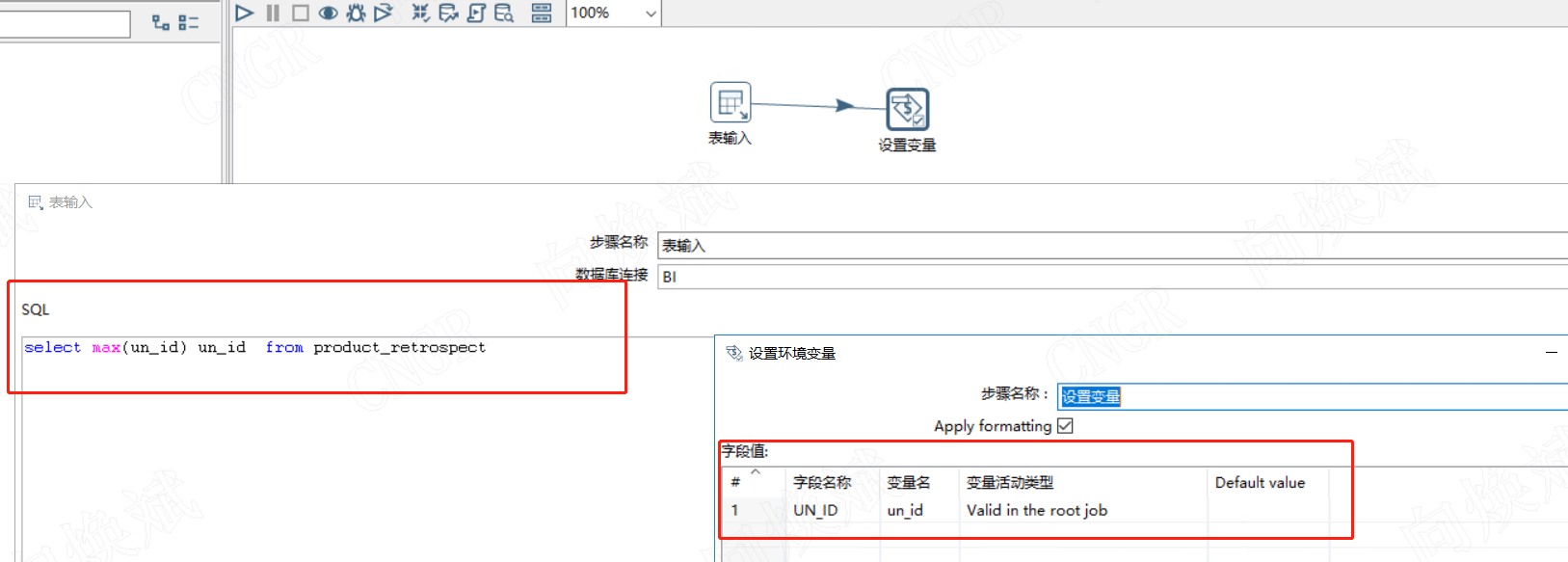
基本思路在前面已经阐述,对应获取最新主键,然后插入过滤对应主键即可。

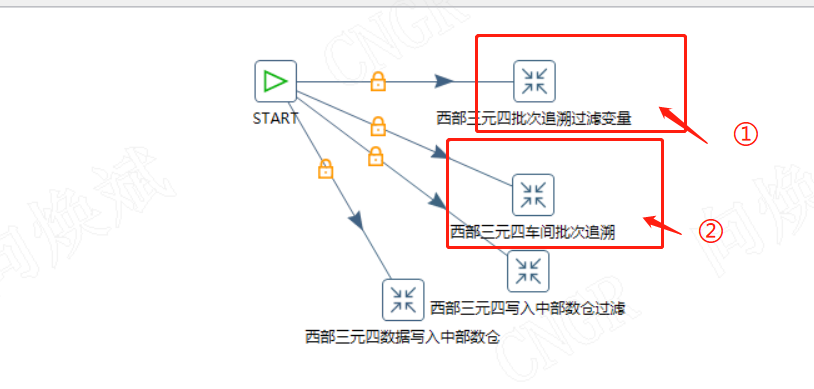
对应作业为下图所示,通过变量过滤,再执行数据插入即可。
相关文章:
kettle开发-Day37-SQ索引优化
前言:在上一个生产项目中,有个单表数据超249G了,里面存储的数据时间跨度就1年左右,那为啥会出现这种情况呢?数据来源为,一个生产基地所有电表的每分钟读数,一个基地大概500个电表左右࿰…...

【camera之3a】AE
文章目录sensorAEsensor 分辨率 常见分辨率的感性表述即30万、100万、200万,正确表述应为0.3M、1M、2M,其中M代表百万,是像素单位。sensor分辨率即指在单位面积上,像素的个数,数值越大 ,则代表像素点越多&…...

Docker-Consul概述以及集群环境搭建
一、Docker consul概述容器服务更新与发现:先发现再更新,发现的是后端节点上容器的变化(registrator),更新的是nginx配置文件(agent)egistrator:是consul安插在docker容器里的眼线&a…...
性能技术分享|Jmeter+InfluxDB+Grafana搭建性能平台(四)
四、Jmeter配置InfluxDB4.1 后端监听器(BackendListener)介绍1、什么是后端监听器(BackendListener)?源码给出的解释是:BackendListener是一种异步监听并获取到测试结果的实现类。也就是说发出的如http等响应请求的结果,都会被封装在SampleRe…...
图数据建模基础
Neo4j 图的组件 节点(Nodes)标签(Labels)关系(Relationships)属性(Properties)建模过程 了解领域并为应用程序定义特定用例(问题)。开发初始图形数据模型。 对…...

nodejs篇 process模块
目录 前言 监听回调 beforeExit 、exit、uncaughtException beforeExit exit uncaughtException Process常用属性 stdout stdin process方法 process.cwd(),process.chdir() process.nextTick() process.exit() process.kill() 前言 process是nodejs提…...

JavaScript高级程序设计读书分享之3章——3.4数据类型
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 ECMAScript 有 6 种简单数据类型(也称为原始类型):Undefined、Null、Boolean、Number、String 和 Symbol(es6新增)。 还有一种复杂数据类型叫…...
棱形打印--进阶2(Java)
棱形打印 问题 * *** ***** ******* ********* ******* ***** *** * * * …...

清除 git 所有历史提交记录,使其为新库
清除 git 所有历史提交记录,使其为新库需求方案需求 基于以前的仓库重新开发,这样可保留以前的配置等文件,但是需要删除全部的历史记录、tag、分支等。 方案 创建新的分支 使用 --orphan 选项,可创建1个干净的分支(无…...

pyTorch下载和cuda下载以及学习笔记
pytorch官方网站,cuda官方网站 CUDA下载:https://developer.nvidia.com/cuda-toolkit-archive CUDNN下载:https://developer.nvidia.com/rdp/cudnn-download pytorch下载:pytorch.org 任务管理器中只显示CUDA占用的专用内存&#…...

【学习总结】IMU预积分推导
本文仅用于记录自己学习总结。记录IMU预积分推导过程,不包含具体原理。 符号表示 RRR: 表示旋转矩阵 vvv: 表示速度 ppp: 表示位移 ExpExpExp: 指数映射,将旋转向量映射为旋转矩阵 w~\widetilde{w}w: 角速度观测值 f~\widetilde{f}f: 加速度观测值 bg…...

天猫商城自动化python脚本(仅供初学者学习使用)
作者:Eason_LYC 悲观者预言失败,十言九中。 乐观者创造奇迹,一次即可。 一个人的价值,在于他所拥有的。可以不学无术,但不能一无所有! 技术领域:WEB安全、网络攻防 关注WEB安全、网络攻防。我的…...
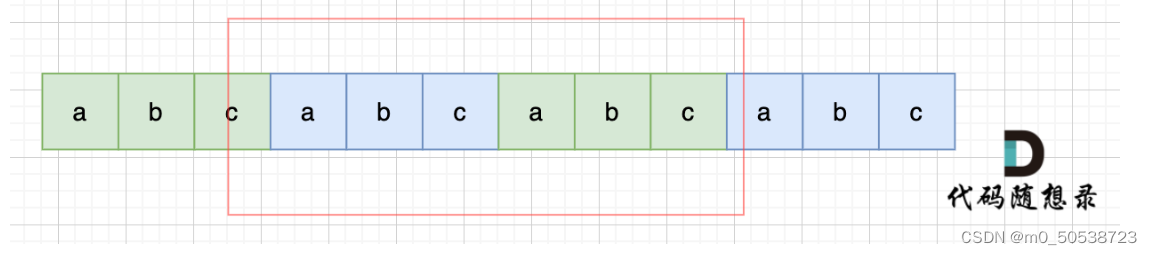
代码随想录第十一天(459)
文章目录459. 重复的子字符串答案思路暴力破解移动匹配459. 重复的子字符串 也不知道为啥这个提示简单题…… 答案思路 暴力破解 例如:abcabc 移位一次:cabcab 移位两次:bcabca 移位三次:abcabc 现在字符串和原字符串匹配了…...

线程及线程池学习
1 线程和进程的区别?进程:进程指正在运行的程序。线程:线程是进程中的一个执行单元,负责当前进程中程序的执行,一个进程中至少有一个线程。同一个进程中的多个线程之间可以并发的执行。2 创建线程有哪几种方式…...
整合Ehcache、Redis、Memcached、jetcache、j2cache缓存)
SpringBoot整合(四)整合Ehcache、Redis、Memcached、jetcache、j2cache缓存
企业级应用主要作用是信息处理,当需要读取数据时,由于受限于数据库的访问效率,导致整体系统性能偏低。 为了改善上述现象,开发者通常会在应用程序与数据库之间建立一种临时的数据存储机制,该区域中的数据在内存…...

想要的古风女生头像让你快速get
如今我看到很多人都喜欢用古风女生当作头像,那么今天我就来教大家如何快速得到一张超美的古风女生头像~ 上图就是我使用 APISpace 的 AI作画(图像生成)服务 快速生成的古风女生头像,不仅可以限定颜色,还可以选择『宝石镶嵌』或『花卉造型』这…...

传统企业数字化转型,到底难在哪里?
数字化转型过程中面临最大的挑战和问题是什么?这篇整理了企业在数字化转型过程中普遍面临的9大问题和挑战以及如何解决这些问题,希望能够对各位企业数字化转型有多启发和帮助。 01 企业数字化转型三大现状 在梳理企业数字化转型问题之前,我想…...
)
Python:青蛙跳杯子(BFS)
题目描述 X 星球的流行宠物是青蛙,一般有两种颜色:白色和黑色。 X 星球的居民喜欢把它们放在一排茶杯里,这样可以观察它们跳来跳去。 如下图,有一排杯子,左边的一个是空着的,右边的杯子,每个…...

6.10 谱分解
文章目录计算方法代码实现计算方法 单纯矩阵normal matrix指的是符号ATAAATA^TAAA^TATAAAT的矩阵,他们的特征值互异。此外,单纯矩阵还有个特点,他们的特征空间彼此正交。 对于单纯矩阵,存在以下的谱定理Spectral theorem&…...

MySQL入门篇-MySQL 行转列小结
备注:测试数据库版本为MySQL 8.0 需求:求emp表各个岗位的工资之和,如无,用0代替 如需要scott用户下建表及录入数据语句,可参考:scott建表及录入数据sql脚本 CASE语法 SELECT deptno,ifnull(sum(case when job MANAGER then sal else 0 …...

VINS-Mono在EUROC数据集上的实战评测:从轨迹精度到运行耗时,我的避坑心得
VINS-Mono在EUROC数据集上的实战评测:从轨迹精度到运行耗时,我的避坑心得 当第一次在无人机上部署VINS-Mono时,我盯着实时轨迹和地面真值之间逐渐拉大的偏差,意识到论文里的漂亮曲线背后藏着太多未言明的细节。这次评测源于一个实…...
)
用Python+CCA算法搞定SSVEP脑电信号识别:从理论到代码实战(附GitHub源码)
PythonCCA算法实现SSVEP脑电信号识别实战指南 在脑机接口研究领域,稳态视觉诱发电位(SSVEP)因其高信噪比和稳定特性成为热门研究方向。典型相关分析(CCA)作为SSVEP信号处理的经典算法,以其数学优雅和实现简…...

伺服电机控制模式全解析:位置、速度、扭矩模式到底怎么选?手把手配置教程
伺服电机控制模式深度实战指南:从原理到参数调优 在工业自动化领域,伺服系统的精准控制直接决定了设备性能的上限。面对位置控制(PT)、速度控制(S)、扭矩控制(T)以及混合模式这四种核心控制策略,许多工程师常陷入选择困境——不同模式对应着截…...

现代Web应用特性管理:从概念到工程实践
1. 项目概述:一个面向现代Web开发的特性管理工具 如果你和我一样,长期在Web应用开发的一线摸爬滚打,那你一定对“特性开关”这个概念不陌生。简单来说,它就像你家里电灯的总闸,可以随时控制某个功能是“亮”还是“灭”…...

西门子S7-1200 PLC编程避坑指南:从振荡电路到浮点数计算,新手最常犯的5个错误
西门子S7-1200 PLC编程实战避坑手册:从逻辑陷阱到数据精度 第一次接触西门子S7-1200 PLC编程时,我对着闪烁的指示灯发呆了半小时——明明按照手册写的梯形图,为什么定时器就是不工作?后来才发现是TON指令的PT参数单位理解错误。这…...
)
ZCU102开发板新手避坑:从官网下载MIG例程到LED闪烁的完整流程(Vivado 2023.1)
ZCU102开发板新手避坑:从官网下载MIG例程到LED闪烁的完整流程(Vivado 2023.1) 刚拿到ZCU102开发板时,那种既兴奋又忐忑的心情我至今记忆犹新。作为Xilinx旗下的高端FPGA开发平台,ZCU102强大的性能和丰富的接口让它成为…...

5分钟免费安装终极Markdown阅读器:浏览器最强文档查看解决方案
5分钟免费安装终极Markdown阅读器:浏览器最强文档查看解决方案 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展࿰…...
)
Unity实战:用RenderTexture和LineRenderer搞定3D物体擦除效果(附完整Shader代码)
Unity实战:用RenderTexture和LineRenderer实现高精度3D物体擦除效果 在游戏开发中,3D物体的动态擦除效果常被用于刮刮乐、迷雾探索、橡皮擦等交互场景。传统实现方式往往面临性能瓶颈或视觉效果不佳的问题。本文将深入探讨如何结合RenderTexture和LineRe…...

告别臃肿!Dell G15笔记本散热控制的轻量级开源替代方案
告别臃肿!Dell G15笔记本散热控制的轻量级开源替代方案 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 你是否厌倦了Dell原厂AWCC软件的缓慢响应和…...

Groops实战入门:从源码编译到首个PPP案例运行
1. 认识Groops:GNSS数据处理的神器 第一次听说Groops这个软件时,我和大多数GNSS新手一样一脸茫然。直到导师扔给我一堆GRACE卫星数据,要求做精密单点定位分析时,才真正开始接触这个工具。Groops全称是Gravity Recovery Object-Ori…...