字符编码及转换
什么是字符编码
字符编码(Character encoding)也称字集码,是把字符集中的字符,编码为指定集合中的某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储或者通信网络的传递。常见的例子是将拉丁字母表编码成摩斯电码和ASCII,比如ASCII编码是将字母、数字和其它符号进行编号,并用7比特的二进制来表示这个整数。
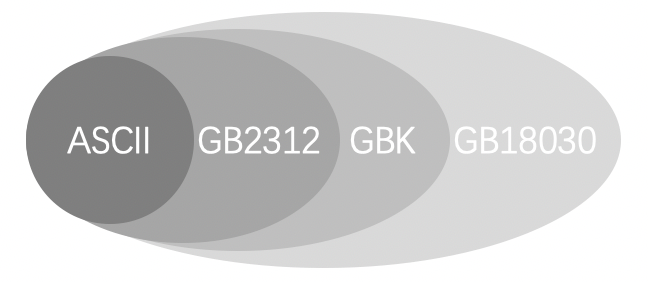
字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,就需要进行字符编码,以便计算机能够识别和存储各种文字。
常见字符编码
ASCII
很久以前,计算机制造商都是按各自的方式来将字符渲染到屏幕上,当时的计算机动不动可就是一套房子的大小,这家伙可不是谁都能玩的起的,那时人们并不关心计算机如何交流。随着上世纪七八十年代微处理器的出现,计算机变得越来越小,个人计算机开始进入大众的视线,随后出现了井喷式的发展,但是之前厂商都是各自为政,没考虑过自家的产品要兼容别人家的东西,导致在不同计算机体系间的数据转换变得十分蛋疼,因此美国的标准协会在1967年制定出了ASCII编码,到目前为止共定义了128个字符。
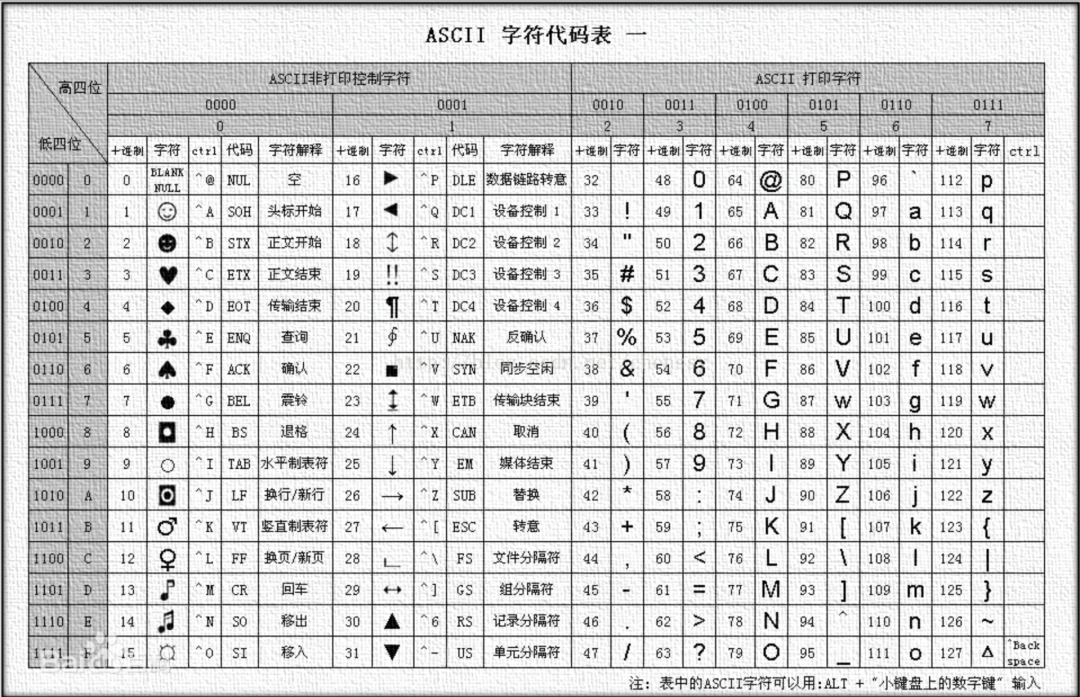
ASCII 编码(注意该表是列表示字节高 4 位)
其中前 32 个(0~31)是不可见的控制字符,32~126 是可见字符,127 是 DELETE 命令(键盘上的 DEL 键)。其实早在ASCII之前,IBM在1963年也推出过一套字符编码系统EBCDIC,跟ASCII码一样囊括了控制字符、数字、常用标点、大小写英文字母。
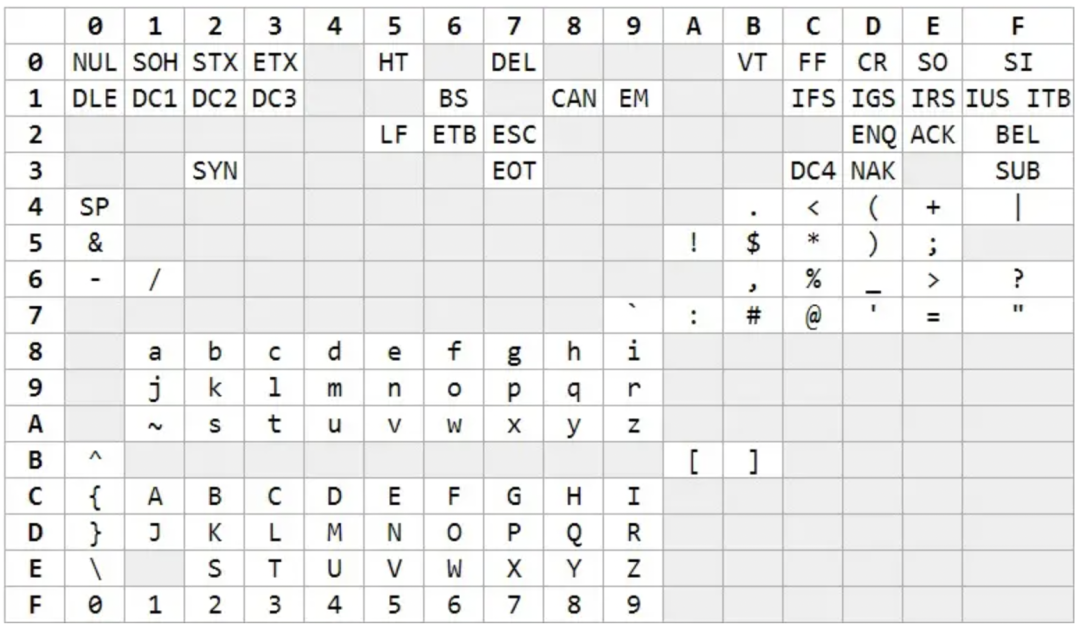
EBCDIC 编码
但是他的字符编号并不是连续的,这给后续程序处理带来了麻烦,后来ASCII 编码吸取了 EBCDIC 的经验教训,给英文单词分配了连续的编码,方便程序处理,因此被后来广泛接受。
ASCII 和 EBCDIC 编码相比,除了字符连续排列之外,最大的优点是ASCII 只用了一个字节的低 7 位,最高位永远是 0。可别小看了这个最高位的 0,看似无足轻重,但这是ASCII设计最成功的地方,后面介绍各编码原理的时候你会发现,正是因为这个高位0,其它编码规范才能对 ASCII 码无缝兼容,使得 ASCII 被广泛接受。
ISO-8859系列
美国市场虽然统一了字符编码,但是计算机制造商在进入欧洲市场的时候又遇到了麻烦,欧洲的主流语言虽然也是用拉丁字母,但却存在很多扩展体,比如法语的「é」,挪威语中的「Å」,都无法用 ASCII 表示。但是大家发现ASCII后面的128个还没有被使用可以利用起来,这对于欧洲主流语言就足够了。
于是就有了大家所熟知的这个ISO-8859-1(Latin-1),它只是扩展了ASCII后128个字符,还是属于单字节编码;同时为了兼容原先的 ASCII码,当最高位是0的时候仍然表示原先的 ASCII 字符不变,当最高位是1的时候表示扩展的欧洲字符。
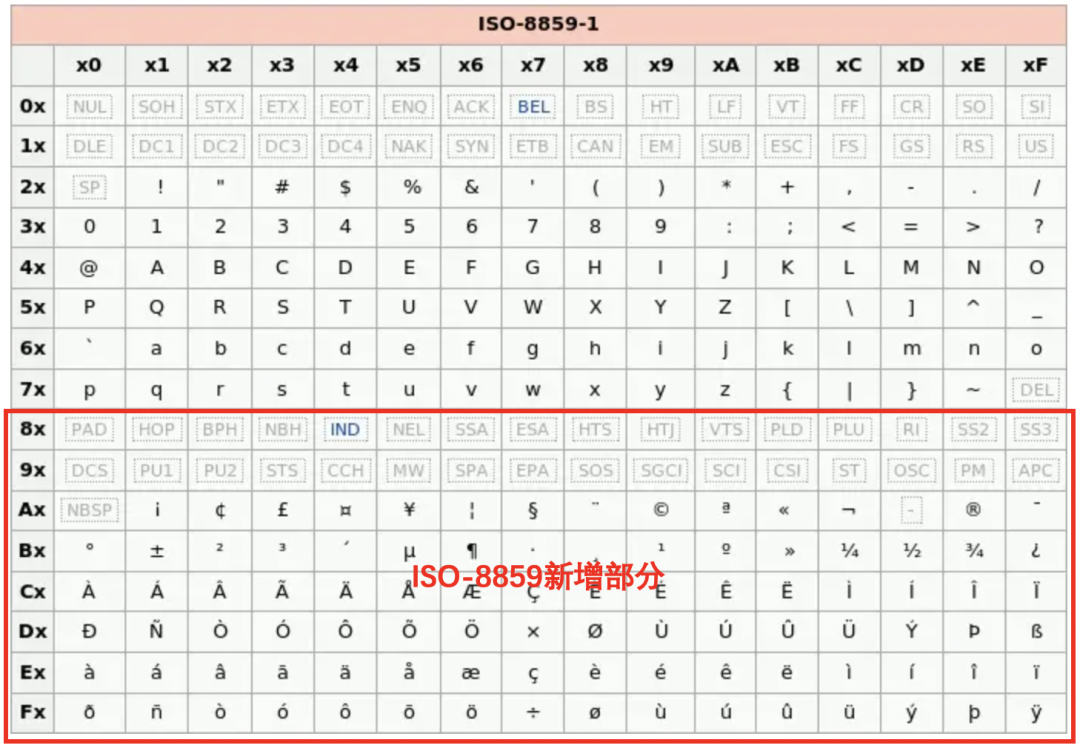
但是到这里还没有完,刚说了这只是欧洲主流的语言,但主流语言里没有法语使用的 œ、Œ、Ÿ 三个字母,也没有芬兰语使用的 Š、š、Ž、ž ,而单字节编码里的256个码点都被用完了,于是就出现了更多的变种 ISO-8859-2/3/.../16 系列,他们都兼容 ASCII,但彼此间又不完全兼容。
ISO-8859-n系列字符集如下:
ISO8859-1 字符集,也就是 Latin-1,是西欧常用字符,包括德法两国的字母。
ISO8859-2 字符集,也称为 Latin-2,收集了东欧字符。
ISO8859-3 字符集,也称为 Latin-3,收集了南欧字符。
ISO8859-4 字符集,也称为 Latin-4,收集了北欧字符。
ISO8859-5 字符集,也称为 Cyrillic,收集了斯拉夫语系字符。
ISO8859-6 字符集,也称为 Arabic,收集了阿拉伯语系字符。
ISO8859-7 字符集,也称为 Greek,收集了希腊字符。
.......
GB系列
当计算机进入东亚国家的时候,厂商们更傻眼了,美国和欧洲国家语言基本都是表音字符,一个字节就足够用了,但亚洲国家有不少是表意字符,字符个数动辄几万十几万的,一个字节完全不够用,所以我们国家有关部门按照ISO规范设计了GB2312双字节编码,但是GB2312是一个封闭字符集,只收录了常用字符总共也就7000多个字符,因此为了扩充更多的字符包括一些生僻字,才有了之后的GBK、GB18030、GB13000(“GB” 为 “国标” 的汉语拼音首字母缩写)。
按照 GB 系列编码方案,在一段文本中,如果一个字节是 0~127,那么这个字节的含义与 ASCII 编码相同,否则,这个字节和下一个字节共同组成汉字(或是 GB 编码定义的其他字符),所以GB系列都是兼容ASCII编码的。
GB2312
GB2312是使用两个字节来表示汉字的编码标准,共收入汉字6763个和非汉字图形字符682个,为了避免与 ASCII 字符编码(0~127)相冲突,规定表示一个汉字的编码字节其值必须大于127(即字节的最高位为 1 ),并且必须是两个大于 127 的字节连在一起来共同表示一个汉字( GB2312 为双字节编码),所以GB2312 属于变长编码,当是英文字符的时候占一个字节,中文字符的时候占两个字节,可以认为 GB2312是对 ASCII 的中文扩展。
GB2312字符集编号空间是一个94*94的二维表,行表示区(高位字节),列表示位(低位字节),每区有94个位,每个区位对应一个字符,称为区位码。区位码上加2020H,就得到国标码,国标码上加8080H,就得到常用的计算机机内码。这里引入了区位码、国标码、机内码概念,下面我们说下三者的关系。
国标码
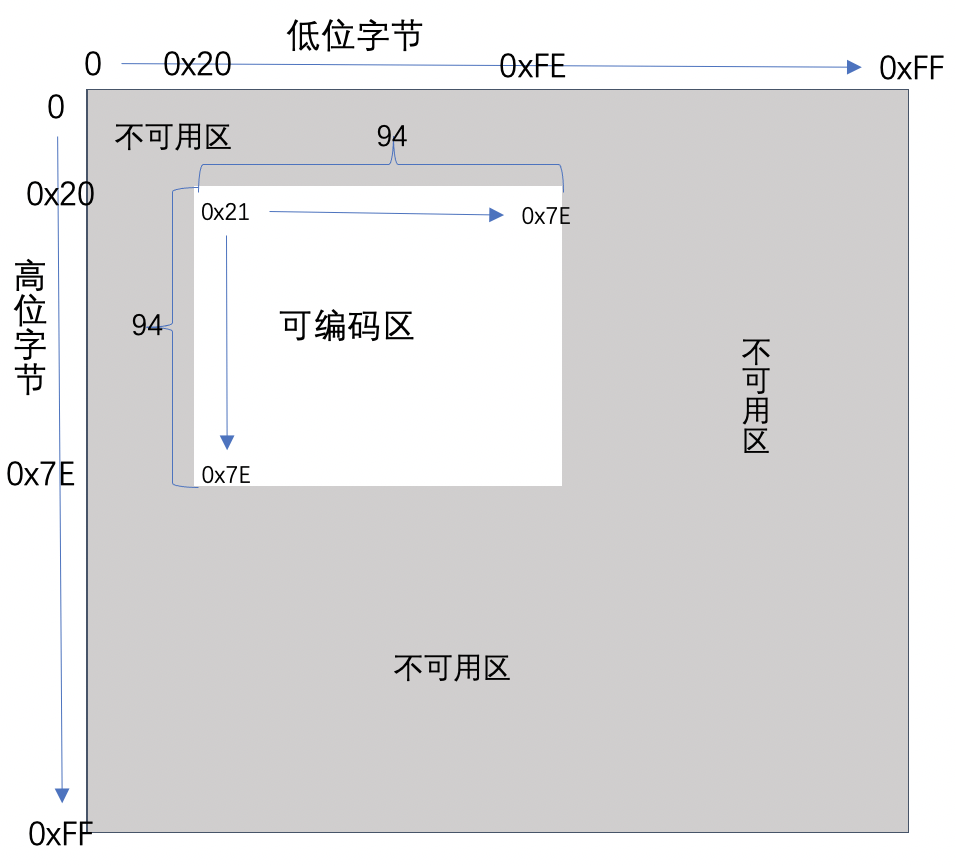
国标码是我国汉字信息交换的标准编码,规定由4位16进制数组成,用两个低7位字节表示,为了避开 ASCII 字符中的前32个控制指令字符,所以每个字节都是从第33个编号开始,如下图所示
区位码
由于上述国标码的16进制可编码区不够直观不方便我们使用,所以我们把他映射成了十进制的94*94二维表编号空间,我们称之为区位码,同时区位码也可以当成一种外码使用,输入法可以直接切换成区位码进行汉字输入,不过这种输入法无规则可言 人们很难记住区位编号,用的人也不多了。
下图是区位码的二维表,比如「万」字是45 区 82 位,所以「万」 字的区位码是「45,82」。
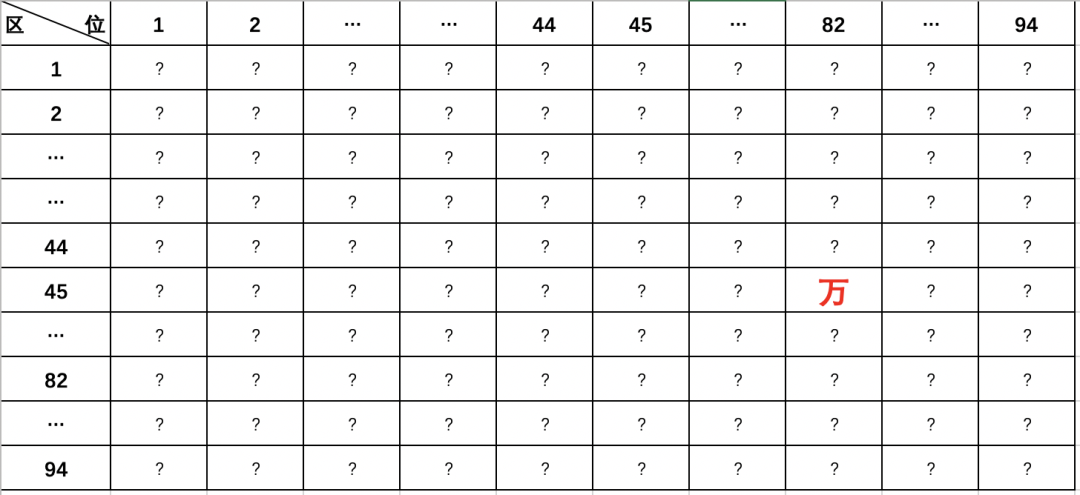
其中:
01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的682个全角字符;
10~15区:空区,留待扩展;
16~55区(3755个):常用汉字(也称一级汉字),按拼音排序;
56~87区(3008个):非常用汉字(也称二级汉字),按部首/笔画排序;
88~94区:空区,留待扩展。
机内码
GB2312国标码规范是覆盖掉ASCII中可见部分的符号和英文字母,使用两个7位码将其中的英文字母和符号重新编入,但是这样产生一个弊端,早期用ASCII码编码的英文文章无法打开,一打开就是乱码,也就是说应该要兼容早期ASCII码而不是覆盖它,后来微软为了解决这个问题,将字节的最高位设为1,因为ASCII中使用7位,最高位为0,转换后的编码称为机内码(内码),这种方式本质上是修改了GB2312的编码标准,最后被大家接受沿用。
总结下三者转换关系:区位码 ---> 区码和位码分别 + 32(即 + 20H )得到国标码 ---> 再分别 + 128(即 + 80H)得到机内码(与 ACSII 码不再冲突)
GBK
GBK即“国标扩展”的意思,因为GB2312双字节的最高位都要求大于1,上限也不会超过1万个字符,所以对此进行了扩展,对GB2312的字符不重新编码直接沿用,因此完全兼容GB2312。GBK虽然也是双字节编码,但是只要求第一个字节大于 127 就固定表示这是一个汉字的开始,正因为如此,GBK的编码空间比GB2312大很多。
GBK 整体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线,总计 23940 个码位,共收入 21886 个汉字和图形符号;其中 GBK/1 收录除 GB 2312 字符外的其他增补字符,GBK/2 收录 GB2312 字符,GBK/3 收录 CJK 字符,GBK/4 收录 CJK 字符和增补字符,GBK/5 为非中文字符,UDC 为用户自定义字符。
详细如下如所示:
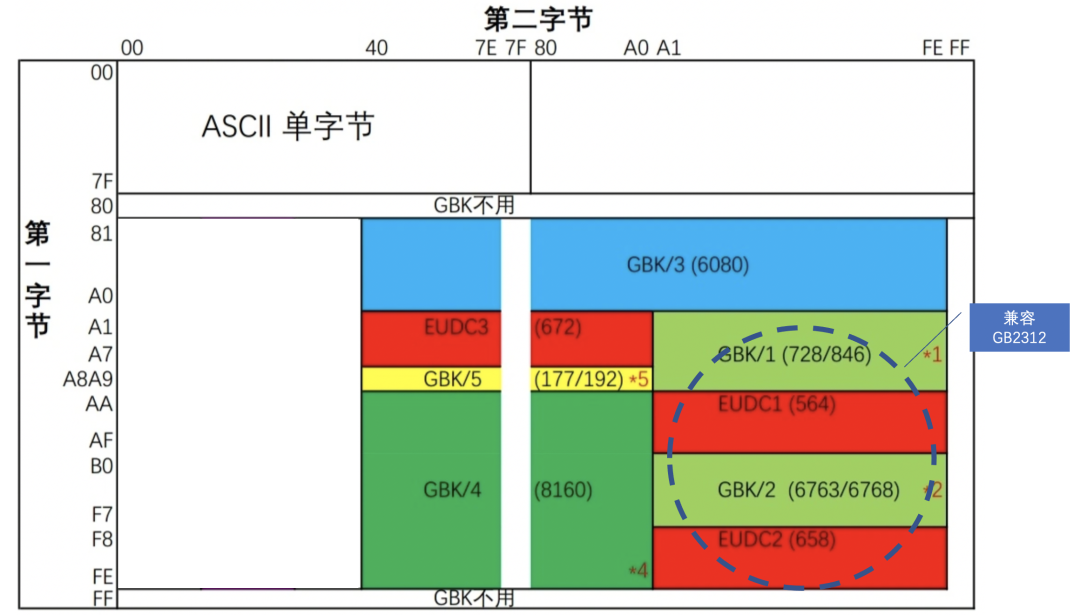
→ 这里大家可能会有两个疑问,为什么尾字节要从40开始,而不是00开始;为什么要排除 FF、xx7F这两条线的编号?
GBK的尾字节编码高位没有强制要求是1,当高位是0时跟ASCII码是冲突的,ASCII码里00-40之间大部分都是控制字符,所以排除控制字符主要是为了防止丢失高字节导致出现系统性严重后果;
排除FF是为了兼容GB2312,GB2312这个位是保留不使用的;而7F表示DEL字符就是向后删除一个字符,如果传输过程中丢失首字节那么就会出现严重的后果,所以需要将xx7F也排除,这是所有编码方案都需要注意的地方。
GB18030
随着计算机的发展,GBK的2万多个字符也还是扛不住,于是2000年我国又制定了新标准 GB18030,用来替代 GBK 标准。GB18030是强制性标准,现在在中国大陆销售的软件都支持 GB18030。
GB18030其实是对齐Unicode标准的,里面包括了所有Unicode字符集,也算是Unicode的一种实现(UTF)。
那既然有了UTF我们为什么还要搞一套Unicode实现?
主要是UTF-8/UCS-2他们是不兼容GB2312的,如果直接升级那么就全乱码了,所以GB18030是为了兼容GB系列,是GBK、GB2312的超集,当我们原先的GB2312(GBK)软件考虑升级到国际化Unicode时,可以直接使用GB18030进行升级。
GB18030虽然也是GB2312的扩展,但它和GBK的扩展方式不一样,GBK主要是充分利用了GB2312的一些没定义的编码空间,而GB18030采用的是字节变长编码,单字节区兼容ASCII、双字节区兼容GBK、四字节区对齐所有Unicode 码位。
实现原理上主要是采用第二字节未使用到的0x30~0x39编码空间来判断是否四字节。
字节数 | 编码空间 | 码点数 | |||
单字节 | 0x00 ~ 0x7F | 128 | |||
双字节 | 第一字节 | 第二字节 | 23940 | ||
0x81 ~ 0xFE | 0x40 ~ 0x7E(排除掉0x7F) | ||||
四字节 | 第一字节 | 第二字节 | 第三字节 | 第四字节 | 1587600 |
0x81 ~ 0xFE | 0x30 ~ 0x39 | 0x81 ~ 0xFE | 0x30 ~ 0x39 | ||
* 单字节,其值从0到0x7F。
* 双字节,第一个字节的值从0x81到0xFE,第二个字节的值从0x40到0xFE(不包括0x7F)。
* 四字节,第一个字节的值从0x81到0xFE,第二个字节的值从0x30到0x39,第三个字节的值从0x81到0xFE,第四个字节的值从0x30到0x39。
UNICODE
Unicode 称为统一码(也叫万国码),是按现代编码模型进行设计的一套字符编码体系,涵盖抽象字符集、编号、逻辑编码、编码实现。Unicode是为了解决传统的字符编码方案的局限而产生的,在这种语言环境下,不会再有语言的编码冲突,可以在同屏下显示任何国家的语言。
UTF-n编码(Unicode Transformation Format Unicode字符集转换格式,n表示码元位数)是Unicode这套编码体系里的编码实现CES部分,像UTF-8、UTF-16、UTF-32都是将数字转换到实际的二进制编码实现,Unicode的编码实现除了UTF系列之外,还有UCS-2/4,GB18030等。但是现在很多人误把Unicode当成只是一个字符编号,这其实是不对的。
Unicode可以容纳世界上所有国家的文字和符号,其编号范围是0-0x10FFFF,有1,114,112个码位,为了方便管理划分成17个平面,现已定义的码位有238,605个,分布在平面0、平面1、平面2、平面14、平面15、平面16。其中平面0又称为基本多语言平面(Basic Multilingual Plane,简称BMP),这个平面基本涵盖了当今世界上正在使用中的常用字符。我们平常用到的字符,一般都是位于 BMP 平面上的,其范围拥有 65,536 个码点,其他平面统称增补平面,关于平面的概念会在UTF-16章节详细介绍。
说起Unicode我们不得不提UCS(全称Universal Multiple-Octet Coded Character Set 通用多八位编码字符集),国际标准编号ISO/IEC 10646,是由 ISO 和 IEC 两家国际标准组织联合成立的工作组设计的一套新的统一字符集项目,目的与Unicode 联盟一样致力于开发一款全世界通用的编码集。
早在1984 年ISO 和 IEC 两家组织就成立了一个联合工作组来设计一套新的统一字符集标准,但是这两个组织都不知道对方的存在,直到Unicode联盟1988年发布了Unicode草案(UCS草案1989年发布),才发现大家在做同一件事,没有必要搞两套标准 所以后面又考虑合并,由于UCS 最初设计的是 31 位编码空间(UCS-4编码实现),可以容纳 2^31 约 21 亿个字符,而Unicode是16位空间(UTF-16编码实现),所以最开始Unicode 打算作为 UCS 的真子集,即 Unicode 中的每个字符都存在于 UCS 中,而且两者的码点相同,但 UCS 中的字符(编号超过65,536的)则不一定存在于 Unicode 中。
不过由于双方利益关系并没有说谁解散谁,最后双方作出一些妥协保持一致共同发展,两个标准中相同字符的编码(码点)必须是一样的,这是一个屁股决定脑袋的决策,如果最初Unicode知道UCS的存在,就不会再出现Unicode了。当然合并工作不是一蹴而就的而是经过多轮迭代, ISO/IEC 和 Unicode在 1993 年发布了第一版相互兼容版本,到了 1996年Unicode 2.0标准发布时,Unicode 字符集和 UCS 字符集(即 ISO/IEC 10646-1 )基本保持了一致,同时Unicode为了跟UCS的四字节保持一致推出了UTF-32编码实现,UCS为了跟Unicode的两字节保持一致推出了UCS-2编码实现。
所以现在我们可以认为UCS和Unicode是同一个东西,比如我们常见的java内部运行就采用的是UTF-16编码,而window操作系统采用的是UCS-2,他们都是同一个Unicode标准。
UTF-16
UTF是Unicode Transfer Format的缩写,即把Unicode转做某种格式的意思,所以UTF-16是Unicode编码里的其中一种实现方式,16代表的是字节位数,占两个字节(UTF-32则表示4个字节)。
Unicode 设计之初是采用UTF-16这种双字节定长编码的,其字符编号就是对应的二进制编号,也就是说第二层的CCS和第三层的CEF是一致的。比如汉字「万」的 Unicode 码点是 「U+4E07」,其二进制序列就是直译的「0100 1110 0000 0111 」,这种编码方式的优点是高效,不需要检查标志位,但缺点是不兼容ASCII,ASCII编码的文本都会显示乱码。
不过后来Unicode联盟发现 16 位编码空间根本不够用,与此同时 ISO/IEC组织也觉得 UCS的 32 位编码空间太多了,实际中根本没有几十亿字符,也挺浪费空间的,所以最终 Unicode 联盟和 ISO/IEC 工作组达成一致:两者使用统一的编码空间「 0000 ~ 10FFFF」(即 UCS 保证永远不分配大于 10FFFF 的字符码点),而且双方在字符编码上保持同步,即一方标准中增加了字符,也要通知另一方同步。
于是Unicode在UTF-16基础上拓展编码空间到 21 位,UCS则搞了一个双字节的UCS-2编码实现。
→ UTF-16 编码是双字节的,上限也只有6w多个码点,怎么让他支持到10FFFF(100w+)个码点呢?
本质就是多加几个字节来表示更多的字符,只是UTF-16不像UCS那样采用定长4字节,而是使用变长的形式,但是这个跟UTF-8变长方式又不太一样,他是采用代理对的方式实现,大部分常用字符用一个码元表示(定长2个字节),其他扩展的特殊字符用两个码元表示(定长4字节)。
UTF-16跟UTF-8、GB系列等都算是变长字节,但是设计初衷却不一样,像GBK是为了兼容ASCII,但是UTF-16一开始就没考虑要兼容ASCII,所以他的变长是为了节约存储空间而采用的自然增长方案,当空间不够的时候增长到4个字节。
那问题来了,我怎么知道存储的4个字节是表示一个字符,还是两个字符呢?比如当程序遇到字节序列01001110 00101101 01010110 11111101时,到底是判断成一个字符还是两个字符?
这就需要一个前导识别,比如GB2312识别第一个字节高位是不是1来判断是单字节还是双字节,但是UTF-16的高位1已经被用来编码了,当然这也难不倒我们,第一位被用了那么就用前几位的组合形式。
UTF-16采用了代理对来解决,也就是高半区编码(前两个字节)范围D800-DBFF(称为代理码点),低半区编码(后两个字节)范围DC00-DFFF,组成一个四个字节表示的字符。

上述前导6位组合也是有讲究的,ISO组织要求编号范围是0~10FFFF(),也就是说用20位就可以表示10FFFF个字符,对于双码元就是每个码元各自负责10位,一个码元是16位,数字位占去10位后,剩下的6位做为前导位。
当UTF-16使用一个码元表示的时候,Unicode字符编号跟码元序列是等值映射的,但是当采用双码元后,字符编号跟码元序列就需要转换了,下面是码元和Unicode编号值之间的计算公式:

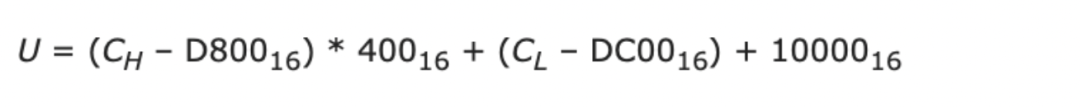
UTF-16把编码空间0000 ~ 10FFFF切成了17个平面,其实就是划分成17个区块,每个平面空间码点数都是=65536个,第一个平面称为基本多语言平面(Basic Multilingual Plane,简称BMP),这个平面涵盖了当今世界上最常用的字符,固定使用定长两个字节,除此之外的字符都放到增补平面里,都是使用两个码元的定长4个字节,下面是各个平面的用途
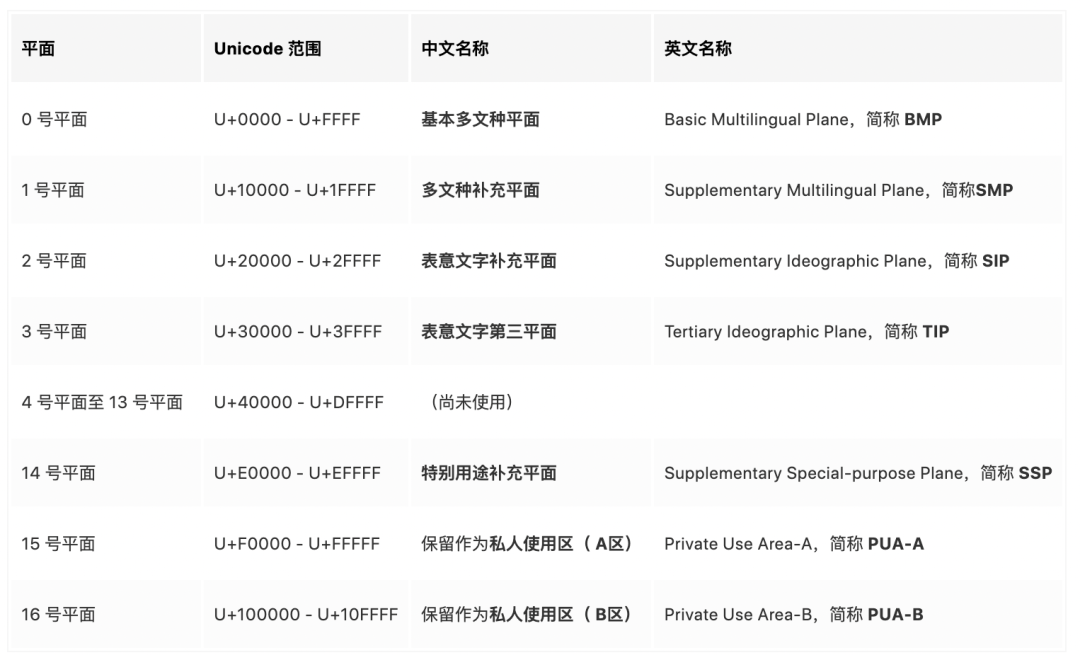
增补平面的编号是采用双码元4个字节来表示的,去除代理对之后有效位数是20位,然后将这20位的编号再划成16个平面区域,其中高半区的数字位里取出4位表示平面,剩下的16位表示每个平面可以表示的字符数也就是2的16次方65536个(两个字节大小)
UTF-16可看成是UCS-2的父集。在没有辅助平面前,UTF-16与UCS-2所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。
字节序顾名思义是指字节的顺序,对于单字节编码来说,一个字符对应一个字节,也就不存在字节序问题;但是对于UTF-16这种定长多字节编码,就有字节顺序问题了。字节序其实跟操作系统和底层硬件有关,不仅只是UTF-16这种多字节编码存在字节序,只要是多字节类型的数据都存在字节顺序问题,比如short、int、long。
为了方便说明,我们这里举个例子,比如存一个整数值「305419896」对应16进制是0x12345678,有人习惯从左到右按顺序去存,也有人说高位当然要放到高位地址而低位放到低位地址,要从右往左存。于是就有了下面两种存取方式。

其实这两种方式没有孰优孰劣,只是我们认知习惯有所不同 最终的设计不同,说来这都是阿拉伯人的锅啊,为什么数字高位非要在左边,这也引起了著名的大小端之争。
因此字节序也就有了大端和小端的概念,也形成了各自的阵营,比如Windows、FreeBSD、Linux 是小端序,Mac是大端序。其实大小端序并没有技术上的好坏之分。
小端序( Little-Endian)就是低位字节(即小端字节、尾端字节)存放在内存的低地址,而高位字节(即大端字节、头端字节)存放在内存的高地址。
大端序(Big-Endian )就是高位字节(即大端字节、头端字节)存放在内存的低地址,低位字节(即小端字节、尾端字节)存放在内存的高地址。
UTF-8
Unicode还是UCS最初都是采用多字节定长编码,由于没有兼容现有的 ASCII 标准的文件和软件,新标准很难被推广,于是兼容ASCII版本的UTF-8就诞生了。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,是现代字符编码模型中的第三层 CEF 。它可以用一至四个字节对 Unicode 字符集中的所有有效编码点进行编码,属于Unicode标准的一部分,UTF-8 就是为了解决向后兼容 ASCII 码而设计,Unicode 中前 128 个字符(与 ASCII 码一一对应),使用与 ASCII 码相同的二进制值的单个字节进行编码,这使得原来处理 ASCII 字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字优先采用的编码方式。—— 维基百科
UTF-8需要兼容ASCII,所以也需要有前缀码来控制,前缀规则如下:
如果首字节以 0 开头,则是单字节编码(即单个单字节码元);
如果首字节以 110 开头,则是双字节编码(即由两个单字节码元所组成的双码元序列);
如果首字节以 1110 开头,则是三字节编码(即由三个单字节码元所组成的三码元序列),以此类推。

理论上UTF-8变长可以超过4个字节,只是Unicode联盟规范上限是10FFFF,所以UTF-8规则设计上也限制了大小。
字符编码转换
GBK编码判断
bool isGBK(unsigned char* data, int len) {int i = 0;while (i < len) {if (data[i] <= 0x7f) {//编码小于等于127,只有一个字节的编码,兼容ASCIIi++;continue;} else {//大于127的使用双字节编码if (data[i] >= 0x81 &&data[i] <= 0xfe &&data[i + 1] >= 0x40 &&data[i + 1] <= 0xfe &&data[i + 1] != 0xf7) {i += 2;continue;} else {return false;}}}return true;
}UTF8编码判断
int preNUm(unsigned char byte) {unsigned char mask = 0x80;int num = 0;for (int i = 0; i < 8; i++) {if ((byte & mask) == mask) {mask = mask >> 1;num++;} else {break;}}return num;
}bool isUtf8(unsigned char* data, int len) {int num = 0;int i = 0;while (i < len) {if ((data[i] & 0x80) == 0x00) {// 0XXX_XXXXi++;continue;}else if ((num = preNUm(data[i])) > 2) {// 110X_XXXX 10XX_XXXX// 1110_XXXX 10XX_XXXX 10XX_XXXX// 1111_0XXX 10XX_XXXX 10XX_XXXX 10XX_XXXX// 1111_10XX 10XX_XXXX 10XX_XXXX 10XX_XXXX 10XX_XXXX// 1111_110X 10XX_XXXX 10XX_XXXX 10XX_XXXX 10XX_XXXX 10XX_XXXX// preNUm() 返回首个字节8个bits中首�?0bit前面1bit的个数,该数量也是该字符所使用的字节数 i++;for(int j = 0; j < num - 1; j++) {//判断后面num - 1 个字节是不是都是10开if ((data[i] & 0xc0) != 0x80) {return false;}i++;}} else {//其他情况说明不是utf-8return false;}} return true;
}UTF8与GBK互转
windows实现
windows 下utf-8与gbk的转换借助Unicode编码来实现
utf-8 >> unicode >> gbk
gbk >> unicode >> utf-8
通过window提供的API(包含在windows.h中):MultiByteToWideChar()和MultiByteToWideChar()两个函数实现的。对于类型根据代码编码或者传入的参数来决定使用CP_ACP还是CP_UTF8等,当然也可以识别具体编码。
CP_ACP和CP_OEMCP,分别是指当前计算机上的Windows操作系统的Windows代码页与OEM代码页。对于东亚的简体中文、繁体中文、日文、韩文等Win操作系统语言环境,这两种代码页是同一个,如简体中文是代码页936即GB2312字符集,繁体中文是950即大五码字符集,韩文是949、日文是932。对于西方国家的拼音文字语言设置,两个代码页不同。典型的如English_US,其Windows代码页是1252、OEM代码页是437,还有第三个代码页ISO-8859-1又称Latin-1或“西欧语言”,是针对英语法语西语德语等西欧语言的扩展ASCII字符集。这三者(1252、437、8859-1)都是针对英语但并不相同。
linux实现
linux下通过 iconv.h 提供的API来进行转换的API来实现,具体API如下所示:
//指定转换类型,返回一个转换描述符,iconv_open("GBK", "UTF-8") 将utf-8字符串转为gbk,
//可以转化的类型可以通过指令 iconv --list 查看。
iconv_t iconv_open(const char *tocode, const char *fromcode);//inbuf ,outbuf分别传入指向buff的指针的地址,outbf调用后指向buff中已保存字符串的末尾,即结束符;
//inbytesleft是一个输入输出参数,传入一个保存有需转换字符串长度的变量的地址,成功调用后该变量为0,表示字符串所有字节均已被转换;
//outbytesleft是一个输入输出参数,传入一个保存outbuf总长度的变量的地址,调用结束后该变量保存outbuf剩下的可用长度。
size_t iconv(iconv_t cd,char **inbuf, size_t *inbytesleft,char **outbuf, size_t *outbytesleft);
//关闭打开的转换描述符
iconv_close(cd);具体实现demo
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#ifdef WIN32
#include <windows.h>
#else
#include <iconv.h>
#endifint preNUm(unsigned char byte) {unsigned char mask = 0x80;int num = 0;for (int i = 0; i < 8; i++) {if ((byte & mask) == mask) {mask = mask >> 1;num++;} else {break;}}return num;
}bool isUtf8(unsigned char* data, int len) {int num = 0;int i = 0;while (i < len) {if ((data[i] & 0x80) == 0x00) {// 0XXX_XXXXi++;continue;}else if ((num = preNUm(data[i])) > 2) {// 110X_XXXX 10XX_XXXX// 1110_XXXX 10XX_XXXX 10XX_XXXX// 1111_0XXX 10XX_XXXX 10XX_XXXX 10XX_XXXX// 1111_10XX 10XX_XXXX 10XX_XXXX 10XX_XXXX 10XX_XXXX// 1111_110X 10XX_XXXX 10XX_XXXX 10XX_XXXX 10XX_XXXX 10XX_XXXX// preNUm() 返回首个字节8个bits中首�?0bit前面1bit的个数,该数量也是该字符所使用的字节数 i++;for(int j = 0; j < num - 1; j++) {//判断后面num - 1 个字节是不是都是10开if ((data[i] & 0xc0) != 0x80) {return false;}i++;}} else {//其他情况说明不是utf-8return false;}} return true;
}bool isGBK(unsigned char* data, int len) {int i = 0;while (i < len) {if (data[i] <= 0x7f) {//编码小于等于127,只有一个字节的编码,兼容ASCIIi++;continue;} else {//大于127的使用双字节编码if (data[i] >= 0x81 &&data[i] <= 0xfe &&data[i + 1] >= 0x40 &&data[i + 1] <= 0xfe &&data[i + 1] != 0xf7) {i += 2;continue;} else {return false;}}}return true;
}
typedef enum {GBK,UTF8,UNKOWN
} CODING;
//需要说明的是,isGBK()是通过双字节是否落在gbk的编码范围内实现的,
//而utf-8编码格式的每个字节都是落在gbk的编码范围内�?
//所以只有先调用isUtf8()先判断不是utf-8编码,再调用isGBK()才有意义
CODING GetCoding(unsigned char* data, int len) {CODING coding;if (isUtf8(data, len) == true) {coding = UTF8;} else if (isGBK(data, len) == true) {coding = GBK;} else {coding = UNKOWN;}return coding;
}
int main() {char src[512] = "你好";int len = strlen(src);//printf("%s, len:%d\n",src, len);char dstgbk[512] = {0};char dstutf8[512] = {0};printf("coding:%d\n", GetCoding((unsigned char*)src, len)); //判断是否是utf-8#ifndef WIN32iconv_t cd;char* pSrc = src;char* pUTFOUT = dstutf8;char* pGBKOUT = dstgbk;size_t srcLen = (size_t)len;size_t outLenUTF = sizeof(dstutf8);size_t outLenGBK = sizeof(dstgbk);size_t ret;#endif#ifdef WIN32wchar_t * pUnicodeBuff = NULL;int rlen = 0;rlen = MultiByteToWideChar(CP_UTF8, 0, src, -1, NULL ,NULL);pUnicodeBuff = new WCHAR[rlen + 1]; //为Unicode字符串空间rlen = MultiByteToWideChar(CP_UTF8, 0, src, -1, pUnicodeBuff, rlen); rlen = WideCharToMultiByte(936, 0, pUnicodeBuff, -1, NULL, NULL, NULL, NULL); //936 为windows gb2312代码页码WideCharToMultiByte(936, 0, pUnicodeBuff ,-1, dstgbk, rlen, NULL ,NULL);delete[] pUnicodeBuff;#elsecd = iconv_open("GBK", "UTF-8");if (cd == (iconv_t)-1) {printf("iconv_open error\n");}ret = iconv(cd, &pSrc, &srcLen, &pGBKOUT, &outLenGBK);iconv_close(cd);#endif//printf("%s, len:%d\n",dstgbk, strlen(dstgbk));printf("coding:%d\n", GetCoding((unsigned char*)dstgbk, strlen(dstgbk))); //判断是否是gbk#ifdef WIN32rlen = MultiByteToWideChar(936, 0, dstgbk, -1, NULL, NULL);pUnicodeBuff = new WCHAR[rlen + 1]; //为Unicode字符串空间rlen = MultiByteToWideChar(936, 0, dstgbk, -1, pUnicodeBuff, rlen); rlen = WideCharToMultiByte(CP_UTF8, 0, pUnicodeBuff, -1, NULL, NULL, NULL, NULL);WideCharToMultiByte(CP_UTF8, 0, pUnicodeBuff, -1, dstutf8, rlen, NULL, NULL);delete[] pUnicodeBuff;#elsecd = iconv_open("UTF-8", "GBK");if (cd == (iconv_t)-1) {printf("iconv_open error\n");}//pSrc = pGBKOUT; 错误,上面调用过一次此时iconv()后,pGBKOUT指向的是dstgbk[512]可用的位置,//即dstgbk[512]保存gbk字符串的后一位,也就是结束符的位置pSrc = dstgbk;srcLen = strlen(dstgbk);ret = iconv(cd, &pSrc, &srcLen, &pUTFOUT, &outLenUTF);iconv_close(cd);#endif//printf("%s, len:%d\n",dstutf8, strlen(dstutf8));printf("coding:%d\n", GetCoding((unsigned char*)dstutf8, strlen(dstutf8))); //判断是否是utf-8getchar();
}相关文章:
字符编码及转换
什么是字符编码字符编码(Character encoding)也称字集码,是把字符集中的字符,编码为指定集合中的某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储或者…...
redis原理
文章目录一、Redis数据结构1.1.动态字符串SDS1.2 intset1.3 Dict1.4 ZipList1.5 QuickList1.6 SkipList1.7 RedisObject二、Redis五大基本数据类型底层2.1.String2.2.List2.3.Set2.4.ZSet2.4.Hash三、Redis网络模型3.1.用户空间和内核空间3.2.阻塞IO3.3.非阻塞IO3.4.IO多路复用…...
kettle开发-Day37-SQ索引优化
前言:在上一个生产项目中,有个单表数据超249G了,里面存储的数据时间跨度就1年左右,那为啥会出现这种情况呢?数据来源为,一个生产基地所有电表的每分钟读数,一个基地大概500个电表左右࿰…...

【camera之3a】AE
文章目录sensorAEsensor 分辨率 常见分辨率的感性表述即30万、100万、200万,正确表述应为0.3M、1M、2M,其中M代表百万,是像素单位。sensor分辨率即指在单位面积上,像素的个数,数值越大 ,则代表像素点越多&…...

Docker-Consul概述以及集群环境搭建
一、Docker consul概述容器服务更新与发现:先发现再更新,发现的是后端节点上容器的变化(registrator),更新的是nginx配置文件(agent)egistrator:是consul安插在docker容器里的眼线&a…...
性能技术分享|Jmeter+InfluxDB+Grafana搭建性能平台(四)
四、Jmeter配置InfluxDB4.1 后端监听器(BackendListener)介绍1、什么是后端监听器(BackendListener)?源码给出的解释是:BackendListener是一种异步监听并获取到测试结果的实现类。也就是说发出的如http等响应请求的结果,都会被封装在SampleRe…...
图数据建模基础
Neo4j 图的组件 节点(Nodes)标签(Labels)关系(Relationships)属性(Properties)建模过程 了解领域并为应用程序定义特定用例(问题)。开发初始图形数据模型。 对…...

nodejs篇 process模块
目录 前言 监听回调 beforeExit 、exit、uncaughtException beforeExit exit uncaughtException Process常用属性 stdout stdin process方法 process.cwd(),process.chdir() process.nextTick() process.exit() process.kill() 前言 process是nodejs提…...

JavaScript高级程序设计读书分享之3章——3.4数据类型
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 ECMAScript 有 6 种简单数据类型(也称为原始类型):Undefined、Null、Boolean、Number、String 和 Symbol(es6新增)。 还有一种复杂数据类型叫…...
棱形打印--进阶2(Java)
棱形打印 问题 * *** ***** ******* ********* ******* ***** *** * * * …...

清除 git 所有历史提交记录,使其为新库
清除 git 所有历史提交记录,使其为新库需求方案需求 基于以前的仓库重新开发,这样可保留以前的配置等文件,但是需要删除全部的历史记录、tag、分支等。 方案 创建新的分支 使用 --orphan 选项,可创建1个干净的分支(无…...

pyTorch下载和cuda下载以及学习笔记
pytorch官方网站,cuda官方网站 CUDA下载:https://developer.nvidia.com/cuda-toolkit-archive CUDNN下载:https://developer.nvidia.com/rdp/cudnn-download pytorch下载:pytorch.org 任务管理器中只显示CUDA占用的专用内存&#…...

【学习总结】IMU预积分推导
本文仅用于记录自己学习总结。记录IMU预积分推导过程,不包含具体原理。 符号表示 RRR: 表示旋转矩阵 vvv: 表示速度 ppp: 表示位移 ExpExpExp: 指数映射,将旋转向量映射为旋转矩阵 w~\widetilde{w}w: 角速度观测值 f~\widetilde{f}f: 加速度观测值 bg…...

天猫商城自动化python脚本(仅供初学者学习使用)
作者:Eason_LYC 悲观者预言失败,十言九中。 乐观者创造奇迹,一次即可。 一个人的价值,在于他所拥有的。可以不学无术,但不能一无所有! 技术领域:WEB安全、网络攻防 关注WEB安全、网络攻防。我的…...
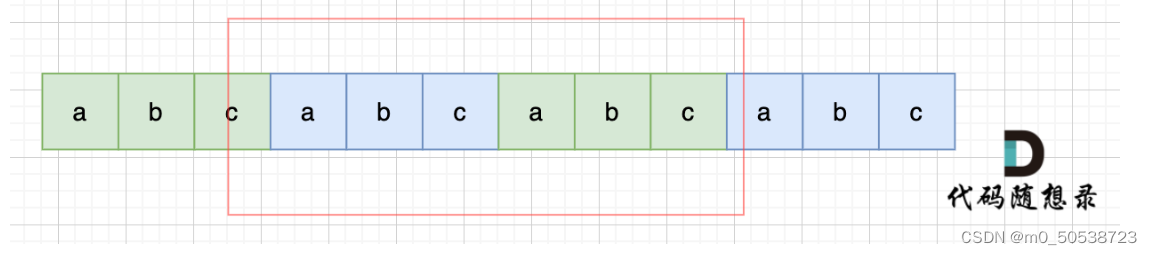
代码随想录第十一天(459)
文章目录459. 重复的子字符串答案思路暴力破解移动匹配459. 重复的子字符串 也不知道为啥这个提示简单题…… 答案思路 暴力破解 例如:abcabc 移位一次:cabcab 移位两次:bcabca 移位三次:abcabc 现在字符串和原字符串匹配了…...

线程及线程池学习
1 线程和进程的区别?进程:进程指正在运行的程序。线程:线程是进程中的一个执行单元,负责当前进程中程序的执行,一个进程中至少有一个线程。同一个进程中的多个线程之间可以并发的执行。2 创建线程有哪几种方式…...
整合Ehcache、Redis、Memcached、jetcache、j2cache缓存)
SpringBoot整合(四)整合Ehcache、Redis、Memcached、jetcache、j2cache缓存
企业级应用主要作用是信息处理,当需要读取数据时,由于受限于数据库的访问效率,导致整体系统性能偏低。 为了改善上述现象,开发者通常会在应用程序与数据库之间建立一种临时的数据存储机制,该区域中的数据在内存…...

想要的古风女生头像让你快速get
如今我看到很多人都喜欢用古风女生当作头像,那么今天我就来教大家如何快速得到一张超美的古风女生头像~ 上图就是我使用 APISpace 的 AI作画(图像生成)服务 快速生成的古风女生头像,不仅可以限定颜色,还可以选择『宝石镶嵌』或『花卉造型』这…...

传统企业数字化转型,到底难在哪里?
数字化转型过程中面临最大的挑战和问题是什么?这篇整理了企业在数字化转型过程中普遍面临的9大问题和挑战以及如何解决这些问题,希望能够对各位企业数字化转型有多启发和帮助。 01 企业数字化转型三大现状 在梳理企业数字化转型问题之前,我想…...
)
Python:青蛙跳杯子(BFS)
题目描述 X 星球的流行宠物是青蛙,一般有两种颜色:白色和黑色。 X 星球的居民喜欢把它们放在一排茶杯里,这样可以观察它们跳来跳去。 如下图,有一排杯子,左边的一个是空着的,右边的杯子,每个…...

PyTorch 2.8镜像惊艳效果:Wan2.2-T2V在RTX 4090D上生成1080p视频实录
PyTorch 2.8镜像惊艳效果:Wan2.2-T2V在RTX 4090D上生成1080p视频实录 1. 开篇:专业级视频生成环境 当我们需要处理视频生成这类计算密集型任务时,一个稳定高效的运行环境至关重要。今天要介绍的PyTorch 2.8深度优化镜像,正是为R…...

双闭环调速系统调参避坑指南:如何用MATLAB/Simulink让ASR和ACR配合更默契?
双闭环调速系统调参避坑指南:如何用MATLAB/Simulink让ASR和ACR配合更默契? 在电机控制领域,双闭环调速系统因其优异的动态性能和抗干扰能力而广受青睐。然而,许多工程师在实际调试过程中常常陷入参数调整的泥潭——转速环…...

GraphQL.NET依赖注入终极指南:7个MicrosoftDI扩展最佳实践
GraphQL.NET依赖注入终极指南:7个MicrosoftDI扩展最佳实践 【免费下载链接】graphql-dotnet GraphQL for .NET 项目地址: https://gitcode.com/gh_mirrors/gr/graphql-dotnet GraphQL.NET 作为 .NET 生态系统中功能最强大的 GraphQL 实现框架,其依…...
)
手把手教你用OpenCV+QT搭建FPGA图像传输测试平台(从环境配置到协议解析)
从零构建FPGA图像传输测试平台:OpenCVQT全链路开发指南 在FPGA图像处理系统的开发中,如何验证硬件输出的图像质量一直是工程师面临的挑战。传统示波器只能查看信号波形,而我们需要的是能够直观显示图像内容、记录传输数据并支持协议分析的完整…...
,我是怎样逆袭的?)
上岸必看!毕业2年差点因工殒命,到成为网安工程师(15K),我是怎样逆袭的?
前言 跟着他的记录,让我们一起体验当初充满期待和挑战的转型时刻 成功的从打灰工种转行到计算机办公也有2年了,笔者就来说说,小镇青年到高级白领的过渡吧,这其中也是万分艰辛不足为外人道,好在最终得偿所愿。没错&am…...

LFM2.5-1.2B-Thinking-GGUF效果展示:多轮追问中思维链持续性验证
LFM2.5-1.2B-Thinking-GGUF效果展示:多轮追问中思维链持续性验证 1. 模型核心能力展示 LFM2.5-1.2B-Thinking-GGUF作为一款轻量级文本生成模型,在思维链持续性和多轮对话场景中展现出独特优势。通过内置的GGUF模型文件和llama.cpp运行时,即…...

2026 AI 超级员工系统推荐:技术重塑营销新生态,降本增效新范式
2026 年,AI 技术正以燎原之势重塑企业营销全链路,AI 超级员工系统凭借人力成本降低 50%、获客效率提升 3 倍的硬核实力,成为破解企业营销困局的核心引擎。从内容生产到私域转化,从跨平台运营到合规风控,这些智能系统正…...

ChatGPT Conversation Not Found 问题分析与AI辅助开发解决方案
在集成ChatGPT这类大模型API构建应用时,我们常常会追求流畅、智能的多轮对话体验。然而,一个令人头疼的报错 Conversation Not Found 或类似提示,却可能让精心维护的对话上下文瞬间“失忆”,用户体验直线下降。今天,我…...

如何在Linux中安装MySQL
一在MySQL官网中再到Linux版本(下载red hat 版的)二下载文件并解压,并在window power shell中上传服务器三在Linux中创建包四在Linux中查看文件是否上传成功五开始安装安装成功后查看原密码最后在MySQL中更改原密码...

3步让你的PyTorch模型在Intel CPU提速50%:开发者实战指南
3步让你的PyTorch模型在Intel CPU提速50%:开发者实战指南 【免费下载链接】intel-extension-for-pytorch A Python package for extending the official PyTorch that can easily obtain performance on Intel platform 项目地址: https://gitcode.com/GitHub_Tre…...