十三、RNN循环神经网络实战
因为我本人主要课题方向是处理图像的,RNN是基本的序列处理模型,主要应用于自然语言处理,故这里就简单的学习一下,了解为主
一、问题引入
已知以前的天气数据信息,进行预测当天(4-9)是否下雨
| 日期 | 温度 | 气压 | 是否下雨 |
|---|---|---|---|
| 4-1 | 10 | 20 | 否 |
| 4-2 | 30 | 40 | 是 |
| 4-3 | 40 | 25 | 是 |
| 4-4 | 10 | 30 | 是 |
| 4-5 | 5 | 10 | 否 |
| 4-6 | 10 | 20 | 是 |
| 4-7 | 12 | 60 | 否 |
| 4-8 | 25 | 80 | 是 |
| 4-9 | 20 | 15 | ? |
这里的数据集都是随别胡乱写的哈,就说在阐述一下待解决的问题,随别做的数据集
思路:可以四天一组,每组中有4天的天气信息,包括温度、气压、是否下雨
前三天作为输入,第四天最为输出
在卷积神经网络中,全连接层是权重最多的,也是整个网络中计算量最多的地方
卷积中
输入:128通道
输出:64通道
卷积核:5×5
总共的权重参数:128×64×5×5 = 204800
全连接中
一般都不会直接将一个高维通道直接变为1,而是多几个中间层进行过度
输入:4096
输出:1024
权重参数个数:4096×1024 = 4194304
权重参数个数压根都不在一个数量级上,所以说,正因为卷积的权重共享,导致卷积操作所需参数远小于全连接
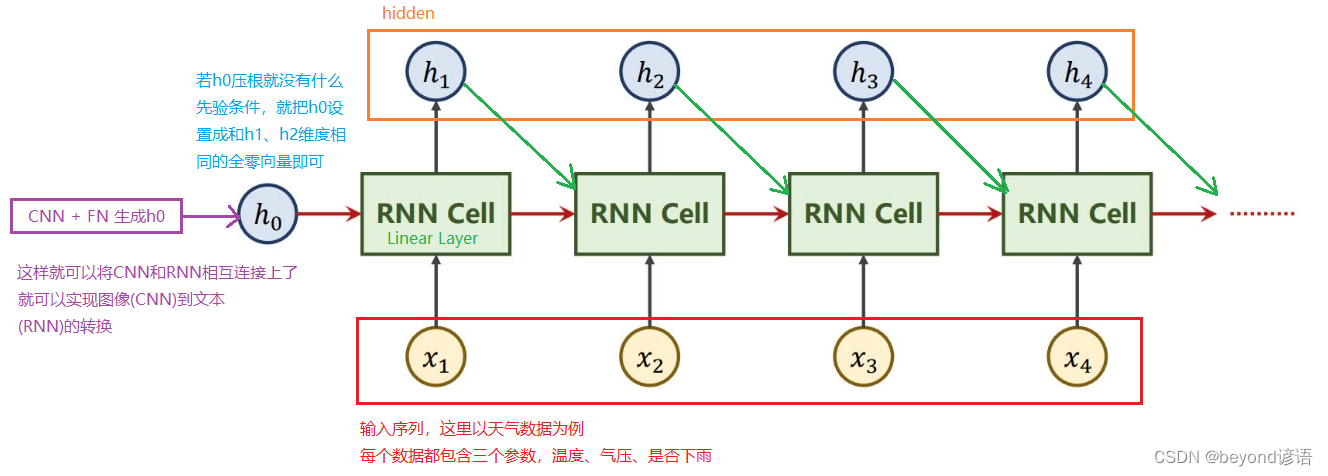
RNN循环神经网络主要用在具有序列关系的数据中进行处理,例如:天气的预测,因为前后的天气会相互影响,并不会断崖式的变化、股市预测等,典型的就是自然语言处理
我喜欢beyond乐队这句话的词语之间具有序列关系,随便调换顺序产生的结果肯定很难理解
二、RNN循环神经网络
Ⅰ,RNN Cell
RNN Cell是RNN中的核心单元
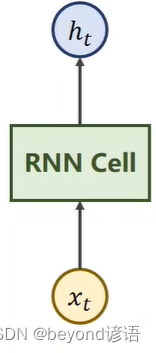
xt:序列当中,时刻t时的数据,这个数据具有一定的维度,例如天气数据就是3D向量的,即,温度、气压、是否下雨
xt通过RNN Cell之后就会得到一个ht,这个数据也是具有一定的维度,假如是5D向量
从xt这个3D向量数据通过RNN Cell得到一个ht这个5D向量数据,很明显,这个RNN Cell本质就是一个线性层
区别:RNN Cell这个线性层是共享的

RNN Cell基本流程

现学现卖

import torch#根据需求设定参数
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2yy_cell = torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)dataset = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(batch_size,hidden_size) #h0设置为全0for idx,inputs in enumerate(dataset):print('-----------------)print("Input size:",inputs.shape)hidden = yy_cell(inputs,hidden)print("outputs size:",hidden.shape)print(hidden)
"""
==================== 0 ====================
Input size: torch.Size([1, 4])
outputs size: torch.Size([1, 2])
tensor([[ 0.6377, -0.4208]], grad_fn=<TanhBackward0>)
==================== 1 ====================
Input size: torch.Size([1, 4])
outputs size: torch.Size([1, 2])
tensor([[-0.2049, 0.6174]], grad_fn=<TanhBackward0>)
==================== 2 ====================
Input size: torch.Size([1, 4])
outputs size: torch.Size([1, 2])
tensor([[-0.1482, -0.2232]], grad_fn=<TanhBackward0>)
"""Ⅱ,RNN

现学现卖
import torch#根据需求设定参数
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 2 #两层RNN Cellcell = torch.nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)inputs = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(num_layers,batch_size,hidden_size) #h0设置为全0out,hidden = cell(inputs,hidden)print('output size:',out.shape)
print('output:',out)
print('hidden size:',hidden.shape)
print('hidden',hidden)"""
output size: torch.Size([3, 1, 2])
output: tensor([[[ 0.8465, -0.1636]],[[ 0.3185, -0.1733]],[[ 0.0269, -0.1330]]], grad_fn=<StackBackward0>)
hidden size: torch.Size([2, 1, 2])
hidden tensor([[[ 0.5514, 0.8349]],[[ 0.0269, -0.1330]]], grad_fn=<StackBackward0>)
"""
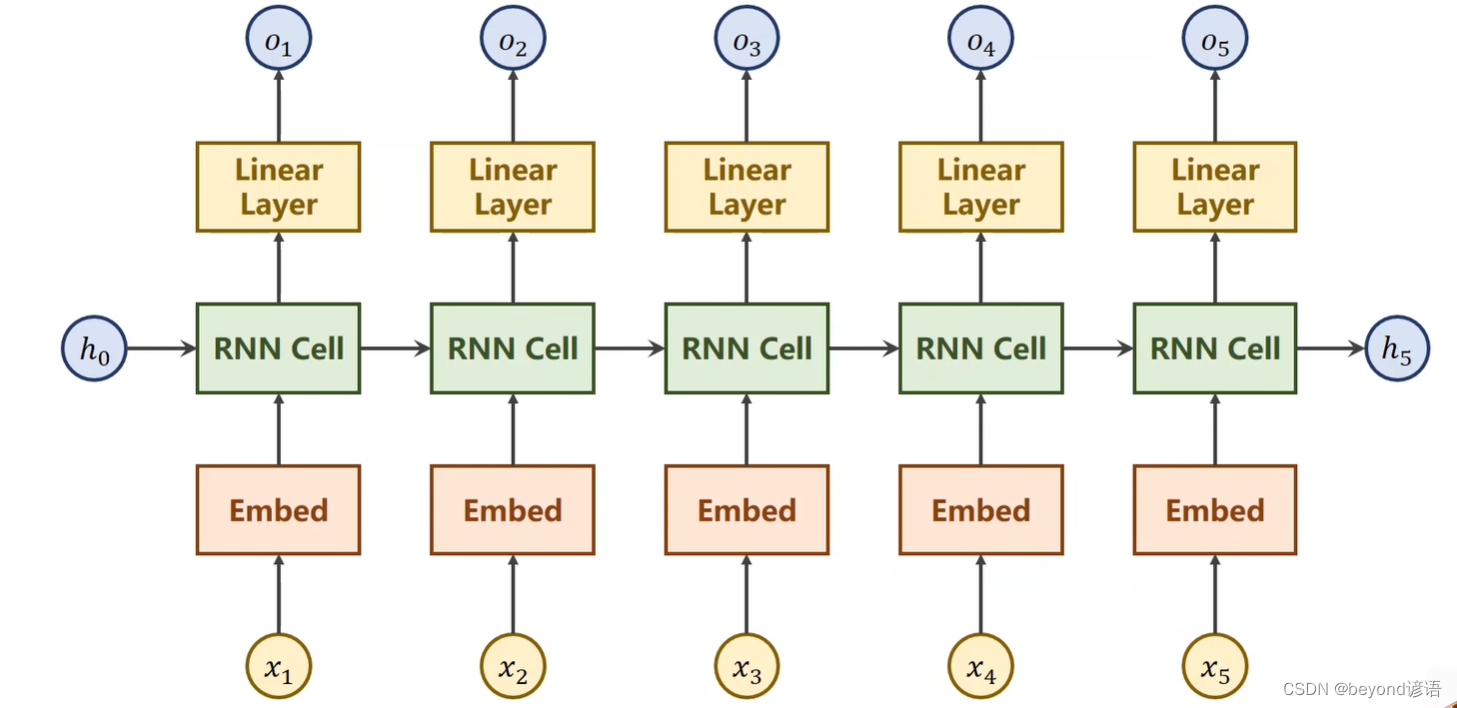
三、RNN实战
需求:实现将输入beyond转换为ynbode
①文本转向量one-hot
因为RNN Cell单元输入的数据必须是由单词构成的向量 ,根据字符来构建一个词典,并为其分配索引,索引变One-Hot向量,词典中有几项,最终构建的向量也有几列,只能出现一个1,其余都为0
| character | index |
|---|---|
| b | 0 |
| d | 1 |
| e | 2 |
| n | 3 |
| o | 4 |
| y | 5 |


②模型训练
Ⅰ RNN Cell
import torchinput_size = 6
hidden_size = 6
batch_size = 1dictionary = ['b','e','y','o','n','d'] #字典
x_data = [0,1,2,3,4,5] #beyond
y_data = [2,4,0,3,5,1] #ynbodeone_hot = [[1,0,0,0,0,0],[0,1,0,0,0,0],[0,0,1,0,0,0],[0,0,0,1,0,0],[0,0,0,0,1,0],[0,0,0,0,0,1]]x_one_hot = [one_hot[x] for x in x_data] #将x_data的每个元素从one_hot得到相对于的向量形式inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size) #inputs形式为(seqlen,batch_size,input_size)
labels = torch.LongTensor(y_data).view(-1,1) #lables形式为(seqlen,1)class y_rnncell_model(torch.nn.Module):def __init__(self,input_size,hidden_size,batch_size):super(y_rnncell_model,self).__init__()self.batch_size = batch_sizeself.input_size = input_sizeself.hidden_size = hidden_sizeself.rnncell = torch.nn.RNNCell(input_size=self.input_size,hidden_size=self.hidden_size)def forward(self,inputs,labels):hidden = self.rnncell(inputs,labels)return hiddendef init_hidden(self): #定义h0初始化return torch.zeros(self.batch_size,self.hidden_size)y_net = y_rnncell_model(input_size,hidden_size,batch_size)#定义损失函数和优化器
lossf = torch.nn.CrossEntropyLoss()
optim = torch.optim.Adam(y_net.parameters(),lr=0.001)# RNN Cell
for epoch in range(800):loss = 0optim.zero_grad() #优化器梯度归零hidden = y_net.init_hidden() #h0print('Predicted string:',end='')for x,y in zip(inputs,labels):hidden = y_net(x,hidden)loss += lossf(hidden,y) #计算损失之和,需要构造计算图_,idx = hidden.max(dim=1)print(dictionary[idx.item()],end='')loss.backward()optim.step()print(',Epoch [%d/20] loss=%.4f'%(epoch+1,loss.item()))
Ⅱ RNN
#引入torch
import torchinput_size = 6 #beyond
hidden_size = 6 #
num_layers = 1
batch_size = 1
seq_len = 6idx2char = ['b','d','e','n','o','y'] #字典
x_data = [0,2,5,4,3,1] #beyond
y_data = [5,3,0,4,1,2] #ynbodeone_hot = [[1,0,0,0,0,0],[0,1,0,0,0,0],[0,0,1,0,0,0],[0,0,0,1,0,0],[0,0,0,0,1,0],[0,0,0,0,0,1]]x_one_hot = [one_hot[x] for x in x_data] #将x_data的每个元素从one_hot得到相对于的向量形式inputs = torch.Tensor(x_one_hot).view(seq_len,batch_size,input_size)labels = torch.LongTensor(y_data)class y_rnn_model(torch.nn.Module):def __init__(self,input_size,hidden_size,batch_size,num_layers):super(y_rnn_model,self).__init__()self.num_layers = num_layersself.batch_size = batch_sizeself.input_size = input_sizeself.hidden_size = hidden_sizeself.rnn = torch.nn.RNN(input_size=self.input_size,hidden_size=self.hidden_size,num_layers=self.num_layers)def forward(self,inputs):hidden = torch.zeros(self.num_layers,self.batch_size,self.hidden_size)#构造h0out,_ = self.rnn(inputs,hidden) return out.view(-1,self.hidden_size) #(seqlen×batchsize,hiddensize)net = y_rnn_model(input_size,hidden_size,batch_size,num_layers)lessf = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=0.05)for epoch in range(30):optimizer.zero_grad()outputs = net(inputs)loss = lessf(outputs,labels) loss.backward()optimizer.step()_, idx = outputs.max(dim=1)idx = idx.data.numpy()print('Predicted:',''.join([idx2char[x] for x in idx]),end='')print(',Epoch[%d/15] loss=%.3f' % (epoch+1,loss.item()))
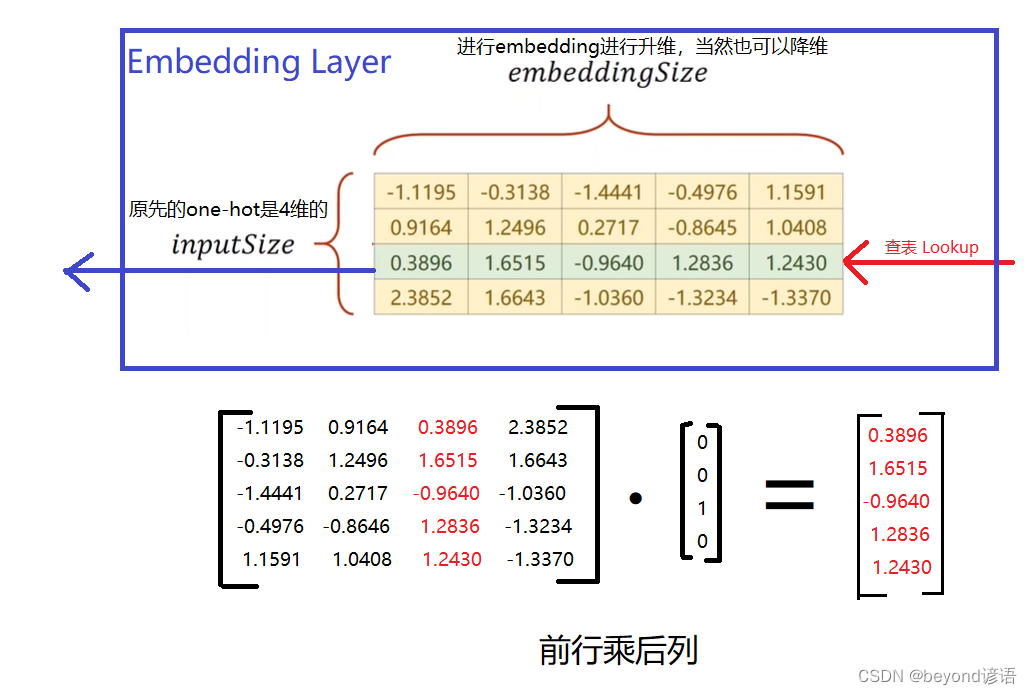
③one-hot的不足
1,维度过高;一个单词得占用一个维度
2,one-hot向量过于稀疏;就一个1,其余全是0
3,硬编码;一对一
解决方法:EMBEDDING
思路:将高维的向量映射到一个稠密的低维的向量空间里面
即:数据的降维
优化RNN
官网torch.nn.Embedding函数详细参数解释
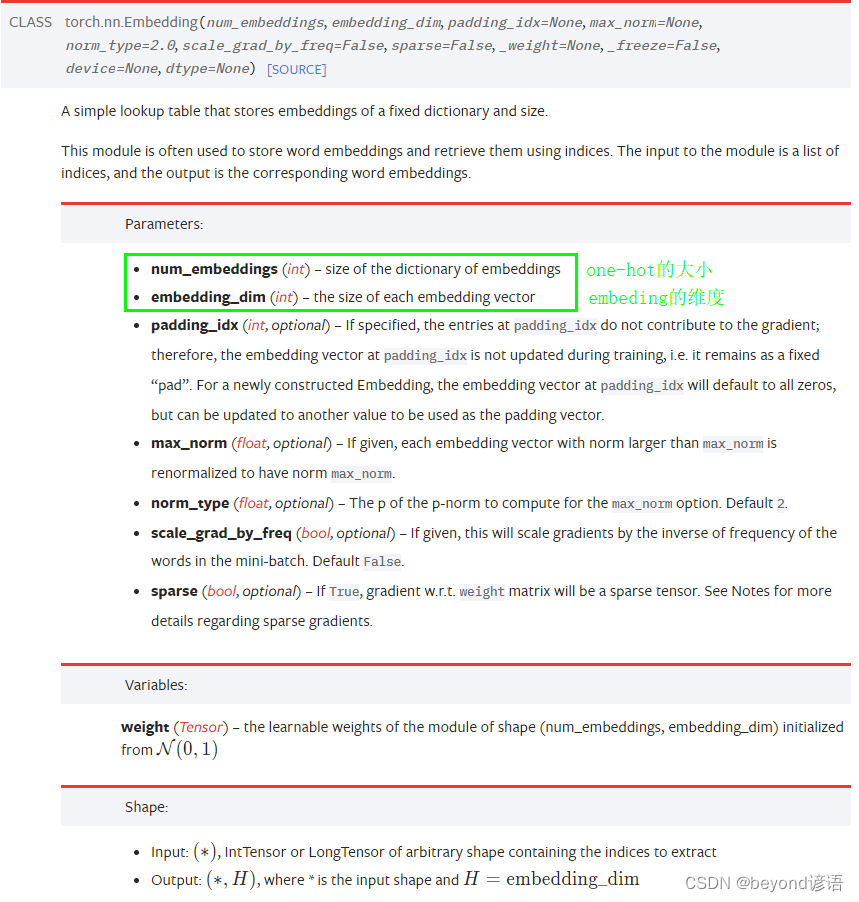
| 参数 | 含义 |
|---|---|
| num_embeddings | one-hot的维度 |
| embedding_dim | embedding的维度 |
| Input: (*)(∗), IntTensor or LongTensor of arbitrary shape containing the indices to extract | 输入需要是一个整型或者长整型IntTensor or LongTensor |
| Output: (*, H), where * is the input shape and H=embedding_dim | (input shape,embedding_dim ) |
网络架构
相关文章:
十三、RNN循环神经网络实战
因为我本人主要课题方向是处理图像的,RNN是基本的序列处理模型,主要应用于自然语言处理,故这里就简单的学习一下,了解为主 一、问题引入 已知以前的天气数据信息,进行预测当天(4-9)是否下雨 日期温度气压是否下雨4-…...
五子棋透明棋盘界面设计(C语言)
五子棋透明棋盘设计,漂亮的界面制作。程序设置双人对奕,人机模式,对战演示三种模式。设置悔棋,记录功能,有禁手设置。另有复盘功能设置。 本文主要介绍透明的玻璃板那样的五子棋棋盘的制作。作为界面设计,…...
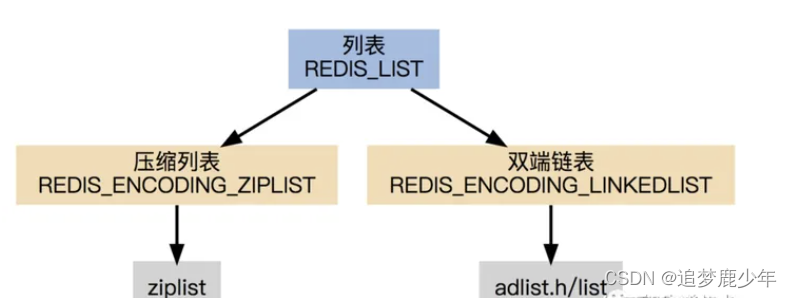
Redis第六讲 Redis之List底层数据结构实现
List数据结构 List是一个有序(按加入的时序排序)的数据结构,Redis采用quicklist(双端链表) 和 ziplist 作为List的底层实现。可以通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率 list-max-ziplist-size -2 // 单个ziplist节点最大能存储 8kb ,…...
真题,含答案解析)
电子学会2023年3月青少年软件编程python等级考试试卷(四级)真题,含答案解析
目录 一、单选题(共25题,共50分) 二、判断题(共10题,共20分) 三、编程题(共3题,共30分)...

【MATLAB】一篇文章带你了解beatxbx工具箱使用
目录 一篇文章带你了解beatxbx工具箱使用 一篇文章带你了解beatxbx工具箱使用 clc;clear; tic; % step1 初始化 % 个体数量 NIND = 35; % 最大遗传代数 MAXGEN = 180; % 变量的维数 NVAR = 2; % 变量的二进制位数 % 上下界 bounds=[-10 10-10 10]; precision=0.0001; %运算精度…...

【LinuxC Sqlite数据库小项目】基于Sqlite的打卡系统------适合初学者练手的小项目
最近小哥老是想浪,不想好好学习,这不行啊,得想点办法,多少做点努力,于是就自己给自己写了个打卡程序; 该程序基于Sqlite数据库,实现一个简单的打卡功能,该函数具有自动初始化的功能…...

在掌握C#基础上再学习C语言
C#和C语言虽然名字相似,但它们在很多方面都有很大的区别。 首先,C#是一种面向对象的语言,而C语言是过程化的语言。这意味着C#具有更丰富的语言特性,如类、接口、继承和多态性等,而C语言则更侧重于直接对计算机硬件进行…...

HTML5 <body> 标签
HTML <body> 标签 实例 一个简单的 HTML 文档,包含尽可能少的必需的标签: <!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>文档标题</title> </head><body> 文档内容…...

(链表)反转链表
文章目录前言:问题描述:解题思路:代码实现:总结:前言: 此篇是针对链表的经典练习。 问题描述: 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1…...
deb文件如何安装到iphone方法分享
Cydia或同类APT管理软件在线安装 Cydia或同类APT管理软件在线安装,这个是最佳的安装方式,因为通常无需考虑依赖关系,但缺点是对网络的要求比较高;命令行中以dpkg-iXXX.deb的形式安装,好处是可以以通配符一次性安装多个deb,而且也可以直接看到脚本的运行状况和安装成功/失…...

mongodb和mysql双写数据一致性问题
文章目录 我们是如何用MongoDB的如何保证双写一致性?先写数据库,再写MongoDB先写MongoDB,再写数据库用户修改操作如何保存数据如何清理新增的垃圾数据定时删除随机删除我们是如何用MongoDB的 MongoDB是一个高可用、分布式的文档数据库,用于大容量数据存储。文档存储一般用…...

Databend 开源周报第 88 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.com 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 Support Eager…...
Vue3学习笔记(9.4)
Vue3自定义指令 除了默认设置的核心指令(v-model和v-show),Vue也允许注册自定义指令。 下面我们注册一个全局指令v-focus,该指令的功能是在页面加载时,元素获得焦点: <!--* Author: RealRoad10834252…...
 错误)
导入 Excel 文件时,抛出 413 (Request Entity Too Large) 错误
Excel文件大小:8MB 异常信息:413 (Request Entity Too Large) 环境:IIS10PHP7.2.33 依次检查如下几项: 一、php.ini Maximum amount of memory a script may consume (128MB) 限制代码消耗的最大内存,默认128…...

Verilog学习笔记1——关键词、运算符、数据类型、function/task、initial/always、generate
文章目录前言一、关键词二、运算符三、数据类型1、基本类型:reg、wire、integer、parameter四、条件语句五、循环语句1、for2、generate六、function和task七、initial和always1、initial和always相同点和区别2、always和assign语句区别前言 2023.4.4 2023.4.7 补充…...
)
探索LeetCode【0005】最长回文子串(未搞懂,未练习)
目录0、题目1、第一个官方答案1.1 动态规划(未懂)1.2 中心扩展(已懂)1.3 Manacher(未懂)2、第二个参考答案2.1 暴力求法(已懂)2.2 反转法(未懂)2.3 动态规划&…...

使用 Docker run 命令简化容器化
使用 Docker run 命令简化容器化 Docker run 是在 Docker 容器中运行应用程序的基本命令。在开始使用 Docker 之前,了解一些重要的命令非常重要。 在本博客中,我们将解释 Docker run 命令的基本语法,并探索其一些最常见的选项,以…...
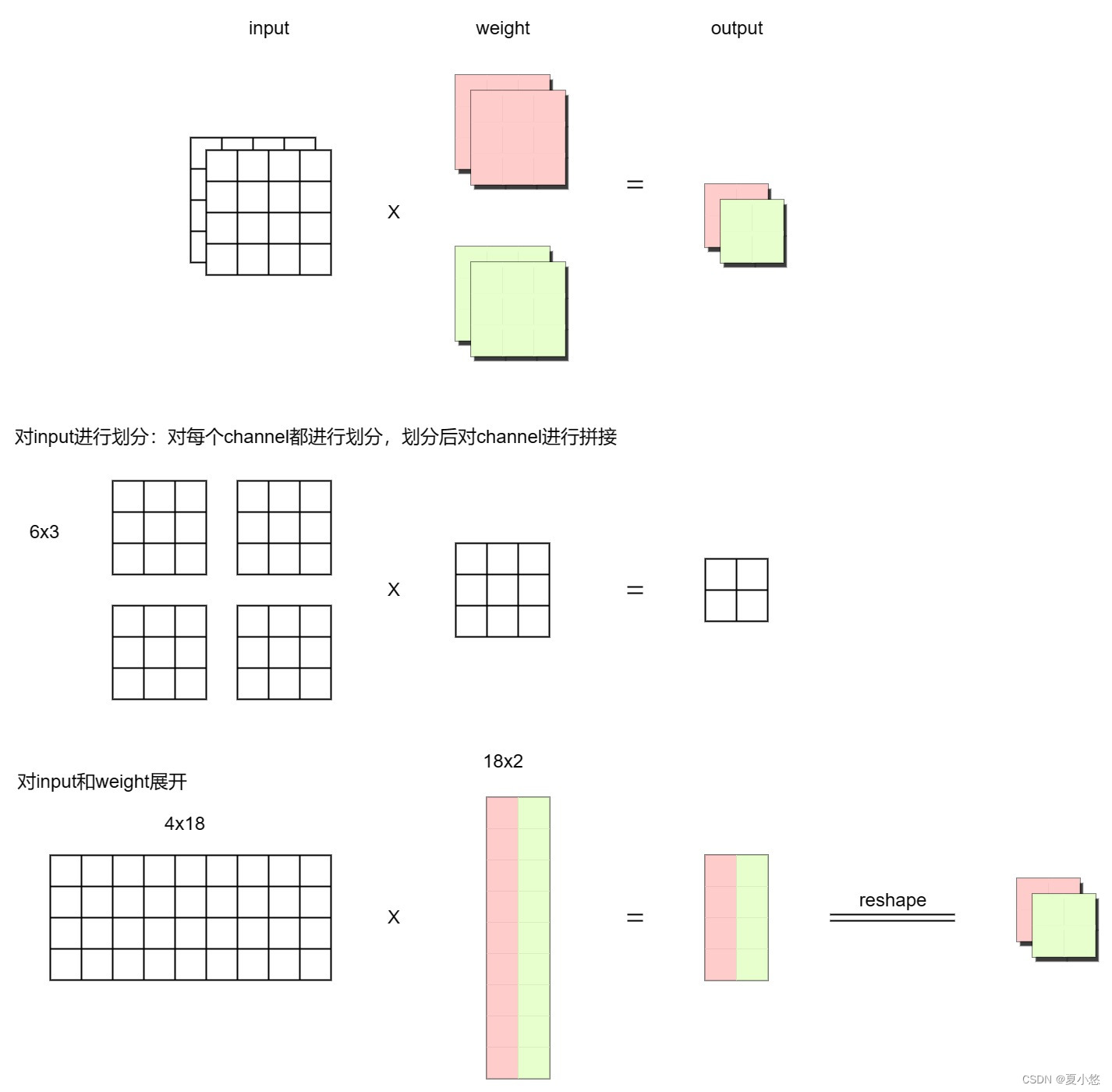
腾讯TNN神经网络推理框架手动实现多设备单算子卷积推理
文章目录前言1. 简介2. 快速开始2.1 onnx转tnn2.2 编译目标平台的 TNN 引擎2.3 使用编译好的 TNN 引擎进行推理3. 手动实现单算子卷积推理(浮点)4. 代码解析4.1 构建模型(单卷积层)4.2 构建解释器4.3 初始化tnn5. 模型量化5.1 编译量化工具5.2 量化scale的计算5.3 量化流程6. i…...

基础解惑:Linux 下文件描述符标志和文件状态标志区别
简述 文件描述符标志,是体现进程的文件描述符的状态,fork进程时,文件描述符被复制;目前只有一种文件描述符:FD_CLOEXEC文件状态标志,是体现进程打开文件的一些标志,fork时不会复制file 结构&am…...

学弟:如何在3个月内学会自动化测试?
有小学弟问:如何在3个月内学会自动化测试? 老实说如果你现在上班,之前主要在做功能测试,或者编程基础比较弱的话,三个月够呛。 如果你是脱产学习,每天能保持6~8小时学习时间的话,可…...

【硬件实战】从栅极驱动芯片到H桥:MOS管驱动电路设计精要
1. 栅极驱动芯片选型与核心参数解析 第一次用IR2104做H桥驱动时,我犯了个低级错误——没仔细看芯片的驱动能力参数,结果MOS管开关速度慢得像老牛拉车,电机发热严重。这个教训让我明白,选对栅极驱动芯片是H桥设计的首要任务。 目前…...
)
告别原生标题栏!用Qt 6.x打造一个可拖拽、可美化的自定义标题栏(附完整源码)
Qt 6.x自定义标题栏实战:从零构建高颜值可拖拽界面组件 当你在开发一款专业级桌面应用时,系统默认的标题栏往往会成为整体UI设计的短板。不同操作系统下的标题栏风格各异,无法与应用主体保持视觉统一,更难以实现个性化的交互效果。…...

思源宋体TTF完全指南:7种字重免费使用,打造专业中文排版
思源宋体TTF完全指南:7种字重免费使用,打造专业中文排版 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版找不到合适的免费字体而烦恼吗ÿ…...

apk 包管理器完全指南:Alpine Linux 的轻量级利器
一、apk 体系架构全景 apk(Alpine Package Keeper)是 Alpine Linux 的核心包管理工具,与 Debian 的 APT 相比,它遵循极简主义设计哲学:代码量少、依赖解析简单、资源占用极低。这使得 Alpine 成为 Docker 容器的默认基…...

通用 Agent 与领域 Agent 的架构差异
从GPT-4o到AI程序员助手:通用Agent与领域Agent的核心架构差异及选型指南 摘要/引言 你有没有试过同时用两款截然不同的AI工具帮你干活?比如前一秒用GPT-4o对着一张写满Python报错的截图问“为什么我的分布式爬虫在Kubernetes集群里总是崩溃”,后一秒打开Cursor编辑器的AI助…...
)
NotebookLM大纲自动生成正在淘汰传统笔记法(内部白皮书泄露:Google Labs 2024 Q2 A/B测试结果首次公开)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM大纲自动生成正在淘汰传统笔记法(内部白皮书泄露:Google Labs 2024 Q2 A/B测试结果首次公开) Google Labs 2024年第二季度A/B测试数据显示,启用…...

林调报告生成慢?文献综述耗时长?NotebookLM林业科研加速器已上线,72小时实测效率提升3.8倍
更多请点击: https://kaifayun.com 第一章:NotebookLM林业科学研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,专为深度阅读与知识整合设计。在林业科学研究中,它可高效处理林学文献、野外调查报告、遥感数据说明书、…...

终极指南:使用Wand-Enhancer免费解锁WeMod高级功能
终极指南:使用Wand-Enhancer免费解锁WeMod高级功能 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer WeMod作为最受欢迎的游戏修改工具之一&am…...

Citra 3DS模拟器:在电脑上重温任天堂掌机经典的完整指南 [特殊字符]
Citra 3DS模拟器:在电脑上重温任天堂掌机经典的完整指南 🎮 【免费下载链接】citra A Nintendo 3DS Emulator 项目地址: https://gitcode.com/GitHub_Trending/ci/citra 想要在Windows、macOS或Linux电脑上体验《精灵宝可梦XY》、《塞尔达传说&am…...

RK3588 ARM开发板KVM虚拟机搭建与性能优化实战指南
1. 项目概述:为什么要在RK3588上折腾虚拟机?最近几年,国产芯片的势头越来越猛,尤其是在嵌入式和高性能计算领域。RK3588这颗芯片,作为瑞芯微的旗舰级SoC,凭借其8核CPU(4xA76 4xA55)…...