Memcache论文总结——Lec16
文章目录
- 一、相关名词
- 1.mcrouter层
- 2.GUTTER SERVER
- 3.mcsqueal
- 4.remote mark
- 二、当流量增长了如何SCALE 你的网站?
- 三、背景及业务特点
- 1.读多写少
- 2.FB需求:
- 3.之前情况
- 四、简介
- 五、FaceBook的架构
- 五、Cache Policy
- 六、In a Cluster : Latency and Load
- (一)Reducing Latency
- (二) Reducing Load
- 1.Lease
- (1)stale set 过期写入
- (2) Thundering herds 惊群
- 2. MemcachePools
- (三)Handling Failures
- 七、In a Region: Replication
- (一)Regional Invalidations
- (二) Regional Pools
- (三)Cold Cluster Warmup
- 八、Across Regions: Consistency
- 九、memcache的一致性
- 十、总结
一、相关名词
1.mcrouter层
FACEBOOK提供了一个mcrouter层,CLIENT对所有请求构建一个DAG,找到可以合并发送的请求发送给mcrouter,让他来分发出去。
降低数据包率:如果直接将失效缓存消息发送会浪费网络资源,因此需要将缓存失效消息批量发送给每个前端集群中的mcrouter,再由mcrouter转发给集群内的服务器。
是memcache 客户端(sdk 与 proxy)的一部分,代理proxy被称为 mcrouter。
2.GUTTER SERVER
他们是一组IDLE的SERVER,用户使用他们只当MC SERVER挂了的时候。
系统设置了少量称为Gutter的机器来暂时管理不可用机器的键范围,Gutter中的数据有效期很短,这样避免了需要使缓存失效的操作。
3.mcsqueal
存储集群保存着最新数据,用户请求将数据副本写入到前端服务器。存储集群负责发送缓存失效命令,来保持数据的一致性。对数据产生修改的SQL会附上需要失效的mamcache键,应用更改之后由mcsqueal将缓存失效消息发送给各个前端集群中的服务器。
利用 DB 数据的更新日志来保证数据在不同集群间的最终一致性。
squeal/skwiːl/告密,尖叫声
4.remote mark
FB解决REGION间的主从不一致,通过"remote mark"
C1 DELETE()的时候,如果是主, 使用mcsqueal传输失效消息可以避免失效信息先于数据更新到达。(因为mcsqueal 这个daemon是监听DB的COMMIT消息)
如果是非主,当Web务器更新键值k时:
在从region , delete()时,这个K上写一个"remote mark"
如果C1 get()的时候,发现了这个标记,就去master那读,而不是自己的LOCAL DB。
随后去主region进行UPDATE,然后复制数据到从DB,这个时候这个标记会被清除。
二、当流量增长了如何SCALE 你的网站?
1.在最开始的时候我们搭建一个站点,可能就一台机器里面包含了WEB SERVER,Application和DB(如MySQL)。 DB就把数据存在硬盘里。application 去查询 db随后渲染HTML。当流量开始增长,你的PHP Application要消耗更多CPU,单机无法承受,这通常这就是他们所遇到的第一个性能瓶颈。所以,你所需要做的就是为你的PHP脚本提供更多的服务器资源。
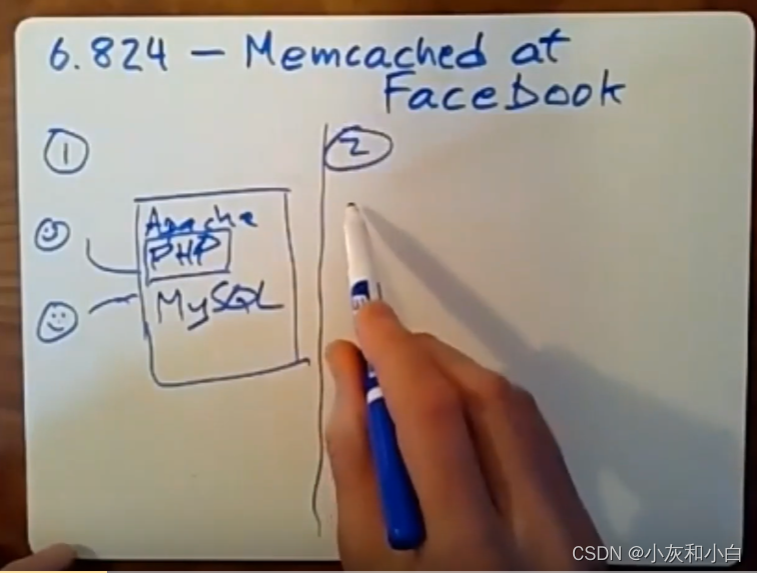
2.我们转向了第二种网站架构—— 多个WEB SERVER, 一个共享的数据库。
用户大量增多,需要更多的CPU处理能力来执行PHP脚本。所以运行了一堆前端服务器(下图中的FE),它们只负责运行和用户浏览器进行通信的web服务器。这上面运行着Apacheweb服务器以及PHP脚本,所有这些前端服务器都需要看到相同的后端数据。为了做到这点,这里你可以放一个数据库服务器(下图最右侧的MySQL)。流量增长,我们只需要加更多WEB SERVER直到DB成为瓶颈。
当使用一个服务器来运行MySQL时,它用来处理所有来自前端服务器对数据库的查询,更新,读取以及写入请求。如果使用两个数据库服务器,并将你的数据以某种方式分散到多个数据库服务器中时,情况就会变得更为复杂。你就需要关心是否要使用分布式事务,或者该PHP脚本应该通过哪种方式来确定它要和哪个数据库服务器进行通信。
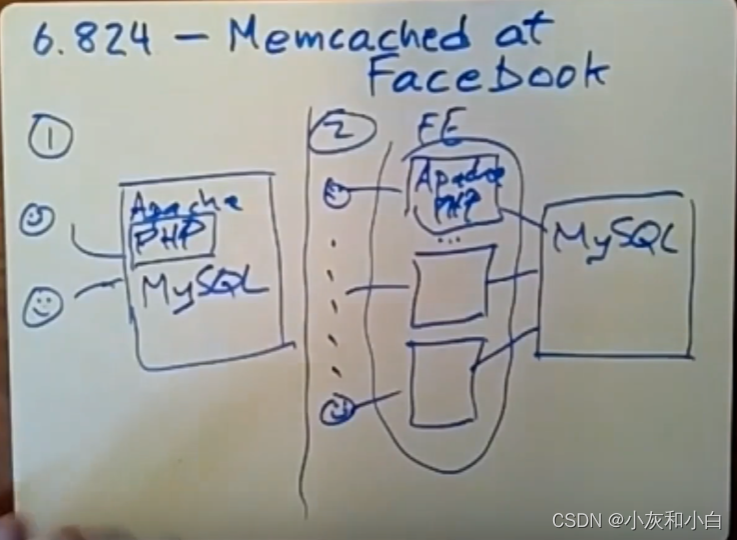
3.大型网站的一种标准演变,下面要转向web架构3——水平扩容
数据根据SHARD KEY散落在不同的DB上。 APP 根据SHARD KEY去查询对应的DB(如下图第一个数据库服务器上保存的是key从a到g的相关数据,第二个数据库服务器上保存的是key从g到q的相关数据,以此类推)。 只要没有单个KEY是超级火爆的,负载就会被均匀的分散。
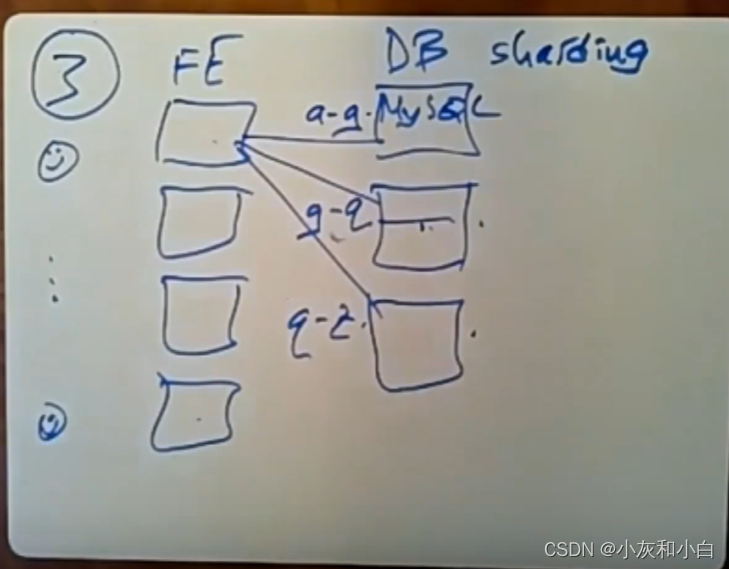
但是数据分片带来了额外开销:①需要对前端服务器上的软件进行修改让PHP代码知道数据分片相关的信息。②对于事务会需要用到两阶段提交或者一些其他分布式事务方案,速度很慢。
这种方案,成本高,速度慢,还会有热点问题。所以我们无须花大量的钱来添加另一台运行着MySQL的数据库服务器,可以在同一台服务器上面运行缓存memcached。在相同的硬件上,使用缓存每秒读取的数据量要比使用数据库多得多。
总结:为了更好的解决流量增长时的网络架构面对的db访问瓶颈,出现了memcached.
4.Facebook的架构
现在我们的架构变成很多WEB SERVER, 很多CACHE SERVER提供读服务,还有很多DB支持写。
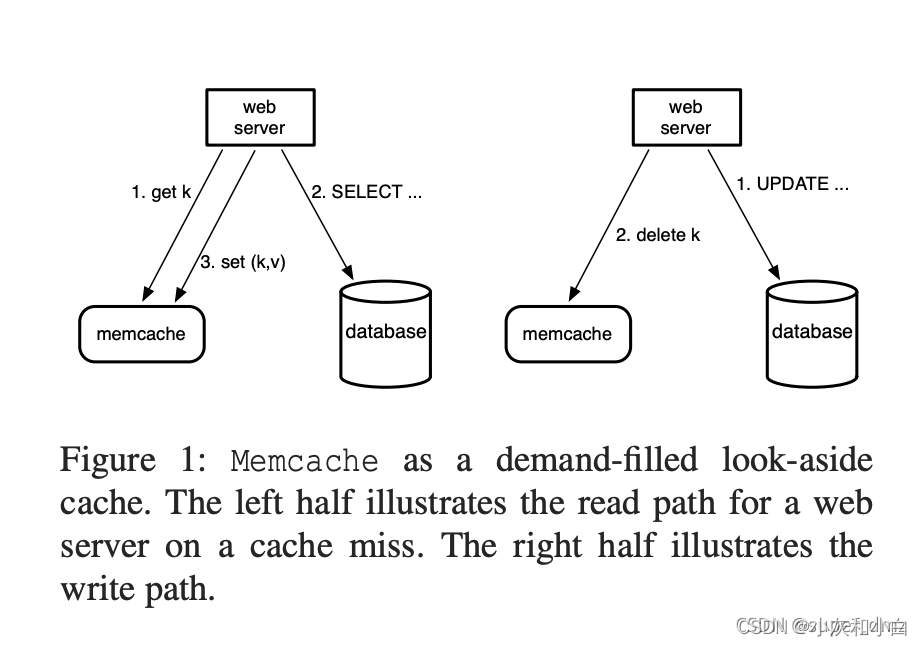
在前端服务器和数据库服务器之间有一个缓存层memcached。当前端服务器需要去读取一些数据,它会往其中一个memcache服务器发送一个携带某个key的get请求。memcache服务器会去检查它内存中的一张表(大型hash table)中是否有这个key,如果有的话,它就会将对应的数据返回给前端服务器。
如果并未命中memcache服务器中的缓存,那么前端服务器就得将请求重新发送给相关的数据库服务器。为了之后的请求,前端服务器会发送一个put请求并携带它从数据库中所拿到的数据给memcache服务器。
(注:读——memcache, 写——数据库)
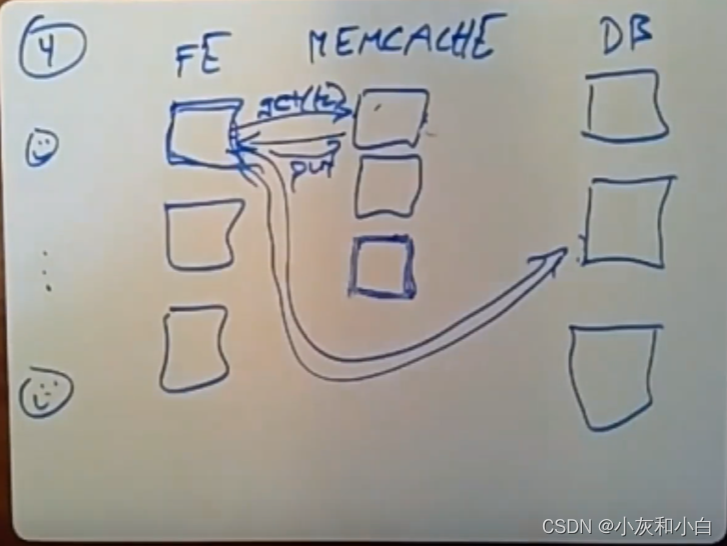
(1)问题:当读memcache miss时,为什么是前端服务器发送put请求写入memcache,而不是memcache在miss时,转发给db,并将db的响应缓存起来?
不能这样做的原因是,memcache就像是一个完全独立的软件,它对数据库一无所知。虽然我们经常将它和数据库放在一起使用,但我们无法将数据库的知识应用到memcache中。
更深层次的理由是,前端服务器会对从db得到的结果进行某种处理(它可能需要花几步来将结果转换为html,或者,它会从数据库的多行数据中获取结果,并将部分处理过的信息缓存到memcache中,以此来节省下一个要执行相同操作的reader所要花的时间)。所以,memcache并不理解前端服务器想看到哪些缓存数据,以及你是如何从数据库中衍生数据的。这些逻辑都是放在前端服务器中的php代码里的。
所以,从架构上来说,这是一个很不错的想法,但我们不能做这种整合,即让memcache和数据库之间直接进行通信,虽然这会让缓存一致性变得更为简单。
(总结:web服务器可能需要的并不是数据库中的原始数据,而是经过处理的html或整合后的结果,会向memcache中存储处理后的数据,所以不能直接由memcache与数据库交互来保存数据)
(2)问题:look-aside cache和look-through cache间的区别是什么?
look-aside cache的作用是,前端服务器会先查看数据是否存在于缓存中,它会从数据库中获取未缓存的数据。如果使用的是look-through cache,那么就会通过memcache将我的请求转发给数据库,让数据库来处理响应(即memcache与数据库有交互)。
(总结:数据同步时,look-aside cache是以前端服务器为中心,look-through cache是以memcache为中心)
memcache流行的部分原因是,它使用的是look-aside cache,让web服务器作为中间方来对memcache中的数据和数据库中的数据进行操作,即memcache不直接与数据库进行交互,通过web服务器来和数据库进行交互。
三、背景及业务特点
1.读多写少
与大部分互联网公司的读写流量特点类似,FB 的整体业务呈现出明显读多写少的特点,其读请求量比写请求量高出 2 个数量级 (数据来自于https://www.usenix.org/sites/default/files/conference/protected-files/nishtala_nsdi13_slides.pdf、 slides),因此增加缓存层可以显著提高业务稳定性,保护 DB。
2.FB需求:
Facebook作为社交网络服务基础设施,需要满足:
- 近似实时通信;
- 实时聚合多个来源的内容;
- 读取/更新热点的共享内容;
- 可伸缩以处理billion级用户并发。
为满足以上需求,Facebook从单机(memcached)、集群(cluster)、区域(region)、跨区域(cross-region)这4个方面以bottom up的方式讲述他们是如何scale的。
3.之前情况
在使用缓存层之前,FB 的 Web Server 直接访问数据库,通过 数据分片 和 一主多从 的方式来扛住读写流量:
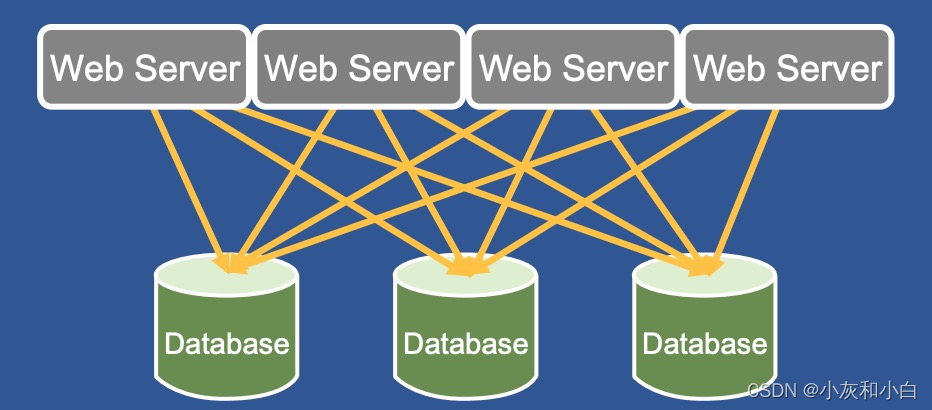
但随着用户数数量飙升,单纯靠数据库来抗压成本高,效率低。
四、简介
1.Scaling Memcache at Facebook是Facebook团队2013年的一篇论文,讲述Facebook如何使用开源的memcached构建分布式内存KV集群,使用memcache来处理海量的工作量(这里指的memcache和下文的memcacheD,说的都是运行着memcacheD的服务器)。
这篇paper中存在着很多可以借鉴的经验,它里面并没有任何新的概念或者想法或者技术之类的东西,当那些公司试着去构建具备高负载能力的基础架构时,他们就会去使用这篇paper中提到的这些方法。
2.Memcached是一个简单的内存cache组件,支持低延迟低成本的内存访问。
3.Memcached提供的是一个纯内存的哈希表访存服务,支持键值对的存储模式,提供的基本接口为put, get, delete。
五、FaceBook的架构
1.在进入正文之前,需要厘清以下概念(见Figure 2):
- memcached:开源memcached技术,在文中指运行时的单台实例;
- cluster:指多台memcached组成的最小单位的集群,memcached之间相互不通信,由client端使用consistent hash将数据分布到多台memcached;
- region:多web server集群和多cluster集群组成frontend clusters,共享一个storage cluster组成一个region;
- cross-region:多个region,每个region分布在不同地理位置。只有一个region的storage
cluster是master角色,其他的是slave角色,从master同步数据。
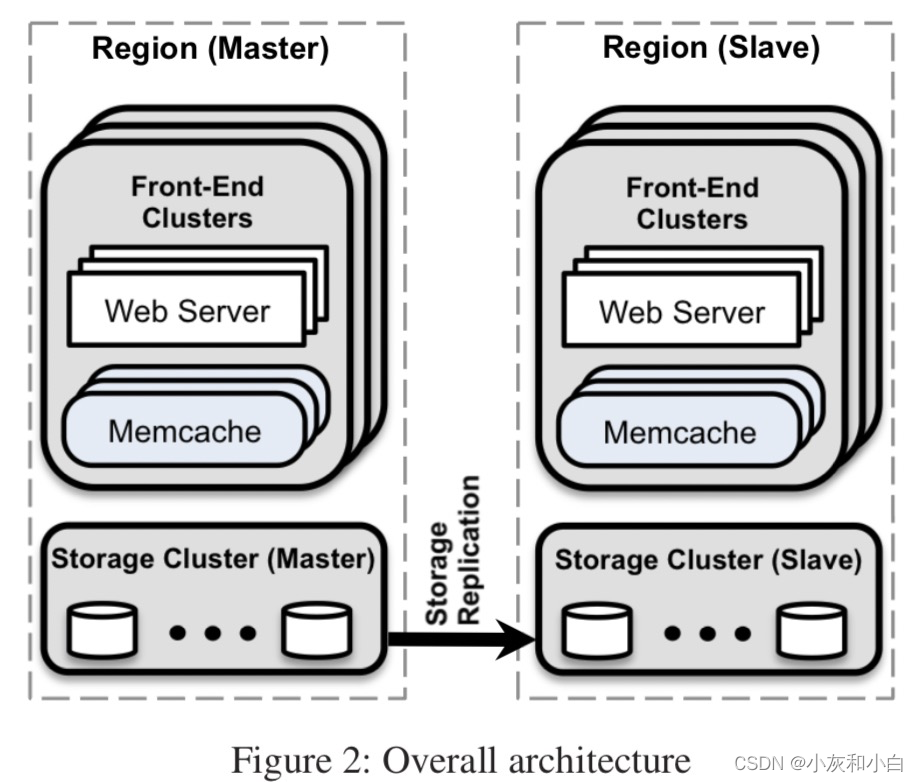
2.如上图所示,一个region对应一个数据中心,单个region内有多个cluster的replica。
在部署规模上,单cluster是对应了10^3量级的memcached server,数据使用一致性哈希分布于各个memcached中(通过对key进行hash来将我们的数据拆分到可用的memcache服务器上)。
一个用户与单个web server通信请求服务,每个前端服务器只和一个memcache服务器进行通信。
3.他们是通过并行执行来做到高性能的。对于存储系统来说,从高级层面来讲,可以通过两种途径来获得不错的性能,其中一种是通过分区(partition),即对数据分片,并分散到10台服务器上,我们希望这10台服务器可以独立运行。另一种方式就是replication(复制),使用额外的硬件来获取更高的性能。
实际上对于memcache,Facebook将分区和复制这两种技术结合起来使用,分区的优点是内存效率(Ram efficient),因为你只保存每个item的一份副本。然而,使用复制技术的话,你会在每台服务器上都保存该数据的一个副本。分区的缺点在于热点问题(not good for hot keys)。分区的另外一个缺点是,每个前端服务器可能要和大量的分区进行通信(clients talk to every partion),因为取的内容可能在不同的分片。
复制优点是有利于热门key(good if hot keys)。每个前端服务器可能只和一个memcache服务器进行通信(few TCP connections)。但缺点是,每个服务器上都留有一份数据副本,通过复制服务器要保存的总数据量就会变得更少**(less total data)。
这就是通过这两种途径使用额外的硬件来获得更高性能时的一些利弊。
注:复制在有一些KEY特别火爆的时候工作的很好。因为他可以把流量均摊出去。

3.从最高层的LEVEL开始说,首先是REGION,REGION是主从结构**。也就是说主负责读写,从只负责读,从通过日志来复制主的写。写请求都要通过主的,随后用复制日志去同步给从REGION(MySQL提供了一种异步日志复制的机制)。
讲完了最上层,我们再看进去。
一个REGION里 有多个front-end 集群,和一个存储集群。 注意集群和集群间的数据是完全等价的。当然REGION 和 REGION间的数据也是完全一致的。这里都是用的复制策略,而不是SHARD策略。而在一个集群里多个WEB SERVER和多个MEMCACHE是SHARD的。 然后多个前端集群共享一个存储集群,存储集群里,多个DB是水平扩容,也就是SHARD的。
(总结:region间完全复制,cluster之间完全复制,web server和memcache是shard,存储集群之内多个DB是shard)
4.为什么有些是复制,有些是SHARD的呢?
从最高层面来看,他们是在不同区域间使用复制和数据分片这两项技术。
(1)regin之间——复制
每个区域中都有一份关于所有数据的完整副本。每个区域中,他们都有一组完整的数据库服务器,是为了让不同位置的用户能够访问距离最近的数据库副本。另外一个原因是,让前端服务器始终能尽可能靠近它们所需要的数据。
例子:假如我们在这两个区域间数据进行拆分(下图中的WEST和EAST数据中心),接着,如果我去查看我的好友列表,其中一部分好友是在东海岸,另一部分是在西海岸,这就可能会需要让前端去发起多个请求(向另一个数据中心发送请求并得到响应需要花50毫秒),用户会注意到这种延迟。
这使得写操作的成本变得更高。如果这个前端服务器是位于第二数据中心,它需要去执行写操作时,它就得通过网络将数据发送给第一数据中心。但是执行读操作的频率要远远高于写操作。所以从设计上来讲,这是一种很好的取舍。
虽然paper并没有提到这一点,对两个数据中心的数据进行完全复制的另一个原因是为了容灾。
(总结:paper中,FB在不同区域之间采取的是复制策略。1.获取不同的key减少时延。2.前端服务器靠近数据。3.容灾)
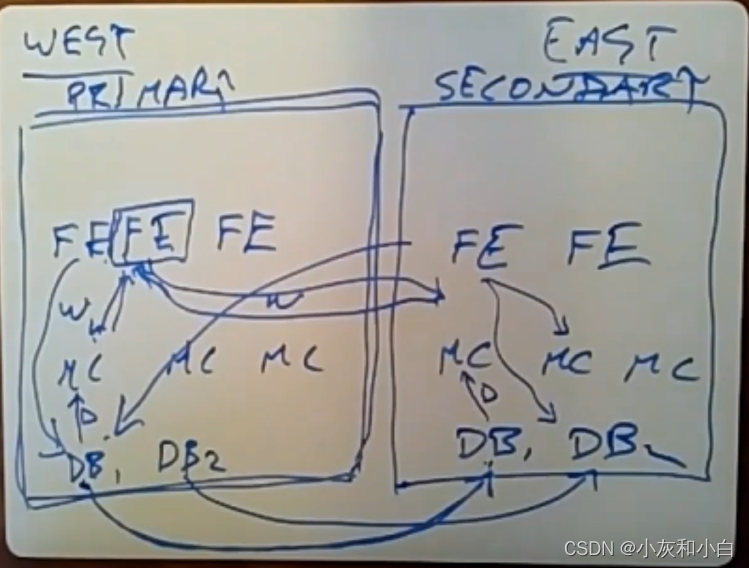
注:MASTER REGION 会把自己的数据复制到非MASTER REGION,这仅仅涉及到存储集群的交互,对上层的前端集群无感知。
(2)region内部
在每个数据中心中,他们都放了一组数据库服务器(下图最下端DB1、DB2。。。)。从数据库层面来讲,数据被分片,并且,在每个region中,我们并没有对它们进行复制。
但是,从memcache的层面来讲,实际上,它们既使用了复制,也使用了数据分片。他们有一个关于集群cluster的概念,在一个给定的区域,它实际上是支持拥有多个(前端服务器和memcache服务器的)集群。下图有2个集群,这两个集群几乎是完全独立的。集群1中的某个前端服务器将它所有的读操作发送给本地(该集群内)的memcache服务器,此时,并没有命中缓存,它就得需要去其中一个数据库服务器组中获取数据。类似地,该集群中的每个前端服务器只会和该集群下的memcache服务器进行通信。
(总结:数据库在每个region中是分片的。memcache和前端服务器FE在cluster之间是复制,在cluster内部是分片)
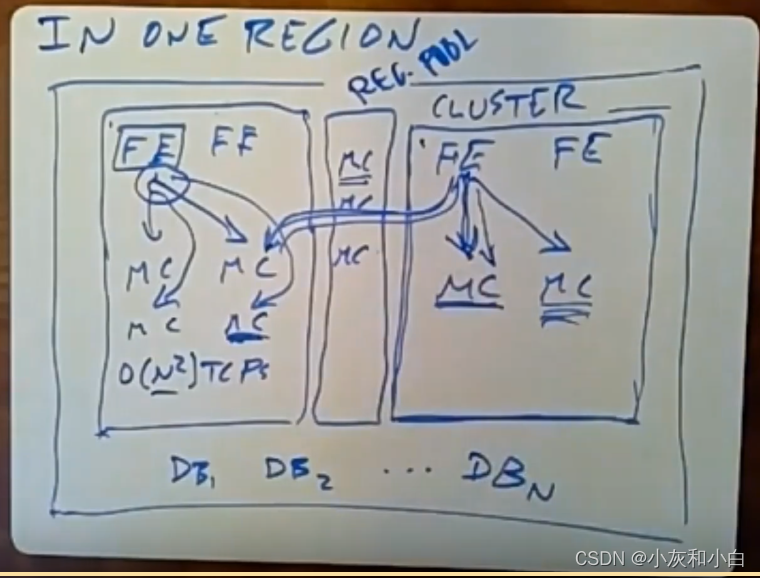
问题:为什么使用多集群而不是单集群?
每个集群下有一组前端服务器以及所有前端服务器所共享的一组memcache服务器。如果是单集群要提高处理能力,往同一个集群中添加更多的其他memcache服务器以及前端服务器(很多的memcache和前端处理器都在同一个集群中)。性能上热门key所对应的数据没有提升,而多集群可以通过复制并行提供热门key对应的数据。
另外一个不想让单个集群变得太大的原因是,该集群内所有的数据都会被拆分到所有的memcache服务器上。通常任意前端服务器可能会从每个memcache服务器上获取它们所需要的数据。这意味着在前端服务器和memcache服务器间,你会拥有N^2个通信连接,他们使用TCP来进行通信,这会产生大量的性能开销以及要去维护所有不同TCP连接的大量状态。他们想对此进行限制,的解决方法就是不让任何集群的体积变得过大。另外,业务繁忙时,前端收到的memcache服务器返回的响应太多,会导致数据包丢失。
paper提到的最后一个原因是,如果一个region是单集群,网络维持太难。
(总结:不用单集群原因:1.会有很多memcache和前端处理器都在同一个集群中。2.对hot key性能没有提升。3.集群内memcache是分片策略,每个FE需要与所有memcache通信,限制通信量。)
5.memcache使用look-aside cache的一些细节
look-aside cache:对于读操作,前端服务器调用库中所提供的get传入要读取的key生成一个RPC请求,并将该请求发送给相关的memcache服务器。它们会对传入的这个key进行hash,以此来选择要进行通信的memcache服务器,memcache服务器会回复Yes和要读取的数据,或者memcache服务器返回No。如果v是nil的话(下图READ中第二行),那么前端服务器就会向数据库发送用来获取该数据的SQL查询。接着,它会将另一个RPC请求(put)发送给相关的memcache服务器,并将获取到的数据放入这个memcache服务器。
对于写操作来说,我们要往write中传入一个key和一个value,让前端服务器将新数据发送给数据库,数据库中所保存的数据的形式可能和memcache中所保存的形式有所不同。但现在,我们假设数据库和memcache服务器中保存的数据形式是一样的。一旦数据库拿到了新的数据,接着,通过调用write操作来发送一个RPC请求给memcacheD,并告诉它请删除这个key所对应的数据,writer会让memcacheD中与这个key所对应的数据失效。下一个试着从memcacheD中读取该key的前端服务器所拿到的是nil,它会从数据库中获取更新后的值,并将它放入memcacheD中。So,这就是失效策略(invalidation scheme)。
实际上,在Facebook所使用的策略中,我们需要这个delete操作的真正原因是,前端服务器会看到它们发出的写请求所更新的结果。事实上,在他们的策略中,数据库服务器也会给memcache服务器发送delete操作,当任意前端服务器往数据库中写入数据时。正如paper中提到的,(具备mcsqueal机制)数据库会将相关的delete操作发送给持有该key数据的memcache服务器。所以,数据库服务器会让memcache中保存的数据失效。前端服务器也会删除这些key相关的数据,前端服务器在它刚刚更新过这个数据后,它不会看到该数据以前的值。这就是大家平时使用memcacheD的方式。

6.问题:当我们把对主MySQL数据库所做的更新操作复制到副数据库时,副数据库是否也要向memcache服务器发送delete操作?
是的。当一个前端服务器发送了一个write操作给数据库服务器,数据库服务器会更新它保存在磁盘上的数据,它会向本地数据中心里保存着刚刚更新过的这个key所对应数据的memcache服务器发送一个用于数据失效的delete操作。数据库服务器也会向其他数据中心中与它相对应的那个数据库服务器发送这个更新操作,它会对磁盘上的数据执行这个写操作。它会去使用mcsqueal机制来读取日志,以此弄清楚哪个memcache服务器可能持有着刚刚更新过的这个key所对应的旧数据,并将这个delete操作发送给这个memcache服务器。所以,如果这个key被缓存在memcache服务器中,那么通过这个delete操作,这两个数据中心中的memcache服务器中这个数据就会失效。
7.问题:在我们执行write操作时,如果我们先执行delete,再将数据发送给数据库时,这会发生什么?
我们来看下图WRITE(k,v)部分的代码,假设你先进行delete操作,然后再将要写入的数据发送给数据库。此处(下图笔尖处),如果有另一个client读取了同一个key所对应的数据,此时就会发生缓存未命中的情况,它们会从数据库中接收到旧数据,接着,它们会将该数据插入memcache。当你去更新这个数据时,memcache中的过时数据还会被保留一段时间,接着,如果这个进行写操作的client再次读取了这个数据,它可能会看到过时的数据,即使它刚刚更新了数据。
实际上的write操作我们是在第二步的时候执行了delete操作(下图WRITE左侧的代码)。有人可能会在这段时间内读取数据,他们所看到的数据都是过时的。但它们并不担心看到的是过时数据,在这个情况下,他们最关心的是client读取它们自己所做的写操作的值。虽然这里存在着一致性问题,我这里第二步所做的delete操作是为了确保client能读取到它们自己写操作所更新后的值。不管在哪种情况下,数据库服务器最终会将一个与写入key相关的delete操作发送给memcache。
总结:为什么需要delete?主要是client更新后能马上读到它自己修改后的最新数据

8.问题:既然client已经知道了新数据,为什么我们不让它直接发一个setRPC给memcache呢,而是使用一个delete操作呢?(下图左下处的set方法)
这里我们使用了一个失效策略(invalidate scheme),这通常也被叫做更新策略(update scheme)。

例子:假设Client1向数据库发送命令,把x值从0变成1(下图第一行C1处)。之后,Client1会调用set命令(下图左下C1处)传入x和它的值1,并将结果写入memcacheD。
此时Client2也想增加x的值,它会从数据库中读取最新的值。为保证正确性,client就会将一个用于增加x值的事务发送给数据库,因为数据库支持事务。假设Client2将数据库中的x的值设置到2,之后Client2也会去执行这个set操作(下图右侧C2处),它会将x设置为2。但现在memcacheD中x的值是1,虽然数据库中正确的值是2。
如果我们使用这个set操作来更新memcache的数据(如下图左侧C1),虽然它确实能避免以后有人请求这个数据时缓存未命中的情况。但我们会冒着这种风险,即数据库中热门数据的值是过时的(因为网络的因素,set(x,1)可能比set(x,2)要后执行,所以会产生过时垃圾数据)。这就是他们使用失效策略而不是去使用更新策略的原因了。
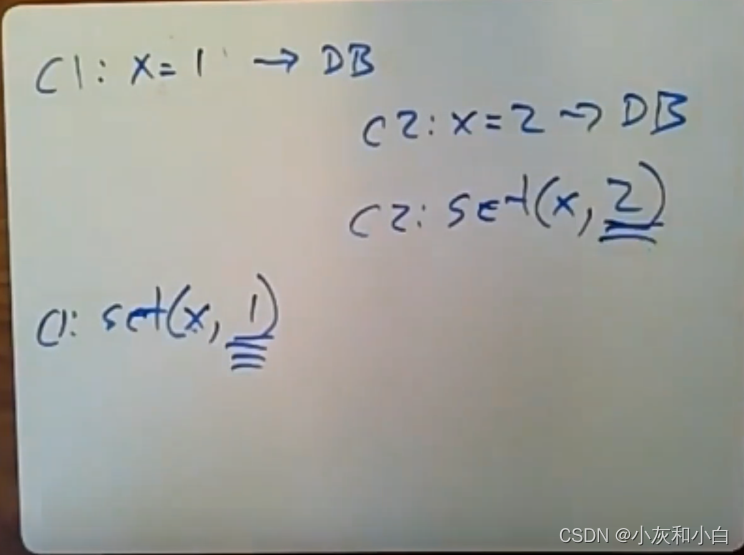
五、Cache Policy
1.memcache 的 cache policy 可以用 2 个词概括:
demand-filled look-aside (read) 按需后备
write-invalidate (write)
读请求:首先从memcache查询数据。如果cache里没有数据,就从后台的database获取数据,并把key-value pair更新到cache中。
写请求:首先对database进行修改,然后向cache发送请求,invalidate之前的旧数据。
采用 write-invalide 的主要原因有两个:
- 删除操作幂等,当任何异常发生时可以重试
- write-invalidate 与 demand-filled 在语义上是天作之合
2.首先缓存是加速读取,同时保护DB过载。MEMCACHE是一个look aside的CACHE,也就是说CACHE对DB无感知,不知道DB存了什么,他存的东西和DB什么关系,这一切都通过应用层CLIENT来控制。还有一种CACHE是LOOK THROUGH,就是DB负责来维护这个CACHE。
六、In a Cluster : Latency and Load
本节探讨在一个集群内部部署上千个 memcached 服务遇到的挑战和相应的解决方案。在这个规模上,系统优化的主要精力集中在如何减少获取缓存数据的时延 (latency),抵抗 cache miss 时造成的负载压力 (load)。
(一)Reducing Latency
1、缓存层扩容,FB 采用的是一种常见的扩容方案:部署多个 memcached 服务,形成单个缓存集群,并通过 consistent hashing 将缓存数据散列在不同的 memcached 实例上。
(总结:memcache的分片)
2.扇出 Fanout
在 FB 的服务中,载入一个热门的网页平均需要从 memcache 中获取 521 条不同的数据,如果出现 cache miss 则需要从持久化存储中获取数据,这些数据读取请求的时延都将影响到服务的质量。通常不同数据的读取之间存在一定的先后依赖关系,可以表示成一个有向无环图 (DAG),如下图所示:
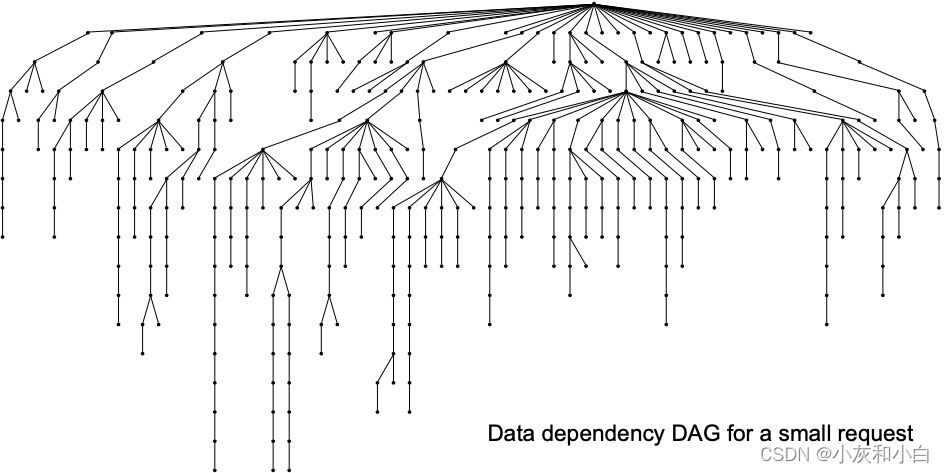
我们称这种放射状的数据读取模式为 fanout。
3.面对 high fanout,memcache 集群首先要面对的问题就是 all-to-all communication。由于缓存数据被散列到不同的 memcached 实例上,每个 web server 都可能需要与所有 memcached 服务通信:
- 由于 fanout 的存在,处理每个请求需要各个 web server 从多个 memcached 实例上获取数据,如果这些数据在短时间内忽然到来,可能造成网络拥堵,即 incast congestion 由于每个 memcached。
- 实例都持有一部分数据,这使得每个实例在高负载下都有可能成为服务瓶颈。
4.客户端的优化手段包括:
- 请求优化(Parallel requests and batching)
- 通信连接优化(Client-server communication)
- client-server通信
- 传输层连接
5.请求本身的优化主要是parallel并行化以及batching合并
Parallel requests and batching
简而言之就是要减少网络上的round trips次数
要实现这一目的可以把数据间的依赖调整为一个DAG图,由于并不存在环,因此可以并行发出请求——parallel并行化
同时在必要时合并多个请求,按照经验可以合并24个key——batching合并
(并行、打包请求memcache)
6.Client-server communication
(1)在通信层面上,memcached server间互不通信,facebook希望把所有复杂实现下放到无状态的客户端
client通过一个mcrouter的代理与server通信,即web server连接client(proxy)即可,proxy接口仍然保持和memcached server一致,这样避免了单个web server直连多个memcached server。
在缓存层上,FB 的主要思路就是将控制逻辑集中到 memcache client 上。memcache client 分成两部分:sdk 与 proxy,后者被称为 mcrouter。mcrouter 向外暴露与 memcached 相同的接口,在 web server 与 memcached server 之间增加一层抽象。
(2)在传输层上,连接尝试尽可能通过使用UDP来减少overhead。
考虑到对数据错误容忍度高,memcached client的get请求使用UDP与memcached服务器通信,减少了创建和维护连接带来的开销。一旦出现丢包或者乱序包,client会将其作为异常处理,即视作cache miss,get请求会被重传到数据库,论文中提到系统在高峰期也只有0.25%的请求会被丢弃。为了可靠性,对于set和delete,则是通过可靠的TCP通信。
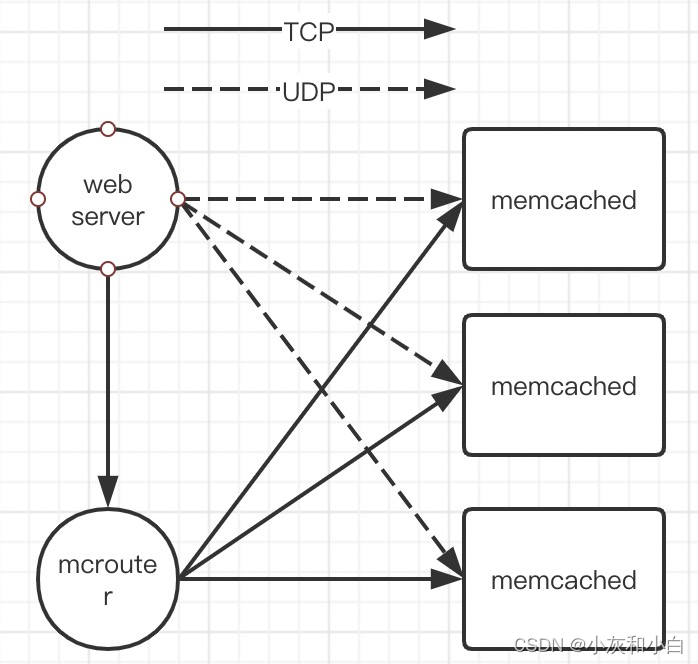
- web server client使用UDP(见图3)绕过mcrouter直接向memcached实例get数据,以实现低通信延迟。
- mcrouter负责set和delete请求(见图3),和web server结对部署,使用TCP和需要通信的memcached建立长连接。这样设计是因为set和delete请求需要TCP的可靠重试,以及不需要每个web server thread都和memcached直接建立长连接,由mcrouter统一接管减少长连接数量可节省CPU、内存、带宽。
7.Incast congestion
对于Incast congestion问题,memcached的client实现了类似TCP的拥塞控制逻辑,根据网络情况控制滑动窗口。
相比TCP不同在于来自同一个web server的请求会放入到同一个窗口(而不是维护单连接的窗口):当超出窗口范围时,主动拒绝响应,避免级联压垮server.
(二) Reducing Load
为了减轻负载,论文提到了三种技术:Leases、Memcache Pools、Replication with int Pools
1.Lease
FB 在 memcache 中通过引入 leases 来解决两个问题:stale set过期写入、thundering herds惊群。
(1)stale set 过期写入
look-aside cache policy 下可能发生数据不一致:
假设两个前端服务器x 和 y,需要读取同一条数据 d,其执行顺序如下:
a.x 从 memcache 中读取数据 d,发生 cache miss,从数据库读出 d = A
b.另一个 memcache client 将 DB 中的 d 更新为 B
c.y 从 memcache 中读取数据 d,发生 cache miss,从数据库读出 d = B
d.y 将 d = B 写入 memcache 中
e.x 将 d = A 写入 memcache 中
此时,在 d 过期或者被删除之前,数据库与缓存内的数据将保持不一致的状态。引入 leases 可以解决这个问题:
每次出现 cache miss 时返回一个 lease id,每个 lease id 都只针对单条数据
当数据被删除 (write-invalidate) 时,之前发出的 lease id 失效
写入数据时,sdk 会将上次收到的 lease id 带上,memcached server 如果发现 lease id 失效,则拒绝执行
注:lease解决过期写入的问题例子见本文第九部分
(2) Thundering herds 惊群
前端服务器对热门key执行write操作时,在删除memcache中热门key和再次写回的空隙时间内,多个访问该热门key的前端服务器对DB的请求可能导致成千上万个请求同时发生 cache miss,从而重击 DB,这就是惊群效应(Thundering herd)。通过扩展 lease 机制可以解决这个问题。每个 memcached server 都会控制每个 key 的 lease 发放速率。默认配置下,每个 key 在 10 秒内只会发放一个 lease,余下访问同一个 key 的请求都会被告知要么等待一小段时间后重试或者拿过期数据走人。通常在数毫秒内,获得 lease 的 web server 就会将数据写入memcache,这时其它 client 重试时就会成功,整个过程只有一个请求会穿透到 DB。
(总结:当cache miss时,同一个key只有第一个拿到lease的请求可以到数据库)
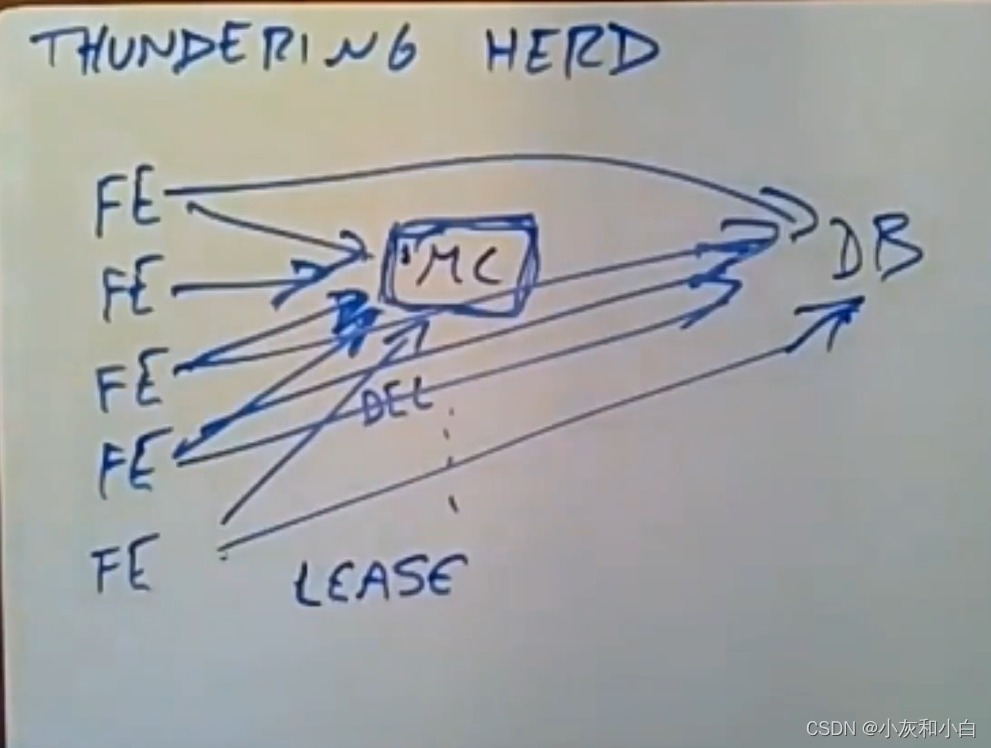
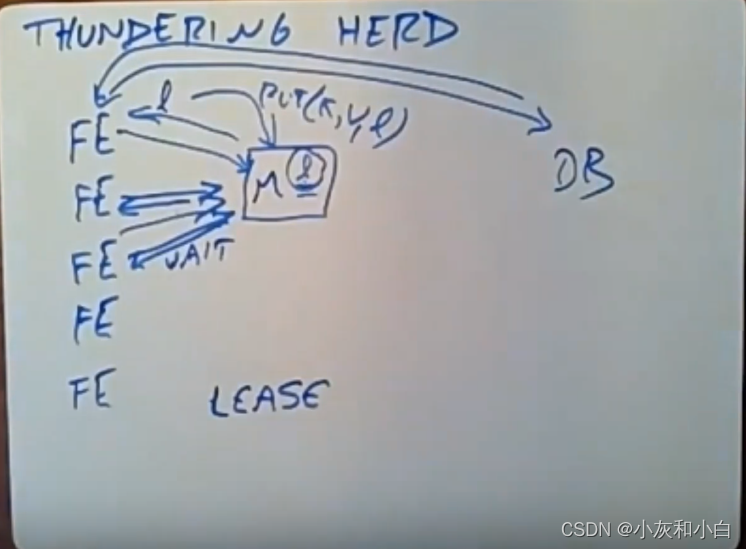
如果拿到lease的前端服务器发生了故障,它并没有向数据库请求数据,或者并没有将数据插入memcached缓存,那么memcached最终会删除这个lease,因为它超时了。接着,下一个访问memcache的前端服务器会拿到一个新的lease,它会和数据库进行通信,并往memcache中插入新的数据。
2. MemcachePools
所谓的池,指的其实是资源的分区,对于数据中的不同的访问模式,根据模式进行资源分区。例如缓存未命中的代价小,但是访问频次高的键放入一个小池,缓存未命中代价高,但访问频次低的键放入一个大池。
(三)Handling Failures
如果整个数据中心出现大面积问题,FB 会将用户请求直接转移到另一个数据中心;
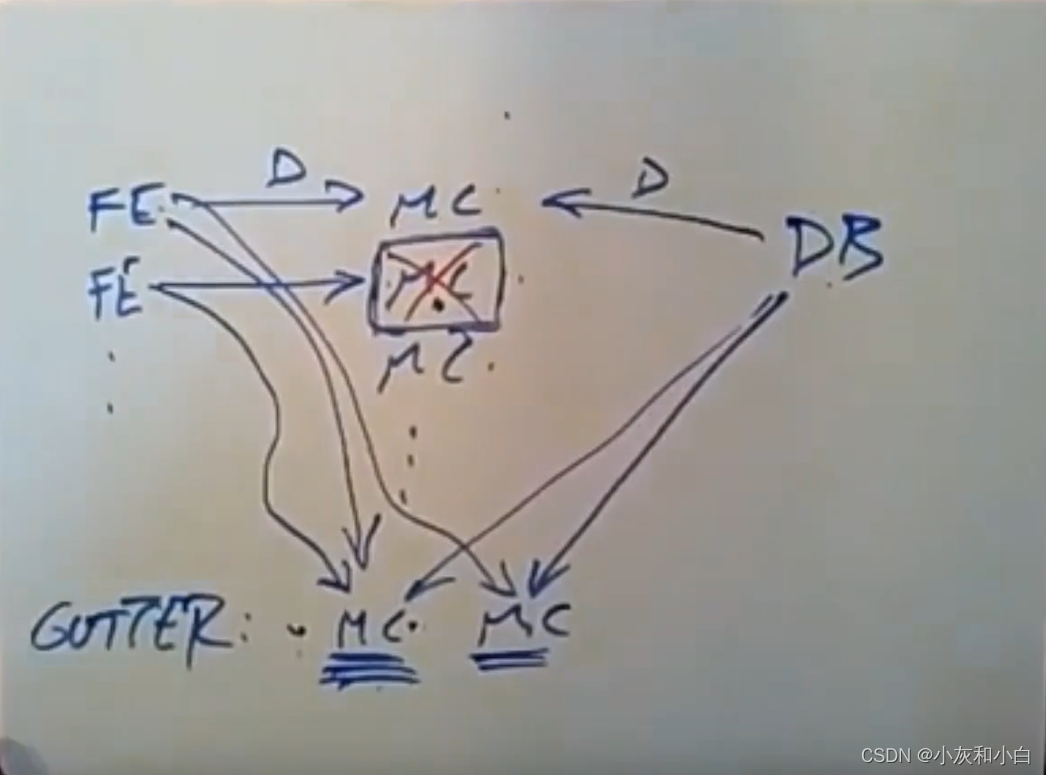
如果只是少数几个memcache server 因为网络原因失联,则依赖于一种自动恢复机制,通常恢复需要几分钟时间,但几分钟就有可能将 DB 和后台服务击垮。为此, FB 团队专门用少量的机器配置一个小的 memcache 集群,称为 Gutter。当集群内部少量的 server 发生故障时,memcached client 会将请求先转发到 Gutter 中。除了在memcache服务器出现故障的情况下,这些GutterServer都处于闲置状态。
Gutter 与普通的 rehash 不同,后者将失联机器的负载转嫁到了剩余的 server 上,可能造成雪崩效应/链式反应。
当前端服务器收到一个错误,说它们无法和memcache服务器进行通信,它会将相同请求再发给其中一个GutterServer。前端服务器会对key进行hash以此来选择它要和哪个Gutter Server进行通信(论文中未说明)。如果这个GutterServer上保存着对应的数据,前端服务器就会和数据库服务器进行通信来读取数据,并将该数据放入memcache服务器(GutterServer),万一其他人也去获取相同的数据,那就可以直接从memcache服务器处获取了。所以,当memcache服务器发生了宕机,简单来讲,这些GutterServer就会去处理原本由这个memcache服务器所处理的请求。这里会发生缓存未命中的情况(因为刚开始时GutterServer是空的),可能出现的惊群问题会由lease机制来解决。
有一个问题,前端服务器应该不会将delete操作发送给这些GutterServer。因为GutterServer可以去接手一个或多个已经挂掉的memcache服务所处理的请求,实际上,它可以去缓存任何key所对应的数据。这意味着当一个前端服务器需要从memcache中删除一个key所对应的数据时,或者数据库中的mcsqueal发送了一个delete操作给保存着某个key相关数据的memcache服务器,它也会将这个delete操作的副本发送给每一个GutterServer。即它们会将数据从memcache服务器中删除,它们也得从GutterServer中删除这些数据,这会使必须要发送的delete操作的数量增加一倍。实际上,他们对GutterServer进行了一些处理,这样他们就能快速删除这些key的相关数据,而不是等到显式删除它们的时候才去删除。这就是这个问题的答案。
(Gutter中的数据有效期很短,这样避免了需要使缓存失效的操作。)
七、In a Region: Replication
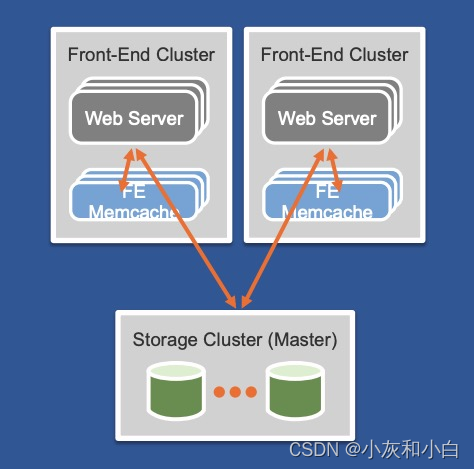
随着用户的访问量继续增大,你可能会想要购买更多的机器来部署 web server 和 memcached server,实现横向扩容。然而简单地横向扩容不能解决所有问题。越来越多的用户会将原本不严重的问题暴露出来:
- 用户增多会导致热点数量增多、单个热点热度增大
- 由于 memcached client 需要与所有 memcached server 通信,incast congestion 问题会更严重
因此有必要将 memcached servers 分成多个集群,将热点问题和网络问题分而治之。多个集群将继续共享同一个 DB 集群:
(一)Regional Invalidations
部署多个 memcached server 集群,同一条数据的不同版本可能会出现在不同集群上。一种简单的解决方案是让 web server 每次发生 cache miss 时,将所有集群中的对应数据删除。显然这会造成大量的跨集群通信,又重新引发了网络问题。
既然数据在 DB 中只有一份,何不利用 DB 数据的更新日志来保证数据在不同集群间的最终一致性?
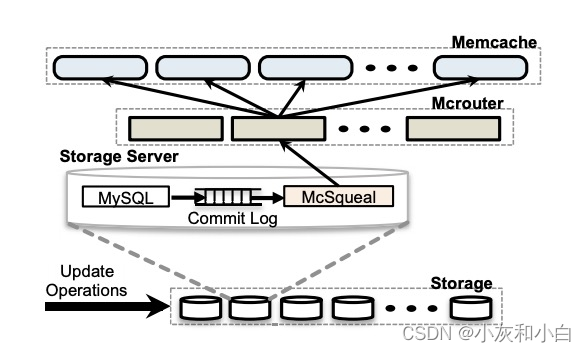
FB 在持久化层中使用 MySQL 集群,于是它们顺着思路开发了 mcsqueal 中间件,并将其部署到每个 MySQL 集群上。mcsqueal 负责读取 MySQL 的 commit log,解析其中的 SQL 语句,捕获数据更新信息,并将其广播给所有 memcached 集群。
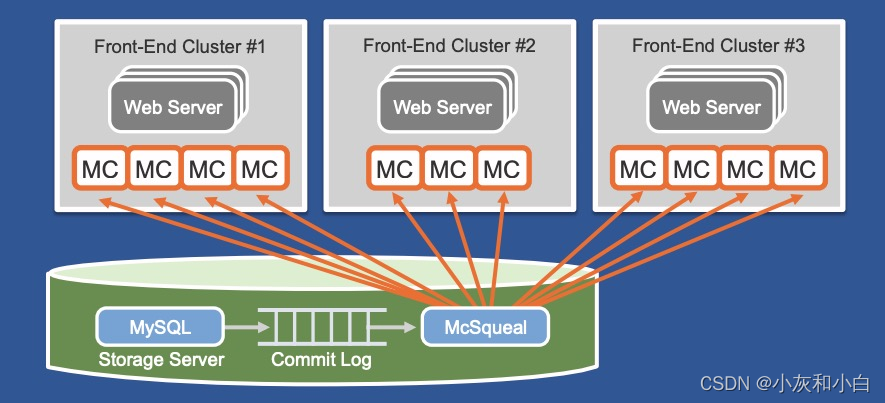
从架构图中,不难看出 fanout 问题再次出现,大量的跨集群通信数据同样可能将网络打垮。解决方案也不难想到,即分而治之:
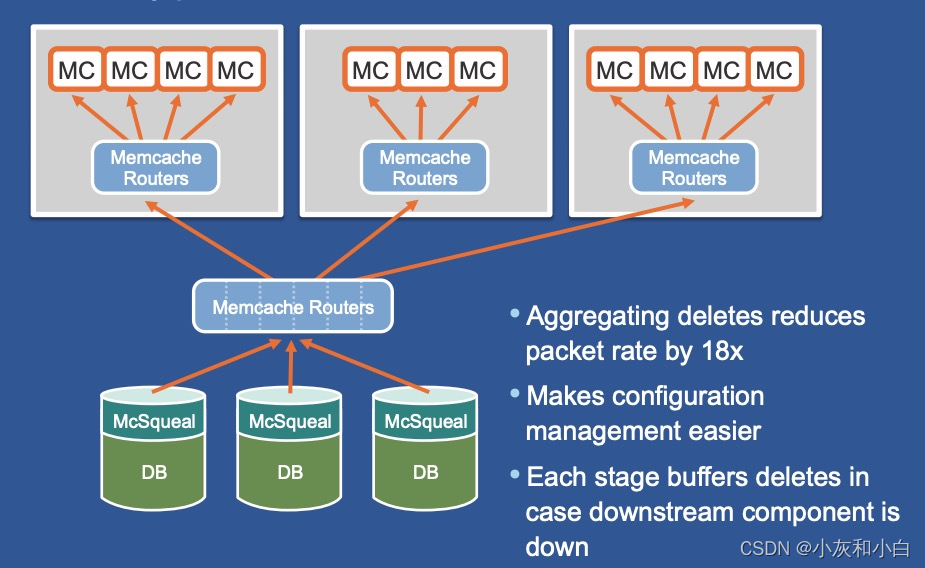
一个区域内部部署多个 memcache 集群能够给我们带来诸多好处,除了缓解热点问题、网络拥堵问题,还能让运维人员方便地下线单个节点、集群,而不至于使得 cash miss rate 忽然增大。
(二) Regional Pools
在同一个region中的不同集群之间,数据进行了复制。但是一些不太热门的数据,其多副本放在内存中是一种浪费。所以每个集群内除了memcache服务器池以外,还会有一个放着memcache服务器的regional pool,它会被该区域中所有集群所共享。前端软件进行修改,当前端服务器上所运行的软件知道这个key所对应的数据的使用频率不高,就不会将这些数据保存在本集群中的memcache服务器里,而是放在这个regional pool(下图REG. POOL)中合适的memcache服务器上。
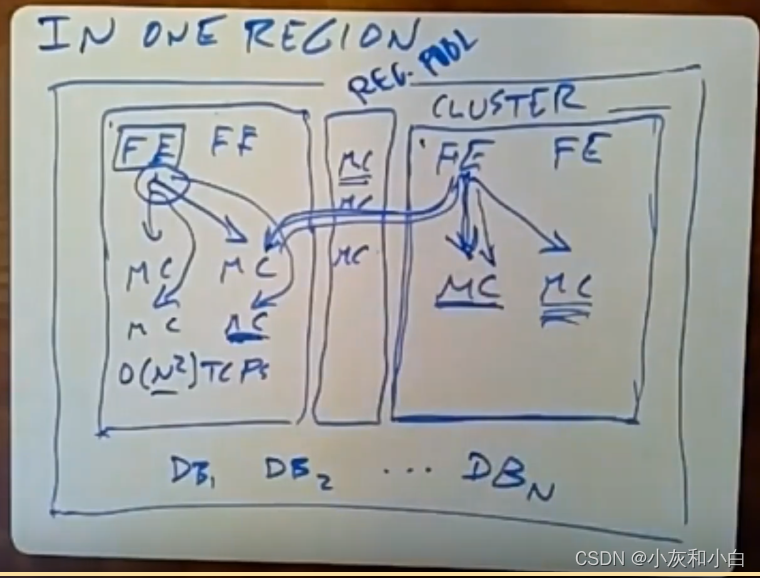
(总结:regional pool所有集群共享一份的memcache,放一些不热门的数据,不必提供多块复制)
(三)Cold Cluster Warmup
上线新的 memcache 集群时,如果不预热可能会出现大量 cache miss(因为一开始缓存是空的)。FB使用了一种cold start的思想,当新集群处于cold start状态时,我们会给它做一个标记。在这种情况下,当新集群中的前端服务器遇到缓存未命中的情况,首先,前端服务器会去访问该集群本地的memcache服务器,如果该memcache服务器表示它上面没有前端服务器所要的这个数据,那么前端服务器就会跑去另一个集群中对应的memcache服务器(warm cluster)那里获取数据,如果有前端服务器就会拿到数据并将该数据放入它所在集群中的本地memcache服务器中。只有当本地memcache服务器,以及warm memcache服务器中没有它所要的数据时,新集群中的这个前端服务器才会从数据库服务器中读取数据。集群会在这种cold mode下运行一段时间直到新集群中的memcache服务器中缓存了所有热门数据为止。然后就可以关闭这种cold mode,直接独立使用该集群本地的memcache服务器即可。
(总结:新集群上线时,memcache中为空,使用cold start思想,标记新集群,memcache未命中时,去另外集群的memcache获取,再找不到再去DB)
八、Across Regions: Consistency
1.memcache 服务也需要能够被部署到多个区域。利用 MySQL 的复制机制,FB 将一个区域设置为 master 区域,而其它区域为只读区域,负责从 master 中同步数据。web servers 处理读请求时只需要访问本地的 DB 或缓存服务即可。
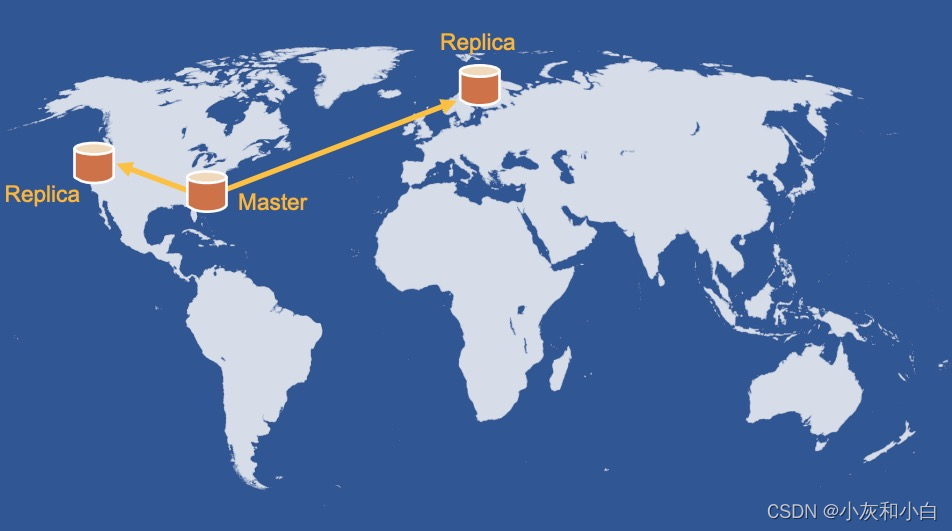
2.但这里将产生一个新的问题:只读区域的数据库有同步延迟,可能导致竞争条件出现。想象以下这个场景:
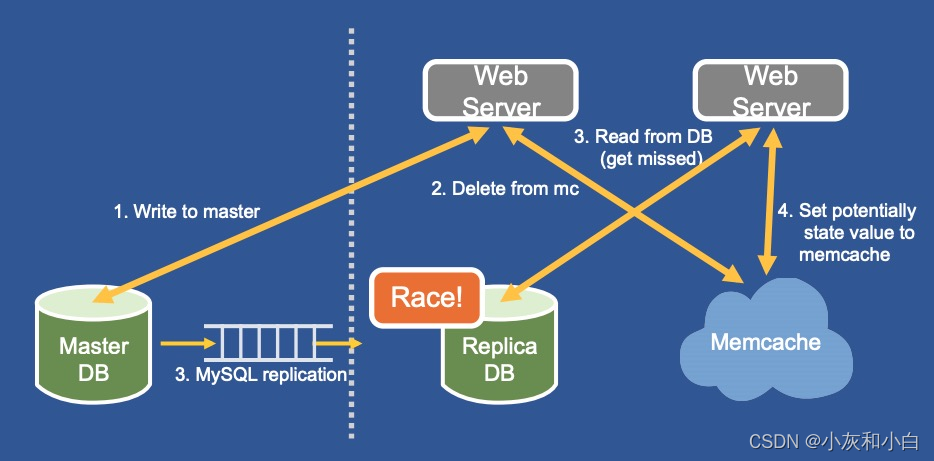
①复制集群中的 web server A 写入数据到 master DB
②A 将本地 memcache 中的数据删除
③复制集群中的 web server B 从 memcache 中读取数据发生 cache miss,从本地 DB 中获取数据
④A 写入的数据从 master DB 中同步到 replica DB,并通过 mcsqueal 将本地 memcache 中的数据删除 ?
⑤web server B 将其读到的数据写入 memcache 中
3.此时,DB 与 memcache 中的数据将再次出现不一致,且必须等待数据过期之后才能恢复。如何解决这个问题?FB 在 memcache 上引入 remote marker 机制:
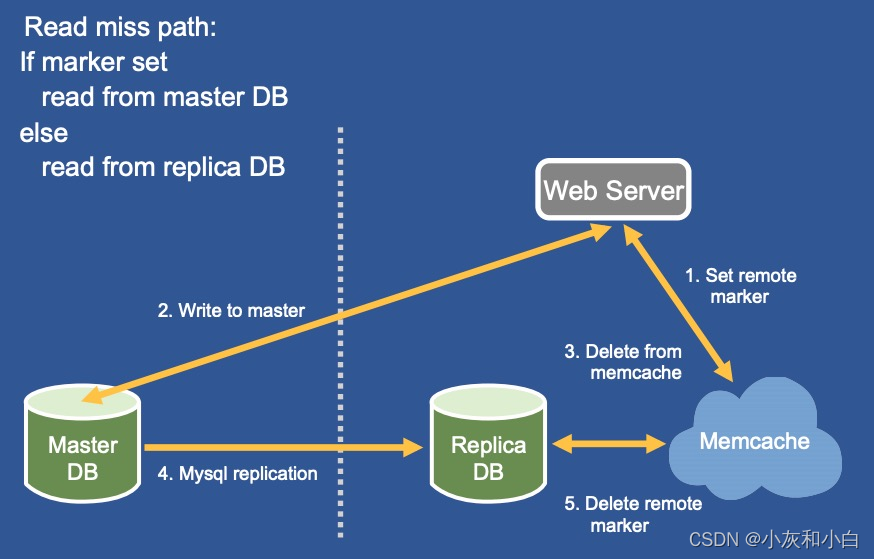
当 replica 区域的 web server 需要写入某数据 d 时:
①在本地 memcache 上打上 remote marker
②将 d 写入到 master DB 中
③将 d 从 memcache 中删除 (remote marker 不删除)
④等待 master DB 将数据同步到本地 replica DB 中,并且在 SQL 语句中埋入remote marker的信息
⑤本地 replica DB 通过 mcsqueal 解析 SQL 语句中,删除 remote marker
4.当 replica 区域的 web server 想要读取数据 d 发生 cache miss 时:
如果 memcache 中数据 d 带了 remote marker,则从 master DB 中读取数据
如果 memcache 中数据 d 没有remote marker,则直接从本地的 replica DB 中读取数据
5.remote marker 机制实际上就是标记了 数据写入 master DB 但尚未同步到 replica DB 的中间状态。
九、memcache的一致性
1.一致性问题在于DB中的数据存在着很多个副本(主数据库、副数据中心数据库、每个集群的memcache服务器、Gutter Server)。
当有一个写操作传入的时候,这个写操作要应用到相关数据的所有这些副本上。此外,这些写操作可能来源于多个地方,在同一时间,可能会有多个前端服务器对同一个key所对应的数据进行写入。这些写操作可能来自于不同区域的前端服务器。由于并发、多副本以及来自多个前端服务器所做的写操作等原因,这就会导致让过时的数据停留在系统中很长一段时间。
2.之前的问题:为什么前端服务器使用的是delete操作而不是update,这是因为多个数据源所导致的。我们在执行正确操作顺序的时候遇上了问题。这里我们来看个关于update race的案例(即并发更新操作所产生的问题)如果它们没有做任何处理,那么memcache中的数据肯定是过时的数据。
假设有个Client1想去读取某个key所对应的数据,但memcache表示它里面并没有这些数据。C1就会从数据库中读取数据,假设它取回的值是v1。与此同时,C2想对该数据进行更新,C2会将要修改的数据(V2)传入这个write操作,并发送给数据库。C2要做的另一件事情就是将原来的数据从memcache中删除,数据库也会将key所对应的数据从memcache中删除,paper中说过delete操作是幂等的,所以delete始终是安全的。
如果你遇上缓存未命中的情况,那你就会从数据库中读取数据,接着,你会将读取到的数据插入memcache中。假设C1的速度比较慢,它会发送一个setRPC给memcache服务器,它之前所读取到的是版本1时的值(过时)并将这个值放入了memcache中。这里所发生的另一件事情就是,当你要往数据库中写入数据时,数据库会往memcache中发送delete操作。此时,数据库会发送一个delete(k)操作给memcache(下图右侧DB的delete(k))。现在我们有两个delete操作(一次DB一次C2),但这并没有关系。当C1去更新该key所对应的数据时,这些delete操作可能就已经执行完了。所以,此时,memcache缓存的一直是该数据的过时版本。如果系统是以这种方式工作的,那么没有任何机制能让memcache拿到的是正确的值,它所保存并向前端服务器提供的(与k相关的)数据始终是过时的。
(总结:C1执行的慢,向memcache执行set操作在C2的delete之后,导致过期数据一直在mamcache中,直到下次修改)

3. 他们实际上通过lease机制解决了这个问题,即之前在惊群问题时所讨论过的lease机制。当memcache告诉我们,缓存中没有我们要的数据时(缓存未命中),它就会颁发lease。client就会拿到这个miss指示,以及这个lease(这个lease是一个很大的数字,并且它是唯一的)。memcache服务器会去记住这个lease和这个key之间的关系,它知道拿着这个lease的人,才有资格去更新这个key所对应的内容。
这里的新规则是这样的,当memcache服务器从另一个Client或者数据库那里收到一个delete操作时,它除了会删除这个数据以外,它还会使之前颁发的lease失效。所以,不管是哪个delete先到达memcache那里,memcache服务器会将这个lease从它的表中删除。这个set操作会携带前端服务器所拿到的lease,当这个set操作到达memcache服务器时,memcache会去查看这个lease,如果这个lease对于这个key来说是失效的,memcache会将这个set操作忽略。如果其中一个delete操作在这个set操作之前到达memcache,它就会看到这个lease是失效的,memcache服务器就会将这个set操作给忽略。这就意味着,这个key所对应的数据并没有放在memcache中,下一个试着读取这个key的client就会遇上缓存未命中的情况,它就会从数据库中读取到最新的数据,并将该数据放入memcache中,第二个reader所拿着的lease就会是有效的。
如果发生的顺序改变,那么会发生什么呢?假设这些delete操作是在set操作之后才发生的,这种方案依然有效。此时,memcache服务器并不会将这个lease从lease表中删除,当这个set操作到达memcache的时候,这个lease依然是有效的。那么它会接受这个set操作,即我们会将该key的值设置为一个过时的数据(V1)。但我们所做的假设是,此时的delete操作是在set之后发生的,当这些delete操作到达memcache时,那么这个过时的数据就会从缓存中清除出去。这些过时数据呆在缓存中的时间会有点长,但我们不希望遇上这种情况:即过时的数据一直呆在缓存中,从来没有被删除。

十、总结
该系统存在着大量的复杂性,因为它是由彼此并不了解的部分所拼接起来的。memcache承担了某些数据库方面的事情,所以需要一种一致性方案来让它们一起协调工作。我们从这篇paper中所学到的其中一点是,对于那些大型操作来说,缓存是至关重要的,它能让我们的系统从高负载的情况下存活下来。对于降低延迟这方面来说,缓存并不是那么有帮助,它更多还是关于将那些高负载工作尽量对那些速度相对较慢的存储服务器屏蔽。Facebook通过缓存来避免让数据库直面这些负载。
我们从中学到的另一个东西是,在大型系统中,你一直得去思考缓存、分区以及replication的问题。你得需要某种方式来决定在分区这块你要投入多少资源,replication这块你又要投入多少资源。最后,在这篇paper中,你能够学会以更好的方式来整合不同的存储层,以此获取良好的一致性。(怎么选择复制、分区,以及他们的整合和资源分配)
相关文章:
Memcache论文总结——Lec16
文章目录一、相关名词1.mcrouter层2.GUTTER SERVER3.mcsqueal4.remote mark二、当流量增长了如何SCALE 你的网站?三、背景及业务特点1.读多写少2.FB需求:3.之前情况四、简介五、FaceBook的架构五、Cache Policy六、In a Cluster : Latency and Load(一&a…...
父子组件传值问题
文章目录前言一、问题描述二、问题解决前言 在写毕业设计,涉及了一些前端Vue.js的组件传值知识并出现了相关问题,因此进行记录。 问题 Vue.js的使用不熟练,相关组件、props等掌握不清晰前端代码书写不规范 望指正! 一、问题描述 …...

Redis大key问题
Redis大key问题 什么是big key? bigKey的危害: 大key不仅仅是占用内存而已,如果是仅仅内存的问题 那么扩大内存就好了。禁止大key是主要是因为你操作redis,比如说读/写等操作redis的时候 会有io操作,大key会导致io操作…...
00后卷王的自述,我难道真的很卷?
前言 前段时间去面试了一个公司,成功拿到了offer,薪资也从12k涨到了18k,对于工作都还没两年的我来说,还是比较满意的,毕竟一些工作3、4年的可能还没我高。 我可能就是大家说的卷王,感觉自己年轻ÿ…...

Redis第七讲 Redis存储模型详解
Redis存储模型 每次在Redis数据库中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,而Redis中的每个对象都是由 redisObject 结构来表示.redisObject的结构与对象类型、内存编码、内存回收、共享对象都有关系,一个redisObject对象的大小为16字节:4bit+…...
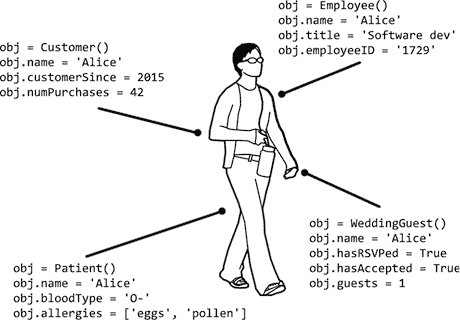
Python 进阶指南(编程轻松进阶):十五、面向对象编程和类
原文:http://inventwithpython.com/beyond/chapter15.html OOP 是一种编程语言特性,允许你将变量和函数组合成新的数据类型,称为类,你可以从中创建对象。通过将代码组织成类,可以将一个整体程序分解成更容易理解和调试…...

windows下postgresql安装timescaledb
timescaledb是一个时序数据库,可以创建超表hypertable。它并不是一个独立的数据库,它依赖于postgresql,目前相当于postgresql的一个插件或者扩展。 要安装timescaledb,需要先安装postgresql。 这里安装的postgresql是12.14版本&am…...

Linux系统常用命令大全
本教程将介绍Linux系统的基本操作,包括文件操作、用户管理和软件安装等。 1. 文件操作 1.1 查看文件内容 使用cat命令可以查看文件的内容,例如:cat file.txt 1.2 创建新文件 使用touch命令可以创建新文件,例如:to…...

月报总结|Moonbeam 3月份大事一览
本月,Moonbeam在社区治理上进入了全新的阶段 — — 针对第一批生态系统Grants的Snapshot投票结果揭晓,链上公投已在进行中,社区获得了更多表达的机会与权力,这些项目也将为生态注入新的活力。 活动方面,Moonriver Ris…...
多功能料理锅语音播放芯片——NV040C
多功能料理锅就是一锅搭配多个锅盘,可以实现火锅、烤肉、花式煎蛋、丸子等多种烹饪功能。 多功能料理锅语音方案设计需求: 多功能锅本身体积有限,按钮比较少,相应功能的字体要贴按钮旁边,字体也是比较小的,…...
vue23自定义svg图标组件
可参考: 未来必热:SVG Sprites技术介绍 懒人神器:svg-sprite-loader实现自己的Icon组件 在Vue3项目中使用svg-sprite-loader 前置知识 在页面中,虽然可以通过如下的方式使用img标签,来引入svg图标。但是,…...
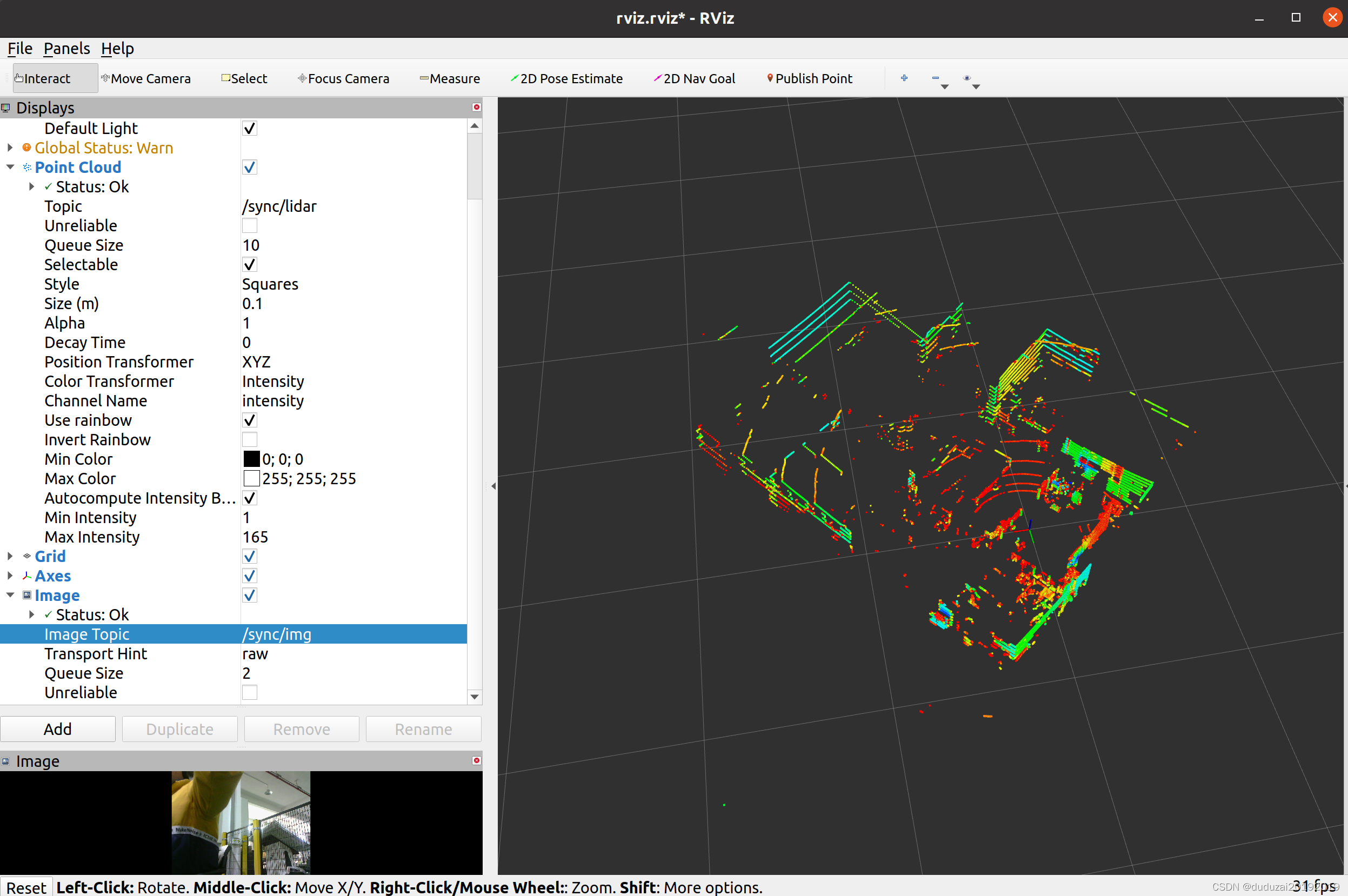
相机雷达时间同步(基于ROS)
文章目录运行环境:思路:同步前和同步后效果对比1.1创建工作空间1.2创建功能包2.1编写源文件2.2编写头文件2.3编写可执行文件2.4配置文件3.1编译运行4.1录制时间同步后的rosbag4.2rviz可视化rosbag运行环境: ubuntu20.04 noetic usb_cam 速腾R…...

素数环PrimeRing [3*]
目录 素数环PrimeRing [3*] 程序设计 程序分析 素数环PrimeRing [3*] 把1~N这N个整数摆成一个环,要求任意相邻两个数的和为素数。按字典序打印出以1开始的素数环 Input 一个整数N (<=10) Output 每行一个素数环。每个数之间用一个空格隔开。 无解输出 No Solution Sampl…...
mongodb 连接池配置
参考官方描述: 如果spring使用以下mongodb的配置,则默认是没有连接池的 spring:data:mongodb:host: 地址port: 27017database: 数据库名username: 账号password: 密码 每隔一两分钟没有去请求的话就会断开连接重连,每次都要等待5-10秒之间才…...

数据在内存中的存储(深度剖析)
目录 1.数据类型介绍 1.1类型分类 2.整形在内存中的存储 2.1原码,反码,补码 2.2大小端介绍 2.3练习 3.浮点型在内存中的存储 3.1浮点数存储规则 引入: 有正负的数据可以存放在有符号的变量中 只有正数的数据可以存放在无符号的变量…...

python 实现二叉搜索树的方法有哪些?
树的介绍 树不同于链表或哈希表,是一种非线性数据结构,树分为二叉树、二叉搜索树、B树、B树、红黑树等等。 树是一种数据结构,它是由n个有限节点组成的一个具有层次关系的集合。用图片来表示的话,可以看到它很像一棵倒挂着的树。…...

ORM概述
1_ORM概述[理解] 解释: 对象关系映射模型特点: 1.将类名,属性, 映射成数据库的表名和字段2.类的对象,会映射成为数据库表中的一行一行的数据 优缺点: 优点: 1.不再需要编写sql语句2.不再关心使用的是什么数据库了 缺点: 1.由于不是直接通过sql操作数据库,所以有性能损失 2_…...
程序员必知必会7种UML图(类图、序列图、组件图、部署图、用例图、状态图和活动图)画法盘点
众所周知,软件开发是一个分阶段进行的过程。不同的开发阶段需要使用不同的模型图来描述业务场景和设计思路,在不同的阶段输出不同的设计文档也是必不可少的,例如,在需求分析阶段需要输出领域模型和业务模型,在架构阶段…...
基于asp的搜索引擎开发和实现
随着因特网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找信息,就像大海捞针一样,搜索引擎技术恰好解决了这一难题。目前,搜索引擎系统可以分类三大类,分别是:目录式搜索引擎:以人工方式或半…...

代码随想录刷题-字符串-实现 strStr()
文章目录实现 strStr()习题暴力解法kmp 解法实现 strStr() 本节对应代码随想录中:代码随想录,讲解视频:帮你把KMP算法学个通透!(理论篇)_哔哩哔哩_bilibili、帮你把KMP算法学个通透!࿰…...

QMCDecode:轻松解锁QQ音乐加密音频的Mac专属神器
QMCDecode:轻松解锁QQ音乐加密音频的Mac专属神器 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结…...

RoboCom备赛救急实录:当VNC崩溃时,我是如何用NoMachine快速搭建远程调试环境的
RoboCom备赛救急实录:当VNC崩溃时,我是如何用NoMachine快速搭建远程调试环境的 距离RoboCom全国机器人开发者大赛还有48小时,我们的视觉识别模块突然在测试中频繁崩溃。更糟糕的是,实验室那台配置了全套开发环境的Ubuntu工作站—…...

企业如何借助Taotoken实现多模型API的容灾与智能路由保障业务连续性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业如何借助Taotoken实现多模型API的容灾与智能路由保障业务连续性 当企业的核心业务系统深度集成大模型能力时,API服…...

SoC与SoM:硬件开发的效率革命与双刃剑效应
1. 项目概述:当“系统”成为商品从业十几年,从画第一块51单片机的板子,到参与设计复杂的通信基站,我亲眼见证了硬件开发模式的剧变。如果说早些年我们还在为如何把CPU、内存、Flash、各种接口控制器塞进一块PCB而绞尽脑汁…...

钉钉机器人消息解析器:基于JSON Path与模板的自动化数据提取方案
1. 项目概述:一个钉钉消息解析器的诞生最近在做一个内部自动化工具时,遇到了一个挺有意思的需求:需要把钉钉机器人推送过来的消息,从原始的、结构复杂的JSON格式里,精准地“抠”出我们关心的业务数据。比如,…...

如何在5分钟内掌握Illustrator智能填充神器Fillinger
如何在5分钟内掌握Illustrator智能填充神器Fillinger 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为复杂的图案填充耗费数小时吗?今天我要为你介绍一款能彻底改变…...

IDM激活脚本终极指南:三步永久免费解锁下载神器
IDM激活脚本终极指南:三步永久免费解锁下载神器 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 还在为IDM试用期到期而烦恼?每次看到&quo…...

命令行代码片段管理器:提升开发效率的智能工具实践
1. 项目概述:一个为开发者量身定制的代码片段管理工具 如果你和我一样,每天在多个项目、多种编程语言之间反复横跳,那你一定对“代码片段复用”这件事又爱又恨。爱的是,那些精心打磨过的工具函数、配置模板、业务逻辑块࿰…...

命令行故障自动修复工具 fix-my-claw:原理、插件架构与实战指南
1. 项目概述:一个修复“爪子”的实用工具最近在GitHub上看到一个挺有意思的项目,叫caopulan/fix-my-claw。光看名字,你可能会有点摸不着头脑——“爪子”是什么?需要修复什么?这其实是一个典型的、由开发者社区需求催生…...

Yolov5算法界面 PyQt5 +.exe文件部署 yolo双击运行 yolo打包识别
介绍 Yolov5是一种基于深度学习的目标检测算法,PyQt5是一个Python编写的GUI框架,用于创建交互式界面。在部署和运行Yolov5模型时,结合PyQt5可以方便地创建一个用户友好的界面,并将代码打包为.exe文件以供其他人使用。 下面是一个简…...