python 实现二叉搜索树的方法有哪些?
树的介绍
树不同于链表或哈希表,是一种非线性数据结构,树分为二叉树、二叉搜索树、B树、B+树、红黑树等等。
树是一种数据结构,它是由n个有限节点组成的一个具有层次关系的集合。用图片来表示的话,可以看到它很像一棵倒挂着的树。因此我们将这类数据结构统称为树,树根在上面,树叶在下面。一般的树具有以下特点:
- 每个节点有0个或者多个子节点
- 没有父节点的节点被称为根节点
- 每个非根节点有且只有一个父节点
- 每个子结点都可以分为多个不相交的子树
二叉树的定义是:每个节点最多有两个子节点。即每个节点只能有以下四种情况:
- 左子树和右子树均为空
- 只存在左子树
- 只存在右子树
- 左子树和右子树均存在
二叉搜索树
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树

列举几种Python中几种常见的实现方式:
1.使用类和递归函数实现
通过定义一个节点类,包含节点值、左右子节点等属性,然后通过递归函数实现插入、查找、删除等操作。代码示例如下:
class Node:def __init__(self, data):self.data = dataself.left = Noneself.right = None
class BST:def __init__(self):self.root = None
def insert(self, value):if self.root is None:self.root = Node(value)else:self._insert(value, self.root)
def _insert(self, value, node):if value < node.data:if node.left is None:node.left = Node(value)else:self._insert(value, node.left)elif value > node.data:if node.right is None:node.right = Node(value)else:self._insert(value, node.right)
def search(self, value):if self.root is None:return Falseelse:return self._search(value, self.root)
def _search(self, value, node):if node is None:return Falseelif node.data == value:return Trueelif value < node.data:return self._search(value, node.left)else:return self._search(value, node.right)
def delete(self, value):if self.root is None:return Falseelse:self.root = self._delete(value, self.root)
def _delete(self, value, node):if node is None:return nodeelif value < node.data:node.left = self._delete(value, node.left)elif value > node.data:node.right = self._delete(value, node.right)else:if node.left is None and node.right is None:del nodereturn Noneelif node.left is None:temp = node.rightdel nodereturn tempelif node.right is None:temp = node.leftdel nodereturn tempelse:temp = self._find_min(node.right)node.data = temp.datanode.right = self._delete(temp.data, node.right)return node
def _find_min(self, node):while node.left is not None:node = node.leftreturn node2.使用列表实现
通过使用一个列表来存储二叉搜索树的元素,然后通过列表中元素的位置关系来实现插入、查找、删除等操作。代码示例如下:
class BST:def __init__(self):self.values = []
def insert(self, value):if len(self.values) == 0:self.values.append(value)else:self._insert(value, 0)
def _insert(self, value, index):if value < self.values[index]:left_child_index = 2 * index + 1if left_child_index >= len(self.values):self.values.extend([None] * (left_child_index - len(self.values) + 1))if self.values[left_child_index] is None:self.values[left_child_index] = valueelse:self._insert(value, left_child_index)else:right_child_index = 2 * index + 2if right_child_index >= len(self.values):self.values.extend([None] * (right_child_index - len(self.values) + 1))if self.values[right_child_index] is None:self.values[right_child_index] = valueelse:self._insert(value, right_child_index)
def search(self, value):if value in self.values:return Trueelse:return False
def delete(self, value):if value not in self.values:return Falseelse:index = self.values.index(value)self._delete(index)return True
def _delete(self, index):left_child_index = 2 * index + 1right_child_index = 2 * index + 2if left_child_index < len(self.values) and self.values[left_child_index] is not None:self._delete(left_child_index)if right_child_index < len(self.values) and self.values[right_child_index] is not None:self3.使用字典实现
其中字典的键表示节点值,字典的值是一个包含左右子节点的字典。代码示例如下:
def insert(tree, value):if not tree:return {value: {}}elif value < list(tree.keys())[0]:tree[list(tree.keys())[0]] = insert(tree[list(tree.keys())[0]], value)else:tree[list(tree.keys())[0]][value] = {}return tree
def search(tree, value):if not tree:return Falseelif list(tree.keys())[0] == value:return Trueelif value < list(tree.keys())[0]:return search(tree[list(tree.keys())[0]], value)else:return search(tree[list(tree.keys())[0]].get(value), value)
def delete(tree, value):if not search(tree, value):return Falseelse:if list(tree.keys())[0] == value:if not tree[list(tree.keys())[0]]:del tree[list(tree.keys())[0]]elif len(tree[list(tree.keys())[0]]) == 1:tree[list(tree.keys())[0]] = list(tree[list(tree.keys())[0]].values())[0]else:min_key = min(list(tree[list(tree.keys())[0]+1].keys()))tree[min_key] = tree[list(tree.keys())[0]+1][min_key]tree[min_key][list(tree.keys())[0]] = tree[list(tree.keys())[0]]del tree[list(tree.keys())[0]]elif value < list(tree.keys())[0]:tree[list(tree.keys())[0]] = delete(tree[list(tree.keys())[0]], value)else:tree[list(tree.keys())[0]][value] = delete(tree[list(tree.keys())[0]].get(value), value)return tree由于字典是无序的,因此该实现方式可能会导致二叉搜索树不平衡,影响插入、查找和删除操作的效率。
4.使用堆栈实现
使用堆栈(Stack)可以实现一种简单的二叉搜索树,可以通过迭代方式实现插入、查找、删除等操作。具体实现过程如下:
- 定义一个节点类,包含节点值、左右子节点等属性。
- 定义一个堆栈,初始时将根节点入栈。
- 当栈不为空时,取出栈顶元素,并对其进行操作:如果要插入的值小于当前节点值,则将要插入的值作为左子节点插入,并将左子节点入栈;如果要插入的值大于当前节点值,则将要插入的值作为右子节点插入,并将右子节点入栈;如果要查找或删除的值等于当前节点值,则返回或删除该节点。
- 操作完成后,继续从堆栈中取出下一个节点进行操作,直到堆栈为空。
需要注意的是,在这种实现方式中,由于使用了堆栈来存储遍历树的过程,因此可能会导致内存占用较高。另外,由于堆栈的特性,这种实现方式只能支持深度优先遍历(Depth-First Search,DFS),不能支持广度优先遍历(Breadth-First Search,BFS)。
以下是伪代码示例:
class Node:def __init__(self, data):self.data = dataself.left = Noneself.right = None
def insert(root, value):if not root:return Node(value)stack = [root]while stack:node = stack.pop()if value < node.data:if node.left is None:node.left = Node(value)breakelse:stack.append(node.left)elif value > node.data:if node.right is None:node.right = Node(value)breakelse:stack.append(node.right)
def search(root, value):stack = [root]while stack:node = stack.pop()if node.data == value:return Trueelif value < node.data and node.left:stack.append(node.left)elif value > node.data and node.right:stack.append(node.right)return False
def delete(root, value):if root is None:return Noneif value < root.data:root.left = delete(root.left, value)elif value > root.data:root.right = delete(root.right, value)else:if root.left is None:temp = root.rightdel rootreturn tempelif root.right is None:temp = root.leftdel rootreturn tempelse:temp = root.rightwhile temp.left is not None:temp = temp.leftroot.data = temp.dataroot.right = delete(root.right, temp.data)return root以上是四种在Python中实现二叉搜索树的方法,在具体使用过程中还是需要合理选择,尽量以运行速度快、内存占用少为出发点,最后觉得有帮助的话请多多关注和赞同!!!
相关文章:
python 实现二叉搜索树的方法有哪些?
树的介绍 树不同于链表或哈希表,是一种非线性数据结构,树分为二叉树、二叉搜索树、B树、B树、红黑树等等。 树是一种数据结构,它是由n个有限节点组成的一个具有层次关系的集合。用图片来表示的话,可以看到它很像一棵倒挂着的树。…...

ORM概述
1_ORM概述[理解] 解释: 对象关系映射模型特点: 1.将类名,属性, 映射成数据库的表名和字段2.类的对象,会映射成为数据库表中的一行一行的数据 优缺点: 优点: 1.不再需要编写sql语句2.不再关心使用的是什么数据库了 缺点: 1.由于不是直接通过sql操作数据库,所以有性能损失 2_…...
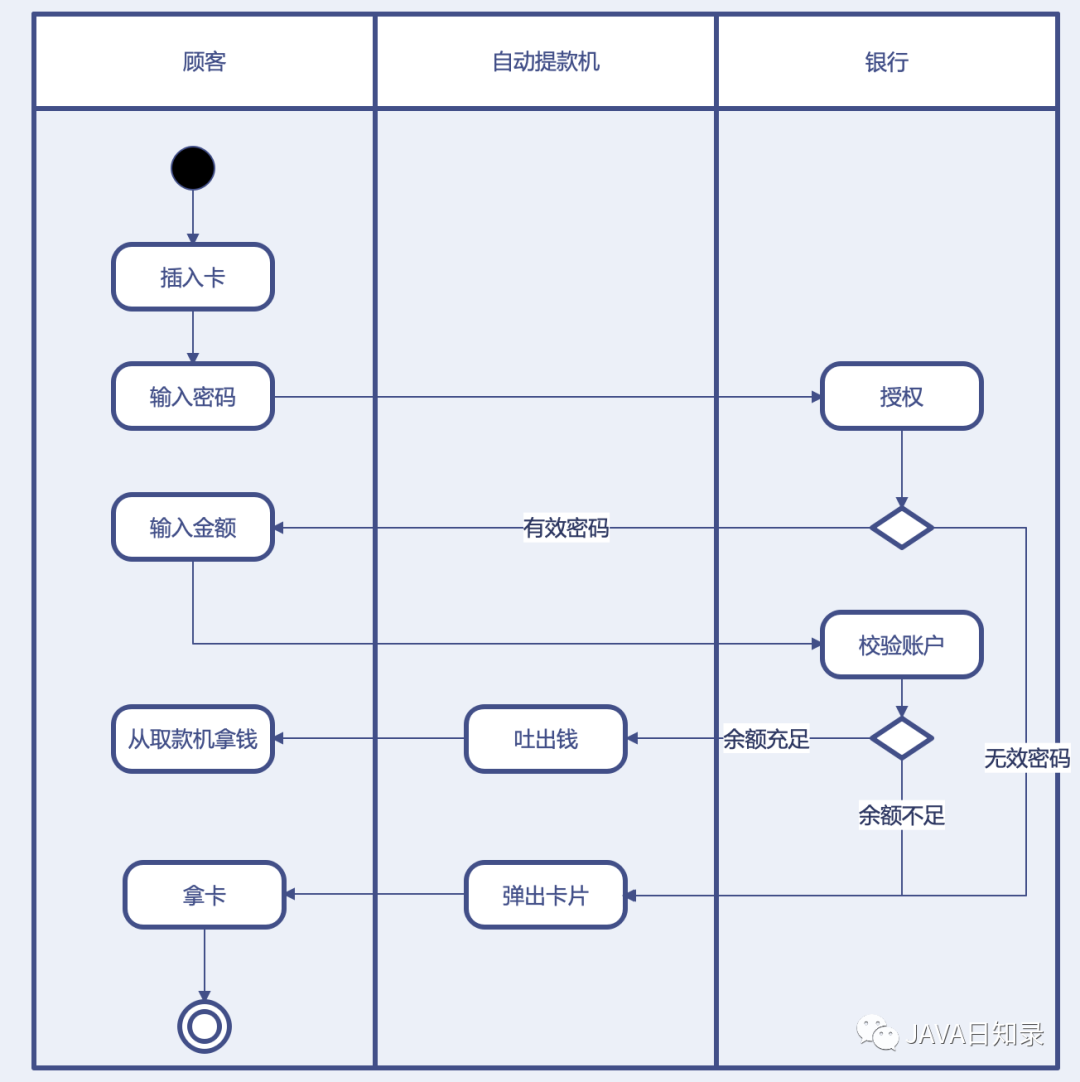
程序员必知必会7种UML图(类图、序列图、组件图、部署图、用例图、状态图和活动图)画法盘点
众所周知,软件开发是一个分阶段进行的过程。不同的开发阶段需要使用不同的模型图来描述业务场景和设计思路,在不同的阶段输出不同的设计文档也是必不可少的,例如,在需求分析阶段需要输出领域模型和业务模型,在架构阶段…...
基于asp的搜索引擎开发和实现
随着因特网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找信息,就像大海捞针一样,搜索引擎技术恰好解决了这一难题。目前,搜索引擎系统可以分类三大类,分别是:目录式搜索引擎:以人工方式或半…...

代码随想录刷题-字符串-实现 strStr()
文章目录实现 strStr()习题暴力解法kmp 解法实现 strStr() 本节对应代码随想录中:代码随想录,讲解视频:帮你把KMP算法学个通透!(理论篇)_哔哩哔哩_bilibili、帮你把KMP算法学个通透!࿰…...

前端已死?金三银四?你收到offer了吗?
目录 一、前言 二、“唱衰” 三、不局限于框架、前端 四、打动面试官 五、正向加成 六、小结 一、前言 最近在脉脉、知乎等平台都有人在渲染前端从业人员的危机,甚至使用“前端已死”的字眼,颇有“语不惊人死不休”的意味,对老鸟来说&a…...

C生万物 | 十分钟带你学会位段相关知识
结构体相关知识可以先看看这篇文章 —— 链接 一、什么是位段 位段的声明和结构是类似的,有两个不同: 位段的成员必须是 int、unsigned int 或signed int位段的成员名后边有一个冒号和一个数字 在下面,我分别写了一个结构体和一个位段&…...
Spring Boot基础学习之(十):修改员工的信息
注意:spring boot专栏是一个新手项目,博文顺序则是功能实现的流程,如果有看不懂的内容可以到前面系列去了解。 本次项目所有能够使用的静态资源可以免费进行下载 静态资源 在本篇代码DAO层将通过Java文件去实现,在这里就不连接数…...

闭关十几天,我完成了我的毕业设计
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,也会涉及到服务端(Node.js) 📃个人状态: 在校大学生一枚,已拿多个前端 offer(…...

认识rust的项目管理工具--cargo
cargo 提供了一系列的工具,从项目的建立、构建到测试、运行直至部署,为 Rust 项目的管理提供尽可能完整的手段。不过,我们无需再手动安装,之前安装 Rust 的时候(用rustup或者vscode加插件的方式安装)&#…...
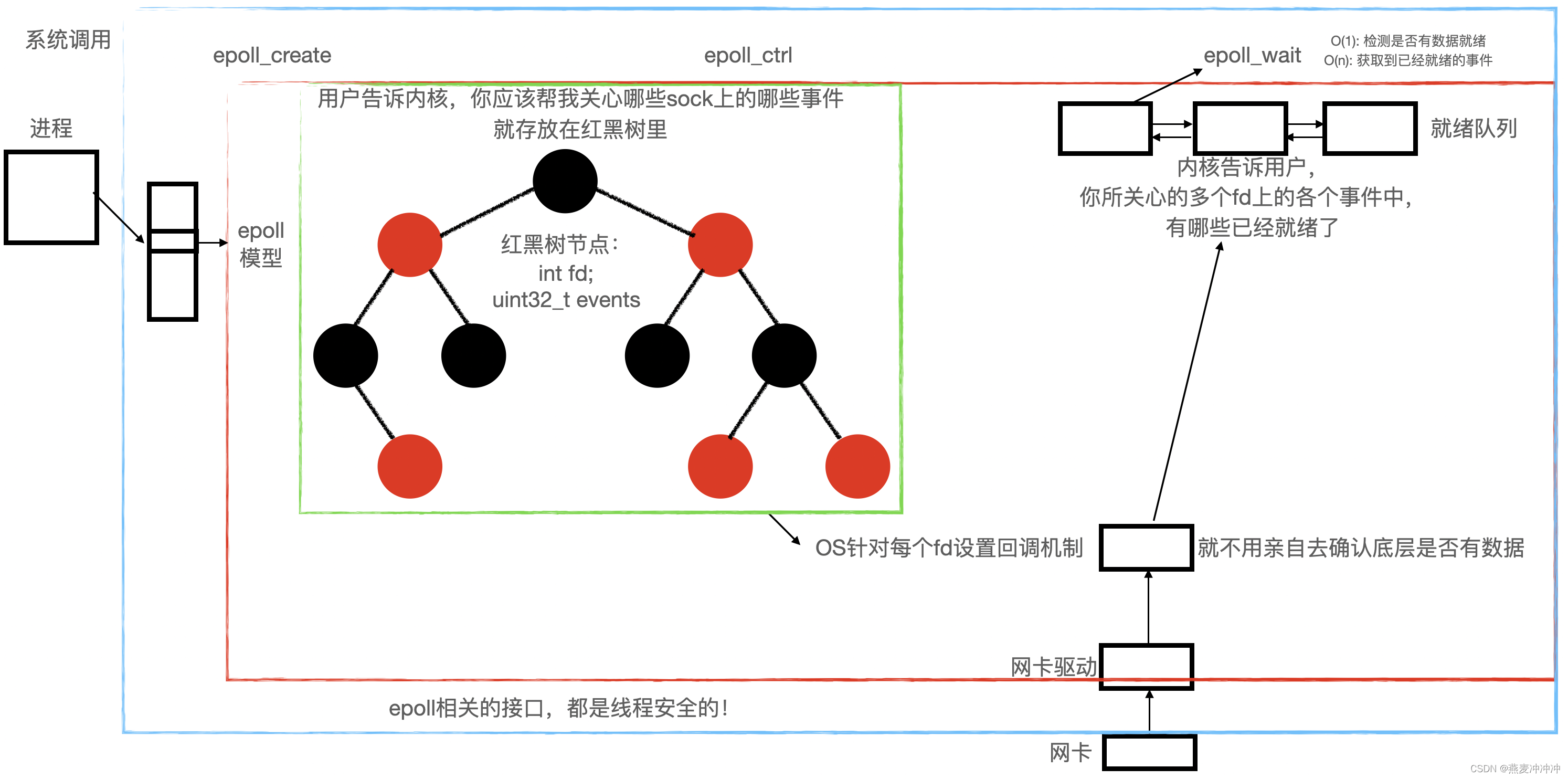
面试常问的Linux之 I/O 复用
I/O 复用 一、I/O的概念 在Linux系统中,I/O(输入/输出)指的是计算机系统的数据交换过程,包括从外部设备读取数据(输入)和将数据发送到外部设备(输出)。I/O操作是Linux系统中非常重要…...

MySQL-binlog+dump备份还原
目录 🍁binlog日志恢复 🍂binlog介绍 🍂Binlog的用途 🍂开启binary log功能 🍂配置binlog 🍁mysqldump 🍂数据库的导出 🍂数据库的导入 🍁mysqldumpbinlog 🦐…...

互联网络-单级互联网络
1.立方体单级网络 1.定义 立方体单级网络(cube)的名称来源于下图所示的三维立方体结构,如010只能连接到000、011、110,不能直接连接到对角线上的001、100、101、111。 2.例题 1.编号为0、1、2、3、4,…,15的16个处理器,用单级互联网络互联,用Cube0互联函数时,与第10…...
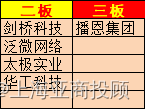
上海亚商投顾:沪指四连阳重回3300点 中字头个股再发力
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 市场情绪大小指数今日走势分化,沪指低开后震荡反弹,创业板指盘中跌超1%。中字头个股再度发力&#x…...

LeetCode:150. 逆波兰表达式求值—栈
🍎道阻且长,行则将至。🍓 🌻算法,不如说它是一种思考方式🍀算法专栏: 👉🏻123 一、🌱150. 逆波兰表达式求值 题目描述:给你一个字符串数组 token…...

C/C++每日一练(20230410) 二叉树专场(4)
目录 1. 二叉搜索树迭代器 🌟🌟🌟 2. 验证二叉搜索树 🌟🌟🌟 3. 不同的二叉搜索树 II 🌟🌟🌟 🌟 每日一练刷题专栏 🌟 Golang每日一练 专…...

策化整理1
概述: 本游戏是一款恐怖类解密游戏,以反应毒品的危害和反对家庭暴力为主题 在游戏中玩家扮演被困入梦境内的主人公,寻找逃出梦境的方法 本游戏故事大背景: 主人公的父亲是一名毒贩,在母亲发现父亲开始吸毒后选择与父亲…...
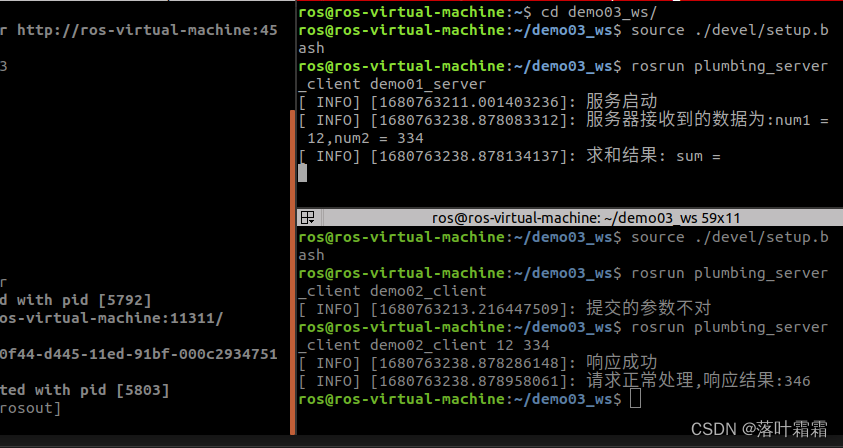
【服务通信自定义srv调用3----客户端的优化】
客户端的优化 服务通信自定义srv调用,客户端随意提交两个数,完成数的相加。也就是实现参数的动态提交: 1.格式:rosrun xxxx xxxx 12 34 2.节点执行时候,需要获取命令中的参数,并且组织进 request 代码中应…...

React跨域解决方案
一、跨域日志报错 我们由于项目需要经常会需要对不同域名、不同子域的网站接口发起请求,有时甚至是对于同一域名的不同端口发起请求,此时我们经常看到以下报错: Access to XMLHttpRequest at xxx from origin xxx has been blocked by COR…...
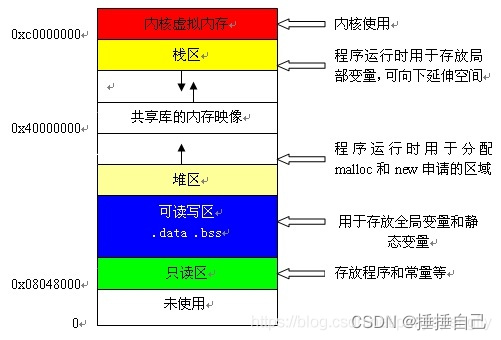
内存五区的概念,内存池技术的诞生。
首先提出一道经典的面试题来引出今天的主角: 进程的虚拟空间分布是什么样的,全局变量放在哪里? 在数据初始化之后,全局变量放在.data段 在数据未初始化时,全局变量放在.bss段 内存五区 进程虚拟内存主要分为五个部分…...

基于ARM9核心板的工业双CAN网关开发实战:从硬件选型到软件架构
1. 项目概述与核心价值最近在做一个工业网关项目,客户要求设备必须支持双路CAN总线,用于同时连接现场的执行器和上位机监控系统。时间紧,任务重,自己从头设计硬件、画板、调试驱动,周期太长,风险也高。这时…...

Postman导入导出避坑指南:为什么你的环境变量导入后不生效?
Postman环境变量导入失效深度解析与解决方案 当你在团队协作或项目迁移时,精心配置的Postman环境变量导入后却神秘消失——这种挫败感每个开发者都经历过。本文将揭示Postman变量系统的底层机制,通过三个典型故障场景还原真实问题根源,并提供…...

【困难】不用任何比较判断找出两个数中较大的数-Java:解法一
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程大家好!欢迎来到我的网站! 人工智能被认为是一种拯救世界、终结世界的技术。毋庸置疑&#x…...

图片换背景在线制作怎么操作?一文解析2026年最好用的免费工具
你是不是也遇到过这样的困境:拍了张不错的证件照,但背景不够专业;电商要上新产品图,需要统一的白色背景;或者就是想给朋友圈的照片换个背景图,结果却卡在了怎么处理上?其实,图片换背…...

简单易学:awesome-embedding-models 中负采样技术的完整实现指南
简单易学:awesome-embedding-models 中负采样技术的完整实现指南 【免费下载链接】awesome-embedding-models A curated list of awesome embedding models tutorials, projects and communities. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-embedding…...

火绒安全软件实战教程:快速查杀、全盘查杀、自定义查杀到底怎么选?
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

紧急通知:NotebookLM v2.3将移除手动标签覆盖功能!立即执行这5项存量标签加固操作,否则知识链永久断裂
更多请点击: https://intelliparadigm.com 第一章:NotebookLM标签管理方法 NotebookLM 原生不提供显式的“标签(Tags)”UI 控件,但可通过其底层的 source 元数据机制实现语义化标签管理。核心思路是将标签作为自定义…...

LiveSplit速通计时器:5个核心功能提升你的游戏计时效率
LiveSplit速通计时器:5个核心功能提升你的游戏计时效率 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款专为游戏速通玩家设计的专业计时器软件&a…...

终极指南:5步快速掌握Aimmy免费AI瞄准辅助工具
终极指南:5步快速掌握Aimmy免费AI瞄准辅助工具 【免费下载链接】Aimmy Universal Second Eye for Gamers with Impairments (Universal AI Aim Aligner (AI Aimbot) - ONNX/YOLOv8 - C#) 项目地址: https://gitcode.com/gh_mirrors/ai/Aimmy 还在为游戏中的瞄…...
)
NotebookLM大纲自动生成失效真相(2024年最新API行为逆向分析报告)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM大纲自动生成失效现象全景速览 NotebookLM 的大纲自动生成功能在近期多个用户反馈中出现非预期中断,表现为输入结构化文本后无响应、输出空大纲或仅返回占位符标题。该问题并非全…...