大数据技术之Sqoop——SQL to Hadoop
一、简介
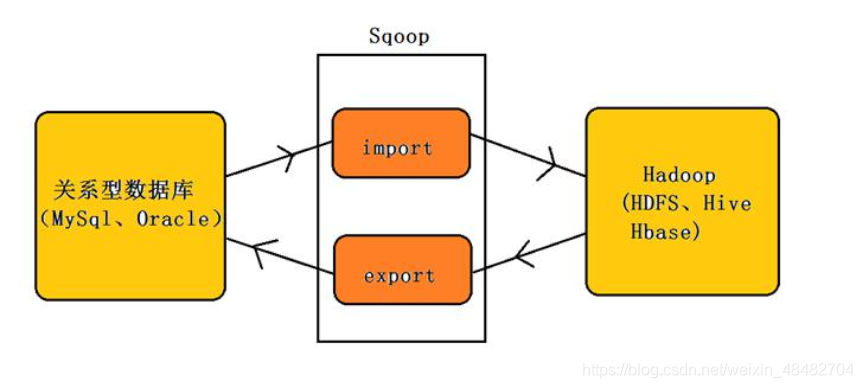
sqoop (sql to hadoop)是一款开源的工具,主要用于在 Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MSQL,Oracle,Postgres 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
1.1 工作机制
将导入或导出命令翻译成mapreduce程序来实现。
1.2 功能
Sqoop的主要功能如下:
导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
导出数据:从Hadoop的文件系统中导出数据到关系数据库
二、sqoop安装
2.1 上传安装包
这里两个安装包 sqoop-1.4.7 bin_hadoop-2.6.0.tar.gz和sqoop-1.4.7.tar.gz
因为hadoop版本为3.1.3 所以sqoop的版本太低,需要自行配置


2.2 解压并更名
# 解压
[root@hadoop install]# tar -zxf sqoop-1.4.7.tar.gz -C ../soft/
# 切换目录
[root@hadoop install]# cd ../soft/
# 更名
[root@hadoop soft]# mv sqoop-1.4.7/ sqoop147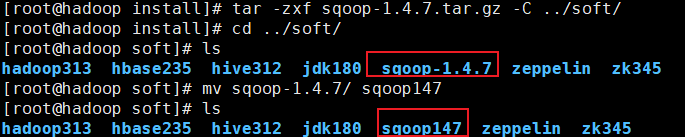
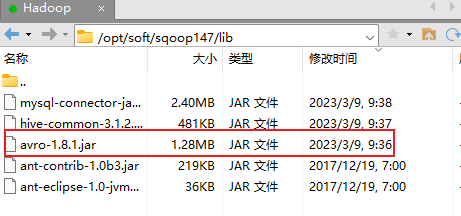
2.3 添加jar包
切换目录到 /opt/soft/sqoop147/lib/
添加avro-1.8.1.jar
# 将hive312/lib下的两个jar包拷贝过来
[root@hadoop lib]# cp /opt/soft/hive312/lib/hive-common-3.1.2.jar ./
[root@hadoop lib]# cp /opt/soft/hive312/lib/mysql-connector-java-8.0.29.jar ./

将sqoop-1.4.7.jar 拷贝到 /opt/soft/sqoop147/

2.4 修改配置文件
切换到cd /opt/soft/sqoop147/conf
# 将配置文件复制并更名
[root@hadoop conf]# cp sqoop-env-template.sh sqoop-env.sh
# 编辑 sqoop-env.sh
[root@hadoop conf]# vim ./sqoop-env.sh 22 #Set path to where bin/hadoop is available23 export HADOOP_COMMON_HOME=/opt/soft/hadoop31324 25 #Set path to where hadoop-*-core.jar is available26 export HADOOP_MAPRED_HOME=/opt/soft/hadoop31327 28 #set the path to where bin/hbase is available29 #export HBASE_HOME=30 31 #Set the path to where bin/hive is available32 export HIVE_HOME=/opt/soft/hive31233 export HIVE_CONF_DIR=/opt/soft/hive312/conf34 35 #Set the path for where zookeper config dir is36 export ZOOCFGDIR=/opt/soft/zk345/conf


2.5 添加sqoop环境变量
# 编辑/etc/profile
[root@hadoop conf]# vim /etc/profile
# SQOOP_HOME
export SQOOP_HOME=/opt/soft/sqoop147
export PATH=$PATH:$SQOOP_HOME/bin
# 刷新文件
[root@hadoop conf]# source /etc/profile

2.6 安装验证
[root@hadoop conf]# sqoop version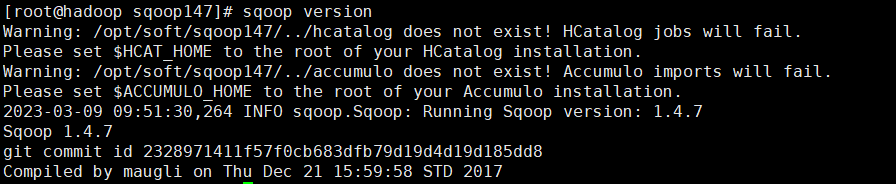
安装验证:
[root@hadoop conf]# sqoop list-databases \
[root@hadoop conf]# --connect jdbc:mysql://192.168.153.134:3306 \
[root@hadoop conf]# --username root \
[root@hadoop conf]# --password 123123注:直接回车会执行代码。\的作用是连接符,用于连接两行代码参数说明:
参数 | 说明 |
–connect | 连接关系型数据库的URL |
–username | 用户名 |
–password | 密码,考虑安全可使用 -P |
–driver | 指定jdbc驱动类 |
三、查看数据库、表
3.1 查看数据库
sqoop list-databases \
--connect jdbc:mysql://192.168.153.134:3306 \
--username root \
--password 1231233.2 查看数据库中的表
sqoop list-tables \
--connect jdbc:mysql://hadoop02:3306/school \
--username root \
--password 123123四、sqoop数据导入import
在 Sqoop 中,“导入”念指:从非大数据集(RDBMS)向大数据集群 (HDFS,HIVE,HBASE)中传输数据,叫做:导入,使用 import 关键字。
导入单个表从 RDBMS 到 HDFS。表中的每一行被视为 HDFS 的记导入工具记录。所有记录都存储为文本文件的文本数据。
4.1 导入MySQL表数据到HDFS
1> 确定MySQL服务开启正常
2> 在MySQL中新建一张表并插入一些数据
3> 导入数据
参数说明:
参数 | 说明 |
import | 从一个数据库中将一个表格导入到HDFS |
import-all-tables | 从一个数据库中将全部表格导入到HDFS |
list-databases | 列出服务器上的可用数据库 |
list-tables | 列出数据库中的可用表 |
# 将mysql表数据导入到hdfs
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--target-dir /tmp/school/student \ --用来指定导出数据存放至HDFS的目录
--table student
--fields-terminated-by '\t' \ --指定分隔符。HDFS上默认用逗号分隔数据和字段。
--m 1 --表示map task的个数。如果不写,默认为4注意:
使用-m 进行切分时,默认按照主键进行切割。如果表格中没有主键,需要指定切割列。
--split-by Sage
验证:
[root@hadoop02 ~]# hdfs dfs -cat /tmp/school/student02/part-m-00000
2023-03-10 02:26:38,581 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1990-01-01,01,赵雷,男
1990-12-21,02,钱电,男
1990-05-20,03,孙风,男
1990-08-06,04,李云,男
1991-12-01,05,周梅,女
1992-03-01,06,吴兰,女
1989-07-01,07,郑竹,女
1990-01-20,08,王菊,女注意:
1> mysql的地址尽量不要使用localhost 请使用ip或者host
2> 如果不指定,导入到hdfs默认分隔符是“,"
3> 可以通过--fields-terminated-by '\t' 指定具体的分隔符
4> 如果表的数据比较大,可以并行启动多个maptask执行导入操作。如果没有主键,需要指定根据哪个字段进行切分。
4.2 导入MySQL表数据到Hive
4.2.1 先复制表结构到hive中再导入数据
复制表结构
sqoop create-hive-table \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table teacher \ --数据库school中的表
--hive-table teacher_hive --hive中新建的表名称导入到hive default库中
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table teacher \
--hive-import \
--hive-table teacher_hive \
--m 14.2.2 直接复制表结构数据到hive中
sqoop import \# 如果不指定maptast数,需要加如下代码:
-Dorg.apache.sqoop.splitter.allow_text_splitter=top.splitter.allow_text_splitter=true--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table teacher \
--hive-import \
--hive-database teacher_hive
--m 1 \导入到hive 自定义数据库中
sqoop import \
--connect jdbc:mysql://hadoop02:3306/school \
--username root \
--password 123123 \
--table teacher \
--hive-import \
--hive-database bigdata teacher_hive4.3 导入表数据子集(where过滤)
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--where "id=01" \
--target-dir /tmp/school/student01
--table student4.4 导入表数据子集(query查询)
sqoop import
--connect jdbc:mysql://192.168.153.134:3306/school
--username root
--password 123123
--target-dir /tmp/school/users01
--query 'select name from users where cardId="1111" and $CONDITIONS'
--m 1注意:
1> 使用query sql语句来进行查找不能加参数--table,且必须要添加 where条件;
2> 并且 where 条件后面必须带一个$CONDITIONS 这个字符串
3> 并且这个 sql 语句必须用单引号,不能用双引号;
4.5 增量导入
在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据每次都全部导入到 hive 或者 hdfs 当中去这样会造成数据重复的问题。因此一般都是选用一些字段进行增量的导入, sqoop 支持增量的导入数据。
-- 所谓的增量数据指的是上次至今中间新增加的数据
-- sqoop支持两种模式的增量导入
append追加 根据数值类型字段进行追加导入,大于指定的last-value
lastmodified 根据时间戳类型字段进行追加,大于等于指定的last-value
注意在lastmodified模式下,还分为两种情形:append merge-key
增量导入是仅导入新添加的表中的行的技术。
--check-column(col)
用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系型数据库中的自增字段及时间戳类似。
注意:这些被指定的列的类型不能使任意字符类型,如 char、varchar 等类型都是不可以的,同时-- check-column 可以去指定多个列。
--incremental(mode)
append:追加,比如对大于 last-value 指定的值之后的记录进行追加导入。
lastmodified:最后的修改时间,追加 last-value 指定的日期之后的记录。
--last-value(value)
指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值。
Append增量导入
原始数据:
注意:实现增量导入
mysql> desc real_estate;
+-------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| cardId | varchar(18) | NO | | NULL | |
| projectName | varchar(50) | NO | | NULL | |
| address | varchar(200) | NO | | NULL | |
| houseType | varchar(20) | NO | | NULL | |
| area | int | NO | | NULL | |
| buildTime | date | NO | | NULL | |
+-------------+--------------+------+-----+---------+----------------+
7 rows in set (0.00 sec)mysql> select * from real_estate;
+----+--------+--------------+-------------------+-----------+------+------------+
| id | cardId | projectName | address | houseType | area | buildTime |
+----+--------+--------------+-------------------+-----------+------+------------+
| 1 | 1111 | 天虹庄园 | 庄派路12号 | 三室 | 89 | 2023-01-31 |
| 2 | 2222 | 中粮家园 | 经天路21号 | 二室 | 68 | 2023-01-31 |
| 3 | 3333 | 招商公寓 | 宏运大道33号 | 四室 | 118 | 2023-01-31 |
| 4 | 4444 | 金地名筑 | 天景路12号 | 三室 | 89 | 2023-01-31 |
| 5 | 1111 | 浦发庄园 | 经天路13号 | 三室 | 98 | 2023-01-31 |
| 6 | 2222 | 中兴家园 | 通天路21号 | 二室 | 60 | 2023-01-31 |
| 7 | 1111 | 粮油公寓 | 宏运大道33号 | 四室 | 118 | 2023-01-31 |
| 8 | 2222 | 金地名筑 | 天景路12号 | 三室 | 89 | 2023-01-31 |
+----+--------+--------------+-------------------+-----------+------+------------+
8 rows in set (0.00 sec)
# 导入初始数据
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table real_estate \
--target-dir /tmp/school/re \
--m 1# hdfs中查看数据,数据成功导入
[root@hadoop02 ~]# hdfs dfs -cat /tmp/school/re/part-m-00000
2023-03-10 17:00:26,770 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1,1111,天虹庄园,庄派路12号,三室,89,2023-01-31
2,2222,中粮家园,经天路21号,二室,68,2023-01-31
3,3333,招商公寓,宏运大道33号,四室,118,2023-01-31
4,4444,金地名筑,天景路12号,三室,89,2023-01-31
5,1111,浦发庄园,经天路13号,三室,98,2023-01-31
6,2222,中兴家园,通天路21号,二室,60,2023-01-31
7,1111,粮油公寓,宏运大道33号,四室,118,2023-01-31
8,2222,金地名筑,天景路12号,三室,89,2023-01-31# mysql中添加数据
mysql> insert into real_estate values(9,'2222','碧桂园','北京路888号','别墅',888,'2023-02-01');
Query OK, 1 row affected (0.00 sec)
mysql> select * from real_estate;
+----+--------+--------------+-------------------+-----------+------+------------+
| id | cardId | projectName | address | houseType | area | buildTime |
+----+--------+--------------+-------------------+-----------+------+------------+
| 1 | 1111 | 天虹庄园 | 庄派路12号 | 三室 | 89 | 2023-01-31 |
| 2 | 2222 | 中粮家园 | 经天路21号 | 二室 | 68 | 2023-01-31 |
| 3 | 3333 | 招商公寓 | 宏运大道33号 | 四室 | 118 | 2023-01-31 |
| 4 | 4444 | 金地名筑 | 天景路12号 | 三室 | 89 | 2023-01-31 |
| 5 | 1111 | 浦发庄园 | 经天路13号 | 三室 | 98 | 2023-01-31 |
| 6 | 2222 | 中兴家园 | 通天路21号 | 二室 | 60 | 2023-01-31 |
| 7 | 1111 | 粮油公寓 | 宏运大道33号 | 四室 | 118 | 2023-01-31 |
| 8 | 2222 | 金地名筑 | 天景路12号 | 三室 | 89 | 2023-01-31 |
| 9 | 2222 | 碧桂园 | 北京路888号 | 别墅 | 888 | 2023-02-01 |
+----+--------+--------------+-------------------+-----------+------+------------+
9 rows in set (0.00 sec)# 实现增量的导入
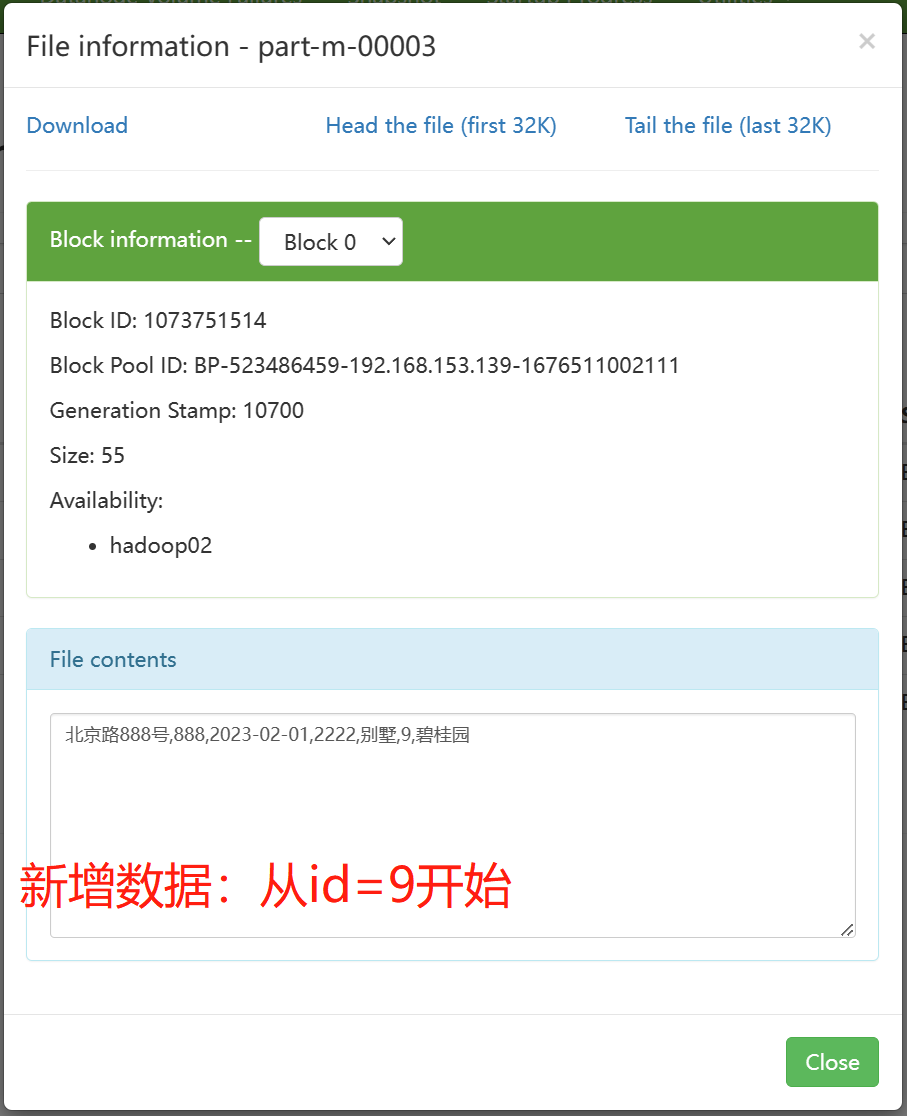
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table real_estate \
--target-dir /tmp/school/real_estate \
--incremental append \ ——increment-追加模式
--check-column id \ ——追加的字段
--last-value 8 \ ——last-value=8,输出从9开始
--m 1
验证导入数据目录,可以发现多了一个文件,里面就是增量数据。
Lastmodified增量导入
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table real_estate \
--target-dir /tmp/school/re \
--check-column buildTime \
--incremental lastmodified \
--last-value '2023-02-01' \ ——"lastmodified"模式
--m 1 \
--append导入最后插入的一条数据,但却此处却插入了两条数据。
采用lastmodified模式处理增量时,会将大于等于last-value值的数据当作增量插入。
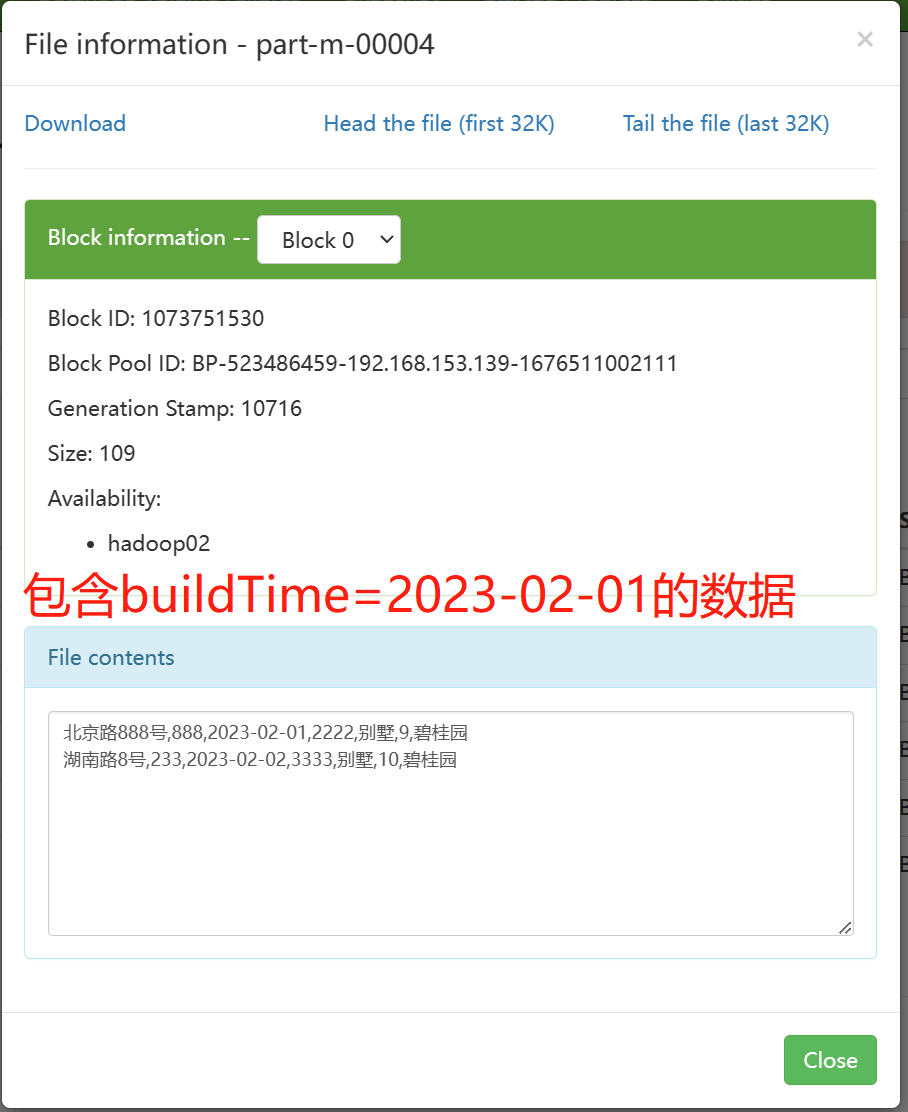
Lastmodified模式:append、merge-key
使用lastmodified 模式进行增量处理要指定增量数据是以append 模式(附加)还是 merge-key(合并)模式添加。
sqoop import \
--connect jdbc:mysql://192.168.153.134:3306/school \
--username root \
--password 123123 \
--table real_estate \
--target-dir /tmp/school/re \
--check-column buildTime \
--incremental lastmodified \
--last-value '2023-02-01' \
--m 1 \
--merge-key idmerge-key模式进行了一次完整了mapreduce操作。
关于lasimodified中的两种模式:
append只会追加数据到一个新的文件中,并且会产生数据的重复问题
因为默认是从指定的last-value大于等于其值的数据开始导入
merge-key 把增量的数据合并到一个文件中。处理追加增量数据之外,如果之前的数据有变化,也可以进行修改操作。底层相当于进行了一次完整的mr作业,数据不会重复。
五、sqoop数据导出export
将数据从 Hadoop 生态体系导出到 RDBMS 数据库导出前,目标表必须存在于目标数据库中。也就是说,导出的目标表需要自己手动提前创建,sqoop并不会帮我们创建复制表结构。
export 有三种模式:
默认操作:是从将文件中的数据使用 INSERT 语句插入到表中
更新模式:Sqoop 将生成 UPDATE 替换数据库中现有记录的语句。
调用模式:Sqoop 将为每条记录创建一个存储过程调用。
5.1 默认模式导出HDFS数据到MySQL
默认情况下,sqoopexport 将每行输入记录转换成一条INSERT 语句,添加到目标数据库表中。如果数据库中的表具有约束条件(例如,其值必须唯一的主键列)并且已有数据存在,则必须注意避免插入违反这些约束条件的记录。如果INSERT 语句失败,导出过程将失败。此模式主要用于将记录导出到可以接收这些结果的空表中。通常用于全表数据导出。
导出时可以是将 Hive 表中的全部记录或者 HDFS 数据(可以是全部字段也可以部分字段)导出到 Mysql 目标表。
hdfs dfs -mkdir /emp_data
hdfs dfs -put emp_data.txt /emp_data1. 手动创建MySQL中的目标表
mysql> create table employee (id int not null primary key,name varchar(10),deg varchar(20),salary int,dept varchar(10));2. 执行导出命令
sqoop export \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--table employee \
--export-dir /emp_data/相关配置参数
--input-fields-terminated-by '\t'
指定文件中的分隔符。
--columns
选择列并控制它们的排序。当导出数据文件和目标表字段列顺序完全致的时候可以不写。否则以逗号为间隔选择和排列各个列。没有被包含在 -columns 后面列名或字段要么具备默认值,要么就允许插入空值,否则数据库会拒绝凌受 sqoop 导出的数据,导致 Sqoop 作业失败。
--export-dir
导出目录。在执行导出的时候,比如指定这个参数,同时需要具备--table 或 --call参数两者之一。
--table指的是导出数据库当中对应的表。--call指的是某个存储过程。
--input-null-string/ --input-null-non-string
如果没有指定第一个参数,对于字符串类型的列来说,“null”这个字符串就会被翻译成空值。
如果没有使用第二个参数,无论是“null”字符串还是空字符串,对于非字符串类型的字段来说,这两个类型的空串都会被翻译成空值。
如:--input-null-string "\\N"/ --input-null-non-string "\\N"
5.2 更新导出(updateonly模式)
更新导出:
updateonly 只更新已经存在的数据,不会执行insert增加新的数据。
allowinsert 更新已有的数据,插入新的数据,底层相当于insert&update
--update-key
更新标识,即根据某个字段进行更新。例如id,可以指定多个更新标识的字段,多个字段之间用逗号分隔。
--updatemod
指定updateonly(默认模式),仅仅更新已存在的数据记录,不会插入新纪录。
sqoop export \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--table updateonly \
--export-dir /updateonly _1/新增一个文件updateonly_2,修改前三条数据并新增一条记录。执行更新导出:
sqoop export \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--table updateonly \
--export-dir /updateonly _2/
--update-key id \
--update-mode updateonlyupdateonly 只更新已经存在的数据,不会执行insert增加新的数据。
5.3 更新导出(allowinsert模式)
--update-key
更新标识,即根据某个字段进行更新。例如id,可以指定多个更新标识的字段,多个字段之间用逗号分隔。
--updatemod
指定allowinsert,更新已存在的数据记录,同时插入新纪录。实质上是一个insert&update的操作。
sqoop export \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--table updateonly \
--export-dir /updateonly _1/新增一个文件updateonly_2,修改前三条数据并新增一条记录。执行更新导出:
sqoop export \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--table updateonly \
--export-dir /updateonly _2/
--update-key id \
--update-mode allowinsertallowinsert 更新已有的数据,插入新的数据,底层相当于insert&update
六、sqoop job作业
创建job
创建一个从DB数据库的emp表导入到HDFS文件的作业。
注意:import前面要有空格。
bin/sqoop --create castjob \
-- import \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password 123123 \
--target-dir /sqoopresult \
--table emp \
--m 1验证作业(--list)
bin/sqoop job --list检查作业(--show)
bin/sqoop job --show myjob执行作业(--exec)
bin/sqoop job --exec myjob免密执行job
sqoop 在创建 job 时,使用--password-file 参数,可以避免输入 mysql 密码,如果使用--password将出现警告,并且每次都要手动输入密码才能执行job,sqoop规定密码文件必须存放在 HDFS 上,并且权限必须是 400。
检查sqoop的sqoop-site.xml是否存在如下配置:
<property><name>sqoop.metastore.client.record.password</name><value>true</value><description>If true, allow saved passwords in the metastore.</description>
</property>bin/sqoop job --create castjob1 -- import \
--connect jdbc:mysql://192.168.153.134:3306/userdb \
--username root \
--password-file /input/sqoop/pwd/castmysql.pwd \
--target-dirsqoopresule \
--table emp \
--m 1相关文章:
大数据技术之Sqoop——SQL to Hadoop
一、简介sqoop (sql to hadoop)是一款开源的工具,主要用于在 Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MSQL,Oracle,Post…...

Java议题
序号议题 解释MyBatis官网1mapper文件中什么时候使用 # 什么时候必须用 $ 1、关键字作为参数,使用"$",两边不加""。 2、非关键字作为参数,使用"#"防注入。 其他情况优先使用"#" 2主键回填࿰…...
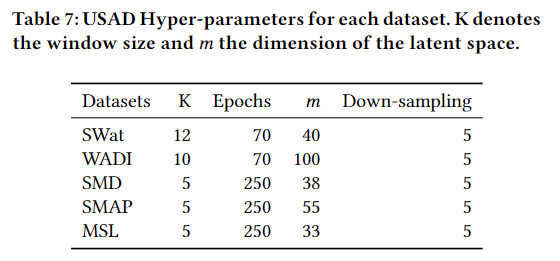
【阅读论文】USAD:多变量时间序列上的无监督异常检测
USAD : UnSupervised Anomaly Detection on Multivariate Time Series 摘要 IT系统的自动监控是Orange目前面临的挑战。考虑到其IT运营所达到的规模和复杂性,随着时间的推移,用于推断正常和异常行为的测量所需的传感器数量急剧增加,使得传统…...

Java多线程:ReentrantLock中的方法
公平锁与非公平锁 ReentrantLock有一个很大的特点,就是可以指定锁是公平锁还是非公平锁,公平锁表示线程获取锁的顺序是按照线程排队的顺序来分配的,而非公平锁就是一种获取锁的抢占机制,是随机获得锁的,先来的未必就一…...

RabbitMQ初识快速入门
RabbitMQ初识&快速入门1.初识MQ1.1.同步和异步通讯1.1.1.同步通讯1.1.2.异步通讯1.2.技术对比:2.快速入门2.1.安装RabbitMQ2.1.1 下载镜像2.1.2 安装MQ2.2.RabbitMQ消息模型2.3.导入Demo工程2.4.入门案例2.4.1.publisher实现2.4.2.consumer实现2.5.总结1.初识MQ…...
由浅入深了解HashMap源码
由经典面试题引入,讲解一下HashMap的底层数据结构?这个面试题你当然可以只答,HashMap底层的数据结构是由(数组链表红黑树)实现的,但是显然面试官不太满意这个答案,毕竟这里有一个坑需要你去填&a…...
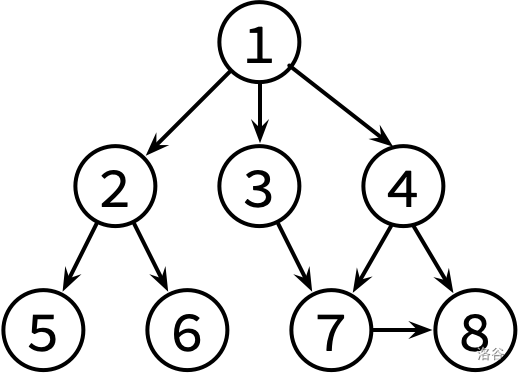
P5318 【深基18.例3】查找文献
题目描述 小K 喜欢翻看洛谷博客获取知识。每篇文章可能会有若干个(也有可能没有)参考文献的链接指向别的博客文章。小K 求知欲旺盛,如果他看了某篇文章,那么他一定会去看这篇文章的参考文献(如果他之前已经看过这篇参考…...

Error caught was: No module named ‘triton‘
虽然报错但是不影响程序运行: A matching Triton is not available, some optimizations will not be enabled. Error caught was: No module named triton解决: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple triton2.0.0.dev20221120...

Ruby设计-开发日志
Log 1 产品 Product 1.1 创建 Product 创建名为 project 的 rails 应用 rails new project创建 Product 模型 rails generate scaffold Product title:string description:text image_url:string price:decimal这会生成一个 migration ,我们需要进一步修改这个…...

SpringBoot 调用外部接口的三种方式
方式一:使用原始httpClient请求 /** description get方式获取入参,插入数据并发起流程* params documentId* return String*/ RequestMapping("/submit/{documentId}") public String submit1(PathVariable String documentId) throws ParseE…...
C 中的结构体
C 中的结构体 C 数组允许定义可存储相同类型数据项的变量,结构是 C 编程中另一种用户自定义的可用的数据类型,它允许您存储不同类型的数据项。 结构体中的数据成员可以是基本数据类型(如 int、float、char 等),也可以…...

nodejs安装教程
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时,可以用于在服务器端运行 JavaScript 代码。以下是 Node.js 的安装教程: 步骤 1:下载 Node.js 访问 Node.js 的官方网站 https://nodejs.org/,进入官方下载页面。 在下载页…...

【华为OD机试】1029 - 整数与IP地址间的转换
文章目录一、题目🔸题目描述🔸输入输出🔸样例1二、代码参考作者:KJ.JK🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 &#x…...
【FPGA实验1】FPGA点灯工程师养成记
对于FPGA几个与LED相关的实验(包括按键点灯、流水灯、呼吸灯等)的记录,方便日后查看。这世界上就又多了一个FPGA点灯工程师了😏 成为一个FPGA点灯工程师分三步:一、按键点灯1、按键点灯程序2、硬件实现二、流水灯1、流…...
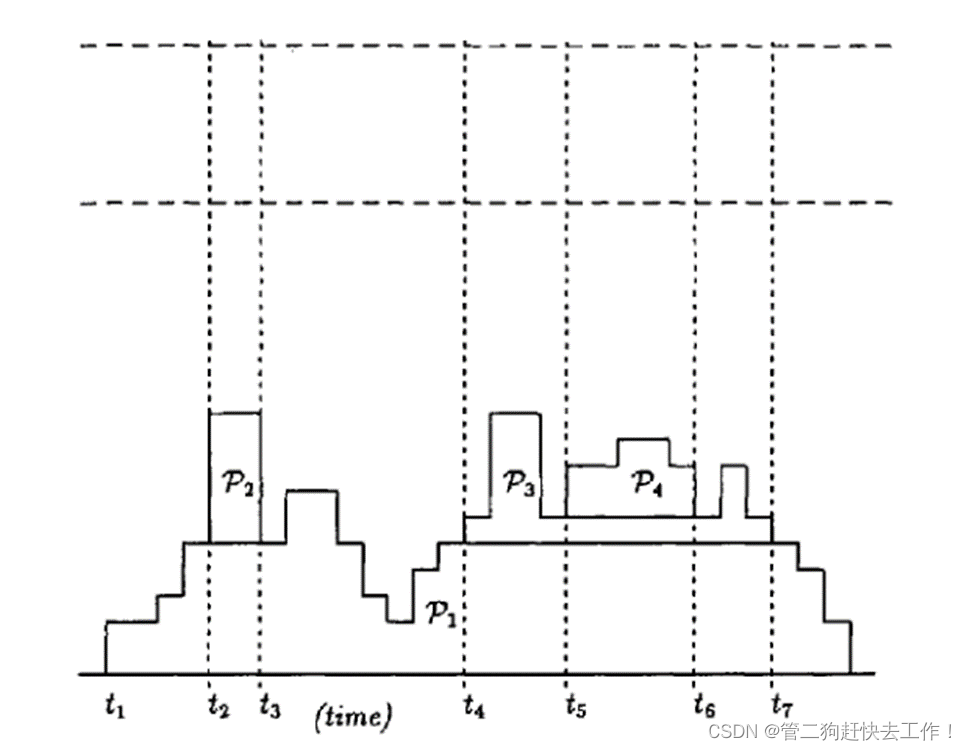
操作系统论文导读(三):Stack-based scheduling of realtime processes基于堆栈的实时进程调度
目录 一、论文核心思想: 二、基本的相关条件 作业运行的条件: 作业抢占其他作业的条件: 三、基本的相关定义 四、基本的相关调度 五、基本的相关调度 六、堆栈资源共享 七、与PCP的比较 一、论文核心思想: -引入了一个抢占优…...

音频延时测试方法与实现
音频延时测试方法有以下几种 1、使用专业的测试设备,通过专业的音频测试仪器可以准确测量音频延时,如常见声学分析仪、信号发生器、声卡Smaart(介绍测试延时方法链接:https://blog.csdn.net/weixin_48408892/article/details/1273…...

在 Python 中管理机密的四种方法
我们生活在一个应用程序用于做任何事情的世界,无论是股票交易还是预订沙龙,但在幕后,连接是使用秘密完成的。必须适当管理机密,例如数据库密码、API 密钥、令牌等,以避免任何泄露。 管理机密的需求对任何组织都至关重…...

全国青少年信息素养大赛Python编程挑战赛初赛试题说明
Python 编程挑战赛初赛采用线上考试比赛形式,分为小学组和初中组。不同组别的考核重难点略有不同,考核内容主要是 Python 基础知识,共 30 题,均为单选题,具体考核如下: 小学组考核内容主要是 Python 基础知识,包括输入输出,变量,条件结构,计次循环和无限循环,海龟库…...

无需魔法打开即用的 AI 工具集锦
作者:明明如月学长, CSDN 博客专家,蚂蚁集团高级 Java 工程师,《性能优化方法论》作者、《解锁大厂思维:剖析《阿里巴巴Java开发手册》》、《再学经典:《EffectiveJava》独家解析》专栏作者。 热门文章推荐…...

如何进行SEO站内优化,让你的网站更易被搜索引擎收录
我们了解了 SEO 的流程,知道了哪些元素对 SEO 的效果会产生关键影响,接下来,我们就该正式开始动手,打造一个让搜索引擎“爱不释手”的网站。 为了方便理解与记忆,我们将网站划分为几个模块,告诉你优化网站…...

CentOS8实战:ZeroTier构建安全异地虚拟局域网
1. 为什么选择ZeroTier替代传统内网穿透方案 最近在帮朋友搭建远程办公环境时,遇到了一个典型问题:分布在三个不同物理位置的服务器需要像在同一个办公室内网那样互相访问。最初考虑使用FRP方案,但实测下来发现几个痛点:首先是带宽…...

智慧树自动刷课终极指南:3分钟快速上手Autovisor免费工具
智慧树自动刷课终极指南:3分钟快速上手Autovisor免费工具 【免费下载链接】Autovisor 2025智慧树刷课脚本 基于Python Playwright的自动化程序 [有免安装版] 项目地址: https://gitcode.com/gh_mirrors/au/Autovisor 还在为智慧树网课的手动操作烦恼吗&#…...

如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南
如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management…...

openpilot自动驾驶系统深度解析:架构剖析与实战指南
openpilot自动驾驶系统深度解析:架构剖析与实战指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/…...

Docker化OpenOffice部署:文档自动化转换服务实战指南
1. 项目概述与核心价值最近在折腾一个老项目,需要处理一批.odt格式的文档,这让我想起了那个曾经在开源办公软件领域与微软Office分庭抗礼的“老将”——OpenOffice。虽然现在LibreOffice的风头更盛,但OpenOffice依然有其独特的生态位和用户群…...

Mantic.sh:Bash脚本实现的终端命令自动化与效率提升工具
1. 项目概述:一个为开发者打造的终端效率工具如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你肯定对效率工具有着近乎偏执的追求。从cd到ls,从grep到awk,我们依赖这些…...
)
乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓)
更多请点击: https://intelliparadigm.com 第一章:乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓) ElevenLabs 官方文档中仅标注 ur 为乌尔…...

Unity区域加载系统:实现开放世界无缝加载与内存优化
1. 项目概述:一个高效、可扩展的Unity区域加载系统 最近在做一个开放世界风格的项目,场景大了之后,加载卡顿和内存管理就成了老大难问题。传统的Unity场景加载,要么一股脑全塞进内存,要么就得自己写一堆脚本来手动控制…...

Midjourney像素艺术提示词工程:98%新手忽略的4个隐藏权重指令,实测提升风格还原度320%
更多请点击: https://intelliparadigm.com 第一章:Midjourney像素艺术提示词工程的底层逻辑重构 像素艺术在 Midjourney 中并非天然适配的生成模态,其高精度、低分辨率、强风格约束的特性与扩散模型默认的连续性渲染范式存在根本张力。要实现…...

【最新 v2.7.1 版本安装包】OpenClaw 零基础无痛部署,无需命令零代码保姆级快速上手
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...