【优化算法】使用遗传算法优化MLP神经网络参数(TensorFlow2)
文章目录
- 任务
- 查看当前的准确率情况
- 使用遗传算法进行优化
- 完整代码
任务
使用启发式优化算法遗传算法对多层感知机中中间层神经个数进行优化,以提高模型的准确率。
待优化的模型:
基于TensorFlow2实现的Mnist手写数字识别多层感知机MLP
# MLP手写数字识别模型,待优化的参数为layer1、layer2
model = tf.keras.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(layer1, activation='relu'),tf.keras.layers.Dense(layer2, activation='relu'),tf.keras.layers.Dense(10,activation='softmax') # 对应0-9这10个数字
])
查看当前的准确率情况
设置随机树种子,避免相同结构的神经网络其结果不同的影响。
random_seed = 10
np.random.seed(random_seed)
tf.random.set_seed(random_seed)
random.seed(random_seed)
model = tf.keras.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(32, activation='relu'),tf.keras.layers.Dense(10,activation='softmax') # 对应0-9这10个数字
])
optimizer = tf.keras.optimizers.Adam()
loss_func = tf.keras.losses.SparseCategoricalCrossentropy()
model.compile(optimizer=optimizer,loss=loss_func,metrics=['acc'])
history = model.fit(dataset, validation_data=test_dataset, epochs=5, verbose=1)
score = model.evaluate(test_dataset)
print("测试集准确率:",score) # 输出 [损失率,准确率]
Epoch 1/5
235/235 [==============================] - 1s 5ms/step - loss: 0.4663 - acc: 0.8703 - val_loss: 0.2173 - val_acc: 0.9361
Epoch 2/5
235/235 [==============================] - 1s 4ms/step - loss: 0.1882 - acc: 0.9465 - val_loss: 0.1604 - val_acc: 0.9521
Epoch 3/5
235/235 [==============================] - 1s 4ms/step - loss: 0.1362 - acc: 0.9608 - val_loss: 0.1278 - val_acc: 0.9629
Epoch 4/5
235/235 [==============================] - 1s 4ms/step - loss: 0.1084 - acc: 0.9689 - val_loss: 0.1086 - val_acc: 0.9681
Epoch 5/5
235/235 [==============================] - 1s 4ms/step - loss: 0.0878 - acc: 0.9740 - val_loss: 0.1077 - val_acc: 0.9675
40/40 [==============================] - 0s 2ms/step - loss: 0.1077 - acc: 0.9675
测试集准确率: [0.10773944109678268, 0.9674999713897705]
准确率为96.7%
使用遗传算法进行优化
使用scikit-opt提供的遗传算法库进行优化。(pip install scikit-opt)
官方文档:https://scikit-opt.github.io/scikit-opt/#/zh/README
# 遗传算法调用
ga = GA(func=loss_func, n_dim=2, size_pop=4, max_iter=3, prob_mut=0.15, lb=[10, 10], ub=[256, 256], precision=1)
优化目标函数loss_func:1 - 模型准确率(求优化目标函数的最小值)
待优化的参数数量n_dim:2
种群数量size_pop:4
迭代次数max_iter:3
变异概率prob_mut:0.15
待优化两个参数的取值范围均为10-256
精确度precision:1
# 定义多层感知机模型函数
def mlp_model(layer1, layer2):model = tf.keras.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(layer1, activation='relu'),tf.keras.layers.Dense(layer2, activation='relu'),tf.keras.layers.Dense(10,activation='softmax') # 对应0-9这10个数字])optimizer = tf.keras.optimizers.Adam()loss_func = tf.keras.losses.SparseCategoricalCrossentropy()model.compile(optimizer=optimizer,loss=loss_func,metrics=['acc'])return model# 定义损失函数
def loss_func(params):random_seed = 10np.random.seed(random_seed)tf.random.set_seed(random_seed)random.seed(random_seed)layer1 = int(params[0])layer2 = int(params[1])model = mlp_model(layer1, layer2)history = model.fit(dataset, validation_data=test_dataset, epochs=5, verbose=0)return 1 - history.history['val_acc'][-1]ga = GA(func=loss_func, n_dim=2, size_pop=4, max_iter=3, prob_mut=0.15, lb=[10, 10], ub=[256, 256], precision=1)
bestx, besty = ga.run()
print('bestx:', bestx, '\n', 'besty:', besty)
结果:
bestx: [165. 155.]
besty: [0.02310002]
通过迭代,找到layer1、layer2的最好值为165、155,此时准确率为1-0.0231=0.9769。
查看每轮迭代的损失函数值图(1-准确率):
Y_history = pd.DataFrame(ga.all_history_Y)
fig, ax = plt.subplots(2, 1)
ax[0].plot(Y_history.index, Y_history.values, '.', color='red')
Y_history.min(axis=1).cummin().plot(kind='line')
plt.show()
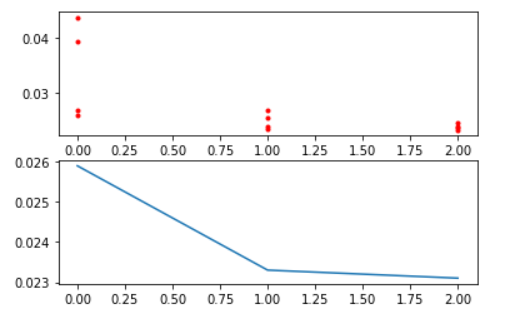
上图为三次迭代种群中,种群每个个体的损失函数值(每个种群4个个体)。
下图为三次迭代种群中,种群个体中的最佳损失函数值。
可以看出,通过遗传算法,其准确率有一定的提升。
增加种群数量及迭代次数效果可更加明显。
完整代码
# python3.6.9
import tensorflow as tf # 2.3
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import random
from sko.GA import GA# 数据导入,获取训练集和测试集
(train_image, train_labels), (test_image, test_labels) = tf.keras.datasets.mnist.load_data()# 增加通道维度
train_image = tf.expand_dims(train_image, -1)
test_image = tf.expand_dims(test_image, -1)# 归一化 类型转换
train_image = tf.cast(train_image/255, tf.float32)
test_image = tf.cast(test_image/255, tf.float32)
train_labels = tf.cast(train_labels, tf.int64)
test_labels = tf.cast(test_labels, tf.int64)# 创建Dataset
dataset = tf.data.Dataset.from_tensor_slices((train_image, train_labels)).shuffle(60000).batch(256)
test_dataset = tf.data.Dataset.from_tensor_slices((test_image, test_labels)).batch(256)# 定义多层感知机模型函数
def mlp_model(layer1, layer2):model = tf.keras.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(layer1, activation='relu'),tf.keras.layers.Dense(layer2, activation='relu'),tf.keras.layers.Dense(10,activation='softmax') # 对应0-9这10个数字])optimizer = tf.keras.optimizers.Adam()loss_func = tf.keras.losses.SparseCategoricalCrossentropy()model.compile(optimizer=optimizer,loss=loss_func,metrics=['acc'])return model# 定义损失函数
def loss_func(params):random_seed = 10np.random.seed(random_seed)tf.random.set_seed(random_seed)random.seed(random_seed)layer1 = int(params[0])layer2 = int(params[1])model = mlp_model(layer1, layer2)history = model.fit(dataset, validation_data=test_dataset, epochs=5, verbose=0)return 1 - history.history['val_acc'][-1]ga = GA(func=loss_func, n_dim=2, size_pop=4, max_iter=3, prob_mut=0.15, lb=[10, 10], ub=[256, 256], precision=1)
bestx, besty = ga.run()
print('bestx:', bestx, '\n', 'besty:', besty)
相关文章:
【优化算法】使用遗传算法优化MLP神经网络参数(TensorFlow2)
文章目录任务查看当前的准确率情况使用遗传算法进行优化完整代码任务 使用启发式优化算法遗传算法对多层感知机中中间层神经个数进行优化,以提高模型的准确率。 待优化的模型: 基于TensorFlow2实现的Mnist手写数字识别多层感知机MLP # MLP手写数字识别…...
CAM类激活映射 |神经网络可视化 | 热力图
文章目录前言:安装库:分类案例--ResNet50分割案例AttributeError: ‘tuple‘ object has no attribute ‘cpu‘RuntimeError: grad can be implicitly created only for scalar outputsTypeError: cant convert cuda:0 device type tensor to numpy. Use…...
RecyclerView+BaseRecyclerViewAdapterHelper显示不全只显示第一行item的解决问题
RecyclerViewBaseRecyclerViewAdapterHelper显示不全只显示第一行item,我懵了…,我不说多,直接说吧 先看一下适配器代码中的convert()方法: class MineRadioAdapter(layoutResId: Int R.layout.item_my_live) :BaseQuickAdapte…...
解决后端无法对前端的ajax请求重定向
本章目录: 问题描述 AJAX请求后端直接重定向失败解决方案 后端拦截请为响应头添加重定向标志后端拦截器为响应头添加重定向路径前端响应拦截器获取响应头数据,并通过location.href url 完成页面跳转一、问题描述 本来想在拦截器里设置未登录用户访问指…...
【Python】1分钟就能制作精美的框架图?太棒啦
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、准备二、基本使用与例子1.初始化与导出2.节点类型3.集群块4.自定义线的颜色与属性总结前言 Diagrams 是一个基于Python绘制云系统架构的模块,它能…...

淘宝必备的补单技巧及注意事项!
补单,是优化善后的s单。单只是模拟用户的购物习惯,而补单同时还要模拟整个店铺的综合数据,包括点击率、转化率等等,补到略高于同行、竞品的平均数据时,淘宝会判断为买家比较喜欢你的商品,从而给你更多推荐机…...
【实用篇】SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式,系统详解springcloud分布式
文章目录一、服务拆分1.1 服务拆分Demo1.2 微服务远程调用二、Eureka2.1 Eureka原理2.2 Eureka-server服务搭建2.3 eureka-client服务注册2.4 eureka-client服务复制2.5 eureka服务发现三、Ribbon负载均衡3.1 负载均衡原理3.2 负载均衡策略3.3 自定义负载均衡策略3.4 饥饿加载与…...

私人飞机、公务机包机会成为富豪圈的主流出行方式吗?
从炫耀性消费到按需使用,私人飞机的消费群体正在被拓宽,但离“成为主流”还有一段距离。“时间就是金钱”为有钱人消费私人飞机提供合理动机,而这群高净值人群的数量增长则成为撑起市场基本面。据相关数据显示,2018年全球超级富豪…...

Oracle组织架构
组织架构 (一)业务组(BG) (二)法律实体(LE) (三)业务实体(OU) (四)库存组织(INV) …...

最小公倍数
目录 最小公倍数 程序设计 程序分析 最小公倍数 【问题描述】给定两个正整数,计算这两个数的最小公倍数。 【输入形式】输入包含多组测试数据,每组只有一行,包括两个不大于1000的正整数. 【输出形式】 对于每个测试用例,给出这两个数的最小公倍数,每个实例输出一行。…...

二叉树的后序遍历(力扣145)
目录 题目描述: 解法一:递归法 解法二:迭代法 解法三:Morris遍历 二叉树的后序遍历 题目描述: 给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。 示例 1: 输入:root …...

《Effective C++》读书纪实 -- 诸君同享
文章目录《Effective C》是一本经典的C编程指南,共包含50条C编程的最佳实践。 确定你的构造函数的行为 在构造函数中,应该尽可能地避免调用虚函数、非静态成员函数和虚基类的函数。 尽量使用const、enum、inline替换#define 使用const、enum、inline可以…...

【云原生】K8S-ConfigMap 实现应用和配置分离
文章目录前言ConfigMap 背景ConfigMap 创建方式ConfigMap 的使用使用 ConfigMap 的注意事项总结前言 Kubernetes 是目前最流行的容器编排系统之一,它提供了丰富的功能来支持容器化应用程序的管理和部署。 ConfigMap 是 Kubernetes 中重要的资源对象,用…...
)
java -测距工具(经纬度)
代码 /*** 测距工具* author qb*/ public class DistanceUtils {/*** 赤道半径*/private static final double EARTH_RADIUS 6378.137;private static double rad(double d) {return d * Math.PI / 180.0;}/*** Description : 通过经纬度获取距离(单位:米)* Group…...

postgres分区表的创建-基于继承
参考文档: http://postgres.cn/docs/12/ddl-partitioning.html 创建基于继承的分区表的步骤 1 创建父表 2 创建子表,从父表继承过来 3 创建函数及触发器,使插入的数据根据规则,插入到对应的子表中 -- 创建父表 CREATE TABLE a…...
Docker应用部署
文章目录Docker 应用部署一、部署MySQL二、部署Tomcat三、部署Nginx四、部署RedisDocker 应用部署 一、部署MySQL 搜索mysql镜像 docker search mysql拉取mysql镜像 docker pull mysql:5.6创建容器,设置端口映射、目录映射 # 在/root目录下创建mysql目录用于存…...
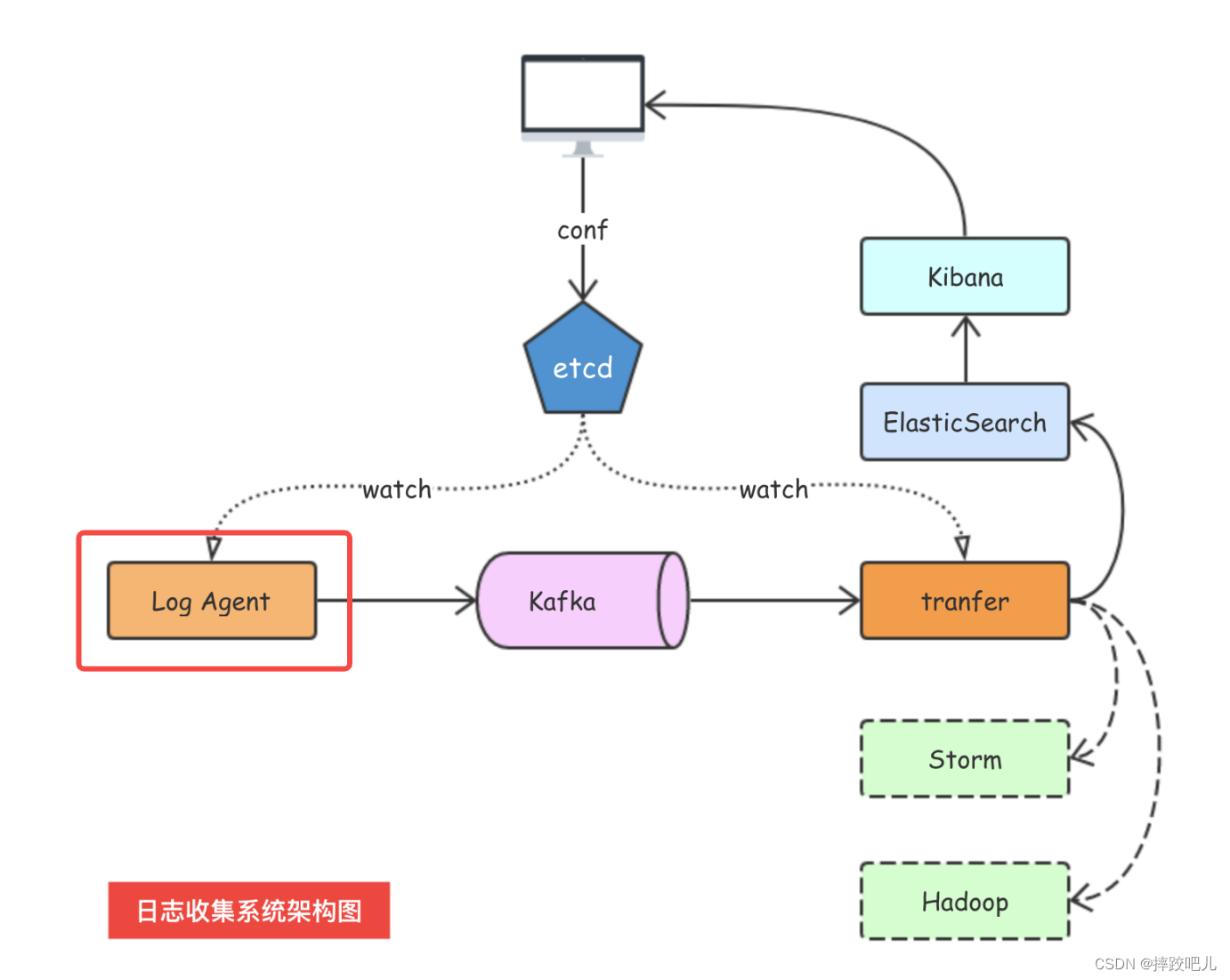
使用golang实现日志收集系统的logagent
整体架构 参考 七米老师的日志收集项目 主要用go实现logagent的部分,logagent的作用主要是实时监控日志追加的变化,并将变化发送到kafka中。 之前我们已经实现了 用go连接kafka并向其中发送数据,也实现了使用tail库监控日志追加操作。 我们…...

小红书点赞不显示怎么回事?小红书笔记评论被吞怎么办
小红书作为一个互联网产品,是一个软件。既然是软件就会有一定的程序漏洞,这是无法避免的。但是很多时候其实并不一定是漏洞的问题。今天就来和大家谈谈小红书点赞不显示怎么回事,小红书评论被吞又是怎么一回事,这些难道都是程序性…...

地址变换和缺页置换习题
1.设某进程页面的访问序列为4,3,2,1,4,3,5,4,3,2,1,5,当分配给该进程的内存页框数分别为3和4时,对于先进先出,最近最少使用,最佳页面置换算法,分别发生多少次缺页中断? 答: 分配的…...
)
PAT 乙级 1010 一元多项式求导(解题思路+AC代码)
题目: 设计函数求一元多项式的导数。(注:xn(n为整数)的一阶导数为nxn−1。) 输入格式: 以指数递降方式输入多项式非零项系数和指数(绝对值均为不超过 1000 的整数)。数字间以空格分…...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...

OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统
OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库
5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 凌晨两点,小林还在为明…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

DriveBench:面向真实驾驶场景的长序列多智能体交互基准测试框架
1. 项目概述:从“世界基准”到“驾驶基准”的演进如果你在自动驾驶或者计算机视觉领域摸爬滚打过几年,一定对“基准测试”(Benchmark)这个词又爱又恨。爱的是,它提供了一个相对公平的擂台,让不同算法、不同…...
,全程复制粘贴即可)
从0到1:手把手教你搭建VSCode(附避坑指南,拒绝报错),全程复制粘贴即可
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...

开源技能库构建指南:Git+Markdown+Docsify打造个人技术知识体系
1. 项目概述:一个开源技能库的诞生与价值在技术领域,尤其是软件开发、运维和数据分析等方向,我们每天都在与海量的工具、框架和命令打交道。时间一长,一个很现实的问题就摆在了面前:那些曾经花了好几个小时才调通的复杂…...

Rekall:基于时空查询的视频内容智能检索开源框架
1. 项目概述:Rekall,一个面向视频时空查询的开源利器 如果你曾经尝试过从一段长视频里,精准地找出“那个穿红色衣服的人从画面左侧走到右侧的片段”,或者想快速定位“所有出现这只特定宠物狗的镜头”,你就会知道这有多…...