JavaEE简单示例——基于注解的SSM整合
基于注解的SSM整合
在之前我们进行了基于XML配置文件的整合,这次我们介绍基于注解的SSM框架的整合。基于注解的含义是将我们之前所有的配置文件用java类来代替,也就是我们会在Java类中编写之前我们之前在配置文件中编写的内容。 首先我们将之前我们编写的基于XML的SSM整合复制一份,我们基于这个项目去改造成基于注解的SSM整合最终我们的效果是要将resources文件夹下面的所有的配置文件都用Java类去代替
MyBatis的注解转换
首先还是从MyBatis开始,我们之前是基于XML配置文件开始的,而我们用到的是application-dao.xml配置文件,在这个文件中,我们配置了SqlSessionFactory和Mapper以及我们的数据源,那么现在,我们就把这些配置文件搬到Java类中。 我们首先打开我们的application-dao.xml文件查看里面的内容,在这个文件里面我们做了三件事:1.声明了数据源。2.配置SqlSessionFactory。3.配置dao层接口映射文件。那么我们就依次将这些配置文件搬出来。 首先,我们创建一个软件包叫做com.spring.config用来存放我们Java类的配置文件,然后创建第一个配置类叫做JdbcConfig,这个类用来配置数据源信息。 之前我们的数据源对象是通过一个类去帮我们代理,这个类叫做com.alibaba.druid.pool.DruidDataSource,现在我们继续使用这个类来代理我们的数据源对象,如果要使用第三方Bean时候,我们要使用@Bean注解,声明这是我们引用的Bean,并将其注册到IoC容器中。 在之前的XML配置文件中,我们要获取一个类的对象,我们需要用class指定类的全路径,然后我们就可以获取到这个类的对象。我们在类中定义一个方法,这个方法的返回值就是我们想要的对象的类型,比如现在我需要一个dataSource,那么我就把我的方法的返回值设置成dataSource,这样我们就可以在IoC容器中注册进一个dataSource类型的对象。 这个地方需要去理解一下,注意我们方法的返回值的类型即可。
package com.spring.config;import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;public class JdbcConfig {@Value("jdbc:mysql://localhost:3306/mybatis")private String url;@Value("com.mysql.cj.jdbc.Driver")private String driver;@Value("root")private String username;@Value("@gaoyang1")private String password;@Beanpublic DruidDataSource dataSource(){DruidDataSource dataSource = new DruidDataSource();dataSource.setUsername(username);dataSource.setUrl(url);dataSource.setPassword(password);dataSource.setDriverClassName(driver);return dataSource;}
}
数据源配置完成之后,我们就正式的开始配置MyBatis的配置类,我们继续在config软件包下面创建一个文件叫做MyBatisConfig。要把一个普通的类转换成Spring的配置类,我们需要在类名上添加@Configuration注解。 然后,我们需要添加SqlSessionFactory对象,根据之前我们的经验,我们要使用跟SqlSessionFactory有关的类,那么Spring整合MyBatis包里面专门为我们准备一个用于管理SqlSessionFactory的类,叫做org.mybatis.spring.SqlSessionFactoryBean,那么根据我们之前所说的,我们现在就要定义一个方法,它的返回值就是SqlSessionFactoryBean,并且我们要在方法中对SqlSessionFactory做一些配置。 对于SqlSessionFactory的配置主要就是配置我们之前就已经配置好的数据源对象。 要在一个Bean中引入另一个Bean,我们只需要在方法的参数中声明被引入的Bean的类型的对象即可,在程序运行的时候,IoC会帮我们自动将类型相同的Bean进行自动装配 比如说我现在正在编写SqlSessionFactory类,此时我们需要引入之前写好的dataSource类,那么我们就可以在SqlSessionFactoryBean方法的形参中声明一个参数,它的类型就是dataSource,我们可以在方法中正常的去使用这个类。
配置完SqlSessionFactoryBean之后,剩下的就是配置dao层接口扫描类,这个类的作用是扫描我们包下的接口,自动的帮我们为每一个接口创建一个实现类,我们只需要声明接口而不用去创建接口的实现类以及将实现类注册进IoC的过程。
package com.spring.config;import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.mapper.MapperScannerConfigurer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.sql.DataSource;@Configuration
public class MyBatisConfig {
// 创建第三方Bean管理SqlSessionFactory@Beanpublic SqlSessionFactoryBean sessionFactoryBean(DataSource dataSource){SqlSessionFactoryBean sessionFactoryBean = new SqlSessionFactoryBean();sessionFactoryBean.setDataSource(dataSource);return sessionFactoryBean;}
// 创建第三方Bean管理接口文件映射@Beanpublic MapperScannerConfigurer mapperScannerConfigurer(){MapperScannerConfigurer mapperScannerConfigurer = new MapperScannerConfigurer();mapperScannerConfigurer.setBasePackage("com.spring.dao");return mapperScannerConfigurer;}
}
配置完之后,我们就完成了MyBatisConfig类的配置,现在这个类就相当于是我们的application-dao.xml配置文件,那么接下来,我们就要开始搬运application-service.xml文件里面的配置了 在application-service.xml中我们只做了一件事,那就是扫描Service包下面的注解,并将注解对应的类注册进IoC容器中。那么我们首先先把这个做了 在Config包下面创建一个类叫做SpringConfig配置文件,并且在类上添加@Configuration注解将他变成一个配置类。 然后就是实现扫描包的功能,实现在配置文件中扫描包,需要添加@ComponentScan注解,注解中使用字符串配置要扫描的包的全限定路径。 在将application-service.xml文件中的基础配置搬运过来之后,我们还需要做一个动作,就是将两个配置文件整合一下,现在我们还是只是两个分散的配置文件,互相之间没有联系,我们要让他们形成一个完整的系统,就要在SpringConfig中引入MyBatis的两个配置文件,分别是JdbcConfig和MyBatisConfig。 在一个配置类中引入外部的配置文件,我们需要使用到@Import注解。 这个注解的值是一个数组,里面可以存放我们的配置文件的class文件,这样我们就完成了Spring和MyBatis的整合。
package com.spring.config;import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;@Configuration
@ComponentScan("com.spring.service")
@Import({MyBatisConfig.class, JdbcConfig.class})
public class SpringConfig {
}
然后我们就开始修改SpringMVC的配置文件的内容,首先我们来看跟SpringMVC有关的内容都有什么,一个SpringMVC的容器配置文件,一个web.xml配置文件。我们首先来看SpringMVC的配置文件。在这个文件中我们做了三件事,首先是包扫描,扫描controller包下面的Bean并将他们注册到IoC容器中。以及配置了一个注解驱动。 我们首先创建一个配置类,叫做SpringMVCConfig文件,然后开始将我们刚才说到的两个步骤搬运到我们的配置类中。 首先是转换配置类的注解是@Configuration,以及包扫描的注解是@ComponentScan,那么注解驱动器怎么配置呢?在SpringMVC的注解驱动的配置需要添加@EnableWebMvc注解去完成这个注解只需要存在就可以了,不需要有任何的值传入。 这样我们之前的SpringMVC的配置文件中的内容就已经全部转移到配置类中了。
package com.spring.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.web.servlet.config.annotation.EnableWebMvc;@Configuration
@ComponentScan("com.spring.controller")
@EnableWebMvc
public class springMVCConfig {}
然后我们再来看web.xml文件,在这个文件中,我们主要就是配置了一个前端控制器,并且完成了一些初始化的操作,那么我们的Spring就提供了一个抽象类去完成这一系列的动作,既可以完成前端控制器的配置,还能完成我们两个容器,也就是Spring容器和SpringMVC子容器的容器初始化的动作。 任何继承AbstractAnnotationConfigDispatcherServletInitializer的类都会在项目启动的时候自动配置DispatchServlet、初始化SpringMVC容器和Spring容器 这是Spring官网的原话,也就是我们只需要创建一个类去继承他的AbstractAnnotationConfigDispatcherServletInitializer类,就可以完成上述的三个动作。 那么我们现在就在config包下面创建一个类叫做ServletContainersInitConfig,这个类去继承AbstractAnnotationConfigDispatcherServletInitializer。 可以看到,我们在继承这个类之后,他会提示我们需要重写三个方法,那么这三个方法就是对应我们刚才说的三个动作,我么现在开始简单介绍一个这三个方法对应的功能
- getRootConfigClasses:将Spring配置类的信息加载到Spring容器中
- getServletConfigClasses:将SpringMVC配置类的信息加载到SpringMVC容器中
- getServletMappings:可以指定DispatchServlet的拦截路径,一般就是“/”这个值,拦截所有就可以了
package com.spring.config;import org.springframework.web.servlet.support.AbstractAnnotationConfigDispatcherServletInitializer;public class ServletContainersInitConfig extendsAbstractAnnotationConfigDispatcherServletInitializer {@Overrideprotected Class<?>[] getRootConfigClasses() {return new Class[]{SpringConfig.class};}@Overrideprotected Class<?>[] getServletConfigClasses() {return new Class[]{springMVCConfig.class};}@Overrideprotected String[] getServletMappings() {return new String[]{"/"};}
}
至此我们就完成了基于注解的SSM的整合,在整个的过程中,我们要明确的认识配置类和配置文件的关系,只要搞清楚了注解和配置之间的关系,我们对于两个模式之间的转化就会非常的得心应手
相关文章:

JavaEE简单示例——基于注解的SSM整合
基于注解的SSM整合 在之前我们进行了基于XML配置文件的整合,这次我们介绍基于注解的SSM框架的整合。基于注解的含义是将我们之前所有的配置文件用java类来代替,也就是我们会在Java类中编写之前我们之前在配置文件中编写的内容。 首先我们将之前我们编写…...

EFBG-06-250双比例阀放大器
EFBG-06-250双比例阀放大器特点: 1.本阀系仅供应驱动元件所需最低的压力及流量的入口节流式节能阀。 2.本阀可使油泵及马达侧的压力随时维持大于负载压0.6-0.9MPa的压差,因而可节省能耗。 3.外置比例放大器参数可调,维修更换简单。...
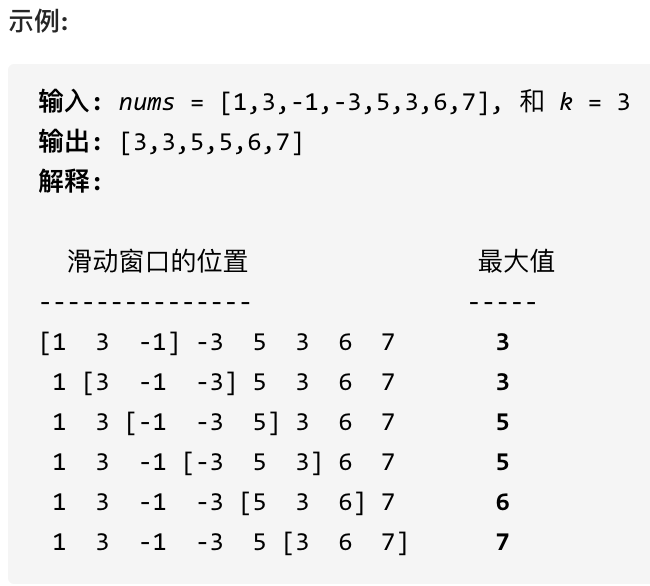
初级算法-栈与队列
主要记录算法和数据结构学习笔记,新的一年更上一层楼! 初级算法-栈与队列一、栈实现队列二、队列实现栈三、有效的括号四、删除字符串中的所有相邻重复项五、逆波兰表达式求值六、滑动窗口最大值七、前K个高频元素栈先进后出,不提供走访功能…...

菜鸟教程之Android学习笔记Service
Service初步 一、StartService启动Service的调用顺序 MainActivity.java package com.example.test2;import androidx.appcompat.app.AppCompatActivity;import android.app.Activity; import android.content.Intent; import android.os.Bundle; import android.view.View;…...

半个月狂飙1000亿,ChatGPT概念股凭什么?
ChatGPT 掀起了AI股历史上最疯狂的一轮市值狂飙。 自春节后至今,ChatGPT概念股开始了暴走模式,短短半月时间,海天瑞声、开普云等ChatGPT概念股市值累计增加了近1400亿。 如此的爆炸效应,得益于ChatGPT所展现出商业化落地的巨大潜…...

linux使用systemctl
要使用 systemd 来控制 frps,需要先安装 systemd,然后在 /etc/systemd/system 目录下创建一个 frps.service 文件 安装systemd # yum yum install systemd # apt apt install systemd创建并编辑 frps.service 文件 [Unit] DescriptionFrp Server Serv…...

交换机和VLAN简介
一.二层设备(交换机和网桥)的区别简介 1.交换机: 2.网桥: 二.交换机原理介绍 三.VLAN概念介绍 1.VLAN将一个物理区域LAN划分为多个区域 2.作用: 3.标识方式VLAN ID 4.VLAN配置下MAC地址表的三元素 5.交换中的…...

想要拯救丢失的海康威视硬盘录像数据?可采用这三种恢复方法
海康威视作为全球领先的视频监控产品及解决方案提供商,其硬盘录像机可用于对大型公共场所、企事业单位及个人住宅等场所的安全监控。然而在实际使用中,有时会发生硬盘录像数据丢失的情况,这将对用户带来不小的损失和困扰。 硬盘录像数据丢失…...
大整数乘整数)
每周一算法:高精度乘法(一)大整数乘整数
高精度乘法 乘法是我们在比赛中常用到运算之一,但在利用C++进行乘方或者阶乘计算时,由于其结果的增长速度很快,很容易就溢出了。例如: 13 ! = 6 , 227 , 020 , 800 13!=6,227,020,800 13!=6...

c++华为od面经
手撕代码: 力扣1004 最大连续1的个数 给定一个二进制数组 nums 和一个整数 k,如果可以翻转最多 k 个 0 ,则返回 数组中连续 1 的最大个数 。 输入:nums [1,1,1,0,0,0,1,1,1,1,0], K 2 输出:6 解释:[1,1,1…...
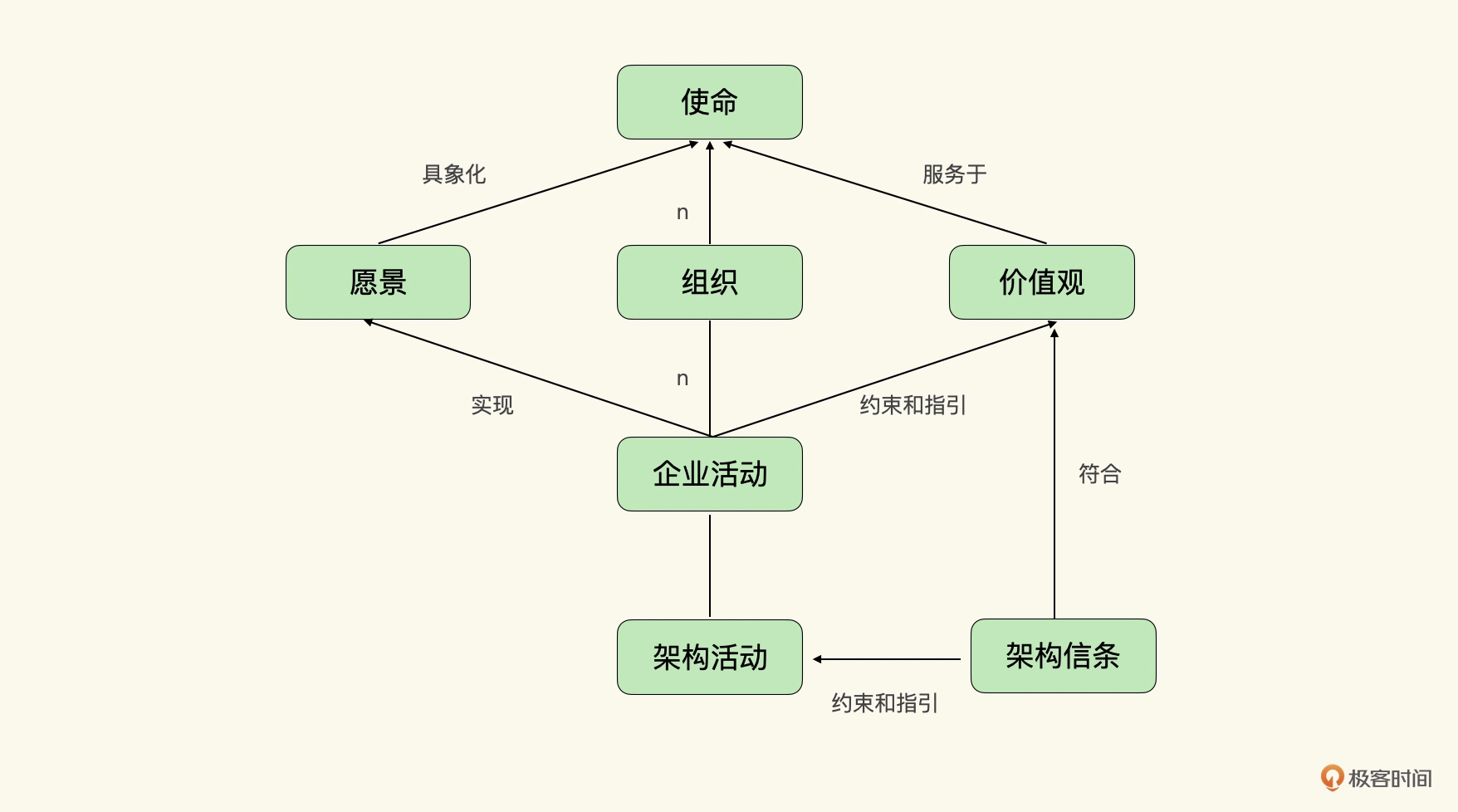
【郭东白架构课 模块二:创造价值】18|节点一:架构活动中为什么要做环境搭建?
你好,我是郭东白。在第 16、17 讲,我们讲解了架构师在架构活动中要起的作用,主要有达成共识、控制风险、保障交付和沉淀知识这四个方面。这是从架构师创造价值的维度来拆解的。 那么从这节课开始,我将从架构活动生命周期的维度上…...
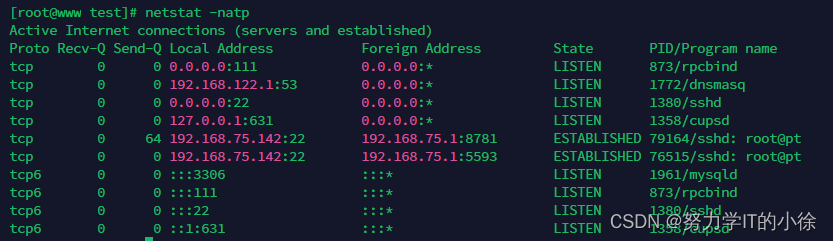
15个awk的经典实战案例
目录 一、插入几个新字段 二、格式化个空白 三、筛选IPV4地址 命令及结果 第一种查询方式 第二种查询方式 第三种查询方式 四、读取.ini配置文件中的某段 命令及结果 第一种查询方式 第二种查询方式 五、根据某字段去重 命令及结果 第一种方式 第二种方式 六、…...
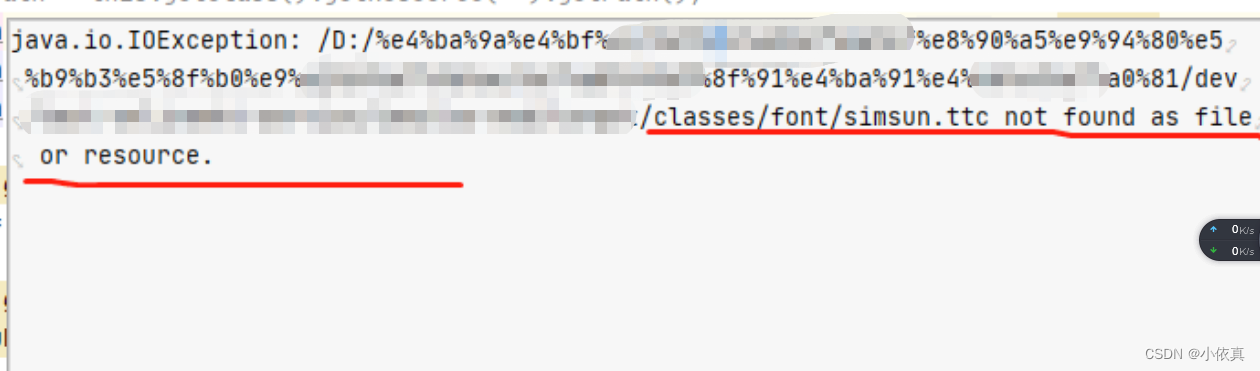
【JAVA】本地代码获取路径乱码
本地代码获取路径乱码 获取resources下资源乱码 解决方法: 获取路径后把返回值decode下就可以了. 用utf-8编码 String path this.getClass().getResource("").getPath();...
自然机器人最新发布:智能流程助手,与GPT深度融合
ChatGPT自2022年11月上线后就受到现象级地广泛关注,5天时间用户就已经突破百万,仅2个月时间月活用户就突破1亿,成为史上增速最快的消费级应用,远超TikTok、Facebook、Google等全球应用。它展现了类似人类的语言理解和对话交互能力…...

【Mybatis】4—动态SQL
⭐⭐⭐⭐⭐⭐ Github主页👉https://github.com/A-BigTree 笔记链接👉https://github.com/A-BigTree/Code_Learning ⭐⭐⭐⭐⭐⭐ 如果可以,麻烦各位看官顺手点个star~😊 如果文章对你有所帮助,可以点赞👍…...
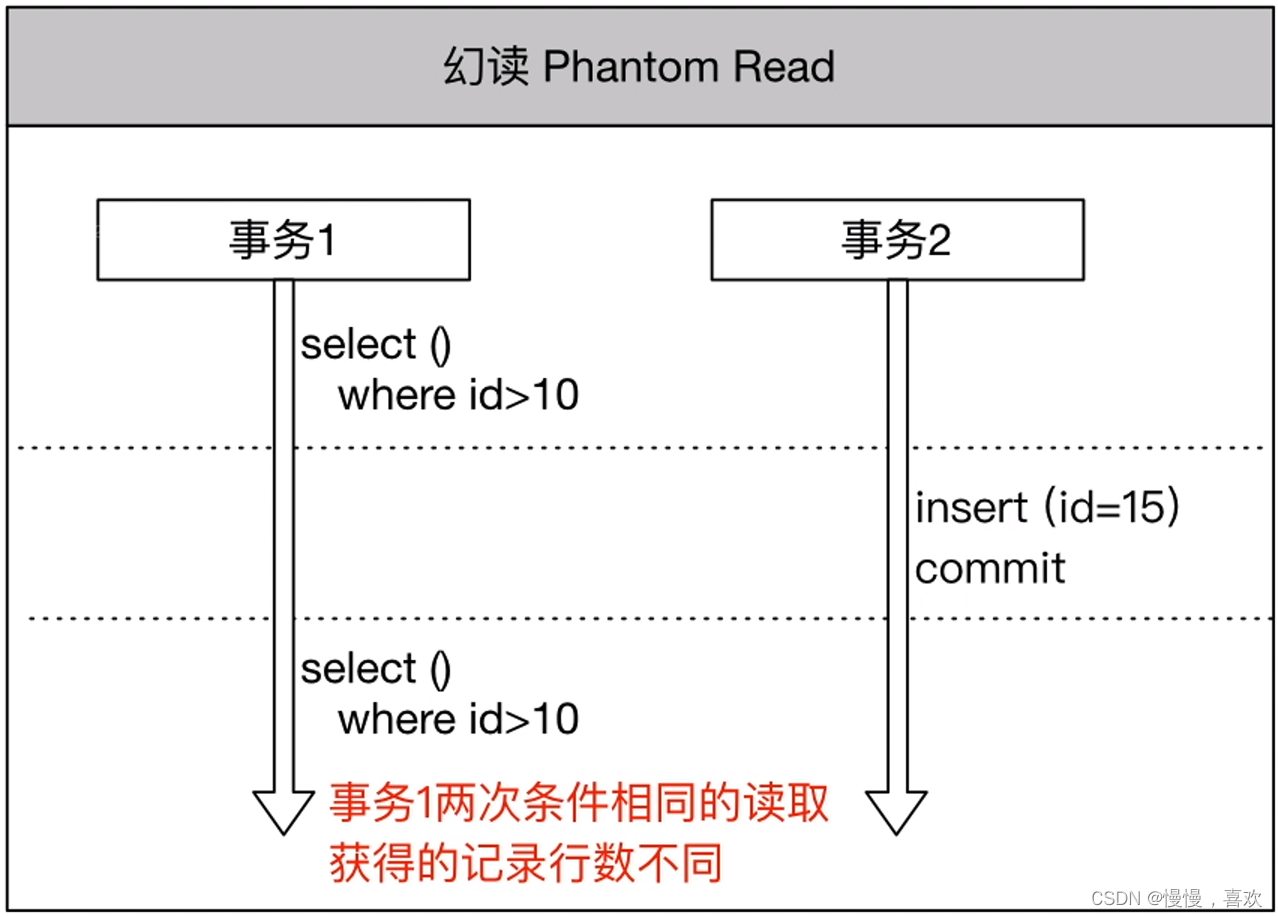
事务传播特性和隔离级别
事务的四大特性 1.原子性(Atomicity):事务不可再分,要么都执行,要么都不执行。 2.一致性(Consistency):事务执行前后,数据的完整性保持一致,即修改前后数据总…...
socket网络编程
端口 :主机上一个应用程序的代号(端口不变) 为什么不用PID来表示一个应用 因为PID会变化,而端口是不变的 套接字进程间通信——跨越主机 1、主机字节序列和网络字节序列 主机字节序列分为大端字节序和小端字节序,不同…...
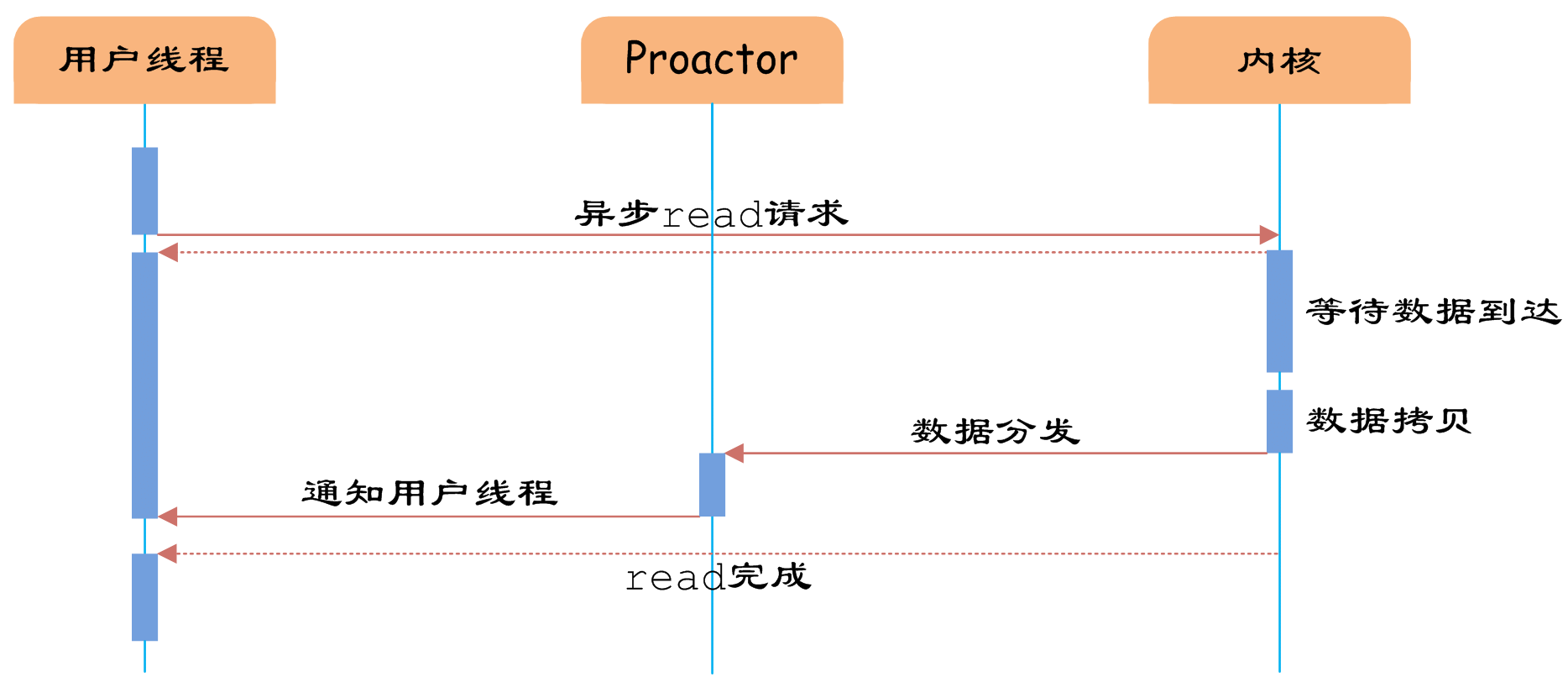
IO多路复用机制详解
高性能IO模型浅析 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型。 (2)同步非阻塞IO(Non-blo…...

选择一款好用的营销项目管理可以更好帮您解决任何问题
营销项目管理软件哪个好用?使用Zoho Projects营销项目管理软件,您可以从营销活动中获得最佳结果,并获得可执行的见解。Zoho Projects的营销项目管理软件可让您和您的团队全面了解您的所有活动。监控您的社交渠道、跟踪结果并在一处进行交流。…...
第三章知识总结(期末复习可用))
计算机网络(第八版)第三章知识总结(期末复习可用)
本笔记来源于博主上课所记笔记整理,可能不全,欢迎大家批评指正,如果觉得有用记得点个赞,给博主点个关注...该笔记将会持续更新...整理不易,希望大家多多点赞。 第一章 第三章 数据链路层 数据链路层属于计算机网络的低…...

从零到一:基于HappyBase的HBase Python应用实战指南
1. 环境准备与基础配置 第一次接触HBase和HappyBase时,环境配置往往是最让人头疼的部分。记得我刚开始搭建环境时,花了整整两天时间才把所有服务调通。为了让各位少走弯路,我把这些年积累的经验都整理在这里。 首先需要明确的是,…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

SmarterRouter:基于软件定义与模块化构建智能路由器系统
1. 项目概述:一个更聪明的路由器,它到底想做什么?如果你和我一样,折腾过家里的网络,从刷第三方固件到组软路由,那你肯定对“路由器”这三个字有复杂的感情。它本该是默默无闻的网络基石,却常常因…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

All in Token,百度李彦宏指出:Token经济,阿里,百度,腾讯,字节,移动,电信,联通,华为,开启新的Token战争
当AI作为生产力已经成为确定性命题,我们当下应该如何衡量一家AI企业的价值?是看大模型跑分刷榜的能力,还是用户每天消耗的token数量?5月13日的Create2026大会上,百度创始人李彦宏提出了一个全新标准——DAA,…...
,全程复制粘贴即可)
从0到1:手把手教你搭建VSCode(附避坑指南,拒绝报错),全程复制粘贴即可
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

前端工程化实战:基于 Kelivo 模板的配置即代码与自动化工作流
1. 项目概述与核心价值最近在整理个人开发环境时,发现一个挺有意思的项目,叫Chevey339/kelivo。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它是一个围绕特定开发工具或框架进行深度定制、优化和功能增…...

从开源AI导师项目GURU-Ai拆解:如何构建具备教学能力的智能体
1. 项目概述:一个“AI导师”的诞生与定位最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个平平无奇的AI工具仓库。但点进去细看,你会发现它的野心不小——它想做的不是又一个聊天机…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...

基于Taotoken统一API开发支持多模型切换的智能对话应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基于Taotoken统一API开发支持多模型切换的智能对话应用 应用场景类,场景是开发一个需要支持用户自由选择或系统自动切换…...