MySQL性能优化(二)索引
文章目录
- 优化手段
- 准备
- 案例
- 索引的本质
- 索引的数据结构
- 不同存储引擎中索引的实践
- MyIsam (索引没有主次之分、都存放在MYI文件)
- 主键索引
- 其他索引
- InnoDB(数据即索引、索引即数据)
- 主键索引——聚集索引
- 聚集索引
- 其他索引
- 没有主键的情况?
- 索引的创建和使用原则
- 索引越多越好么?
- 列的离散度:count(distinct(column_name)):count(*)
- 联合索引的最左匹配原则
- 冗余索引
- 覆盖索引
- 索引条件下推(ICP)
- 建立索引的原则:
- 前缀索引
- 使用索引的原则
- 什么时候用不到索引
- 优化器
优化手段
- 表的索引越全越好么?
- 为什么不要在性别子弹常见索引?
- 为什么不建议使用身份证做主键?
- 模糊匹配like xx%,like %xx% , like %xx都不用到索引么?
- 为什么不建议使用select * ?
准备
create table user_innodb
(id int not null primary key,username varchar(255) null,gender char(1) null,phone char(11) null
) ENGINE=INNODB;create table user_myisam
(id int not null primary key,username varchar(255) null,gender char(1) null,phone char(11) null
) ENGINE=myisam;create table user_memory
(id int not null primary key,username varchar(255) null,gender char(1) null,phone char(11) null
) ENGINE=memory;SET @i = 1;
INSERT INTO user_innodb (id, username,gender, phone)
SELECT @i := @i + 1 AS id,CONCAT('user', LPAD(@i, 5, '0')) AS username,IF(FLOOR(RAND() * 2) = 0, '1', '0') AS gender,CONCAT('1', LPAD(FLOOR(RAND() * 10000000000), 10, '0')) AS phone
FROM INFORMATION_SCHEMA.TABLES,INFORMATION_SCHEMA.TABLES AS t2
WHERE @i < 5000000;select max(id) from user_innodb
案例
-- 没有索引的查询时间
select * from user_innodb where username = 'huathy'
> OK
> 时间: 5.872s
-- 为username字段加上索引
alter table user_innodb add index idx_user_innodb_name(username);
-- 走索引的name查询时间开销
select * from user_innodb where username = 'huathy'
> OK
> 时间: 0.017s
索引的本质
数据库索引:数据库管理系统中一个排序的数据结构,加快查询效率。
- 索引按列分类:单列索引、联合索引
- 索引类型:normal正常、spatial、unique唯一索引(空)、主键索引(非空)、fulltext全文索引(大文本字段、对于中文需要分词效果不佳、替代ES)
- 索引方法:B+树,hash索引

索引的数据结构
-
二分查找的链表结构:二叉查找树。
左子树的节点小于父节点,右子树的节点大于父节点。二叉树存在极端情况,当所有的节点都大于父节点的时候,二叉树会退化成为链表结构。
-
平衡二叉树(AVL Three)
左右子树的深度差绝对值不能超过1。
左左形->右旋,右右形->左旋。
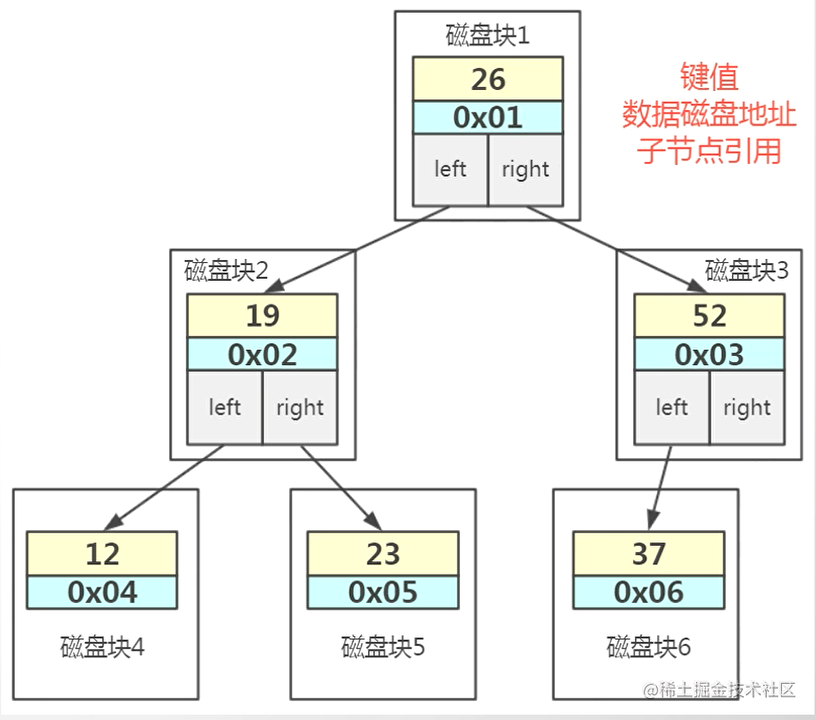
- 多路平衡搜索树(B树)
通过分裂与合并来保持平衡,这个分裂合并就是innodb页的分裂合并。
如果键是无序的,那么存储磁盘的时候可能导致碎片。所以身份证
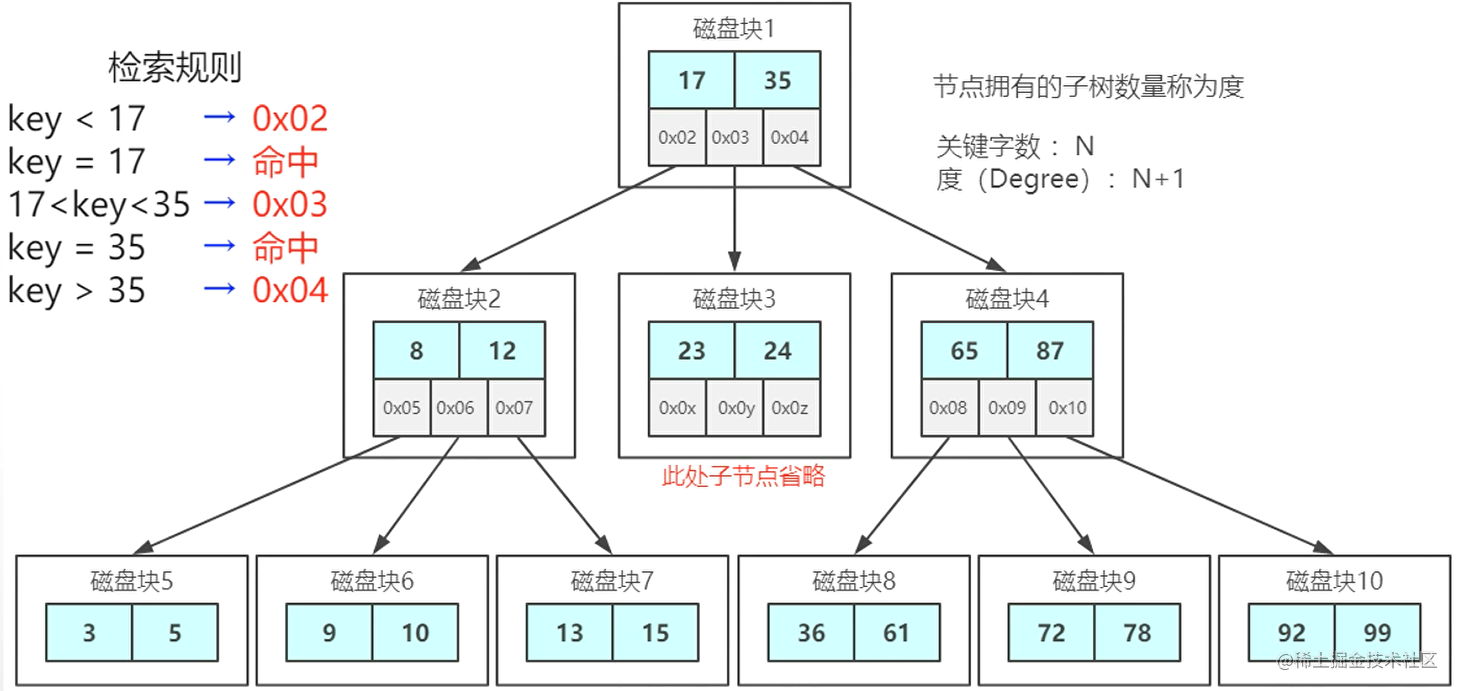
4. B+树 加强版多路平衡查找树
所有数据存放到叶子节点,叶子节点与叶子节点之间有双向指针形成链表结构。
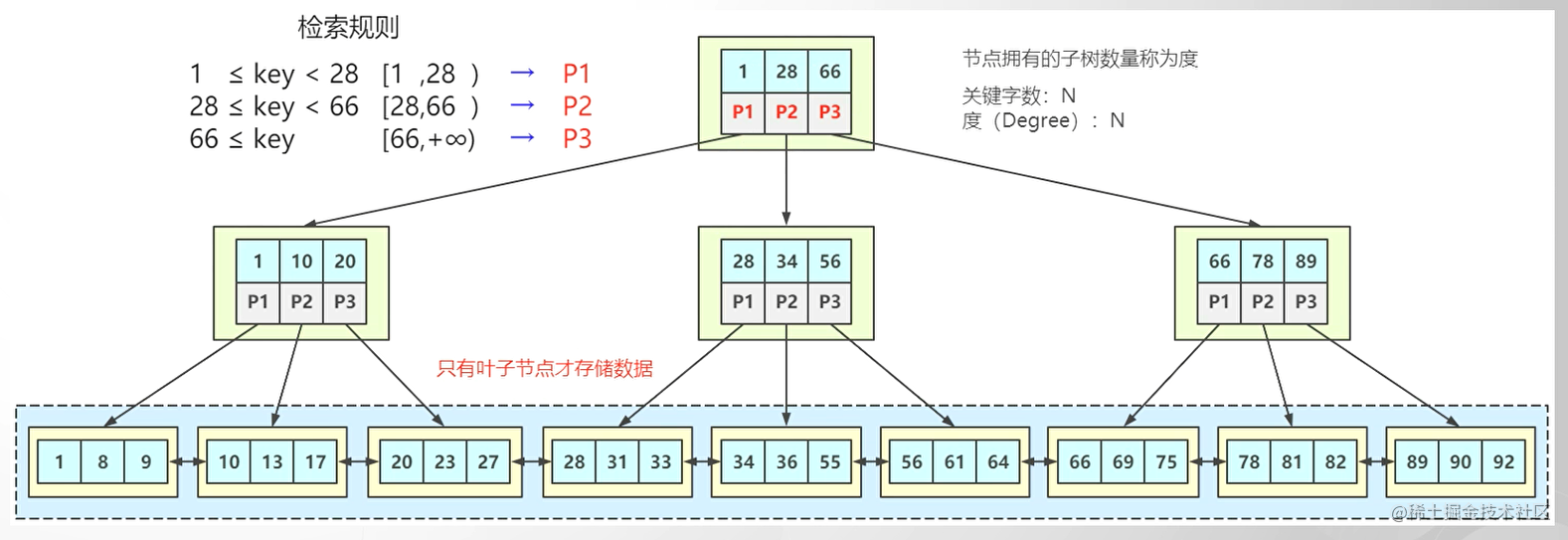
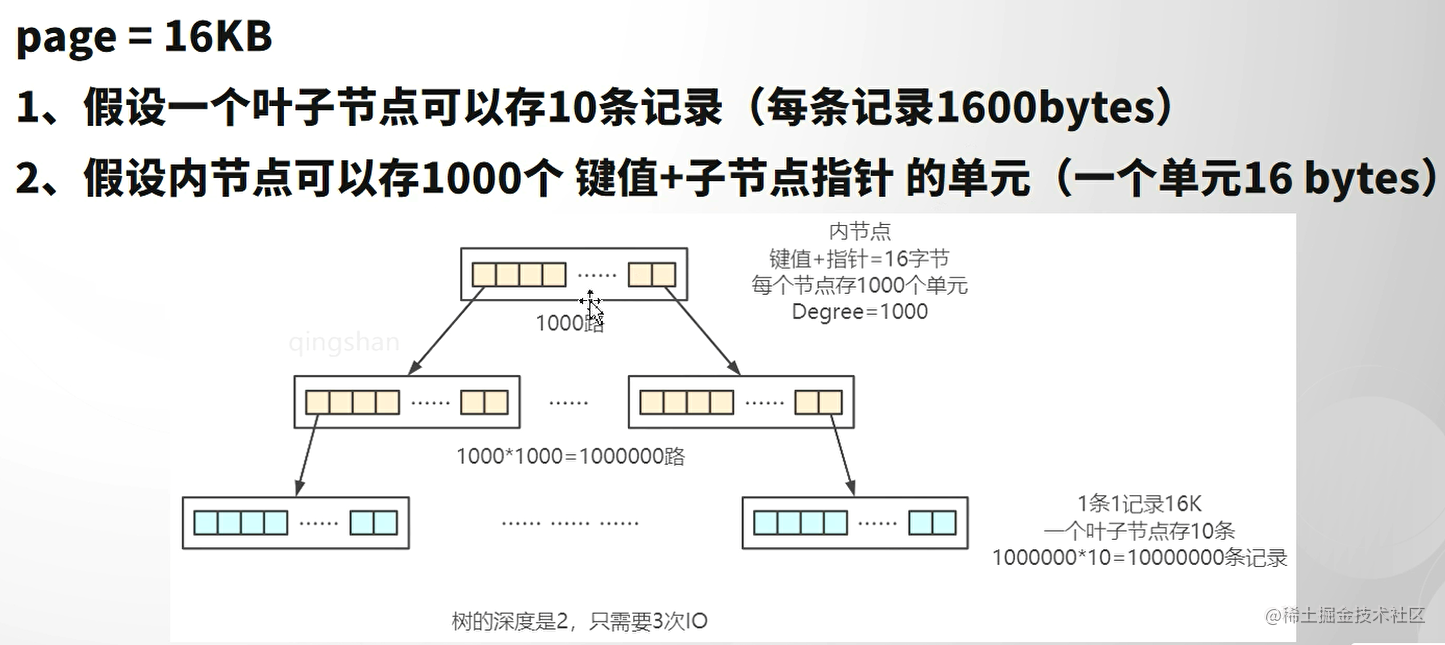
优势:
- B树解决了AVL树一个节点没有存满数据导致深度过深的问题。
- 扫库、扫表性能更强
- IO次数更少。磁盘读写能力更强
- 排序能力更强
- 效率更加稳定
为什么MySQL不用红黑树来作为索引数据结构?红黑树的目的是最大深度不超过最小深度的2倍。红黑树不够平衡。不适用于磁盘数据结构。可以防止内存。
- 节点分为红色或黑色。
- 根节点必须是黑色。
- 叶子节点都是黑色的NULL节点。
- 红色节点的两个子节点都是黑色(不允许两个相邻的红色节点)。
- 从任意节点出发,到达每个叶子节点的路径中包含相同数量的黑色节点。
5. Hash索引 时间复杂度永远是O(1)
查询快。经过hash的数据本质上是无序的。所以比较数值比较耗时。Hash碰撞不可避免。
这种索引类型是不可以在InnoDB中使用的。但是可以在其他引擎使用。比如memory引擎。
不同存储引擎中索引的实践
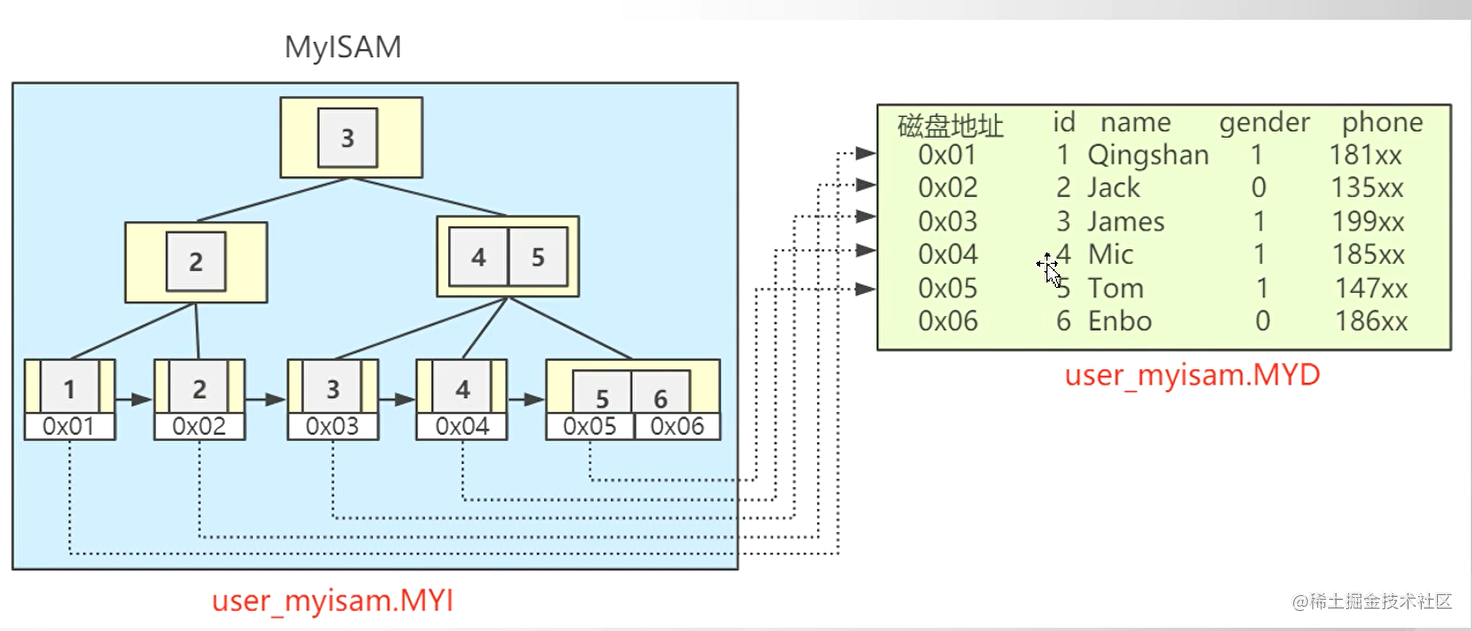
MyIsam (索引没有主次之分、都存放在MYI文件)
主键索引
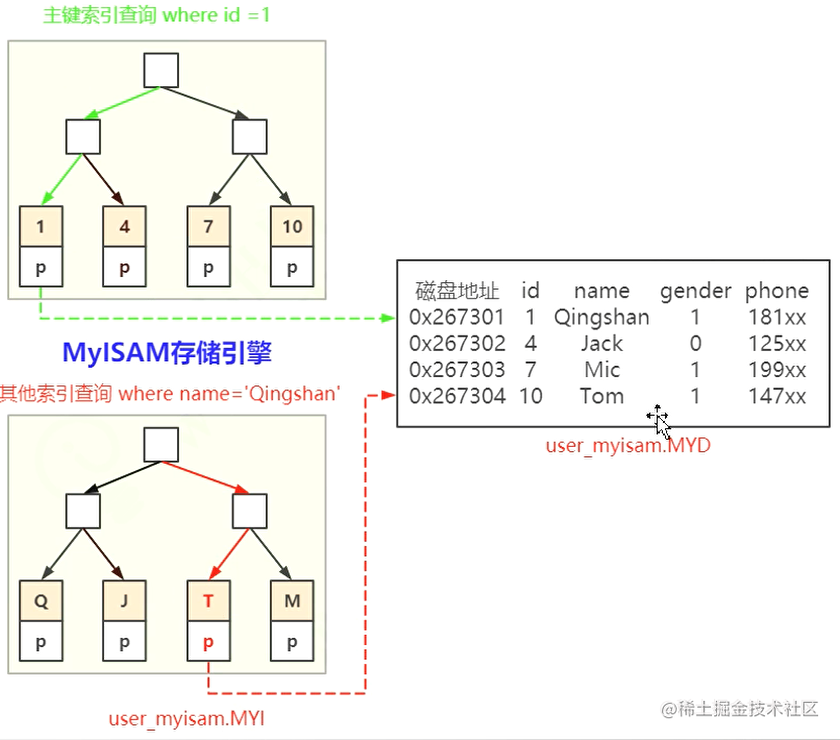
其他索引
InnoDB(数据即索引、索引即数据)
索引和数据存放在一个文件中。其B+树的叶子节点直接存放数据。
主键索引——聚集索引
叶子节点存储数据
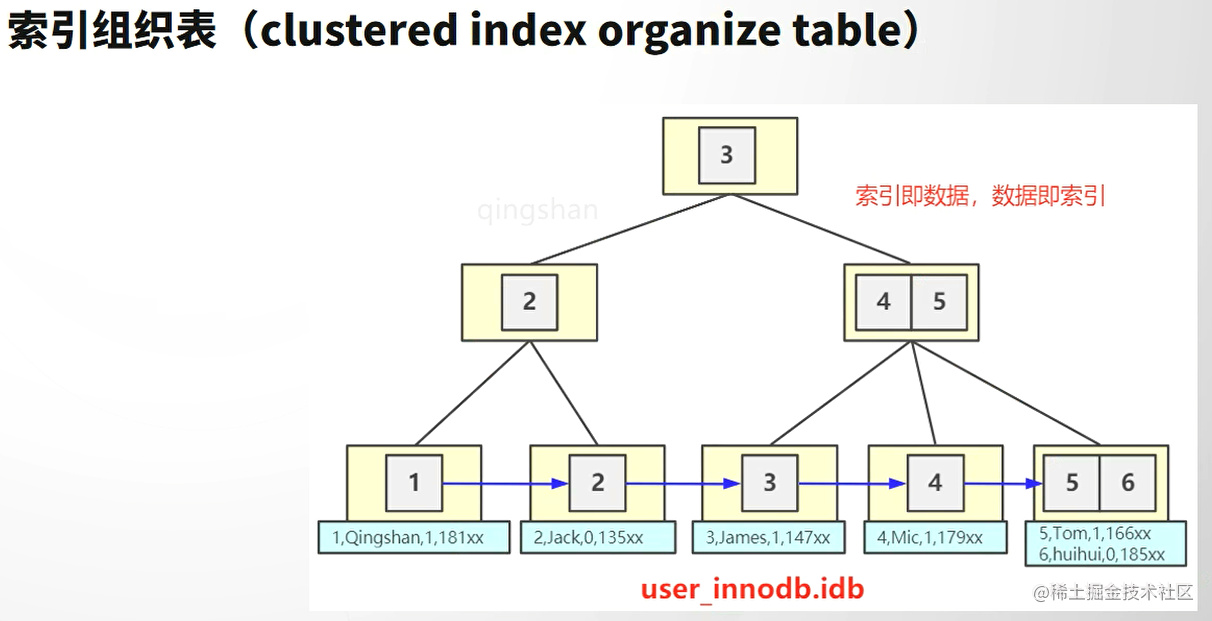
聚集索引
如果索引键值的顺序,与数据行的物理存储顺序一致,则成为聚集索引。
其他索引
叶子节点存储主键。
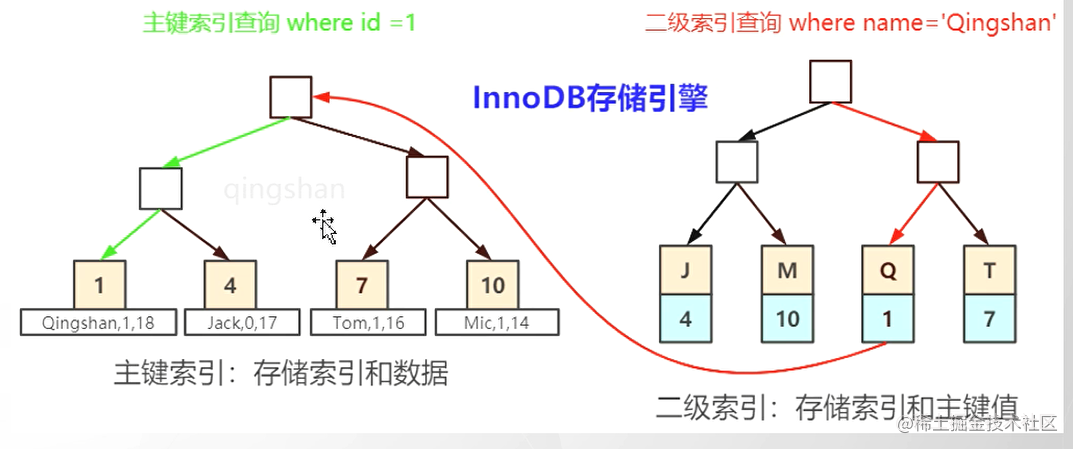
问题:为什么在二级索引上面存储的是数据的主键,而不是地址?
由于增删数据,B+树的分裂合并,地址是会改变的。
回表:查询到二级索引后,还要根据主键去表里面查询数据。图中最长的红线就是表示回表操作。
没有主键的情况?
官方回答:MySQL :: MySQL 5.7 Reference Manual :: 14.6.2.1 Clustered and Secondary Indexes
如果有主键索引,就使用主键索引。如果没有主键索引,就使用非空的唯一索引。如果没有合适的主键和唯一索引,就使用隐藏的rowID来当作索引。
// 但是我在这里查询的时候,好像提示以下错误信息:
// 1054 - Unknown column '_rowid' in 'field list'
select _rowid from test ;
这里找到了解释:https://blog.csdn.net/u011196295/article/details/88030451
当创建表时没有显示定义主键时.
- 首先判断表中是否有非空的整形唯一索引,如果有,则该列为主键(这时候可以使用 select _rowid from table 查询到主键列).
- 如果没有符合条件的则会自动创建一个6字节的主键(该主键是查不到的).
索引的创建和使用原则
索引越多越好么?
不是的。索引是会占用磁盘空间,以空间换时间。
列的离散度:count(distinct(column_name)):count(*)
gender和phone哪个离散度越高?phone离散度高。
所以不需要在离散度很低的键上面去建立索引。因为走索引会有回表操作,反而降低了性能。
联合索引的最左匹配原则
联合索引必须从第一个字段开始,不能中断。建议把查询最多的放到左侧。
alter table user_innodb add index comidx_name_phone(username,phone);EXPLAIN select * from user_innodb t where t.phone = '13603108202' and t.username='huathy'; -- 使用索引
EXPLAIN select * from user_innodb t where t.username='huathy' and t.phone = '13603108202'; -- 使用索引
EXPLAIN select * from user_innodb t where t.username='huathy'; -- 使用索引
EXPLAIN select * from user_innodb t where t.phone = '13603108202'; -- 不使用索引
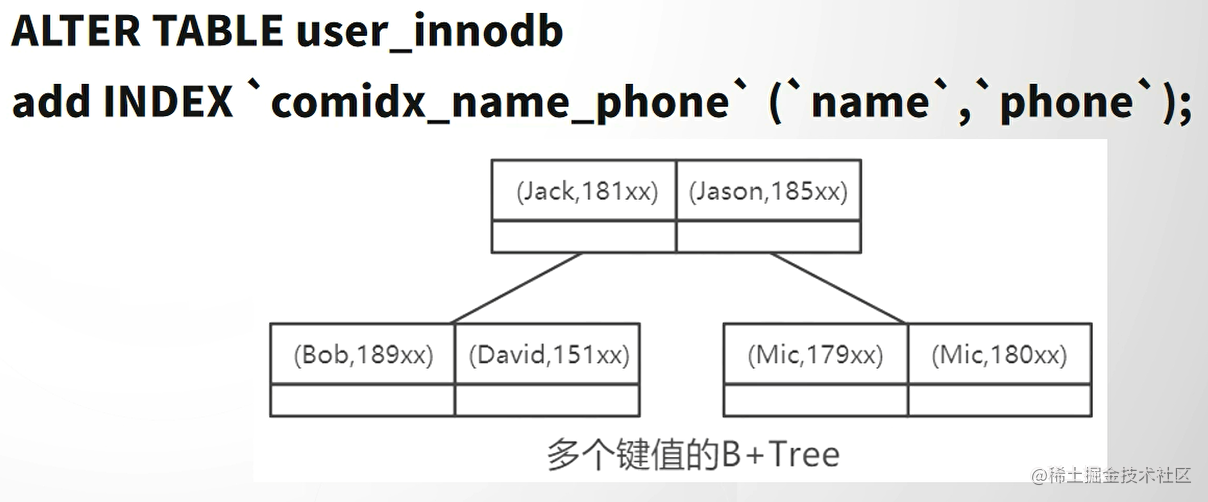
使用场景:
对于身份证号和考号这种必须要两个同时来检索的数据,可以使用联合索引。
冗余索引
有了上面的索引,我们是否有必要再为上面的查询建立一个这样的索引。不必要,索引冗余。
select * from user_innodb t where t.username='huathy';
alter table user_innodb add index idx_user_innodb_name(username);
覆盖索引
如果查询的列已经包含在了用到的索引中,那么就无需回表操作。这就称为覆盖索引。覆盖索引是使用索引的一种情况。
如何判断是否使用覆盖索引:在Extra中如果是Using Index表示使用了覆盖索引。
EXPLAIN select username,phone from user_innodb t where t.username='huathy'; -- 使用覆盖索引
EXPLAIN select username from user_innodb t where t.username='huathy' and t.phone = '13603108202'; -- 使用覆盖索引
EXPLAIN select username from user_innodb t where t.phone = '13603108202'; -- 使用覆盖索引
EXPLAIN select * from user_innodb t where t.username='huathy'; -- 不使用覆盖索引,不得不回表操作
索引条件下推(ICP)
innoDB自动开启,自动优化。
索引是在存储引擎实现的,存储引擎负责存储数据,数据的过滤、计算是在服务层实现的。如果可以根据索引查询,那么效率更高。将在本存储引擎中无法过滤的条件,先在存储引擎过滤一遍。这个动作就是索引条件下推。
如何判断是否使用了索引条件下推:在执行计划的Extra中存在Using index condition表示使用了索引条件下推。index condition全称:Index condition pushing down。
-- 创建员工表
CREATE TABLE `employees` (`emp_no` int(11) NOT NULL,`birth_date` date NULL,`first_name` varchar(14) NOT NULL,`last_name` varchar(16) NOT NULL,`gender` enum('M','F') NOT NULL,`hire_date` date NULL,PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB ;
-- 在姓、名列上加上索引
alter table employees add index idx_lastname_firstname(last_name,first_name);-- 进行查询
EXPLAIN SELECT * FROM employees t WHERE t.last_name = 'Wu' AND t.first_name like '%x'
-- 可以看到Extra中Using index condition表示用到了索引条件下推。-- 查看操作开关是否开启索引条件下推
show global variables like '%optimizer_switch%';
-- index_condition_pushdown=on
-- 关闭索引条件下推
set optimizer_switch = 'index_condition_pushdown=off'
-- 再次查看是否使用了索引条件下推
EXPLAIN SELECT * FROM employees t WHERE t.last_name = 'Wu' AND t.first_name like '%x'
-- 可以看到返回 Using Where 表示在server层过滤
以上的查询方式,查询流程如下
- 如果不进行索引下推的流程:
二级索引检索数据 --回表–> 在主键索引叶子节点拿到完整记录 --> Server层过滤数据(不符合like条件的N条记录,需要server层自己过滤) - 进行索引下推的查询流程:二级索引检索数据 --> 过滤二级索引 Wu,x --回表–> 在主键索引叶子节点获取到完整记录 --> 返回给Server层(符合like条件的N条记录,不需要server层过滤)
建立索引的原则:
- 在用于where判断、order排序、join链接、group by分组字段上创建索引。
- 索引个数不宜过多。
- 区分度底的字段(列的离散度底),不需要建索引。
- 频繁更新的值,不要作为主键或索引。
- 不建议用无序的值(身份证、UUID)作为索引。会引起B+树大量结构调整,消耗计算性能。
- 复合索引,将离散度高的列放在前面。
- 常见符合索引,而不是修改单列索引。
- 过长的字段,创建前缀索引。
前缀索引
一些文本过长,我们只需要通过前缀来匹配,可以截取字串使用前缀索引。文本过长,占用存储空间,太短则没有区分度。这里就需要计算合适的长度。
-- 前缀索引:
CREATE TABLE `pre_test` (`content` varchar(20) DEFAULT NULL,KEY `pre_idx` (`content`(6))
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
使用索引的原则
什么时候用不到索引
- 索引列上使用函数(replace、substr、concat、sum、count、avg)、表达式
- 字符串不加引号,出现隐式转换。
- like条件前面加了%。违反了最左匹配原则。当然索引条件下推的情况除外。
- 负向查询的情况无法确定:与优化器版本、数据库版本等相关
<>、!=、not in、not exists
优化器
- 基于成本的优化器(MySQL采用):IO、CPU
- 基于规则的优化器(Oracle早期版本):
相关文章:
MySQL性能优化(二)索引
文章目录优化手段准备案例索引的本质索引的数据结构不同存储引擎中索引的实践MyIsam (索引没有主次之分、都存放在MYI文件)主键索引其他索引InnoDB(数据即索引、索引即数据)主键索引——聚集索引聚集索引其他索引没有主键的情况&a…...
< 每日闲谈:你真的了解 “ ChatGPT ” 嘛 ? >
< 每日闲谈:你真的了解 “ ChatGPT ” 嘛 ? >👉 前言👉 OpenAI的创立👉 ChatGPT有何过人之处?> 效果演示👉 OpenAI看家之作 — GPT自然语言模型> GPT发展史> 里程碑-GPT3> 从…...
改善Instagram客户服务的6个技巧
Instagram仍然是全球前四大社交网络,按用户数量排名。它通过其创新的过滤器、内容创建工具、视频和卷轴选项继续增长并推动流量。这是一个平台,世界顶级名人和有影响力的人可以为全球用户提供有趣和令人印象深刻的内容。 但不仅仅是一个娱乐平台…...
8年经验之谈:4步解决测试与开发人员有争议的bug问题...
“开发认为不是bug,测试如何处理?”很多面试中,测试工程师都会被问到这个问题,不仅仅是面试,工作中测试人员也会遇到这类问题,甚至可能由于某种原因,无论是开发人员还是开发经理就是不愿修改程序…...

Linux日常小技巧shell脚本
在工作中我们常用shell脚本处理一些问题,这里整理了一些工作中常用的简单shell脚本。 定时备份文件 #!/bin/bash backup_dir="/data1/backup" src_dir="/data1/app" date_time=$(date +%Y%m%d_%H%M%S) tar -czvf ${backup_dir}/${date_time}.tar.gz ${sr…...

技术创业者必读:从验证想法到技术产品商业化的全方位解析
导语 | 技术创业之路往往充满着挑战和不确定性,对于初入创业领域的人来说,如何验证自己的创业想法是否有空间、如何选择靠谱的投资人、如何将技术产品商业化等问题都需要认真思考和解决。在「TVP 技术夜未眠」第六期直播中,正马软件 CTO、腾讯…...
Docker Registry 本地镜像发布到私有库
本地镜像发布到私有库流程 是什么1 官方Docker Hub地址:https://hub.docker.com/,中国大陆访问太慢了且准备被阿里云取代的趋势,不太主流。2 Dockerhub、阿里云这样的公共镜像仓库可能不太方便,涉及机密的公司不可能提供镜像给公…...

Pytorch构建ResNet-50V2
🍨 本文为🔗365天深度学习训练营 中的学习记录博客 🍦 参考文章地址: 365天深度学习训练营-第J2周:ResNet-50V2算法实战与解析 🍖 作者:K同学啊 一、ResNetV2与ResNet结构对比 改进点 (a)origi…...

【01】PointNet论文解析
PointNet的应用 1.点云图像的分类(整片点云是什么物体) 2.点云图像的部件分割(整片点云所代表的物体能拆分的结构) 3.点云图像的语义分割(将三维点云环境中不同的物体用不同的颜色区分开) 补充 PointN…...
nuxt.js 在IE浏览器||其他浏览不识别document/window 情况处理
1 第一步注册到nuxt.config.js文件 2 第二步建立js 文件 import Vue from vue (function(){ if(process.client){ console.log(process.client) }else{ console.log(process.client) } if (!!window.ActiveXObject || "ActiveXObject" i…...

JavaEE简单示例——基于注解的SSM整合
基于注解的SSM整合 在之前我们进行了基于XML配置文件的整合,这次我们介绍基于注解的SSM框架的整合。基于注解的含义是将我们之前所有的配置文件用java类来代替,也就是我们会在Java类中编写之前我们之前在配置文件中编写的内容。 首先我们将之前我们编写…...

EFBG-06-250双比例阀放大器
EFBG-06-250双比例阀放大器特点: 1.本阀系仅供应驱动元件所需最低的压力及流量的入口节流式节能阀。 2.本阀可使油泵及马达侧的压力随时维持大于负载压0.6-0.9MPa的压差,因而可节省能耗。 3.外置比例放大器参数可调,维修更换简单。...
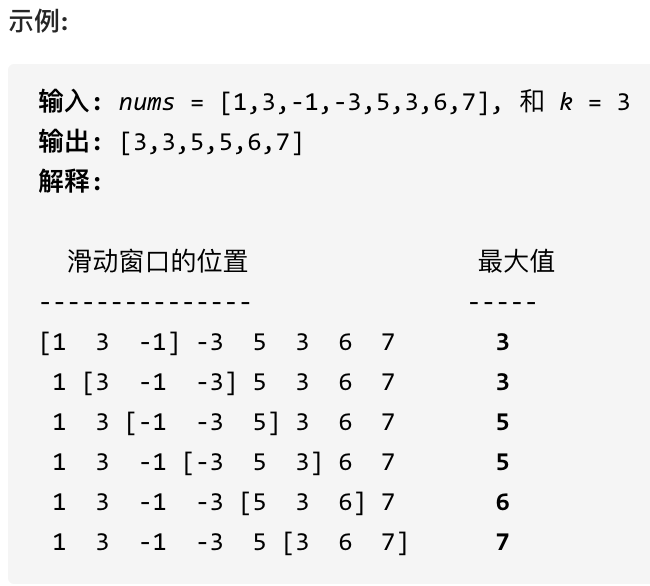
初级算法-栈与队列
主要记录算法和数据结构学习笔记,新的一年更上一层楼! 初级算法-栈与队列一、栈实现队列二、队列实现栈三、有效的括号四、删除字符串中的所有相邻重复项五、逆波兰表达式求值六、滑动窗口最大值七、前K个高频元素栈先进后出,不提供走访功能…...

菜鸟教程之Android学习笔记Service
Service初步 一、StartService启动Service的调用顺序 MainActivity.java package com.example.test2;import androidx.appcompat.app.AppCompatActivity;import android.app.Activity; import android.content.Intent; import android.os.Bundle; import android.view.View;…...

半个月狂飙1000亿,ChatGPT概念股凭什么?
ChatGPT 掀起了AI股历史上最疯狂的一轮市值狂飙。 自春节后至今,ChatGPT概念股开始了暴走模式,短短半月时间,海天瑞声、开普云等ChatGPT概念股市值累计增加了近1400亿。 如此的爆炸效应,得益于ChatGPT所展现出商业化落地的巨大潜…...

linux使用systemctl
要使用 systemd 来控制 frps,需要先安装 systemd,然后在 /etc/systemd/system 目录下创建一个 frps.service 文件 安装systemd # yum yum install systemd # apt apt install systemd创建并编辑 frps.service 文件 [Unit] DescriptionFrp Server Serv…...

交换机和VLAN简介
一.二层设备(交换机和网桥)的区别简介 1.交换机: 2.网桥: 二.交换机原理介绍 三.VLAN概念介绍 1.VLAN将一个物理区域LAN划分为多个区域 2.作用: 3.标识方式VLAN ID 4.VLAN配置下MAC地址表的三元素 5.交换中的…...

想要拯救丢失的海康威视硬盘录像数据?可采用这三种恢复方法
海康威视作为全球领先的视频监控产品及解决方案提供商,其硬盘录像机可用于对大型公共场所、企事业单位及个人住宅等场所的安全监控。然而在实际使用中,有时会发生硬盘录像数据丢失的情况,这将对用户带来不小的损失和困扰。 硬盘录像数据丢失…...
大整数乘整数)
每周一算法:高精度乘法(一)大整数乘整数
高精度乘法 乘法是我们在比赛中常用到运算之一,但在利用C++进行乘方或者阶乘计算时,由于其结果的增长速度很快,很容易就溢出了。例如: 13 ! = 6 , 227 , 020 , 800 13!=6,227,020,800 13!=6...

c++华为od面经
手撕代码: 力扣1004 最大连续1的个数 给定一个二进制数组 nums 和一个整数 k,如果可以翻转最多 k 个 0 ,则返回 数组中连续 1 的最大个数 。 输入:nums [1,1,1,0,0,0,1,1,1,1,0], K 2 输出:6 解释:[1,1,1…...

ESP32-S2物联网实战:IPv6配置与Adafruit IO双向通信
1. 项目概述与核心价值如果你手头有一块ESP32-S2开发板,并且已经厌倦了仅仅让它连上Wi-Fi、点个灯,想让它真正“活”起来,成为一个能融入现代互联网、能与云端自由对话的智能节点,那么这篇文章就是为你准备的。我们将深入两个在物…...

终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案
终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

3步轻松掌握:163MusicLyrics歌词下载完全指南
3步轻松掌握:163MusicLyrics歌词下载完全指南 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到高质量的LRC歌词而烦恼吗?163MusicLyri…...

基于大语言模型的本地语义搜索工具LLocalSearch部署与应用指南
1. 项目概述:一个能“读懂”你电脑的本地搜索工具 如果你和我一样,电脑里塞满了各种文档、邮件、聊天记录和代码片段,那么“找东西”这件事,绝对能排进日常最耗时的任务前三。传统的文件搜索,比如Windows自带的搜索或者…...

10分钟掌握Autovisor:智慧树网课自动化学习的完整解决方案
10分钟掌握Autovisor:智慧树网课自动化学习的完整解决方案 【免费下载链接】Autovisor 2025智慧树刷课脚本 基于Python Playwright的自动化程序 [有免安装版] 项目地址: https://gitcode.com/gh_mirrors/au/Autovisor 还在为繁重的智慧树网课任务而烦恼吗&am…...

Steam Achievement Manager完整指南:快速解决游戏成就难题的终极工具
Steam Achievement Manager完整指南:快速解决游戏成就难题的终极工具 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 核心关键词:S…...

构建轻量级LLM工具集:模块化设计、多模型集成与本地化部署实践
1. 项目概述:一个面向日常的轻量级LLM工具集最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“Daily-LLM”。光看名字,你可能会觉得这又是一个庞大的、需要海量算力才能跑起来的“大模型”项目。但点进去仔细研究后,我…...

Go语言缓存雪崩:防止缓存失效
Go语言缓存雪崩:防止缓存失效 1. 雪崩防护 type CacheWithProtection struct {cache *RedisCachemu sync.Mutexlocks map[string]*sync.Mutex }func NewCacheWithProtection(cache *RedisCache) *CacheWithProtection {return &CacheWithProtect…...

LLM应用快速演示框架:从架构解析到智能体开发的实战指南
1. 项目概述:一个面向开发者的LLM应用快速演示框架最近在GitHub上闲逛,发现了一个名为wronai/llm-demo的项目,点进去一看,瞬间觉得眼前一亮。这可不是又一个简单的“Hello World”式的大语言模型调用示例,而是一个结构…...
:启动时快稍后慢,断断续续哥还在)
车载以太网之要火系列 - 第46篇:郭大侠学SOME/IP (offer Service):启动时快稍后慢,断断续续哥还在
写在开篇蓉儿继续挖坑上回说到,郭靖搞清楚了Offer Service的基本原理——服务端广播“我会啥,我在这”,TTL告诉客户端有效期。郭靖合上笔记本,突然皱起眉头:“蓉儿,我有个问题——如果每个ECU都每隔1.5秒发…...