Hudi-集成Spark之spark-shell 方式
Hudi集成Spark之spark-shell 方式
启动 spark-shell
(1)启动命令
#针对Spark 3.2
spark-shell \--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
(2)设置表名,基本路径和数据生成器(不需要单独的建表。如果表不存在,第一批写表将创建该表):
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
插入数据
新增数据,生成一些数据,将其加载到DataFrame中,然后将DataFrame写入Hudi表。
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").options(getQuickstartWriteConfigs).option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).mode(Overwrite).save(basePath)
Mode(overwrite)将覆盖重新创建表(如果已存在)。可以检查/tmp/hudi_trps_cow 路径下是否有数据生成。
数据文件的命名规则,源码如下:

查询数据
查询
(1)转换成DF
val tripsSnapshotDF = spark.read.format("hudi").load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
注意:该表有三级分区(区域/国家/城市),在0.9.0版本以前的hudi,在load中的路径需要按照分区目录拼接"*",如:load(basePath + “////”),当前版本不需要。
(2)查询
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()

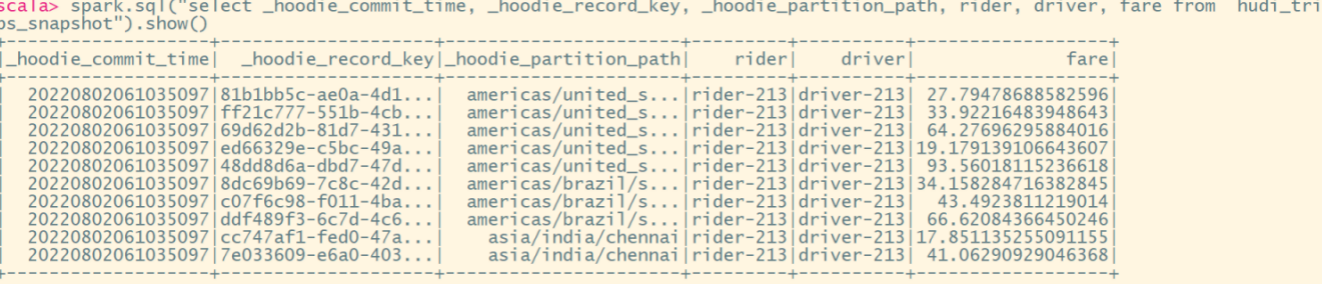
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
时间旅行查询
Hudi从0.9.0开始就支持时间旅行查询。目前支持三种查询时间格式,如下所示。
spark.read.format("hudi").option("as.of.instant", "20210728141108100").load(basePath)spark.read.format("hudi").option("as.of.instant", "2021-07-28 14:11:08.200").load(basePath)// 表示 "as.of.instant = 2021-07-28 00:00:00"
spark.read.format("hudi").option("as.of.instant", "2021-07-28").load(basePath)
增量查询
Hudi还提供了增量查询的方式,可以获取从给定提交时间戳以来更改的数据流。需要指定增量查询的beginTime,选择性指定endTime。如果我们希望在给定提交之后进行所有更改,则不需要指定endTime(这是常见的情况)。
(1)重新加载数据
spark.read.format("hudi").load(basePath).createOrReplaceTempView("hudi_trips_snapshot")
(2)获取指定beginTime
val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
val beginTime = commits(commits.length - 2)
(3)创建增量查询的表
val tripsIncrementalDF = spark.read.format("hudi").option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
(4)查询增量表
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()
这将过滤出beginTime之后提交且fare>20的数据。
利用增量查询,我们能在批处理数据上创建streaming pipelines。
指定时间点查询
查询特定时间点的数据,可以将endTime指向特定时间,beginTime指向000(表示最早提交时间)
(1)指定beginTime和endTime
val beginTime = "000"
val endTime = commits(commits.length - 2)
(2)根据指定时间创建表
val tripsPointInTimeDF = spark.read.format("hudi").option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).option(END_INSTANTTIME_OPT_KEY, endTime).load(basePath)
tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")
(3)查询
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").show()
更新数据
类似于插入新数据,使用数据生成器生成新数据对历史数据进行更新。将数据加载到DataFrame中并将DataFrame写入Hudi表中。
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi").options(getQuickstartWriteConfigs).option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).mode(Append).save(basePath)
注意:保存模式现在是Append。通常,除非是第一次创建表,否则请始终使用追加模式。现在再次查询数据将显示更新的行程数据。每个写操作都会生成一个用时间戳表示的新提交。查找以前提交中相同的_hoodie_record_keys在该表的_hoodie_commit_time、rider、driver字段中的变化。
查询更新后的数据,要重新加载该hudi表:
val tripsSnapshotDF = spark.read.format("hudi").load(basePath)
tripsSnapshotDF1.createOrReplaceTempView("hudi_trips_snapshot")spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()
删除数据
根据传入的HoodieKeys来删除(uuid + partitionpath),只有append模式,才支持删除功能。
(1)获取总行数
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
(2)取其中2条用来删除
val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2)
(3)将待删除的2条数据构建DF
val deletes = dataGen.generateDeletes(ds.collectAsList())
val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2))
(4)执行删除
df.write.format("hudi").options(getQuickstartWriteConfigs).option(OPERATION_OPT_KEY,"delete").option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).mode(Append).save(basePath)
(5)统计删除数据后的行数,验证删除是否成功
val roAfterDeleteViewDF = spark.read.format("hudi").load(basePath)roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot")// 返回的总行数应该比原来少2行
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
覆盖数据
对于表或分区来说,如果大部分记录在每个周期都发生变化,那么做upsert或merge的效率就很低。我们希望类似hive的 "insert overwrite "操作,以忽略现有数据,只用提供的新数据创建一个提交。
也可以用于某些操作任务,如修复指定的问题分区。我们可以用源文件中的记录对该分区进行’插入覆盖’。对于某些数据源来说,这比还原和重放要快得多。
Insert overwrite操作可能比批量ETL作业的upsert更快,批量ETL作业是每一批次都要重新计算整个目标分区(包括索引、预组合和其他重分区步骤)。
(1)查看当前表的key
spark.read.format("hudi").load(basePath).select("uuid","partitionpath").sort("partitionpath","uuid").show(100, false)
(2)生成一些新的行程数据
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2)).filter("partitionpath = 'americas/united_states/san_francisco'")
(3)覆盖指定分区
df.write.format("hudi").options(getQuickstartWriteConfigs).option(OPERATION.key(),"insert_overwrite").option(PRECOMBINE_FIELD.key(), "ts").option(RECORDKEY_FIELD.key(), "uuid").option(PARTITIONPATH_FIELD.key(), "partitionpath").option(TBL_NAME.key(), tableName).mode(Append).save(basePath)
(4)查询覆盖后的key,发生了变化
spark.read.format("hudi").load(basePath).select("uuid","partitionpath").sort("partitionpath","uuid").show(100, false)
相关文章:
Hudi-集成Spark之spark-shell 方式
Hudi集成Spark之spark-shell 方式 启动 spark-shell (1)启动命令 #针对Spark 3.2 spark-shell \--conf spark.serializerorg.apache.spark.serializer.KryoSerializer \--conf spark.sql.catalog.spark_catalogorg.apache.spark.sql.hudi.catalog.Hoo…...

Python爬虫:从js逆向了解西瓜视频的下载链接的生成
前言 最近花费了几天时间,想获取西瓜视频这个平台上某个视频的下载链接,运用js逆向进行获取。其实,如果小编一开始就注意到这一点(就是在做js逆向时,打了断点之后,然后执行相关代码,查看相关变量的值,结果一下子就蹦出很多视频相关的数据,查看了网站下的相关api链接,也…...

Numpy-如何对数组进行切割
前言 本文是该专栏的第24篇,后面会持续分享python的数据分析知识,记得关注。 继上篇文章,详细介绍了使用numpy对数组进行叠加。本文再详细来介绍,使用numpy如何对数组进行切割。说句题外话,前面有重点介绍numpy的各个知识点。 感兴趣的同学,可查看笔者之前写的详细内容…...
Python之字符串精讲(下)
前言 今天继续讲解字符串下半部分,内容包括字符串的检索、大小写转换、去除字符串中空格和特殊字符。 一、检索字符串 在Python中,字符串对象提供了很多用于字符串查找的方法,主要给大家介绍以下几种方法。 1. count() 方法 count() 方法…...

Python图像卡通化animegan2-pytorch实例演示
先看下效果图: 左边是原图,右边是处理后的图片,使用的 face_paint_512_v2 模型。 项目获取: animegan2-pytorch 下载解压后 cmd 可进入项目地址的命令界面。 其中 img 是我自己建的,用于存放图片。 需要 torch 版本 …...
谢希仁版《计算机网络》期末总复习【完结】
文章目录说明第一章 计算机网络概述计算机网络和互联网网络边缘网络核心分组交换网的性能网络体系结构控制平面和数据平面第二章 IP地址分类编址子网划分无分类编址特殊用途的IP地址IP地址规划和分配第三章 应用层应用层协议原理万维网【URL / HTML / HTTP】域名系统DNS动态主机…...

问:React的useState和setState到底是同步还是异步呢?
先来思考一个老生常谈的问题,setState是同步还是异步? 再深入思考一下,useState是同步还是异步呢? 我们来写几个 demo 试验一下。 先看 useState 同步和异步情况下,连续执行两个 useState 示例 function Component() {const…...
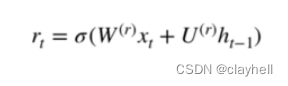
深度理解机器学习16-门控循环单元
评估简单循环神经网络的缺点。 描述门控循环单元(Gated Recurrent Unit,GRU)的架构。 使用GRU进行情绪分析。 将GRU应用于文本生成。 基本RNN通常由输入层、输出层和几个互连的隐藏层组成。最简单的RNN有一个缺点,那就是它们不…...

Python中Generators教程
要想创建一个iterator,必须实现一个有__iter__()和__next__()方法的类,类要能够跟踪内部状态并且在没有元素返回的时候引发StopIteration异常. 这个过程很繁琐而且违反直觉.Generator能够解决这个问题. python generator是一个简单的创建iterator的途径…...

数据结构与算法基础-学习-10-线性表之栈的清理、销毁、压栈、弹栈
一、函数实现1、ClearSqStack(1)用途清理栈的空间。只需要栈顶指针和栈底指针相等,就说明栈已经清空,后续新入栈的数据可以直接覆盖,不用实际清理数据,提升了清理效率。(2)源码Statu…...

Leetcode 每日一题 1234. 替换子串得到平衡字符串
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

【MYSQL中级篇】数据库数据查询学习
🍁博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 相关文章 文章名文章地址【MYSQL初级篇】入门…...
)
华为OD机试真题JAVA实现【火星文计算】真题+解题思路+代码(20222023)
🔥系列专栏 华为OD机试(JAVA)真题目录汇总华为OD机试(Python)真题目录汇总华为OD机试(C++)真题目录汇总华为OD机试(JavaScript)真题目录汇总文章目录 🔥系列专栏题目输入输出描述示例一输入输出说明解题思路核心知识点Code运行结果版...

Linux基础知识
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...
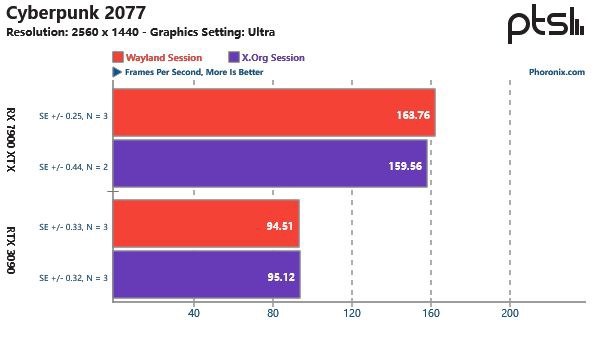
Linux 游戏性能谁的 更优秀X.Org还是Wayland!
导读X.Org 和 Wayland 是目前 Linux 平台上的两大主流显示服务器,那么两者在 Linux 游戏性能上谁更优秀呢?国外科技媒体 Phoronix 在 Ubuntu 22.10 上对其进行了多款游戏的实测。评测在运行 GNOME 43.1 的 Ubuntu 22.10 上进行测试,在安装英伟…...

【数据结构】算法的复杂度分析:让你拥有未卜先知的能力
👑专栏内容:数据结构⛪个人主页:子夜的星的主页💕座右铭:日拱一卒,功不唐捐 文章目录一、前言二、时间复杂度1、定义2、大O的渐进表示法3、常见的时间复杂度三、空间复杂度1、定义2、常见的空间复杂度一、前…...
Linux根文件系统移植
目录 一、根文件系统 1.1根文件系统 1.2根文件系统内容 二、根文件系统移植 2.1BusyBox 2.2BusyBox的获取 2.3BusyBox的使用 2.4make menuconfig 2.5编译和安装 2.6修改根文件系统 一、根文件系统 1.1根文件系统 根文件系统是内核启动后挂载的第一个文件系统系统引…...
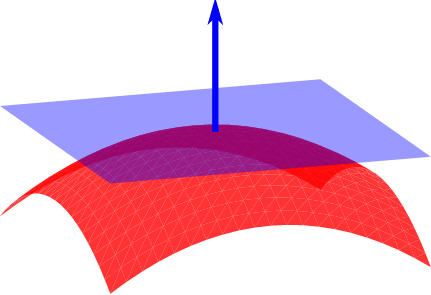
Three.js 无限平面快速教程【Plane】
Three.js 提供了 Plane 概念来表示在 3d 空间中无限延伸的二维表面。 这对于光标交互很有用,因此你可能需要了解如何设置此平面、将其可视化并根据需要进行调整。 推荐:使用 NSDT场景设计器 快速搭建 3D场景。 Three.js 的 Plane 文档很好而且准确&…...
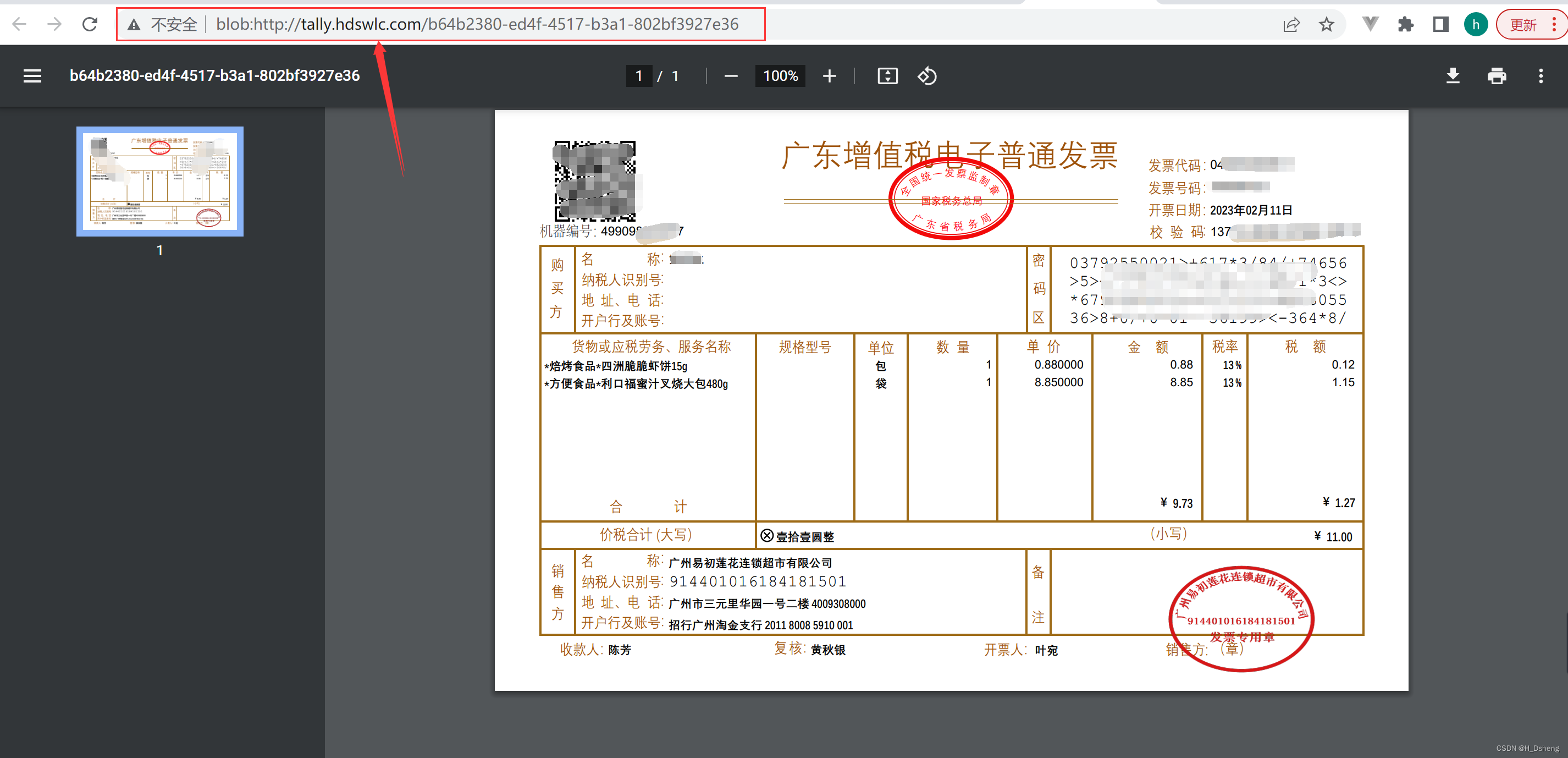
在线预览PDF文件、图片,并且预览地址不显示文件或图片的真实路径。
实现在线预览PDF文件、图片,并且预览地址不显示文件或图片的真实路径。1、vue使用blob流在线预览PDF、图片(包括jpg、png等格式)。1、按钮的方法:2、方法详细:(此方法可以在发起请求时携带token,…...
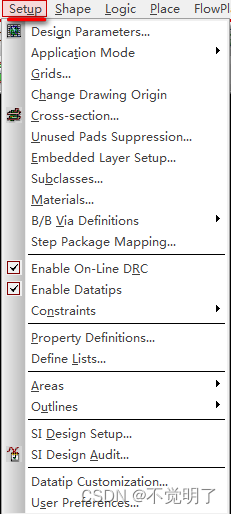
Allegro如何设置导入Subdrawing可自由选择目录操作指导
Allegro如何设置导入Subdrawing可自由选择目录操作指导 用Allgro做PCB设计的时候,导入Subdrawing是非常常用的功能,在导入Subdrawing的时候,通常需要把Subdrawing文件放在需要导入PCB的相同目录下,不能自由选择,如下图 但是Allegro是支持自由选择目录的,只需按照下方的步…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

具身智能:面向新兴交叉学科建设的思考与建议 2026
这份由 CCF YOCSEF 长三角五地学术委员会 2026 年 5 月发布的白皮书,聚焦具身智能作为新兴交叉学科的建设,明确其并非 AI 与机器人学的简单拼接,而是围绕物理交互中的智能行为形成的新问题域,提出 “三大基本问题 一个应用需求”…...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...
)
Midjourney辉光效果失效诊断手册(含12个隐性触发条件与4类GPU显存陷阱)
更多请点击: https://codechina.net 第一章:Midjourney辉光效果失效诊断手册(含12个隐性触发条件与4类GPU显存陷阱) 辉光效果(Glow Effect)在 Midjourney v6 的 --style raw 模式下常被用于强化主体边缘光…...

FModel完整部署指南:UE5资源提取与逆向解析实战
1. 为什么FModel不是“另一个UE资源查看器”,而是虚幻项目逆向分析的起点FModel虚幻引擎资源提取工具完整部署指南——这标题里藏着三个被多数人忽略的关键信号:“FModel”不是泛指,“虚幻引擎”特指UE4/UE5原生资产体系,“完整部…...

Unity Spine换装系统:骨骼映射与Skin动态管理实战
1. 为什么Spine换装不能只靠“替换贴图”——一个被低估的骨骼绑定难题 在Unity里做Spine换装,很多人第一反应是:把新衣服的Atlas和SkeletonData拖进去,用 SkeletonRenderer 的 skeletonDataAsset 字段一换,完事。我去年接手一…...
)
一文讲透|高效论文写作全流程AI论文工具推荐(2026 最新)
论文写作全流程可拆解为文献调研→选题/开题→大纲/初稿→文献综述→降重/去AI味→润色/格式→查重/投稿七大环节,以下工具按环节精准匹配,兼顾中文适配、降重能力、去AI痕迹、学术合规四大核心需求,覆盖免费/付费、通用/垂直场景。2026年&am…...

从‘调参苦手’到‘一击即中’:实战解读glmnet中lambda.min与lambda.1se到底怎么选
从‘调参苦手’到‘一击即中’:实战解读glmnet中lambda.min与lambda.1se到底怎么选 在机器学习的世界里,LASSO回归就像一位精明的裁缝,能够为数据量身定制最合身的模型。而glmnet包中的lambda.min和lambda.1se,则是这位裁缝手中的…...