ZooKeeper+Kafka+ELK+Filebeat集群搭建实现大批量日志收集和展示
文章目录
- 一、集群环境准备
- 二、搭建 ZooKeeper 集群和配置
- 三、搭建 Kafka 集群对接zk
- 四、搭建 ES 集群和配置
- 五、部署 Logstash 消费 Kafka数据写入至ES
- 六、部署 Filebeat 收集日志
- 七、安装 Kibana 展示日志信息
一、集群环境准备
1.1 因为资源原因这里我就暂时先一台机器部署多个应用给大家演示
| 硬件资源 | 节点 | 组件 |
|---|---|---|
| 8c16g 50 | node1-192.168.40.162 | Kafka+ZooKeeper,ES-7.9.2+Logstash-7.9.2 |
| 8c16g 50 | node2-192.168.40.163 | Kafka+ZooKeeper,ES-7.9.2,Kibana-7.9.2 |
| 8c16g 50 | node3-192.168.40.164 | Kafka+ZooKeeper,ES-7.9.2,Filebeat-7.9.2,Elasticsearch-head |
二、搭建 ZooKeeper 集群和配置
2.1 修改时区 - 修改主机名 - 安装JDK环境变量 - 停防火墙(三台一样设置)
[root@node1 ~]# rm -f /etc/localtime && ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
[root@node1 ~]# date#修改主机名
[root@node1 ~]# hostnamectl set-hostname node3#检查JDK环境变量
[root@node1 ~]# java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)#停防火墙并关闭
[root@node1 ~]# systemctl stop firewalld && setenforce 0 && systemctl disable firewalld#三台都设置同样的DNS解析
[root@node1 ~]# vim /etc/hosts
192.168.40.162 node1
192.168.40.163 node2
192.168.40.164 node3
2.1 安装 ZooKeeper
#下载zk安装包
[root@node1 ~]# wget http://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
#解压到指定目录并修改文件夹名
[root@node1 ~]# tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /usr/local/
[root@node1 ~]# mv /usr/local/apache-zookeeper-3.8.0-bin/ /usr/local/zookeeper-3.8.0
#备份原始配置文件
[root@node1 ~]# mv /usr/local/zookeeper-3.8.0/conf/zoo_sample.cfg /usr/local/zookeeper-3.8.0/conf/zoo.cfg
[root@node1 ~]# cp /usr/local/zookeeper-3.8.0/conf/zoo.cfg /usr/local/zookeeper-3.8.0/conf/zoo.cfg_bak
2.2 修改三台 zk 配置文件
[root@node1 ~]# vim /usr/local/zookeeper-3.8.0/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
#这个目录要自己创建不然启动会报错,省了重新创建一次
dataDir=/tmp/zookeeper
clientPort=2181
#集群地址
server.1=192.168.40.162:3188:3288
server.2=192.168.40.163:3188:3288
server.3=192.168.40.164:3188:3288# 其他两台都执行以上的部署和修改文件,配置文件可以通过scp进行传输
[root@node1 ~]# cd /usr/local/zookeeper-3.8.0/conf/
[root@node1 ~]# scp zoo_sample.cfg 192.168.40.163:/usr/local/zookeeper-3.8.0/conf 192.168.40.164:/usr/local/zookeeper-3.8.0/conf#创建文件并指定节点号 注意:每台都要执行,并且节点号不能相同 myid 必须在dataDir 数据目录下
[root@node1 ~]# echo 1 > /tmp/zookeeper/myid
[root@node2 ~]# echo 2 > /tmp/zookeeper/myid
[root@node3 ~]# echo 3 > /tmp/zookeeper/myid
2.3 启动 3台的 zk 并查看集群状态
#要三台都起起来 才能看到主从
[root@node1 ~]# sh /usr/local/zookeeper/bin/zkServer.sh start[root@node1 ~]# sh /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader #主[root@node2 ~]# sh /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower #从[root@node2 ~]# sh /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower #从
三、搭建 Kafka 集群对接zk
3.1 安装 Kafka
#下载 kafka安装包
[root@node1 ~]# wget http://archive.apache.org/dist/kafka/2.7.1/kafka_2.13-2.7.1.tgz#解压到指定目录
[root@node1 ~]# tar -zxvf kafka_2.13-2.7.1.tgz -C /usr/local/
[root@node1 ~]# mv /usr/local/kafka_2.13-2.7.1/ /usr/local/kafka
[root@node1 ~]# cp /usr/local/kafka/config/server.properties /usr/local/kafka/config/server.properties_bak
3.2 修改三台 zk 配置文件 并配置环境变量
[root@node1 ~]# vim /usr/local/kafka/config/server.properties
#borkerid 每台都不一样 不能重复
broker.id=1
#本地监听地址
listeners=PLAINTEXT://192.168.40.162:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zk 集群地址
zookeeper.connect=192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
#borkerid 每台都不一样 不能重复
broker.id=2
#本地监听地址
listeners=PLAINTEXT://192.168.40.163:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zk 集群地址
zookeeper.connect=192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
#borkerid 每台都不一样 不能重复
broker.id=3
#本地监听地址
listeners=PLAINTEXT://192.168.40.164:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zk 集群地址
zookeeper.connect=192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
[root@node1 ~]# vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin[root@node1 ~]# source /etc/profile
3.3 启动kafka (命令可以在任意路径执行,不需要填写绝对路径)
[root@node1 ~]# sh /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
#检查端口
[root@node1 ~]# netstat -tunlp | grep 9092
3.4 Kafka常用命令行操作
#查看当前服务器中的所有topic
kafka-topics.sh --list --zookeeper 192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181
#查看某个topic的详情
kafka-topics.sh --describe --zookeeper 192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181
#发布消息
kafka-console-producer.sh --broker-list 192.168.40.162:9092,192.168.40.163:9092,192.168.40.164:9092 --topic test
#消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.40.162:9092,192.168.40.163:9092,192.168.40.164:9092 --topic test --from-beginning
--from-beginning 会把主题中以往所有的数据都读取出来
#修改分区数
kafka-topics.sh --zookeeper 192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181 --alter --topic test --partitions 6
#删除topic
kafka-topics.sh --delete --zookeeper 192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181 --topic test
3.5 Kafka命令创建Topic
[root@node1 ~]# sh /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper \
> 192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181 \
> --partitions 3 \
> --replication-factor 2 \
> --topic test
Created topic test.--zookeeper: 定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor: 定义分区副本数,1 代表单副本,建议为 2
--partitions: 定义分区数
--topic: 定义 topic 名称#查看Topic 信息,三台都随便查某个节点
[root@node1 ~]# sh /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.40.163:2181
Topic: test PartitionCount: 3 ReplicationFactor: 2 Configs: Topic: test Partition: 0 Leader: 1 Replicas: 1,3 Isr: 1,3Topic: test Partition: 1 Leader: 3 Replicas: 3,1 Isr: 3,1Topic: test Partition: 2 Leader: 1 Replicas: 1,3 Isr: 1,3
3.6 测试 Kafka-Topic
#发布消息
[root@node1 logs]# kafka-console-producer.sh --broker-list 192.168.40.162:9092,192.168.40.163:9092,192.168.40.164:9092 --topic test
>1
>2
>3
>4
>5
>6
>7
#消费消息
[root@node1 logs]# kafka-console-consumer.sh --bootstrap-server 192.168.40.162:9092,192.168.40.163:9092,192.168.40.164:9092 --topic test --from-beginning
5
6
exit
3
4
quit
1
2
7
qu
q
四、搭建 ES 集群和配置
4.1 三台主机安装 ES 修改配置文件并启动
#下载ES安装包
[root@node1 ~]# wget http://dl.elasticsearch.cn/elasticsearch/elasticsearch-7.9.2-x86_64.rpm#安装
[root@node1 ~]# rpm -ivh elasticsearch-7.9.2-x86_64.rpm#备份原始配置文件
[root@node1 ~]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml_bak
#修改 Node1 配置文件
[root@node1 elasticsearch]# vim /etc/elasticsearch/elasticsearch.yml#集群名
cluster.name: my-application
#节点名
node.name: node1
#数据存放路径,生产建议改为挂载盘
path.data: /var/lib/elasticsearch
#日志存放路径
path.logs: /var/log/elasticsearch
#网络
network.host: 0.0.0.0
#监听端口
http.port: 9200
#集群节点设置,不需要写端口号默认9300 内部通信端口
discovery.seed_hosts: ["192.168.40.162", "192.168.40.163", "192.168.40.164"]
#集群Master节点数
cluster.initial_master_nodes: ["node1","node2","node3"]
#修改 Node2 配置文件
#集群名
cluster.name: my-application
#节点名
node.name: node2
#数据存放路径,生产建议改为挂载盘
path.data: /var/lib/elasticsearch
#日志存放路径
path.logs: /var/log/elasticsearch
#网络
network.host: 0.0.0.0
#监听端口
http.port: 9200
#集群节点设置,不需要写端口号默认9300 内部通信端口
discovery.seed_hosts: ["192.168.40.162", "192.168.40.163", "192.168.40.164"]
#集群Master节点数
cluster.initial_master_nodes: ["node1","node2","node3"]
#修改 Node3 配置文件
#集群名
cluster.name: my-application
#节点名
node.name: node3
#数据存放路径,生产建议改为挂载盘
path.data: /var/lib/elasticsearch
#日志存放路径
path.logs: /var/log/elasticsearch
#网络
network.host: 0.0.0.0
#服务端口
http.port: 9200
#集群节点设置,不需要写端口号默认9300 内部通信端口
discovery.seed_hosts: ["192.168.40.162", "192.168.40.163", "192.168.40.164"]
#集群Master节点数
cluster.initial_master_nodes: ["node1","node2","node3"]
#启动三台ES 并设置开机自启动,浏览器访问服务端口,检查集群是否监控
[root@node1 elasticsearch]# systemctl start elasticsearch && systemctl enable elasticsearch
● elasticsearch.service - ElasticsearchLoaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: disabled)Active: active (running) since Fri 2023-04-07 15:31:50 CST; 1min 24s agoDocs: https://www.elastic.coMain PID: 38495 (java)CGroup: /system.slice/elasticsearch.service├─38495 /usr/share/elasticsearch/jdk/bin/java -Xshare:auto -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 ...└─38705 /usr/share/elasticsearch/modules/x-pack-ml/platform/linux-x86_64/bin/controllerApr 07 15:31:28 node3 systemd[1]: Starting Elasticsearch...
Apr 07 15:31:50 node3 systemd[1]: Started Elasticsearch.#status key 为green 则为健康
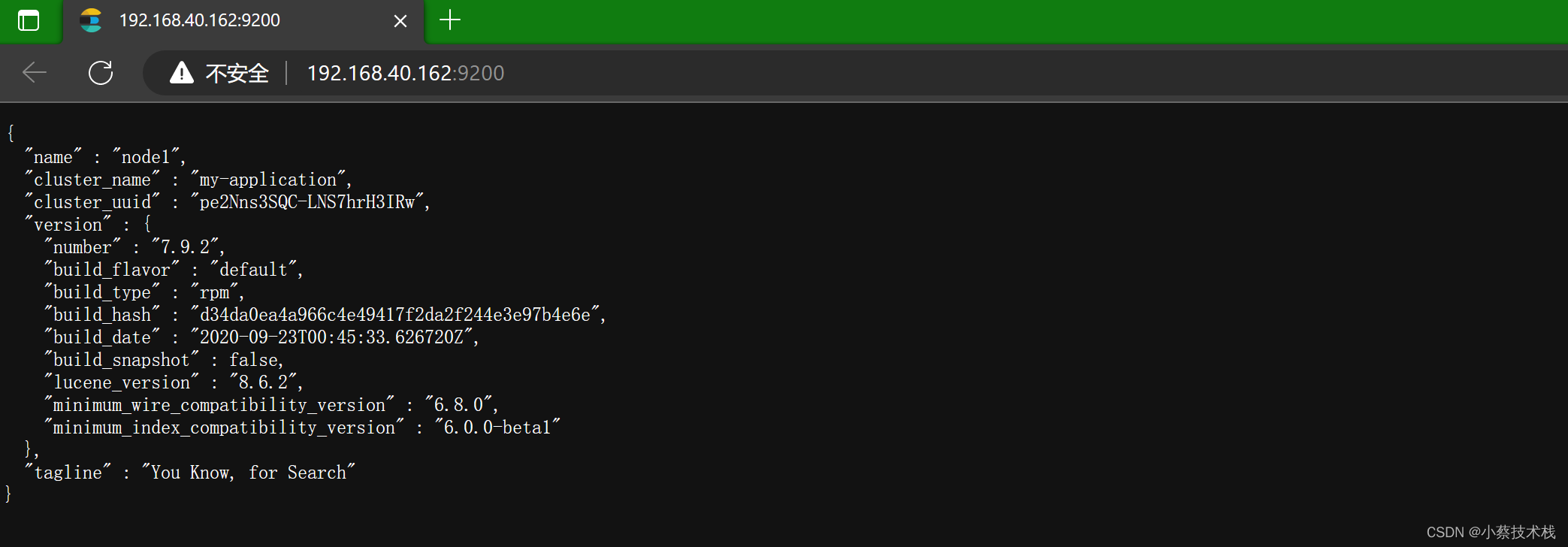
[root@node1 elasticsearch]# curl http://192.168.40.162:9200/_cluster/health?pretty
{"cluster_name" : "my-application","status" : "green","timed_out" : false,"number_of_nodes" : 3,"number_of_data_nodes" : 3,"active_primary_shards" : 0,"active_shards" : 0,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}

4.2 部署 Elasticsearch-head 数据可视化工具
# head插件是Nodejs实现的,所以需要先安装Nodejs
[root@node3 ~]# wget https://nodejs.org/dist/v12.18.4/node-v12.18.4-linux-x64.tar.xz
#注意这里是 -xf 参数
[root@node3 ~]# tar -xf node-v12.18.4-linux-x64.tar.xz
[root@node3 ~]# vim /etc/profile
# 添加 如下配置
export NODE_HOME=/root/node-v12.18.4-linux-x64
export PATH=$NODE_HOME/bin:$PATH#从Git 上下载安装包
[root@node3 ~]# wget https://github.com/mobz/elasticsearch-head/archive/master.zip
[root@node3 ~]# unzip master.zip
[root@node3 ~]# mv elasticsearch-head-master/ elasticsearch-head
[root@node3 ~]# cd elasticsearch-head
#此步安装的比较慢耐心等待
[root@node3 elasticsearch-head]# npm install
#后台启动插件
[root@node3 elasticsearch-head]# npm run start &#修改三台的ES配置文件
--末尾添加以下内容--
http.cors.enabled: true #开启跨域访问支持,默认为false
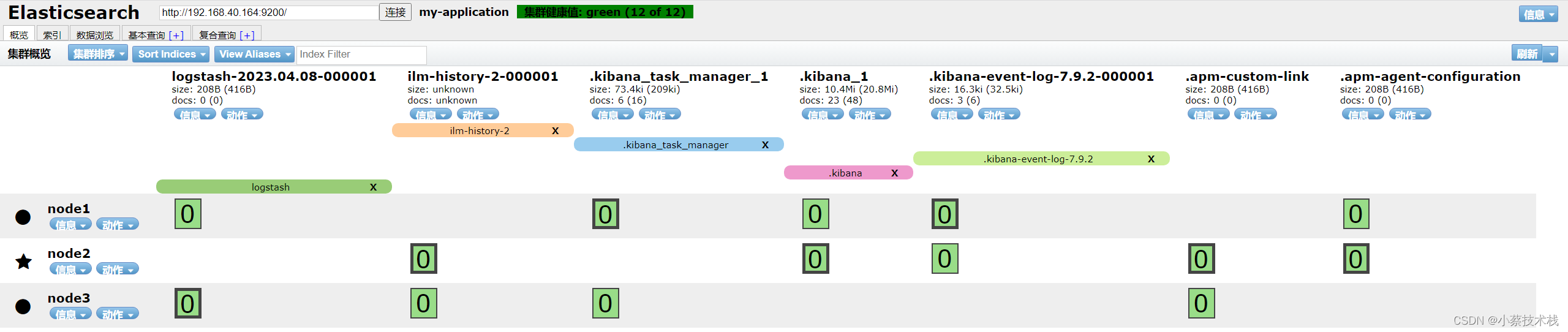
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有4.3 访问 Elasticsearch-head
http://192.168.40.164:9100/
五、部署 Logstash 消费 Kafka数据写入至ES
5.1 安装 Logstash
#我这里安装三台,你也可以安装在一台上进行测试
[root@node1 ~]# wget http://dl.elasticsearch.cn/logstash/logstash-7.9.2.rpm
[root@node1 ~]# rpm -ivh logstash-7.9.2.rpm
[root@node1 ~]# vim /etc/logstash/conf.d/logstash.conf
#下面一定要按照格式写,不然会不识别
input {kafka {codec => "plain"topics => ["test"]bootstrap_servers => "192.168.40.162:9092,192.168.40.163:9092,192.168.40.164:9092"max_poll_interval_ms => "3000000"session_timeout_ms => "6000"heartbeat_interval_ms => "2000"auto_offset_reset => "latest"group_id => "logstash"type => "logs"}
}
output {elasticsearch {hosts => ["http://192.168.40.162:9200", "http://192.168.40.163:9200","http://192.168.40.164:9200"]index => "test-%{+YYYY.MM.dd}"}
}#配置软连 方便用命令检查配置文件
[root@node1 ~]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
[root@node1 ~]# logstash -t
5.2 检查配置的时候报错提示如下 寻找这个文件失败,原因是因为我用rpm 装的,文件位置在/etc/logstash/ 下面,它去标红的路径下面去找了
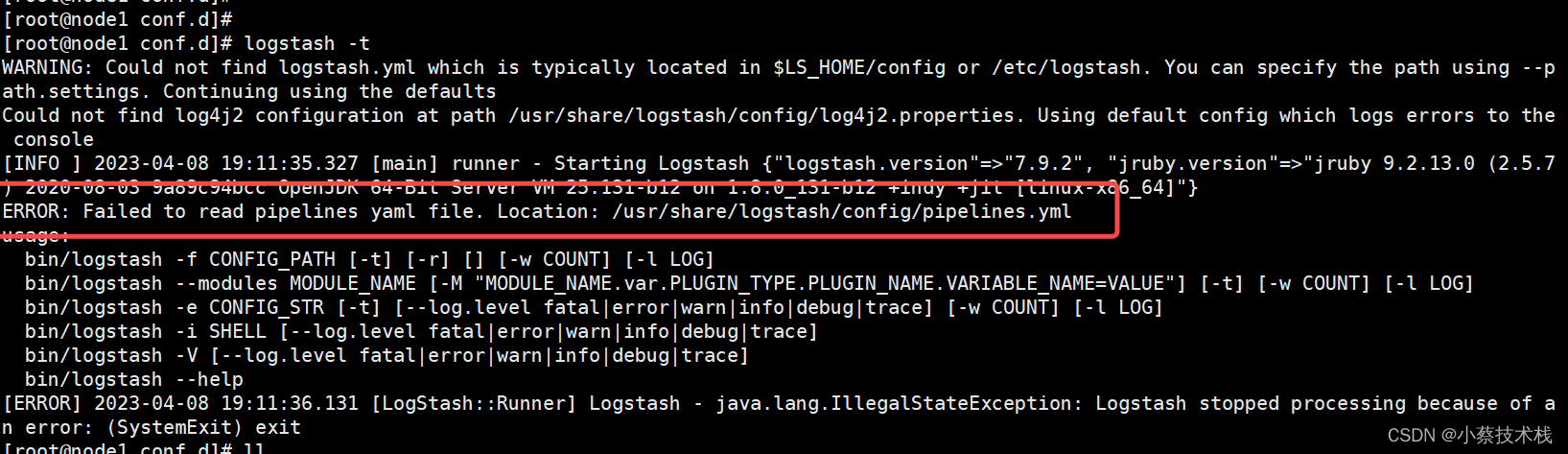
#/usr/share/logstash/ 目录下面少了一层config,我们这里来创建
[root@node1 ~]# mkdir -p /usr/share/logstash/config/
#把/etc/logstash/pipelines.yml cp到 /usr/share/logstash/config/下面
[root@node1 ~]# cp /etc/logstash/pipelines.yml /usr/share/logstash/config/
5.3 再次测试文件的时候 又报了一个错误,这个错误是因为 配置文件配置的有误导致的
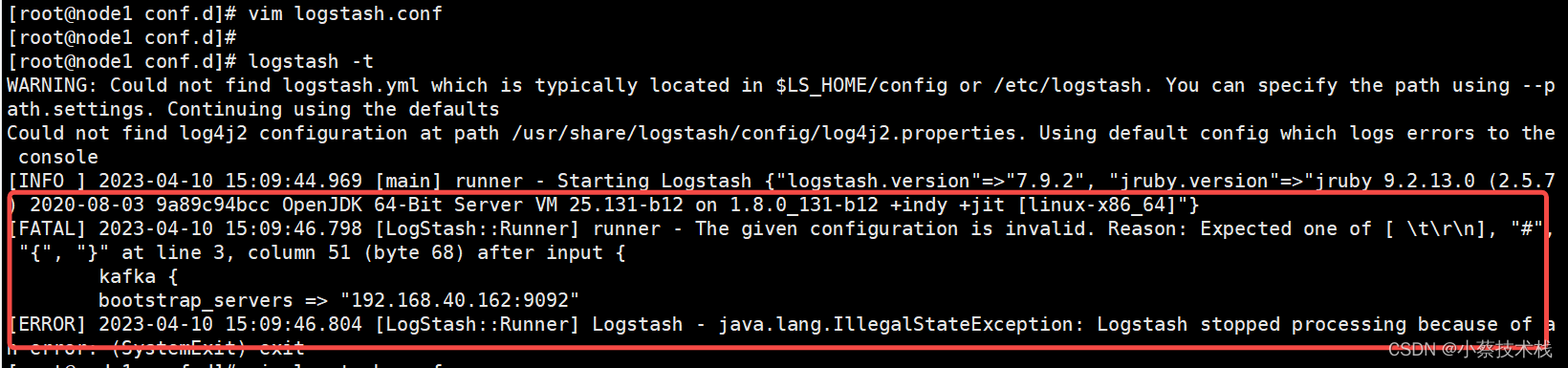
#启动 Logstash
[root@node1 ~]# systemctl start logstash && systemctl enable logstash
#查看日志是否消费了Kafka信息
[root@node1 ~]# tail -f /var/log/logstash/logstash-plain.log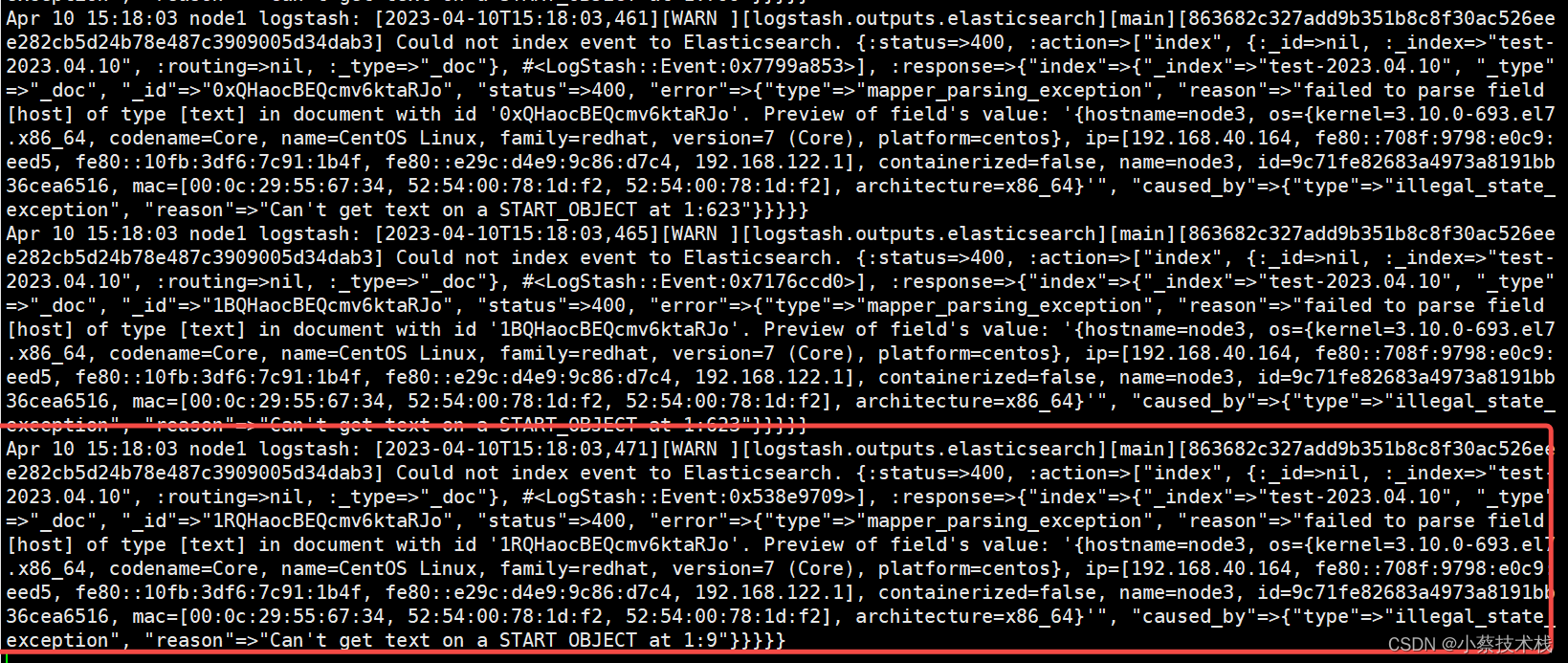
六、部署 Filebeat 收集日志
[root@node3 ~]# wget http://dl.elasticsearch.cn/filebeat/filebeat-7.9.2-x86_64.rpm
[root@node3 ~]# rpm -ivh filebeat-7.9.2-x86_64.rpm
#配置Filebeat 收集NG日志信息
[root@node3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: logenabled: falsepaths:#收集日志地址- /usr/local/openresty/nginx/logs/*.log
output.kafka:#配置Kafka地址hosts: ["192.168.40.162:9092","192.168.40.163:9092","192.168.40.164:9092"]#这个Topic 要和Kafka一致topic: 'test'

七、安装 Kibana 展示日志信息
7.1 安装并配置
#下载
[root@node2 ~]# wget http://dl.elasticsearch.cn/kibana/kibana-7.9.2-x86_64.rpm
[root@node2 ~]# rpm -ivh kibana-7.9.2-x86_64.rpm
[root@node2 ~]# vim /etc/kibana/kibana.yml
#WEB访问端口
server.port: 5601
server.host: "0.0.0.0"
#ES集群地址
elasticsearch.hosts: ["http://192.168.40.162:9200/","http://192.168.40.163:9200/","http://192.168.40.164:9200/"]
kibana.index: ".kibana"
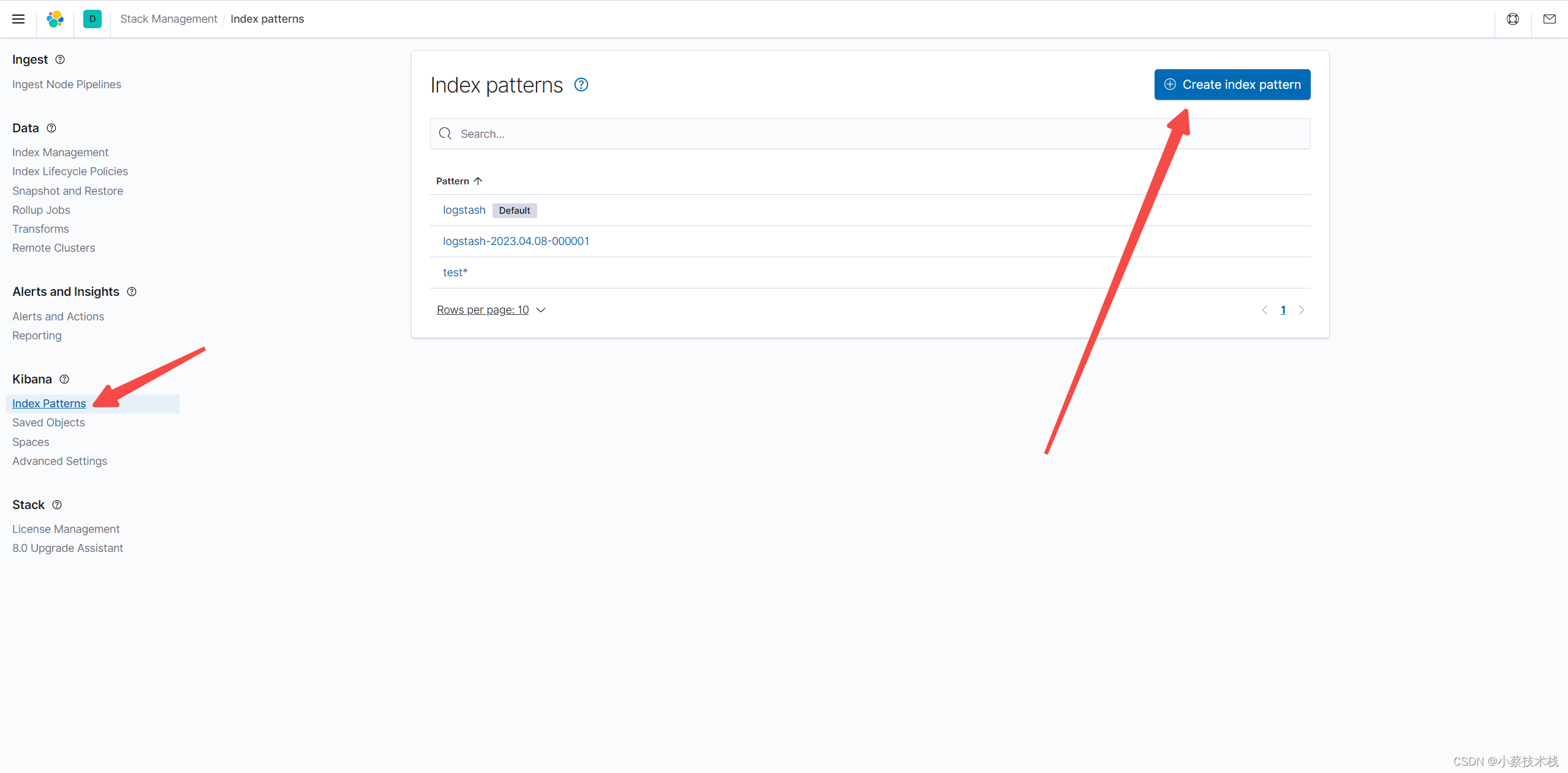
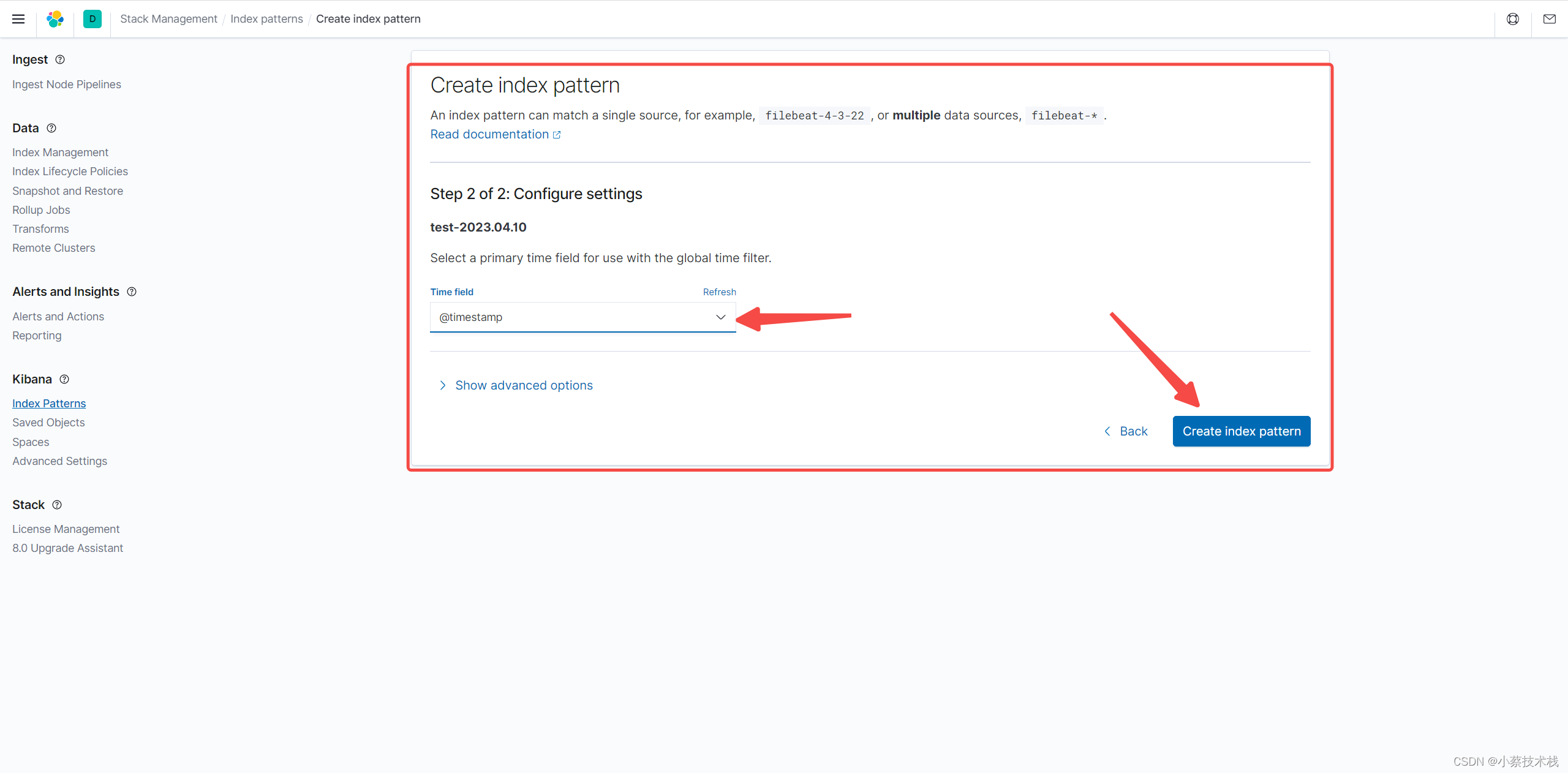
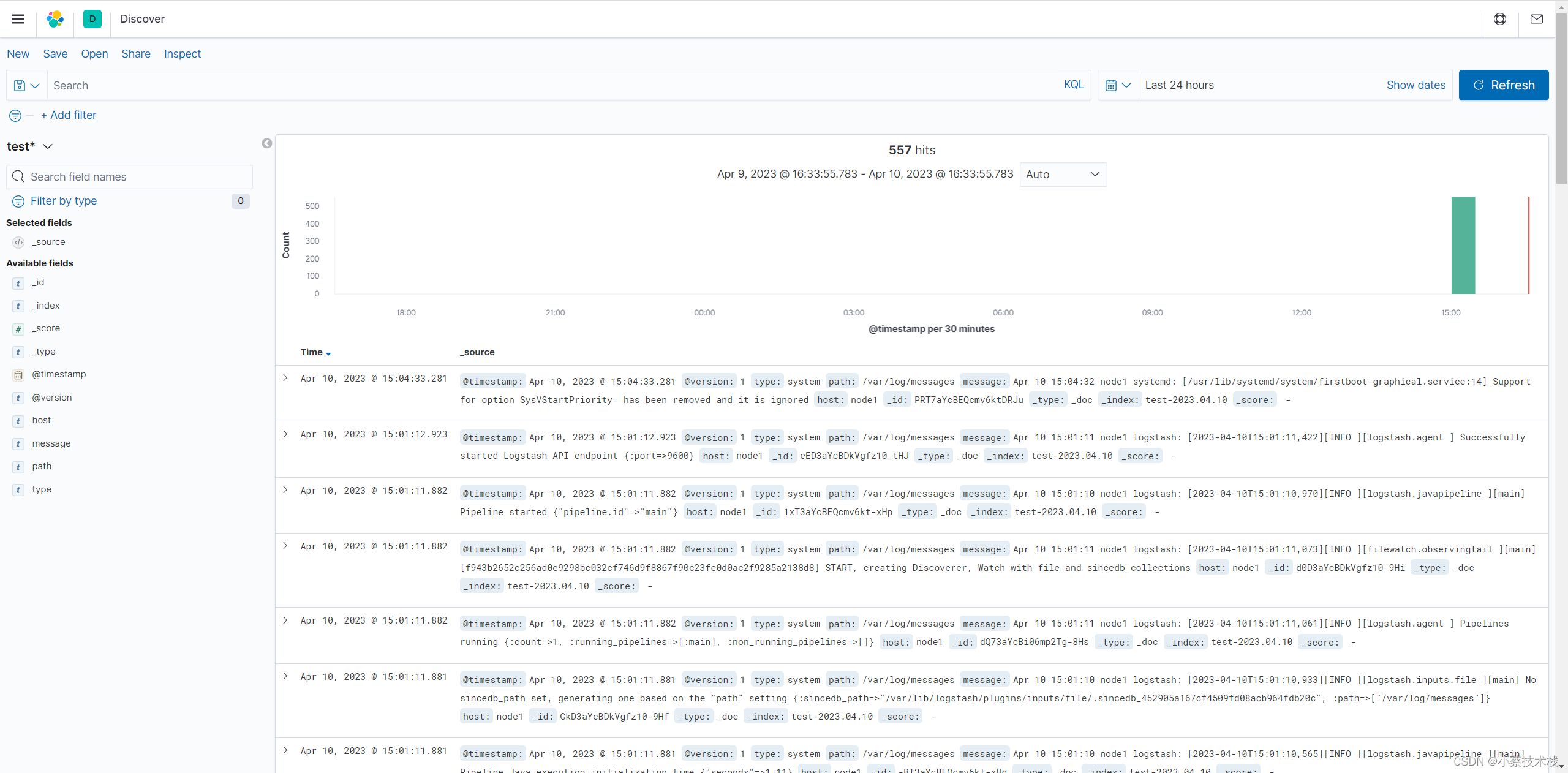
7.2 配置索引

相关文章:
ZooKeeper+Kafka+ELK+Filebeat集群搭建实现大批量日志收集和展示
文章目录一、集群环境准备二、搭建 ZooKeeper 集群和配置三、搭建 Kafka 集群对接zk四、搭建 ES 集群和配置五、部署 Logstash 消费 Kafka数据写入至ES六、部署 Filebeat 收集日志七、安装 Kibana 展示日志信息一、集群环境准备 1.1 因为资源原因这里我就暂时先一台机器部署多…...

数据结构初阶 - 总结
-0- 数据结构前言 什么是数据结构 什么是算法 数据结构和算法的重要性-1- 时间复杂度和空间复杂度 👉数据结构 -1- 时间复杂度和空间复杂度 | C 算法效率 时间复杂度大O的渐进表示法eg 空间复杂度 常见复杂度对比OJ 消失的数组 轮转数组-2- 顺序表 与 链表 &am…...
)
代码随想录算法训练营第四十四天-动态规划6|518. 零钱兑换 II ,377. 组合总和 Ⅳ (遍历顺序决定是排列还是组合)
如果求组合数就是外层for循环遍历物品,内层for遍历背包。 如果求排列数就是外层for遍历背包,内层for循环遍历物品。 求物品可以重复使用时,最好是用一维数组,会比较方便。二维数组不想思考了,二维还是用在01背吧吧。…...
wma格式怎么转换mp3,4种方法超快学
其实我们在任何电子设备上所获取的音频文件都具有自己的格式,每种格式又对应着自己的属性特点。比如wma就是一种音质优于MP3的音频格式,虽然很多小伙伴比较青睐于wma所具有的音质效果,但也不得不去考虑因wma自身兼容性而引起很多播放器不能支…...
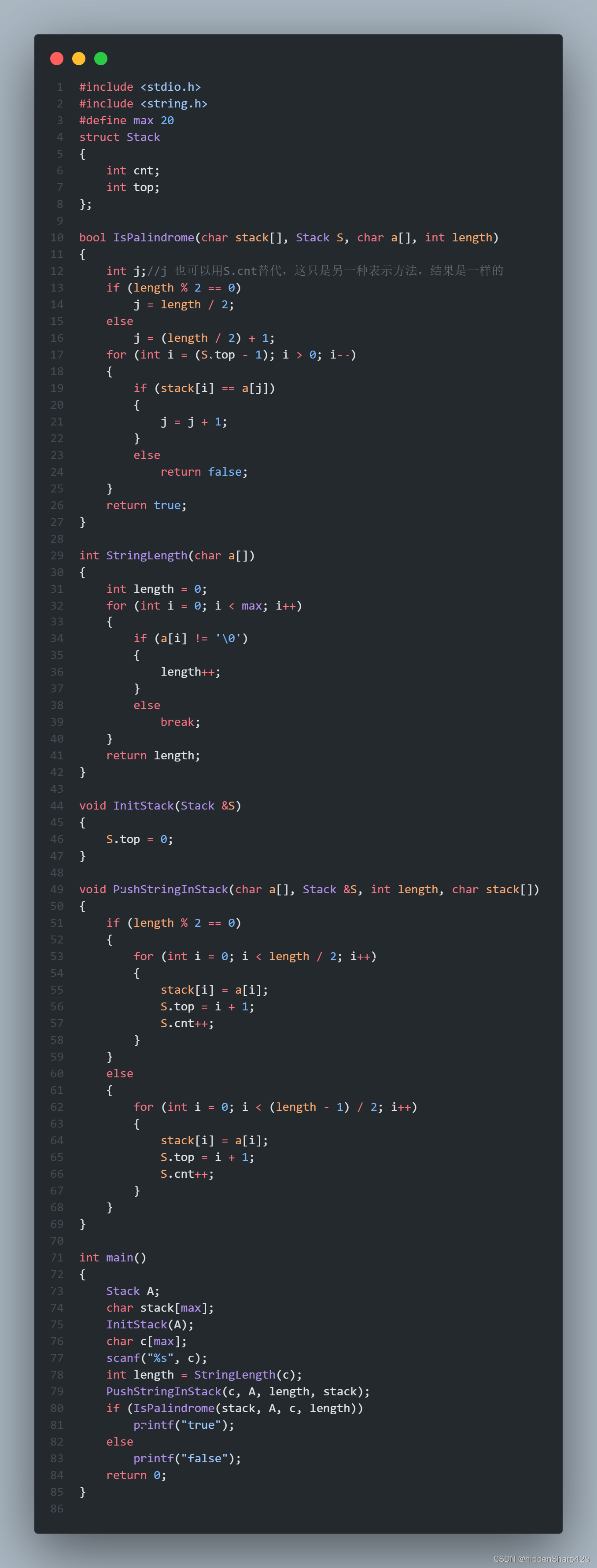
【数据结构与算法】判定给定的字符向量是否为回文算法
题目: Qestion: 试写一个算法判定给定的字符向量是否为回文。 回文解释: 回文是指正读反读均相同的字符序列,如“abba”和“abdba”均是回文,但“good”不是回文。 主要思路: 因为数据要求不是很严格并且是一个比较简单的…...
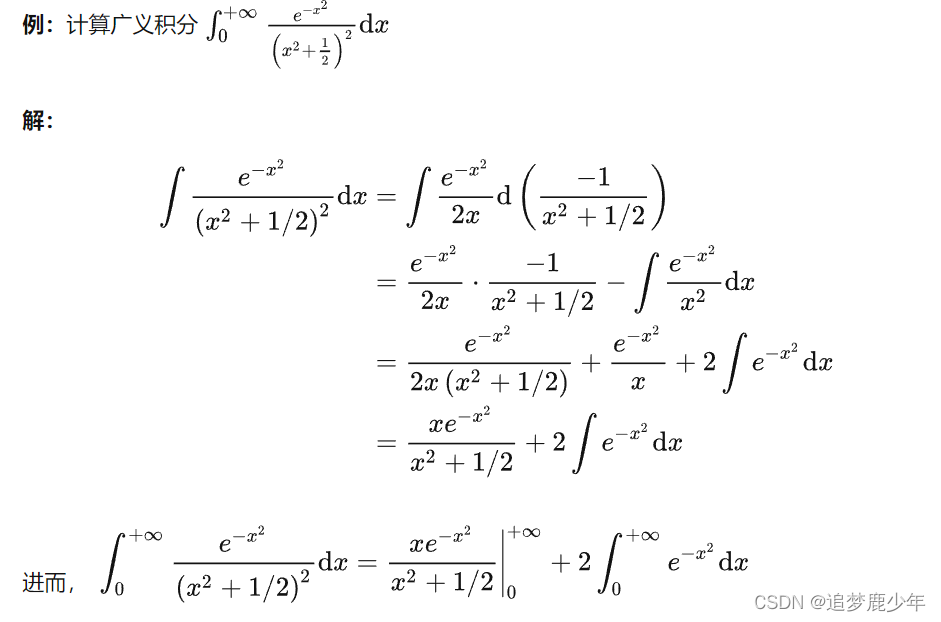
考研数二第十七讲 反常积分与反常积分之欧拉-泊松(Euler-Poisson)积分
反常积分 反常积分又叫广义积分,是对普通定积分的推广,指含有无穷上限/下限,或者被积函数含有瑕点的积分,前者称为无穷限广义积分,后者称为瑕积分(又称无界函数的反常积分)。 含有无穷上限/下…...
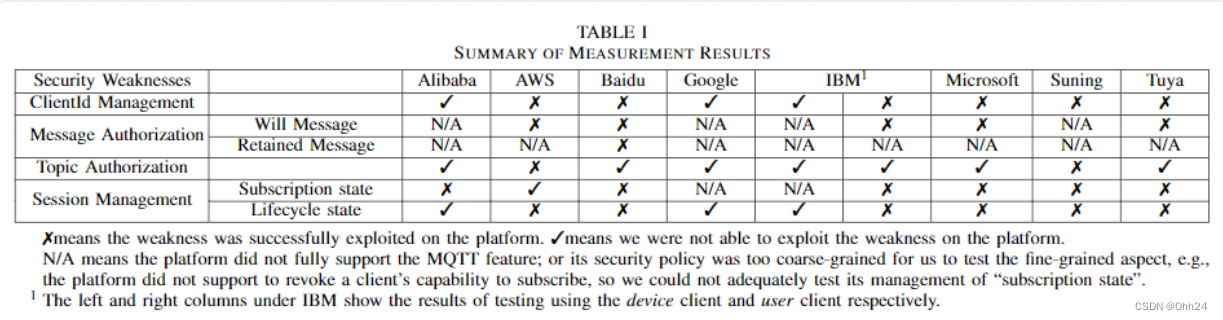
【论文总结】理解和减轻IoT消息协议的安全风险
理解和减轻IoT消息协议的安全风险介绍概述前置知识威胁模型MQTT IoT通信安全分析未授权的MQTT消息未授权的Will消息未经授权的保留消息MQTT会话管理故障未更新的会话订阅状态未更新的会话生命周期状态未经身份验证的 MQTT 身份客户端id劫持MQTT Topics的授权MQTT Topic不安全的…...

SpringBoot基础入门
一、概述 Spring Boot是一个开源的Java框架,它是基于Spring框架的基础之上创建的。Spring Boot可以帮助开发人员更快地创建Spring应用程序,并以最小的配置要求来运行它们。Spring Boot可以用于构建各种类型的应用程序,包括Web应用程序、RESTful API、批处理作业、消息传递应…...

jar 包与 war 包区别
1、war是一个web模块,其中需要包括WEB-INF,是可以直接运行的WEB模块;jar一般只是包括一些class文件,在声明了Main_class之后是可以用java命令运行的。 2、war包是做好一个web应用后,通常是网站,打成包部署…...

【数据结构:复杂度】时间复杂度
本节重点内容: 算法的复杂度时间复杂度的概念大O的渐进表示法常见时间复杂度计算举例⚡算法的复杂度 算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的&…...
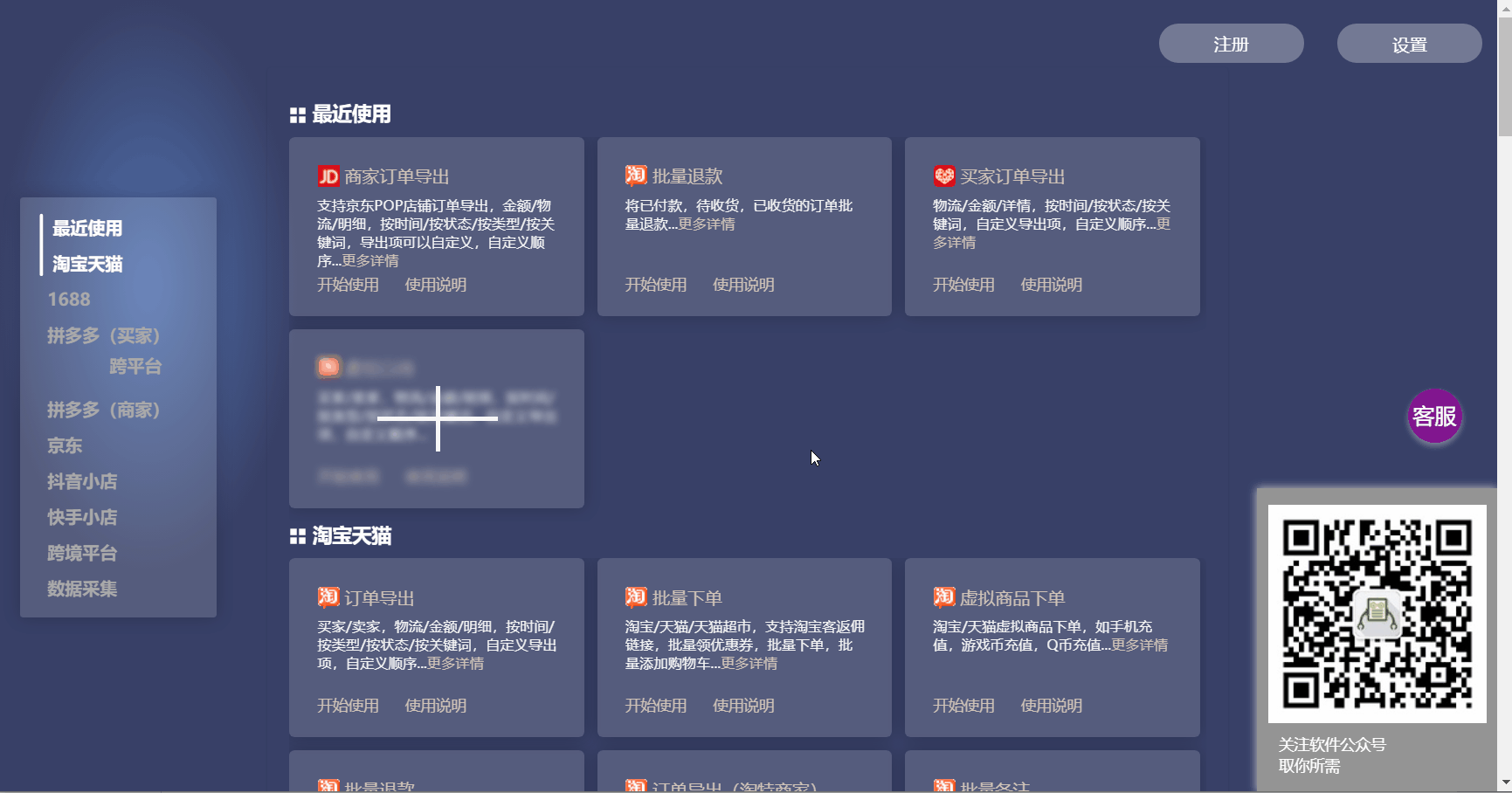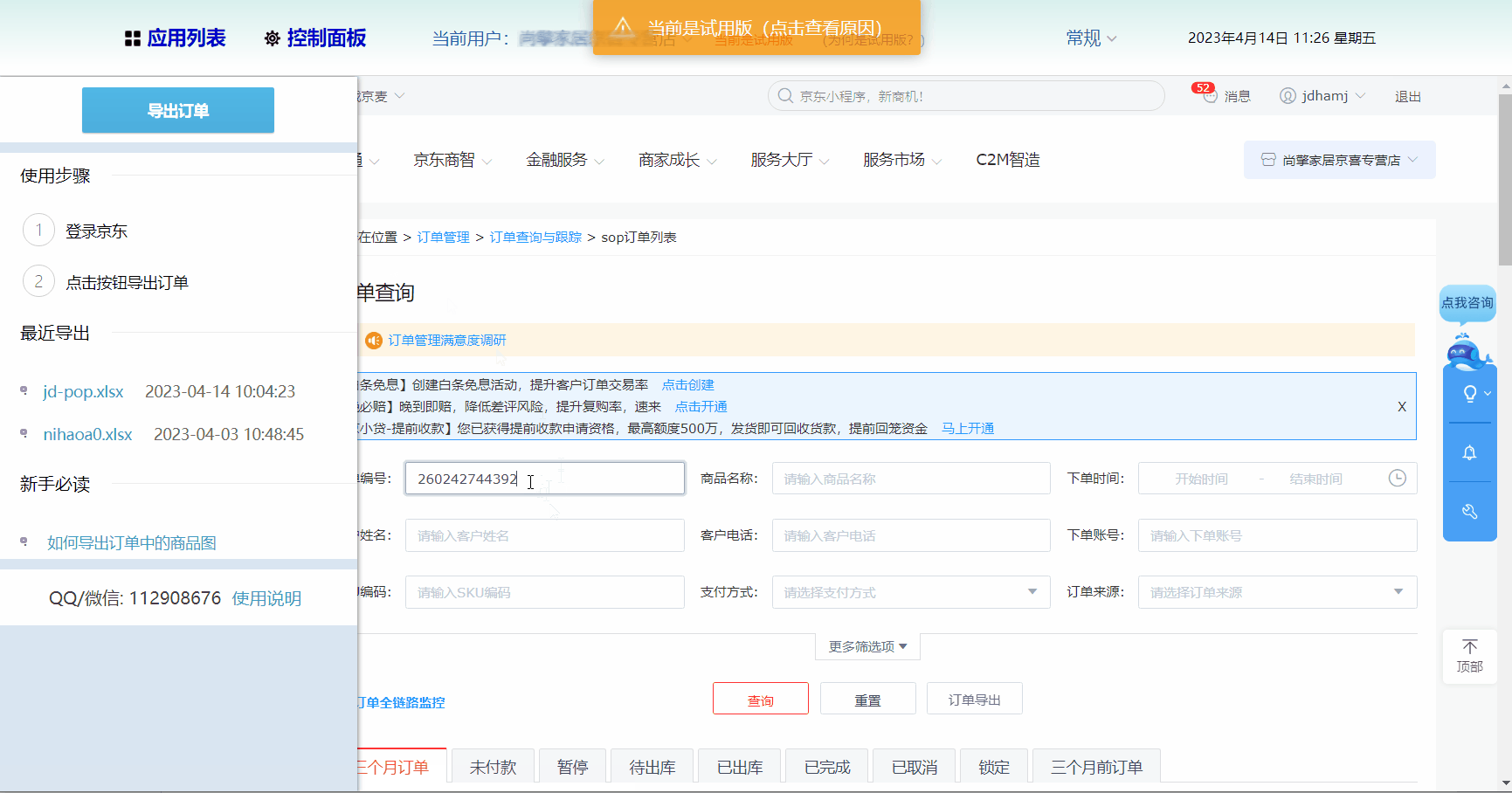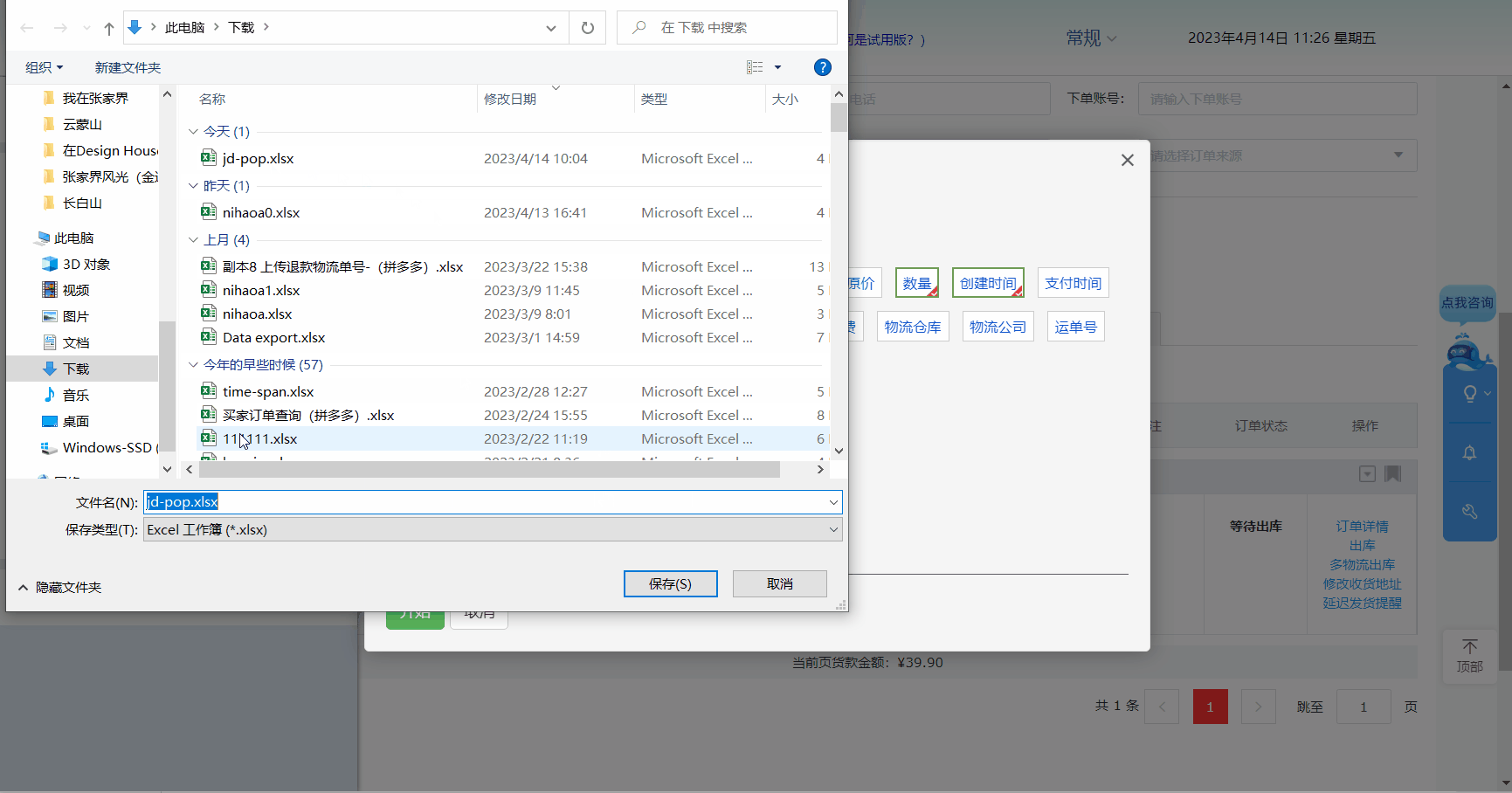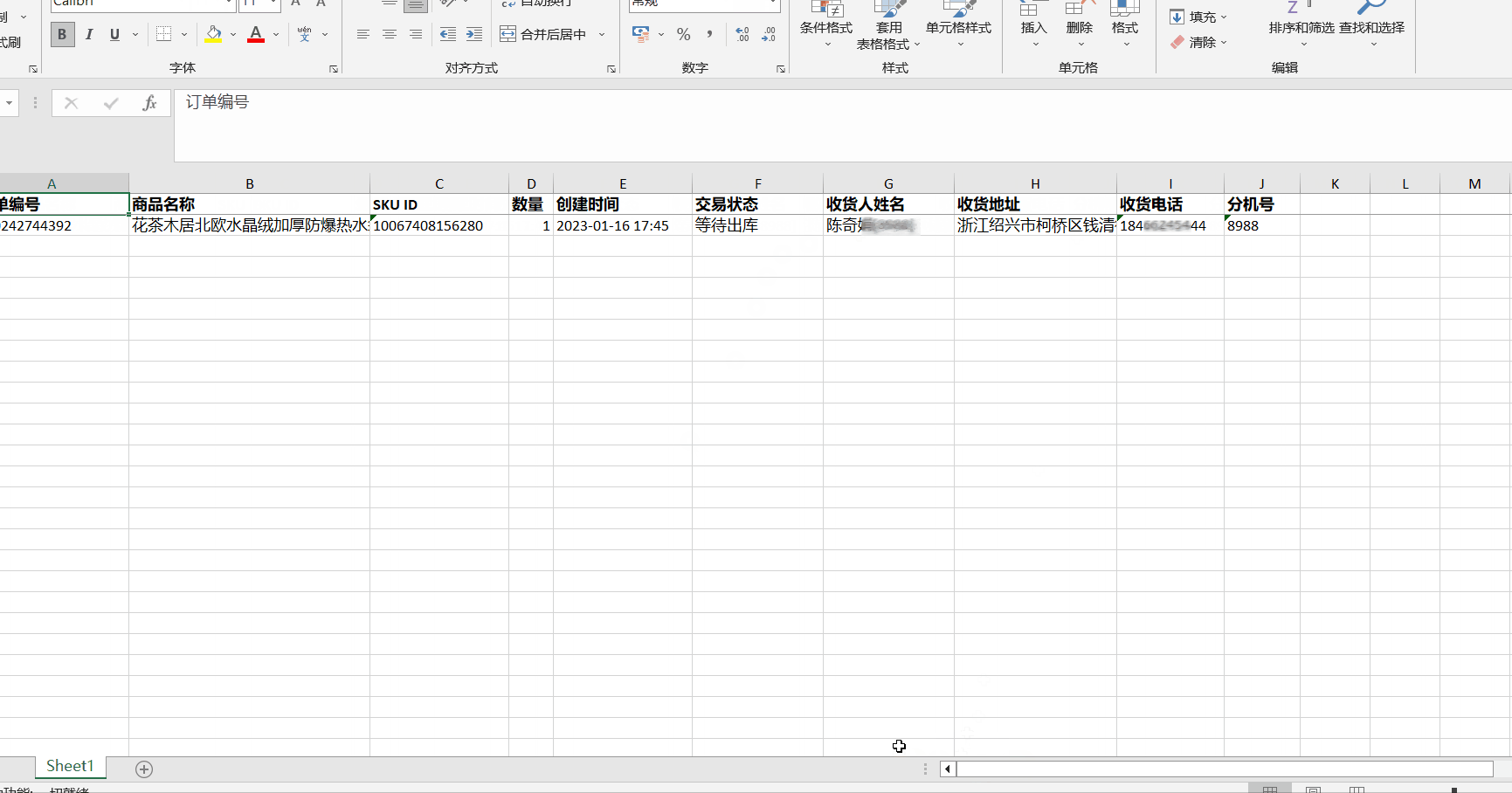
京东pop店铺订单导出
下载安装与运行 下载、安装与运行 语雀 特别提醒 只能导出已登录店铺的订单导出的收件人手机号是虚拟号 功能 主要是方便线下工厂发货的店主 所见即所得的导出自由选择导出项自由排序Excel导出列顺序导出过程中有进度提示,用户可以随时提前中止 什么是所见即所…...

论文阅读:Towards Stable Test-time Adaptation in Dynamic Wild World
今天阅读ICLR 2023 ——Towards Stable Test-time Adaptation in Dynamic Wild World Keywords:Test-time adaptation (TTA); 文章目录Towards Stable Test-time Adaptation in Dynamic Wild WorldProblem:motivation:Contributio…...

2022国赛27:Linux-1时间服务chrony配置
大赛试题内容: 3.利用chrony配置Linux-1为其他Linux主机提供时间同步服务。 解答过程: 安装chrony服务[root@cs1 ~]# yum -y install chrony 配置/etc/chrony.conf文件[root@cs1 ~]# vi /etc/chrony.conf 7行改为 server 10.10.70.101 iburst 23行改为 去掉#号 allow 1…...
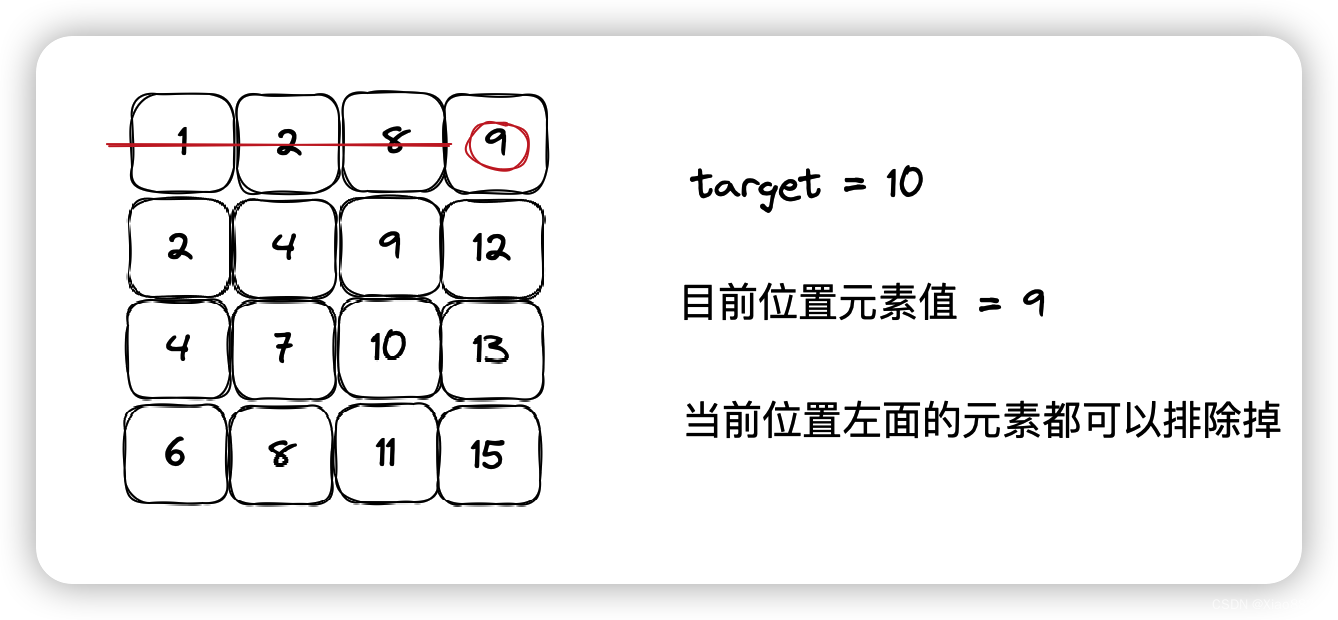
Java——二维数组中的查找
题目链接 牛客在线oj题——二维数组中的查找 题目描述 在一个二维数组array中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二…...

Android 9.0 添加关机铃声功能实现
1.前言 在9.0的系统rom定制化开发中,在原生系统中,关于开机铃声和关机铃声是默认不支持的,系统默认支持开机动画和关机动画等功能,所以关于增加开机铃声和关机 铃声的相关功能,需要自己增加相关的关机铃声功能 2.添加关机铃声功能实现的核心类 frameworks\base\cmds\boo…...

IPv4 和 IPv6 的组成结构和对比
IPv4 和 IPv6 的组成结构和对比IPv4IPv6互联网协议 (IP) 是互联网通信的基础,IP 地址是互联网上每个设备的唯一标识符。目前最常用的 IP 协议是 IPv4,它已经有近 30 年的历史了。然而,IPv4 存在一些问题,例如: 地址空间不足:IPv4 …...

Spring的事务管理
Spring的事务管理Spring的事务管理1、事务的回顾【1】事务的定义【2】事务的ACID原则2、spring事务API介绍【了解】【1】PlatformTransactionManager【1.1】PlatformTransactionManager作用【1.2】PlatformTransactionManager接口【1.3】PlatformTransactionManager实现类【2】…...
:VADC驱动配置详解(理论基础篇))
MCAL知识点(十六):VADC驱动配置详解(理论基础篇)
目录 1、概述 2、EB配置 2.1、通用界面配置 2.1.1、General 2.1.2、AdcConfigSet_0 2.1.3、AdcGlobinputClass 2.1.4、AdcHwUn...
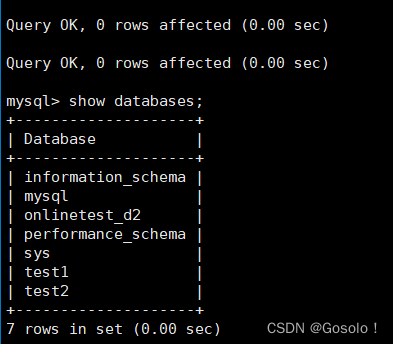
MySQL--库的操作--校验规则对于数据库的影响--0409
目录 1.库的基础操作 查看数据库 创建数据库 删除数据库 查看建库语句 修改数据库 2.字符集和字符集校验规则 2.1 查看系统默认字符集以及校验规则 2.2 使用特定的字符集创建数据库 2.3 不同校验规则对数据库的影响 2.3.1 大小写验证 2.3.2 排序验证 3.备份和恢复 3.1…...
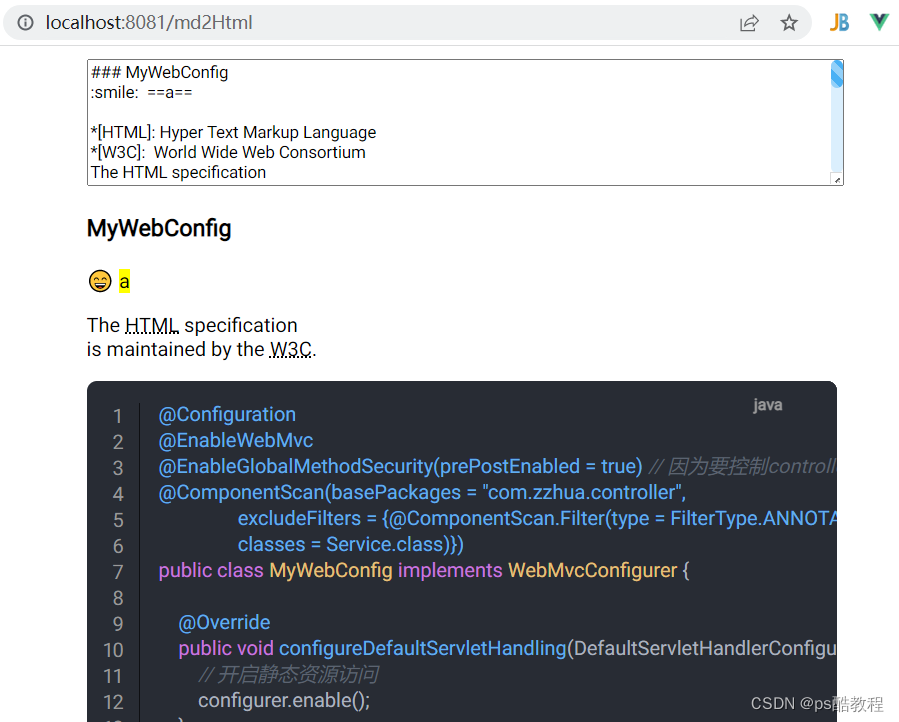
markdown-it基本使用
markdown-it能够将markdown语法的内容转换为html内容,这样我们使用markdown语法写的笔记,就可以转换作为网页使用了 Markdown语法 Markdown语法图文全面详解(10分钟学会) 基础使用 安装markdown-it npm install markdown-it --save使用markdown-it …...

如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南
如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经历过手机丢失、微信重装后珍贵聊天…...

机械臂时间冲击最优轨迹规划【附代码】
✨ 长期致力于串联机械臂、时间-冲击最优、轨迹规划、多目标粒子群算法、非支配排序遗传算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)构建基于…...

低配置电脑适配 OpenClaw 搭配 Ollama 流畅使用技巧
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑已成功安装运行 OpenClaw 客户端,顶部 Gateway 状态保持在线网络正常,可顺利访问 Ollama 官方网站电脑空余磁盘空间充足,本地 AI 模型占用体积较大提…...
)
藏文语音生成准确率从61.2%跃升至94.8%:ElevenLabs Fine-tuning私有数据集构建全流程(含217小时母语者录音标注规范)
更多请点击: https://intelliparadigm.com 第一章:藏文语音生成技术演进与ElevenLabs适配挑战 藏文作为具有复杂音节结构、声调隐含性及丰富上下文依赖的黏着语系文字,其语音合成长期受限于高质量标注语料稀缺、音素-音节映射不唯一、以及缺…...

VS Code光标主题buen-cursor:提升开发者编码体验的视觉优化方案
1. 项目概述:一个为开发者定制的光标主题 如果你和我一样,每天有超过8小时的时间都泡在代码编辑器里,那么你一定对那个闪烁的光标再熟悉不过了。它可能是你思考的起点,也可能是你调试时目光的焦点。但你是否想过,这个…...

Linux光标主题管理工具x-cursor-help:从原理到实战
1. 项目概述:一个被低估的鼠标光标辅助工具如果你在Linux桌面环境下工作,尤其是使用像GNOME、KDE Plasma这类现代化的桌面环境,你可能会遇到一个不大不小但很恼人的问题:鼠标光标主题的安装和管理。从网上下载了一个漂亮的.tar.gz…...

SQL学习指南——背景知识
关系型数据库中每个数据表都包含能够唯一标识某一行的信息(称为主键 primary key),以及完整描述实体所需的额外信息 一些数据表中还包含了导航到其他数据表的信息,这些列称为外键(foreign key) 术语术语定义实体数据库…...

005 DevEco Studio OHPM同步404报错 解决文档
[cs]005 DevEco Studio OHPM同步404报错 解决文档 文档简介 本文解决鸿蒙开发中新建空白项目自动触发ohpm install时报错:ohos/hypium、ohos/hamock包404找不到、拉取依赖失败问题。 核心原则:不修改项目任何自带文件、不删除系统生成依赖、不改动业务代…...

复杂系统交付中的风险治理与经济模型转型
1. 复杂系统交付中的风险本质与治理转型在航空航天、国防军工等复杂系统开发领域,项目失败率长期居高不下。根据IBM对全球500个大型系统的调研,73%的项目存在严重进度延迟,平均超支达到原始预算的189%。这种系统性失效的根源在于传统工程治理…...

基于RP2040与Santroller固件,复活旧吉他控制器玩转现代音游
1. 项目概述:让尘封的“神器”重获新生如果你和我一样,是个从《吉他英雄》、《摇滚乐队》时代走过来的老玩家,家里大概率还躺着一两把当年斥“巨资”购入的专用吉他控制器。它们手感扎实,造型酷炫,但最大的悲哀莫过于&…...